

So zeigen Sie den Ausführungsplan in MySQL an


Empfohlenes Lernen: MySQL-Video-Tutorial
Verwenden Sie das Schlüsselwort EXPLAIN, um die Ausführung von SQL-Abfrageanweisungen durch den Optimierer zu simulieren, um zu erfahren, wie MySQL Ihre SQL-Anweisungen verarbeitet, und um Leistungsengpässe bei Ihren Abfrageanweisungen oder Tabellenstrukturen zu analysieren.
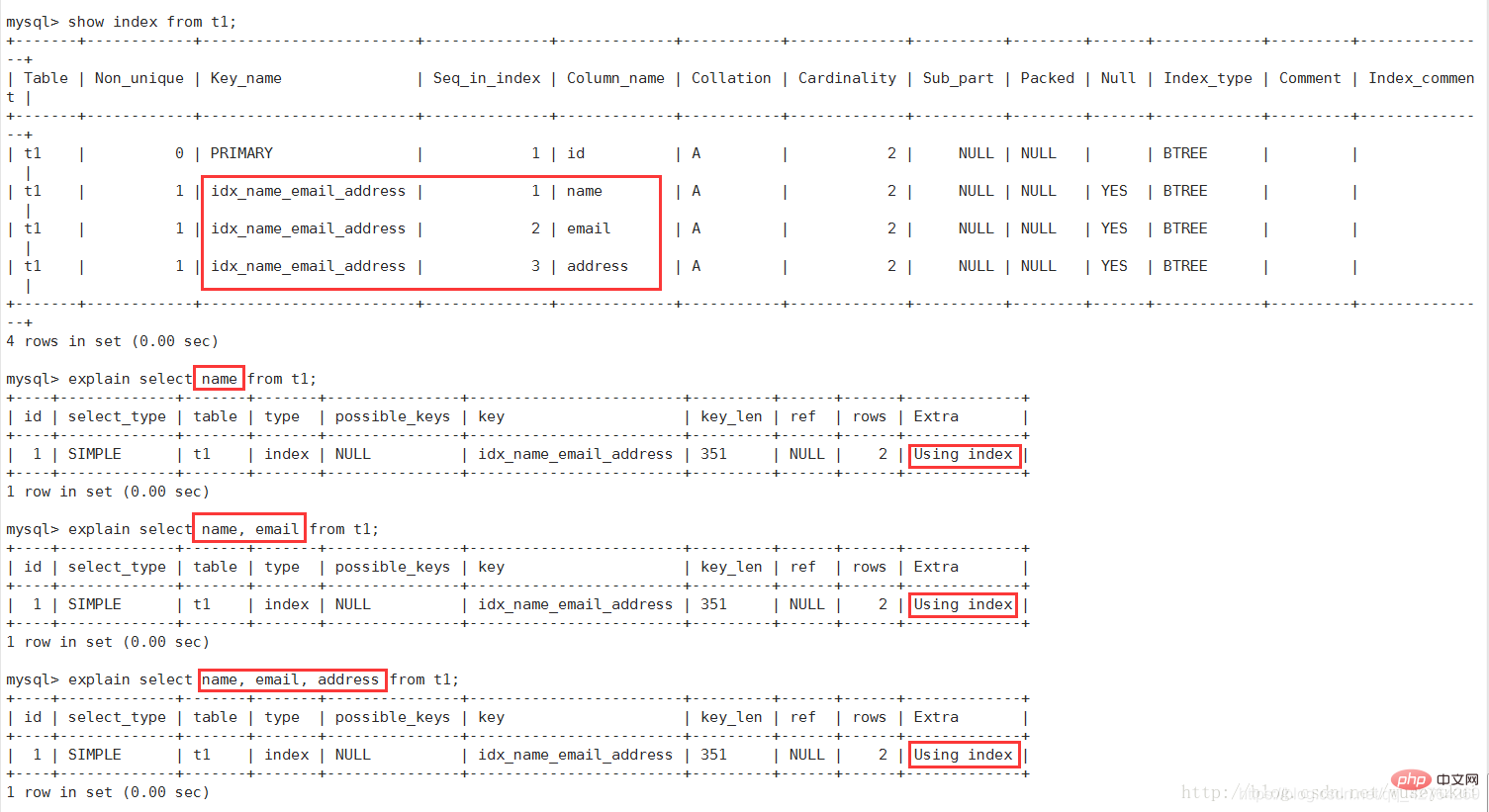
Erklären Sie die im Ausführungsplan enthaltenen Informationen
Die wichtigsten Felder sind: ID, Typ, Schlüssel, Zeilen, Extra
Detaillierte Erläuterung jedes Feldes
id
Wählen Sie die Sequenznummer der Abfrage aus, einschließlich einer Reihe von Zahlen. Gibt die Reihenfolge an, in der ausgewählte Klauseln oder Operationstabellen in der Abfrage ausgeführt werden 2. Unterschiedliche IDs: Wenn es sich um eine Unterabfrage handelt, erhöht sich die Seriennummer der ID, desto höher ist die Priorität und desto früher wird die ID ausgeführt gleich, aber unterschiedlich (beide Situationen existieren gleichzeitig)
: Wenn die ID gleich ist, kann sie als Gruppe betrachtet werden. Je größer der ID-Wert, desto höher Priorität, desto früher wird sie ausgeführtselect_type
Der Typ der Abfrage, der hauptsächlich zur Unterscheidung von gewöhnlichen Abfragen, gemeinsamen Abfragen und Unterabfragen sowie anderen komplexen Abfragen verwendet wird 
1. SIMPLE: Einfache Auswahlabfrage, die Die Abfrage enthält keine Unterabfragen oder Unions
 2. PRIMARY
