
Dieser Artikel bringt Ihnen relevantes Wissen über Redis, das hauptsächlich den relevanten Inhalt zur Persistenzstrategie vorstellt. RDB-Persistenz bezieht sich auf das Schreiben eines Snapshots des Datensatzes im Speicher innerhalb eines bestimmten Zeitintervalls. Ich hoffe, es wird für alle hilfreich sein.

Empfohlenes Lernen: Redis-Video-Tutorial
Redis (Remote Dictionary Server), der Remote-Wörterbuchdienst, ist ein Open-Source-Speicher-Cache-Datenspeicherdienst. Es ist in der Sprache ANSI C geschrieben, unterstützt netzwerkbasierte, speicherbasierte und persistente Protokolldatenspeicherung und bietet APIs in mehreren Sprachen.
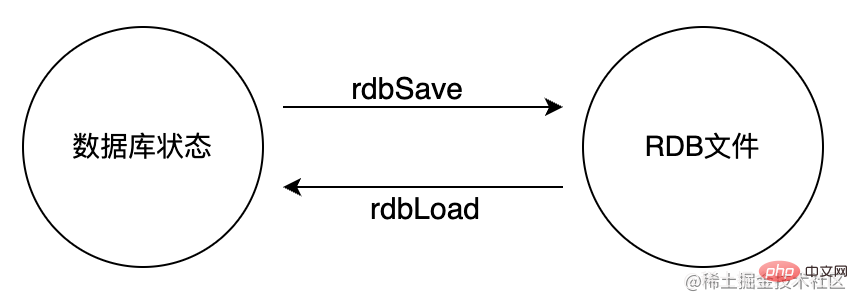
Redis ist eine In-Memory-Datenbank, und Daten werden im Speicher gespeichert Um einen dauerhaften Datenverlust durch Prozessbeendigung zu vermeiden, müssen die Daten in Redis regelmäßig in irgendeiner Form (Daten oder Befehle) aus dem Speicher auf der Festplatte gespeichert werden. Verwenden Sie beim nächsten Neustart von Redis persistente Dateien, um eine Datenwiederherstellung zu erreichen. Darüber hinaus können persistente Dateien für Notfallsicherungszwecke an einen Remote-Standort kopiert werden. Es gibt zwei Persistenzmechanismen von Redis:
RDB speichert die aktuellen Daten auf der Festplatte und AOF speichert die aktuellen Daten jedes Mal auf die Festplatte Die ausgeführten Schreibbefehle werden auf der Festplatte gespeichert (ähnlich wie bei MySQLs Binlog). AOF-Persistenz bietet eine bessere Echtzeitleistung, d. h. es gehen weniger Daten verloren, wenn der Prozess unerwartet beendet wird.
RDB ( RedisData Base) bezieht sich auf das Schreiben eines Snapshots des Datensatzes im Speicher auf die Festplatte innerhalb eines bestimmten Zeitintervalls. RDB ist werden in Form von Speicher-Snapshots (binär serialisierte Form von Speicherdaten) gespeichert. Jedes Mal wird von Redis ein Snapshot generiert, um die Daten vollständig zu sichern.
Vorteile:
Nachteile:
Standardmäßig speichert Redis den Datenbank-Snapshot in einer Binärdatei mit dem Namen dump.rdb. Die RDB-Dateistruktur besteht aus fünf Teilen:
(1) REDIS Konstantenzeichenfolge mit einer Länge von 5 Bytes. REDIS 常量字符串。
(2)4字节的 db_version,标识 RDB 文件版本。
(3)databases:不定长度,包含零个或多个数据库,以及各数据库中的键值对数据。
