

Vom Aufbau der Redis-Hochverfügbarkeitsarchitektur zur Prinzipanalyse

Dieser Artikel bringt Ihnen relevantes Wissen über Redis, das hauptsächlich die relevanten Inhalte vom Aufbau einer Hochverfügbarkeitsarchitektur bis zur Prinzipanalyse vorstellt. Ich hoffe, es wird für alle hilfreich sein.

Empfohlenes Lernen: Redis-Video-Tutorial
Aufgrund der jüngsten Systemoptimierung des Unternehmens arbeiten wir nun wieder an Redis, nachdem wir vor einiger Zeit die große Tabelle in Tabellen unterteilt haben. In Bezug auf Redis besteht eine der Anforderungen darin, den Redis-Dienst von Alibaba Cloud auf den unternehmenseigenen Server zu migrieren (aufgrund der Art des Unternehmens). Ich habe gerade diese Gelegenheit genutzt, um die Hochverfügbarkeits-Cluster-Architektur von Redis zu überprüfen. Es gibt drei Redis-Cluster-Modi, nämlich den Master-Slave-Replikationsmodus, den Sentinel-Modus und den Cluster-Cluster-Modus. Im Allgemeinen werden Sentinel- und Cluster-Cluster häufiger verwendet.
Persistenzmechanismus
Bevor wir die Clusterarchitektur verstehen, müssen wir zunächst den Persistenzmechanismus von Redis einführen, da die Persistenz im nachfolgenden Cluster eine Rolle spielt. Bei der Redis-Persistenz werden die im Speicher zwischengespeicherten Daten gemäß einigen Regeln gespeichert, um eine Datenwiederherstellung oder Master-Slave-Knotendatensynchronisierung in der Clusterarchitektur zu verhindern, wenn der Redis-Dienst ausfällt. Es gibt zwei Arten der Redis-Persistenz: RDB und AOF. Nach Version 4.0 wurde ein neuer Hybrid-Persistenzmodus eingeführt.
RDB
RDB ist der von Redis standardmäßig aktivierte Persistenzmechanismus. Seine Persistenzmethode besteht darin, Snapshots zu generieren und diese gemäß den vom Benutzer konfigurierten Regeln auf die Festplatte herunterzuladen. „Im Dump sind mindestens Y Änderungen aufgetreten. RDB-Binärdatei. Standardmäßig ist Redis mit drei Konfigurationen konfiguriert: Innerhalb von 900 Sekunden ist mindestens eine Cache-Schlüsseländerung aufgetreten, innerhalb von 300 Sekunden sind mindestens 10 Cache-Schlüsseländerungen aufgetreten und innerhalb von 60 Sekunden sind mindestens 10.000 Änderungen aufgetreten. <code>"X秒内至少发生过Y次改动",生成快照并落盘到dump.rdb二进制文件中。默认情况下,redis配置了三种,分别为900秒内至少发生过1次缓存key的改动,300秒内至少发生过10次缓存key的改动以及60秒内至少发生过10000次改动。

除了redis自动快照持久化数据外,还有两个命令可以帮助我们手动进行内存数据快照,这两个命令分别为save和bgsave。

save:以同步的方式进行数据快照,当缓存数据量大,会阻塞其他命令的执行,效率不高。
bgsave:以异步的方式进行数据快照,有redis主线程fork出一个子进程来进行数据快照,不会阻塞其他命令的执行,效率较高。由于是采用异步快照的方式,那么就有可能发生在快照的过程中,有其他命令对数据进行了修改。为了避免这个问题reids采用了写时复制(Cpoy-On-Write)的方式,因为此时进行快照的进程是由主线程fork出来的,所以享有主线程的资源,当快照过程中发生数据改动时,那么该数据会被复制一份并生成副本数据,子进程会将改副本数据写入到dump.rdb文件中。
RDB快照是以二进制的方式进行存储的,所以在数据恢复时,速度会比较快,但是它存在数据丢失的风险。假如设置的快照规则为60秒内至少发生100次数据改动,那么在50秒时,redis服务由于某种原因突然宕机了,那在这50秒内的所有数据将会丢失。
AOF
AOF是Redis的另一种持久化方式,与RDB不同时是,AOF记录着每一条更改数据的命令并保存到磁盘下的appendonly.aof文件中,当redis服务重启时,会加载该文将并再次执行文件中保存的命令,从而达到数据恢复的效果。默认情况下,AOF是关闭的,可以通过修改conf配置文件来进行开启。
# appendonly no 关闭AOF持久化 appendonly yes # 开启AOF持久化 # The name of the append only file (default: "appendonly.aof") appendfilename "appendonly.aof" # 持久化文件名
AOF提供了三种方式,可以让命令保存到磁盘。默认情况下,AOF采用appendfsync everysec
außer Zusätzlich zum automatischen Snapshot persistenter Daten durch Redis gibt es zwei Befehle, die uns dabei helfen können, Speicherdaten manuell zu snapshoten. Diese beiden Befehle sind save und bgsave. 
