

Grundlegendes zum MySQL-Index-Pushdown in einem Artikel

Dieser Artikel bringt Ihnen relevantes Wissen über MySQL, das hauptsächlich den relevanten Inhalt zum Index-Pushdown vorstellt, der auch Index-Pushdown genannt wird, oder kurz ICP Optimierung der Datenabfrage. Ich hoffe, dass es für alle hilfreich sein wird.

Empfohlenes Lernen: MySQL-Video-Tutorial
SELECT-Anweisungsausführungsprozess
MySQL-Datenbank besteht aus Server-Ebene und Engine Schichtzusammensetzung: MySQL 数据库由 Server 层和 Engine 层组成:
-
Server层: 有SQL分析器、SQL优化器、SQL执行器,用于负责SQL语句的具体执行过程。 -
Engine层: 负责存储具体的数据,如最常使用的InnoDB存储引擎,还有用于在内存中存储临时结果集的TempTable引擎。
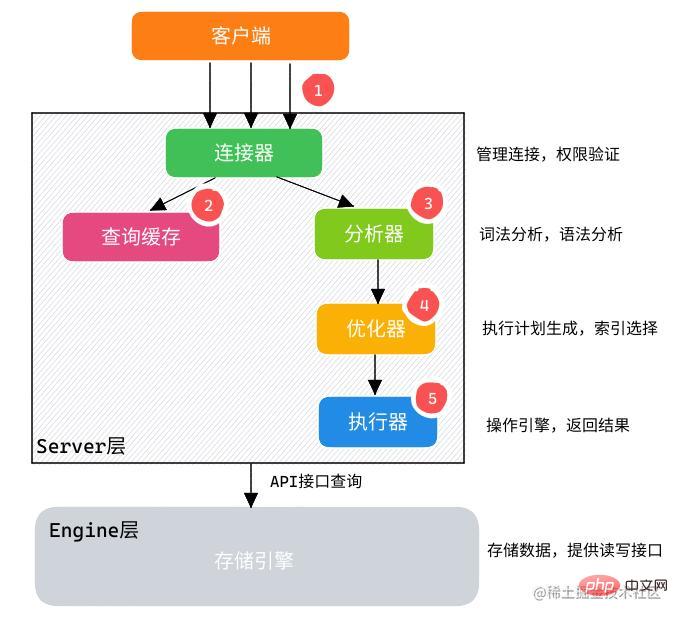
通过客户端/服务器通信协议与
MySQL建立连接。-
查询缓存:
- 如果开启了
Query Cache且在查询缓存过程中查询到完全相同的SQL语句,则将查询结果直接返回给客户端; - 如果没有开启
Query Cache或者没有查询到完全相同的SQL语句则会由解析器进行语法语义解析,并生成解析树。
- 如果开启了
分析器生成新的解析树。
查询优化器生成执行计划。
-
查询执行引擎执行
SQL语句,此时查询执行引擎会根据SQL语句中表的存储引擎类型,以及对应的API接口与底层存储引擎缓存或者物理文件的交互情况,得到查询结果,由MySQL Server过滤后将查询结果缓存并返回给客户端。若开启了
Query Cache,这时也会将SQL语句和结果完整地保存到Query Cache中,以后若有相同的SQL语句执行则直接返回结果。
Tips:MySQL 8.0 已去掉 query cache(查询缓存模块)。
因为查询缓存的命中率会非常低。 查询缓存的失效非常频繁:只要有对一个表的更新,这个表上所有的查询缓存都会被清空。
什么是索引下推?
