
 🎜
🎜
Eine eingehende Analyse von Stream in Node

Was ist Flow? Wie versteht man den Fluss? Der folgende Artikel wird Ihnen ein tiefgreifendes Verständnis von Streams in Nodejs vermitteln. Ich hoffe, er wird Ihnen hilfreich sein!

Stream ist eine abstrakte Datenschnittstelle, die EventEmitter erbt. Sie kann Daten senden/empfangen, wie unten gezeigt: 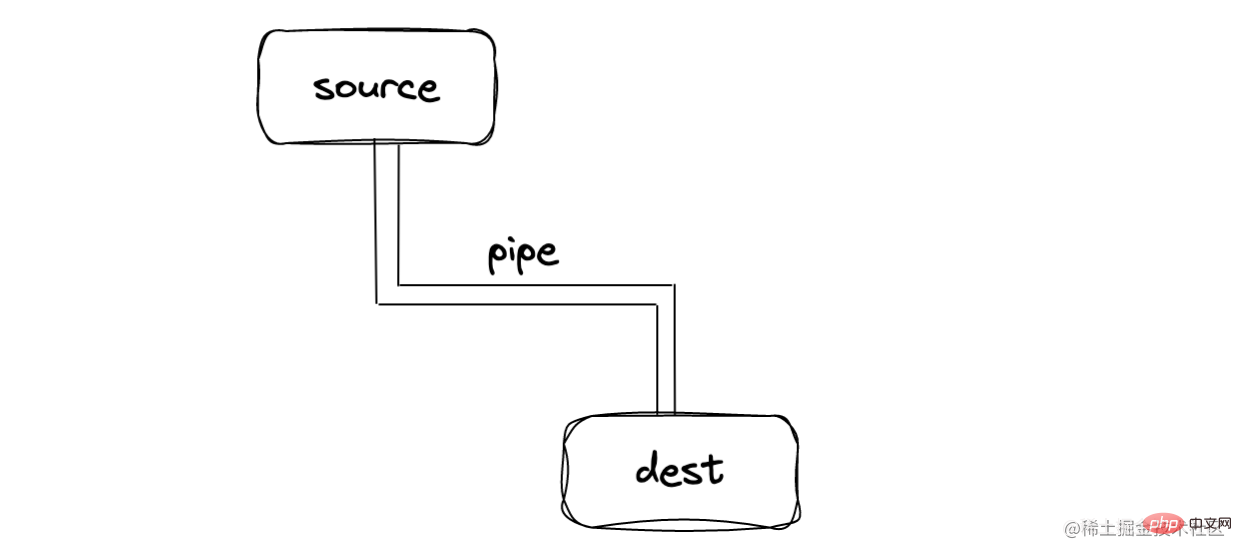
Stream ist kein einzigartiges Konzept in Node, sondern ein Betriebssystem . Die grundlegendste Betriebsmethode in Linux |. ist Stream, aber sie ist auf Knotenebene gekapselt und stellt die entsprechende API bereit
Warum müssen wir es Stück für Stück tun?
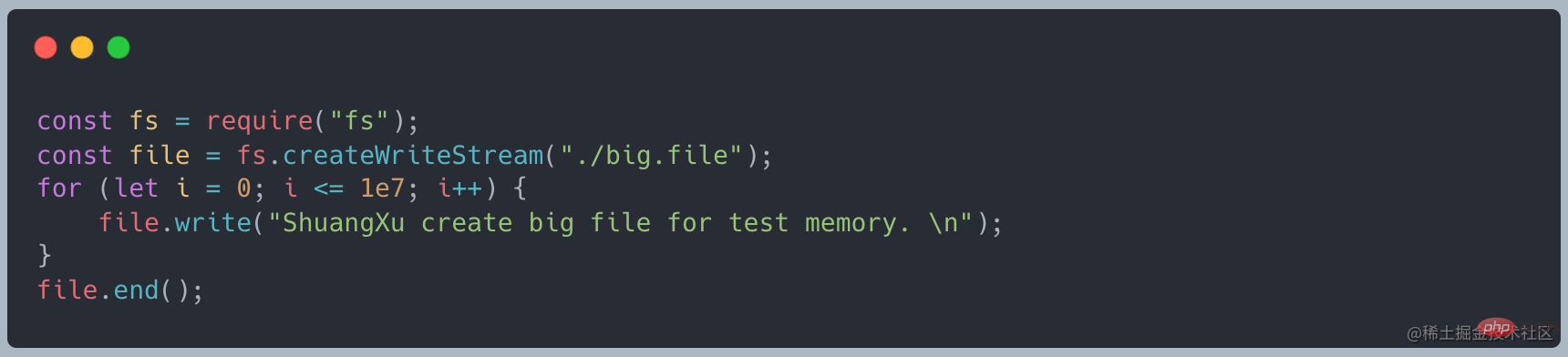
Verwenden Sie zunächst den folgenden Code, um eine Datei mit einer Größe von ca. 400 MB zu erstellen [Empfehlung für entsprechende Tutorials: nodejs-Video-Tutorial]
Wenn wir readFile zum Lesen verwenden, ist der folgende Code
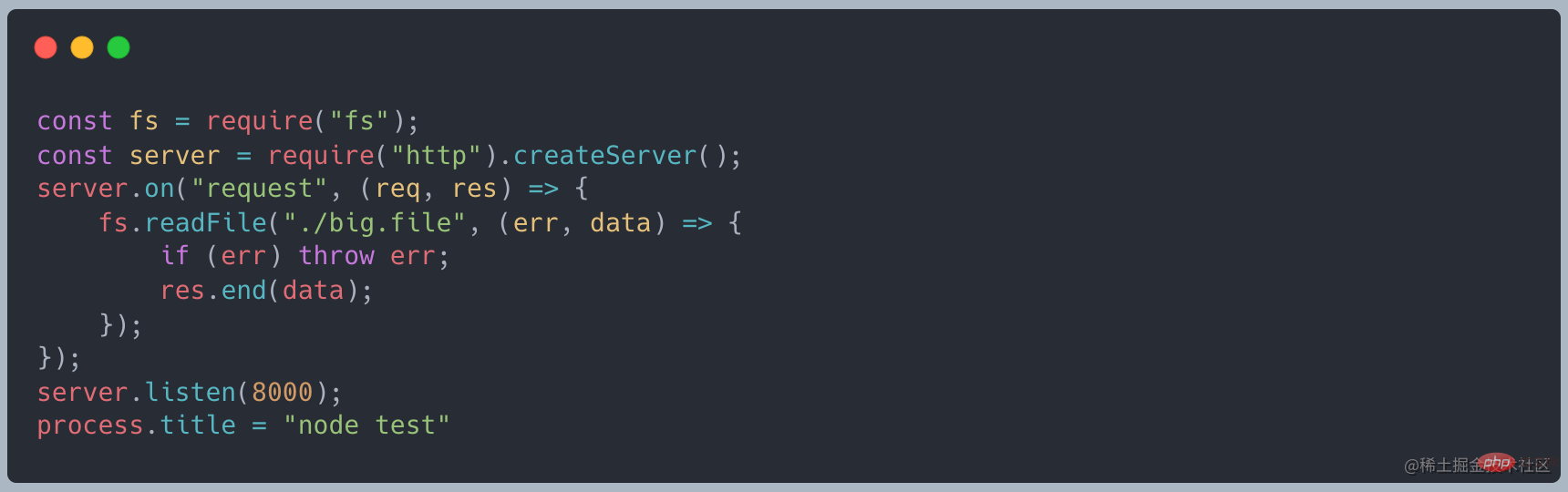
normal. Beim Start Der Dienst belegt etwa 10 MB Speicher.
