

Wie viele Daten kann jede Tabelle in MySQL speichern? In tatsächlichen Situationen ist aufgrund der unterschiedlichen Felder und des unterschiedlichen Speicherplatzes, den jede Tabelle einnimmt, auch die Datenmenge, die sie bei optimaler Leistung speichern können, unterschiedlich, was eine manuelle Berechnung erfordert.
Das Folgende ist der Interviewbericht meines Freundes:
An diesem Ausdruck scheint nichts auszusetzen zu sein, oder? Keine Sorge, lesen wir weiter:Interviewer: Erzählen Sie mir, was Sie während Ihres Praktikums gemacht haben.
Freund: Während meines Praktikums habe ich eine Funktion zum Speichern von Benutzerbetriebsdatensätzen erstellt. Sie ruft hauptsächlich Benutzerbetriebsinformationen ab, die vom Upstream-Dienst von MQ gesendet wurden, und speichert diese Informationen dann in MySQL zur Verwendung durch Kollegen im Data Warehouse.
Freund: Da die Datenmenge relativ groß ist, gibt es jeden Tag etwa 40 bis 50 Millionen Elemente, daher habe ich auch Untertabellenoperationen dafür durchgeführt. Jeden Tag werden regelmäßig drei Tabellen generiert. Anschließend werden die Daten in diesen drei Tabellen modelliert und gespeichert, um zu verhindern, dass übermäßige Daten in den Tabellen die Abfragegeschwindigkeit verlangsamen.
Interviewer: Warum teilen Sie ihn dann nicht in drei Tabellen auf? Würden vier Tische nicht funktionieren? Freunde: Da jede MySQL-Tabelle 20 Millionen Daten nicht überschreiten sollte, wird sonst die Abfragegeschwindigkeit verringert und die Leistung beeinträchtigt. Unsere täglichen Daten belaufen sich auf etwa 50 Millionen Teile, daher ist es sicherer, sie in drei Tabellen aufzuteilen. Interviewer: Noch mehr? Freund: Nicht mehr...Nachdem ich mit dem Sprechen fertig bin, sehen Sie etwas? Glauben Sie, dass an der Antwort meines Freundes etwas nicht stimmt?Was machst du? Ups
Interviewer: Dann geh zurück und warte auf die Benachrichtigung.
Aber tatsächlich sind diese 20 Millionen oder 5 Millionen nur eine ungefähre Zahl und gelten nicht für alle Szenarien. Wenn Sie blind glauben, dass es kein Problem geben wird, solange die Tabellendaten 20 Millionen nicht überschreiten, ist dies der Fall Dies führt wahrscheinlich zu einem erheblichen Leistungsabfall des Systems.
Um diesen Artikel zu lesen, benötigen Sie eine gewisse MySQL-Grundlage. Es ist am besten, über ein gewisses Verständnis von InnoDB- und B+-Bäumen zu verfügen Jahr MySQL-Lernerfahrung (ungefähr ein Jahr?) Kennen Sie das theoretische Wissen „Im Allgemeinen ist es besser, die Höhe des B + -Baums in InnoDB innerhalb von drei Ebenen zu halten“.
