

Eine kurze Analyse, wie Node OCR implementiert

Wie implementiert man OCR (optische Zeichenerkennung)? Der folgende Artikel stellt Ihnen vor, wie Sie node zur Implementierung von OCR verwenden. Ich hoffe, er wird Ihnen hilfreich sein!

ocr ist eine optische Zeichenerkennung, die einfach ausgedrückt den Text auf dem Bild erkennt.
Leider bin ich nur ein einfacher Webprogrammierer? Ich weiß nicht viel über KI. Wenn ich OCR implementieren möchte, kann ich nur eine Bibliothek eines Drittanbieters finden.
Es gibt viele Drittanbieter-Bibliotheken für OCR in der Python-Sprache. Ich habe lange nach einer Drittanbieter-Bibliothek für NodeJS gesucht, um OCR zu implementieren. Endlich habe ich herausgefunden, dass die Bibliothek tesseract.js immer noch OCR implementieren kann sehr praktisch. [Verwandte Tutorial-Empfehlungen: nodejs Video-Tutorial]
Effektanzeige
Online-Beispiel: http://www.lolmbbs.com/tool/ocr
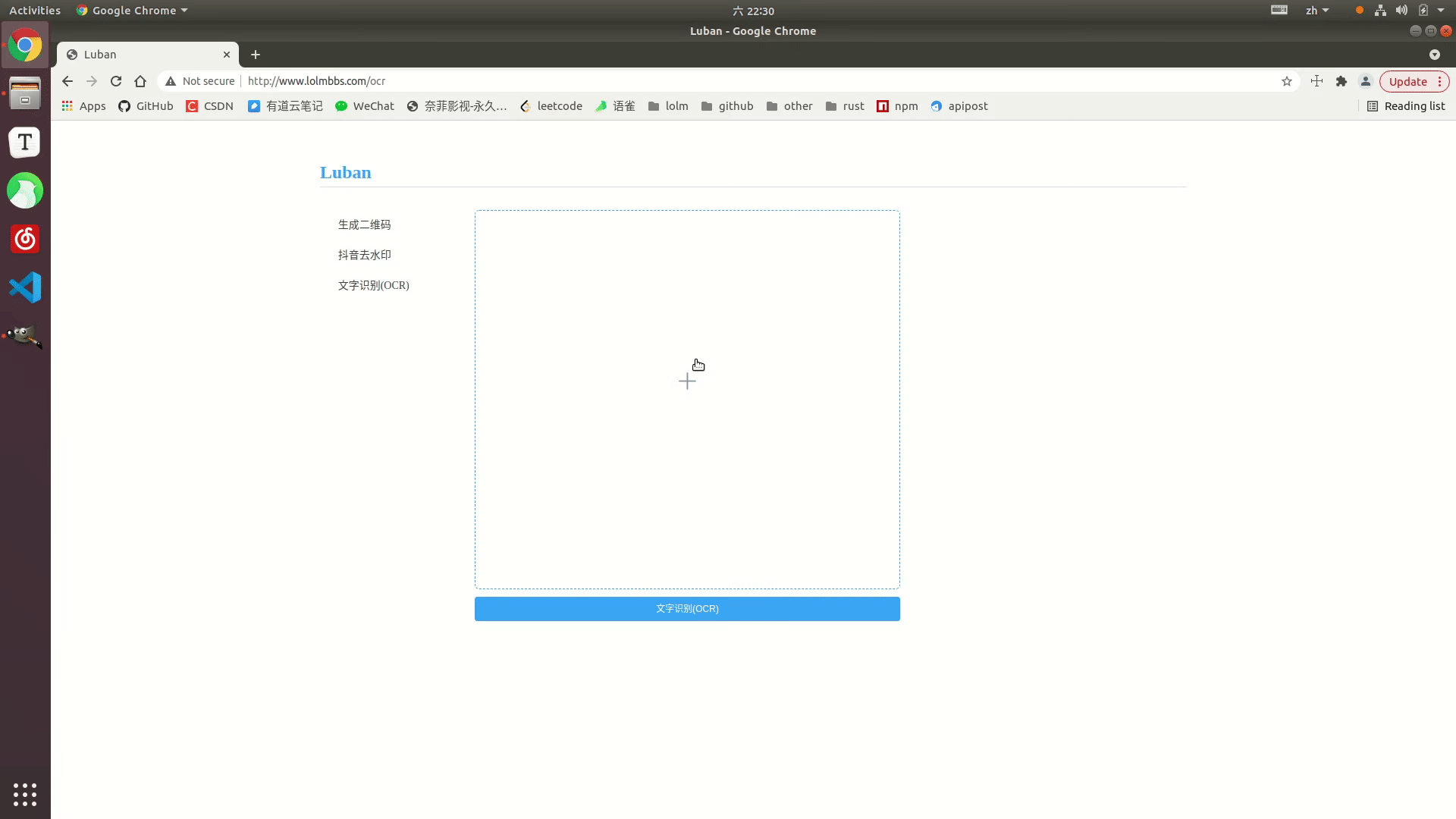