

Dieser Artikel vermittelt Ihnen relevantes Wissen über Python, das hauptsächlich relevantes Wissen über Crawler vorstellt. Einfach ausgedrückt: Crawler sind ein Name für den Prozess der Verwendung von Programmen zum Abrufen von Daten im Internet. Ich hoffe, es hilft allen .

Ein Crawler ist einfach eine Bezeichnung für den Prozess, bei dem mithilfe eines Programms Daten im Internet abgerufen werden.
Wenn wir Daten im Internet abrufen möchten, müssen wir dem Crawler eine Website-Adresse (im Programm normalerweise URL genannt) geben. Der Crawler sendet eine HTTP-Anfrage an den Server der Zielwebseite , und der Server gibt die Daten an den Client (d. h. unseren Crawler) zurück. Der Crawler führt dann eine Reihe von Vorgängen aus, z. B. Datenanalyse und -speicherung.
Crawler können uns Zeit sparen, wenn wir beispielsweise die 250 besten Douban-Filme erhalten möchten und wir keinen Crawler verwenden, müssen wir zuerst die URL der Douban-Filme im Browser und im Client eingeben (Browser) findet Douban durch Parsen und stellt dann eine Verbindung mit ihm her. Der Browser erstellt eine HTTP-Anfrage und sendet sie an den Douban Movie-Server Nehmen Sie die Top250-Liste aus der Datenbank, kapseln Sie sie in eine HTTP-Antwort und geben Sie dann das Antwortergebnis an den Browser zurück. Der Browser zeigt den Antwortinhalt an und wir sehen die Daten. Auch unser Crawler basiert auf diesem Verfahren, allerdings wird es in Codeform umgewandelt.
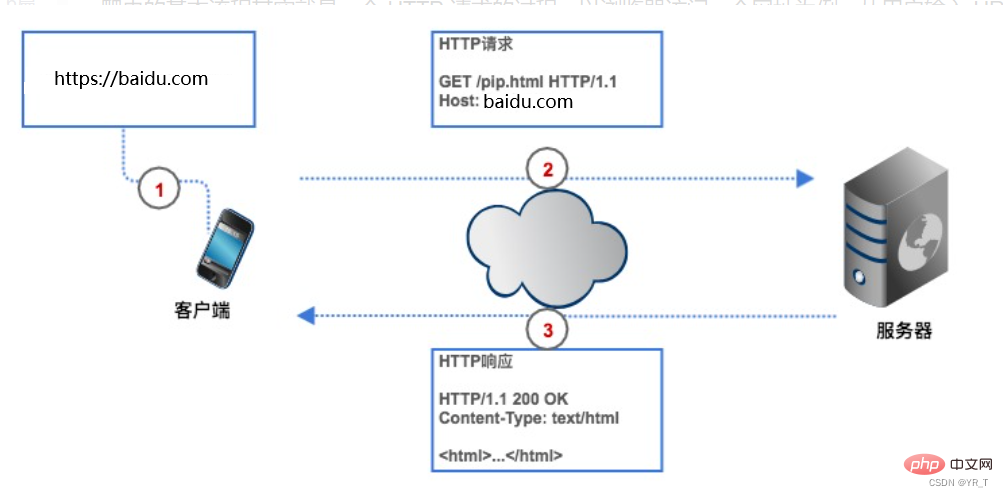
HTTP-Anfrage besteht aus Anfragezeile, Anfrageheader, Leerzeile und Anfragetext.

Die Anforderungszeile besteht aus drei Teilen:
1. Anforderungsmethode, gängige Anforderungsmethoden sind GET, POST, PUT, DELETE, HEAD
2. Der Ressourcenpfad, den der Client erhalten möchte
3. Wird verwendet von der Client Die Versionsnummer des HTTP-Protokolls
Der Anforderungsheader ist eine ergänzende Beschreibung der vom Client an den Server gesendeten Anforderung, beispielsweise die Identität des Besuchers, die weiter unten erläutert wird.
Der Anforderungstext besteht aus den vom Client an den Server übermittelten Daten, z. B. den Konto- und Kennwortinformationen, die der Benutzer beim Anmelden erhöhen muss. Der Anforderungsheader und der Anforderungstext sind durch Leerzeilen getrennt. Der Anfragetext ist nicht in allen Anfragen enthalten. Beispielsweise verfügt das allgemeine GET nicht über einen Anfragetext.
Das Bild oben zeigt die HTTP-POST-Anfrage, die an den Server gesendet wird, wenn sich der Browser bei Douban anmeldet. Der Benutzername und das Passwort werden im Anfragetext angegeben.
Das HTTP-Antwortformat ist dem Anforderungsformat sehr ähnlich und besteht außerdem aus Antwortzeilen, Antwortheadern, Leerzeilen und Antworttexten.

Die Antwortzeile enthält außerdem drei Teile, nämlich die HTTP-Versionsnummer des Servers, den Antwortstatuscode und die Statusbeschreibung.
Hier gibt es eine Tabelle mit Statuscodes, die der Bedeutung jedes Statuscodes entspricht



