

So lösen Sie Redis-Cache-Lawine, -Ausfall und -Penetration

Dieser Artikel vermittelt Ihnen relevantes Wissen über Redis und stellt vor allem vor, wie Sie die Probleme im Zusammenhang mit Redis-Cache-Lawine lösen können. Cache-Lawine bedeutet, dass eine große Anzahl von Anfragen den Cache in Redis nicht erreichen kann Das heißt, die Daten können nicht in Redis gefunden werden. Werfen wir einen Blick darauf. Ich hoffe, dass sie für alle hilfreich sind.

Empfohlenes Lernen: Redis-Video-Tutorial
1. Cache-Lawine
1. Was ist Cache-Lawine?
Cache-Lawine bedeutet, dass eine große Anzahl von Anfragen die zwischengespeicherten Daten in Redis nicht erreichen kann, d. h. die Daten können nicht in Redisgefunden werden >, dann Das Geschäftssystem kann nur die Datenbank abfragen, wodurch alle Anforderungen an die Datenbank gesendet werden. Wie im Bild unten gezeigt: 缓存雪崩是指大量的请求无法命中Redis中的缓存数据,也就是在Redis找不到数据了,那业务系统只能到数据库中查询,进而导致所有的请求都发送到了数据库。如下图所示:

数据库并不像Redis能处理大量请求,由缓存雪崩导致的请求激增必须会导致数据库所在宕机,这样势必会影响业务系统,所以如果发生缓存雪崩,对于业务系统肯定是致命的。
2. 为什么发会生缓存雪崩?
什么情况下出现缓存雪崩呢?总结起来有以下两个方面的原因:
大量
Redis缓存数据同时过期,导致所有的发送到Redis请求都无法命中数据,只能到数据库中进行查询。Redis服务器宕机,所有请求都无法经Redis来处理,只能转向数据库查询数据。
3. 如何避免缓存雪崩?
针对导致缓存雪崩的原因,有不同的解决方法:
针对大量缓存随机过期时间,解决方法就是在原始过期时间的基础上,再加一个随机过期时间,比如1到5分钟之间的随机过期时间,这样可以避免大量的缓存数据在同一时间过期。
而针对
Redis解决宕机的导致的缓存雪崩,可以提前搭建好Redis的主从服务器进行数据同步,并配置哨兵机制,这样在Redis服务器因为宕机而无法提供服务时,可以由哨兵将Redis从服务器设置为主服务器,继续提供服务。
二、缓存击穿
1. 什么是缓存击穿
缓存击穿与缓存雪崩的情况相似,雪崩是因为大量的数据过期,而缓存击穿则是指热点数据过期,所有针对热点数据的请求都需要到数据库中进行处理,如下图所示:

2. 怎么避免缓存击穿?
解决缓存击穿的三种方式:
- 不设置过期时间
如果我们能提前知道某个数据是热点数据,那么就可以不设置这些数据的过期,从而避免缓存击穿问题,比如一些秒杀活动的商品,在秒杀时会大量用户访问,这时候我们就可以将这些用于秒杀的商品数据提前写入缓存并且不设置过期时间。
- 互斥锁
提前知道某些数据会有大量访问,我们当然可以设置不过期,但更多时候,我们并不能提前预知,这种情况要怎么处理呢?
