

So komprimieren Sie großen Textspeicher in MySQL


Wie bereits erwähnt, wird der Snapshot-Inhalt unseres Cloud-Dokumentprojekts direkt in db gespeichert, einem großen Textspeicher. Die meisten Inhaltsfelder des Dokument-Snapshots befinden sich auf KB-Ebene, einige sogar auf der MB-Ebene. Derzeit wurde eine CDN-Caching-Optimierung für das Datenlesen durchgeführt (Statisches Ressourcen-Caching-Tool – CDN). Wenn einige Komprimierungsalgorithmen zum Komprimieren und Speichern großer Texte verwendet werden können, ist dies möglich Sparen Sie erheblich DB-Speicherplatz und entlasten Sie den DB-E/A-Druck.
Bestandsdatenanalyse
select
table_name as '表名',
table_rows as '记录数',
truncate(data_length/1024/1024, 2) as '数据容量(MB)',
truncate(index_length/1024/1024, 2) as '索引容量(MB)',
truncate(DATA_FREE/1024/1024, 2) as '碎片占用(MB)'
from
information_schema.tables
where
table_schema=${数据库名}
order by
data_length desc, index_length desc;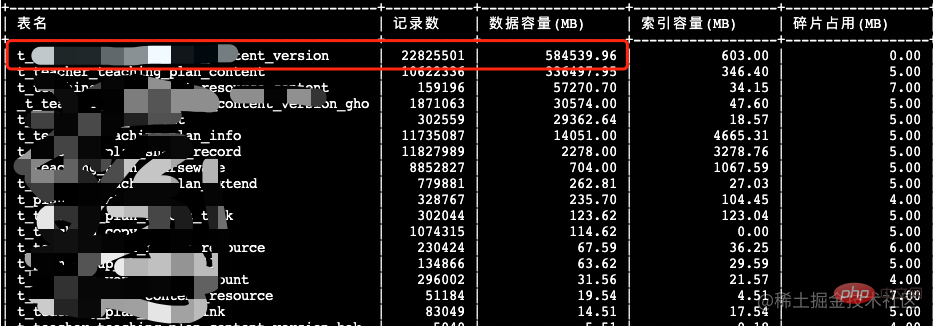

Einführung in verwandte Inhalte
Was soll ich tun, wenn die Seitendaten der Innodb-Engine 16 KB überschreiten?
Wir alle wissen, dass die Standardseitenblockgröße von innodb 16 KB beträgt. Wenn die Datenlänge einer Zeile in der Tabelle 16 KB überschreitet, kommt es zu einem Zeilenüberlauf und die übergelaufene Zeile wird an einer anderen Stelle gespeichert (Blobseite dekomprimieren). Da innodb zum Speichern von Daten einen Clustered-Index verwendet, d Es werden 8 KB Daten abgerufen (das große Feld speichert 768 Byte Daten auf der Datenseite und die verbleibenden Daten werden auf eine andere Seite übertragen. Die Datenseite verfügt außerdem über 20 Byte zum Aufzeichnen der Adresse der Überlaufseite)
- Für Dynamisches Format: Wenn die im großen Objektfeld (Text/BLOB) gespeicherte Datengröße weniger als 40 Byte beträgt, werden alle Daten auf der Datenseite platziert. In den übrigen Szenarien behält die Datenseite nur einen 20-Byte-Zeiger zeigt auf die Überlaufseite. Wenn in diesem Szenario die in jedem großen Objektfeld gespeicherten Daten weniger als 40 Byte umfassen, hat dies den gleichen Effekt wie varchar(40).
