
 Datenbank
Redis
Erfahren Sie in einem Artikel mehr über Redis-Cache-Lawine, Cache-Aufschlüsselung und Cache-Penetration
Datenbank
Redis
Erfahren Sie in einem Artikel mehr über Redis-Cache-Lawine, Cache-Aufschlüsselung und Cache-Penetration
Erfahren Sie in einem Artikel mehr über Redis-Cache-Lawine, Cache-Aufschlüsselung und Cache-Penetration

Dieser Artikel bringt Ihnen relevantes Wissen über Redis, das hauptsächlich die relevanten Inhalte zu Cache-Lawine, Cache-Aufschlüsselung und Cache-Penetration vorstellt. Ich hoffe, es wird für alle hilfreich sein.

Empfohlenes Lernen: Redis-Video-Tutorial
In Bezug auf die Hochfrequenzprobleme von Redis müssen Cache-Lawine, Cache-Aufschlüsselung und Cache-Penetration unverzichtbar sein. Ich glaube, dass jedem in Interviews ähnliche Fragen gestellt wurden. Warum sind diese Fragen so beliebt? Denn wenn wir den Redis-Cache verwenden, können diese Probleme leicht auftreten. Schauen wir uns als Nächstes an, wie diese Probleme entstehen und welche Lösungen es gibt.
Cache-Lawine
Werfen wir zunächst einen Blick auf die Cache-Lawine Das Konzept der Cache-Lawine besteht darin, dass eine große Anzahl von Anfragen nicht im Redis-Cache verarbeitet wird, was dazu führt, dass Anfragen in die Datenbank überflutet werden und dann der Druck zunimmt Die Datenbank vergrößert sich dramatisch.
Die Gründe für die Cache-Lawine lassen sich in zwei Gründe zusammenfassen:
- Eine große Datenmenge im Cache läuft gleichzeitig ab, sodass zu diesem Zeitpunkt eine große Anzahl von Anfragen an die Datenbank gesendet wird.
- Die Redis-Cache-Instanz fällt aus und kann eine große Anzahl von Anfragen nicht verarbeiten, was auch dazu führt, dass die Anfragen an die Datenbank weitergeleitet werden.
Schauen wir uns das erste Szenario an: Eine große Datenmenge im Cache läuft gleichzeitig ab.
Eine große Datenmenge im Cache ist gleichzeitig abgelaufen
Der Legende nach bedeutet dies, dass eine große Datenmenge gleichzeitig abgelaufen ist und es zu diesem Zeitpunkt viele Anfragen zum Lesen der Daten gab. Natürlich wird es zu einer Cache-Lawine kommen, die zu einem dramatischen Anstieg des Datenbankdrucks führt.
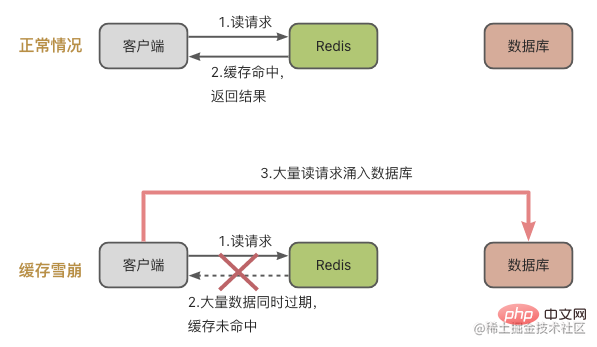
Lösung für den Fall, dass eine große Datenmenge gleichzeitig abläuft
Um das Problem zu lösen, dass eine große Datenmenge gleichzeitig abläuft, gibt es normalerweise zwei Lösungen:
- Erhöhen Sie den Zufall Zeit in der Datenablaufeinstellung: Das heißt, wenn Sie den Ablaufbefehl verwenden, um die Ablaufzeit für die Daten festzulegen, fügen Sie eine zufällige Zeit hinzu, z. B. laufen Daten a in 5 Minuten ab und 10-120 Sekunden werden zufällig zu den 5 hinzugefügt Minuten. Dadurch wird verhindert, dass große Datenmengen gleichzeitig ablaufen.