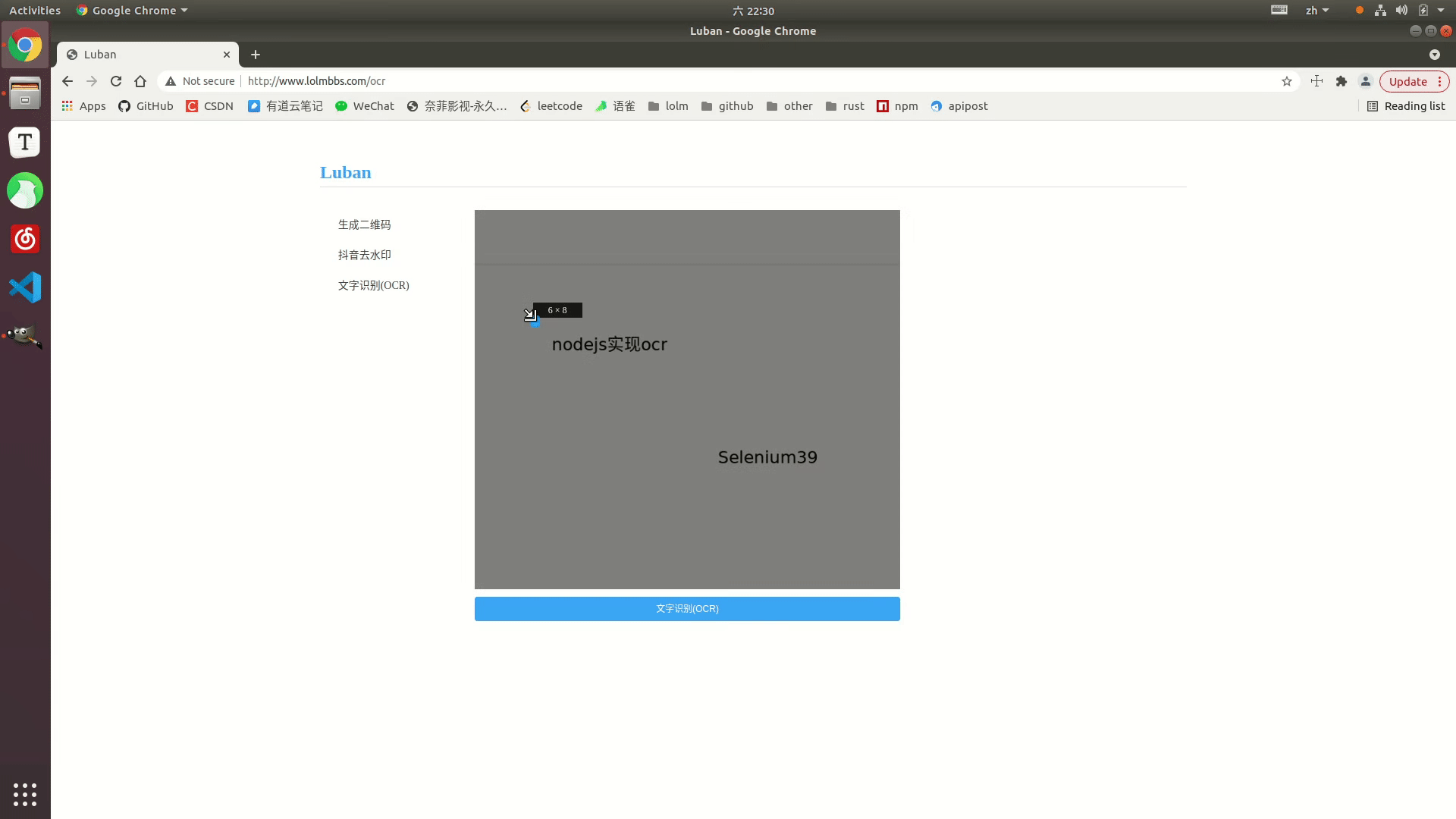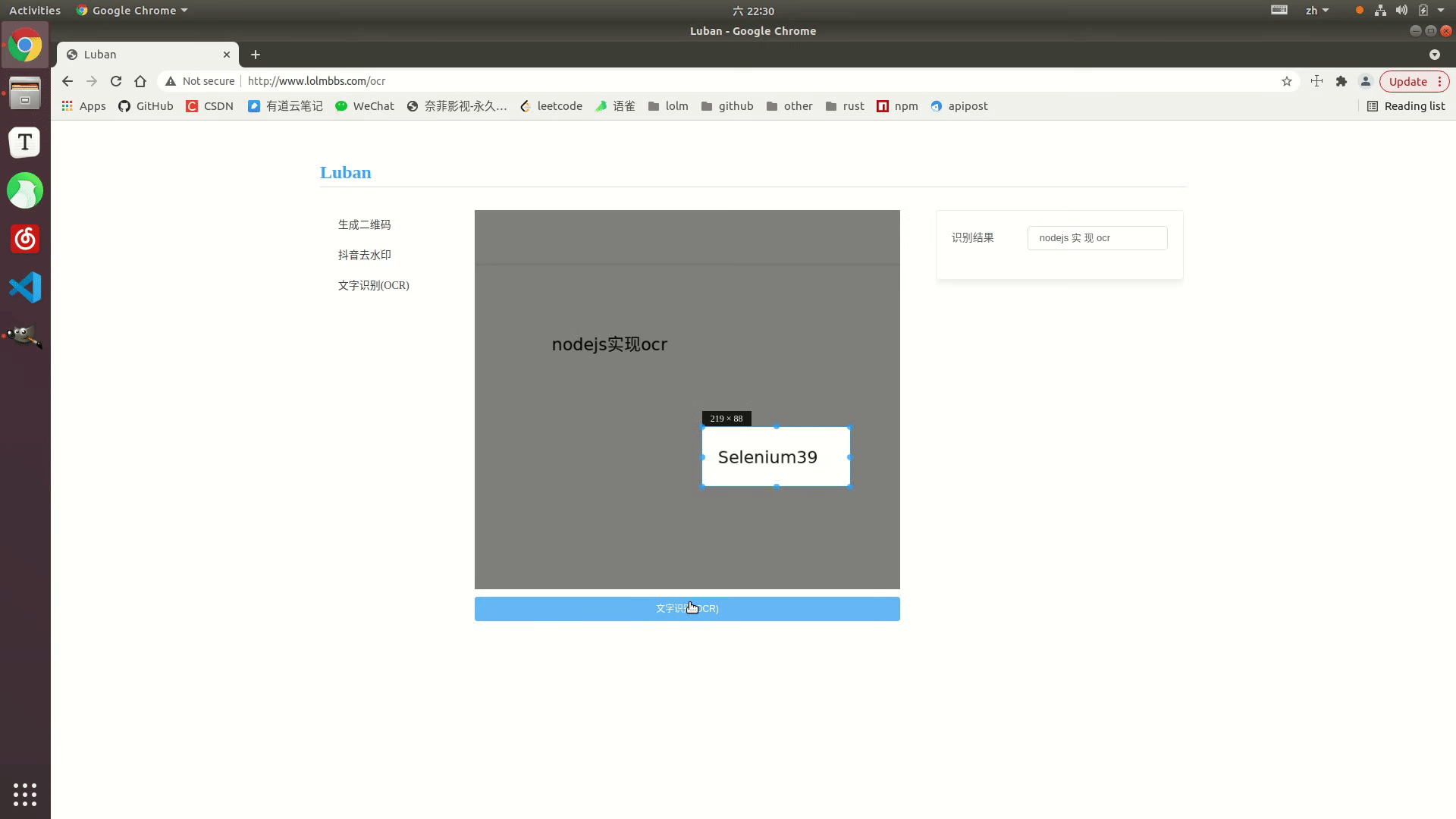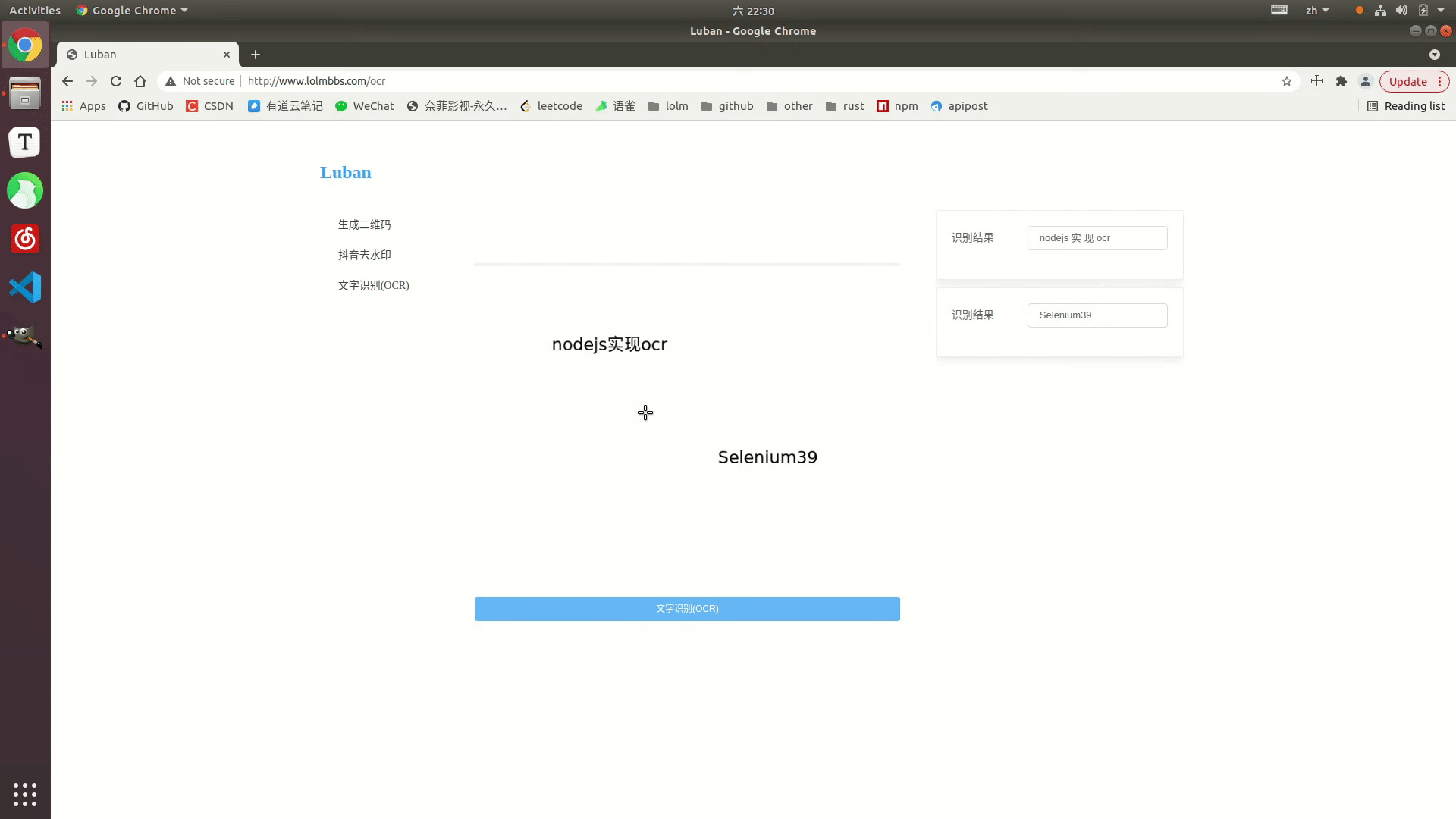
Detaillierter Code
tesserract.js das Die Bibliothek bietet mehrere Versionen zur Auswahl. Ich verwende die Offline-Version tesseract.js-offline. Schließlich ist jeder von schlechten Netzwerkbedingungen betroffen. 