Speichern: Führen Sie Daten-Snapshots synchron durch. Wenn die Menge der zwischengespeicherten Daten groß ist, blockiert dies die Ausführung anderer Befehle und ist ineffizient.

- bgsave: Führen Sie Daten-Snapshots auf asynchrone Weise aus. Der Redis-Hauptthread gibt einen Unterprozess aus, um Daten-Snapshots zu erstellen. Er blockiert nicht die Ausführung anderer Befehle und ist effizienter. Da ein asynchroner Snapshot verwendet wird, ist es möglich, dass andere Befehle die Daten während des Snapshot-Vorgangs ändern. Um dieses Problem zu vermeiden, verwendet Reids die Copy-on-Write-Methode (Cpoy-On-Write). Da der Prozess, der den Snapshot erstellt, zu diesem Zeitpunkt vom Hauptthread gegabelt wird, nutzt er die Ressourcen des Hauptthreads Während des Snapshot-Prozesses treten Datenänderungen auf, dann werden die Daten kopiert und die Kopierdaten generiert, und der untergeordnete Prozess schreibt die geänderten Kopierdaten in die Datei dump.rdb.

appendfsync always #每次有新的改写命令时,都会追加到磁盘的aof文件中。数据安全性最高,但效率最慢。 appendfsync everysec # 每一秒,都会将改写命令追加到磁盘中的aof文件中。如果发生宕机,也只会丢失1秒的数据。 appendfsync no #不会主动进行命令落盘,而是由操作系统决定什么时候写入到磁盘。数据安全性不高。 