2. PRIMARY
3, SUBQUERY
: Eine Unterabfrage ist in der Select- oder Where-Liste enthalten
: Die in der Von-Liste enthaltene Unterabfrage wird als abgeleitet (abgeleitet) markiert, und MySQL führt diese Unterabfragen rekursiv aus und fügt die Ergebnisse in die Nullzeittabelle ein
5: Wenn die zweite Abfrage erscheint nach der Union, wird sie als Union markiert; wenn die Union in der Unterabfrage der from-Klausel enthalten ist, wird die äußere Auswahl als abgeleitet markiert- 6, UNION-ERGEBNIS: Select
- type Zugriffstyp zum Erhalten von Ergebnissen aus der Union-Tabelle, einem sehr wichtigen Indikator bei der Optimierung von SQL-Abfragen. Die Ergebniswerte sind vom besten zum schlechtesten:
- Im Allgemeinen sollte eine gute SQL-Abfrage mindestens den Bereich erreichen Ebene und erreichen Sie vorzugsweise das Ref
- 1. Die Tabelle hat nur eine Zeile mit Datensätzen (entspricht der Systemtabelle). Dies ist normalerweise ein Sonderfall ignoriert
- 2. Dies bedeutet, dass es über den Index gefunden wird, sobald const zum Vergleichen des Primärschlüssels oder des eindeutigen Index verwendet wird. Da Sie nur eine Datenzeile abgleichen müssen, geht es sehr schnell. Wenn der Primärschlüssel in der Where-Liste platziert ist, kann MySQL die Abfrage in eine Konstante konvertieren. eq_ref: Eindeutiger Index-Scan. Für jeden Indexschlüssel stimmt nur ein Datensatz mit ihm überein. Kommt häufig bei Primärschlüssel- oder eindeutigen Index-Scans vor.
