

Einspaltiger MySQL-Index und gemeinsame Indexzusammenfassung

Dieser Artikel vermittelt Ihnen relevantes Wissen über MySQL, in dem hauptsächlich Probleme im Zusammenhang mit einspaltigen Indizes und gemeinsamen Indizes vorgestellt werden. Die Verwendung zusätzlicher Spalten im Index kann den Suchbereich einschränken, die Verwendung eines zweispaltigen Indexes ist jedoch anders Ich hoffe, dass es für alle hilfreich ist.

Empfohlenes Lernen: MySQL-Video-Tutorial
1. Einführung
Durch die Verwendung zusätzlicher Spalten im Index können Sie den Suchbereich eingrenzen, aber die Verwendung eines Index mit zwei Spalten unterscheidet sich von der Verwendung zweier separater Indizes .
Die Struktur des gemeinsamen Verzeichnisses ähnelt der eines Telefonbuchs. Die Namen von Personen bestehen aus Nachnamen und Vornamen. Das Telefonbuch wird zunächst nach Nachnamen und dann nach Vornamen für Personen mit demselben Nachnamen sortiert. Ein Telefonbuch ist sehr nützlich, wenn Sie Ihren Nachnamen kennen, noch nützlicher, wenn Sie Ihren Vor- und Nachnamen kennen, aber nutzlos, wenn Sie nur Ihren Vornamen, aber nicht Ihren Nachnamen kennen.
Wenn Sie also einen gemeinsamen Index erstellen, sollten Sie die Reihenfolge der Spalten sorgfältig berücksichtigen. Union-Indizes sind nützlich, wenn alle Spalten im Index oder nur die ersten paar Spalten durchsucht werden. Sie sind nicht nützlich, wenn nach nachfolgenden Spalten gesucht wird.
2. Einspaltiger Index
Wenn mehrere einspaltige Indizes für Abfragen mit mehreren Bedingungen verwendet werden, gibt der Optimierer der optimalen Indexstrategie Priorität. Es kann sein, dass er nur einen Index verwendet, oder alle mehreren Indizes. Bei mehreren einspaltigen Indizes werden jedoch unten mehrere B+-Indexbäume erstellt, was mehr Platz beansprucht und eine gewisse Sucheffizienz verschwendet. Daher ist es am besten, einen gemeinsamen Index zu erstellen, wenn nur gemeinsame Abfragen mit mehreren Bedingungen vorliegen .
3. Das Prinzip des Präfixes ganz links
Wie der Name schon sagt, kann jeder aufeinanderfolgende Index, der ganz links beginnt, abgeglichen werden. Wenn es sich bei dem ersten Feld um eine Bereichsabfrage handelt, muss ein separater Index erstellt werden Gemeinsamer Index, entsprechend den Geschäftsanforderungen, wird die am häufigsten verwendete Spalte in der where-Klausel ganz links platziert. In diesem Fall ist die Skalierbarkeit besser. Beispielsweise wird der Benutzername häufig als Abfragebedingung verwendet, das Alter jedoch nicht häufig, sodass der Benutzername an der ersten Position des gemeinsamen Index, also ganz links, platziert werden muss .
1. Erstellen Sie einen zusammengesetzten Index
ALTER TABLE employee ADD INDEX idx_name_salary (name,salary)
2. Wenn das am weitesten links liegende Merkmal des zusammengesetzten Index erfüllt ist, wird der zusammengesetzte Index wirksam Erscheint das Merkmal ganz links nicht, ist der Index ungültig
SELECT * FROM employee WHERE NAME='哪吒编程'
4. Alle zusammengesetzten Indizes werden in der Reihenfolge auf der linken Seite angezeigt und der Index wird wirksam Am weitesten links optimiert MySQL, wenn SQL ausgeführt wird, und die unterste Ebene wird verkehrt herum optimiert
SELECT * FROM employee WHERE salary=5000
6. Der zusammengesetzte Index wird auch als gemeinsamer Index bezeichnet, z. k3) entspricht der Erstellung von drei Indexen (k1), (k1, k2) und (k1, k2, k3). Dies ist das Übereinstimmungsprinzip ganz links.
Der gemeinsame Index erfüllt nicht das Prinzip ganz links, und der Index schlägt im Allgemeinen fehl.
4. Es gibt gleichzeitig gemeinsame Indizes und einspaltige Indizes (Felder werden wiederholt, wenn MySQL zu diesem Zeitpunkt abgefragt wird).