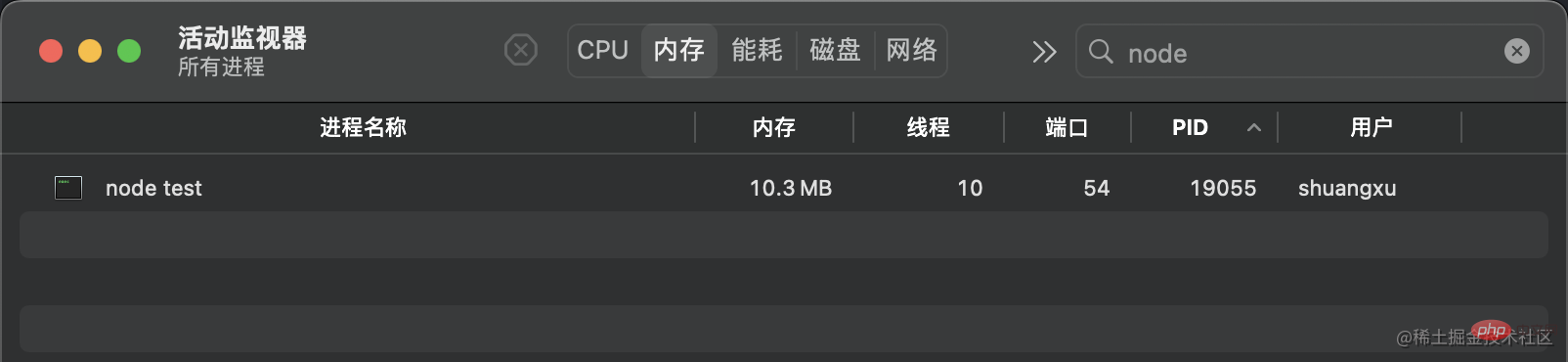
Wenn Sie curl http://127.0.0.1:8000 verwenden, um eine Anfrage zu initiieren, beträgt der Speicher etwa 420 MB, was ungefähr dem gleichen Wert entspricht Größe wie die von uns erstellte Datei. lazy"/>curl http://127.0.0.1:8000发起请求时,内存变为了 420MB 左右,和我们创建的文件大小差不多

改为使用使用 stream 的写法,代码如下
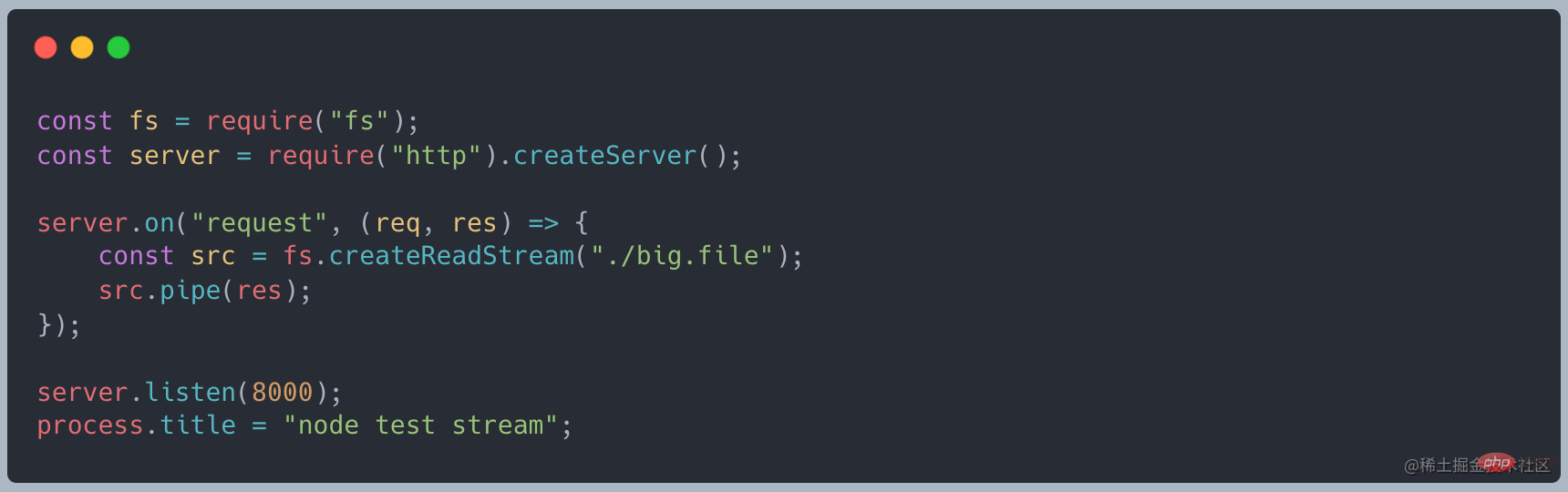
再次发起请求时,发现内存只占用了 35MB 左右,相比 readFile 大幅减少

如果我们不采用流的模式,等待大文件加载完成在操作,会有如下的问题:
- 内存暂用过多,导致系统崩溃
- CPU 运算速度有限制,且服务于多个程序,大文件加载过大且时间久
总结来说就是,一次性读取大文件,内存和网络都吃不消
如何才能一点一点?
我们读取文件的时候,可以采用读取完成之后在输出数据
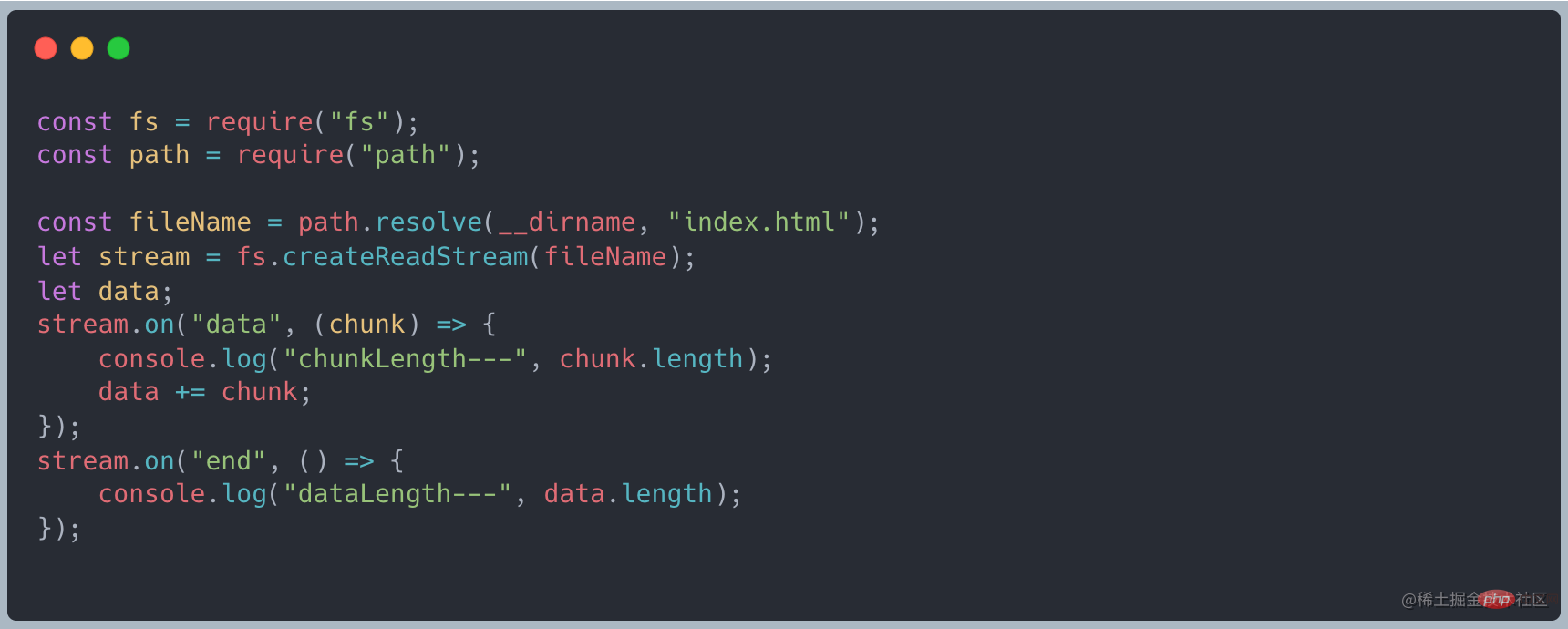
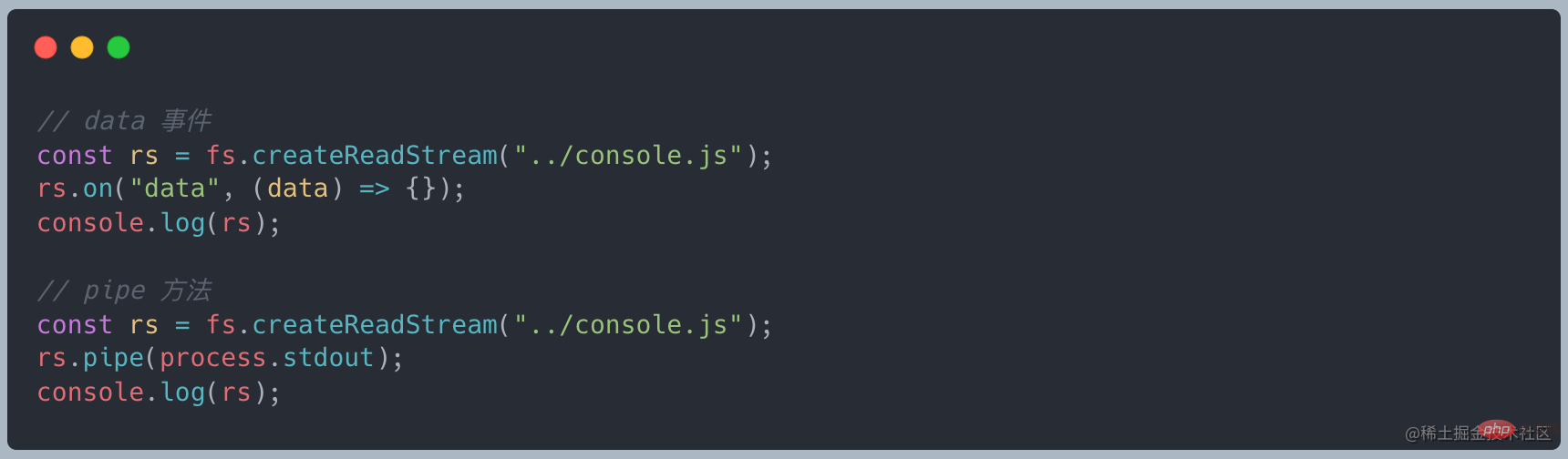
上述说到 stream 继承了 EventEmitter 可以是实现监听数据。首先将读取数据改为流式读取,使用 on("data", ()⇒{}) 接收数据,最后通过 on("end", ()⇒{}) 最后的结果
有数据传递过来的时候就会触发 data 事件,接收这段数据做处理,最后等待所有的数据全部传递完成之后触发 end 事件。
数据的流转过程
数据从哪里来—source
数据是从一个地方流向另一个地方,先看看数据的来源。