Der zweite Teil ist der Antwortheader. Der Antwortheader entspricht dem Anforderungsheader und ist zusätzlich Anweisungen vom Server für die Antwort, wie z. B. welches Format der Antwortinhalt hat, wie lang der Antwortinhalt ist, wann er an den Client zurückgegeben wird und sogar einige Cookie-Informationen werden im Antwortheader platziert.
Der dritte Teil ist der Antworttext, bei dem es sich um die eigentlichen Antwortdaten handelt. Diese Daten sind eigentlich der HTML-Quellcode der Webseite.
Crawler können viele Sprachen wie Python, C++ usw. verwenden, aber ich denke, Python ist die einfachste,
Da Python über vorgefertigte Bibliotheken verfügt, die nahezu perfekt verpackt sind,
Obwohl C++ auch vorgefertigte Bibliotheken hat, sind ihre Crawler immer noch relativ Nischenbibliotheken. Die einzigen Bibliotheken, die sie haben, sind nicht einfach genug und der Code ist nicht sehr kompatibel mit verschiedenen Compilern oder sogar verschiedenen Versionen desselben Compilers , daher ist es nicht besonders gut zu gebrauchen. Deshalb stellen wir heute hauptsächlich den Python-Crawler vor.
cmd ausführen: PIP-Installationsanfragen, um Anfragen zu installieren.
Dann geben Sie
Importanforderungen auf IDLE oder einen Compiler (ich persönlich empfehle VS Code oder Pycharm) ein, um ihn auszuführen. Wenn kein Fehler gemeldet wird, ist die Installation erfolgreich.
Die Methode zum Installieren der meisten Bibliotheken ist: pip install xxx (Name der Bibliothek)
| requests.request() | Erstellen Sie eine Anfrage und unterstützen Sie die grundlegenden Methoden jeder Methode |
| requests.get() | Die Hauptmethode zum Abrufen von HTML-Webseiten, entsprechend HTTPs GET |
requests.head() |
Die Methode zum Abrufen der Header-Informationen der HTML-Webseite, entsprechend dem HEAD von HTTP |
| requests.post() | Die Methode zum Senden eines POST Anfrage an die HTML-Webseite, entsprechend HTTP POST |
| requests.put() | Senden Sie eine PUT-Anfrage an eine HTML-Webseite, entsprechend HTTPs PUT |
| requests.patch() | Senden Sie eine teilweise Änderungsanforderung an eine HTML-Webseite, entsprechend HTTP PATCT |
| requests.delete() | sendet eine Löschanforderung an eine HTML-Webseite, entsprechend HTTPs DELETE |
r = Anfragen .get(url)
enthält zwei wichtige Objekte:
Erstellen Sie ein Request-Objekt, um Ressourcen vom Server anzufordern; geben Sie ein Antwortobjekt zurück, das Serverressourcen enthält.
| r.status_code | Der Rückgabestatus der HTTP-Anfrage. 200 bedeutet, dass die Verbindung erfolgreich ist, 404 bedeutet Fehler. |
| r.text | Die Zeichenfolgenform des HTTP-Antwortinhalts, dh der Seiteninhalt, der der URL entspricht Kodierungsmethode, die aus dem HTTP-Header erraten wird (wenn der Zeichensatz nicht im Header vorhanden ist, dann erwägen Sie die Kodierung nach ISO-8859-1) |
| Die binäre Form des HTTP-Antwortinhalts | |
| requests.ConnectionError | |
| requests .HTTPError |
| URL fehlt Ausnahme | |
| Die maximale Anzahl von Weiterleitungen wurde überschritten, was zu einer Weiterleitungsausnahme führte | |
| Timeout Ausnahme beim Herstellen einer Verbindung zum Remote-Server | |
| Die Anforderungs-URL ist abgelaufen, was zu einer Timeout-Ausnahme geführt hat | |
| Crawler kleine Demo | requests ist die einfachste Crawler-Bibliothek, aber wir können eine erstellen einfache Übersetzung |
| Das Folgende ist der Quellcode des Übersetzungsteils |
[
{xx:xx} , {xx:xx} , {xx: xx } , {xx:xx} 
}
Die Stelle, die ich rot markiert habe, sind die Informationen, die wir benötigen. 
dic_lenth = len(ch['data']
for i in range(dic_lenth):
print("词:"+ch['data'][i]['k']+" "+"单词意思:"+ch['data'][i]['v'])# -*- coding:utf-8 -*-
import requests
import bs4
def get_web(url):
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36 Edg/91.0.864.59"}
res = requests.get(url, headers=header, timeout=5)
# print(res.encoding)
content = res.text.encode('ISO-8859-1')
return content
def parse_content(content):
soup = bs4.BeautifulSoup(content, 'lxml')
'''
存放天气情况
'''
list_weather = []
weather_list = soup.find_all('p', class_='wea')
for i in weather_list:
list_weather.append(i.text)
'''
存放日期
'''
list_day = []
i = 0
day_list = soup.find_all('h1')
for each in day_list:
if i <= 6:
list_day.append(each.text.strip())
i += 1
# print(list_day)
'''
存放温度:最高温度和最低温度
'''
tem_list = soup.find_all('p', class_='tem')
i = 0
list_tem = []
for each in tem_list:
if i == 0:
list_tem.append(each.i.text)
i += 1
elif i > 0:
list_tem.append([each.span.text, each.i.text])
i += 1
# print(list_tem)
'''
存放风力
'''
list_wind = []
wind_list = soup.find_all('p', class_='win')
for each in wind_list:
list_wind.append(each.i.text.strip())
# print(list_wind)
return list_day, list_weather, list_tem, list_wind
def get_content(url):
content = get_web(url)
day, weather, tem, wind = parse_content(content)
item = 0
for i in range(0, 7):
if item == 0:
print(day[i]+':\t')
print(weather[i]+'\t')
print("今日气温:"+tem[i]+'\t')
print("风力:"+wind[i]+'\t')
print('\n')
item += 1
elif item > 0:
print(day[i]+':\t')
print(weather[i] + '\t')
print("最高气温:"+tem[i][0]+'\t')
print("最低气温:"+tem[i][1] + '\t')
print("风力:"+wind[i]+'\t')
print('\n')【Verwandte Empfehlungen:
Python3-Video-Tutorial】
Das obige ist der detaillierte Inhalt vonVerstehen Sie den Python-Crawler in einem Artikel. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