In diesem Artikel wird hauptsächlich das Thema „Wie viele Daten können in einem B+-Baum mit einer Höhe von 3 in InnoDB gespeichert werden?“ erläutert. Darüber hinaus ist die Datenberechnung in diesem Artikel relativ streng (zumindest strenger als in mehr als 95 % der entsprechenden Blog-Beiträge im Internet). Wenn Sie sich für diese Details interessieren und sich im Moment nicht im Klaren sind, lesen Sie bitte weiter. Das Lesen dieses Artikels dauert etwa 10 bis 20 Minuten. Wenn Sie die Daten beim Lesen überprüfen, kann es etwa 30 Minuten dauern.Mindmap dieses Artikels
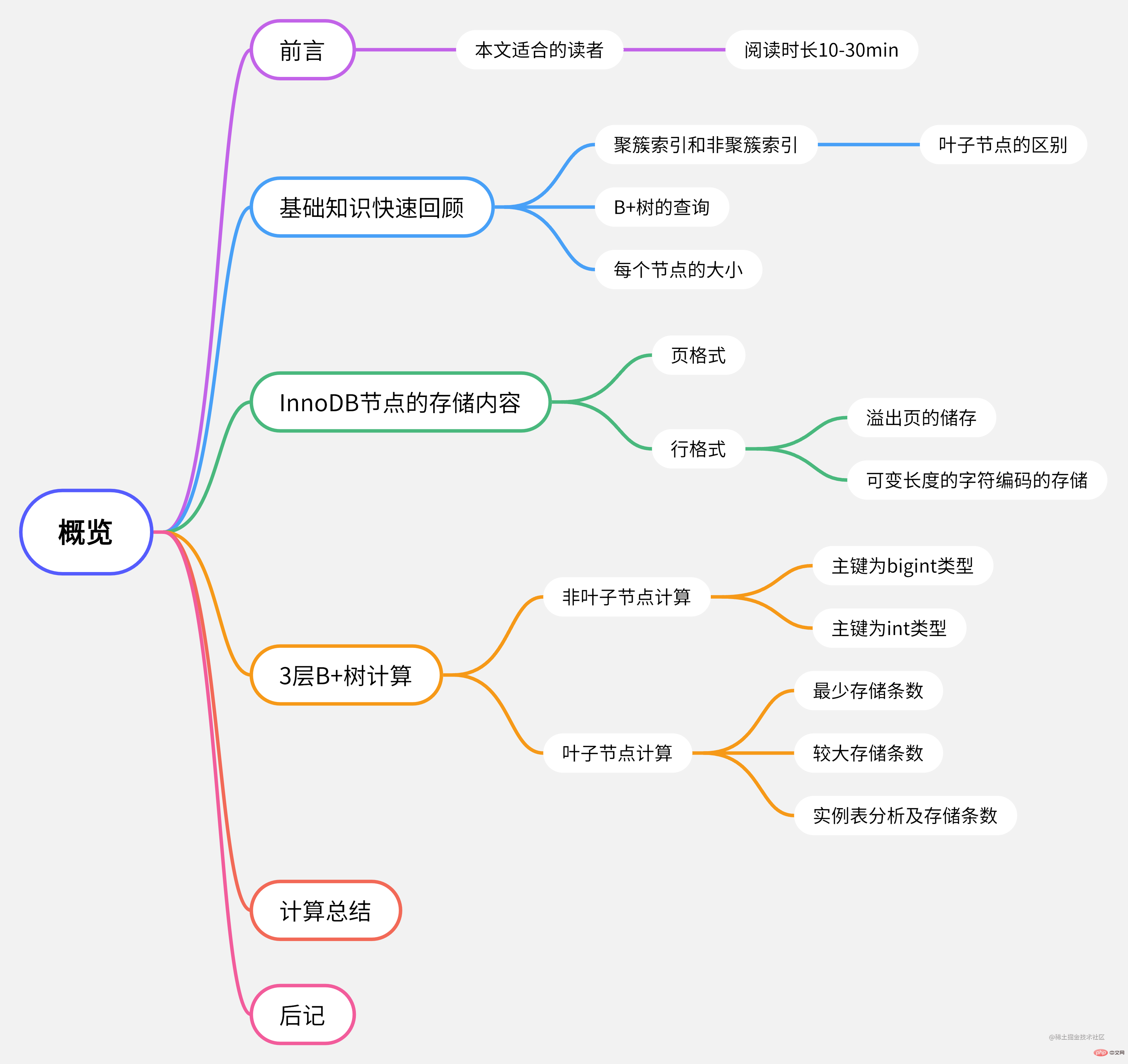
Kurzer Überblick über das Grundwissen
Hinweis: Der folgende Inhalt ist das Wesentliche. Schülern, die ihn nicht lesen oder verstehen können, wird empfohlen, diesen Artikel zuerst zu speichern und ihn dann erneut zu lesen, wenn sie über eine Wissensdatenbank verfügen.
