
 Backend-Entwicklung
Python-Tutorial
Einrichtung und Betrieb des Python-Django-Modells (detaillierte Beispiele)
Backend-Entwicklung
Python-Tutorial
Einrichtung und Betrieb des Python-Django-Modells (detaillierte Beispiele)
Einrichtung und Betrieb des Python-Django-Modells (detaillierte Beispiele)

本篇文章给大家带来了关于Python的相关知识,其中主要介绍了关于Django的模型建立与操作的相关内容,下面一起来看一下,希望对大家有帮助。

【相关推荐:Python3视频教程 】
模型的建立
我们要建立一个博客系统,首先先在 manage.py 所在目录下,用命令 python manage.py startapp blog 新建一个 blog 应用,然后在 ./blog/models.py 中写一个类,命名为 BlogArticles。
通过这个类我们可以创建一个专门用来保存博客文章的数据库表,代码如下:
from django.db import modelsfrom django.utils import timezone # 新增from django.contrib.auth.models import User # 新增# Create your models here.# 编写博客的数据类型类BlogArticlesclass BlogArticles(models.Model): # 字段title的属性为CharField()类型,并且以参数max_length=300说明字段的最大数量
title = models.CharField(max_length=300) # 一个用户对应多篇文章,级联删除
author = models.ForeignKey(User, on_delete=models.CASCADE, related_name="blog_posts")
body = models.TextField()
publish = models.DateTimeField(default=timezone.now) class Meta:
ordering = ("-publish", ) # 规定了BlogArticles实例对象的显示顺序,即按照publish字段值的倒序显示
def __str__(self): return self.title相信经过上一篇文章的介绍,这里很多面孔你都很熟悉,现在对他们进行简单介绍:
- timezone 模块,我们未来记录文章发布时间,所以导入了这个模块。但因为 Django 默认开启时区且为 UTC,所以需要在 settings 中进行如下设置:
TIME_ZONE = 'Asia/Shanghai' # 设置东八区时间# TIME_ZONE = 'UTC'USE_TZ = False
-
User模型被命名为内置应用叫 auth,它以命名空间django.contrib.auth的形式出现在INSTALL_APPS配置中 -
ForeignKey()反映出一个用户可以发表多篇文章,其中参数on_delete=models.CASCADE是数据库中的“级联删除”,如果“用户表”中的某个用户被删除,那么“文章表”中该用户对应的文章记录也将被删除。 - 另一个参数
related_name="blog_posts"的作用是允许 User 的实例(某个用户名)以 “blog_posts” 属性反向查询到类 BlogArticles 的实例。 - 我们还定义了 Meta 子类,使用了
ordering = ("-publish", )规定文章的显示顺序 -
__str__方法是对象的字符串表示形式。我们可以使用版块的名称来表示它。
以上步骤我们还是仅仅在我们创建 blog 应用中写了一个博客文章模型,如果想要让应用生效,我们还需要将应用配置到我们的 settings 当中去,在 settings.py 文件的 INSTALLED_APPS 列表中添加 blog 应用,如下所示:
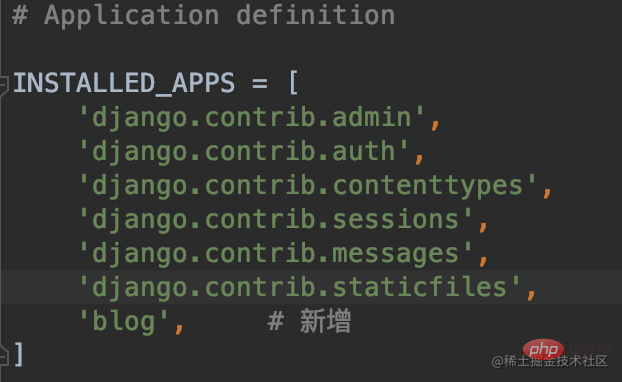
BlogArticles 类的数据模型编写完毕,我们得数据库表就是通过这个类中各字段和属性创建完成。
数据迁移
下一步就是告诉 Django,我的模型类创建好了,该到你创建数据库了,我们打开终端,转到 manage.py 文件所在的文件夹,然后运行一下命令:
python manage.py makemigrations
然后你将看到如下输出内容:
Migrations for 'blog': blog/migrations/0001_initial.py - Create model BlogArticles
此时,Django 在 /blog/migrations 目录中创建了一个名为 0001_initial.py 的文件。它代表了应用程序模型的当前状态,在下一步,将使用该文件创建表和列。
迁移文件将被翻译成 SQL 语句。执行下面命令:
python manage.py sqlmigrate blog 0001
然后可以看到如下输出内容:
BEGIN;
--
-- Create model BlogArticles
--
CREATE TABLE "blog_blogarticles" ("id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "title" varchar(300) NOT NULL, "body" text NOT NULL, "publish" datetime NOT NULL, "author_id" integer NOT NULL REFERENCES "auth_user" ("id") DEFERRABLE INITIALLY DEFERRED);