(4)1字节的 EOF 常量,表示文件正文内容结束。
(5)check_sum: 8字节长的无符号整数,保存校验和。

数据结构举例,以下是数据库[0]和数据库[3]有数据的情况:

手动指令触发
手动触发 RDB 持久化的方式可以使用 save 命令和 bgsave 命令,这两个命令的区别如下:
save:执行 save 指令,阻塞 Redis 的其他操作,会导致 Redis 无法响应客户端请求,不建议使用。
bgsave:执行 bgsave 指令,Redis 后台创建子进程,异步进行快照的保存操作,此时 Redis 仍然能响应客户端的请求。
自动间隔性保存
在默认情况下,Redis 将数据库快照保存在名字为 dump.rdb的二进制文件中。可以对 Redis 进行设置,让它在“ N 秒内数据集至少有 M 个改动”这一条件被满足时,自动保存一次数据集。
比如说, 以下设置会让 Redis 在满足“ 60 秒内有至少有 10 个键被改动”这一条件时,自动保存一次数据集:save 60 10
🎜🎜Beispiel für eine Datenstruktur: Das Folgende ist die Situation, in der Datenbank [0] und Datenbank [3] Daten haben: 🎜🎜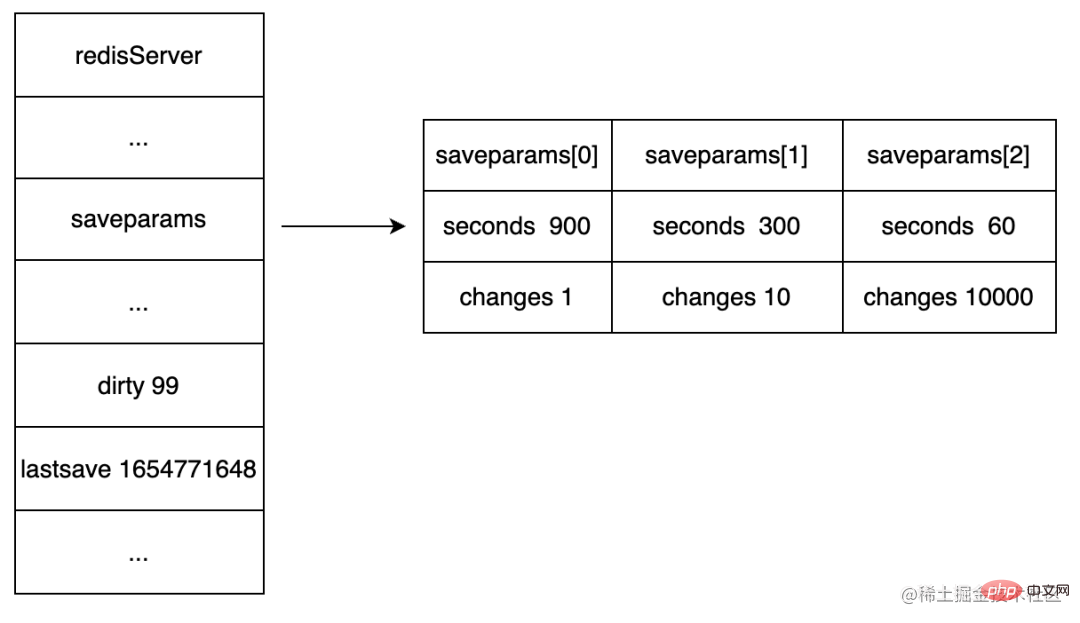 🎜
🎜save und den Befehl bgsave verwenden. Die Unterschiede zwischen diesen beiden Befehlen sind wie folgt: 🎜🎜 save: Das Ausführen des Befehls save zum Blockieren anderer Vorgänge von Redis führt dazu, dass Redis nicht auf Clientanfragen reagieren kann und wird nicht empfohlen. 🎜🎜bgsave: Führen Sie den Befehl bgsave aus. Redis erstellt einen untergeordneten Prozess im Hintergrund und speichert den Snapshot asynchron. Zu diesem Zeitpunkt kann Redis noch auf die Anfrage des Clients reagieren . 🎜🎜🎜Automatische Intervallspeicherung🎜🎜🎜Standardmäßig speichert Redis Datenbank-Snapshots in einer Binärdatei mit dem Namen dump.rdb. Redis kann so eingestellt werden, dass ein Datensatz automatisch gespeichert wird, wenn die Bedingung „Der Datensatz hat mindestens M Änderungen innerhalb von N Sekunden“ erfüllt ist. 🎜🎜Die folgenden Einstellungen führen beispielsweise dazu, dass Redis einen Datensatz automatisch speichert, wenn die Bedingung „mindestens 10 Schlüssel wurden innerhalb von 60 Sekunden geändert“ erfüllt ist: save 60 10. 🎜Die Standardkonfiguration von Redis ist wie folgt: Das automatische Speichern kann ausgelöst werden, wenn eine der drei Einstellungen erfüllt ist:
save 60 10000 save 300 10 save 900 1
Die Datenstruktur der automatischen Speicherkonfiguration
zeichnet die -Bedingung des Servers auf, der die automatische Speicherung auslöst <code>BGSAVE saveparams-Attribut. BGSAVE 条件的saveparams属性。
lastsave 属性:记录服务器最后一次执行 SAVE 或者 BGSAVE 的时间。
dirty
lastsave-Attribut: Zeichnet den letzten Zeitpunkt auf, zu dem der Server SAVE oder BGSAVE ausgeführt hat. dirty-Attribut: und wie oft der Server seit dem letzten Speichern der RDB-Datei geschrieben hat.