- Dienstverschlechterung: Das heißt, wenn eine Cache-Lawine auftritt, (1) wenn der Zugriff nicht auf Kerndaten erfolgt und kein Cache-Treffer vorliegt, wird die Datenbank nicht auf die Datenbank zugreifen und voreingestellte Informationen wie Nullwerte eingeben oder Fehlermeldungen werden direkt zurückgegeben. (2) Wenn auf Kerndaten zugegriffen wird und der Cache fehlschlägt, ist eine Datenbankabfrage zulässig. Auf diese Weise werden Anfragen, die keine Kerndaten sind, abgelehnt und an die Datenbank gesendet.
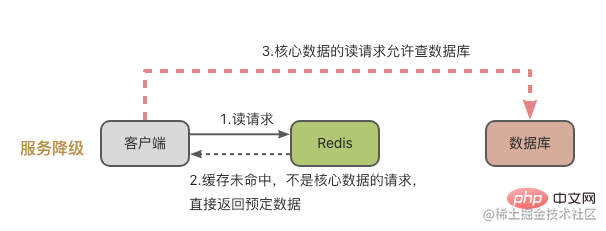
Nachdem wir uns die Situation angesehen haben, in der eine große Datenmenge gleichzeitig abläuft, werfen wir einen Blick auf die Situation des Ausfalls einer Redis-Cache-Instanz.
Cache-Lawine durch Redis-Cache-Instanzfehler verursacht
In diesem Fall kann Redis die Leseanforderung nicht verarbeiten und die Anforderung wird natürlich an die Datenbank weitergeleitet.
Generell haben wir zwei Möglichkeiten, mit dieser Situation umzugehen:
- Leistungsschalter warten/Strombegrenzung anfordern im Geschäftssystem. Vorsichtsmaßnahme im Voraus: Erstellen Sie einen hochzuverlässigen Redis-Cluster,
- z. B. Master-Slave-Cluster-Switching.
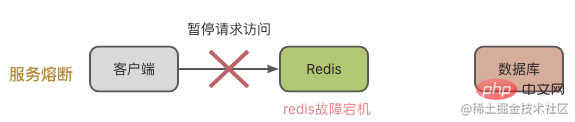
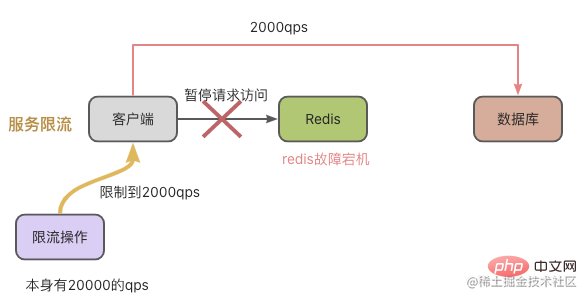
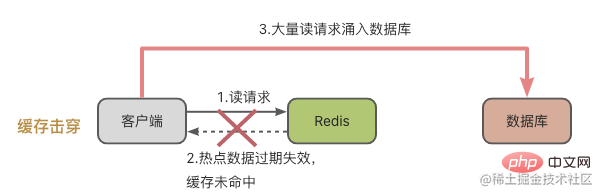
Cache-Penetration
Cache-Avalanche ist etwas Besonderes, es bedeutet, dass sich die Daten, auf die zugegriffen werden soll, weder im Redis-Cache noch in der Datenbank befinden. Wenn eine große Anzahl von Anfragen in das System eingeht, stehen Redis und die Datenbank unter enormem Druck.