Nach dem Login kopieren AOF bietet drei Möglichkeiten, Befehle auf der Festplatte zu speichern. Standardmäßig verwendet AOF die Methode appendfsync everysec für die Befehlspersistenz. |
Nachdem Sie AOF aktiviert haben, müssen Sie den Redis-Dienst neu starten. Wenn der entsprechende Rewrite-Befehl erneut ausgeführt wird, wird der Operationsbefehl in der AOF-Datei aufgezeichnet. | |
|---|---|---|
| Obwohl AOF im Vergleich zu RDB eine höhere Datensicherheit bietet, wird die Datei von AOF mit der weiteren Ausführung des Dienstes immer größer und die Geschwindigkeit wird bei der nächsten Wiederherstellung der Daten höher und schneller Je langsamer. Wenn sowohl RDB als auch AOF aktiviert sind, gibt Redis AOF beim Wiederherstellen von Daten Vorrang. Schließlich verliert AOF weniger Daten. | ||
| RDB | AOF | |
| Wiederherstellungseffizienz | Hoch | Niedrig |
混合模式
由于RDB持久化方式容易造成数据丢失,AOF持久化方式数据恢复较慢,所以在redis4.0版本后,新出来混合持久化模式。混合持久化将RDB和AOF的优点进行了集成,并而且依赖于AOF,所以在使用混合持久化前,需要开启AOF。在开启混合持久化后,当发生AOF重写时,会将内存中的数据以RDB的数据格式保存到aof文件中,在下一次的重写之前,混合持久化会追加保存每条改写命令到aof文件中。当需要恢复数据时,会加载保存的rdb内容数据,然后再继续同步aof指令。
