
 Datenbank
Redis
Lassen Sie uns kurz über zwei Lösungen für Redis sprechen, um mit Schnittstellen-Idempotenz umzugehen.
Datenbank
Redis
Lassen Sie uns kurz über zwei Lösungen für Redis sprechen, um mit Schnittstellen-Idempotenz umzugehen.
Lassen Sie uns kurz über zwei Lösungen für Redis sprechen, um mit Schnittstellen-Idempotenz umzugehen.


Empfohlenes Lernen: Redis-Video-Tutorial
Vorwort: Das Problem der Schnittstellen-Idempotenz ist ein öffentliches Problem, das für Entwickler nichts mit Sprache zu tun hat. Bei einigen Benutzeranfragen kann es sein, dass sie wiederholt gesendet werden. Wenn es sich um einen Abfragevorgang handelt, handelt es sich bei einigen um Schreibvorgänge, die jedoch schwerwiegende Folgen haben können Bei wiederholter Nachfrage nach der Schnittstelle kann es zu wiederholten Bestellungen kommen. Schnittstellen-Idempotenz bedeutet, dass die Ergebnisse einer oder mehrerer vom Benutzer initiierter Anforderungen für denselben Vorgang konsistent sind und es keine Nebenwirkungen durch mehrere Klicks gibt. 接口幂等性问题,对于开发人员来说,是一个跟语言无关的公共问题。对于一些用户请求,在某些情况下是可能重复发送的,如果是查询类操作并无大碍,但其中有些是涉及写入操作的,一旦重复了,可能会导致很严重的后果,例如交易的接口如果重复请求可能会重复下单。接口幂等性是指用户对于同一操作发起的一次请求或者多次请求的结果是一致的,不会因为多次点击而产生了副作用。
一、接口幂等性
1.1、什么是接口幂等性
在HTTP/1.1中,对幂等性进行了定义。它描述了一次和多次请求某一个资源对于资源本身应该具有同样的结果,即第一次请求的时候对资源产生了副作用,但是以后的多次请求都不会再对资源产生副作用。这里的副作用是不会对结果产生破坏或者产生不可预料的结果。也就是说,其任意多次执行对资源本身所产生的影响均与一次执行的影响相同。
这类问题多发于接口的:
-
insert操作,这种情况下多次请求,可能会产生重复数据。 -
update操作,如果只是单纯的更新数据,比如:update user set status=1 where id=1,是没有问题的。如果还有计算,比如:update user set status=status+1 where id=1,这种情况下多次请求,可能会导致数据错误。
1.2、为什么需要实现幂等性
在接口调用时一般情况下都能正常返回信息不会重复提交,不过在遇见以下情况时可以就会出现问题,如:
- 前端重复提交表单: 在填写一些表格时候,用户填写完成提交,很多时候会因网络波动没有及时对用户做出提交成功响应,致使用户认为没有成功提交,然后一直点提交按钮,这时就会发生重复提交表单请求。
- 用户恶意进行刷单: 例如在实现用户投票这种功能时,如果用户针对一个用户进行重复提交投票,这样会导致接口接收到用户重复提交的投票信息,这样会使投票结果与事实严重不符。
- 接口超时重复提交: 很多时候 HTTP 客户端工具都默认开启超时重试的机制,尤其是第三方调用接口时候,为了防止网络波动超时等造成的请求失败,都会添加重试机制,导致一个请求提交多次。
- 消息进行重复消费: 当使用 MQ 消息中间件时候,如果发生消息中间件出现错误未及时提交消费信息,导致发生重复消费。
本文讨论的是如何在服务端优雅地统一处理这种接口幂等性情况,如何禁止用户重复点击等客户端操作不在此次讨论范围。
1.3、引入幂等性后对系统的影响
幂等性是为了简化客户端逻辑处理,能放置重复提交等操作,但却增加了服务端的逻辑复杂性和成本,其主要是:
- 把并行执行的功能改为串行执行,降低了执行效率。
- 增加了额外控制幂等的业务逻辑,复杂化了业务功能;
所以在使用时候需要考虑是否引入幂等性的必要性,根据实际业务场景具体分析,除了业务上的特殊要求外,一般情况下不需要引入的接口幂等性。
二、如何设计幂等
幂等意味着一条请求的唯一性。不管是你哪个方案去设计幂等,都需要一个全局唯一的ID ,去标记这个请求是独一无二的。
- 如果你是利用唯一索引控制幂等,那唯一索引是唯一的
- 如果你是利用数据库主键控制幂等,那主键是唯一的
- 如果你是悲观锁的方式,底层标记还是全局唯一的ID
2.1、全局的唯一性ID
全局唯一性ID,我们怎么去生成呢?你可以回想下,数据库主键Id怎么生成的呢?