- innodb-row-format-dynamic: dev.mysql.com/doc/refman/…
Linux Sparse Files & Holes
- Sparse File: Sparse-Dateien sind im Grunde die gleichen wie andere gewöhnliche Dateien. Der Unterschied ist, dass einige der Daten in der Datei alle 0 sind und dieser Teil der Daten keinen Speicherplatz belegt
- Dateilücken: Die Dateiverschiebung kann größer sein als die tatsächliche Länge der Datei (Bytes, die sich in der Datei befinden, aber nicht geschrieben wurden, sind auf 0 gesetzt. Ob das Loch Speicherplatz belegt, wird vom Betriebssystem bestimmt ist immer noch kontinuierlich
- Das von innodb bereitgestellte Komprimierungsschema
 Seitenkomprimierung
Seitenkomprimierung
ist anwendbar Szenario: Aufgrund der großen Datenmenge und des unzureichenden Speicherplatzes spiegelt sich die Last hauptsächlich in E / A wider und die CPU des Servers hat einen relativ großen Spielraum . - Das von innodb bereitgestellte Komprimierungsschema

1) COMPRESS-Seitenkomprimierung
Verwandte Dokumente:
dev.mysql.com/doc/refman/…- Die vor MySQL-Version 5.7 bereitgestellte Seitenkomprimierungsfunktion gibt beim Erstellen der Tabelle ROW_FORMAT = COMPRESS an und legt die Größe der komprimierten Seite über KEY_BLOCK_SIZE fest
- Es gibt Designfehler, die zu erheblichen Leistungseinbußen und anderen Problemen führen können Das Original Ziel des Entwurfs ist es, die Leistung zu verbessern, und das Konzept „Protokoll ist Daten“ wird eingeführt
- Für die Datenänderung der komprimierten Seite wird die Seite selbst nicht direkt geändert, sondern das Änderungsprotokoll wird auf dieser Seite gespeichert , was tatsächlich die Daten ändert Es ist benutzerfreundlicher und muss nicht jedes Mal komprimiert/dekomprimiert werden, wenn es geändert wird
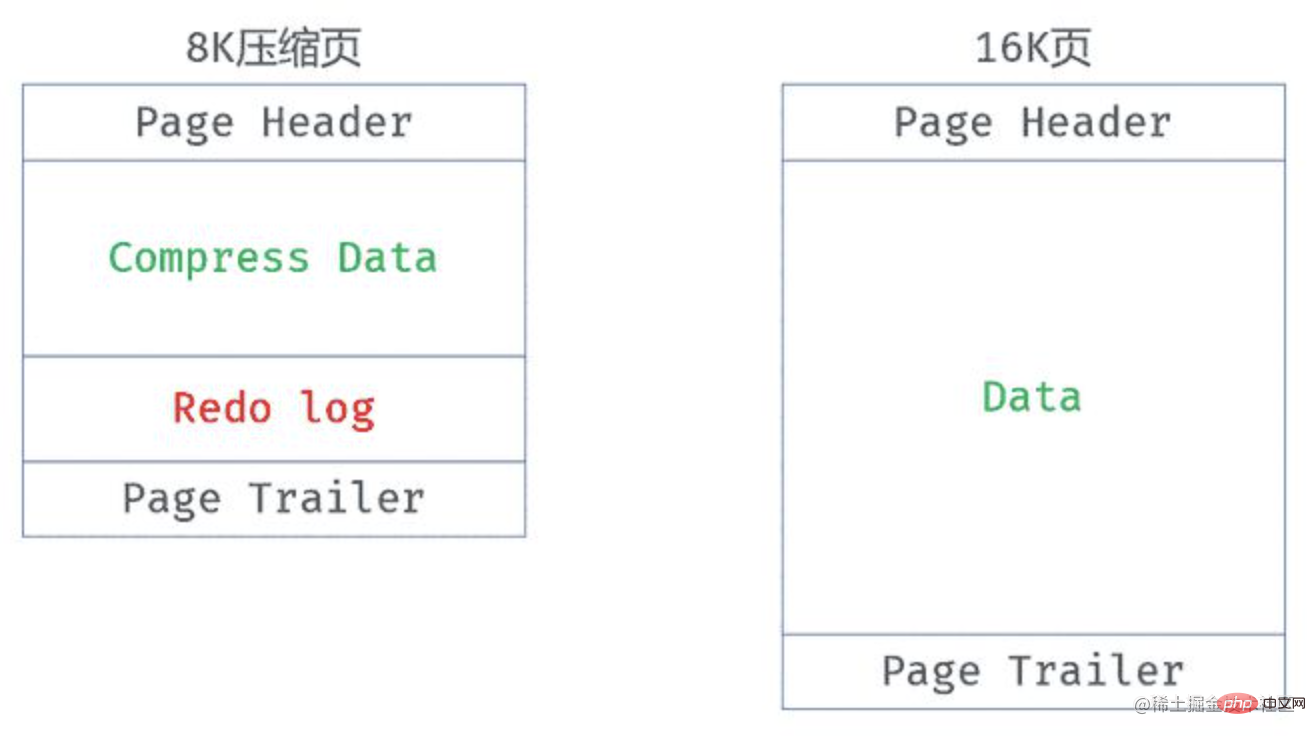
- Beim Datenlesen können die komprimierten Daten nicht direkt gelesen werden, daher behält dieser Algorithmus eine dekomprimierte Datei bei 16 KB in der Speicherseite zum Lesen von Daten