Standard-Beispielcode默认示例代码
const { createWorker } = require('tesseract.js');
const path = require('path');
const worker = createWorker({
langPath: path.join(__dirname, '..', 'lang-data'),
logger: m => console.log(m),
});
(async () => {
await worker.load();
await worker.loadLanguage('eng');
await worker.initialize('eng');
const { data: { text } } = await worker.recognize(path.join(__dirname, '..', 'images', 'testocr.png'));
console.log(text);
await worker.terminate();
})();1. 支持多语言识别
tesseract.js 离线版本默认示例代码只支持识别英文,如果识别中文,结果会是一堆问号。但是幸运的是你可以导入多个训练好的语言模型,让它支持多个语言的识别。
从https://github.com/naptha/tessdata/tree/gh-pages/4.0.0这里下载你需要的对应语言模型,放入到根目录下的lang-data目录下
我这里选择了中(chi_sim.traineddata.gz)日(jpn.traineddata.gz)英(eng.traineddata.gz)三国语言模型。修改代码中加载和初始化模型的语言项配置,来同时支持中日英三国语言。
await worker.loadLanguage('chi_sim+jpn+eng'); await worker.initialize('chi_sim+jpn+eng');
为了方便大家的测试,我在示例的离线版本,已经放入了中日韩三国语言的训练模型和实例代码以及测试图片。
https://github.com/Selenium39/tesseract.js-offline
2. 提高识别性能
如果你运行了离线的版本,你会发现模型的加载和ocr的识别有点慢。可以通过这两个步骤优化。
web项目中,你可以在应用一启动的时候就加载模型,这样后续接收到ocr请求的时候就可以不用等待模型加载了。
参照Why I refactor tesseract.js v2?这篇博客,可以通过
createScheduler方法添加多个worker线程来并发的处理ocr请求。
多线程并发处理ocr请求示例
const Koa = require('koa')
const Router = require('koa-router')
const router = new Router()
const app = new Koa()
const path = require('path')
const moment = require('moment')
const { createWorker, createScheduler } = require('tesseract.js')
;(async () => {
const scheduler = createScheduler()
for (let i = 0; i < 4; i++) {
const worker = createWorker({
langPath: path.join(__dirname, '.', 'lang-data'),
cachePath: path.join(__dirname, '.'),
logger: m => console.log(`${moment().format('YYYY-MM-DD HH:mm:ss')}-${JSON.stringify(m)}`)
})
await worker.load()
await worker.loadLanguage('chi_sim+jpn+eng')
await worker.initialize('chi_sim+jpn+eng')
scheduler.addWorker(worker)
}
app.context.scheduler = scheduler
})()
router.get('/test', async (ctx) => {
const { data: { text } } = await ctx.scheduler.addJob('recognize', path.join(__dirname, '.', 'images', 'chinese.png'))
// await ctx.scheduler.terminate()
ctx.body = text
})
app.use(router.routes(), router.allowedMethods())
app.listen(3002)发起并发请求,可以看到多个worker再并发执行ocr任务
ab -n 4 -c 4 localhost:3002/test
<template>
<div>
<div style="margin-top:30px;height:500px">
<div class="show">
<vueCropper
v-if="imgBase64"
ref="cropper"
:img="imgBase64"
:output-size="option.size"
:output-type="option.outputType"
:info="true"
:full="option.full"
:can-move="option.canMove"
:can-move-box="option.canMoveBox"
:original="option.original"
:auto-crop="option.autoCrop"
:fixed="option.fixed"
:fixed-number="option.fixedNumber"
:center-box="option.centerBox"
:info-true="option.infoTrue"
:fixed-box="option.fixedBox"
:max-img-size="option.maxImgSize"
style="background-image:none"
@mouseenter.native="enter"
@mouseleave.native="leave"
></vueCropper>
<el-upload
v-else
ref="uploader"
class="avatar-uploader"
drag
multiple
action=""
:show-file-list="false"
:limit="1"
:http-request="upload"
>
<i class="el-icon-plus avatar-uploader-icon"></i>
</el-upload>
</div>
<div
class="ocr"
@mouseleave="leaveCard"
>
<el-card
v-for="(item,index) in ocrResult"
:key="index"
class="card-box"
