

Zusammenfassung der Syntaxregeln für MySQL-Datenbankunterabfragen

Dieser Artikel vermittelt Ihnen relevantes Wissen über MySQL, das hauptsächlich Probleme im Zusammenhang mit den Syntaxregeln für Datenbankunterabfragen behandelt. Dies liegt daran, dass wir viele unbekannte Daten extrahieren Abhängigkeiten haben; schauen wir uns diese gemeinsam an, ich hoffe, es wird für alle hilfreich sein.

Empfohlenes Lernen: MySQL-Video-Tutorial
Eine Unterabfrage ist eine in der Abfrageanweisung verschachtelte Abfrage. Dies liegt daran, dass beim Extrahieren von Daten viele unbekannte Daten vorhanden sind, die Abhängigkeiten aufweisen. Zu diesem Zeitpunkt müssen wir zuerst die Ergebnismenge eines Datensatzes abfragen und diese Ergebnismenge dann als Objekt der nächsten Abfrage verwenden. Im „Tabellenverbindungskapitel“ haben wir einmal über die geringe Effizienz von Unterabfragen gesprochen. Tatsächlich müssen nicht alle Unterabfragen beim Abgleichen von Datensätzen wiederholt ausgeführt werden. Wenn Sie jedoch die Abfrageergebnismenge als Tabelle verwenden und eine Verbindung mit anderen Tabellen herstellen, ist dies eine Unterabfrage der „FROM“-Klausel. Diese Unterabfragemethode wird weiterhin empfohlen.
Im Detail sind Unterabfragen in „Einzelzeilen-Unterabfrage“, „Mehrzeilen-Unterabfrage“, „WHERE“-Unterabfrage, „FROM“-Unterabfrage und „SELECT“-Unterabfrage unterteilt; das müssen wir in diesem Kapitel lernen.
Einführung in die Unterabfrage
