

In diesem Artikel geht es um die verschiedenen I/O-Modelle in Node und um die Seele von Node – nicht blockierendes asynchrones IO. Ich hoffe, dass es für alle hilfreich ist!
 ...
...
Die Anwendung erhält ein Operationsergebnis, das normalerweise zwei verschiedene Phasen umfasst: Warten, bis die Daten bereit sind
Daten vom Kernel in den Prozess kopieren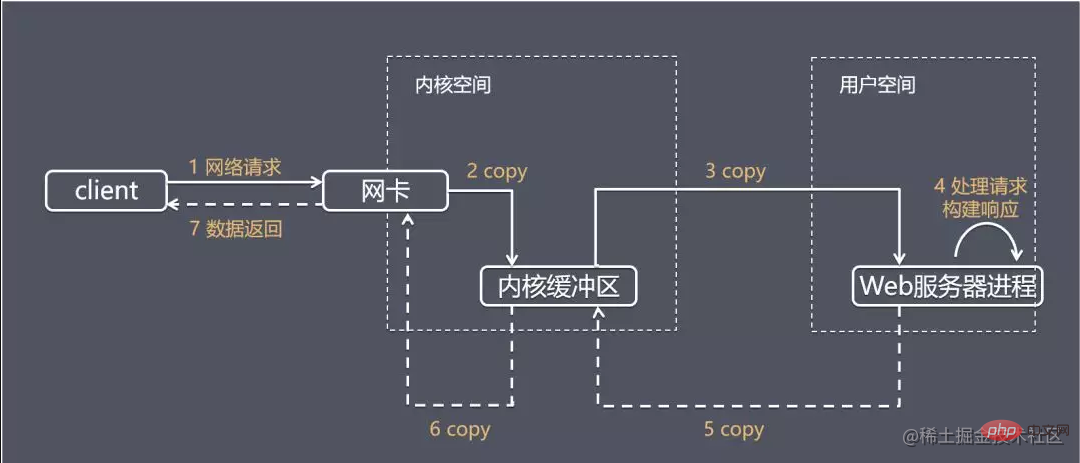
als Beispiel zur Erläuterung verschiedener E/A-Modelle
I/O
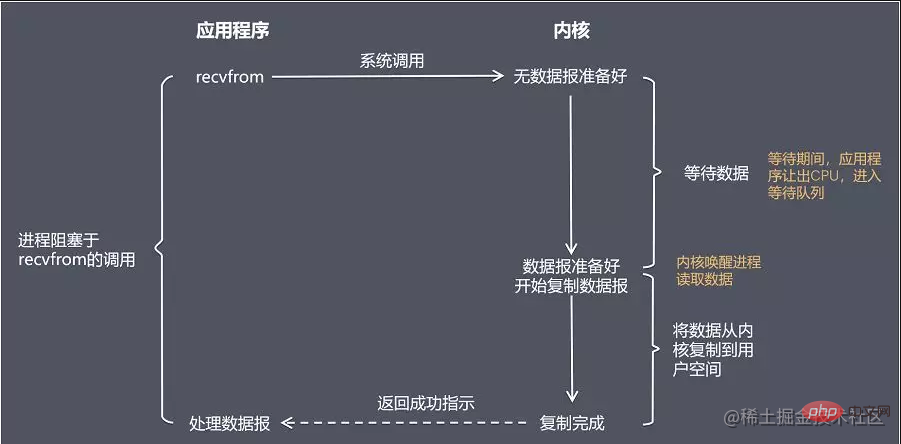
bedeutet, dass der aktuelle Thread angehalten wird, bevor das Aufrufergebnis zurückgegeben wird, und der aufrufende Thread dies tun kann Warten Sie nur auf alle Vorgänge auf Systemkernebene. recvfrom
Nicht blockierendes E/A-Modell (nicht blockierende E/A)Im Vergleich zum ersteren gibt nicht blockierende E/Adirekt ohne Daten zurück, Sie müssen auch a übergeben Dateideskriptor Nachdem versucht wurde, die Daten erneut zu lesen
 nicht blockierender Aufruf
nicht blockierender Aufruf
Um vollständige Daten zu erhalten, muss die Anwendung wiederholt den E/A-Vorgang aufrufen, um zu bestätigen, ob der Vorgang abgeschlossen ist. Mehrere gängige Abfragestrategien sind wie folgt:
Busy Polling
Dies ist die primitivste und leistungsschwächste Methode. Sie überprüft den E/A-Status durch wiederholte Aufrufe, um vollständige Daten zu erhalten. Vorteile: Einfache Programmierung. Nachteile: Die CPU wird beim Abfragen immer beansprucht Leistung, da der Server nach Ihrer Abfrage immer noch antworten muss
I/O-Multiplexing-Modell (I/O-Multiplexing)Im I/O-Multiplexing-Modell wird die Select- oder Poll-Funktion oder die Epoll-Funktion (unterstützt von) verwendet (im Linux-Kernel nach 2.6) blockieren diese beiden Funktionen ebenfalls den Prozess, unterscheiden sich jedoch vom Blockieren von E/A.