- Dies führt zu einer Seite, die möglicherweise zwei Versionen (komprimierte Version und unkomprimierte Version) im Pufferpool enthält, was ein sehr ernstes Problem verursacht, nämlich den Pufferpool Die Anzahl der Seiten, die zwischengespeichert werden können, ist stark reduziert, was zu einer starken Verschlechterung der Datenbankleistung führen kann
- Für die Datenänderung der komprimierten Seite wird die Seite selbst nicht direkt geändert, sondern das Änderungsprotokoll wird auf dieser Seite gespeichert , was tatsächlich die Daten ändert Es ist benutzerfreundlicher und muss nicht jedes Mal komprimiert/dekomprimiert werden, wenn es geändert wird

2) TPC (Transparente Seitenkomprimierung)
Verwandte Dokumente: dev.mysql.com/doc/ refman/…
- Arbeitsprinzip: Wenn Sie eine Seite schreiben, verwenden Sie den angegebenen Komprimierungsalgorithmus, um die Seite zu komprimieren, und schreiben Sie sie nach der Komprimierung auf die Festplatte, wobei der leere Raum vom Ende der Seite durch den Stanzmechanismus (den) freigegeben wird Das Betriebssystem muss
Löcherunterstützen Um die gesamte Tabelle zu komprimieren, müssen SieOPTIMIZE TABLE xxxausführen.空洞特性) ALTER TABLE xxx COMPRESSION = ZLIB可以启用TPC页压缩功能,但这只是对后续增量数据进行压缩,如果期望对整个表进行压缩,则需要执行OPTIMIZE TABLE xxx实现过程:一个压缩页在缓冲池中都是一个16K的非压缩页,只有在数据刷盘的时候,会进行一次压缩,压缩后剩余的空间会用 0x00 填满,利用文件系统的空洞特性(hole punch)对文件进行裁剪,释放 0x00 占用的稀疏空间
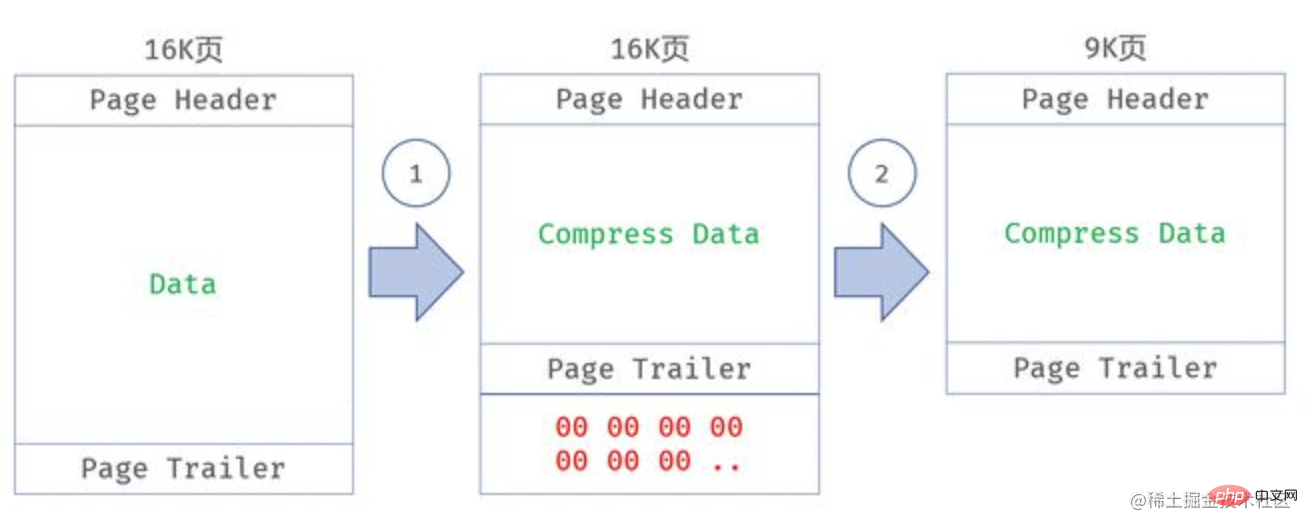
- TPC虽好,但它依赖操作系统的 Hole Punch 特性,且裁剪后的文件大小需要和文件系统块大小对齐(4K)。即假如压缩后的页大小是9K,那么实际占用的空间是12K
列压缩
MySQL目前没有直接针对列压缩的方案,有一个曲线救国的方法,就是在业务层使用MySQL提供的压缩和解压函数来针对列进行压缩和解压操作。也就是如果需要对某一列做压缩,在写入时调用COMPRESS函数对那个列的内容进行压缩,读取的时候,使用UNCOMPRESS函数对压缩过的数据进行解压。
- 使用场景:针对表中某些列数据长度比较大的情况,一般是 varchar、text、blob、json等数据类型
- 相关函数:
- 压缩函数:
COMPRESS() - 解压缩函数:
UNCOMPRESS() - 字符串长度函数:
LENGTH() - 未解压字符串长度函数:
UNCOMPRESSED_LENGTH()
- 压缩函数:
- 测试:
- 插入数据:
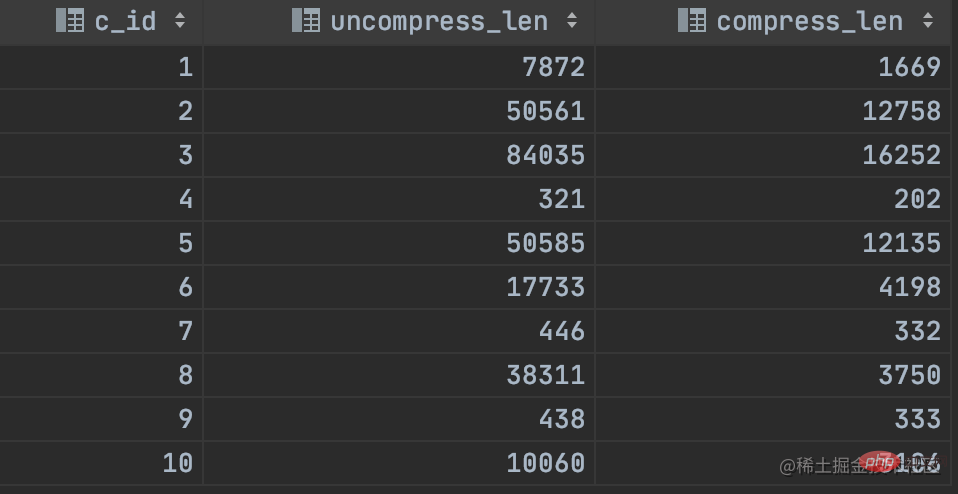
insert into xxx (content) values (compress('xxx....')) 读取压缩的数据:
select c_id, uncompressed_length(c_content) uncompress_len, length(c_content) compress_len from xxx