Eine Unterabfrage ist eine Abfrageanweisung mit einer anderen darin verschachtelten Abfrage
Gewöhnliche Abfrageanweisungen sind in die Unterabfrage „SELECT“, die Unterabfrage „FROM“ und die Unterabfrage „WHERE“ unterteilt. Verwenden Sie „'; FROM' Unterabfrage")
Beispiele für Unterabfragen sind wie folgt:
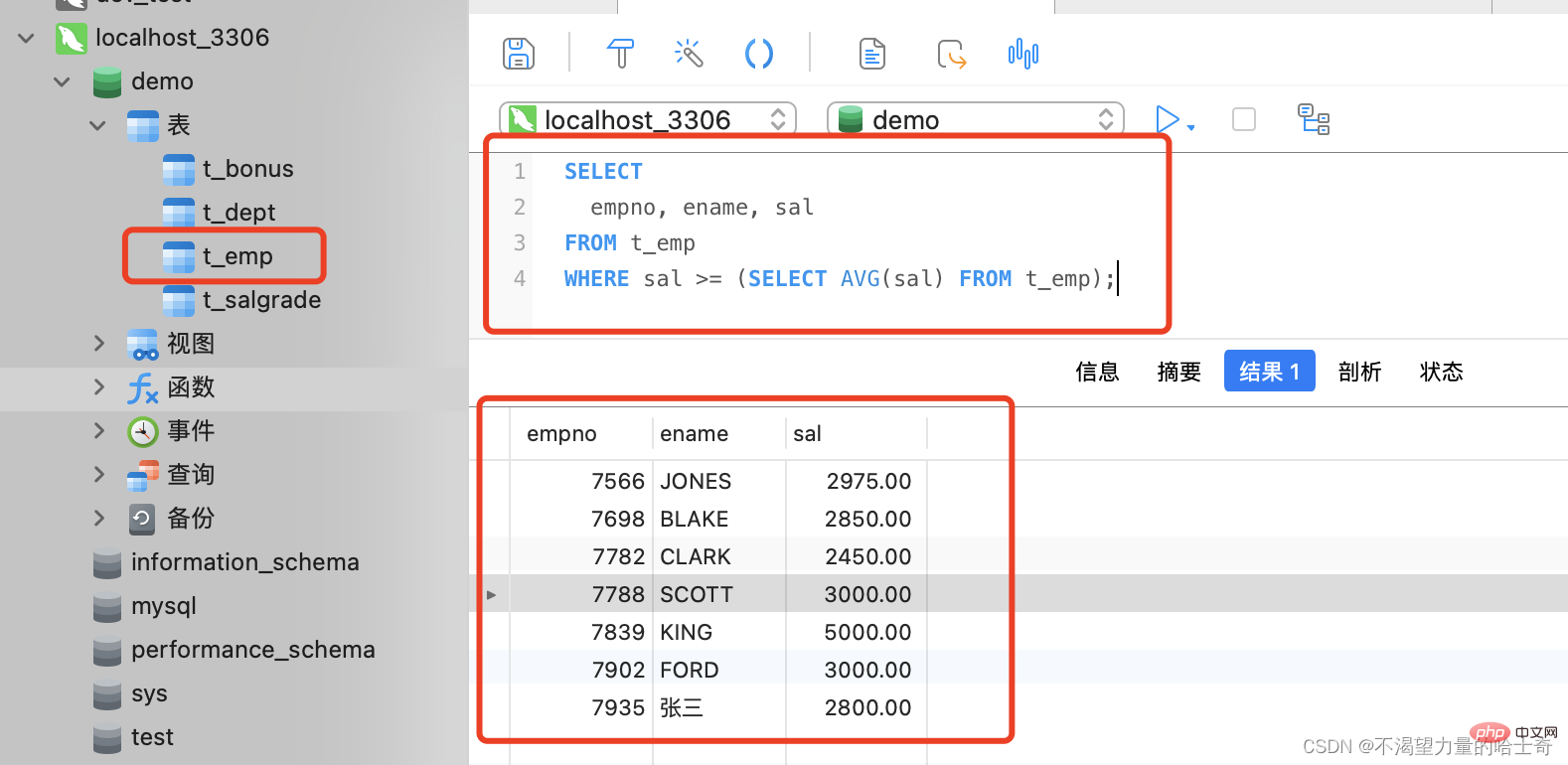
Informationen zu Mitarbeitern abfragen, deren Grundgehalt das durchschnittliche Grundgehalt des Unternehmens übersteigt. (Wir haben bereits Tabellenverknüpfungen verwendet, um diesen Fall zu erstellen. Schauen wir uns an, wie man ihn durch Unterabfragen implementiert.) Es wird nicht empfohlen, die Tabellenverknüpfungsmethode zu verwenden.
 WHERE-Unterabfrage
WHERE-Unterabfrage
Obwohl diese Art von Unterabfrage am einfachsten und am leichtesten zu verstehen ist, handelt es sich um eine sehr ineffiziente Unterabfrage
Nehmen wir die Abfrage Soeben wurde die Abfrage von Mitarbeiterinformationen gezeigt, deren Grundgehalt das durchschnittliche Grundgehalt des Unternehmens übersteigt. Wenn die „WHERE“-Klausel jeden Mitarbeiterdatensatz mit der „SELECT“-Unterabfrage vergleicht, muss die Unterabfrage erneut ausgeführt werden. Wenn die Mitarbeitertabelle 10.000 Datensätze enthält, muss die Unterabfrage 10.000 Mal ausgeführt werden. Eine wiederholte Ausführung so oft ist äußerst ineffizient.In der Abfrageanweisung wird die Unterabfrage, die wiederholt abgefragt wird, als „korrelierte Unterabfrage“ bezeichnet. Diese Art von Unterabfrage sollte vermieden werden.