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
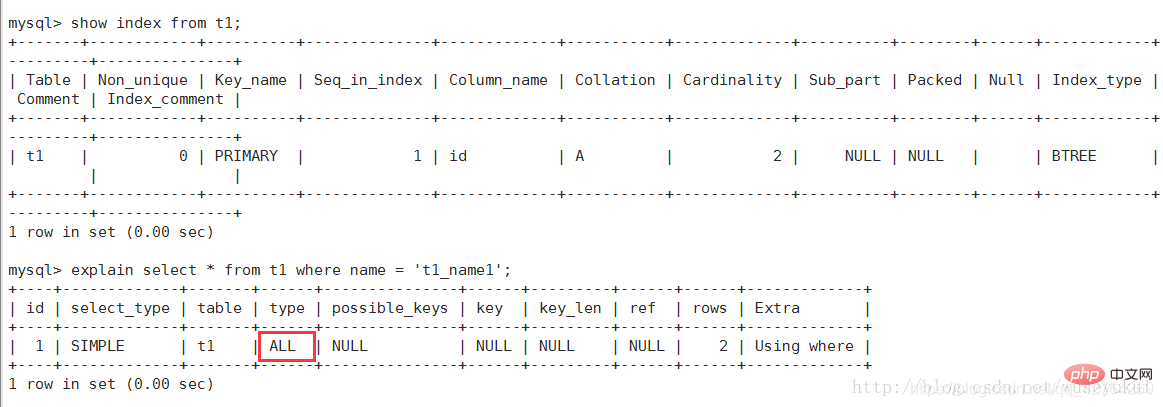
 Hinweis: ALLER vollständiger Tabellenscan der Tabelle mit den wenigsten Datensätzen wie t1-Tabelle
Hinweis: ALLER vollständiger Tabellenscan der Tabelle mit den wenigsten Datensätzen wie t1-Tabelle
: nicht eindeutiger Indexscan, gibt alle Zeilen zurück, die einem einzelnen Wert entsprechen. Im Wesentlichen handelt es sich auch um einen Indexzugriff, der alle Zeilen zurückgibt, die einem einzelnen Wert entsprechen. Es können jedoch mehrere Zeilen gefunden werden, die den Kriterien entsprechen, daher sollte es sich um eine Mischung aus Suche und Scan handeln
5. Bereich: Rufen Sie nur Zeilen in einem bestimmten Bereich ab und verwenden Sie einen Index, um Zeilen auszuwählen. Die Schlüsselspalte zeigt, welcher Index verwendet wird. Im Allgemeinen erscheinen Abfragen wie between, , in usw. in der where-Anweisung. Dieser Bereichsscan für Indexspalten ist besser als ein vollständiger Indexscan. Es muss nur an einem bestimmten Punkt beginnen und an einem anderen Punkt enden, ohne den gesamten Index zu scannen

6: Der Unterschied zwischen Index und ALL besteht darin, dass der Indextyp nur den Index durchläuft Baum. Dies sind normalerweise ALLE Blöcke, da Indexdateien normalerweise kleiner sind als Datendateien. (Obwohl Index und ALL beide die gesamte Tabelle lesen, wird der Index vom Index gelesen, während ALL von der Festplatte gelesen wird.)