-
http 请求,请求接口来的数据

-
console 控制台,标准输入 stdin
file 文件,读取文件内容,例如上面的例子

连接的管道—pipe
在 source 和 dest 中有一个连接的管道 pipe,基本语法为 source.pipe(dest)
Als ich die Anfrage erneut initiierte, stellte ich fest, dass der Speicher nur etwa 35 MB belegte, was im Vergleich zu readFile deutlich reduziert war
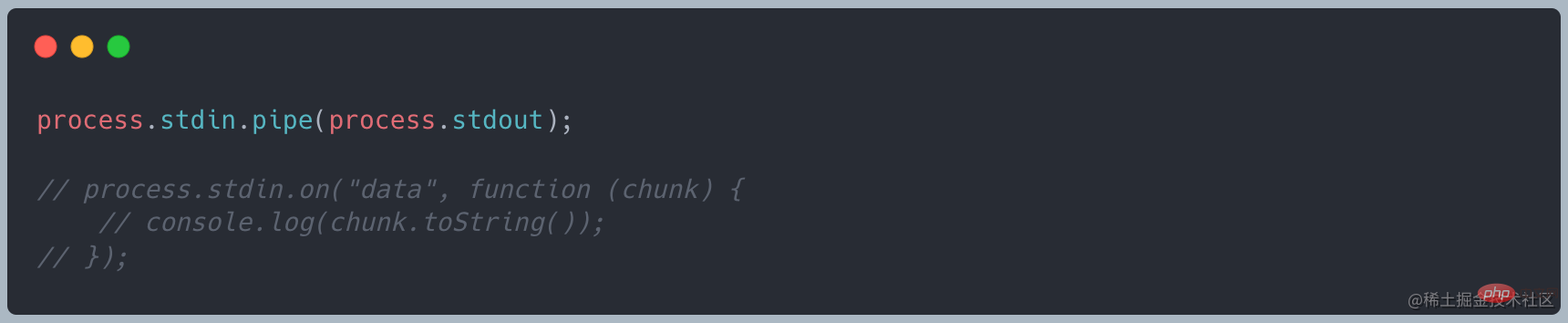
Wenn wir den Streaming-Modus nicht verwenden und Warten Sie, bis die große Datei geladen ist, bevor Sie mit dem Betrieb beginnen. Es treten folgende Probleme auf:
Zu viel Speicher wird vorübergehend verwendet, was zum Absturz des Systems führtDie CPU-Betriebsgeschwindigkeit ist begrenzt und dient mehreren Programme sind zu groß und brauchen viel Zeit zum Laden.
Zusammenfassung Mit anderen Worten: Das gleichzeitige Lesen einer großen Datei ist zu viel für den Speicher und das Netzwerk- Wie schaffe ich es Stück für Stück?