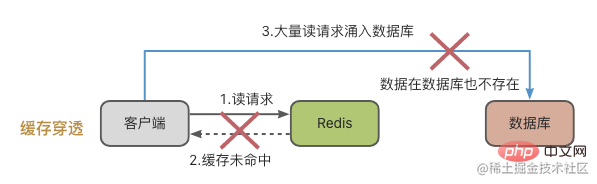
Es gibt normalerweise zwei Gründe für das Eindringen in den Cache:
- Die Daten werden versehentlich gelöscht, was dazu führt, dass keine Daten im Cache und in der Datenbank vorhanden sind. Der Kunde weiß das jedoch nicht und fragt trotzdem hektisch nach.
- Es gibt Fälle von böswilligen Angriffen: Das heißt, jemand zielt auf Sie ab, um nach Daten zu suchen, die nicht verfügbar sind.
Für die Cache-Penetration können Sie auf die folgenden Lösungen zurückgreifen:
- besteht darin, einen Nullwert oder einen Standardwert für den Cache festzulegen. Wenn beispielsweise eine Cache-Penetration auftritt, legen Sie im Redis-Cache einen Nullwert/Standardwert fest. Nachfolgende Abfragen für diesen Wert geben diesen Standardwert direkt zurück.
- Verwenden Sie den Bloom-Filter, um festzustellen, ob Daten vorhanden sind, und um Abfragen aus der Datenbank zu vermeiden.
- Führen Sie die Anforderungserkennung im Frontend durch. Filtern Sie beispielsweise einige illegale Anfragen direkt im Frontend, anstatt sie zur Verarbeitung an das Backend zu senden.
Der erste und dritte Punkt sind leichter zu verstehen und werden hier nicht beschrieben. Konzentrieren wir uns auf den zweiten Punkt: Bloom-Filter.
Bloom-Filter
Der Bloom-Filter wird hauptsächlich verwendet, um festzustellen, ob ein Element in einer Menge enthalten ist. Es besteht aus einem binären Vektor fester Größe (kann als Bitarray mit dem Standardwert 0 verstanden werden) und einer Reihe von Zuordnungsfunktionen.
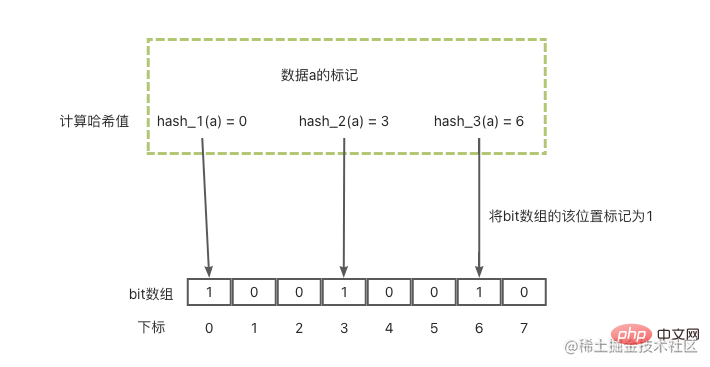
Sehen wir uns zunächst an, wie der Bloom-Filter Daten als a markiert:
- Im ersten Schritt werden mehrere Zuordnungsfunktionen (Hash-Funktionen) verwendet, und jede Funktion berechnet den Hash des Daten-a-Werts
- Im zweiten Schritt werden diese berechneten Hash-Werte jeweils der Länge des Bit-Arrays angepasst, um die Position jedes Hash-Werts im Array zu erhalten.
- Im dritten Schritt werden die Positionen ermittelt jeweils im Bit-Array auf 1 gesetzt.
Mit diesen 3 Schritten ist die Datenkennzeichnung abgeschlossen. Um die Daten dann abzufragen, wenn sie nicht vorhanden sind, gehen Sie wie folgt vor:
- Berechnen Sie zunächst die mehreren Positionen dieser Daten im Bit-Array.
- Überprüfen Sie dann jeweils die Bitwerte dieser Positionen im Bit-Array. Nur wenn der Bitwert jeder Position 1 ist, bedeutet dies, dass die Daten vorhanden sein dürfen, andernfalls dürfen die Daten nicht vorhanden sein.