CREATE INDEX "blog_blogarticles_author_id_ed798e23" ON "blog_blogarticles" ("author_id");
COMMIT;最后我们将生产的迁移文件应用到数据库中:
python manage.py migrate
当看到
Operations to perform: Apply all migrations: admin, auth, blog, contenttypes, sessions Running migrations: ... Applying sessions.001_initial... OK
Applying sessions.001_initial... OK,这是我们在上一步生产的迁移脚本。意味着,我们的数据库已经可以开始使用了。
Django 自带一个数据库 SQLite,需要注意的是 SQLite 是一个产品级数据库。SQLite 被许多公司用于成千上万的产品,如所有 Android 和 iOS 设备,主流的 Web 浏览器,Windows 10,MacOS 等。 但这不适合所有情况。SQLite 不能与 MySQL,PostgreSQL 或 Oracle 等数据库进行比较。大容量的网站,密集型写入的应用程序,大的数据集,高并发性的应用使用 SQLite 最终都会导致问题。
SQLite 很轻量级,但是并不影响我们用来学习,接下来我们将利用命令行工具来对模型进行操作,也就是我们学习过数据库的基本操作——增、删、改、查。
模型操作
上面的内容中建立了一个博客文章的模型,然后通过数据迁移建立我们对应中的数据库表,加下来基于上述模型进行一些增删改成的操作,这小部分内容可能需要大家对数据库操作有一点熟悉。相信大家都是抱着学习 Django 的目的来看这一套入门笔记,我就不敢再各位数据库大佬们面前班门弄斧了,直接进入本章学习了。
SQLite 的启动
对数据库的操作可以利用 GUI 工具,也可以通过命令行 sqlite3 db.sqlite3,我们在 db.sqlite3 所在的目录下使用上述命令,就可以进入到 db.sqlite3 数据库,如果本地开发中没有配置 SQLite 环境,可以自行搜索如何配置。
如果我们输入命令,看到如下信息,说明进入成功:
~/DjangoProject/myblog $ sqlite3 db.sqlite3 SQLite version 3.29.0 2019-07-10 17:32:03 Enter ".help" for usage hints. sqlite>
然后我们使用 .tables 即可查看当前数据库中的数据库表的名称,除了 blog_blogarticles 是我们通过 BlogArticles 模型建立的,其余的都是项目默认创建的数据库表。
~/DjangoProject/myblog $ sqlite3 db.sqlite3 SQLite version 3.29.0 2019-07-10 17:32:03 Enter ".help" for usage hints. sqlite> .tables auth_group blog_blogarticles auth_group_permissions django_admin_log auth_permission django_content_type auth_user django_migrations auth_user_groups django_session auth_user_user_permissions sqlite>
接下来使用 pragma table_info(blog_blogarticles); 命令来查看 blog_blogarticles 表的结构:
sqlite> .header on sqlite> pragma table_info(blog_blogarticles); cid|name |type |notnull|dflt_value|pk 0| id |integer |1 | |1 1|title |varchar(300)|1 | |0 2|body |text |1 | |0 3|publish |datetime |1 | |0 4|author_id|integer |1 | |0 sqlite>
.header on 开启头部显示
SQLite 的
PRAGMA命令是一个特殊的命令,可以用在 SQLite 环境内控制各种环境变量和状态标志。一个 PRAGMA 值可以被读取,也可以根据需求进行设置。
我们可以大致查看上面的表结构,cid 是指列 id,name 是指列名,type 是指列类型,notnull 非空,值为 1 表示 True,dflt_value 是指 default 默认值(这一列没有值,说明设置设置默认值),pk 是指 primary_key 主键。
大家可以跟我们在前一章中的数据模型 BlogArticles 所规定的字段和属性进行对比,是不是刚好我们利用数据迁移成功将数据模型转化为数据库表。
创建超级管理员
我们可以在命令行中输入 python manage.py createsuperuser 创建一个 Django 超级管理员,输入用户名和密码,当提示 Superuser created successfully,创建成功。如下:
~/DjangoProject/myblog $ python manage.py createsuperuser Username (leave blank to use 'yuzhou_1su'): zoeu Email address: test@test.com Password: Password (again): Superuser created successfully.