索引下推(Index Condition Pushdown): 简称 ICP,通过把索引过滤条件下推到存储引擎,来减少 MySQL 存储引擎访问基表的次数 和 MySQL 服务层访问存储引擎的次数。
索引下推 VS 覆盖索引: 其实都是 减少回表的次数,只不过方式不同
覆盖索引: 当索引中包含所需要的字段(
SELECT XXX),则不再回表去查询字段。索引下推: 对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表的行数。
要了解 ICP 是如何工作的,先从一个查询 SQL 开始:
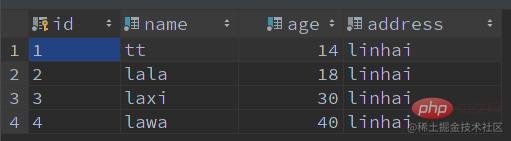
举个栗子:查询名字 la 开头、年龄为 18 的记录
SELECT * FROM user WHERE name LIKE 'la%' AND age = 18;
有这些记录:
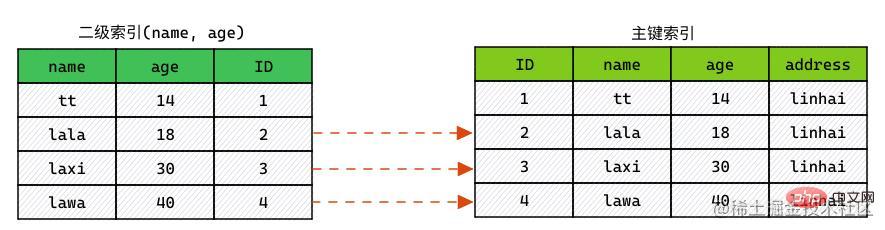
不开启 ICP 时索引扫描是如何进行的:
- 通过索引元组,定位读取对应数据行。(实际上:就是回表)
- 对
WHERE中字段做判断,过滤掉不满足条件的行。
使用 ICP,索引扫描如下进行:
- 获取索引元组。
- 对
WHERE中字段做判断,在索引列中进行过滤。 - 对满足条件的索引,进行回表查询整行。
- 对
WHEREServerSchicht: HatSQL-Analysator,SQL-Optimierung Executor,SQLExecutor, ist für den spezifischen Ausführungsprozess vonSQL-Anweisungen verantwortlich.
🎜Engine-Schicht: Verantwortlich für die Speicherung spezifischer Daten, wie z. B. der am häufigsten verwendetenInnoDB-Speicher-Engine, und für die Speicherung temporärer Ergebnisse in SpeichersetsTempTable-Engine. 🎜
🎜- 🎜Vom Kunden Stellen Sie mithilfe des Client/Server-Kommunikationsprotokolls eine Verbindung mit
MySQLher. 🎜🎜 - 🎜🎜Abfrage-Cache:🎜
- Wenn
Abfrage-Cacheaktiviert ist und genau das gleicheSQLwährend der Abfrage abgefragt wird Cache-Prozesscode>-Anweisung werden die Abfrageergebnisse direkt an den Client zurückgegeben. 🎜 - Wenn
Query Cachenicht aktiviert ist oder genau dieselbeSQL-Anweisung nicht aktiviert ist Wenn es abgefragt wird, wird es analysiert. Der Prozessor führt eine syntaktische und semantische Analyse durch und generiert einen Analysebaum. 🎜🎜🎜 - 🎜Der Parser generiert einen neuen Parse-Baum. 🎜🎜
- 🎜Der Abfrageoptimierer generiert einen Ausführungsplan. 🎜🎜
- 🎜Die Abfrageausführungs-Engine führt die
SQL-Anweisung aus. Zu diesem Zeitpunkt basiert die Abfrageausführungs-Engine auf dem Speicher-Engine-Typ der Tabelle imSQLAnweisung und die entsprechendeAPIDie Schnittstelle interagiert mit dem zugrunde liegenden Speicher-Engine-Cache oder physischen Dateien, um Abfrageergebnisse zu erhalten. Nach der Filterung durchMySQL Serverwerden die Abfrageergebnisse zwischengespeichert und zurückgegeben der Kunde. 🎜🎜Wenn
🎜🎜🎜🎜Query Cacheaktiviert ist, werden dieSQL-Anweisung und die Ergebnisse zu diesem Zeitpunkt vollständig imQuery Cachegespeichert Wird dieselbeSQL-Anweisung ausgeführt, wird das Ergebnis direkt zurückgegeben. 🎜Tipps:MySQL 8.0hat denAbfrage-Cache(Abfrage-Cache-Modul) entfernt. 🎜🎜Weil die Trefferquote des Abfragecaches sehr niedrig sein wird. Ungültigmachungen des Abfragecaches kommen sehr häufig vor: Bei jeder Aktualisierung einer Tabelle werden alle Abfragecaches für diese Tabelle geleert. 🎜