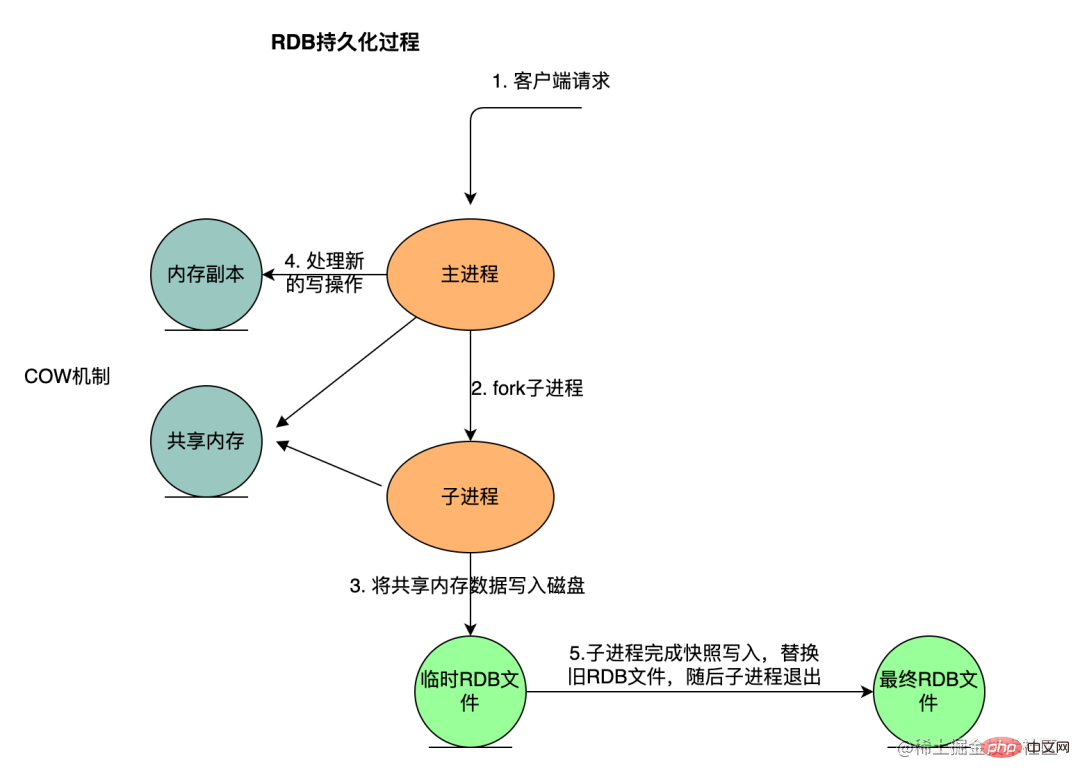 Beim Sichern des RDB-Persistenzschemas erstellt Redis einen separaten Unterprozess für die Persistenz, schreibt die Daten in eine temporäre Datei und ersetzt die alte RDB-Datei, nachdem die Persistenz abgeschlossen ist. Während des gesamten Persistenzprozesses nimmt der Hauptprozess (der Prozess, der Dienste für den Client bereitstellt) nicht an E/A-Vorgängen teil, wodurch die hohe Leistung des Redis-Dienstes sichergestellt wird. Der RDB-Persistenzmechanismus eignet sich für den Einsatz ohne hohe Anforderungen für Datenintegrität, strebt aber eine effiziente Wiederherstellungsszene an. Das Folgende zeigt den RDB-Persistenzprozess:
Beim Sichern des RDB-Persistenzschemas erstellt Redis einen separaten Unterprozess für die Persistenz, schreibt die Daten in eine temporäre Datei und ersetzt die alte RDB-Datei, nachdem die Persistenz abgeschlossen ist. Während des gesamten Persistenzprozesses nimmt der Hauptprozess (der Prozess, der Dienste für den Client bereitstellt) nicht an E/A-Vorgängen teil, wodurch die hohe Leistung des Redis-Dienstes sichergestellt wird. Der RDB-Persistenzmechanismus eignet sich für den Einsatz ohne hohe Anforderungen für Datenintegrität, strebt aber eine effiziente Wiederherstellungsszene an. Das Folgende zeigt den RDB-Persistenzprozess:
Der untergeordnete Prozess schließt das Schreiben des Snapshots ab, ersetzt die alte RDB-Datei und wird dann beendet.