7: Vollständiger Tabellenscan, Durchsuchen der gesamten Tabelle, um die Übereinstimmung zu finden Wenn in der Zeile
 possible_keys
possible_keys
ein Index für das an der Abfrage beteiligte Feld vorhanden ist, wird der Index aufgelistet, aber möglicherweise nicht tatsächlich von der Abfrage verwendet.
key
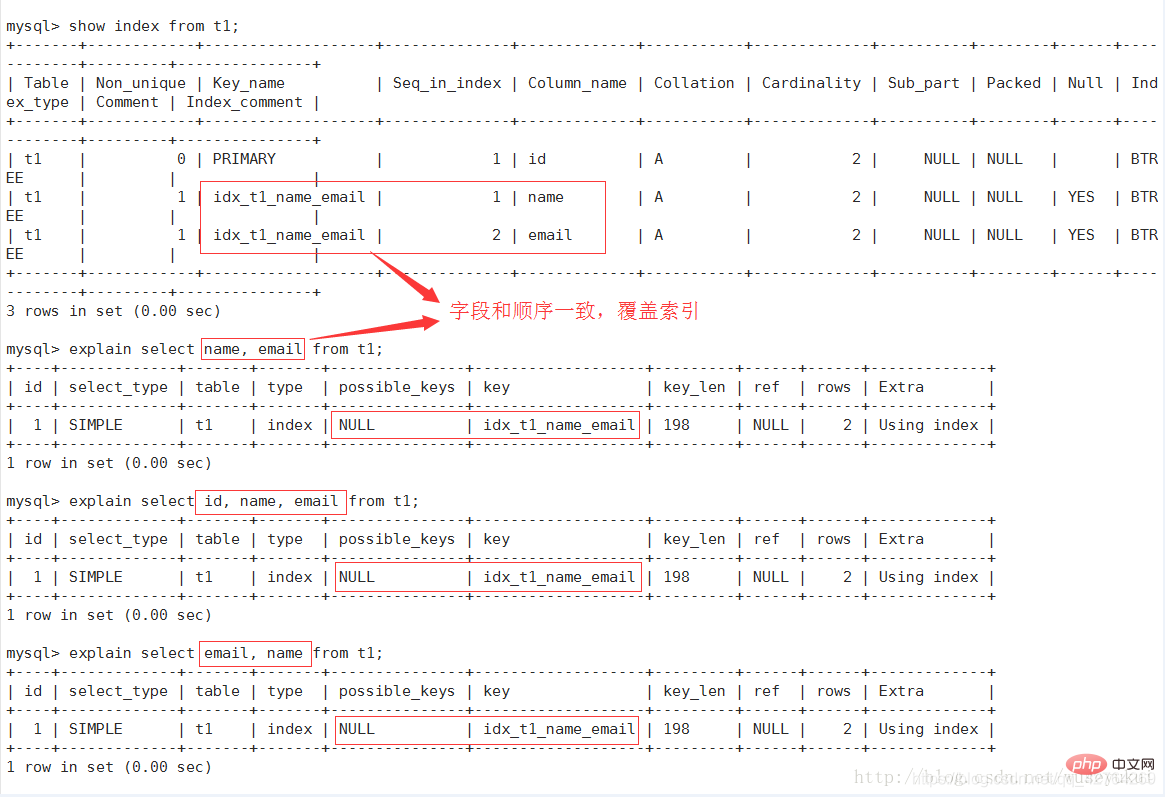
Der tatsächlich verwendete Index. Wenn es NULL ist, wird der Index nicht verwendet.
Wenn in der Abfrage ein abdeckender Index verwendet wird, erscheint der Index nur in der Schlüsselliste.
 key_len
key_len
stellt die Anzahl der im Index verwendeten Bytes und die Länge des Index dar wird in der Abfrage verwendet (maximal mögliche Länge), nicht die tatsächlich verwendete Länge. Theoretisch gilt: Je kürzer die Länge, desto besser. key_len wird basierend auf der Tabellendefinition berechnet. Es wird keine
ref
display-Indexspalte verwendet.
Zeilen
Schätzen Sie anhand der Tabellenstatistik und der Indexauswahl grob die Anzahl der Zeilen, die gelesen werden müssen, um die erforderlichen Datensätze zu finden.
Extra
eignet sich nicht für die Anzeige in anderen Feldern, ist aber eine sehr wichtige Zusatzinformation
1. Verwenden von Filesort:
MySQL verwendet einen externen Index, um die Daten zu sortieren, anstatt sie nach dem Index in der Tabelle zu sortieren und zu lesen. Mit anderen Worten, MySQL kann den Index nicht verwenden, um den Sortiervorgang als „Dateisortierung“ abzuschließen
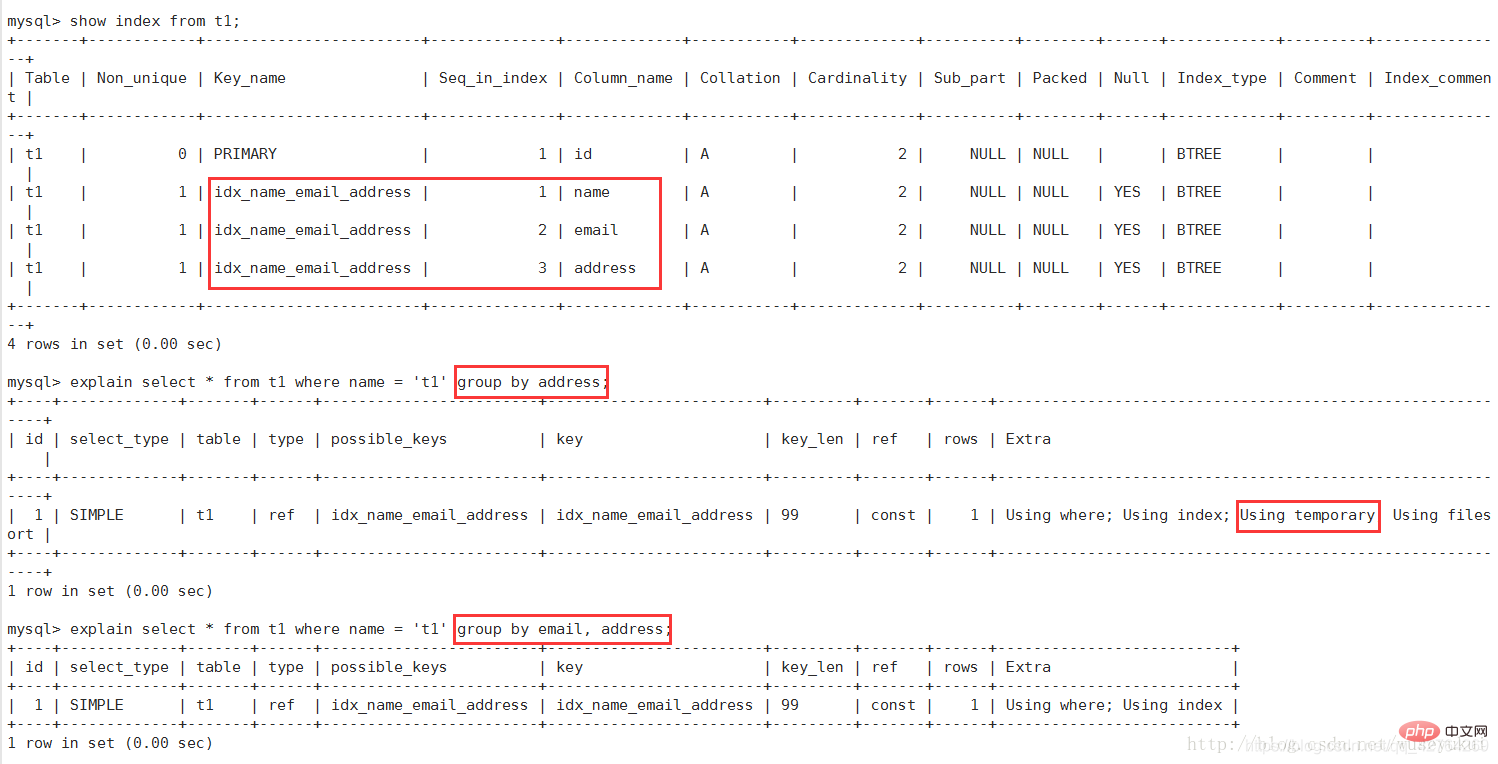
 Da der Index zuerst nach E-Mail und dann nach Adresse sortiert wird, kann der Index nicht erfüllt werden, wenn Sie während der Abfrage direkt nach Adresse sortieren die Anforderungen. MySQL muss die „Dateisortierung“ erneut implementieren
Da der Index zuerst nach E-Mail und dann nach Adresse sortiert wird, kann der Index nicht erfüllt werden, wenn Sie während der Abfrage direkt nach Adresse sortieren die Anforderungen. MySQL muss die „Dateisortierung“ erneut implementieren
Verwenden Sie temporäre Tabellen, um Zwischenergebnisse zu speichern, was bedeutet, dass MySQL temporäre Tabellen verwendet, wenn die Abfrageergebnisse sortiert werden, was in der Reihenfolge nach und üblich ist Gruppieren nach
bedeutet, dass die entsprechende Auswahloperation einen
abdeckenden Index(Covering Index) verwendet, der den Zugriff auf die Datenzeilen der Tabelle vermeidet und sehr effizient ist Bei Verwendung Wo gleichzeitig angezeigt wird, bedeutet dies, dass der Index zur Suche nach Indexschlüsselwerten verwendet wird (siehe Abbildung oben).