@mouseenter.native="enterCard(item)"
>
<el-form
size="small"
label-width="100px"
label-position="left"
>
<el-form-item label="识别结果">
<el-input v-model="item.text"></el-input>
</el-form-item>
</el-form>
</el-card>
</div>
</div>
<div style="margin-top:10px">
<el-button
size="small"
type="primary"
style="width:60%"
@click="doOcr"
>
文字识别(OCR)
</el-button>
</div>
</div>
</template>
<script>
import { uploadImage, ocr } from '../utils/api'
export default {
name: 'Ocr',
data () {
return {
imgSrc: '',
imgBase64: '',
option: {
info: true, // 裁剪框的大小信息
outputSize: 0.8, // 裁剪生成图片的质量
outputType: 'jpeg', // 裁剪生成图片的格式
canScale: false, // 图片是否允许滚轮缩放
autoCrop: true, // 是否默认生成截图框
fixedBox: false, // 固定截图框大小 不允许改变
fixed: false, // 是否开启截图框宽高固定比例
fixedNumber: [7, 5], // 截图框的宽高比例
full: true, // 是否输出原图比例的截图
canMove: false, // 时候可以移动原图
canMoveBox: true, // 截图框能否拖动
original: false, // 上传图片按照原始比例渲染
centerBox: true, // 截图框是否被限制在图片里面
infoTrue: true, // true 为展示真实输出图片宽高 false 展示看到的截图框宽高
maxImgSize: 10000
},
ocrResult: []
}
},
methods: {
upload (fileObj) {
const file = fileObj.file
const reader = new FileReader()
reader.readAsDataURL(file)
reader.onload = () => {
this.imgBase64 = reader.result
}
const formData = new FormData()
formData.append('image', file)
uploadImage(formData).then(res => {
this.imgUrl = res.imgUrl
})
},
doOcr () {
const cropAxis = this.$refs.cropper.getCropAxis()
const imgAxis = this.$refs.cropper.getImgAxis()
const cropWidth = this.$refs.cropper.cropW
const cropHeight = this.$refs.cropper.cropH
const position = [
(cropAxis.x1 - imgAxis.x1) / this.$refs.cropper.scale,
(cropAxis.y1 - imgAxis.y1) / this.$refs.cropper.scale,
cropWidth / this.$refs.cropper.scale,
cropHeight / this.$refs.cropper.scale
]
const rectangle = {
top: position[1],
left: position[0],
width: position[2],
height: position[3]
}
if (this.imgUrl) {
ocr({ imgUrl: this.imgUrl, rectangle }).then(res => {
this.ocrResult.push(
{
text: res.text,
cropInfo: { //截图框显示的大小
width: cropWidth,
height: cropHeight,
left: cropAxis.x1,
top: cropAxis.y1
},
realInfo: rectangle //截图框在图片上真正的大小
})
})
}
},
enterCard (item) {
this.$refs.cropper.goAutoCrop()// 重新生成自动裁剪框
this.$nextTick(() => {
// if cropped and has position message, update crop box
// 设置自动裁剪框的宽高和位置
this.$refs.cropper.cropOffsertX = item.cropInfo.left
this.$refs.cropper.cropOffsertY = item.cropInfo.top
this.$refs.cropper.cropW = item.cropInfo.width
this.$refs.cropper.cropH = item.cropInfo.height
})
},
leaveCard () {
this.$refs.cropper.clearCrop()
},
enter () {
if (this.imgBase64 === '') {
return
}
this.$refs.cropper.startCrop() // 开始裁剪
},
leave () {
this.$refs.cropper.stopCrop()// 停止裁剪
}
}
}
</script>1. Unterstützung der Mehrsprachenerkennung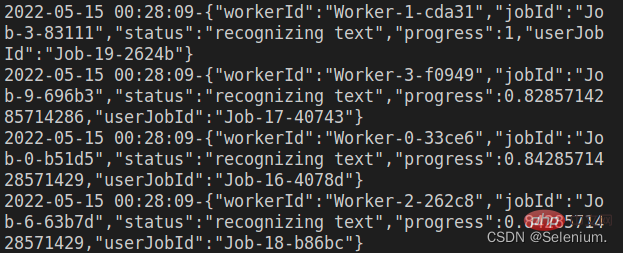
tesseract.js Der Standard-Beispielcode der Offline-Version unterstützt nur die Erkennung von Englisch Das Ergebnis wird eine Menge Fragezeichen sein. Aber glücklicherweise können Sie mehrere trainierte Sprachmodelle importieren, um die Erkennung mehrerer Sprachen zu unterstützen.
Laden Sie das entsprechende Sprachmodell herunter, das Sie benötigen, von https://github.com/naptha/tessdata/tree/gh-pages/4.0.0. Legen Sie es im Verzeichnis lang-data im Stammverzeichnis ab.