Die Rolle des Fork-Kindprozesses
Aus Effizienzgründen verwendet das Linux-Betriebssystem den COW-Copy-on-Write-Mechanismus (Copy-on-Write). Der untergeordnete Fork-Prozess verwendet im Allgemeinen nur dann einen Abschnitt des physischen Speichers mit dem übergeordneten Prozess, wenn der Speicher im Prozess vorhanden ist Speicherplatz geändert wird, wird der Speicherplatz kopiert.
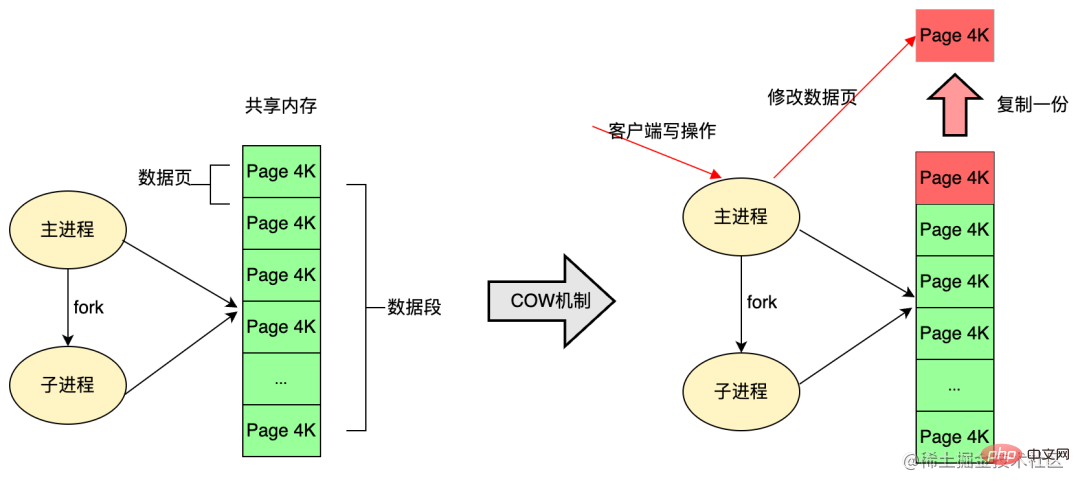 In Redis nutzt die RDB-Persistenz diese Technologie vollständig aus. Redis ruft die Glibc-Funktion auf, um einen untergeordneten Prozess während der Persistenz zu forken, und ist vollständig für die Persistenzarbeit verantwortlich, sodass der übergeordnete Prozess weiterhin Dienste bereitstellen kann Kunde. Der untergeordnete Prozess von Fork teilt sich zunächst den gleichen Speicher wie der übergeordnete Prozess (der Hauptprozess von Redis). Wenn der Client während des Persistenzprozesses eine Änderung der Daten im Speicher anfordert, wird dazu der COW-Mechanismus (Copy On Write) verwendet Ändern Sie die Daten im Speicher. Die Datensegmentseite ist getrennt, was bedeutet, dass ein Teil des Speichers kopiert wird, damit der Hauptprozess geändert werden kann.
In Redis nutzt die RDB-Persistenz diese Technologie vollständig aus. Redis ruft die Glibc-Funktion auf, um einen untergeordneten Prozess während der Persistenz zu forken, und ist vollständig für die Persistenzarbeit verantwortlich, sodass der übergeordnete Prozess weiterhin Dienste bereitstellen kann Kunde. Der untergeordnete Prozess von Fork teilt sich zunächst den gleichen Speicher wie der übergeordnete Prozess (der Hauptprozess von Redis). Wenn der Client während des Persistenzprozesses eine Änderung der Daten im Speicher anfordert, wird dazu der COW-Mechanismus (Copy On Write) verwendet Ändern Sie die Daten im Speicher. Die Datensegmentseite ist getrennt, was bedeutet, dass ein Teil des Speichers kopiert wird, damit der Hauptprozess geändert werden kann.