- 插入数据:
 🎜🎜🎜TPC ist gut, aber es verlässt sich auf das Loch Die Punch-Funktion des Betriebssystems und die zugeschnittene Dateigröße erfordern eine Ausrichtung auf die Blockgröße des Dateisystems (4 KB). Das heißt, wenn die Größe der komprimierten Seite 9 KB beträgt, beträgt der tatsächlich belegte Speicherplatz 12 KB. 🎜🎜
🎜🎜🎜TPC ist gut, aber es verlässt sich auf das Loch Die Punch-Funktion des Betriebssystems und die zugeschnittene Dateigröße erfordern eine Ausrichtung auf die Blockgröße des Dateisystems (4 KB). Das heißt, wenn die Größe der komprimierten Seite 9 KB beträgt, beträgt der tatsächlich belegte Speicherplatz 12 KB. 🎜🎜Spaltenkomprimierung
🎜MySQL bietet derzeit keine direkte Lösung für die Spaltenkomprimierung Es gibt eine Möglichkeit, das Land zu retten: Die von MySQL bereitgestellten Komprimierungs- und Dekomprimierungsfunktionen auf der Geschäftsebene verwenden, um Komprimierungs- und Dekomprimierungsvorgänge für Spalten durchzuführen. Das heißt, wenn Sie eine bestimmte Spalte komprimieren müssen, rufen Sie die FunktionCOMPRESS auf, um den Inhalt dieser Spalte beim Schreiben zu komprimieren, und verwenden Sie die Funktion UNCOMPRESS, um den komprimierten Inhalt zu komprimieren Beim Lesen werden die Daten dekomprimiert. 🎜🎜🎜Verwendungsszenario: Für den Fall, dass die Datenlänge einiger Spalten in der Tabelle relativ groß ist, normalerweise Varchar, Text, Blob, JSON und andere Datentypen🎜🎜Verwandte Funktionen: 🎜🎜Komprimierungsfunktion: COMPRESS( )</code >🎜🎜Dekomprimierungsfunktion: <code>UNCOMPRESS()🎜🎜Stringlängenfunktion: LENGTH()🎜🎜Unkomprimierte Stringlängenfunktion: UNCOMPRESSED_LENGTH()< /code>🎜🎜🎜🎜Test: 🎜🎜Daten einfügen: <code>in xxx (Inhalts-)Werte einfügen (compress('xxx....'))🎜🎜🎜Komprimierte Daten lesen: < code>select c_id, uncompressed_length(c_content) uncompress_len, length(c_content) compress_len from xxx🎜🎜🎜🎜🎜🎜为什么innodb提供的都是基于页面的压缩技术?
- 记录压缩:每次读写记录的时候,都要进行压缩或解压,过度依赖CPU的计算能力,性能相对会比较差
- 表空间压缩:压缩效率高,但要求表空间文件是静态不增长的,这对于我们大部分的场景都是不适用的