Wenn man sich das Bild unten ansieht, sieht das Grundprinzip so aus.
Empfohlenes Lernen: Redis-Video-Tutorial
Das obige ist der detaillierte Inhalt vonErfahren Sie in einem Artikel mehr über Redis-Cache-Lawine, Cache-Aufschlüsselung und Cache-Penetration. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1677
1677
 14
1431
52
1334
25
1279
29
1257
24
14
1431
52
1334
25
1279
29
1257
24

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So konfigurieren Sie die Ausführungszeit der Lua -Skript in CentOS Redis
Apr 14, 2025 pm 02:12 PM
So konfigurieren Sie die Ausführungszeit der Lua -Skript in CentOS Redis
Apr 14, 2025 pm 02:12 PM
Auf CentOS -Systemen können Sie die Ausführungszeit von LuA -Skripten einschränken, indem Sie Redis -Konfigurationsdateien ändern oder Befehle mit Redis verwenden, um zu verhindern, dass bösartige Skripte zu viele Ressourcen konsumieren. Methode 1: Ändern Sie die Redis -Konfigurationsdatei und suchen Sie die Redis -Konfigurationsdatei: Die Redis -Konfigurationsdatei befindet sich normalerweise in /etc/redis/redis.conf. Konfigurationsdatei bearbeiten: Öffnen Sie die Konfigurationsdatei mit einem Texteditor (z. B. VI oder Nano): Sudovi/etc/redis/redis.conf Setzen Sie die LUA -Skriptausführungszeit.
 So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
Verwenden Sie das Redis-Befehlszeilen-Tool (REDIS-CLI), um Redis in folgenden Schritten zu verwalten und zu betreiben: Stellen Sie die Adresse und den Port an, um die Adresse und den Port zu stellen. Senden Sie Befehle mit dem Befehlsnamen und den Parametern an den Server. Verwenden Sie den Befehl Hilfe, um Hilfeinformationen für einen bestimmten Befehl anzuzeigen. Verwenden Sie den Befehl zum Beenden, um das Befehlszeilenwerkzeug zu beenden.
 So implementieren Sie Redis -Zähler
Apr 10, 2025 pm 10:21 PM
So implementieren Sie Redis -Zähler
Apr 10, 2025 pm 10:21 PM
Der Redis-Zähler ist ein Mechanismus, der die Speicherung von Redis-Schlüsselwertpaaren verwendet, um Zählvorgänge zu implementieren, einschließlich der folgenden Schritte: Erstellen von Zählerschlüssel, Erhöhung der Zählungen, Verringerung der Anzahl, Zurücksetzen der Zählungen und Erhalt von Zählungen. Die Vorteile von Redis -Zählern umfassen schnelle Geschwindigkeit, hohe Parallelität, Haltbarkeit und Einfachheit und Benutzerfreundlichkeit. Es kann in Szenarien wie Benutzerzugriffszählungen, Echtzeit-Metrikverfolgung, Spielergebnissen und Ranglisten sowie Auftragsverarbeitungszählung verwendet werden.
 So setzen Sie die Redis -Ablaufpolitik
Apr 10, 2025 pm 10:03 PM
So setzen Sie die Redis -Ablaufpolitik
Apr 10, 2025 pm 10:03 PM
Es gibt zwei Arten von RETIS-Datenverlaufstrategien: regelmäßige Löschung: periodischer Scan zum Löschen des abgelaufenen Schlüssels, der über abgelaufene Cap-Remove-Count- und Ablauf-Cap-Remove-Delay-Parameter festgelegt werden kann. LAZY LELETION: Überprüfen Sie nur, ob abgelaufene Schlüsseln gelöscht werden, wenn Tasten gelesen oder geschrieben werden. Sie können durch LazyFree-Lazy-Eviction, LazyFree-Lazy-Expire, LazyFree-Lazy-User-Del-Parameter eingestellt werden.
 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