Eine Datentabelle entspricht im Allgemeinen der Speicherung eines oder mehrerer Bäume. Die Anzahl der Bäume hängt von der Anzahl der Indizes ab.
Clusterierter Index und nicht gruppierter Index:
select * from table where id = 1, gehen wir immer zu den Blattknoten, um die Daten abzurufen. Deshalb berechnen wir die maximale Anzahl an Daten, die der dreischichtige B+-Baum von InnoDB speichern kann.
Wenn eine Zeile die maximale Zeilenlänge überschreitet, wird die Spalte mit variabler Länge auf externen Seiten gespeichert, bis die Zeile die maximale Zeilenlängenbeschränkung erreicht. Das heißt, Varchar und Text mit variabler Länge werden auf externen Seiten gespeichert, um die Datenlänge dieser Zeile zu reduzieren.

MySQL :: MySQL 5.7 Referenzhandbuch :: 14.12.2 Dateispeicherverwaltung
, im Vergleich zu Festplatten-E/A im Allgemeinen Sprechen, es kann ignoriert werden.
Im B+-Baum von Innodb heißt der Knoten, den wir oft aufrufen, Seite (Seite), jede Seite speichert Benutzerdaten und alle Seiten werden kombiniert. Zusammen bilden sie einen B+-Baum ( Natürlich wird es in der Realität viel komplizierter sein, aber wir müssen nur berechnen, wie viele Daten gespeichert werden können, damit wir es so verstehen können?).
Seite ist die kleinste Festplatteneinheit, die von der InnoDB-Speicher-Engine zum Verwalten der Datenbank verwendet wird. Wir sagen oft, dass jeder Knoten 16 KB groß ist, was tatsächlich bedeutet, dass die Größe jeder Seite 16 KB beträgt.
In diesem 16-KB-Speicherplatz müssen Informationen zum Seitenformat und zum Zeilenformat gespeichert werden. Die Informationen zum Zeilenformat enthalten auch einige Metadaten und Benutzerdaten. Deshalb müssen wir bei der Berechnung alle diese Daten einbeziehen.
Seitenformat
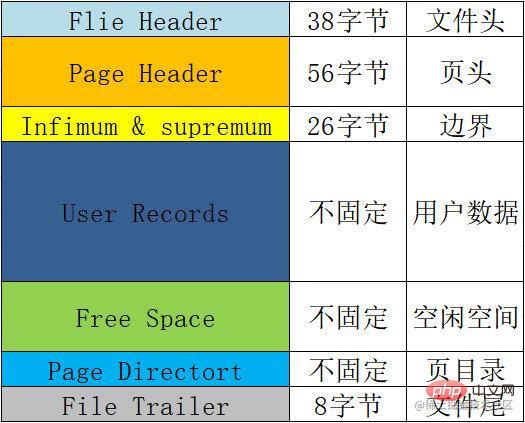
Das Grundformat jeder Seite, d. usw.