我们来分析一下缓存击穿的情况:
正常情况下,当某个Redis缓存数据过期时,如果有对该数据的请求,则重新到数据库中查询并再写入缓存,让后续的请求可以命中该缓存而无须再去数据库中查询。
而热点数据过期时,由于大量请求,当某个请求无法命中缓存时,会去查询数据库并重新把数据写入Redis,也就是在写入Redis之前,其他请求进来,也会去查询数据库。
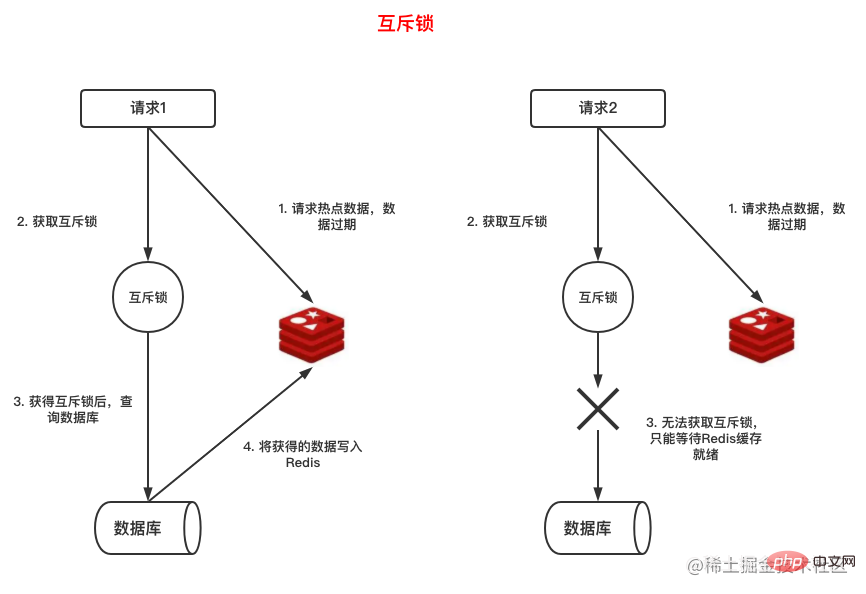
好了,我们知道热点数据过期后,很多请求会去查询数据库,那么我们可以给去查询数据库的业务逻辑加个互斥锁,只有获得锁的请求才能去查询数据库并把数据写回Redis
Die Datenbank ist nicht wie
Redis, das eine große Anzahl von Anfragen verarbeiten kann. Der durch die Cache-Lawine verursachte Anstieg der Anfragen führt definitiv zum Ausfall der Datenbank, was sich unweigerlich auf das Geschäftssystem auswirkt. Wenn also eine Cache-Lawine auftritt, hat dies definitiv schwerwiegende Auswirkungen auf das Geschäftssystem.
2. Warum kommt es zu einer Cache-Lawine?  Unter welchen Umständen kommt es zu einer Cache-Lawine? Zusammenfassend gibt es zwei Gründe: 🎜
Unter welchen Umständen kommt es zu einer Cache-Lawine? Zusammenfassend gibt es zwei Gründe: 🎜
- 🎜Eine große Anzahl von
Redis zwischengespeicherten Daten ist gleichzeitig abgelaufen, was dazu geführt hat, dass alle Anfragen an Redis gesendet wurden Um die Daten nicht zu treffen, kann sie nur in der Datenbank abgefragt werden. 🎜
- 🎜Der
Redis-Server ist ausgefallen, alle Anfragen können nicht von Redis verarbeitet werden und können nur zur Datenabfrage an die Datenbank weitergeleitet werden. 🎜
3. Wie vermeide ich eine Cache-Lawine? 🎜🎜Es gibt verschiedene Lösungen für die Ursachen einer Cache-Lawine: 🎜
- 🎜Für eine große Anzahl zufälliger Cache-Ablaufzeiten besteht die Lösung darin, der ursprünglichen Ablaufzeit eine zufällige Ablaufzeit hinzuzufügen, z. B. 1 Zufall Ablaufzeit zwischen 5 Minuten, um zu verhindern, dass eine große Menge zwischengespeicherter Daten gleichzeitig abläuft. 🎜
- 🎜Um die durch die Ausfallzeit von
Redis verursachte Cache-Lawine zu beheben, können Sie den Master-Slave-Server von Redis im Voraus für Daten einrichten Synchronisieren und konfigurieren Sie den Sentinel-Mechanismus, sodass der Sentinel den Redis-Slave-Server auf den Master-Server setzen und damit fortfahren kann, wenn der Redis-Server aufgrund von Ausfallzeiten keine Dienste bereitstellen kann Dienstleistungen erbringen. 🎜