- 页面压缩:既能提升效率,又能在性能中取得一定的平衡
总结
- 对于一些性能不敏感的业务表,如日志表、监控表、告警表等,这些表只期望对存储空间进行优化,对性能的影响不是很关注,可以使用COMPRESS页压缩
- 对于一些比较核心的表,则比较推荐使用TPC压缩
- 列压缩过度依赖CPU,性能方面会稍差,且对业务有一定的改造成本,不够灵活,需要评估影响范围,做好切换的方案。好处是可以由业务端决定哪些数据需要压缩,并控制解压操作
- 对页面进行压缩,在业务侧不用进行什么改动,对线上完全透明,压缩方案也非常成熟
为什么要进行数据压缩?
- 由于处理器和高速缓存存储器的速度提高超过了磁盘存储设备,因此很多时候工作负载都是受限于磁盘I/O。数据压缩可以使数据占用更小的空间,可以节省磁盘I/O、减少网络I/O从而提高吞吐量,虽然会牺牲部分CPU资源作为代价
- 对于OLTP系统,经常进行update、delete、insert等操作,通过压缩表能够减少存储占用和IO消耗
- 压缩其实是一种平衡,并不一定是为了提升数据库的性能,这种平衡取决于解压缩带来的收益和开销之间的一种权衡,但压缩对存储空间来说,收益无疑是很大的
简单测试
innodb透明页压缩(TPC)
测试数据
1)创建表
- create table table_origin ( ...... ) comment '测试原表';
- create table table_compression_zlib ( ...... ) comment '测试压缩表_zlib' compression = 'zlib';
- create table table_compression_lz4 ( ...... ) comment '测试压缩表_lz4' compression = 'lz4';
2)往表中写入10w行测试数据
压缩率
SELECT NAME, FS_BLOCK_SIZE, FILE_SIZE, ALLOCATED_SIZE FROM information_schema.INNODB_TABLESPACES WHERE NAME like 'test_compress%';
-
FS_BLOCK_SIZE:文件系统块大小,也就是打孔使用的单位大小 -
FILE_SIZE:文件的表观大小,表示文件的最大大小,未压缩 -
ALLOCATED_SIZE:文件的实际大小,即磁盘上分配的空间量
压缩率:
- zlib:1320636416/3489660928 = 37.8%
- lz4:1566949376/3489660928 = 45%
耗时
- 循环插入10w条记录
- 原表:918275 ms
- zlib:878540 ms
- lz4:875259 ms
- 循环查询10w条记录
- 原表:332519 ms
- zlib:373387 ms
- lz4:343501 ms
【相关推荐:mysql视频教程】
Das obige ist der detaillierte Inhalt vonSo komprimieren Sie großen Textspeicher in MySQL. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1381
1381
 52
52

 MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL ist ein Open Source Relational Database Management System. 1) Datenbank und Tabellen erstellen: Verwenden Sie die Befehle erstellte und creatEtable. 2) Grundlegende Vorgänge: Einfügen, aktualisieren, löschen und auswählen. 3) Fortgeschrittene Operationen: Join-, Unterabfrage- und Transaktionsverarbeitung. 4) Debugging -Fähigkeiten: Syntax, Datentyp und Berechtigungen überprüfen. 5) Optimierungsvorschläge: Verwenden Sie Indizes, vermeiden Sie ausgewählt* und verwenden Sie Transaktionen.