然后我在浏览器输入 http://127.0.0.1:8000/admin/ ,就可以打开如下界面:
输入刚才创建的超级管理员的用户名和密码就可以进入系统,如图:

Groups 和 Users 是 Django 在用户管理应用中默认的用户分类。为了让我们得管理员用户能够发布博客,我们需要在 ./blog/admin.py 文件中,加入如下代码:
from django.contrib import admin# 新增,将BlogArticles类引入到当前环境中from .models import BlogArticles # 将BlogArticles注册到admin中admin.site.register(BlogArticles)
刷新页面,我们可以得到如下的页面:

超级管理员界面先放在这,我们回到模型操作。
模型 API 测试
使用 Python 进行开发的一个重要优点是交互式 shell。我们在 ./blog/models.py 中创建了数据模型后,Django 就会自动提供数据库抽象的 API,这是一种快速尝试和试验 API 的方法。通过这个 API 我们可以快速创建、获取、修改和删除对象,对此我们称之为 ORM(Object-Relational Mapper)
我们可以使用 manage.py 工具加载我们的项目来启动 Python shell :
python3 manage.py shell
Python 3.7.3 (v3.7.3:ef4ec6ed12, Mar 25 2019, 16:52:21) [Clang 6.0 (clang-600.0.57)] on darwin Type "help", "copyright", "credits" or "license" for more information. (InteractiveConsole) >>>
请特别注意我们进入 shell 的方式,不是直接在命令行中敲 python3,虽然这与直接输入 python 指令来调用交互式控制台是非常相似。
区别是我们利用 manage.py 工具,将项目将被添加到 sys.path 并加载 Django。这意味着我们可以在项目中导入我们的模型和其他资源并使用它。
让我们从导入 BlogArticles 类开始:下面就可以开始我们对数据库的增、删、改、查等操作。
$ python3 manage.py shell Python 3.7.3 (v3.7.3:ef4ec6ed12, Mar 25 2019, 16:52:21) [Clang 6.0 (clang-600.0.57)] on darwinType "help", "copyright", "credits" or "license" for more information. (InteractiveConsole)>>> from django.contrib.auth.models import User>>> from blog.models import BlogArticles>>> admin = User.objects.get(username="zoue")>>> admin.username'zoeu'>>> admin.id1>>> admin.password'pbkdf2_sha256$150000$b9j0ZKBVZSo1$l+fEIiKIaS6u1mhjMPOX1qR0xMOaemnRJIwiE2lNn60='>>> admin.email'test@test.com'>>> type(admin) <class></class>
以上是对用户的查询操作是不是刚好是我们上一节中在创建管理员的内容,恭喜你!
接下来,我们对博客文章进行操作,要创建新的 BlogArticle 对象,我们可以执行以下操作:
- 增
>>> BlogAriticle01 = BlogArticles(title ='DjangoNotes_Day01', author=zoue, body='Django是啥?');
为了将这个对象保存在数据库中,我们必须调用 save 方法:
>>> BlogAriticle01.save()
save方法用于创建和更新对象。这里Django创建了一个新对象,因为这时 BlogAriticle01 实例没有 id。第一次保存后,Django 会自动设置 ID :
>>> BlogAriticle01.id4
因为我自己在之前创建过其它文章,所以这个 id 值为 4,如果你是按照本入门笔记一步步操作过来,id 值应该为 1。
当然,还可以查看其它属性,这里统一将命令敲出来:
>>> BlogAriticle01.title'DjangoNotes_Day01'>>> BlogAriticle01.author <user:>>>> BlogAriticle01.body'Django是啥?'>>> BlogAriticle01.publish datetime.datetime(2019, 9, 30, 19, 56, 58, 735676)>>></user:>
每个 Django 模型都带有一个特殊的属性; 我们称之为模型管理器(Model Manager)。你可以通过属性 objects 来访问这个管理器,它主要用于数据库操作。例如,我们可以使用它来直接创建一个新的 Board 对象:
>>> BlogArticle02 = BlogArticles.objects.create(title='Python', author=admin, body='Head First to Python.')>>> BlogArticle02.id5
- 改
要更新一个值,我们可以利用如下操作:
>>> BlogAriticle01.body = 'I love Django, 但是我太难了'>>> BlogAriticle01.body'I love Django, 但是我太难了'
- 查
>>> blogs = BlogArticles.objects.all()>>> blogs <queryset>, <blogarticles:>, <blogarticles:>, <blogarticles:>, <blogarticles:>]></blogarticles:></blogarticles:></blogarticles:></blogarticles:></queryset>
结果是一个 QuerySet,我们可以将这个 QuerySet 看作一个列表。假设我们想遍历它并打印每个模块的标题。
>>> for blog in blogs:... print(blog.title)... Python DjangoNotes_Day01 right here waiting Yesterday once more You Raise me up>>>
同样,我们可以使用模型的 管理器(Manager) 来查询数据库并返回单个对象。为此,我们要使用 get 方法:
>>> BlogArticles.objects.get(id=5) <blogarticles:></blogarticles:>