🎜Was ist Index-Pushdown? 🎜🎜🎜Index Condition Pushdown (Index Condition Pushdown): wird alsICPbezeichnet und reduziertMySQL, indem die Indexfilterbedingungen nach unten verschoben werden Speicher-Engine.Die Häufigkeit, mit der die Speicher-Engine auf die Basistabelle zugreift, und die Häufigkeit, mit der dieMySQL-Dienstschicht auf die Speicher-Engine zugreift. 🎜🎜🎜Index-Pushdown vs. Covering-Index: Tatsächlich 🎜reduzieren beide die Anzahl der Tabellenrückgaben, aber auf unterschiedliche Weise 🎜- 🎜🎜Covered-Index: Wenn die Indizierung die erforderlichen Felder enthält (
SELECT XXX), ist es nicht erforderlich, zur Tabelle zurückzukehren, um die Felder abzufragen. 🎜🎜 - 🎜🎜Index-Pushdown: Treffen Sie zunächst eine Beurteilung der im Index enthaltenen Felder, 🎜filtern Sie direkt die Datensätze heraus, die die Bedingungen nicht erfüllen und reduzieren Sie die Anzahl der zurückgegebenen Zeilen der Tisch. 🎜🎜🎜🎜🎜Um zu verstehen, wie
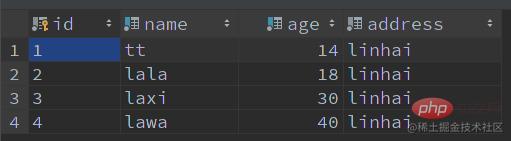
ICPfunktioniert, beginnen Sie mit einer AbfrageSQL:🎜🎜Zum Beispiel: Fragen Sie den Namenla Records ab, der mit beginntund Alter18🎜🎜🎜 haben diese Datensätze: 🎜🎜-- 表创建 CREATE TABLE IF NOT EXISTS `user` ( `id` VARCHAR(64) NOT NULL COMMENT '主键 id', `name` VARCHAR(50) NOT NULL COMMENT '名字', `age` TINYINT NOT NULL COMMENT '年龄', `address` VARCHAR(100) NOT NULL COMMENT '地址', PRIMARY KEY (id) ) ENGINE=InnoDB DEFAULT CHARSET utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT '用户表'; -- 创建索引 CREATE INDEX idx_name_age ON user (name, age); -- 新增数据 INSERT INTO user (id, name, age, address) VALUES (1, 'tt', 14, 'linhai'); INSERT INTO user (id, name, age, address) VALUES (2, 'lala', 18, 'linhai'); INSERT INTO user (id, name, age, address) VALUES (3, 'laxi', 30, 'linhai'); INSERT INTO user (id, name, age, address) VALUES (4, 'lawa', 40, 'linhai'); -- 查询语句 SELECT * FROM user WHERE name LIKE 'la%' AND age = 18;
Nach dem Login kopierenNach dem Login kopieren 🎜🎜🎜So funktioniert das Indexscannen, wenn
🎜🎜🎜So funktioniert das Indexscannen, wenn ICPnicht aktiviert ist:🎜- Suchen und lesen die entsprechende Datenzeile durch das Indextupel. (Eigentlich: Geben Sie einfach die Tabelle zurück) 🎜
- Beurteilen Sie die Felder in
WHEREund filtern Sie Zeilen heraus, die die Bedingungen nicht erfüllen. 🎜🎜🎜🎜🎜🎜Verwenden Sie ICP</ code>, der Indexscan läuft wie folgt ab:</strong>🎜<ul><li>Holen Sie sich das Indextupel. 🎜<li>Beurteilen Sie die Felder in <code>WHEREund filtern Sie in der Indexspalte. 🎜 - Für Indizes, die die Bedingungen erfüllen, fragen Sie die gesamte Zeile zurück in die Tabelle ab. 🎜
- Beurteilen Sie die Felder in
WHEREund filtern Sie Zeilen heraus, die die Bedingungen nicht erfüllen. 🎜🎜🎜🎜🎜动手实验:
实验:使用