Wenn gleichzeitig Wo verwenden angezeigt wird, bedeutet dies, dass der Index zum Lesen von Daten verwendet wird Anstatt Suchvorgänge durchzuführen
(Covering Index): Auch Indexabdeckung genannt. Es handelt sich um die Felder in der Auswahlliste, die nur aus dem Index abgerufen werden können. Es ist nicht erforderlich, die Datendatei erneut gemäß dem Index zu lesen. Mit anderen Worten, die Abfragespalte muss durch den erstellten Index abgedeckt werden. Hinweis:
a. Wenn Sie einen abdeckenden Index verwenden müssen, entfernen Sie nur die erforderlichen Spalten aus den Feldern in der Auswahlliste. Verwenden Sie nicht select *b wird zu groß sein, was die grobe Leistung verringert.- Wo-Filterung verwendet:
Wert der Where-Klausel Es ist immer falsch und kann nicht verwendet werden, um Vorfahren zu erhalten
7 Wegoptimierte Tabellen auswählen:
In Ermangelung einer Group-By-Klausel optimieren Sie MIN/. MAX-Operationen basierend auf dem Index oder optimieren COUNT für die MyISAM-Speicher-Engine (*)-Operation, Sie müssen nicht auf die Ausführungsphase warten, um Berechnungen durchzuführen, die Optimierung kann während der Phase der Abfrageausführungsplangenerierung abgeschlossen werden8 . eindeutig:
Optimieren Sie den eindeutigen Vorgang und hören Sie auf, nach demselben zu suchen, nachdem Sie den ersten passenden Vorfahren gefunden haben. Die Aktion lohnt sichUmfassender Fall

Ausführungssequenz
1 (id = 4), [select id, name from t2]: select_type ist eine Union, was angibt, dass die Auswahl mit der ID = 4 die zweite Auswahl in der Union ist.
2 (id = 3), [select id, name from t1 where address = '11']: Da es sich um eine in der from-Anweisung enthaltene Unterabfrage handelt, wird sie als DERIVED (abgeleitet) markiert, wobei Adresse = '11' bestanden Der zusammengesetzte Index idx_name_email_address kann abgerufen werden, daher ist der Typ index.
3 (id = 2), [select id from t3]: Da es sich um eine in select enthaltene Unterabfrage handelt, wird sie als SUBQUERY markiert.
4 (id = 1), [select d1.name, … d2 from … d1]: select_type ist PRIMARY, was darauf hinweist, dass die Abfrage die äußerste Abfrage ist, und die Tabellenspalte ist als „derived3“ markiert, was darauf hinweist, dass die Abfrage Die Ergebnisse stammen aus einer abgeleiteten Tabelle (wählen Sie das Ergebnis für ID = 3 aus).
5 (id = NULL), [ ... Union ... ]: Stellt die Phase des Lesens von Zeilen aus der temporären Tabelle der Union dar. „Union 1, 4“ in der Tabellenspalte bedeutet die Verwendung der ausgewählten Ergebnisse von id=1 und id=4. Union-Operation.
Empfohlenes Lernen: MySQL-Video-Tutorial
Das obige ist der detaillierte Inhalt vonSo zeigen Sie den Ausführungsplan in MySQL an. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 MySQL: Die einfache Datenverwaltung für Anfänger
Apr 09, 2025 am 12:07 AM
MySQL: Die einfache Datenverwaltung für Anfänger
Apr 09, 2025 am 12:07 AM
MySQL ist für Anfänger geeignet, da es einfach zu installieren, leistungsfähig und einfach zu verwalten ist. 1. Einfache Installation und Konfiguration, geeignet für eine Vielzahl von Betriebssystemen. 2. Unterstützung grundlegender Vorgänge wie Erstellen von Datenbanken und Tabellen, Einfügen, Abfragen, Aktualisieren und Löschen von Daten. 3. Bereitstellung fortgeschrittener Funktionen wie Join Operations und Unterabfragen. 4. Die Leistung kann durch Indexierung, Abfrageoptimierung und Tabellenpartitionierung verbessert werden. 5. Backup-, Wiederherstellungs- und Sicherheitsmaßnahmen unterstützen, um die Datensicherheit und -konsistenz zu gewährleisten.
 Kann ich das Datenbankkennwort in Navicat abrufen?
Apr 08, 2025 pm 09:51 PM
Kann ich das Datenbankkennwort in Navicat abrufen?
Apr 08, 2025 pm 09:51 PM
Navicat selbst speichert das Datenbankkennwort nicht und kann das verschlüsselte Passwort nur abrufen. Lösung: 1. Überprüfen Sie den Passwort -Manager. 2. Überprüfen Sie Navicats "Messnot Password" -Funktion; 3.. Setzen Sie das Datenbankkennwort zurück; 4. Kontaktieren Sie den Datenbankadministrator.