Dies beinhaltet die Abfrageoptimierungsstrategie von MySQL selbst. Wenn eine Tabelle mehrere Indizes hat, wählt MySQL basierend auf den Kosten der Abfrageanweisung aus, welchen Index sie verwenden möchten.
Manche Leute sagen, dass die Abfrage von links nach rechts erfolgt . Daher sollten die Bedingungen mit der stärksten Abschirmungskraft so weit wie möglich im Vordergrund platziert werden. Baidu Online hat diese Aussage, aber ich habe sie persönlich getestet. Wenn der Index nicht berücksichtigt wird, hat die Reihenfolge, in der die Bedingungen vorliegen, keinen Einfluss auf die Effizienz gebraucht!
5. Die Essenz des gemeinsamen Indexes
Beim Erstellen eines ** (a, b, c) gemeinsamen Indexes entspricht dies dem Erstellen eines (a) Einzelspaltenindex, eines (a, b) gemeinsamen Indexes und eines (a, b). , c) Gemeinsamer Index Index: Wenn Sie möchten, dass der Index wirksam wird, können Sie natürlich nur drei Kombinationen verwenden. Wie wir oben getestet haben, können Sie auch die Kombination von a und c verwenden, aber tatsächlich nur den Index von a wird verwendet und c wird nicht verwendet.
6. Indexfehler
1. Setzen Sie % vor
2. Es wird kein Index vor und nach der or-Anweisung verwendet. Wenn nur eines der linken und rechten Abfragefelder von or ein Index ist, wird er nur wirksam, wenn es sich sowohl bei dem linken als auch dem rechten Abfragefeld um einen Index handelt Sind Indizes davor und danach, sollte die SQL-Optimierung das Schreiben von or-Anweisungen vermeiden);
4 Es gibt eine implizite Konvertierung des Datentyps. Wenn varchar nicht in einfache Anführungszeichen gesetzt wird, wird es möglicherweise automatisch in den Typ int konvertiert, wodurch der Index ungültig wird und ein vollständiger Tabellenscan erfolgt. 7. Andere Wissenspunkte Wenn die Datenmenge gering ist, ist die Erstellung von Indizes nicht erforderlich.
3. Gemeinsame Indizes haben mehr Vorteile als die Erstellung von Indizes für jede Spalte, denn je mehr Indizes erstellt werden, desto mehr Speicherplatz beanspruchen sie und desto langsamer ist die Aktualisierung von Daten. Außerdem ist die Erstellung von Indizes mit mehreren Spalten erforderlich Auch die Reihenfolge muss beachtet werden. Wir sollten eine strikte Indizierung an die erste Stelle setzen, damit das Screening stärker und effizienter wird.
八、MySQL存储引擎简介
1、InnoDB
支持事务处理,支持外键,支持崩溃修复能力和并发控制。如果需要对事务的完整性要求比较高(比如银行),要求实现并发控制(比如售票),那选择InnoDB有很大的优势。如果需要频繁的更新、删除操作的数据库,也可以选择InnoDB,因为支持事务的提交和回滚。
2、MyISAM
插入速度快,空间和内存使用比较低。如果表主要是用于插入新纪录和读取记录,那么选择MyISAM能实现处理高效率。如果应用的完整性、并发要求比较低,也可以使用。
注意,同一个数据库也可以使用多种存储引擎的表。如果一个表要求比较高的事务处理,可以选择InnoDB。这个数据库中可以将查询要求比较高的表选择MyISAM存储。如果该数据库需要一个用于查询的临时表,可以选择MEMORY存储引擎。