是的,我们可以使用UUID
1. Schnittstellen-Idempotenz
1.1. Was ist Schnittstellen-Idempotenz
In HTTP/1.1 ist Idempotenz definiert. Es beschreibt, dass eine und mehrere Anfragen für eine Ressource das gleiche Ergebnis für die Ressource selbst haben sollten, d. h. die erste Anfrage hat Nebenwirkungen auf die Ressource, nachfolgende Anfragen haben jedoch keine Nebenwirkungen mehr auf die Ressource. Die hier auftretenden Nebenwirkungen beeinträchtigen die Ergebnisse nicht und führen nicht zu unvorhersehbaren Ergebnissen. Mit anderen Worten: Mehrere Ausführungen haben die gleichen Auswirkungen auf die Ressource selbst wie eine einzelne Ausführung. 🎜🎜Diese Art von Problem tritt häufig in der Schnittstelle auf: 🎜-
insert-Vorgang In diesem Fall können mehrere Anfragen zu doppelten Daten führen. -
update-Vorgang: Wenn Sie nur Daten aktualisieren, zum Beispiel:update user set status=1 where id=1, gibt es kein Problem. Bei Berechnungen wie:update user set status=status+1 where id=1können mehrere Anfragen in diesem Fall zu Datenfehlern führen.
1.2. Warum ist es notwendig, Idempotenz zu implementieren?
🎜Im Allgemeinen können und werden die Informationen normal zurückgegeben, wenn die Schnittstelle aufgerufen wird nicht wiederholt eingereicht werden. In folgenden Situationen kann es jedoch zu Problemen kommen: 🎜- Wiederholte Übermittlung von Formularen am Frontend: Beim Ausfüllen einiger Formulare schließt der Benutzer die Übermittlung ab und schlägt häufig fehl um dem Benutzer aufgrund von Netzwerkschwankungen rechtzeitig zu antworten, was dazu führt, dass der Benutzer denkt, dass die Übermittlung nicht erfolgreich war, und dann weiterhin auf die Schaltfläche „Senden“ klickt.
- Benutzer swipen Bestellungen in böswilliger Absicht: Wenn der Benutzer beispielsweise bei der Implementierung der Benutzerabstimmungsfunktion wiederholt Stimmen für einen Benutzer abgibt, führt dies dazu, dass die Schnittstelle die vom Benutzer wiederholt übermittelten Abstimmungsinformationen empfängt wird dazu führen, dass die Abstimmung blockiert wird. Die Ergebnisse stehen im Widerspruch zu den Tatsachen.
- Schnittstellen-Timeout und wiederholte Übermittlung: Viele HTTP-Client-Tools aktivieren standardmäßig den Timeout-Wiederholungsmechanismus, insbesondere wenn ein Dritter die Schnittstelle aufruft, um Anforderungsfehler aufgrund von Netzwerkschwankungen, Timeouts usw. zu verhindern. Es wird ein Wiederholungsmechanismus hinzugefügt, der dazu führt, dass eine Anfrage mehrmals gesendet wird.
- Wiederholter Nachrichtenverbrauch: Wenn bei Verwendung der MQ-Nachrichten-Middleware ein Fehler in der Nachrichten-Middleware auftritt und die Verbrauchsinformationen nicht rechtzeitig übermittelt werden, kommt es zu einem wiederholten Verbrauch.
1.3. Auswirkungen auf das System nach der Einführung von Idempotenz
🎜Idempotenz vereinfacht die Verarbeitung der Client-Logik und kann Vorgänge wie wiederholte Übermittlungen platzieren, erhöht aber auch die Logikkomplexität und Die Kosten des Terminals sind hauptsächlich: 🎜- Der Wechsel der parallelen Ausführungsfunktion zur seriellen Ausführung verringert die Ausführungseffizienz.