2. Cache-Ausfall 🎜1 Was ist ein Cache-Ausfall 🎜🎜Cache-Ausfall Die Lawine ähnelt der Cache-Lawine. Die Lawine ist auf den Ablauf einer großen Datenmenge zurückzuführen, während sich die Cache-Aufschlüsselung auf den Ablauf von Hotspot-Daten bezieht. Alle Anfragen nach Hotspot-Daten müssen in der Datenbank verarbeitet werden Folgende Abbildung: 🎜🎜🎜2. Wie vermeide ich einen Cache-Ausfall? 🎜🎜Drei Möglichkeiten, einen Cache-Fehler zu beheben: 🎜- Legen Sie keine Ablaufzeit fest
🎜Wenn wir im Voraus wissen können, dass es sich bei bestimmten Daten um heiße Daten handelt, müssen wir sie nicht festlegen Diese Daten laufen ab, wodurch das Problem der Cache-Aufschlüsselung vermieden wird. Auf einige Produkte im Flash-Sale wird beispielsweise während des Flash-Sales zugegriffen. Zu diesem Zeitpunkt können wir die Produktdaten für Flash-Sale in den Cache schreiben Vorlauf und legen Sie keine Ablaufzeit fest. 🎜- Mutex-Sperre
🎜Da wir im Voraus wissen, dass auf bestimmte Daten in großen Mengen zugegriffen wird, können wir sie natürlich so einstellen, dass sie nicht ablaufen, aber in den meisten Fällen können wir das nicht vorhersagen diese Situation im Voraus Wie gehe ich damit um? 🎜🎜Lassen Sie uns die Situation des Cache-Ausfalls analysieren: 🎜🎜Unter normalen Umständen, wenn bestimmte zwischengespeicherte Daten von Redis ablaufen und eine Anforderung für die Daten vorliegt, wird die Datenbank erneut abgefragt und dann geschrieben den Cache, sodass nachfolgende Anfragen den Cache erreichen können, ohne die Datenbank abzufragen. 🎜🎜Wenn die Hotspot-Daten aufgrund einer großen Anzahl von Anfragen ablaufen und eine Anfrage den Cache nicht erreichen kann, wird die Datenbank abgefragt und die Daten werden erneut in Redis geschrieben Schreiben von Redis Bevor andere Anfragen eingehen, wird auch die Datenbank abgefragt. 🎜🎜Okay, wir wissen, dass nach Ablauf der Hotspot-Daten viele Anfragen die Datenbank abfragen, sodass wir der Geschäftslogik zum Abfragen der Datenbank eine Mutex-Sperre hinzufügen können. Nur Anfragen, die die Sperre erhalten, können die Datenbank abfragen und die Daten schreiben backRedis, während andere Anfragen, die die Sperre nicht erhalten haben, nur warten können, bis die Daten bereit sind. 🎜🎜Die oben genannten Schritte sind im Bild unten dargestellt: 🎜🎜🎜🎜- Legen Sie die logische Ablaufzeit fest