AOF (Append Only File) 是把所有对内存进行修改的指令(写操作)以独立日志文件的方式进行记录,重启时通过执行 AOF 文件中的 Redis 命令来恢复数据。类似MySql bin-log 原理。AOF 能够解决数据持久化实时性问题,是现在 Redis 持久化机制中主流的持久化方案。
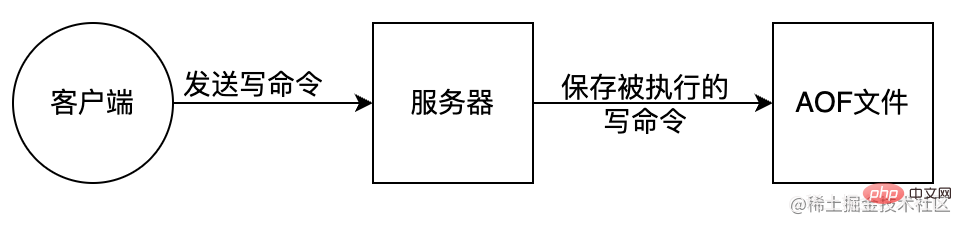
优点:
缺点:
被写入 AOF 文件的所有命令都是以 RESP 格式保存的,是纯文本格式保存在 AOF 文件中。
Redis 客户端和服务端之间使用一种名为
RESP(REdis Serialization Protocol)的二进制安全文本协议进行通信。
下面以一个简单的 SET 命令进行举例:
redis> SET mykey "hello" //客户端命令OK
客户端封装为以下格式(每行用 \r\n分隔)
*3$3SET$5mykey$5hello
AOF 文件中记录的文本内容如下
*2\r\n$6\r\nSELECT\r\n$1\r\n0\r\n //多出一个SELECT 0 命令,用于指定数据库,为系统自动添加 *3\r\n$3\r\nSET\r\n$5\r\nmykey\r\n$5\r\nhello\r\n
AOF 持久化方案进行备份时,客户端所有请求的写命令都会被追加到 AOF 缓冲区中,缓冲区中的数据会根据 Redis 配置文件中配置的同步策略来同步到磁盘上的 AOF 文件中,追加保存每次写的操作到文件末尾。同时当 AOF 的文件达到重写策略配置的阈值时,Redis 会对 AOF 日志文件进行重写,给 AOF 日志文件瘦身。Redis 服务重启的时候,通过加载 AOF 日志文件来恢复数据。
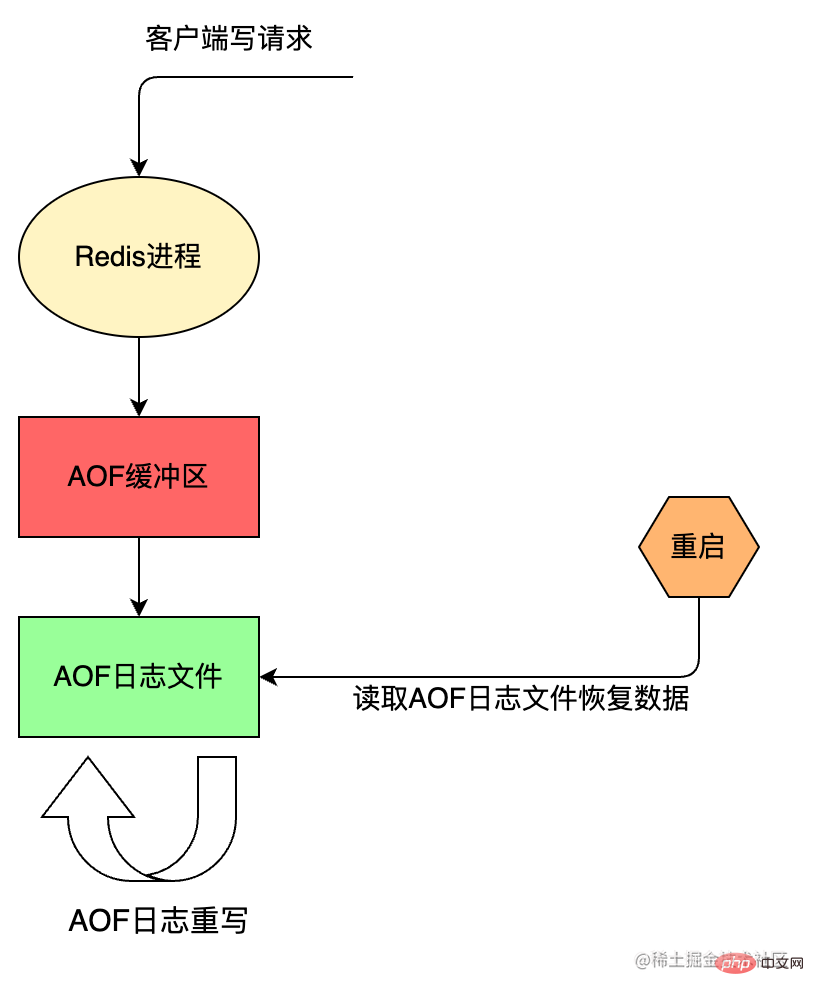
AOF 的执行流程包括:
命令追加(append)
Redis 先将写命令追加到缓冲区 aof_buf,而不是直接写入文件,主要是为了避免每次有写命令都直接写入硬盘,导致硬盘 IO 成为 Redis 负载的瓶颈。
struct redisServer {
//其他域... sds aof_buf; // sds类似于Java中的String //其他域...}文件写入(write)和文件同步(sync)
根据不同的同步策略将 aof_buf 中的内容同步到硬盘;
Linux 操作系统中为了提升性能,使用了页缓存(page cache)。当我们将 aof_buf 的内容写到磁盘上时,此时数据并没有真正的落盘,而是在 page cache 中,为了将 page cache 中的数据真正落盘,需要执行 fsync / fdatasync 命令来强制刷盘。这边的文件同步做的就是刷盘操作,或者叫文件刷盘可能更容易理解一些。
AOF 缓存区的同步文件策略由参数 appendfsync 控制,有三种同步策略,各个值的含义如下:
always:命令写入 aof_buf 后立即调用系统 write 操作和系统 fsync 操作同步到 AOF 文件,fsync 完成后线程返回。这种情况下,每次有写命令都要同步到 AOF 文件,硬盘 IO 成为性能瓶颈,Redis 只能支持大约几百TPS写入,严重降低了 Redis 的性能;即便是使用固态硬盘(SSD),每秒大约也只能处理几万个命令,而且会大大降低 SSD 的寿命。可靠性较高,数据基本不丢失。no:命令写入 aof_buf 后调用系统 write 操作,不对 AOF 文件做 fsync 同步;同步由操作系统负责,通常同步周期为30秒。这种情况下,文件同步的时间不可控,且缓冲区中堆积的数据会很多,数据安全性无法保证。everysec:命令写入 aof_buf 后调用系统 write 操作,write 完成后线程返回;fsync 同步文件操作由专门的线程每秒调用一次。everysec 是前述两种策略的折中,是性能和数据安全性的平衡,因此是 Redis 的默认配置,也是我们推荐的配置。文件重写(rewrite)
定期重写 AOF 文件,达到压缩的目的。
AOF 重写是 AOF 持久化的一个机制,用来压缩 AOF 文件,通过 fork 一个子进程,重新写一个新的 AOF 文件,该次重写不是读取旧的 AOF 文件进行复制,而是读取内存中的Redis数据库,重写一份 AOF 文件,有点类似于 RDB 的快照方式。
文件重写之所以能够压缩 AOF 文件,原因在于:
前面提到 AOF 的缺点时,说过 AOF 属于日志追加的形式来存储 Redis 的写指令,这会导致大量冗余的指令存储,从而使得 AOF 日志文件非常庞大,比如同一个 key 被写了 10000 次,最后却被删除了,这种情况不仅占内存,也会导致恢复的时候非常缓慢,因此 Redis 提供重写机制来解决这个问题。Redis 的 AOF 持久化机制执行重写后,保存的只是恢复数据的最小指令集,我们如果想手动触发可以使用如下指令:
bgrewriteaof
文件重写时机
相关参数:
同时满足下面两个条件,则触发 AOF 重写机制:
AOF 重写流程如下:
bgrewriteaof 触发重写,判断是否存在 bgsave 或者 bgrewriteaof 正在执行,存在则等待其执行结束再执行
子进程遍历 Redis 内存快照中数据写入临时 AOF 文件,同时会将新的写指令写入 aof_buf 和 aof_rewrite_buf 两个重写缓冲区,前者是为了写回旧的 AOF 文件,后者是为了后续刷新到临时 AOF 文件中,防止快照内存遍历时新的写入操作丢失
子进程结束临时 AOF 文件写入后,通知主进程
主进程会将上面 3 中的 aof_rewirte_buf 缓冲区中的数据写入到子进程生成的临时 AOF 文件中
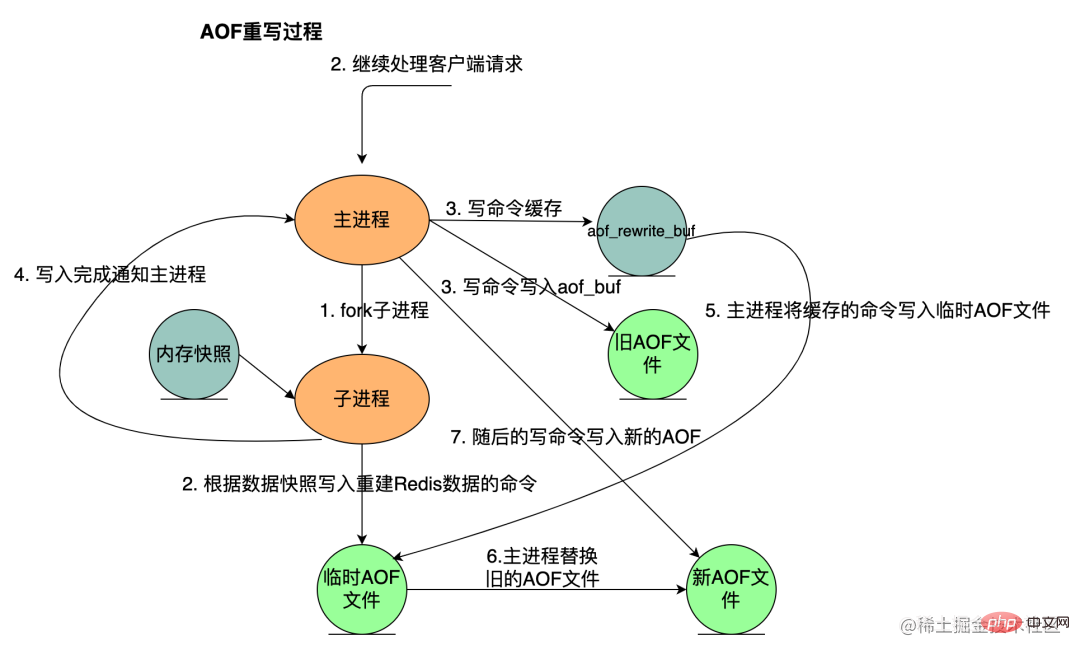
在实际中,为了避免在执行命令时造成客户端输入缓冲区溢出,重写程序会检查集合元素数量是否超过 REDIS_AOF_REWRITE_ITEMS_PER_CMD 常量的值,如果超过了,则会使用多个命令来记录,而不单单使用一条命令。
Redis 2.9版本中该常量为64,如果一个命令的集合键包含超过了64个元素,重写程序会拆成多个命令。

AOF重写是一个有歧义的名字,该功能是通过直接读取数据库的键值对实现的,程序无需对现有AOF文件进行任何读入、分析或者写入操作。
Redis 为什么考虑使用 AOF 而不是 WAL 呢?
很多数据库都是采用的 Write Ahead Log(WAL)写前日志,其特点就是先把修改的数据记录到日志中,再进行写数据的提交,可以方便通过日志进行数据恢复。