| 38 Bytes | Dateikopfzeile, wird zum Aufzeichnen einiger Kopfzeileninformationen der Seite verwendet. | |
|---|---|---|
File Header |
38字节 | 文件头,用来记录页的一些头信息。 包括校验和、页号、前后节点的两个指针、 页的类型、表空间等。 |
Page Header |
56字节 | 页头,用来记录页的状态信息。 包括页目录的槽数、空闲空间的地址、本页的记录数、 已删除的记录所占用的字节数等。 |
Infimum & supremum |
26字节 | 用来限定当前页记录的边界值,包含一个最小值和一个最大值。 |
User Records |
不固定 | 用户记录,我们插入的数据就存储在这里。 |
Free Space |
不固定 | 空闲空间,用户记录增加的时候从这里取空间。 |
Page Directort |
不固定 | 页目录,用来存储页当中用户数据的位置信息。 每个槽会放4-8条用户数据的位置,一个槽占用1-2个字节, 当一个槽位超过8条数据的时候会自动分成两个槽。 |
File TrailerSeitenkopf
|
56 Bytes | Seitenkopf, der zum Aufzeichnen von Seitenstatusinformationen verwendet wird. | Einschließlich der Anzahl der Slots im Seitenverzeichnis, der Adresse des freien Speicherplatzes, der Anzahl der Datensätze auf dieser Seite,
Infimum & Supremum🎜🎜26 Bytes🎜🎜 wird verwendet, um den Grenzwert des aktuellen Seitendatensatzes zu begrenzen, einschließlich eines Mindestwerts und eines Maximalwerts. 🎜🎜🎜🎜Benutzerdatensätze🎜🎜Nicht festgelegt🎜🎜Benutzerdatensätze, die von uns eingegebenen Daten werden hier gespeichert. 🎜🎜🎜🎜Freier Speicherplatz🎜🎜Nicht festgelegt🎜🎜Freier Speicherplatz. Wenn Benutzerdatensätze hinzugefügt werden, wird der Speicherplatz von hier aus übernommen. 🎜🎜🎜🎜Page Directort🎜🎜Unfixed🎜🎜Das Seitenverzeichnis wird zum Speichern der Standortinformationen von Benutzerdaten auf der Seite verwendet. 🎜Jeder Steckplatz fasst 4-8 Benutzerdaten und ein Steckplatz belegt 1-2 Bytes. 🎜Wenn ein Steckplatz mehr als 8 Daten enthält, wird er automatisch in zwei Steckplätze aufgeteilt. 🎜🎜🎜🎜Datei-Trailer🎜🎜8 Bytes🎜🎜Informationen zum Ende der Datei, die hauptsächlich zur Überprüfung der Seitenintegrität verwendet werden. 🎜🎜🎜🎜Schematische Darstellung:
Ich habe lange auf der offiziellen Website gesucht und konnte sie nicht finden. . . . Ich weiß nicht, ob es daran liegt, dass ich es nicht geschrieben habe oder weil ich blind bin. Wenn jemand es gefunden hat, hoffe ich, dass er mir helfen kann, es im Kommentarbereich zu veröffentlichen.
Der Tabelleninhalt im Format der obigen Seite basiert also hauptsächlich auf Erkenntnissen und Zusammenfassungen einiger Blogs.
Außerdem versucht InnoDB, wenn ein neuer Datensatz in einen InnoDB-Clusterindex eingefügt wird, 1/16 der Seite für zukünftige Einfügungen und Aktualisierungen von Indexdatensätzen frei zu lassen. Wenn die Indexdatensätze der Reihe nach (aufsteigend oder absteigend) eingefügt werden, verfügt die resultierende Seite über etwa 15/16 des verfügbaren Platzes. Wenn Datensätze in zufälliger Reihenfolge eingefügt werden, steht etwa die Hälfte bis 15/16 des Seitenplatzes zur Verfügung. Referenzdokumentation: MySQL :: MySQL 5.7 Referenzhandbuch :: 14.6.2.2 Die physische Struktur eines InnoDB-Index
Der belegte Speicher außer User Records和Free Space ist
Jede Datensatzzeile enthält Folgendes Informationen, die größtenteils in offiziellen Dokumenten zu finden sind. Was ich hier geschrieben habe, ist nicht sehr detailliert. Ich habe nur einige Kenntnisse geschrieben, die uns bei der Berechnung des Speicherplatzes helfen können. Für detailliertere Informationen können Sie online nach „MySQL-Zeilenformat“ suchen.