 Unter welchen Umständen kommt es zu einer Cache-Lawine? Zusammenfassend gibt es zwei Gründe: 🎜
Unter welchen Umständen kommt es zu einer Cache-Lawine? Zusammenfassend gibt es zwei Gründe: 🎜Redis zwischengespeicherten Daten ist gleichzeitig abgelaufen, was dazu geführt hat, dass alle Anfragen an Redis gesendet wurden Um die Daten nicht zu treffen, kann sie nur in der Datenbank abgefragt werden. 🎜Redis-Server ist ausgefallen, alle Anfragen können nicht von Redis verarbeitet werden und können nur zur Datenabfrage an die Datenbank weitergeleitet werden. 🎜- 🎜Für eine große Anzahl zufälliger Cache-Ablaufzeiten besteht die Lösung darin, der ursprünglichen Ablaufzeit eine zufällige Ablaufzeit hinzuzufügen, z. B. 1 Zufall Ablaufzeit zwischen 5 Minuten, um zu verhindern, dass eine große Menge zwischengespeicherter Daten gleichzeitig abläuft. 🎜
- 🎜Um die durch die Ausfallzeit von
Redisverursachte Cache-Lawine zu beheben, können Sie den Master-Slave-Server vonRedisim Voraus für Daten einrichten Synchronisieren und konfigurieren Sie den Sentinel-Mechanismus, sodass der Sentinel denRedis-Slave-Server auf den Master-Server setzen und damit fortfahren kann, wenn derRedis-Server aufgrund von Ausfallzeiten keine Dienste bereitstellen kann Dienstleistungen erbringen. 🎜
2. Cache-Ausfall 🎜1 Was ist ein Cache-Ausfall 🎜🎜Cache-Ausfall Die Lawine ähnelt der Cache-Lawine. Die Lawine ist auf den Ablauf einer großen Datenmenge zurückzuführen, während sich die Cache-Aufschlüsselung auf den Ablauf von Hotspot-Daten bezieht. Alle Anfragen nach Hotspot-Daten müssen in der Datenbank verarbeitet werden Folgende Abbildung: 🎜🎜🎜2. Wie vermeide ich einen Cache-Ausfall? 🎜🎜Drei Möglichkeiten, einen Cache-Fehler zu beheben: 🎜- Legen Sie keine Ablaufzeit fest
🎜Wenn wir im Voraus wissen können, dass es sich bei bestimmten Daten um heiße Daten handelt, müssen wir sie nicht festlegen Diese Daten laufen ab, wodurch das Problem der Cache-Aufschlüsselung vermieden wird. Auf einige Produkte im Flash-Sale wird beispielsweise während des Flash-Sales zugegriffen. Zu diesem Zeitpunkt können wir die Produktdaten für Flash-Sale in den Cache schreiben Vorlauf und legen Sie keine Ablaufzeit fest. 🎜- Mutex-Sperre