- 删
>>> BlogArticles.objects.get(id=5).delete()
(1, {'blog.BlogArticles': 1})删除后再重新查看一下 QuerySet,发现没有了
>>> blogs = BlogArticles.objects.all()>>> blogs <queryset>, <blogarticles:>, <blogarticles:>, <blogarticles:>]></blogarticles:></blogarticles:></blogarticles:></queryset>
除了 get 方法,其实也可以用 filter 进行筛选查询 id=5 然后删除,
BlogArticles.objects.filter(id=5).delete(),关于 filter 方法我们将在后面的文章中进行介绍。
总结
下面是我们在本节中关于模型学到的方法和操作,使用 BlogArticles 模型作为参考。大写的 BlogArticles 指的是类,BlogArticles01 指 BlogArticles 的一个实例(或对象):
| 操作 | 代码示例 |
|---|---|
| 创建一个对象而不保存 | BlogAriticle01 = BlogArticles() |
| 保存一个对象(创建或更新) | BlogAriticle01.save() |
| 数据库中创建并保存一个对象 | BlogArticle02 = BlogArticles.objects.create(title='...', author=..., body='...') |
| 列出所有对象 | BlogArticles.objects.all() |
| 通过字段标识获取单个对象 | BlogArticles.objects.get(id=5) |
| 通过字段标识删除单个对象 | BlogArticles.objects.get(id=5).delete() |
【相关推荐:Python3视频教程 】
Das obige ist der detaillierte Inhalt vonEinrichtung und Betrieb des Python-Django-Modells (detaillierte Beispiele). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1359
1359
 52
52

 Was ist die Funktion der C -Sprachsumme?
Apr 03, 2025 pm 02:21 PM
Was ist die Funktion der C -Sprachsumme?
Apr 03, 2025 pm 02:21 PM
Es gibt keine integrierte Summenfunktion in der C-Sprache, daher muss sie selbst geschrieben werden. Die Summe kann erreicht werden, indem das Array durchquert und Elemente akkumulieren: Schleifenversion: Die Summe wird für die Schleifen- und Arraylänge berechnet. Zeigerversion: Verwenden Sie Zeiger, um auf Array-Elemente zu verweisen, und eine effiziente Summierung wird durch Selbststillstandszeiger erzielt. Dynamisch Array -Array -Version zuweisen: Zuordnen Sie Arrays dynamisch und verwalten Sie selbst den Speicher selbst, um sicherzustellen, dass der zugewiesene Speicher befreit wird, um Speicherlecks zu verhindern.
 Ist DifferiDItistinginginging verwandt?
Apr 03, 2025 pm 10:30 PM
Ist DifferiDItistinginginging verwandt?
Apr 03, 2025 pm 10:30 PM
Obwohl eindeutig und unterschiedlich mit der Unterscheidung zusammenhängen, werden sie unterschiedlich verwendet: Unterschieds (Adjektiv) beschreibt die Einzigartigkeit der Dinge selbst und wird verwendet, um Unterschiede zwischen den Dingen zu betonen; Das Unterscheidungsverhalten oder die Fähigkeit des Unterschieds ist eindeutig (Verb) und wird verwendet, um den Diskriminierungsprozess zu beschreiben. In der Programmierung wird häufig unterschiedlich, um die Einzigartigkeit von Elementen in einer Sammlung darzustellen, wie z. B. Deduplizierungsoperationen; Unterscheidet spiegelt sich in der Gestaltung von Algorithmen oder Funktionen wider, wie z. B. die Unterscheidung von ungeraden und sogar Zahlen. Bei der Optimierung sollte der eindeutige Betrieb den entsprechenden Algorithmus und die Datenstruktur auswählen, während der unterschiedliche Betrieb die Unterscheidung zwischen logischer Effizienz optimieren und auf das Schreiben klarer und lesbarer Code achten sollte.
 Wer bekommt mehr Python oder JavaScript bezahlt?
Apr 04, 2025 am 12:09 AM
Wer bekommt mehr Python oder JavaScript bezahlt?