Wenn wir die Datei lesen, können wir die Daten ausgeben, nachdem der Lesevorgang abgeschlossen ist
🎜🎜Wie oben erwähnt, erbt Stream EventEmitter und kann zur Überwachung von Daten verwendet werden. Ändern Sie zunächst die Lesedaten in Streaming-Lesung, verwenden Sie on("data", ()⇒{}), um die Daten zu empfangen, und verwenden Sie schließlichon("end", ()⇒ { })Das Endergebnis🎜🎜🎜🎜Wenn Daten übertragen werden, wird das Datenereignis ausgelöst, die Daten werden zur Verarbeitung empfangen und das Endereignis wird ausgelöst, nachdem alle Daten übertragen wurden. 🎜🎜Datenflussprozess🎜🎜
🎜Woher kommen die Daten – Quelle🎜🎜🎜Daten fließen zuerst von einem Ort zum anderen Schauen wir uns die Quelle der Daten an. 🎜🎜🎜🎜http-Anfrage, Daten von der Schnittstelle anfordern🎜🎜
🎜 🎜🎜Konsolenkonsole, Standardeingabe stdin🎜🎜
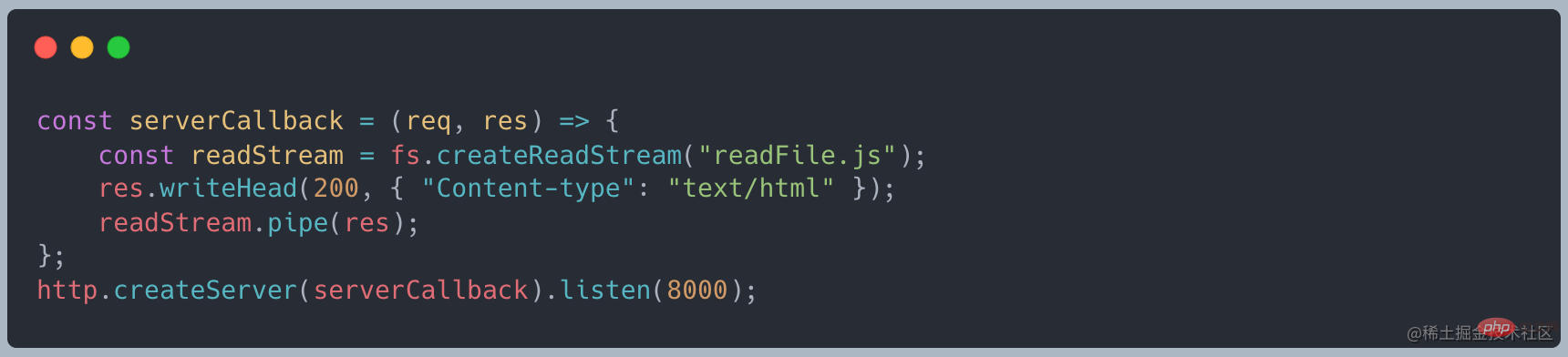 🎜🎜🎜Dateidatei, lesen Sie den Dateiinhalt, wie im obigen Beispiel🎜
🎜🎜🎜Dateidatei, lesen Sie den Dateiinhalt, wie im obigen Beispiel🎜🎜Verbundene Pipe – Pipe🎜🎜🎜Es gibt eine verbundene Pipe in Quelle und Ziel. Die grundlegende Syntax ist source.pipe(dest), Quelle und Ziel sind über eine Pipe verbunden, sodass Daten von der Quelle zum Ziel fließen können. 🎜🎜Wir müssen das Daten-/Endereignis nicht wie im obigen Code manuell überwachen. Bei der Verwendung von Pipe gelten strenge Anforderungen. Die Quelle muss lesbar sein stream und dest müssen Es ist ein beschreibbarer Stream🎜🎜??? Was genau sind fließende Daten? Was ist ein Chunk im Code? 🎜🎜🎜Wohin – Ziel🎜🎜🎜Drei gängige Ausgabemethoden streamen🎜🎜🎜🎜Konsolenkonsole, Standardausgabe stdout🎜🎜🎜🎜
Ein lesbarer Stream ist eine Abstraktion der Quelle, die Daten bereitstellt
? Datei-Stream-Erstellung lesen
Lesemodus

Flowing-Modusund Pause-Modus
, die den Flussmodus von Blockdaten bestimmen: automatischer Fluss und manueller FlussflussEs gibt ein _readableState-Attribut in ReadableStream, in dem es ein Fließattribut gibt Es gibt drei Zustandswerte:ture: Zeigt den Fließmodus an 
null: Anfangszustand
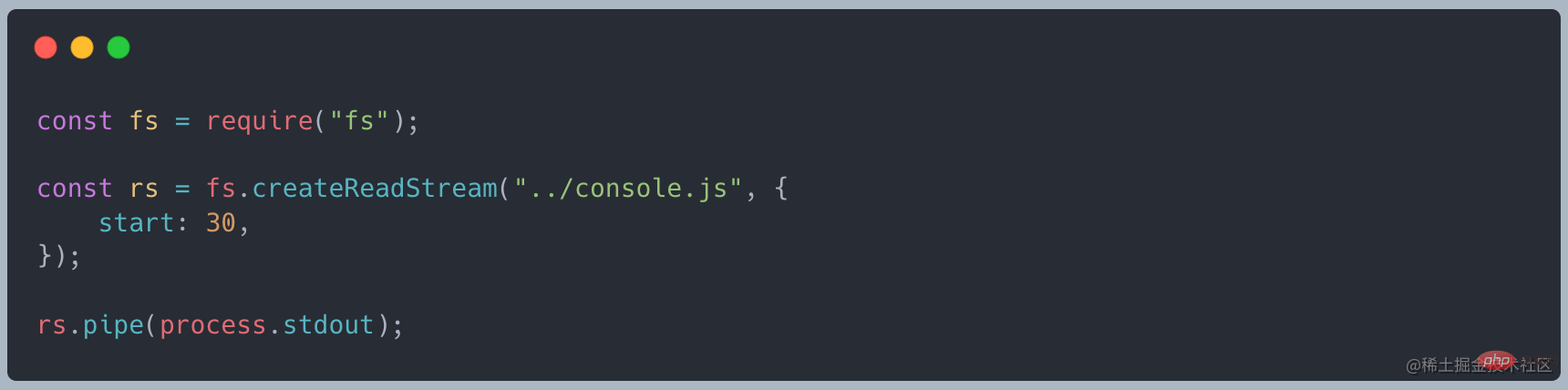
Sie können das Warmwasserbereitermodell zur Simulation verwenden der Datenfluss. Der Warmwasserbereiterspeicher (Pufferspeicher) speichert heißes Wasser (erforderliche Daten). Wenn wir den Wasserhahn öffnen, fließt weiterhin heißes Wasser aus dem Wassertank und Leitungswasser fließt weiterhin in den Wassertank Flow-Modus. Wenn wir den Wasserhahn schließen, unterbricht der Wassertank den Wasserzufluss und der Wasserhahn unterbricht die Wasserausgabe. Dies ist der Pausenmodus.
Flow-ModusDaten werden automatisch aus der untersten Ebene gelesen, bilden ein Flussphänomen und werden der Anwendung über Ereignisse bereitgestellt.
Sie können diesen Modus aufrufen, indem Sie das Datenereignis abhören.
Wenn das Datenereignis hinzugefügt wird und sich Daten im beschreibbaren Stream befinden, werden die Daten an die Ereignisrückruffunktion übertragen. Sie müssen den Datenblock verbrauchen Wenn es nicht verarbeitet wird, gehen die Daten verloren. Rufen Sie die stream.pipe-Methode auf, um Daten an Writeable zu senden. Rufen Sie die stream.resume-Methode auf Die Daten werden im internen Puffer gesammelt und müssen angezeigt werden. Rufen Sie stream.read() auf, um den Datenblock zu lesen- Hören Sie sich das lesbare Ereignis an Der beschreibbare Stream löst diesen Ereignisrückruf aus, nachdem die Daten bereit sind. Zu diesem Zeitpunkt müssen Sie stream.read() in der Rückruffunktion verwenden, um aktiv Daten zu verbrauchen. Das lesbare Ereignis zeigt an, dass der Stream eine neue Dynamik aufweist: Entweder liegen neue Daten vor oder der Stream hat alle Daten gelesen //TODO: Inkonsistent mit der Online-Freigabe
- 监听 data 事件 - 调用 stream.resume 方法 - 调用 stream.pipe 方法将数据发送到 Writable
Flow-Modus in Pausenmodus umschalten
ImplementierungsprinzipErstellen Sie einen lesbaren Stream Wann, wir Sie müssen das Readable-Objekt erben und die _read-Methode implementieren
, um einen benutzerdefinierten lesbaren Stream zu erstellen
-
Wenn wir die Read-Methode aufrufen, ist der Gesamtprozess wie folgt:
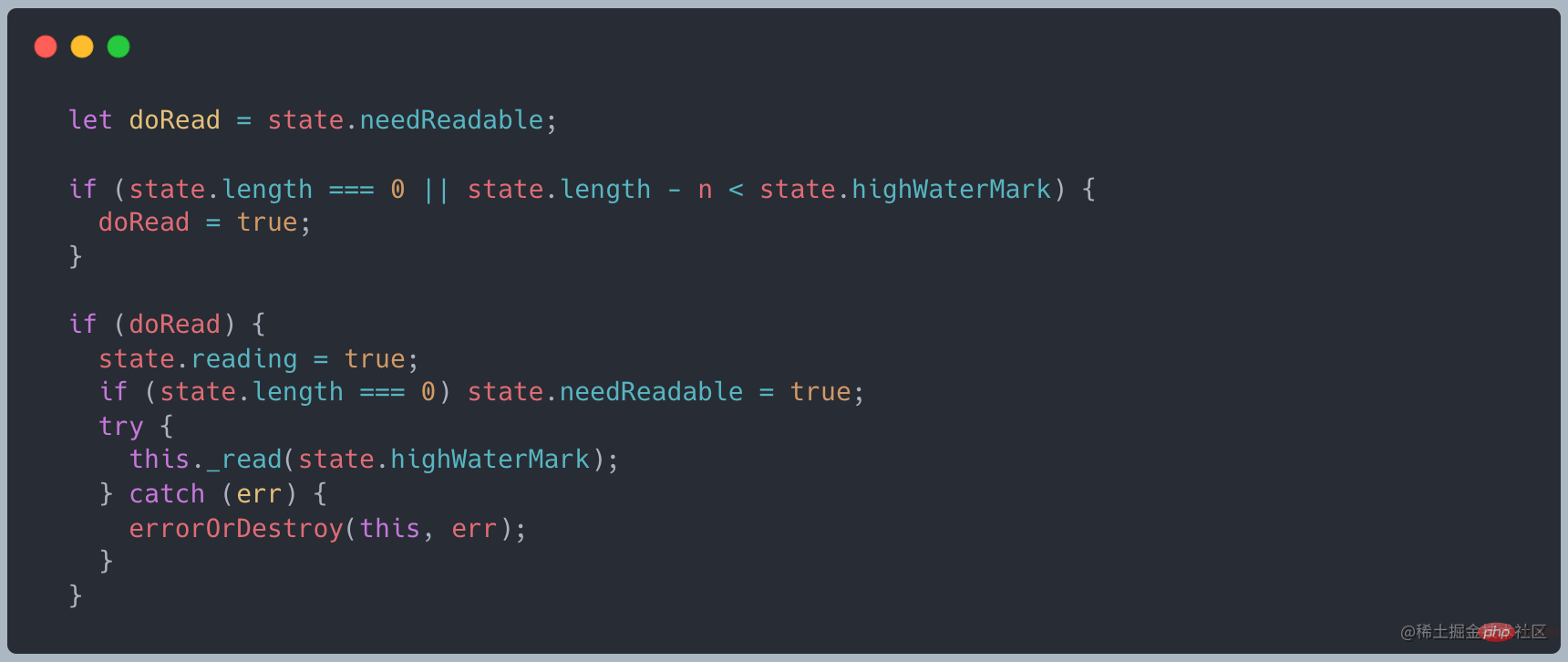
A Der Cache wird im Stream verwaltet. Wenn die Lesemethode aufgerufen wird, wird beurteilt, ob Daten von der untersten Ebene angefordert werden müssenWenn die Pufferlänge 0 oder kleiner als der Wert von highWaterMark ist, wird _read aufgerufen, um die Daten von der untersten Ebene abzurufen. Quellcode-Link Daten schreiben Eine Abstraktion des Ziels wird verwendet, um vom Upstream fließende Daten zu verbrauchen und die Daten über einen beschreibbaren Stream auf das Gerät zu schreiben. Ein üblicher Schreibstream ist das Schreiben auf die lokale Festplatte. Merkmale beschreibbarer Streams
Daten durch Schreiben schreiben
Daten durch Ende schreiben und den Stream schließen, Ende = Schreiben + Schließen
Wenn die geschriebenen Daten die Größe von highWaterMark erreichen, wird ein Entleeren ausgelöst Das Ereignis
-
ruft ws.write(chunk) auf und gibt false zurück, was angibt, dass die aktuellen Pufferdaten größer oder gleich dem Wert von highWaterMark sind und das Drain-Ereignis ausgelöst wird. Tatsächlich dient es als Warnung. Wir können weiterhin Daten schreiben, aber die unverarbeiteten Daten werden immer im
internen Puffer des beschreibbaren Streams zurückgehalten. Dies wird nicht erzwungen, bis der Rückstand im Node.js-Puffer voll ist . Unterbrechen: Benutzerdefinierter beschreibbarer Stream Rufen Sie die Methode writable.write auf, um Daten in den Stream zu schreiben. Wenn _write data erfolgreich ist, müssen Sie die nächste Methode aufrufen, um die nächsten Daten zu verarbeiten Rufen Sie writable.end( data) auf, um den beschreibbaren Stream zu beenden, data ist optional. Danach kann das Schreiben nicht mehr aufgerufen werden, um neue Daten hinzuzufügen, andernfalls wird ein Fehler gemeldet
Nachdem die End-Methode aufgerufen wurde und alle zugrunde liegenden Schreibvorgänge abgeschlossen sind, wird das Finish-Ereignis ausgelöst
-
Duplex Stream
Duplex Stream, sowohl lesbar als auch beschreibbar. Tatsächlich handelt es sich um einen Stream, der Readable und Writable erbt. Er kann sowohl als lesbarer Stream als auch als beschreibbarer Stream verwendet werden. Ein benutzerdefinierter Duplex-Stream muss die Methode _readable und die Methode _write implementieren Das
- net-Modul kann zum Erstellen eines Sockets in NodeJS verwendet werden. Schauen Sie sich ein Beispiel eines TCP-Clients an. Der beschreibbare Stream wird zum Senden von Nachrichten verwendet Der Lesestream wird zum Empfangen von Servernachrichten verwendet.
Transform Stream
Im obigen Beispiel sind die Daten im lesbaren Stream (0/1) und Die beschreibbaren Daten ('F', 'B', 'B') sind isoliert und es besteht keine Beziehung zwischen den beiden. Bei Transform werden die am beschreibbaren Ende geschriebenen Daten jedoch automatisch zum lesbaren Ende hinzugefügt Transformation. Transform erbt von Duplex und hat bereits die Methoden _write und _read implementiert. Sie müssen nur die Methode _transform implementieren.
gulp ist ein Stream-basiertes automatisiertes Konstruktionstool Website
less → less in CSS konvertiert → CSS-Komprimierung durchführen → CSS komprimieren
Tatsächlich führen less() und minifyCss() beide eine Verarbeitung der Eingabedaten durch und übergeben dann die Ausgabedaten
Duplex- und Transformationsoptionen -
Im Vergleich zum obigen Beispiel stellen wir fest, dass wir uns für Duplex entscheiden, wenn wir nur einige Konvertierungsarbeiten an den Daten durchführen.
Gegendruckproblem
Was ist Gegendruck? Das Problem des Gegendrucks ergibt sich aus dem Produzenten-Verbraucher-Modell, bei dem die Verarbeitungsgeschwindigkeit des Verbrauchers zu langsam ist. Während unseres Download-Vorgangs beträgt die Verarbeitungsgeschwindigkeit beispielsweise 3 Mbit/s, während die Verarbeitungsgeschwindigkeit während der Komprimierung zu niedrig ist Prozess, die Verarbeitungsgeschwindigkeit ist zu langsam. Die Geschwindigkeit beträgt 1 Mbit/s. In diesem Fall wird sich die Pufferwarteschlange schnell ansammeln, oder der gesamte Puffer wird langsam sein und einige Daten gehen verloren . Was ist die Gegendruckverarbeitung?