| Name | Leerzeichen | Bedeutung und Funktion usw. |
|---|---|---|
| Zeilendatensatz-Header-Informationen | 5 Bytes | Die Header-Informationen des Zeilendatensatzes enthalten einige Flag-Bits, Datentypen und andere Informationen wie zum Beispiel: Löschkennzeichen, Mindestdatensatzkennzeichen, sortierte Datensätze, Datentyp, Die Position des nächsten Datensatzes auf der Seite usw. |
| Feldliste mit variabler Länge | Nicht festgelegt | zum Speichern der belegten Bytes diese Felder mit variabler Länge Zahlen, wie Varchar, Text, Blob usw. Wenn die Länge des Felds variabler Länge weniger als 255 Bytes beträgt, wird es durch 1 Byte dargestellt. 1字节表示;若大于 255字节,用 2字节Wenn es größer als 255 Bytes ist, wird es durch 2 Bytes dargestellt. Code>. <br>Es gibt mehrere Felder variabler Länge in der Liste. Wenn keine vorhanden sind, werden sie nicht gespeichert.
|
| Nullwertliste | nicht festgelegt | wird verwendet, um zu speichern, ob ein Feld, das null sein kann, null ist. Jedes nullbare Feld belegt hier ein Bit, was die Idee der Bitmap ist. Der von dieser Liste belegte Speicherplatz wächst in Bytes, wenn beispielsweise 9 bis 16 nullable-Spalten vorhanden sind, werden zwei Bytes anstelle von 1,5 Bytes verwendet. |
| Transaktions-ID und Zeigerfeld | 6+7 Bytes | Freunde, die MVCC kennen, sollten wissen, dass die Datenzeile eine 6-Byte-Transaktions-ID und ein 7-Byte-Zeigerfeld enthält. Wenn der Primärschlüssel nicht definiert ist, gibt es ein zusätzliches 6-Byte-Zeilen-ID-Feld Natürlich haben wir alle einen Primärschlüssel, daher berechnen wir diese Zeilen-ID nicht. |
| Die tatsächlichen Daten | sind nicht festgelegt | Dieser Teil sind unsere tatsächlichen Daten. |
Schematische Darstellung:

Es gibt noch ein paar weitere Punkte zu beachten:
Hinweis: Dies ist eine Funktion von DYNAMIC.
Wenn Sie DYNAMIC zum Erstellen einer Tabelle verwenden, entfernt InnoDB die Werte längerer Spalten variabler Länge (z. B. VARCHAR-, VARBINARY-, BLOB- und TEXT-Typen) und speichert sie nur auf einer Überlaufseite Spalte Reserviert einen 20-Byte-Zeiger auf die Überlaufseite.
Das COMPACT-Zeilenformat (MySQL5.6-Standardformat) speichert die ersten 768 Bytes und den 20-Byte-Zeiger im Datensatz des B+-Baumknotens, der Rest wird auf der Überlaufseite gespeichert.
Ob eine Spalte außerhalb der Seite gespeichert wird, hängt von der Seitengröße und der Gesamtgröße der Zeilen ab. Wenn eine Zeile zu lang ist, wird die längste Spalte für die Off-Page-Speicherung ausgewählt, bis der gruppierte Indexdatensatz auf die B+-Baumseite passt (das Dokument sagt nicht, wie viele?). TEXT und BLOBs, die kleiner oder gleich 40 Byte sind, werden direkt in der Zeile gespeichert und nicht ausgelagert.
Das dynamische Zeilenformat vermeidet das Problem, B+-Baumknoten mit großen Datenmengen zu füllen, was zu langen Spalten führt.
Die Idee des DYNAMIC-Zeilenformats besteht darin, dass es normalerweise am effizientesten ist, den gesamten Wert außerhalb der Seite zu speichern, wenn ein Teil eines langen Datenwerts außerhalb der Seite gespeichert wird.