Ich habe Chinesisch (chi_sim.traineddata.gz), Japanisch (jpn.traineddata.gz) und Englisch () ausgewählt eng.traineddata.gz) Drei-Länder-Sprachmodell.
https://github.com/Selenium39/tesseract.js-offline
2. Erkennungsleistung verbessernWenn Sie die Offline-Version ausführen, werden Sie feststellen, dass das Laden des Modells und die Erkennung von OCR ein Problem darstellen etwas langsam. Es kann durch diese beiden Schritte optimiert werden. In Webprojekten können Sie das Modell laden, sobald die Anwendung gestartet wird, sodass Sie nicht warten müssen, bis das Modell verfügbar ist geladen, wenn Sie später eine OCR-Anfrage erhalten.
createScheduler mehrere Worker-Threads hinzufügen, um OCR-Anfragen gleichzeitig zu verarbeiten. 🎜Beispiel für die gleichzeitige Multithread-Verarbeitung von OCR-Anfragen🎜rrreee🎜Gleichzeitige Anfragen initiieren, Sie können sehen, wie mehrere Mitarbeiter gleichzeitig OCR-Aufgaben ausführen🎜🎜ab - n 4 -c 4 localhost:3002/test🎜🎜🎜🎜🎜🎜3. Front-End-Code 🎜🎜🎜Der Front-End-Code in der Effektanzeige wird hauptsächlich mit der Elementui-Komponente und dem Vue-Cropper implementiert Komponente. 🎜🎜Vue-Cropper-Komponente Informationen zur spezifischen Verwendung finden Sie in meinem Blog zum Zuschneiden von Vue-Bildern: Verwenden von Vue-Cropper zum Zuschneiden von Bildern🎜🎜🎜PS: 🎜Beim Hochladen von Bildern können Sie zunächst die Base64 des hochgeladenen Bildes im Frontend laden , siehe zuerst Laden Sie das Bild hoch und fordern Sie dann das Backend auf, das Bild hochzuladen, was eine bessere Benutzererfahrung bietet🎜🎜Der vollständige Code lautet wie folgt🎜rrreee🎜Weitere knotenbezogene Kenntnisse finden Sie unter: 🎜nodejs-Tutorial🎜! 🎜Das obige ist der detaillierte Inhalt vonEine kurze Analyse, wie Node OCR implementiert. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
52

 Ist NodeJS ein Backend-Framework?
Apr 21, 2024 am 05:09 AM
Ist NodeJS ein Backend-Framework?
Apr 21, 2024 am 05:09 AM
Node.js kann als Backend-Framework verwendet werden, da es Funktionen wie hohe Leistung, Skalierbarkeit, plattformübergreifende Unterstützung, ein umfangreiches Ökosystem und einfache Entwicklung bietet.
 So verbinden Sie NodeJS mit der MySQL-Datenbank
Apr 21, 2024 am 06:13 AM
So verbinden Sie NodeJS mit der MySQL-Datenbank
Apr 21, 2024 am 06:13 AM
Um eine Verbindung zu einer MySQL-Datenbank herzustellen, müssen Sie die folgenden Schritte ausführen: Installieren Sie den MySQL2-Treiber. Verwenden Sie mysql2.createConnection(), um ein Verbindungsobjekt zu erstellen, das die Hostadresse, den Port, den Benutzernamen, das Passwort und den Datenbanknamen enthält. Verwenden Sie „connection.query()“, um Abfragen durchzuführen. Verwenden Sie abschließend Connection.end(), um die Verbindung zu beenden.
 Was sind die globalen Variablen in NodeJS?
Apr 21, 2024 am 04:54 AM
Was sind die globalen Variablen in NodeJS?
Apr 21, 2024 am 04:54 AM
Die folgenden globalen Variablen sind in Node.js vorhanden: Globales Objekt: global Kernmodul: Prozess, Konsole, erforderlich Laufzeitumgebungsvariablen: __dirname, __filename, __line, __column Konstanten: undefiniert, null, NaN, Infinity, -Infinity
 Was ist der Unterschied zwischen den Dateien npm und npm.cmd im Installationsverzeichnis von nodejs?
Apr 21, 2024 am 05:18 AM
Was ist der Unterschied zwischen den Dateien npm und npm.cmd im Installationsverzeichnis von nodejs?
Apr 21, 2024 am 05:18 AM
Es gibt zwei npm-bezogene Dateien im Node.js-Installationsverzeichnis: npm und npm.cmd. Die Unterschiede sind wie folgt: unterschiedliche Erweiterungen: npm ist eine ausführbare Datei und npm.cmd ist eine Befehlsfensterverknüpfung. Windows-Benutzer: npm.cmd kann über die Eingabeaufforderung verwendet werden, npm kann nur über die Befehlszeile ausgeführt werden. Kompatibilität: npm.cmd ist spezifisch für Windows-Systeme, npm ist plattformübergreifend verfügbar. Nutzungsempfehlungen: Windows-Benutzer verwenden npm.cmd, andere Betriebssysteme verwenden npm.