🎜Da wir im Voraus wissen, dass auf bestimmte Daten in großen Mengen zugegriffen wird, können wir sie natürlich so einstellen, dass sie nicht ablaufen, aber in den meisten Fällen können wir das nicht vorhersagen diese Situation im Voraus Wie gehe ich damit um? 🎜🎜Lassen Sie uns die Situation des Cache-Ausfalls analysieren: 🎜🎜Unter normalen Umständen, wenn bestimmte zwischengespeicherte Daten von Redis ablaufen und eine Anforderung für die Daten vorliegt, wird die Datenbank erneut abgefragt und dann geschrieben den Cache, sodass nachfolgende Anfragen den Cache erreichen können, ohne die Datenbank abzufragen. 🎜🎜Wenn die Hotspot-Daten aufgrund einer großen Anzahl von Anfragen ablaufen und eine Anfrage den Cache nicht erreichen kann, wird die Datenbank abgefragt und die Daten werden erneut in Redis geschrieben Schreiben von Redis Bevor andere Anfragen eingehen, wird auch die Datenbank abgefragt. 🎜🎜Okay, wir wissen, dass nach Ablauf der Hotspot-Daten viele Anfragen die Datenbank abfragen, sodass wir der Geschäftslogik zum Abfragen der Datenbank eine Mutex-Sperre hinzufügen können. Nur Anfragen, die die Sperre erhalten, können die Datenbank abfragen und die Daten schreiben backRedis, während andere Anfragen, die die Sperre nicht erhalten haben, nur warten können, bis die Daten bereit sind. 🎜🎜Die oben genannten Schritte sind im Bild unten dargestellt: 🎜🎜🎜🎜- Legen Sie die logische Ablaufzeit fest
🎜2. Wie vermeide ich einen Cache-Ausfall? 🎜🎜Drei Möglichkeiten, einen Cache-Fehler zu beheben: 🎜- Legen Sie keine Ablaufzeit fest
🎜Wenn wir im Voraus wissen können, dass es sich bei bestimmten Daten um heiße Daten handelt, müssen wir sie nicht festlegen Diese Daten laufen ab, wodurch das Problem der Cache-Aufschlüsselung vermieden wird. Auf einige Produkte im Flash-Sale wird beispielsweise während des Flash-Sales zugegriffen. Zu diesem Zeitpunkt können wir die Produktdaten für Flash-Sale in den Cache schreiben Vorlauf und legen Sie keine Ablaufzeit fest. 🎜- Mutex-Sperre