# AOF重写配置,当aof文件达到60MB并且比上次重写后的体量多100%时自动触发AOF重写 auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb aof-use-rdb-preamble yes # 开启混合持久化# aof-use-rdb-preamble no # 关闭混合持久化
AOF重写是指当aof文件越来越大时,redis会自动优化aof文件中无用的命令,从而减少文件体积。比如在处理文章阅读量时,每查看一次文章就会执行一次Incr命令,但是随着阅读量的不断增加,aof文件中的incr命令也会积累的越来越多。在AOF重写后,将会删除这些没用的Incr命令,将这些命令直接替换为set key value命令。除了redis自动重写AOF,如果需要,也可以通过bgrewriteaof命令手动触发。
主从复制
在生产环境中,一般不会直接配置单节点的redis服务,这样压力太大。为了缓解redis服务压力,可以搭建主从复制,做读写分离。redis主从复制,是有一个主节点Master和多个从节点Slave组成。主从节点间的数据同步只能是单向传输的,只能由Master节点传输到Slave节点。
环境配置
准备三台linux服务器,其中一台作为redis的主节点,两台作为reids的从节点。如果没有足够的机器可以在同一台机器上面将redis文件多复制两份并更改端口号,这样可以搭建一个伪集群。
| IP | 主/从节点 | 端口 | 版本 |
|---|---|---|---|
| 192.168.36.128 | 主 | 6379 | 5.0.14 |
| 192.168.36.130 | 从 | 6379 | 5.0.14 |
| 192.168.36.131 | 从 | 6379 | 5.0.14 |
- 配置从节点36.130,36.131机器中reids.conf
修改redis.conf文件中的replicaof,配置主节点的ip和端口号,并且开启从节点只读。


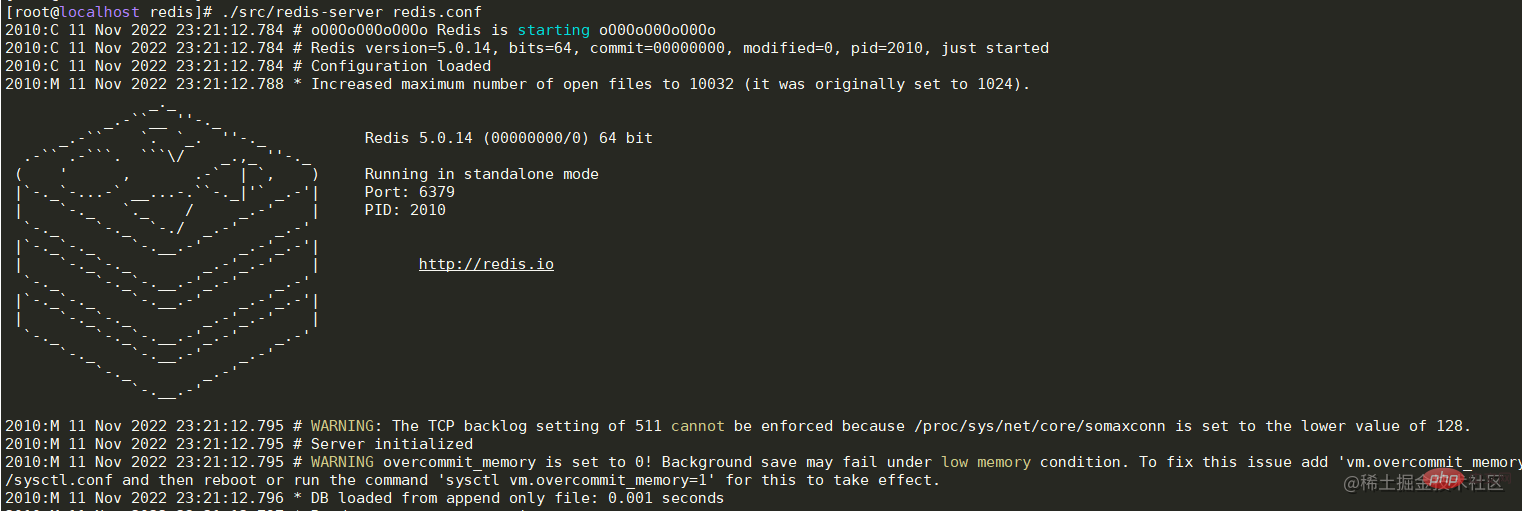
- 启动主节点36.128机器中reids服务
./src/redis-server redis.conf
 3. 依次启动从节点36.130,36.131机器中的redis服务
3. 依次启动从节点36.130,36.131机器中的redis服务
./src/redis-server redis.conf
启动成功后可以看到日志中显示已经与Master节点建立的连接。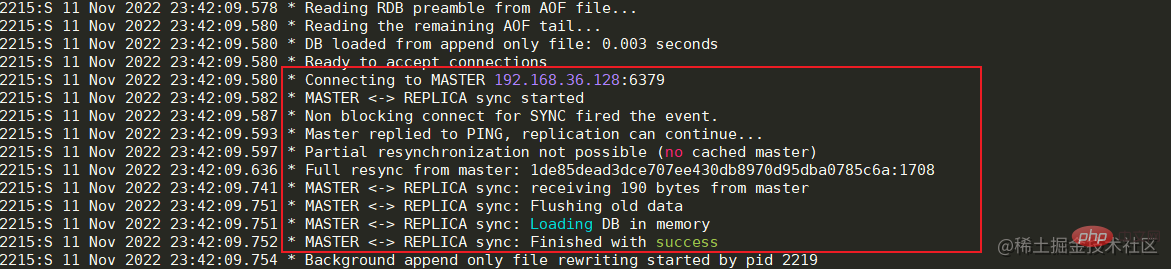 如果出现与Master节点的连接被拒,那么先检查Master节点的服务器是否开启防火墙,如果开启,可以开放6379端口或者关闭防火墙。如果防火墙被关闭但连接仍然被拒,那么可以修改Master节点服务中的redis.conf文件。将bing 127.0.0.1修改为本机对外的网卡ip或者直接注释掉即可,然后重启服务器即可。