 FROM-Unterabfrage
FROM-Unterabfrage
Auch am Beispiel der Abfrage von Mitarbeiterinformationen, deren Grundgehalt das durchschnittliche Grundgehalt des Unternehmens übersteigt, schauen wir uns an, wie die Unterabfrage „VON“ implementiert wird. SELECT
empno, ename, sal
FROM
t_emp
WHERE
sal >= (SELECT AVG(sal) FROM t_emp);
-- 正常情况下,将聚合函数作为 WHERE 子句的条件是不可以的,但是这里利用子查询与聚合函数先将平均底薪查询出来,这就变成具体的数据了
-- 这种情况下,作为 WHERE 子句的条件,就可以被使用了Nach dem Login kopieren
SELECT
empno, ename, sal
FROM
t_emp
WHERE
sal >= (SELECT AVG(sal) FROM t_emp);
-- 正常情况下,将聚合函数作为 WHERE 子句的条件是不可以的,但是这里利用子查询与聚合函数先将平均底薪查询出来,这就变成具体的数据了
-- 这种情况下,作为 WHERE 子句的条件,就可以被使用了Diese Frage kann also einfach mit der Unterabfrage „FROM“ implementiert werden, und es ist nicht notwendig, die Unterabfrage „WHERE“ zu verwenden. Da es sich bei der Unterabfrage „FROM“ nicht um eine korrelierte Unterabfrage handelt, sollte dieser Unterabfragetyp bei der Lösung einiger Probleme eingeschränkt werden.
 SELECT-Unterabfrage
SELECT-Unterabfrage
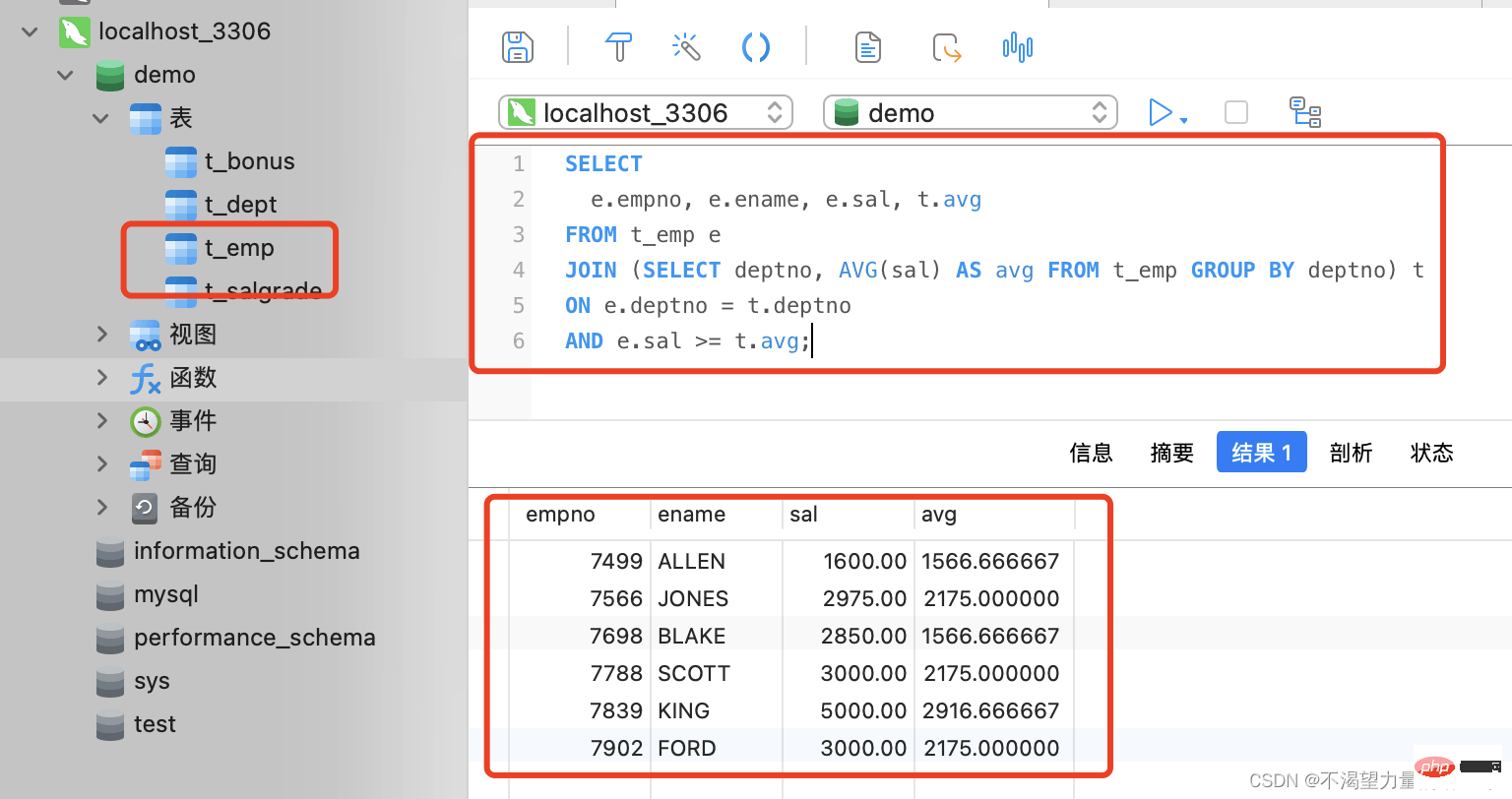
Der Grund dafür ist, dass die Unterabfrage „SELECT“ auch eine korrelierte Unterabfrage ist. Sie wird in der SQL-Anweisung wiederholt ausgeführt und die Abfrageeffizienz ist sehr gering.
Hier geben wir ein Beispiel: Wenn wir beispielsweise die Abteilungsinformationen jedes Mitarbeiters abfragen möchten,SELECT