- Zusätzliche Geschäftslogik zur Steuerung der Idempotenz hinzugefügt, was die Geschäftsfunktionen verkompliziert
2. Wie man Idempotenz gestaltet
🎜Impotenz bedeutet die Einzigartigkeit einer Anfrage. Unabhängig davon, welchen Plan Sie zum Entwerfen von Idempotenz verwenden, benötigen Sie eine global eindeutige ID, um diese Anfrage als eindeutig zu kennzeichnen. 🎜- Wenn Sie einen eindeutigen Index verwenden, um die Idempotenz zu steuern, dann ist der eindeutige Index eindeutig
- Wenn Sie einen Datenbank-Primärschlüssel verwenden, um die Idempotenz zu steuern, dann ist der Primärschlüssel eindeutig Wenn Sie pessimistisches Sperren verwenden, ist das zugrunde liegende Tag immer noch eine global eindeutige ID
2.1 Globale Eindeutigkeits-ID
🎜Globale Eindeutigkeits-ID , wie erzeugen wir es? Sie können darüber nachdenken: Wie wird die Datenbank-Primärschlüssel-ID generiert? 🎜🎜Ja, wir könnenUUID verwenden, aber die Nachteile von UUID liegen auf der Hand. Die Zeichenfolge nimmt viel Platz ein, die generierte ID ist zu zufällig, schlecht lesbar und erhöht sich nicht. 🎜Wir können auch den Snowflake-Algorithmus (Snowflake) verwenden, um eindeutige IDs zu generieren. 雪花算法(Snowflake) 生成唯一性ID。
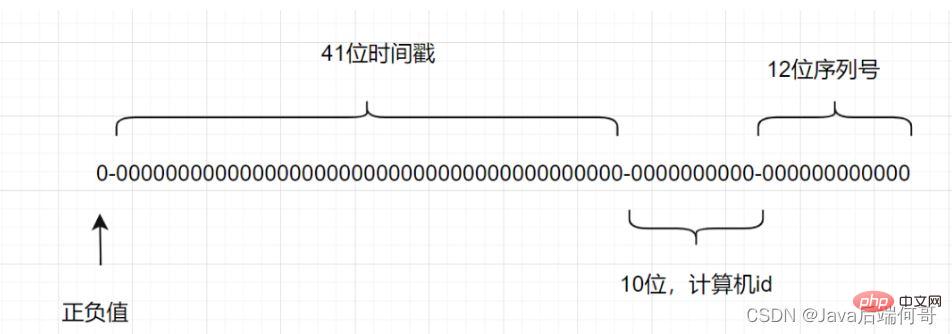
雪花算法是一种生成分布式全局唯一ID的算法,生成的ID称为Snowflake IDs。这种算法由Twitter创建,并用于推文的ID。
一个Snowflake ID有64位。
- 第1位:Java中long的最高位是符号位代表正负,正数是0,负数是1,一般生成ID都为正数,所以默认为0。
- 接下来前41位是时间戳,表示了自选定的时期以来的毫秒数。
- 接下来的10位代表计算机ID,防止冲突。
- 其余12位代表每台机器上生成ID的序列号,这允许在同一毫秒内创建多个Snowflake ID。
当然,全局唯一性的ID,还可以使用百度的Uidgenerator,或者美团的Leaf。
2.2、幂等设计的基本流程
幂等处理的过程,说到底其实就是过滤一下已经收到的请求,当然,请求一定要有一个全局唯一的ID标记
Snowflake-IDs genannt. Dieser Algorithmus wurde von Twitter erstellt und wird für Tweet-IDs verwendet. Eine Snowflake-ID hat 64 Bit. 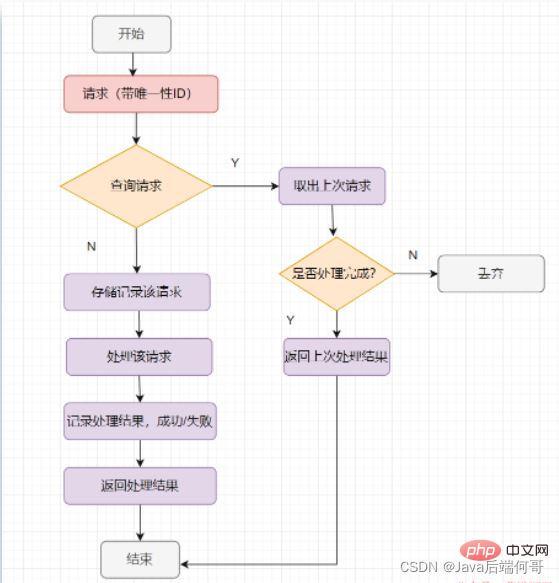
Die nächsten 10 Ziffern stellen die Computer-ID dar, um Konflikte zu vermeiden.