 PI -Knotenunterricht: Was ist ein PI -Knoten? Wie installiere und richte ich einen PI -Knoten ein?
Mar 05, 2025 pm 05:57 PM
PI -Knotenunterricht: Was ist ein PI -Knoten? Wie installiere und richte ich einen PI -Knoten ein?
Mar 05, 2025 pm 05:57 PM
Detaillierte Erläuterungs- und Installationshandbuch für Pinetwork -Knoten In diesem Artikel wird das Pinetwork -Ökosystem im Detail vorgestellt - PI -Knoten, eine Schlüsselrolle im Pinetwork -Ökosystem und vollständige Schritte für die Installation und Konfiguration. Nach dem Start des Pinetwork -Blockchain -Testnetzes sind PI -Knoten zu einem wichtigen Bestandteil vieler Pioniere geworden, die aktiv an den Tests teilnehmen und sich auf die bevorstehende Hauptnetzwerkveröffentlichung vorbereiten. Wenn Sie Pinetwork noch nicht kennen, wenden Sie sich bitte an was Picoin ist? Was ist der Preis für die Auflistung? PI -Nutzung, Bergbau und Sicherheitsanalyse. Was ist Pinetwork? Das Pinetwork -Projekt begann 2019 und besitzt seine exklusive Kryptowährung PI -Münze. Das Projekt zielt darauf ab, eine zu erstellen, an der jeder teilnehmen kann
 Gibt es einen großen Unterschied zwischen NodeJS und Java?
Apr 21, 2024 am 06:12 AM
Gibt es einen großen Unterschied zwischen NodeJS und Java?
Apr 21, 2024 am 06:12 AM
Die Hauptunterschiede zwischen Node.js und Java sind Design und Funktionen: Ereignisgesteuert vs. Thread-gesteuert: Node.js ist ereignisgesteuert und Java ist Thread-gesteuert. Single-Threaded vs. Multi-Threaded: Node.js verwendet eine Single-Threaded-Ereignisschleife und Java verwendet eine Multithread-Architektur. Laufzeitumgebung: Node.js läuft auf der V8-JavaScript-Engine, während Java auf der JVM läuft. Syntax: Node.js verwendet JavaScript-Syntax, während Java Java-Syntax verwendet. Zweck: Node.js eignet sich für I/O-intensive Aufgaben, während Java für große Unternehmensanwendungen geeignet ist.
 Ist NodeJS eine Back-End-Entwicklungssprache?
Apr 21, 2024 am 05:09 AM
Ist NodeJS eine Back-End-Entwicklungssprache?
Apr 21, 2024 am 05:09 AM
Ja, Node.js ist eine Backend-Entwicklungssprache. Es wird für die Back-End-Entwicklung verwendet, einschließlich der Handhabung serverseitiger Geschäftslogik, der Verwaltung von Datenbankverbindungen und der Bereitstellung von APIs.
 So stellen Sie das NodeJS-Projekt auf dem Server bereit
Apr 21, 2024 am 04:40 AM
So stellen Sie das NodeJS-Projekt auf dem Server bereit
Apr 21, 2024 am 04:40 AM
Serverbereitstellungsschritte für ein Node.js-Projekt: Bereiten Sie die Bereitstellungsumgebung vor: Erhalten Sie Serverzugriff, installieren Sie Node.js, richten Sie ein Git-Repository ein. Erstellen Sie die Anwendung: Verwenden Sie npm run build, um bereitstellbaren Code und Abhängigkeiten zu generieren. Code auf den Server hochladen: über Git oder File Transfer Protocol. Abhängigkeiten installieren: Stellen Sie eine SSH-Verbindung zum Server her und installieren Sie Anwendungsabhängigkeiten mit npm install. Starten Sie die Anwendung: Verwenden Sie einen Befehl wie node index.js, um die Anwendung zu starten, oder verwenden Sie einen Prozessmanager wie pm2. Konfigurieren Sie einen Reverse-Proxy (optional): Verwenden Sie einen Reverse-Proxy wie Nginx oder Apache, um den Datenverkehr an Ihre Anwendung weiterzuleiten