Die Gegendruckverarbeitung kann als ein Prozess des „Weinens“ nach oben verstanden werden.Wenn der Komprimierungsprozess feststellt, dass der Pufferdatendruck den Schwellenwert überschreitet, wird er zur Download-Verarbeitung „schreien“. zu beschäftigt, bitte nicht mehr posten Download-Verarbeitung pausiert das Senden von Daten nach unten, nachdem eine Nachricht empfangen wurde
So gehen Sie mit Rückstau um
Wir haben verschiedene Funktionen, um Daten von einem Prozess zum anderen zu übertragen. In Node.js gibt es eine integrierte Funktion namens .pipe(), und letztendlich haben wir auf einer grundlegenden Ebene in diesem Prozess zwei unabhängige Komponenten: die Datenquelle und den Verbraucher
Wenn .pipe() ist Wird von der Quelle aufgerufen und benachrichtigt den Verbraucher darüber, dass Daten übertragen werden müssen. Die Pipeline-Funktion erstellt ein geeignetes Backlog-Paket zum Auslösen von EreignissenWenn der Datencache HighWaterMark überschreitet oder die Schreibwarteschlange beschäftigt ist, gibt .write() false zurück.Wenn false zurückgegeben wird, greift das Backlog-System ein. Es pausiert eingehende Readables von jedem Datenstrom, der Daten sendet. Sobald der Datenstrom geleert ist, wird das Drain-Ereignis ausgelöst und der eingehende Datenstrom wird verbraucht. Sobald die Warteschlange vollständig verarbeitet ist, ermöglicht der Rückstandsmechanismus das erneute Senden der Daten. Der verwendete Speicherplatz wird freigegeben und bereitet sich auf den Empfang des nächsten Datenstapels vor
Wir können die Gegendruckverarbeitung der Pipe sehen:
Teilen Sie die Daten in Blöcke auf und schreiben Sie
Wenn der Block durchläuft Wenn die Warteschlange zu groß oder ausgelastet ist, wird das Lesen angehalten
Wenn die Warteschlange leer ist, lesen Sie die Daten weiter
Weitere Informationen zu Knoten finden Sie unter: nodejs-Tutorial
!

ruft ws.write(chunk) auf und gibt false zurück, was angibt, dass die aktuellen Pufferdaten größer oder gleich dem Wert von highWaterMark sind und das Drain-Ereignis ausgelöst wird. Tatsächlich dient es als Warnung. Wir können weiterhin Daten schreiben, aber die unverarbeiteten Daten werden immer im
internen Puffer des beschreibbaren Streams zurückgehalten. Dies wird nicht erzwungen, bis der Rückstand im Node.js-Puffer voll ist . Unterbrechen: Benutzerdefinierter beschreibbarer Stream Rufen Sie die Methode writable.write auf, um Daten in den Stream zu schreiben. Wenn _write data erfolgreich ist, müssen Sie die nächste Methode aufrufen, um die nächsten Daten zu verarbeiten Rufen Sie writable.end( data) auf, um den beschreibbaren Stream zu beenden, data ist optional. Danach kann das Schreiben nicht mehr aufgerufen werden, um neue Daten hinzuzufügen, andernfalls wird ein Fehler gemeldet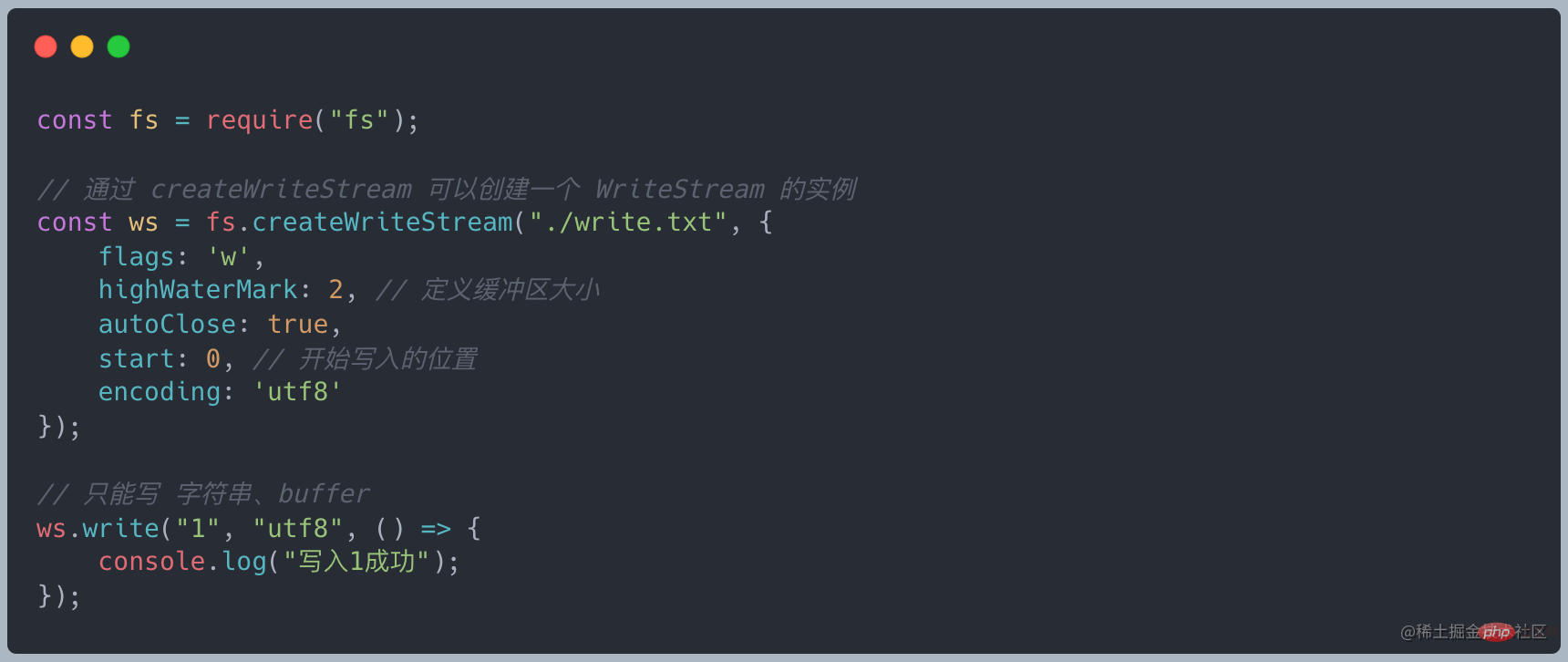
 Duplex Stream, sowohl lesbar als auch beschreibbar. Tatsächlich handelt es sich um einen Stream, der Readable und Writable erbt. Er kann sowohl als lesbarer Stream als auch als beschreibbarer Stream verwendet werden. Ein benutzerdefinierter Duplex-Stream muss die Methode _readable und die Methode _write implementieren Das
Duplex Stream, sowohl lesbar als auch beschreibbar. Tatsächlich handelt es sich um einen Stream, der Readable und Writable erbt. Er kann sowohl als lesbarer Stream als auch als beschreibbarer Stream verwendet werden. Ein benutzerdefinierter Duplex-Stream muss die Methode _readable und die Methode _write implementieren Das
Transform Stream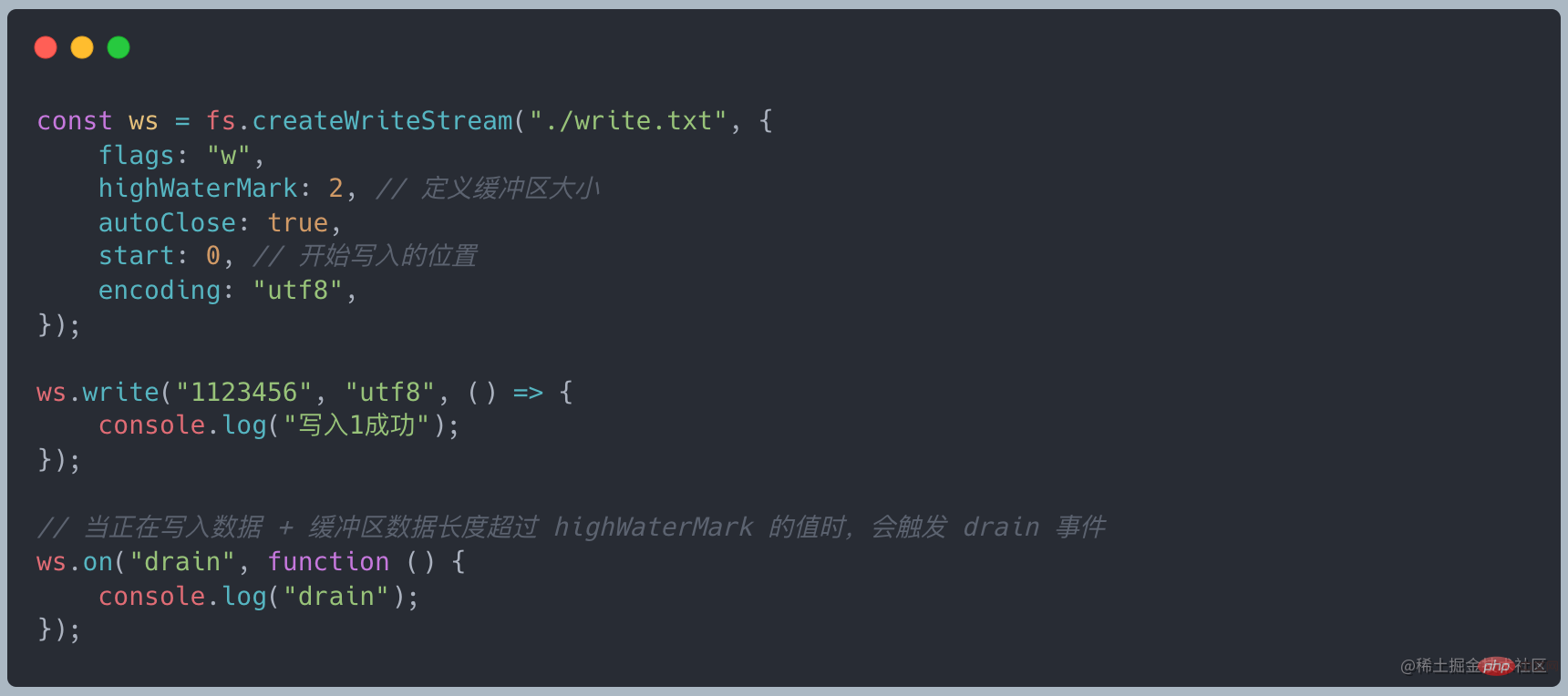
Im obigen Beispiel sind die Daten im lesbaren Stream (0/1) und Die beschreibbaren Daten ('F', 'B', 'B') sind isoliert und es besteht keine Beziehung zwischen den beiden. Bei Transform werden die am beschreibbaren Ende geschriebenen Daten jedoch automatisch zum lesbaren Ende hinzugefügt Transformation. Transform erbt von Duplex und hat bereits die Methoden _write und _read implementiert. Sie müssen nur die Methode _transform implementieren.