Mit dem DYNAMIC-Format werden nach Möglichkeit kürzere Spalten in B+-Baumknoten gehalten, wodurch die Anzahl der für eine bestimmte Zeile erforderlichen Überlaufseiten minimiert wird.
char, varchar, text usw. müssen den Zeichenkodierungstyp festlegen. Bei der Berechnung des belegten Speicherplatzes muss der von verschiedenen Kodierungen belegte Platz berücksichtigt werden.
varchar, text und andere Typen verfügen über eine Längenfeldliste, um die Länge aufzuzeichnen, die sie belegen, aber char ist ein Typ mit fester Länge, daher ist die Situation etwas Besonderes. Nehmen Sie dann an, dass der Feldname char(10) ist Die folgende Situation tritt auf:
Bei der Zeichenkodierung mit fester Länge (z. B. ASCII-Code) wird der Feldname in einem Format mit fester Länge gespeichert. Jedes Zeichen des ASCII-Codes belegt ein Byte, sodass der Name ein Byte einnimmt 10 Byte.
Für Zeichenkodierungen mit variabler Länge (z. B. utf8mb4) werden mindestens 10 Bytes für den Namen reserviert. Wenn möglich, speichert InnoDB es auf 10 Bytes, indem es abschließende Leerzeichen kürzt.
Wenn der Platz nach dem Zuschneiden nicht gespart werden kann, kürzen Sie die nachfolgenden Leerzeichen auf die minimale Bytelänge des Spaltenwerts (normalerweise 1 Byte). Die maximale Länge einer Spalte beträgt:
WortDas des Grad ×
Um ehrlich zu sein, verstehe ich das Design von char nicht ganz. Obwohl ich es schon lange gelesen habe, einschließlich offizieller Dokumente und einiger Blogs, hoffe ich, dass Studenten, die es verstehen, ihre Zweifel im Kommentarbereich klären können:
Für Zeichen mit variabler Länge Ist char in Bezug auf die Codierung nicht ein bisschen wie ein Typ mit variabler Länge? Das häufig verwendete utf8mb4 belegt 1 bis 4 Bytes, sodass der von char (10) belegte Speicherplatz 10 bis 40 Bytes beträgt. Diese Änderung ist ziemlich groß, lässt jedoch nicht genügend Platz dafür und ist auch nicht besonders Feldliste variabler Länge zum Aufzeichnen des Speicherplatzverbrauchs von Zeichenfeldern?
Okay, wir wissen bereits, was auf jeder Seite gespeichert ist, und jetzt haben wir die Möglichkeit zur Berechnung.
Da ich oben bereits den verbleibenden Platz der Seite im Seitenformat berechnet habe, stehen für jede Seite 15232 Bytes zur Verfügung. Berechnen wir direkt unten die Zeilen.
Berechnung des Nicht-Blattknotens
Die Indexseite ist der Knoten, in dem der Index gespeichert ist, dh der Nicht-Blattknoten.
Jeder Indexdatensatz enthält den Wert des aktuellen Index, eine 6-Byte-Zeigerinformation, einen 5-Byte-Zeilenkopf, der verwendet wird, um auf den Zeiger auf die nächste Ebene der Datenseite zu verweisen.
Ich habe den vom Zeiger belegten Platz im Indexdatensatz im offiziellen Dokument nicht gefunden? Ich verweise auf andere Blog-Beiträge für diese 6 Bytes. Sie sagten, dass es im Quellcode 6 Bytes sind, aber ich weiß es nicht. Ich weiß nicht, um welchen Abschnitt des Quellcodes es sich handelt.
Ich hoffe, dass Studierende, die mehr wissen, ihre Zweifel im Kommentarbereich klären können.
Angenommen, unsere Primärschlüssel-ID ist vom Typ Bigint, also 8 Bytes, dann ist der von jeder Datenzeile auf der Indexseite belegte Platz gleich Bytes. Auf jeder Seite können gespeichert werden
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Datenbank drei Paradigmen
Datenbank drei Paradigmen
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL



![MySQL-Abfrageoptimierungslösung [gelehrt von Architekten großer Hersteller] [Erste Schritte mit MySQL] Erweitertes Tutorial |](https://img.php.cn/upload/course/000/000/068/6242a7d5be236814.png)







![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