如果出现与Master节点的连接被拒,那么先检查Master节点的服务器是否开启防火墙,如果开启,可以开放6379端口或者关闭防火墙。如果防火墙被关闭但连接仍然被拒,那么可以修改Master节点服务中的redis.conf文件。将bing 127.0.0.1修改为本机对外的网卡ip或者直接注释掉即可,然后重启服务器即可。

- 查看状态
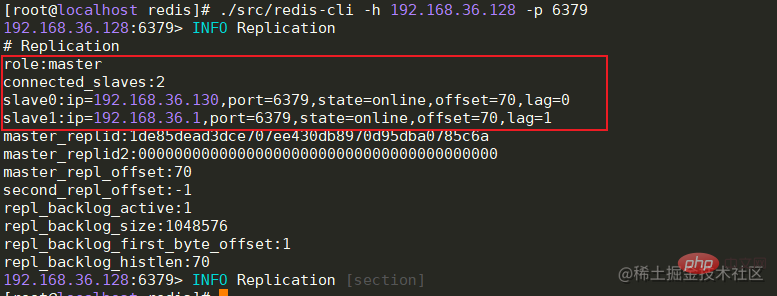
全部节点启动成功后,Master节点可以查看从节点的连接状态,offset偏移量等信息。
info replication # 主节点查看连接信息
数据同步流程
全量数据同步
主从节点之间的数据同步是通过建立socket长连接来进行传输的。当Slave节点启动时,会与Master节点建立长连接,并且发送psync同步数据命令。当Master节点收到psync命令时,会执行pgsave进行rdb内存数据快照(这里的rdb快照与conf文件中是否开启rdb无关),如果在快照过程中有新的改写命令,那么Master节点会将这些命令保存到repl buffer缓冲区中。当快照结束后,会将rdb传输给Slave节点。Slave节点在接收到rdb后,如果存在旧数据,那么会将这些旧数据清除并加载rdb。加载完成后会接受master缓存在repl buffer中的新命令。在这些步骤全部执行完成后,主从节点已经算连接成功了,后续Master节点的命令会不断的发送到Slave节点。如果在高并发的情况下,可能会存在数据延迟的情况。部分数据同步
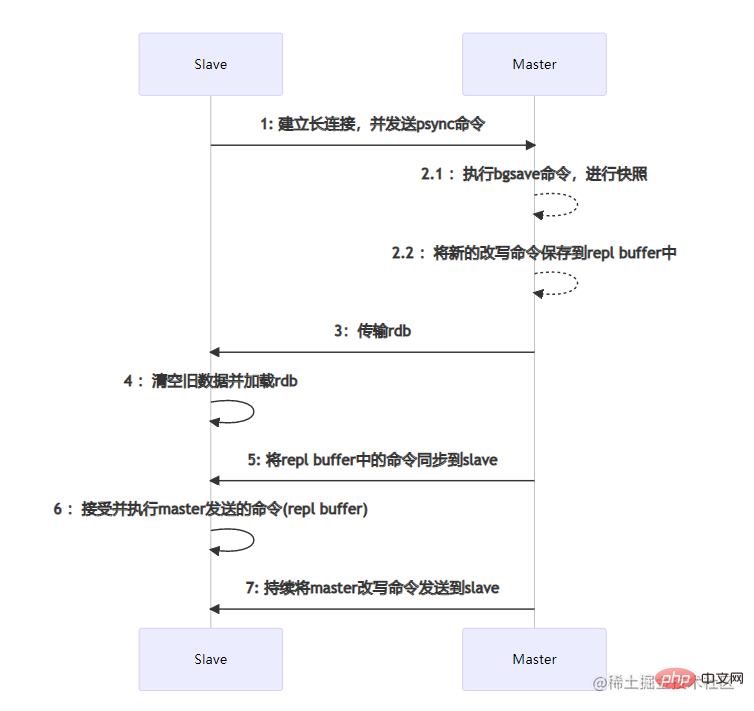 主从节点之间的数据同步是通过建立socket长连接来进行传输的。当Slave节点启动时,会与Master节点建立长连接,并且发送psync同步数据命令。当Master节点收到psync命令时,会执行pgsave进行rdb内存数据快照(这里的rdb快照与conf文件中是否开启rdb无关),如果在快照过程中有新的改写命令,那么Master节点会将这些命令保存到repl buffer缓冲区中。当快照结束后,会将rdb传输给Slave节点。Slave节点在接收到rdb后,如果存在旧数据,那么会将这些旧数据清除并加载rdb。加载完成后会接受master缓存在repl buffer中的新命令。在这些步骤全部执行完成后,主从节点已经算连接成功了,后续Master节点的命令会不断的发送到Slave节点。如果在高并发的情况下,可能会存在数据延迟的情况。