 So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
Erstellen Sie eine Datenbank mit Navicat Premium: Stellen Sie eine Verbindung zum Datenbankserver her und geben Sie die Verbindungsparameter ein. Klicken Sie mit der rechten Maustaste auf den Server und wählen Sie Datenbank erstellen. Geben Sie den Namen der neuen Datenbank und den angegebenen Zeichensatz und die angegebene Kollektion ein. Stellen Sie eine Verbindung zur neuen Datenbank her und erstellen Sie die Tabelle im Objektbrowser. Klicken Sie mit der rechten Maustaste auf die Tabelle und wählen Sie Daten einfügen, um die Daten einzufügen.
 MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL ist ein Open Source Relational Database Management System. 1) Datenbank und Tabellen erstellen: Verwenden Sie die Befehle erstellte und creatEtable. 2) Grundlegende Vorgänge: Einfügen, aktualisieren, löschen und auswählen. 3) Fortgeschrittene Operationen: Join-, Unterabfrage- und Transaktionsverarbeitung. 4) Debugging -Fähigkeiten: Syntax, Datentyp und Berechtigungen überprüfen. 5) Optimierungsvorschläge: Verwenden Sie Indizes, vermeiden Sie ausgewählt* und verwenden Sie Transaktionen.
 Wie kann ich das Datenbankkennwort in Navicat für Mariadb anzeigen?
Apr 08, 2025 pm 09:18 PM
Wie kann ich das Datenbankkennwort in Navicat für Mariadb anzeigen?
Apr 08, 2025 pm 09:18 PM
Navicat für MariADB kann das Datenbankkennwort nicht direkt anzeigen, da das Passwort in verschlüsselter Form gespeichert ist. Um die Datenbanksicherheit zu gewährleisten, gibt es drei Möglichkeiten, Ihr Passwort zurückzusetzen: Setzen Sie Ihr Passwort über Navicat zurück und legen Sie ein komplexes Kennwort fest. Zeigen Sie die Konfigurationsdatei an (nicht empfohlen, ein hohes Risiko). Verwenden Sie Systembefehlsleitungs -Tools (nicht empfohlen, Sie müssen die Befehlszeilen -Tools beherrschen).
 MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL sind wesentliche Fähigkeiten für Entwickler. 1.MYSQL ist ein Open -Source -Relational Database Management -System, und SQL ist die Standardsprache, die zum Verwalten und Betrieb von Datenbanken verwendet wird. 2.MYSQL unterstützt mehrere Speichermotoren durch effiziente Datenspeicher- und Abruffunktionen, und SQL vervollständigt komplexe Datenoperationen durch einfache Aussagen. 3. Beispiele für die Nutzung sind grundlegende Abfragen und fortgeschrittene Abfragen wie Filterung und Sortierung nach Zustand. 4. Häufige Fehler umfassen Syntaxfehler und Leistungsprobleme, die durch Überprüfung von SQL -Anweisungen und Verwendung von Erklärungsbefehlen optimiert werden können. 5. Leistungsoptimierungstechniken umfassen die Verwendung von Indizes, die Vermeidung vollständiger Tabellenscanning, Optimierung von Join -Operationen und Verbesserung der Code -Lesbarkeit.
 So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
Sie können eine neue MySQL -Verbindung in Navicat erstellen, indem Sie den Schritten folgen: Öffnen Sie die Anwendung und wählen Sie eine neue Verbindung (Strg N). Wählen Sie "MySQL" als Verbindungstyp. Geben Sie die Hostname/IP -Adresse, den Port, den Benutzernamen und das Passwort ein. (Optional) Konfigurieren Sie erweiterte Optionen. Speichern Sie die Verbindung und geben Sie den Verbindungsnamen ein.
 So führen Sie SQL in Navicat aus
Apr 08, 2025 pm 11:42 PM
So führen Sie SQL in Navicat aus
Apr 08, 2025 pm 11:42 PM
Schritte zur Durchführung von SQL in Navicat: Verbindung zur Datenbank herstellen. Erstellen Sie ein SQL -Editorfenster. Schreiben Sie SQL -Abfragen oder Skripte. Klicken Sie auf die Schaltfläche Ausführen, um eine Abfrage oder ein Skript auszuführen. Zeigen Sie die Ergebnisse an (wenn die Abfrage ausgeführt wird).