Apr 04, 2025 am 12:09 AM
Es gibt kein absolutes Gehalt für Python- und JavaScript -Entwickler, je nach Fähigkeiten und Branchenbedürfnissen. 1. Python kann mehr in Datenwissenschaft und maschinellem Lernen bezahlt werden. 2. JavaScript hat eine große Nachfrage in der Entwicklung von Front-End- und Full-Stack-Entwicklung, und sein Gehalt ist auch beträchtlich. 3. Einflussfaktoren umfassen Erfahrung, geografische Standort, Unternehmensgröße und spezifische Fähigkeiten.
 Wie versteht man! X in c?
Apr 03, 2025 pm 02:33 PM
Wie versteht man! X in c?
Apr 03, 2025 pm 02:33 PM
! X Understanding! X ist ein logischer Nicht-Operator in der C-Sprache. Es booleschen den Wert von x, dh wahre Änderungen zu falschen, falschen Änderungen an True. Aber seien Sie sich bewusst, dass Wahrheit und Falschheit in C eher durch numerische Werte als durch Boolesche Typen dargestellt werden, ungleich Null wird als wahr angesehen und nur 0 wird als falsch angesehen. Daher handelt es sich um negative Zahlen wie positive Zahlen und gilt als wahr.
 Bedarf die Produktion von H5 -Seiten eine kontinuierliche Wartung?
Apr 05, 2025 pm 11:27 PM
Bedarf die Produktion von H5 -Seiten eine kontinuierliche Wartung?
Apr 05, 2025 pm 11:27 PM
Die H5 -Seite muss aufgrund von Faktoren wie Code -Schwachstellen, Browserkompatibilität, Leistungsoptimierung, Sicherheitsaktualisierungen und Verbesserungen der Benutzererfahrung kontinuierlich aufrechterhalten werden. Zu den effektiven Wartungsmethoden gehören das Erstellen eines vollständigen Testsystems, die Verwendung von Versionstools für Versionskontrolle, die regelmäßige Überwachung der Seitenleistung, das Sammeln von Benutzern und die Formulierung von Wartungsplänen.
 Was bedeutet Summe in der C -Sprache?
Apr 03, 2025 pm 02:36 PM
Was bedeutet Summe in der C -Sprache?
Apr 03, 2025 pm 02:36 PM
Es gibt keine integrierte Summenfunktion in C für die Summe, kann jedoch implementiert werden durch: Verwenden einer Schleife, um Elemente nacheinander zu akkumulieren; Verwenden eines Zeigers, um auf die Elemente nacheinander zuzugreifen und zu akkumulieren; Betrachten Sie für große Datenvolumina parallele Berechnungen.
 Kopieren Sie den Liebescode und fügen Sie den Liebescode kostenlos kopieren und einfügen
Apr 04, 2025 am 06:48 AM
Kopieren Sie den Liebescode und fügen Sie den Liebescode kostenlos kopieren und einfügen
Apr 04, 2025 am 06:48 AM
Das Kopieren und Einfügen des Codes ist nicht unmöglich, sollte aber mit Vorsicht behandelt werden. Abhängigkeiten wie Umgebung, Bibliotheken, Versionen usw. im Code stimmen möglicherweise nicht mit dem aktuellen Projekt überein, was zu Fehlern oder unvorhersehbaren Ergebnissen führt. Stellen Sie sicher, dass der Kontext konsistent ist, einschließlich Dateipfade, abhängiger Bibliotheken und Python -Versionen. Wenn Sie den Code für eine bestimmte Bibliothek kopieren und einfügen, müssen Sie möglicherweise die Bibliothek und ihre Abhängigkeiten installieren. Zu den häufigen Fehlern gehören Pfadfehler, Versionskonflikte und inkonsistente Codestile. Die Leistungsoptimierung muss gemäß dem ursprünglichen Zweck und den Einschränkungen des Codes neu gestaltet oder neu gestaltet werden. Es ist entscheidend, den Code zu verstehen und den kopierten kopierten Code zu debuggen und nicht blind zu kopieren und einzufügen.
 Wie erhalten Sie Echtzeit-Anwendungs- und Zuschauerdaten auf der Arbeit von 58.com?
Apr 05, 2025 am 08:06 AM
Wie erhalten Sie Echtzeit-Anwendungs- und Zuschauerdaten auf der Arbeit von 58.com?
Apr 05, 2025 am 08:06 AM
Wie erhalte ich dynamische Daten von 58.com Arbeitsseite beim Kriechen? Wenn Sie eine Arbeitsseite von 58.com mit Crawler -Tools kriechen, können Sie auf diese begegnen ...