主从节点之间的数据同步是通过建立socket长连接来进行传输的。当Slave节点启动时,会与Master节点建立长连接,并且发送psync同步数据命令。当Master节点收到psync命令时,会执行pgsave进行rdb内存数据快照(这里的rdb快照与conf文件中是否开启rdb无关),如果在快照过程中有新的改写命令,那么Master节点会将这些命令保存到repl buffer缓冲区中。当快照结束后,会将rdb传输给Slave节点。Slave节点在接收到rdb后,如果存在旧数据,那么会将这些旧数据清除并加载rdb。加载完成后会接受master缓存在repl buffer中的新命令。在这些步骤全部执行完成后,主从节点已经算连接成功了,后续Master节点的命令会不断的发送到Slave节点。如果在高并发的情况下,可能会存在数据延迟的情况。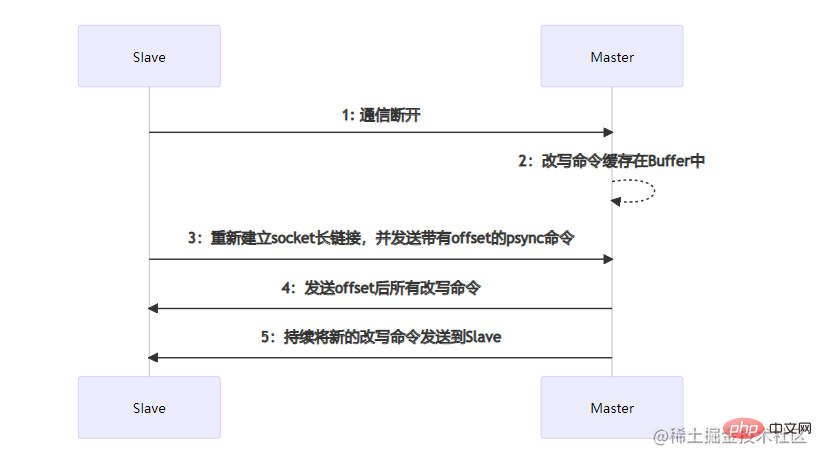
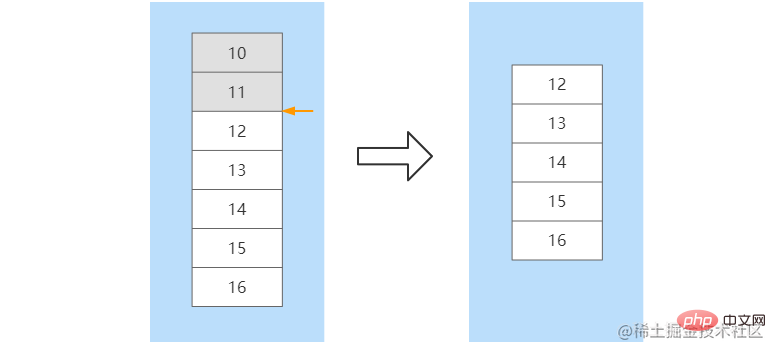
部分数据同步发生在Slave节点发生宕机,并且在短时间内进行了服务恢复。短时间内主从节点之间的数据差额不会太大,如果执行全量数据同步将会比较耗时。部分数据同步时,Slave会向Master节点建立socket长连接并发送带有一个offset偏移量的数据同步请求,这个offset可以理解数据同步的位置。Master节点在收到数据同步请求后,会根据offset结合buffer缓冲区内新的改写命令进行位置确定。如果确定了offset的位置,那么就会将这个位置往后的所有改写命令发送到Slave节点。如果没有确定offset的位置,那么会再次执行全量数据同步。比如,在Slave节点没有宕机之前命令已经同步到了offset=11这个位置,当该节点重启后,向Master节点发送该offset,Master根据offset在缓冲区中进行定位,在定位到11这个位置后,将该位置往后的所有命令发送给Slave。在数据同步完成后,后续Master节点的命令会不断的发送到该Slave节点
优缺点
-
优点
- 可以实现一主多从,读写分离,减轻Master节点读操作压力
- 是哨兵,集群架构的基础
-
缺点
- Es gibt keine automatische Master-Slave-Umschaltfunktion. Wenn der Master-Knoten ausfällt, müssen Sie den Master-Knoten manuell wechseln.