Die verbleibenden 12 Bit stellen die Seriennummer auf jedem Computer dar, auf dem die ID generiert wurde, wodurch mehrere Snowflake-IDs in derselben Millisekunde erstellt werden können.
Natürlich ist die weltweit eindeutige ID, Sie können auch den Uidgenerator von Baidu oder den Leaf von Meituan verwenden.
- Der Prozess der idempotenten Verarbeitung besteht letztendlich darin, die empfangenen Anfragen zu filtern. Natürlich müssen die Anfragen einen
globalen eindeutigen ID-Taghaben >Ha. Wie kann dann festgestellt werden, ob die Anfrage schon einmal eingegangen ist? Speichern Sie die Anfrage. Überprüfen Sie zunächst den Speicherdatensatz. Wenn der Datensatz vorhanden ist, wird das letzte Ergebnis zurückgegeben. - Die allgemeine idempotente Verarbeitung sieht wie folgt aus:
- 3. Gängige Lösungen für Schnittstellen-Idempotenz
- 3.1. Übergeben Sie eindeutige Anforderungsnummern nachgelagert
- Die sogenannte eindeutige Anforderungssequenznummer bedeutet tatsächlich, dass jede Anforderung an den Server in einem kurzen Zeitraum von einer eindeutigen und sich nicht wiederholenden Sequenznummer begleitet wird. Die Seriennummer kann eine fortlaufende ID oder sein Eine Bestellnummer, die im Allgemeinen vom Downstream-Server generiert wird. Beim Aufruf der Upstream-Serverschnittstelle werden die Seriennummer und die zur Authentifizierung verwendete ID angehängt.
- Wenn der Upstream-Server die Anforderungsinformationen empfängt, kombiniert er die Seriennummer und die Downstream-Authentifizierungs-ID, um einen Schlüssel für den Betrieb von Redis zu bilden, und fragt dann Redis ab, um zu sehen, ob es ein Schlüssel-Wert-Paar für den entsprechenden Schlüssel gibt Das Ergebnis:
Wenn es vorhanden ist, bedeutet dies, dass die nachgelagerte Anfrage nach der Seriennummer verarbeitet wurde. Zu diesem Zeitpunkt können Sie direkt auf die Fehlermeldung der wiederholten Anfrage reagieren.