但是 Redis 采用的却是 AOF(Append Only File)写后日志,特点就是先执行写命令,把数据写入内存中,再记录日志。
Wenn Sie das System den Befehl zuerst ausführen lassen, wird nur der Befehl im Protokoll aufgezeichnet, der erfolgreich ausgeführt werden kann. Daher verwendet Redis die Protokollierung nach dem Schreiben, um die Aufzeichnung falscher Befehle zu vermeiden.
Ein weiterer Grund ist, dass AOF das Protokoll erst nach Ausführung des Befehls aufzeichnet, sodass der aktuelle Schreibvorgang nicht blockiert wird.
In Redis mit einer Versionsnummer größer oder gleich 2.4 kann BGREWRITEAOF nicht während der Ausführung von BGSAVE ausgeführt werden. Andererseits kann BGSAVE nicht während der Ausführung von BGREWRITEAOF ausgeführt werden. Dadurch wird verhindert, dass zwei Redis-Hintergrundprozesse gleichzeitig umfangreiche E/A-Vorgänge auf der Festplatte ausführen.
Wenn BGSAVE ausgeführt wird und der Benutzer explizit den Befehl BGREWRITEAOF aufruft, antwortet der Server dem Benutzer mit einem OK-Status und informiert den Benutzer, dass die Ausführung von BGREWRITEAOF geplant wurde: BGREWRITEAOF wird offiziell gestartet, sobald BGSAVE abgeschlossen ist.
Wenn Redis startet und sowohl die RDB-Persistenz als auch die AOF-Persistenz aktiviert sind, gibt das Programm der Verwendung von AOF-Dateien zum Wiederherstellen des Datensatzes Vorrang, da die in AOF-Dateien gespeicherten Daten normalerweise am vollständigsten sind.