九、索引结构(方法、算法)
在mysql中常用两种索引结构(算法)BTree和Hash,两种算法检索方式不一样,对查询的作用也不一样。
1、Hash
Hash索引的底层实现是由Hash表来实现的,非常适合以 key-value 的形式查询,也就是单个key 查询,或者说是等值查询。
Hash 索引可以比较方便的提供等值查询的场景,由于是一次定位数据,不像BTree索引需 要从根节点到枝节点,最后才能访问到页节点这样多次IO访问,所以检索效率远高于BTree索引。但是对于范围查询的话,就需要进行全表扫描了。
但为什么我们使用BTree比使用Hash多呢?主要Hash本身由于其特殊性,也带来了很多限制和弊端:
Hash索引仅仅能满足“=”,“IN”,“”查询,不能使用范围查询。
联合索引中,Hash索引不能利用部分索引键查询。 对于联合索引中的多个列,Hash是要么全部使用,要么全部不使用,并不支持BTree支持的联合索引的最优前缀,也就是联合索引的前面一个或几个索引键进行查询时,Hash索引无法被利用。
Hash索引无法避免数据的排序操作 由于Hash索引中存放的是经过Hash计算之后的Hash值,而且Hash值的大小关系并不一定和Hash运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算。
Hash索引任何时候都不能避免表扫描 Hash索引是将索引键通过Hash运算之后,将Hash运算结果的Hash值和所对应的行指针信息存放于一个Hash表中,由于不同索引键存在相同Hash值,所以即使满足某个Hash键值的数据的记录条数,也无法从Hash索引中直接完成查询,还是要通过访问表中的实际数据进行比较,并得到相应的结果。
Hash索引遇到大量Hash值相等的情况后性能并不一定会比BTree高 对于选择性比较低的索引键,如果创建Hash索引,那么将会存在大量记录指针信息存于同一个Hash值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据访问,而造成整体性能底下。
2、B+ Tree
B+Tree索引是最常用的mysql数据库索引算法,因为它不仅可以被用在=,>,>=,
例如:
select * from user where name like 'jack%'; select * from user where name like 'jac%k%';
如果一通配符开头,或者没有使用常量,则不会使用索引,
例如:
select * from user where name like '%jack'; select * from user where name like simply_name;
3、 B+/-Tree原理
在数据库中,数据量相对较大,多路查找树显然更加适合数据库的应用场景,接下来我们就介绍这两类多路查找树,毕竟作为程序员,心里没点B树怎么能行呢?
B树:B树就是B-树,他有着如下的特性:
B树不同于二叉树,他们的一个节点可以存储多个关键字和多个子树指针,这就是B+树的特点;
一个m阶的B树要求除了根节点以外,所有的非叶子子节点必须要有[m/2,m]个子树;
根节点必须只能有两个子树,当然,如果只有根节点一个节点的情况存在;
B树是一个查找二叉树,这点和二叉查找树很像,他都是越靠前的子树越小,并且,同一个节点内,关键字按照大小排序;
B树的一个节点要求子树的个数等于关键字的个数+1;
B+树就是B树的plus版
B+树将所有的查找结果放在叶子节点中,这也就意味着查找B+树,就必须到叶子节点才能返回结果;
Die Anzahl der Schlüsselwörter in jedem Knoten des B + -Baums entspricht der Anzahl der Teilbaumzeiger.
Jedes Schlüsselwort des Nicht-Blattknotens des B + -Baums entspricht einem Zeiger, und das Schlüsselwort ist der Maximum des Teilbaums oder Minimalwert;
Optimieren Sie den B-Baum im vorherigen Abschnitt, da die Nicht-Blattknoten von B+Tree nur Schlüsselwertinformationen speichern, vorausgesetzt, dass jeder Festplattenblock 4 Schlüsselwerte speichern kann und Zeigerinformationen, es wird Die Struktur von B+Tree ist wie folgt:
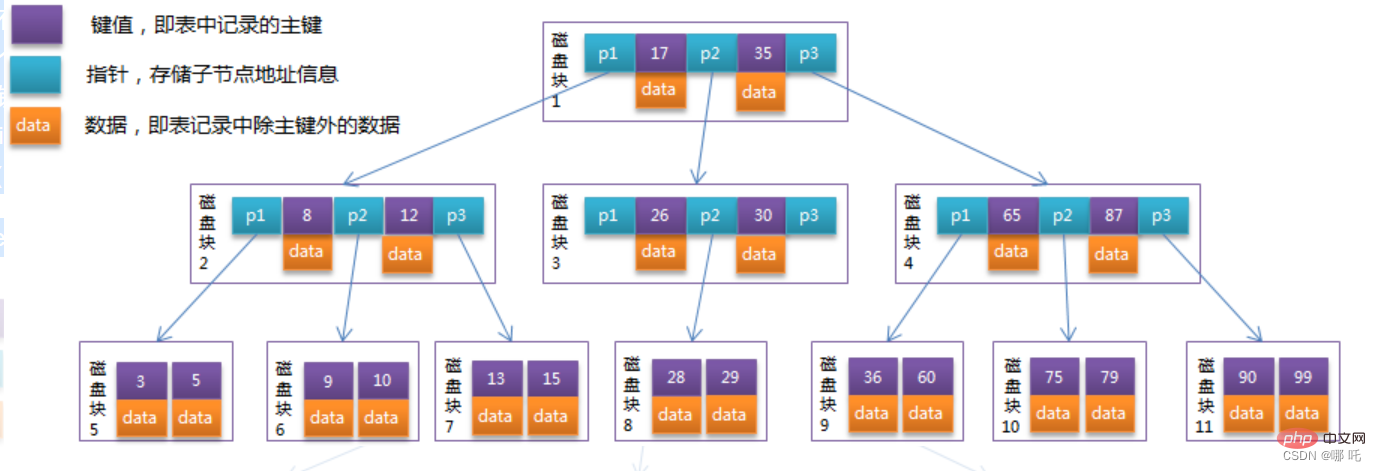
Normalerweise gibt es zwei Kopfzeiger auf B+Tree, einer zeigt auf den Wurzelknoten, der andere zeigt auf den Blattknoten mit dem kleinsten Schlüsselwort, und alle Blattknoten (d. h. Datenknoten) Dazwischen liegt eine Kettenringstruktur. Daher können für B+Tree zwei Suchvorgänge durchgeführt werden: einer ist eine Bereichssuche und eine Paging-Suche nach dem Primärschlüssel und der andere ist eine Zufallssuche ausgehend vom Wurzelknoten.