Wenn er nicht vorhanden ist, verwenden Sie den Schlüssel als Redis-Schlüssel, verwenden Sie die Downstream-Schlüsselinformationen als gespeicherten Wert (z. B. einige vom Downstream-Anbieter übergebene Geschäftslogikinformationen), speichern Sie das Schlüssel-Wert-Paar in Redis und Führen Sie dann die entsprechende Geschäftslogik normal aus. 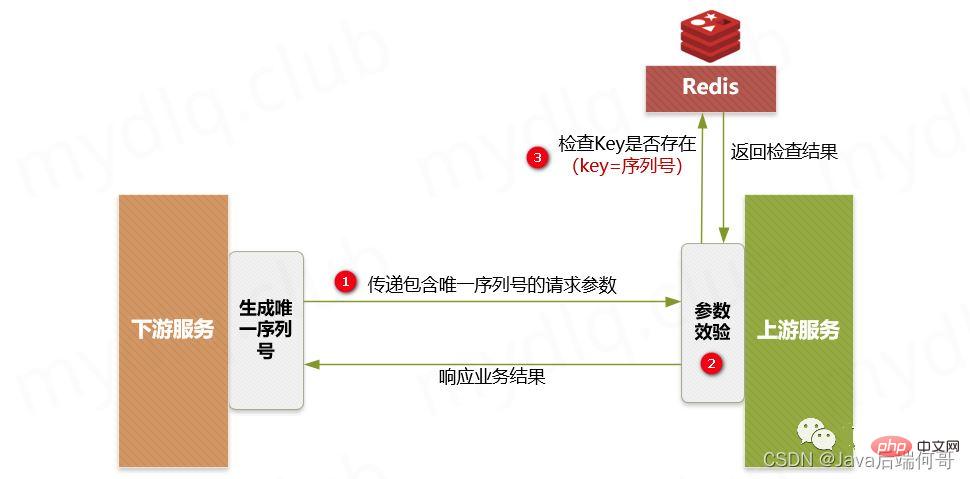
Antierbarer Betrieb:
- Ut-Betrieb
- Update Operation
- Delete Operation
Usage Beschränkungen:
🎜🎜🎜 🎜🎜🎜 🎜🎜🎜 🎜🎜🎜 🎜🎜🎜 einen dritten Partner übergeben, um eine eindeutige Seriennummer zu übergeben; Redis zur Datenvalidierung; 🎜🎜 🎜Hauptprozess: 🎜🎜🎜🎜🎜 Hauptschritte: 🎜🎜🎜 Der Downstream-Dienst generiert eine verteilte ID als Seriennummer und führt dann die Anforderung zum Aufrufen der Upstream-Schnittstelle zusammen mit dem „einzigartigen“ aus Seriennummer“ und die angeforderte „Authentifizierungs-ID“. 🎜🎜 Der Upstream-Dienst führt eine Sicherheitsüberprüfung durch und erkennt, ob die „Seriennummer“ und die „Anmeldeinformations-ID“ in den Downstream-Parametern vorhanden sind. 🎜🎜 Der Upstream-Dienst erkennt, ob in Redis ein Schlüssel vorhanden ist, der aus der entsprechenden „Seriennummer“ und „Authentifizierungs-ID“ besteht. Wenn dieser vorhanden ist, löst er eine Ausnahmemeldung zur wiederholten Ausführung aus und antwortet dann auf die entsprechende Fehlermeldung flussabwärts. Wenn dies nicht der Fall ist, wird die Kombination aus „Seriennummer“ und „Authentifizierungs-ID“ als Schlüssel verwendet, und die Downstream-Schlüsselinformationen werden als Wert verwendet und dann in Redis und dann in der nachfolgenden Geschäftslogik gespeichert normal ausgeführt werden. 🎜🎜🎜In den obigen Schritten müssen Sie beim Einfügen von Daten in Redis die Ablaufzeit festlegen. Dadurch wird sichergestellt, dass innerhalb dieses Zeitraums bei wiederholtem Aufruf der Schnittstelle eine Beurteilung und Identifizierung erfolgen kann. Wenn die Ablaufzeit nicht festgelegt ist, wird wahrscheinlich eine unbegrenzte Datenmenge in Redis gespeichert, was dazu führt, dass Redis nicht ordnungsgemäß funktioniert. 🎜🎜🎜3.2. Anti-Duplikat-Token-Token🎜🎜🎜Projektbeschreibung: 🎜🎜Angesichts der kontinuierlichen Klicks des Kunden oder der Timeout-Wiederholungsversuche des Anrufers, z. B. beim Senden einer Bestellung, kann dieser Vorgang den Token-Mechanismus verwenden, um wiederholte Übermittlungen zu verhindern. Vereinfacht ausgedrückt fordert der Aufrufer beim Aufruf der Schnittstelle zunächst eine globale ID (Token) vom Backend an und trägt diese globale ID mit der Anfrage (am besten fügt man das Token in Header ein). Das Backend muss dieses Token verwenden Als Schlüssel werden die Benutzerinformationen als Wert zur Überprüfung des Schlüsselwertinhalts an Redis gesendet. Wenn der Schlüssel vorhanden ist und der Wert übereinstimmt, wird der Löschbefehl ausgeführt, und dann wird die nachfolgende Geschäftslogik normal ausgeführt. Wenn kein entsprechender Schlüssel vorhanden ist oder der Wert nicht übereinstimmt, wird eine wiederholte Fehlermeldung zurückgegeben, um idempotente Operationen sicherzustellen. 🎜
Nutzungsbeschränkungen:
- Muss eine global eindeutige Token-Zeichenfolge generiert werden;
- Muss die Drittanbieterkomponente Redis zur Datenvalidierung verwenden;
Hauptprozess:
Der Server stellt eine Schnittstelle zum Erhalten von Token bereit. Dies kann eine Sequenznummer sein, die auch eine verteilte ID oder UUID-Zeichenfolge sein kann.