🎜Da wir im Voraus wissen, dass auf bestimmte Daten in großen Mengen zugegriffen wird, können wir sie natürlich so einstellen, dass sie nicht ablaufen, aber in den meisten Fällen können wir das nicht vorhersagen diese Situation im Voraus Wie gehe ich damit um? 🎜🎜Lassen Sie uns die Situation des Cache-Ausfalls analysieren: 🎜🎜Unter normalen Umständen, wenn bestimmte zwischengespeicherte Daten von Redis ablaufen und eine Anforderung für die Daten vorliegt, wird die Datenbank erneut abgefragt und dann geschrieben den Cache, sodass nachfolgende Anfragen den Cache erreichen können, ohne die Datenbank abzufragen. 🎜🎜Wenn die Hotspot-Daten aufgrund einer großen Anzahl von Anfragen ablaufen und eine Anfrage den Cache nicht erreichen kann, wird die Datenbank abgefragt und die Daten werden erneut in Redis geschrieben Schreiben von Redis Bevor andere Anfragen eingehen, wird auch die Datenbank abgefragt. 🎜🎜Okay, wir wissen, dass nach Ablauf der Hotspot-Daten viele Anfragen die Datenbank abfragen, sodass wir der Geschäftslogik zum Abfragen der Datenbank eine Mutex-Sperre hinzufügen können. Nur Anfragen, die die Sperre erhalten, können die Datenbank abfragen und die Daten schreiben backRedis, während andere Anfragen, die die Sperre nicht erhalten haben, nur warten können, bis die Daten bereit sind. 🎜🎜Die oben genannten Schritte sind im Bild unten dargestellt: 🎜🎜🎜🎜- Legen Sie die logische Ablaufzeit fest
Obwohl die Verwendung einer Mutex-Sperre das Cache-Aufschlüsselungsproblem sehr einfach lösen kann, werden Anforderungen, die die Sperre nicht erhalten, in die Warteschlange gestellt und warten, was sich auf die Leistung des Systems auswirkt. Es gibt einen anderen Weg zur Lösung Das Problem der Cache-Aufschlüsselung besteht darin, den Geschäftsdaten eine Ablaufzeit hinzuzufügen. In den folgenden Daten haben wir beispielsweise das Feld expire_at hinzugefügt, um die Ablaufzeit der Daten anzugeben. expire_at字段用于表示数据过期时间。
{"name":"test","expire_at":"1599999999"}复制代码这种方式的实现过程如下图所示:
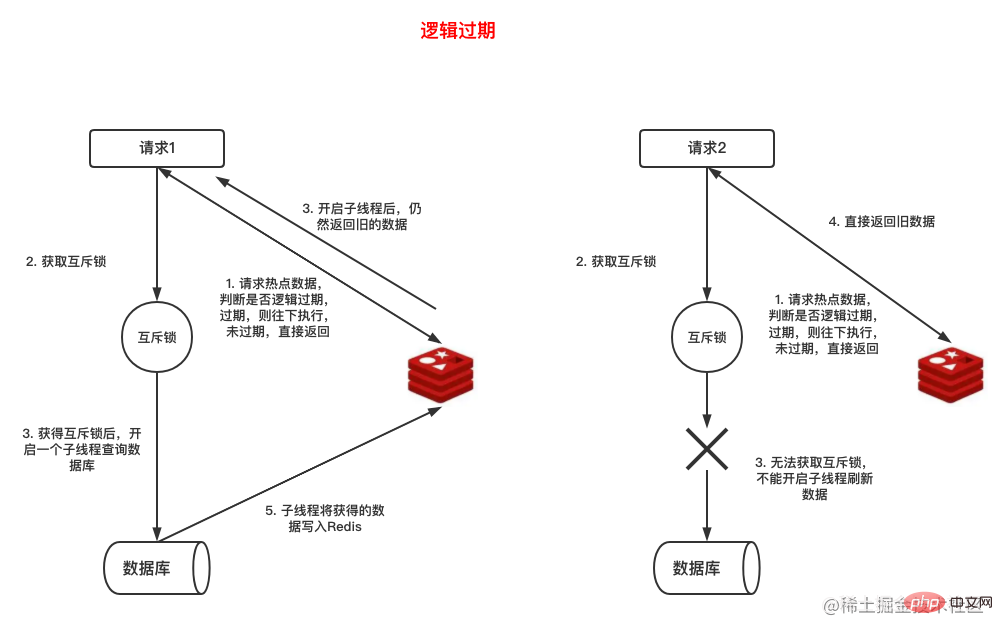
缓存中的热点数据中冗余一个逻辑过期时间,但数据在Redis不设置过期时间
当一个请求拿到Redis中的数据时,判断逻辑过期时间是否到期,如果没有到期,直接返回,如果到期则开启另一个线程获得锁后去查询数据库并将查询的最新数据写回Redis,而当前请求返回已经查询的数据。
三、缓存穿透
1. 什么是缓存穿透
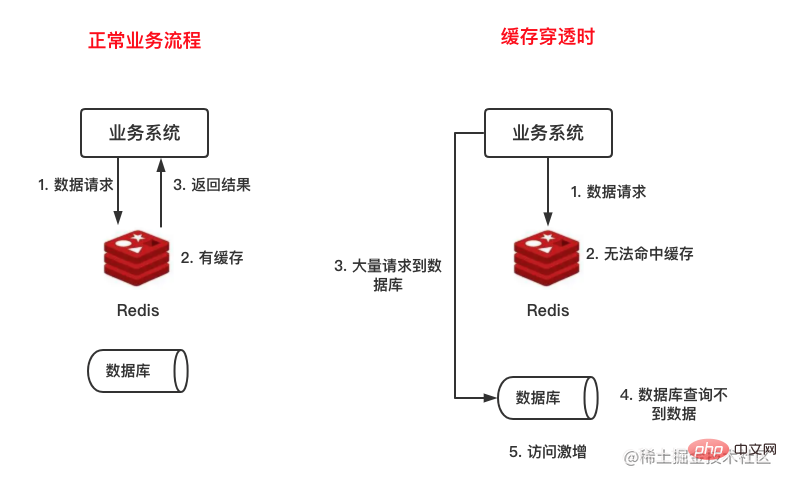
缓存穿透是指要查找的数据既不在缓存当中,也不在数据库中,因为不在缓存中,所以请求一定会到达数据库,Redis缓存形同虚设,如下图所示:
2. 为什么会发生缓存穿透
什么条件下会发生缓存穿透呢?主要有以下三种情况:
用户恶意攻击请求
误操作把
Redis和数据库里的数据删除了用户还未产生内容时,比如用户的文章列表,用户还未写文章,所以缓存和数据库都没有数据
3. 如何避免缓存穿透?