Im Vergleich zum obigen Beispiel stellen wir fest, dass wir uns für Duplex entscheiden, wenn wir nur einige Konvertierungsarbeiten an den Daten durchführen.
Gegendruckproblem
Was ist Gegendruck? Das Problem des Gegendrucks ergibt sich aus dem Produzenten-Verbraucher-Modell, bei dem die Verarbeitungsgeschwindigkeit des Verbrauchers zu langsam ist. Während unseres Download-Vorgangs beträgt die Verarbeitungsgeschwindigkeit beispielsweise 3 Mbit/s, während die Verarbeitungsgeschwindigkeit während der Komprimierung zu niedrig ist Prozess, die Verarbeitungsgeschwindigkeit ist zu langsam. Die Geschwindigkeit beträgt 1 Mbit/s. In diesem Fall wird sich die Pufferwarteschlange schnell ansammeln, oder der gesamte Puffer wird langsam sein und einige Daten gehen verloren . Was ist die Gegendruckverarbeitung?
Die Gegendruckverarbeitung kann als ein Prozess des „Weinens“ nach oben verstanden werden.Wenn der Komprimierungsprozess feststellt, dass der Pufferdatendruck den Schwellenwert überschreitet, wird er zur Download-Verarbeitung „schreien“. zu beschäftigt, bitte nicht mehr posten Download-Verarbeitung pausiert das Senden von Daten nach unten, nachdem eine Nachricht empfangen wurde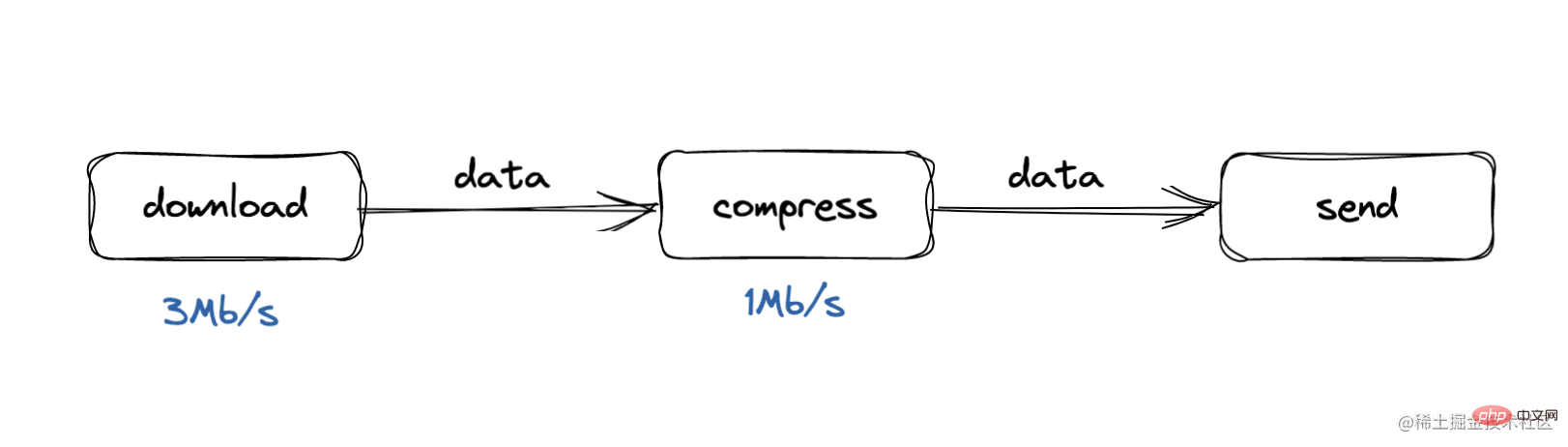
So gehen Sie mit Rückstau um
Wir haben verschiedene Funktionen, um Daten von einem Prozess zum anderen zu übertragen. In Node.js gibt es eine integrierte Funktion namens .pipe(), und letztendlich haben wir auf einer grundlegenden Ebene in diesem Prozess zwei unabhängige Komponenten: die Datenquelle und den VerbraucherWenn .pipe() ist Wird von der Quelle aufgerufen und benachrichtigt den Verbraucher darüber, dass Daten übertragen werden müssen. Die Pipeline-Funktion erstellt ein geeignetes Backlog-Paket zum Auslösen von EreignissenWenn der Datencache HighWaterMark überschreitet oder die Schreibwarteschlange beschäftigt ist, gibt .write() false zurück.Wenn false zurückgegeben wird, greift das Backlog-System ein. Es pausiert eingehende Readables von jedem Datenstrom, der Daten sendet. Sobald der Datenstrom geleert ist, wird das Drain-Ereignis ausgelöst und der eingehende Datenstrom wird verbraucht. Sobald die Warteschlange vollständig verarbeitet ist, ermöglicht der Rückstandsmechanismus das erneute Senden der Daten. Der verwendete Speicherplatz wird freigegeben und bereitet sich auf den Empfang des nächsten Datenstapels vor
Wir können die Gegendruckverarbeitung der Pipe sehen:
Teilen Sie die Daten in Blöcke auf und schreiben Sie
Wenn der Block durchläuft Wenn die Warteschlange zu groß oder ausgelastet ist, wird das Lesen angehalten
Wenn die Warteschlange leer ist, lesen Sie die Daten weiter
Weitere Informationen zu Knoten finden Sie unter:nodejs-Tutorial
!Das obige ist der detaillierte Inhalt vonEine eingehende Analyse von Stream in Node. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1205
24
52
1205
24

 PHP und Vue: eine perfekte Kombination von Front-End-Entwicklungstools
Mar 16, 2024 pm 12:09 PM
PHP und Vue: eine perfekte Kombination von Front-End-Entwicklungstools
Mar 16, 2024 pm 12:09 PM
PHP und Vue: eine perfekte Kombination von Front-End-Entwicklungstools In der heutigen Zeit der rasanten Entwicklung des Internets ist die Front-End-Entwicklung immer wichtiger geworden. Da Benutzer immer höhere Anforderungen an das Erlebnis von Websites und Anwendungen stellen, müssen Frontend-Entwickler effizientere und flexiblere Tools verwenden, um reaktionsfähige und interaktive Schnittstellen zu erstellen. Als zwei wichtige Technologien im Bereich der Front-End-Entwicklung können PHP und Vue.js in Kombination als perfekte Waffe bezeichnet werden. In diesem Artikel geht es um die Kombination von PHP und Vue sowie um detaillierte Codebeispiele, die den Lesern helfen sollen, diese beiden besser zu verstehen und anzuwenden
 Wie verwende ich die Go-Sprache für die Front-End-Entwicklung?