Der Client ruft die Schnittstelle auf, um das Token zu erhalten. Zu diesem Zeitpunkt generiert der Server eine Token-Zeichenfolge.
Speichern Sie dann die Zeichenfolge in der Redis-Datenbank und verwenden Sie dabei das Token als Redis-Schlüssel (beachten Sie die Ablaufzeit).
Geben Sie das Token an den Kunden zurück. Nachdem der Kunde es erhalten hat, sollte es im versteckten Feld des Formulars gespeichert werden.
Wenn der Client das Formular ausführt und absendet, speichert er das Token in den Headern und überträgt die Header bei der Ausführung der Geschäftsanfrage.
Nach Erhalt der Anfrage ruft der Server das Token aus den Headern ab und prüft dann anhand des Tokens, ob der Schlüssel in Redis vorhanden ist.
Der Server bestimmt, ob der Schlüssel in Redis vorhanden ist. Wenn er vorhanden ist, löschen Sie den Schlüssel und führen Sie dann die Geschäftslogik normal aus. Wenn es nicht vorhanden ist, wird eine Ausnahme ausgelöst und bei wiederholten Übermittlungen wird eine Fehlermeldung zurückgegeben.
Beachten Sie, dass unter gleichzeitigen Bedingungen beim Ausführen der Redis-Datensuche und -löschung die Atomizität sichergestellt werden muss, andernfalls kann die Idempotenz unter Parallelität möglicherweise nicht garantiert werden. Seine Implementierung kann verteilte Sperren oder Lua-Ausdrücke verwenden, um Abfrage- und Löschvorgänge abzumelden.
Empfohlenes Lernen: Redis-Video-Tutorial
Das obige ist der detaillierte Inhalt vonLassen Sie uns kurz über zwei Lösungen für Redis sprechen, um mit Schnittstellen-Idempotenz umzugehen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1386
1386
 52
52

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
Um die Operationen zu sperren, muss die Sperre durch den Befehl setNX erfasst werden und dann den Befehl Ablauf verwenden, um die Ablaufzeit festzulegen. Die spezifischen Schritte sind: (1) Verwenden Sie den Befehl setNX, um zu versuchen, ein Schlüsselwertpaar festzulegen; (2) Verwenden Sie den Befehl Ablauf, um die Ablaufzeit für die Sperre festzulegen. (3) Verwenden Sie den Befehl Del, um die Sperre zu löschen, wenn die Sperre nicht mehr benötigt wird.
 So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
Redis verwendet Hash -Tabellen, um Daten zu speichern und unterstützt Datenstrukturen wie Zeichenfolgen, Listen, Hash -Tabellen, Sammlungen und geordnete Sammlungen. Ernähren sich weiterhin über Daten über Snapshots (RDB) und appendiert Mechanismen nur Schreibmechanismen. Redis verwendet die Master-Slave-Replikation, um die Datenverfügbarkeit zu verbessern. Redis verwendet eine Ereignisschleife mit einer Thread, um Verbindungen und Befehle zu verarbeiten, um die Datenatomizität und Konsistenz zu gewährleisten. Redis legt die Ablaufzeit für den Schlüssel fest und verwendet den faulen Löschmechanismus, um den Ablaufschlüssel zu löschen.
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So erstellen Sie Message Middleware für Redis
Apr 10, 2025 pm 07:51 PM
So erstellen Sie Message Middleware für Redis
Apr 10, 2025 pm 07:51 PM
Redis unterstützt als Messing Middleware Modelle für Produktionsverbrauch, kann Nachrichten bestehen und eine zuverlässige Lieferung sicherstellen. Die Verwendung von Redis als Message Middleware ermöglicht eine geringe Latenz, zuverlässige und skalierbare Nachrichten.