a. 缓存空值或缺省值
当在Redis缓存中查询不到数据时,再从数据库查询,如果同样没有数据,就直接缓存一个空间或缺省值,这样可以避免下次再去查询数据库;不过为了防止之后已经数据库已经相应数据库,再返回空值问题,应该为缓存设置过期时间,或者在产生数据时直接清除对应的缓存空值。
b. 布隆过滤器
虽然缓存空值可以解决缓存穿透问题,但仍然需要查询一次数据库才能确定是否有数据,如果有用户恶意攻击,高并发地使用系统不存在的数据id进行查询,所有的查询都要经过数据库,这样仍然会给数据库带来很大的压力。
所以,有没有不用查询数据库就能确定数据是否存在的办法呢?有的,用布隆过滤器。
布隆过滤器主要是两个部分:bit数组+N个哈希函数,其原理为:
使用N个哈希函数对所要标记的数据进行哈希值计算。
将计算到的哈希值对bit数组的长度取模,这样可以得到每个哈希值在bit数组的位置。
把bit数组中对应的位置标记为1。
下面是布隆过滤器原理示意图:

当要进行数据写入时,执行述述步骤,计算对应bit数组位置并标识为1,那么在执行查询时,就能查询该数据是否存在了。
另外,由于哈希碰撞问题导致的误差,所以不存在的数据经过布隆过滤器后,会被判定为存在,再去查数据库,不过哈希碰到的概率很小,用布隆过滤器已经能帮我们拦截大部分的穿透请求了。
Redis本身就支持布隆过滤器,所以我们可以直接使用Redis布隆过滤器,而不用自己去实现,非常方便。
四、小结
缓存的雪崩、击穿、穿透是在业务应用缓存时经常会碰到的缓存异常问题,其原因与解决方法如以下表示所示:
| 问题 | 原因 | 解决方法 |
|---|---|---|
| 缓存雪崩 | 大量数据过期或Redis服务器宕机 |
1. 随机过期时间 2. 主从+哨兵的集群 |
| 缓存击穿 | 热点数据过期 | 1. 不设置过期时间 2. 加互斥锁 3. 冗余逻辑过期时间 |
| 缓存穿透 | 请求数据库和Redisrrreee | Der Implementierungsprozess dieser Methode ist in der folgenden Abbildung dargestellt:
Bei einer Anfrage Ruft Redis ab und ermittelt, ob die logische Ablaufzeit abgelaufen ist. Wenn sie abgelaufen ist, starten Sie einen anderen Thread, um die Sperre zu erhalten, fragen Sie die Datenbank ab und schreiben Sie die neuesten abgefragten Daten Zurück zu <code>Redis und die aktuelle Anfrage gibt die abgefragten Daten zurück. 3. Cache-Penetration
1. Was ist Cache-Penetration?
Cache-Penetration ist das Die zu findenden Daten befinden sich weder im Cache noch in der Datenbank. Da sie sich nicht im Cache befinden, ist der Redis-Cache definitiv nutzlos :
🎜2. Warum kommt es zu einer Cache-Penetration
🎜Unter welchen Bedingungen kommt es zu einer Cache-Penetration? Es gibt hauptsächlich die folgenden drei Situationen: 🎜🎜🎜🎜Böswillige Angriffsanforderung durch den Benutzer🎜🎜🎜🎜Fehlbedienung zum Löschen vonRedis und den Daten in der Datenbank🎜🎜🎜🎜Wenn der Benutzer noch keine Generierung vorgenommen hat Inhalt, z. B. der Benutzer Die Artikelliste, der Benutzer hat noch keinen Artikel geschrieben, daher sind keine Daten im Cache und in der Datenbank vorhanden 🎜🎜🎜3 So vermeiden Sie Cache Penetration?