Nach Redis 4.0 verwenden die meisten Nutzungsszenarien nicht nur RDB oder AOF als Persistenzmechanismus, sondern berücksichtigen die Vorteile beider. Der Grund dafür ist, dass RDB zwar schnell ist, aber viele Daten verliert und die Datenintegrität nicht garantieren kann. Obwohl AOF die Datenintegrität so weit wie möglich gewährleisten kann, ist seine Leistung in der Tat ein Kritikpunkt, beispielsweise bei der Wiedergabe und Wiederherstellung von Daten.
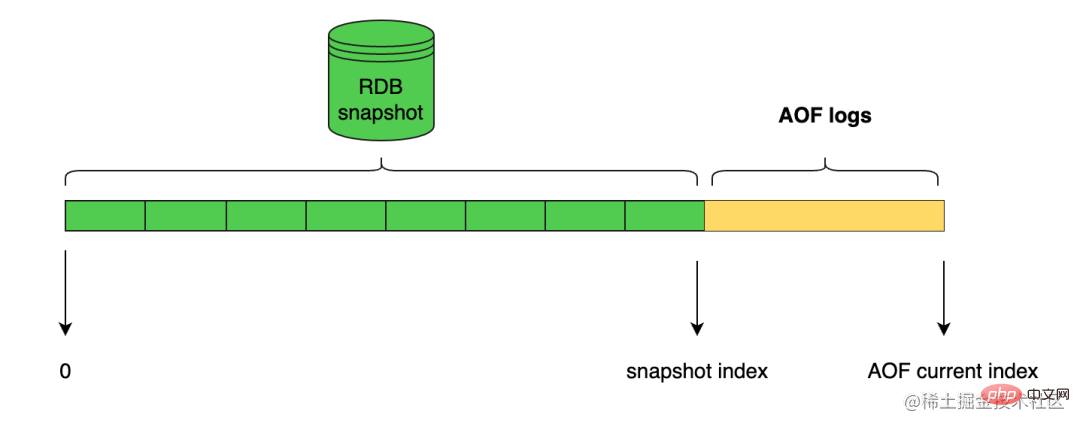
Redis hat seit Version 4.0 den RDB-AOF-Hybrid-Persistenzmodus eingeführt. Dieser Modus basiert auf dem AOF-Hybrid-Persistenzmodus, der durch aof-use-rdb-preamble yes aktiviert wird.
Wenn der Redis-Server dann den AOF-Rewrite-Vorgang ausführt, generiert er die entsprechenden RDB-Daten basierend auf dem aktuellen Status der Datenbank, genau wie beim Ausführen des BGSAVE-Befehls, und schreibt diese Daten in die neu erstellte AOF-Datei Die AOF-Rewrite-Redis-Befehle, die nach Beginn des Schreibens ausgeführt werden, werden weiterhin in Form von Protokolltext an das Ende der neuen AOF-Datei angehängt, d. h. nach den vorhandenen RDB-Daten.
Mit anderen Worten: Nachdem die RDB-AOF-Hybrid-Persistenzfunktion aktiviert wurde, besteht die vom Server generierte AOF-Datei aus zwei Teilen. Die Daten am Anfang der AOF-Datei sind die Daten im RDB-Format und die folgenden Bei den RDB-Daten handelt es sich um Daten im AOF-Format.
Wenn ein Redis-Server, der den RDB-AOF-Hybrid-Persistenzmodus unterstützt, startet und eine AOF-Datei lädt, prüft er, ob der Anfang der AOF-Datei Inhalte im RDB-Format enthält.
Die Struktur der Protokolldatei ist wie folgt:
Um die beiden zusammenzufassen: Welche ist besser?
Empfohlenes Lernen: Redis-Video-Tutorial
Das obige ist der detaillierte Inhalt vonEine kurze Analyse der Redis-Persistenzstrategie. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Häufig verwendete Datenbanksoftware
Häufig verwendete Datenbanksoftware
 Was sind In-Memory-Datenbanken?
Was sind In-Memory-Datenbanken?
 Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
 So verwenden Sie Redis als Cache-Server
So verwenden Sie Redis als Cache-Server
 Wie Redis die Datenkonsistenz löst
Wie Redis die Datenkonsistenz löst
 Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
 Welche Daten speichert der Redis-Cache im Allgemeinen?
Welche Daten speichert der Redis-Cache im Allgemeinen?
 Was sind die 8 Datentypen von Redis?
Was sind die 8 Datentypen von Redis?










![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