 poll
poll
ist der effizienteste E/A-Ereignisbenachrichtigungsmechanismus unter Linux. Wenn während der Abfrage kein E/A-Ereignis erkannt wird, bleibt es im Ruhezustand, bis ein Ereignis eintritt und der Thread aufwacht. Es nutzt Ereignisbenachrichtigungen wirklich aus und führt Rückrufe aus, anstatt (Dateideskriptor-)Abfragen zu durchlaufen, sodass keine CPU verschwendet wird
Zusammenfassung: Im Wesentlichen ist Polling immer noch ein synchroner Vorgang, da die Anwendung immer noch auf die vollständige Rückkehr der E/A wartet. Während der Wartezeit durchläuft sie entweder den Dateibeschreibungsstatus oder schläft, um auf das Eintreten des Ereignisses zu warten .

Im signalgesteuerten E/A-Modell verwendet die Anwendung Signale zum Ansteuern von E/A und installiert eine Signalverarbeitungsfunktion. Der Prozess läuft ohne Blockierung weiter.
Wenn die Daten bereit sind, empfängt das Programm ein SIGIO-Signal und kann die E/A-Operationsfunktion in der Signalverarbeitungsfunktion aufrufen, um die Daten zu verarbeiten.
Zusammenfassung: Bisher entspricht das signalgesteuerte E/A-Modell eher unseren asynchronen Anforderungen. Das Programm führt andere Geschäftslogik asynchron aus, während es auf Daten wartet.
Aber! ! ! Während des Kopiervorgangs von Daten vom Kernel in den Benutzerbereich ist er immer noch blockiert, was keine vollständige Revolution darstellt (asynchron).
Unsere ideale asynchrone E/A sollte ein nicht blockierender Aufruf sein, der von der Anwendung initiiert wird, ohne dass Daten durch Abfragen abgerufen werden müssen und es keine Notwendigkeit gibt, sie zu kopieren Daten in der Phase Anstatt unnötig zu warten, können die E/A-Vorgänge nach Abschluss der E/A über ein Signal oder eine Rückruffunktion an die Anwendung übergeben werden, während die Anwendung andere Geschäftslogik ausführen kann.

Tatsächlich unterstützt die Linux-Plattform nativ asynchrone E/A (AIO), aber derzeit ist AIO nicht perfekt, sodass es bei der Implementierung von Netzwerkprogrammierung mit hoher Parallelität unter Linux hauptsächlich so ist /O Wiederverwendungsmodell.
Unter Windows wird echte asynchrone E/A über IOCP implementiert.
Unter der Linux-Plattform verwendet Node den Thread-Pool, um die Datenerfassung abzuschließen, indem er einige Threads blockierende E/A oder nicht blockierende E/A + Abfragen durchführen lässt Ein einzelner Thread führt Berechnungen durch und überträgt E/A-Ergebnisse durch Kommunikation zwischen Threads, wodurch die Simulation asynchroner E/A realisiert wird.
Tatsächlich wird die unterste Ebene der asynchronen IOCP-Lösung unter der Windows-Plattform auch mithilfe eines Thread-Pools implementiert. Der Unterschied besteht darin, dass der Thread-Pool des letzteren vom Systemkernel gehostet wird.
Wir sagen oft, dass Node Single-Threaded ist, aber tatsächlich kann man nur sagen, dass JS in einem einzelnen Thread ausgeführt wird Unabhängig davon, ob es sich um eine *nix- oder eine Windows-Plattform handelt, verwendet die unterste Ebene einen Thread-Pool um E/A-Vorgänge abzuschließen.
Weitere Informationen zu Knoten finden Sie unter: nodejs-Tutorial!
Das obige ist der detaillierte Inhalt vonMachen Sie sich mit der nicht blockierenden asynchronen E/A in Nodejs vertraut. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 die Funktionsnutzung
die Funktionsnutzung
 Der Unterschied zwischen der Win10-Home-Version und der Professional-Version
Der Unterschied zwischen der Win10-Home-Version und der Professional-Version
 Mindestkonfigurationsanforderungen für das Win10-System
Mindestkonfigurationsanforderungen für das Win10-System
 Wie man Go-Sprache von Grund auf lernt
Wie man Go-Sprache von Grund auf lernt
 So verwenden Sie die Dekodierfunktion
So verwenden Sie die Dekodierfunktion
 Metasuchmaschine
Metasuchmaschine
 Sequenznummer der zusammengeführten Zellenfüllung
Sequenznummer der zusammengeführten Zellenfüllung
 Was soll ich tun, wenn sich mein Computer nicht einschalten lässt?
Was soll ich tun, wenn sich mein Computer nicht einschalten lässt?
 ERR_CONNECTION_REFUSED
ERR_CONNECTION_REFUSED












![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