e.empno, e.ename, e.sal, t.avg
FROM t_emp e
JOIN (SELECT deptno, AVG(sal) AS avg FROM t_emp GROUP BY deptno) t
ON e.deptno = t.deptno
AND e.sal >= t.avg;
-- 首先,按照每一个部门编号去分组,然后统计部门标号与该部门对应的平均月薪。将这个结果集作为一张临时的表与员工的表做连接。
-- 连接的条件为 "员工表" 的 "部门编号" = "结果集" 的 "部门编号",并且员工的月薪大于部门的平均月薪Obwohl das Ausführungsergebnis korrekt ist, ist die Ausführungseffizienz wirklich zu gering, daher ist dies" Das SELECT "-Unterabfragemethode wird ebenfalls nicht empfohlen. Verstehen Sie es einfach. Wenn wir sehen, dass andere Leute die Unterabfrage „SELECT“ verwenden, ist es am besten, sie freundlich daran zu erinnern.
Empfohlenes Lernen:  MySQL-Video-Tutorial
MySQL-Video-Tutorial
Das obige ist der detaillierte Inhalt vonZusammenfassung der Syntaxregeln für MySQL-Datenbankunterabfragen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL ist ein Open Source Relational Database Management System. 1) Datenbank und Tabellen erstellen: Verwenden Sie die Befehle erstellte und creatEtable. 2) Grundlegende Vorgänge: Einfügen, aktualisieren, löschen und auswählen. 3) Fortgeschrittene Operationen: Join-, Unterabfrage- und Transaktionsverarbeitung. 4) Debugging -Fähigkeiten: Syntax, Datentyp und Berechtigungen überprüfen. 5) Optimierungsvorschläge: Verwenden Sie Indizes, vermeiden Sie ausgewählt* und verwenden Sie Transaktionen.