 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
Erstellen Sie eine Datenbank mit Navicat Premium: Stellen Sie eine Verbindung zum Datenbankserver her und geben Sie die Verbindungsparameter ein. Klicken Sie mit der rechten Maustaste auf den Server und wählen Sie Datenbank erstellen. Geben Sie den Namen der neuen Datenbank und den angegebenen Zeichensatz und die angegebene Kollektion ein. Stellen Sie eine Verbindung zur neuen Datenbank her und erstellen Sie die Tabelle im Objektbrowser. Klicken Sie mit der rechten Maustaste auf die Tabelle und wählen Sie Daten einfügen, um die Daten einzufügen.
 MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL ist ein Open Source Relational Database Management -System, das hauptsächlich zum schnellen und zuverlässigen Speicher und Abrufen von Daten verwendet wird. Sein Arbeitsprinzip umfasst Kundenanfragen, Abfragebedingungen, Ausführung von Abfragen und Rückgabergebnissen. Beispiele für die Nutzung sind das Erstellen von Tabellen, das Einsetzen und Abfragen von Daten sowie erweiterte Funktionen wie Join -Operationen. Häufige Fehler umfassen SQL -Syntax, Datentypen und Berechtigungen sowie Optimierungsvorschläge umfassen die Verwendung von Indizes, optimierte Abfragen und die Partitionierung von Tabellen.
 Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
MySQL wird für seine Leistung, Zuverlässigkeit, Benutzerfreundlichkeit und Unterstützung der Gemeinschaft ausgewählt. 1.MYSQL bietet effiziente Datenspeicher- und Abruffunktionen, die mehrere Datentypen und erweiterte Abfragevorgänge unterstützen. 2. Übernehmen Sie die Architektur der Client-Server und mehrere Speichermotoren, um die Transaktion und die Abfrageoptimierung zu unterstützen. 3. Einfach zu bedienend unterstützt eine Vielzahl von Betriebssystemen und Programmiersprachen. V.
 So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
Sie können eine neue MySQL -Verbindung in Navicat erstellen, indem Sie den Schritten folgen: Öffnen Sie die Anwendung und wählen Sie eine neue Verbindung (Strg N). Wählen Sie "MySQL" als Verbindungstyp. Geben Sie die Hostname/IP -Adresse, den Port, den Benutzernamen und das Passwort ein. (Optional) Konfigurieren Sie erweiterte Optionen. Speichern Sie die Verbindung und geben Sie den Verbindungsnamen ein.
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
 MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL sind wesentliche Fähigkeiten für Entwickler. 1.MYSQL ist ein Open -Source -Relational Database Management -System, und SQL ist die Standardsprache, die zum Verwalten und Betrieb von Datenbanken verwendet wird. 2.MYSQL unterstützt mehrere Speichermotoren durch effiziente Datenspeicher- und Abruffunktionen, und SQL vervollständigt komplexe Datenoperationen durch einfache Aussagen. 3. Beispiele für die Nutzung sind grundlegende Abfragen und fortgeschrittene Abfragen wie Filterung und Sortierung nach Zustand. 4. Häufige Fehler umfassen Syntaxfehler und Leistungsprobleme, die durch Überprüfung von SQL -Anweisungen und Verwendung von Erklärungsbefehlen optimiert werden können. 5. Leistungsoptimierungstechniken umfassen die Verwendung von Indizes, die Vermeidung vollständiger Tabellenscanning, Optimierung von Join -Operationen und Verbesserung der Code -Lesbarkeit.