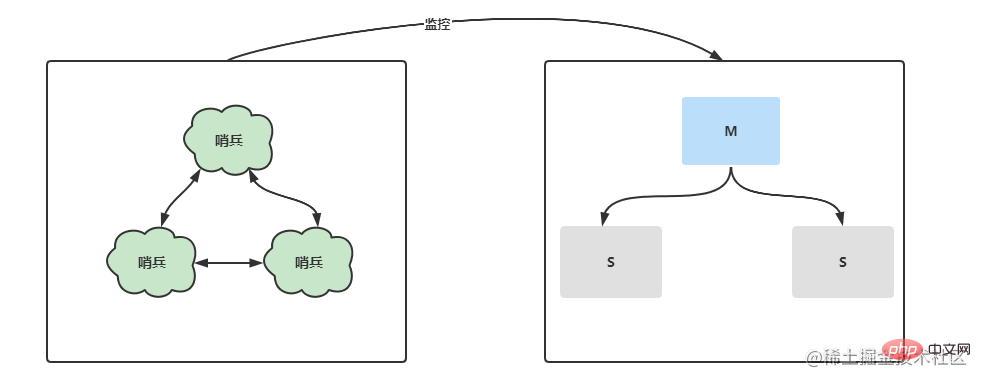
- Es kann leicht zu Dateninkonsistenzen kommen, wenn der Master-Knoten ausfällt Dies führt zu Datenverlust. Der Sentinel-Modus optimiert die Master-Slave-Replikation weiter und trennt einen separaten Sentinel-Prozess, um den Serverstatus in der Master-Slave-Architektur zu überwachen. Der Sentinel wählt in kurzer Zeit einen neuen Master-Knoten und führt eine Master-Slave-Umschaltung durch. Darüber hinaus überwacht jeder Sentinel unter einem Multi-Sentinel-Knoten einander und überwacht, ob der Sentinel-Knoten ausgefallen ist.
Umgebungskonfiguration
 IP
IP
Master/Slave-Knoten
| 192.1 68.36.12 8 | Meister | 6379 | ||
|---|---|---|---|---|
| von | 6379 | 26379 | 5.0.14 |


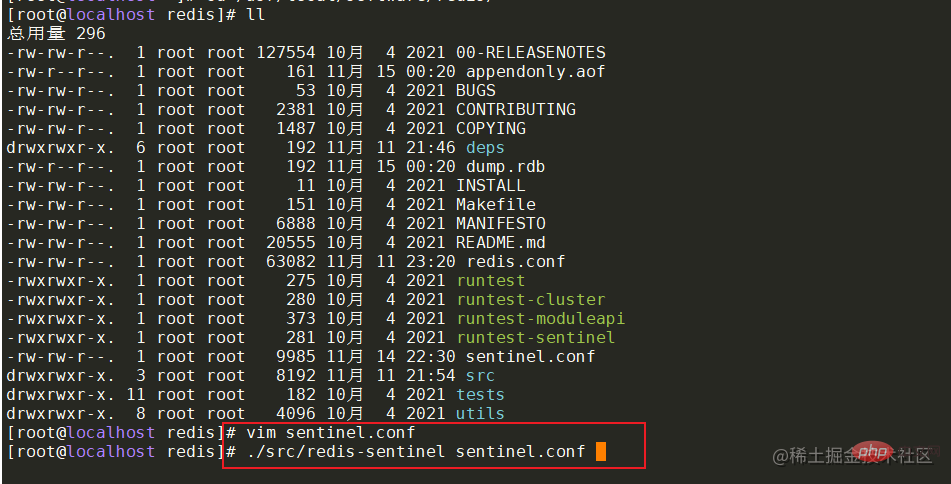
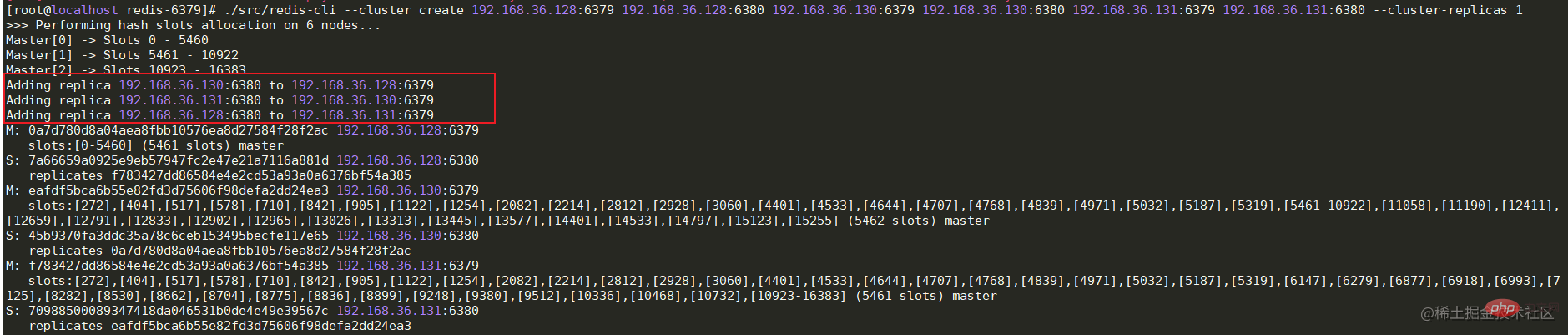
 搭建成功后,就来通过代码演示主节点宕机的情况下,哨兵是否会帮助系统自动进行主备切换。在springboot项目中引入对应的pom,并配置对应的redis哨兵信息。
搭建成功后,就来通过代码演示主节点宕机的情况下,哨兵是否会帮助系统自动进行主备切换。在springboot项目中引入对应的pom,并配置对应的redis哨兵信息。
| IP | Master/Slave 5.0 .14 | 192.168.36.128 | |
|---|---|---|---|
| 6380 | 5.0.14 | 192.168.36.131 | |
| 6379 | 5.0.14 | 192.168.36.131 | |
| 6380 | 5.0.14 |
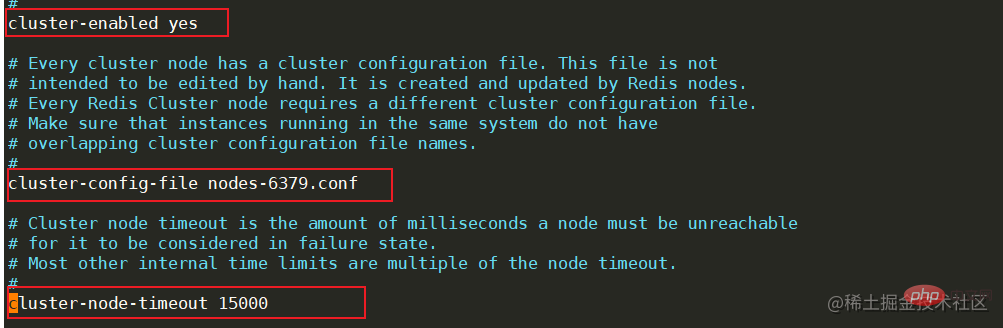