 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
Erstellen Sie eine Datenbank mit Navicat Premium: Stellen Sie eine Verbindung zum Datenbankserver her und geben Sie die Verbindungsparameter ein. Klicken Sie mit der rechten Maustaste auf den Server und wählen Sie Datenbank erstellen. Geben Sie den Namen der neuen Datenbank und den angegebenen Zeichensatz und die angegebene Kollektion ein. Stellen Sie eine Verbindung zur neuen Datenbank her und erstellen Sie die Tabelle im Objektbrowser. Klicken Sie mit der rechten Maustaste auf die Tabelle und wählen Sie Daten einfügen, um die Daten einzufügen.
 So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
Sie können eine neue MySQL -Verbindung in Navicat erstellen, indem Sie den Schritten folgen: Öffnen Sie die Anwendung und wählen Sie eine neue Verbindung (Strg N). Wählen Sie "MySQL" als Verbindungstyp. Geben Sie die Hostname/IP -Adresse, den Port, den Benutzernamen und das Passwort ein. (Optional) Konfigurieren Sie erweiterte Optionen. Speichern Sie die Verbindung und geben Sie den Verbindungsnamen ein.
 MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL sind wesentliche Fähigkeiten für Entwickler. 1.MYSQL ist ein Open -Source -Relational Database Management -System, und SQL ist die Standardsprache, die zum Verwalten und Betrieb von Datenbanken verwendet wird. 2.MYSQL unterstützt mehrere Speichermotoren durch effiziente Datenspeicher- und Abruffunktionen, und SQL vervollständigt komplexe Datenoperationen durch einfache Aussagen. 3. Beispiele für die Nutzung sind grundlegende Abfragen und fortgeschrittene Abfragen wie Filterung und Sortierung nach Zustand. 4. Häufige Fehler umfassen Syntaxfehler und Leistungsprobleme, die durch Überprüfung von SQL -Anweisungen und Verwendung von Erklärungsbefehlen optimiert werden können. 5. Leistungsoptimierungstechniken umfassen die Verwendung von Indizes, die Vermeidung vollständiger Tabellenscanning, Optimierung von Join -Operationen und Verbesserung der Code -Lesbarkeit.
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
 So wiederherstellen Sie Daten nach dem Löschen von SQL Zeilen
Apr 09, 2025 pm 12:21 PM
So wiederherstellen Sie Daten nach dem Löschen von SQL Zeilen
Apr 09, 2025 pm 12:21 PM
Das Wiederherstellen von gelöschten Zeilen direkt aus der Datenbank ist normalerweise unmöglich, es sei denn, es gibt einen Backup- oder Transaktions -Rollback -Mechanismus. Schlüsselpunkt: Transaktionsrollback: Führen Sie einen Rollback aus, bevor die Transaktion Daten wiederherstellt. Sicherung: Regelmäßige Sicherung der Datenbank kann verwendet werden, um Daten schnell wiederherzustellen. Datenbank-Snapshot: Sie können eine schreibgeschützte Kopie der Datenbank erstellen und die Daten wiederherstellen, nachdem die Daten versehentlich gelöscht wurden. Verwenden Sie eine Löschanweisung mit Vorsicht: Überprüfen Sie die Bedingungen sorgfältig, um das Verhandlich von Daten zu vermeiden. Verwenden Sie die WHERE -Klausel: Geben Sie die zu löschenden Daten explizit an. Verwenden Sie die Testumgebung: Testen Sie, bevor Sie einen Löschvorgang ausführen.
 MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL ist ein Open Source Relational Database Management -System, das hauptsächlich zum schnellen und zuverlässigen Speicher und Abrufen von Daten verwendet wird. Sein Arbeitsprinzip umfasst Kundenanfragen, Abfragebedingungen, Ausführung von Abfragen und Rückgabergebnissen. Beispiele für die Nutzung sind das Erstellen von Tabellen, das Einsetzen und Abfragen von Daten sowie erweiterte Funktionen wie Join -Operationen. Häufige Fehler umfassen SQL -Syntax, Datentypen und Berechtigungen sowie Optimierungsvorschläge umfassen die Verwendung von Indizes, optimierte Abfragen und die Partitionierung von Tabellen.