a. Leerer Wert oder Standardwert im Cache
🎜Wenn die Daten nicht imRedis-Cache abgefragt werden können, rufen Sie sie ab Wenn bei Datenbankabfragen keine Daten vorhanden sind, wird einfach ein Leerzeichen oder ein Standardwert direkt zwischengespeichert, um die nächste Abfrage der Datenbank zu vermeiden und das Problem der Rückgabe von Nullwerten zu vermeiden, wenn die Datenbank bereits korrespondiert Für die Datenbank sollte die Ablaufzeit für den Cache festgelegt oder der entsprechende Cache-Nullwert beim Generieren von Daten direkt gelöscht werden. 🎜b. Bloom-Filter
🎜Obwohl das Caching von Nullwerten das Problem der Cache-Penetration lösen kann, muss die Datenbank dennoch einmal abgefragt werden, um festzustellen, ob Daten vorhanden sind. Bei böswilligen Angriffen eines Benutzers werden Daten-IDs verwendet, die nicht im System vorhanden sind, um mit hoher Parallelität abzufragen. Alle Abfragen müssen über die Datenbank erfolgen, was die Datenbank dennoch stark belastet. 🎜🎜Gibt es also eine Möglichkeit festzustellen, ob die Daten vorhanden sind, ohne die Datenbank abzufragen? Ja, verwenden Sie denBloom-Filter. 🎜🎜Der Bloom-Filter besteht hauptsächlich aus zwei Teilen: Bit-Array + N Hash-Funktionen. Sein Prinzip ist: 🎜🎜🎜🎜Verwenden Sie N Hash-Funktionen, um den Hash-Wert der zu markierenden Daten zu berechnen. 🎜🎜🎜🎜 Nehmen Sie den berechneten Hash-Wert modulo zur Länge des Bit-Arrays, sodass die Position jedes Hash-Werts im Bit-Array ermittelt werden kann. 🎜🎜🎜🎜 Markieren Sie die entsprechende Position im Bit-Array als 1. 🎜🎜🎜🎜Das Folgende ist ein schematisches Diagramm des Bloom-Filterprinzips: 🎜🎜🎜🎜Wenn Daten geschrieben werden sollen, führen Sie die oben beschriebenen Schritte aus, berechnen Sie die entsprechende Bit-Array-Position und markieren Sie sie als 1. Anschließend können Sie beim Ausführen der Abfrage abfragen, ob die Daten vorhanden sind . 🎜🎜Darüber hinaus werden aufgrund von Fehlern, die durch Hash-Kollisionsprobleme verursacht werden, nicht vorhandene Daten nach dem Durchlaufen des Bloom-Filters als vorhanden beurteilt und dann die Datenbank überprüft. Da die Wahrscheinlichkeit einer Hash-Begegnung jedoch sehr gering ist, verwenden Sie daher Bloom Filter Der Server kann uns bereits dabei helfen, die meisten Penetrationsanfragen abzufangen. 🎜🎜Redis selbst unterstützt Bloom-Filter, sodass wir Redis Bloom-Filter direkt verwenden können, ohne sie selbst implementieren zu müssen, was sehr praktisch ist. 🎜IV. Zusammenfassung
🎜Cache-Lawine, -Ausfall und -Penetration sind Cache-Ausnahmeprobleme, die beim Caching von Geschäftsanwendungen häufig auftreten. Ihre Ursachen und Lösungen werden im Folgenden gezeigt Darstellung: 🎜| Problem | Ursache | Lösung | 🎜
|---|---|---|
Das obige ist der detaillierte Inhalt vonSo lösen Sie Redis-Cache-Lawine, -Ausfall und -Penetration. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
Um die Operationen zu sperren, muss die Sperre durch den Befehl setNX erfasst werden und dann den Befehl Ablauf verwenden, um die Ablaufzeit festzulegen. Die spezifischen Schritte sind: (1) Verwenden Sie den Befehl setNX, um zu versuchen, ein Schlüsselwertpaar festzulegen; (2) Verwenden Sie den Befehl Ablauf, um die Ablaufzeit für die Sperre festzulegen. (3) Verwenden Sie den Befehl Del, um die Sperre zu löschen, wenn die Sperre nicht mehr benötigt wird.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So erstellen Sie Message Middleware für Redis
Apr 10, 2025 pm 07:51 PM
So erstellen Sie Message Middleware für Redis
Apr 10, 2025 pm 07:51 PM
Redis unterstützt als Messing Middleware Modelle für Produktionsverbrauch, kann Nachrichten bestehen und eine zuverlässige Lieferung sicherstellen. Die Verwendung von Redis als Message Middleware ermöglicht eine geringe Latenz, zuverlässige und skalierbare Nachrichten.