Das obige ist der detaillierte Inhalt vonVom Aufbau der Redis-Hochverfügbarkeitsarchitektur zur Prinzipanalyse. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So sehen Sie alle Schlüssel in Redis
Apr 10, 2025 pm 07:15 PM
So sehen Sie alle Schlüssel in Redis
Apr 10, 2025 pm 07:15 PM
Um alle Schlüssel in Redis anzuzeigen, gibt es drei Möglichkeiten: Verwenden Sie den Befehl keys, um alle Schlüssel zurückzugeben, die dem angegebenen Muster übereinstimmen. Verwenden Sie den Befehl scan, um über die Schlüssel zu iterieren und eine Reihe von Schlüssel zurückzugeben. Verwenden Sie den Befehl Info, um die Gesamtzahl der Schlüssel zu erhalten.
 So starten Sie den Server mit Redis
Apr 10, 2025 pm 08:12 PM
So starten Sie den Server mit Redis
Apr 10, 2025 pm 08:12 PM
Zu den Schritten zum Starten eines Redis -Servers gehören: Installieren von Redis gemäß dem Betriebssystem. Starten Sie den Redis-Dienst über Redis-Server (Linux/macOS) oder redis-server.exe (Windows). Verwenden Sie den Befehl redis-cli ping (linux/macOS) oder redis-cli.exe ping (Windows), um den Dienststatus zu überprüfen. Verwenden Sie einen Redis-Client wie Redis-Cli, Python oder Node.js, um auf den Server zuzugreifen.