MySQL版本8.0.16-- 表创建 CREATE TABLE IF NOT EXISTS `user` ( `id` VARCHAR(64) NOT NULL COMMENT '主键 id', `name` VARCHAR(50) NOT NULL COMMENT '名字', `age` TINYINT NOT NULL COMMENT '年龄', `address` VARCHAR(100) NOT NULL COMMENT '地址', PRIMARY KEY (id) ) ENGINE=InnoDB DEFAULT CHARSET utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT '用户表'; -- 创建索引 CREATE INDEX idx_name_age ON user (name, age); -- 新增数据 INSERT INTO user (id, name, age, address) VALUES (1, 'tt', 14, 'linhai'); INSERT INTO user (id, name, age, address) VALUES (2, 'lala', 18, 'linhai'); INSERT INTO user (id, name, age, address) VALUES (3, 'laxi', 30, 'linhai'); INSERT INTO user (id, name, age, address) VALUES (4, 'lawa', 40, 'linhai'); -- 查询语句 SELECT * FROM user WHERE name LIKE 'la%' AND age = 18;
Nach dem Login kopierenNach dem Login kopieren新增数据如下:
- 关闭
ICP,再调用EXPLAIN查看语句:
-- 将 ICP 关闭 SET optimizer_switch = 'index_condition_pushdown=off'; -- 查看确认 show variables like 'optimizer_switch'; -- 用 EXPLAIN 查看 EXPLAIN SELECT * FROM user WHERE name LIKE 'la%' AND age = 18;
Nach dem Login kopieren- 开启
ICP,再调用EXPLAIN查看语句:
-- 将 ICP 打开 SET optimizer_switch = 'index_condition_pushdown=on'; -- 查看确认 show variables like 'optimizer_switch'; -- 用 EXPLAIN 查看 EXPLAIN SELECT * FROM user WHERE name LIKE 'la%' AND age = 18;
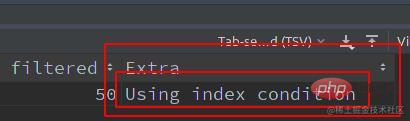
Nach dem Login kopieren由上实验可知,区别是否开启
ICP:Exira字段中的Using index condition更进一步,来看下
ICP带来的性能提升:通过访问数据文件的次数
-- 1. 清空 status 状态 flush status; -- 2. 查询 SELECT * FROM user WHERE name LIKE 'la%' AND age = 18; -- 3. 查看 handler 状态 show status like '%handler%';
Nach dem Login kopieren对比开启
ICP和 关闭ICP: 关注Handler_read_next的值-- 开启 ICP flush status; SELECT * FROM user WHERE name LIKE 'la%' AND age = 18; show status like '%handler%'; +----------------------------|-------+ | Variable_name | Value | +----------------------------|-------+ | Handler_commit | 1 | | Handler_delete | 0 | | Handler_discover | 0 | | Handler_external_lock | 2 | | Handler_mrr_init | 0 | | Handler_prepare | 0 | | Handler_read_first | 0 | | Handler_read_key | 1 | | Handler_read_last | 0 | | Handler_read_next | 1 | <---重点 | Handler_read_prev | 0 | | Handler_read_rnd | 0 | | Handler_read_rnd_next | 0 | | Handler_rollback | 0 | | Handler_savepoint | 0 | | Handler_savepoint_rollback | 0 | | Handler_update | 0 | | Handler_write | 0 | +----------------------------|-------+ 18 rows in set (0.00 sec) -- 关闭 ICP flush status; SELECT * FROM user WHERE name LIKE 'la%' AND age = 18; show status like '%handler%'; +----------------------------|-------+ | Variable_name | Value | +----------------------------|-------+ | Handler_commit | 1 | | Handler_delete | 0 | | Handler_discover | 0 | | Handler_external_lock | 2 | | Handler_mrr_init | 0 | | Handler_prepare | 0 | | Handler_read_first | 0 | | Handler_read_key | 1 | | Handler_read_last | 0 | | Handler_read_next | 3 | <---重点 | Handler_read_prev | 0 | | Handler_read_rnd | 0 | | Handler_read_rnd_next | 0 | | Handler_rollback | 0 | | Handler_savepoint | 0 | | Handler_savepoint_rollback | 0 | | Handler_update | 0 | | Handler_write | 0 | +----------------------------|-------+ 18 rows in set (0.00 sec)
Nach dem Login kopieren由上实验可知:
- 开启
ICP:Handler_read_next等于 1,回表查 1 次。 - 关闭
ICP:Handler_read_next等于 3,回表查 3 次。
这实验跟上面的栗子就对应上了。
索引下推限制
根据官网可知,索引下推 受以下条件限制:
当需要访问整个表行时,
ICP用于range、ref、eq_ref和ref_or_nullICP可以用于InnoDB和MyISAM表,包括分区表InnoDB和MyISAM表。对于
InnoDB表,ICP仅用于二级索引。ICP的目标是减少全行读取次数,从而减少I/O操作。对于InnoDB聚集索引,完整的记录已经读入InnoDB缓冲区。在这种情况下使用ICP不会减少I/O。在虚拟生成列上创建的二级索引不支持
ICP。InnoDB支持虚拟生成列的二级索引。引用子查询的条件不能下推。
引用存储功能的条件不能被按下。存储引擎不能调用存储的函数。
触发条件不能下推。
不能将条件下推到包含对系统变量的引用的派生表。(
MySQL 8.0.30及更高版本)。
小结下:
ICP仅适用于 二级索引。ICP目标是 减少回表查询。ICP对联合索引的部分列模糊查询非常有效。
拓展:虚拟列
CREATE TABLE UserLogin ( userId BIGINT, loginInfo JSON, cellphone VARCHAR(255) AS (loginInfo->>"$.cellphone"), PRIMARY KEY(userId), UNIQUE KEY idx_cellphone(cellphone) );
Nach dem Login kopieren列
cellphone:就是一个虚拟列,它是由后面的函数表达式计算而成,本身这个列不占用任何的存储空间,而索引idx_cellphone实质是一个函数索引。好处: 在写
SQL时可以直接使用这个虚拟列,而不用写冗长的函数。举个栗子: 查询手机号
-- 不用虚拟列 SELECT * FROM UserLogin WHERE loginInfo->>"$.cellphone" = '13988888888' -- 使用虚拟列 SELECT * FROM UserLogin WHERE cellphone = '13988888888'
Nach dem Login kopieren推荐学习:mysql视频教程
Das obige ist der detaillierte Inhalt vonGrundlegendes zum MySQL-Index-Pushdown in einem Artikel. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
- 关闭
- 🎜🎜Covered-Index: Wenn die Indizierung die erforderlichen Felder enthält (
- Wenn
- 🎜Vom Kunden Stellen Sie mithilfe des Client/Server-Kommunikationsprotokolls eine Verbindung mit



Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 MySQL: Die einfache Datenverwaltung für Anfänger
Apr 09, 2025 am 12:07 AM
MySQL: Die einfache Datenverwaltung für Anfänger
Apr 09, 2025 am 12:07 AM
MySQL ist für Anfänger geeignet, da es einfach zu installieren, leistungsfähig und einfach zu verwalten ist. 1. Einfache Installation und Konfiguration, geeignet für eine Vielzahl von Betriebssystemen. 2. Unterstützung grundlegender Vorgänge wie Erstellen von Datenbanken und Tabellen, Einfügen, Abfragen, Aktualisieren und Löschen von Daten. 3. Bereitstellung fortgeschrittener Funktionen wie Join Operations und Unterabfragen. 4. Die Leistung kann durch Indexierung, Abfrageoptimierung und Tabellenpartitionierung verbessert werden. 5. Backup-, Wiederherstellungs- und Sicherheitsmaßnahmen unterstützen, um die Datensicherheit und -konsistenz zu gewährleisten.
 MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL ist ein Open Source Relational Database Management System. 1) Datenbank und Tabellen erstellen: Verwenden Sie die Befehle erstellte und creatEtable. 2) Grundlegende Vorgänge: Einfügen, aktualisieren, löschen und auswählen. 3) Fortgeschrittene Operationen: Join-, Unterabfrage- und Transaktionsverarbeitung. 4) Debugging -Fähigkeiten: Syntax, Datentyp und Berechtigungen überprüfen. 5) Optimierungsvorschläge: Verwenden Sie Indizes, vermeiden Sie ausgewählt* und verwenden Sie Transaktionen.
 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
Erstellen Sie eine Datenbank mit Navicat Premium: Stellen Sie eine Verbindung zum Datenbankserver her und geben Sie die Verbindungsparameter ein. Klicken Sie mit der rechten Maustaste auf den Server und wählen Sie Datenbank erstellen. Geben Sie den Namen der neuen Datenbank und den angegebenen Zeichensatz und die angegebene Kollektion ein. Stellen Sie eine Verbindung zur neuen Datenbank her und erstellen Sie die Tabelle im Objektbrowser. Klicken Sie mit der rechten Maustaste auf die Tabelle und wählen Sie Daten einfügen, um die Daten einzufügen.
 MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL sind wesentliche Fähigkeiten für Entwickler. 1.MYSQL ist ein Open -Source -Relational Database Management -System, und SQL ist die Standardsprache, die zum Verwalten und Betrieb von Datenbanken verwendet wird. 2.MYSQL unterstützt mehrere Speichermotoren durch effiziente Datenspeicher- und Abruffunktionen, und SQL vervollständigt komplexe Datenoperationen durch einfache Aussagen. 3. Beispiele für die Nutzung sind grundlegende Abfragen und fortgeschrittene Abfragen wie Filterung und Sortierung nach Zustand. 4. Häufige Fehler umfassen Syntaxfehler und Leistungsprobleme, die durch Überprüfung von SQL -Anweisungen und Verwendung von Erklärungsbefehlen optimiert werden können. 5. Leistungsoptimierungstechniken umfassen die Verwendung von Indizes, die Vermeidung vollständiger Tabellenscanning, Optimierung von Join -Operationen und Verbesserung der Code -Lesbarkeit.
 So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
Sie können eine neue MySQL -Verbindung in Navicat erstellen, indem Sie den Schritten folgen: Öffnen Sie die Anwendung und wählen Sie eine neue Verbindung (Strg N). Wählen Sie "MySQL" als Verbindungstyp. Geben Sie die Hostname/IP -Adresse, den Port, den Benutzernamen und das Passwort ein. (Optional) Konfigurieren Sie erweiterte Optionen. Speichern Sie die Verbindung und geben Sie den Verbindungsnamen ein.
 So führen Sie SQL in Navicat aus
Apr 08, 2025 pm 11:42 PM
So führen Sie SQL in Navicat aus
Apr 08, 2025 pm 11:42 PM
Schritte zur Durchführung von SQL in Navicat: Verbindung zur Datenbank herstellen. Erstellen Sie ein SQL -Editorfenster. Schreiben Sie SQL -Abfragen oder Skripte. Klicken Sie auf die Schaltfläche Ausführen, um eine Abfrage oder ein Skript auszuführen. Zeigen Sie die Ergebnisse an (wenn die Abfrage ausgeführt wird).
 Navicat stellt eine Verbindung zu Datenbankfehlercode und Lösung her
Apr 08, 2025 pm 11:06 PM
Navicat stellt eine Verbindung zu Datenbankfehlercode und Lösung her
Apr 08, 2025 pm 11:06 PM
Häufige Fehler und Lösungen beim Anschließen mit Datenbanken: Benutzername oder Kennwort (Fehler 1045) Firewall -Blocks -Verbindungsverbindung (Fehler 2003) Timeout (Fehler 10060) Die Verwendung von Socket -Verbindung kann nicht verwendet werden (Fehler 1042).