Vielleicht gibt es im obigen Beispiel nur 22 Datensätze und die Vorteile von B+Tree sind nicht zu erkennen. Hier ist eine Berechnung:
Die Seitengröße in der InnoDB-Speicher-Engine beträgt 16 KB und der Primärschlüsseltyp Die allgemeine Tabelle ist INT (belegt 4 Wörter) oder BIGINT (belegt 8 Bytes). Der Zeigertyp ist im Allgemeinen 4 oder 8 Bytes, was bedeutet, dass eine Seite (ein Knoten in B + Baum) wahrscheinlich 16 KB/( 8B+8B )=1K Schlüsselwerte (da es sich um eine Schätzung handelt, beträgt der Wert von K hier zur Vereinfachung der Berechnung 〖10〗^3). 16KB/(8B+8B)=1K个键值(因为是估值,为方便计算,这里的K取值为〖10〗^3)。
也就是说一个深度为3的B+Tree索引可以维护10^3 * 10^3 * 10^3 = 10亿 Mit anderen Worten: Ein B+Tree-Index mit einer Tiefe von 3 kann 10^3 * 10^3 * 10^3 = 1 Milliarde Datensätze verwalten.
In tatsächlichen Situationen ist möglicherweise nicht jeder Knoten vollständig gefüllt, daher beträgt die Höhe von B+Tree in der Datenbank im Allgemeinen 2-4 Schichten. Die InnoDB-Speicher-Engine von MySQL ist so konzipiert, dass der Root-Knoten im Speicher resident ist, was bedeutet, dass nur 1 bis 3 Festplatten-E/A-Vorgänge erforderlich sind, um den Zeilendatensatz eines bestimmten Schlüsselwerts zu finden.
Der B+Tree-Index in der Datenbank kann in Clustered-Index und Sekundärindex unterteilt werden. Das obige B+Tree-Beispieldiagramm ist in der Datenbank als Clustered-Index implementiert. Die Blattknoten im B+Tree des Clustered-Index speichern die Zeilendatensatzdaten der gesamten Tabelle. Der Unterschied zwischen einem Hilfsindex und einem Clustered-Index besteht darin, dass die Blattknoten des Hilfsindex nicht alle Daten des Zeilendatensatzes enthalten, sondern den Clustered-Index-Schlüssel, der die entsprechenden Zeilendaten speichert, also den Primärschlüssel. Beim Abfragen von Daten über einen Sekundärindex durchläuft die InnoDB-Speicher-Engine den Sekundärindex, um den Primärschlüssel zu finden, und findet dann über den Primärschlüssel die vollständigen Zeilendatensatzdaten im Clustered-Index.
Empfohlenes Lernen: MySQL-Video-Tutorial
Das obige ist der detaillierte Inhalt vonEinspaltiger MySQL-Index und gemeinsame Indexzusammenfassung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL ist ein Open Source Relational Database Management -System, das hauptsächlich zum schnellen und zuverlässigen Speicher und Abrufen von Daten verwendet wird. Sein Arbeitsprinzip umfasst Kundenanfragen, Abfragebedingungen, Ausführung von Abfragen und Rückgabergebnissen. Beispiele für die Nutzung sind das Erstellen von Tabellen, das Einsetzen und Abfragen von Daten sowie erweiterte Funktionen wie Join -Operationen. Häufige Fehler umfassen SQL -Syntax, Datentypen und Berechtigungen sowie Optimierungsvorschläge umfassen die Verwendung von Indizes, optimierte Abfragen und die Partitionierung von Tabellen.
 Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Die Position von MySQL in Datenbanken und Programmierung ist sehr wichtig. Es handelt sich um ein Open -Source -Verwaltungssystem für relationale Datenbankverwaltung, das in verschiedenen Anwendungsszenarien häufig verwendet wird. 1) MySQL bietet effiziente Datenspeicher-, Organisations- und Abruffunktionen und unterstützt Systeme für Web-, Mobil- und Unternehmensebene. 2) Es verwendet eine Client-Server-Architektur, unterstützt mehrere Speichermotoren und Indexoptimierung. 3) Zu den grundlegenden Verwendungen gehören das Erstellen von Tabellen und das Einfügen von Daten, und erweiterte Verwendungen beinhalten Multi-Table-Verknüpfungen und komplexe Abfragen. 4) Häufig gestellte Fragen wie SQL -Syntaxfehler und Leistungsprobleme können durch den Befehl erklären und langsam abfragen. 5) Die Leistungsoptimierungsmethoden umfassen die rationale Verwendung von Indizes, eine optimierte Abfrage und die Verwendung von Caches. Zu den Best Practices gehört die Verwendung von Transaktionen und vorbereiteten Staten
 Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
MySQL wird für seine Leistung, Zuverlässigkeit, Benutzerfreundlichkeit und Unterstützung der Gemeinschaft ausgewählt. 1.MYSQL bietet effiziente Datenspeicher- und Abruffunktionen, die mehrere Datentypen und erweiterte Abfragevorgänge unterstützen. 2. Übernehmen Sie die Architektur der Client-Server und mehrere Speichermotoren, um die Transaktion und die Abfrageoptimierung zu unterstützen. 3. Einfach zu bedienend unterstützt eine Vielzahl von Betriebssystemen und Programmiersprachen. V.
 So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
Apache verbindet eine Verbindung zu einer Datenbank erfordert die folgenden Schritte: Installieren Sie den Datenbanktreiber. Konfigurieren Sie die Datei web.xml, um einen Verbindungspool zu erstellen. Erstellen Sie eine JDBC -Datenquelle und geben Sie die Verbindungseinstellungen an. Verwenden Sie die JDBC -API, um über den Java -Code auf die Datenbank zuzugreifen, einschließlich Verbindungen, Erstellen von Anweisungen, Bindungsparametern, Ausführung von Abfragen oder Aktualisierungen und Verarbeitungsergebnissen.
 So starten Sie MySQL von Docker
Apr 15, 2025 pm 12:09 PM
So starten Sie MySQL von Docker
Apr 15, 2025 pm 12:09 PM
Der Prozess des Startens von MySQL in Docker besteht aus den folgenden Schritten: Ziehen Sie das MySQL -Image zum Erstellen und Starten des Containers an, setzen
 MySQLs Rolle: Datenbanken in Webanwendungen
Apr 17, 2025 am 12:23 AM
MySQLs Rolle: Datenbanken in Webanwendungen
Apr 17, 2025 am 12:23 AM
Die Hauptaufgabe von MySQL in Webanwendungen besteht darin, Daten zu speichern und zu verwalten. 1.Mysql verarbeitet effizient Benutzerinformationen, Produktkataloge, Transaktionsunterlagen und andere Daten. 2. Durch die SQL -Abfrage können Entwickler Informationen aus der Datenbank extrahieren, um dynamische Inhalte zu generieren. 3.Mysql arbeitet basierend auf dem Client-Server-Modell, um eine akzeptable Abfragegeschwindigkeit sicherzustellen.
 CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
Die Installation von MySQL auf CentOS umfasst die folgenden Schritte: Hinzufügen der entsprechenden MySQL Yum -Quelle. Führen Sie den Befehl mySQL-server aus, um den MySQL-Server zu installieren. Verwenden Sie den Befehl mySQL_SECURE_INSTALLATION, um Sicherheitseinstellungen vorzunehmen, z. B. das Festlegen des Stammbenutzerkennworts. Passen Sie die MySQL -Konfigurationsdatei nach Bedarf an. Tune MySQL -Parameter und optimieren Sie Datenbanken für die Leistung.