Jun 10, 2023 pm 05:00 PM
Wie verwende ich die Go-Sprache für die Front-End-Entwicklung?
Jun 10, 2023 pm 05:00 PM
Mit der Entwicklung der Internet-Technologie hat die Front-End-Entwicklung immer mehr an Bedeutung gewonnen. Insbesondere die Popularität mobiler Geräte erfordert eine Front-End-Entwicklungstechnologie, die effizient, stabil, sicher und einfach zu warten ist. Als sich schnell entwickelnde Programmiersprache wird die Go-Sprache von immer mehr Entwicklern verwendet. Ist es also möglich, die Go-Sprache für die Front-End-Entwicklung zu verwenden? Als Nächstes wird in diesem Artikel ausführlich erläutert, wie die Go-Sprache für die Front-End-Entwicklung verwendet wird. Werfen wir zunächst einen Blick darauf, warum die Go-Sprache für die Front-End-Entwicklung verwendet wird. Viele Leute denken, dass die Go-Sprache eine ist
 Erfahrungsaustausch in der C#-Entwicklung: Fähigkeiten zur kollaborativen Front-End- und Back-End-Entwicklung
Nov 23, 2023 am 10:13 AM
Erfahrungsaustausch in der C#-Entwicklung: Fähigkeiten zur kollaborativen Front-End- und Back-End-Entwicklung
Nov 23, 2023 am 10:13 AM
Als C#-Entwickler umfasst unsere Entwicklungsarbeit in der Regel die Front-End- und Back-End-Entwicklung. Mit der Weiterentwicklung der Technologie und der zunehmenden Komplexität von Projekten wird die gemeinsame Entwicklung von Front-End und Back-End immer wichtiger und komplexer. In diesem Artikel werden einige kollaborative Front-End- und Back-End-Entwicklungstechniken vorgestellt, um C#-Entwicklern dabei zu helfen, die Entwicklungsarbeit effizienter abzuschließen. Nach der Festlegung der Schnittstellenspezifikationen ist die gemeinsame Entwicklung von Front-End und Backend untrennbar mit dem Zusammenspiel der API-Schnittstellen verbunden. Um den reibungslosen Ablauf der kollaborativen Front-End- und Back-End-Entwicklung sicherzustellen, ist es am wichtigsten, gute Schnittstellenspezifikationen zu definieren. Bei der Schnittstellenspezifikation handelt es sich um den Namen der Schnittstelle
 Häufig gestellte Fragen von Front-End-Interviewern
Mar 19, 2024 pm 02:24 PM
Häufig gestellte Fragen von Front-End-Interviewern
Mar 19, 2024 pm 02:24 PM
In Front-End-Entwicklungsinterviews decken häufige Fragen ein breites Themenspektrum ab, darunter HTML/CSS-Grundlagen, JavaScript-Grundlagen, Frameworks und Bibliotheken, Projekterfahrung, Algorithmen und Datenstrukturen, Leistungsoptimierung, domänenübergreifende Anfragen, Front-End-Engineering, Designmuster sowie neue Technologien und Trends. Interviewerfragen sollen die technischen Fähigkeiten, die Projekterfahrung und das Verständnis des Kandidaten für Branchentrends beurteilen. Daher sollten Kandidaten in diesen Bereichen umfassend vorbereitet sein, um ihre Fähigkeiten und Fachkenntnisse unter Beweis zu stellen.
 Ist Django Front-End oder Back-End? Hör zu!
Jan 19, 2024 am 08:37 AM
Ist Django Front-End oder Back-End? Hör zu!
Jan 19, 2024 am 08:37 AM
Django ist ein in Python geschriebenes Webanwendungs-Framework, das Wert auf schnelle Entwicklung und saubere Methoden legt. Obwohl Django ein Web-Framework ist, müssen Sie zur Beantwortung der Frage, ob Django ein Front-End oder ein Back-End ist, ein tiefes Verständnis der Konzepte von Front-End und Back-End haben. Das Front-End bezieht sich auf die Schnittstelle, mit der Benutzer direkt interagieren, und das Back-End bezieht sich auf serverseitige Programme. Sie interagieren mit Daten über das HTTP-Protokoll. Wenn das Front-End und das Back-End getrennt sind, können die Front-End- und Back-End-Programme unabhängig voneinander entwickelt werden, um Geschäftslogik bzw. interaktive Effekte sowie den Datenaustausch zu implementieren.
 Erkundung der Front-End-Technologie der Go-Sprache: eine neue Vision für die Front-End-Entwicklung
Mar 28, 2024 pm 01:06 PM
Erkundung der Front-End-Technologie der Go-Sprache: eine neue Vision für die Front-End-Entwicklung
Mar 28, 2024 pm 01:06 PM
Als schnelle und effiziente Programmiersprache erfreut sich Go im Bereich der Backend-Entwicklung großer Beliebtheit. Allerdings assoziieren nur wenige Menschen die Go-Sprache mit der Front-End-Entwicklung. Tatsächlich kann die Verwendung der Go-Sprache für die Front-End-Entwicklung nicht nur die Effizienz verbessern, sondern Entwicklern auch neue Horizonte eröffnen. In diesem Artikel wird die Möglichkeit der Verwendung der Go-Sprache für die Front-End-Entwicklung untersucht und spezifische Codebeispiele bereitgestellt, um den Lesern ein besseres Verständnis dieses Bereichs zu erleichtern. In der traditionellen Frontend-Entwicklung werden häufig JavaScript, HTML und CSS zum Erstellen von Benutzeroberflächen verwendet
 So implementieren Sie Instant Messaging im Frontend
Oct 09, 2023 pm 02:47 PM
So implementieren Sie Instant Messaging im Frontend
Oct 09, 2023 pm 02:47 PM
Zu den Methoden zur Implementierung von Instant Messaging gehören WebSocket, Long Polling, vom Server gesendete Ereignisse, WebRTC usw. Detaillierte Einführung: 1. WebSocket, das eine dauerhafte Verbindung zwischen dem Client und dem Server herstellen kann, um eine bidirektionale Kommunikation in Echtzeit zu erreichen. Das Front-End kann die WebSocket-API verwenden, um eine WebSocket-Verbindung herzustellen und Instant Messaging durch Senden und Empfangen zu erreichen 2. Long Polling, eine Technologie, die Echtzeitkommunikation usw. simuliert.
 Kann Golang als Frontend verwendet werden?
Jun 06, 2023 am 09:19 AM
Kann Golang als Frontend verwendet werden?
Jun 06, 2023 am 09:19 AM
Golang kann als Front-End verwendet werden. Golang ist eine sehr vielseitige Programmiersprache, mit der verschiedene Arten von Anwendungen entwickelt werden können, einschließlich Front-End-Anwendungen Eine Reihe von Problemen, die durch Sprachen wie JavaScript verursacht werden. Zum Beispiel Probleme wie schlechte Typsicherheit, geringe Leistung und schwierig zu wartender Code.
