


Unnötig zu sagen, dass man einfach Python verwenden kann, um einen Crawler zu erstellen. Ich habe jedoch gehört, dass das in Golang integrierte http-Paket sehr leistungsfähig ist. Auch wenn ich keine Arbeit leisten muss, möchte ich einfach nur neue Dinge lernen und die damit verbundenen Wissenspunkte überprüfen die Anfrage und Antwort des http-Protokolls. Kommen wir ohne weitere Umschweife direkt zur Sacherequests包走天下。但是呢,听说golang中内置的http包非常牛逼,咱就是说不得整点活,也刚好学习学习新东西,复习下http协议的请求和响应相关的知识点。话不多说,咱直接开整
本文章爬下必应壁纸先小试牛刀。狗头保命 狗头保命 狗头保命
graph TD 请求数据 --> 解析数据 --> 数据入库
上图的流程图大家可以看到,其实爬虫并不麻烦,整个流程就只有三步而已。接下来具体聊聊每一步需要做什么
请求数据:在这里我们需要使用golang中的内置包http包向目标地址发起请求,这一步就完成了
解析数据:这里我们需要对请求到的数据进行解析,因为不是整个请求到的数据我们都需要,我们只需要某些具体的关键的数据而已。这一步也叫数据清洗
数据入库:不难理解,这就是将解析好的数据进行入库操作
先到必应壁纸官网上观察,做爬虫的话是需要对数据特别敏感的。这是首页信息,整个页面是非常简洁的
接下来,需要调出浏览器的开发者工具(这个大家应该都非常熟悉吧,不熟悉的话很难跟下去的喔)。直接按下F12
Überblick über den Crawler-Prozess mühsam. Der gesamte Prozess besteht nur aus drei Schritten. Lassen Sie uns als Nächstes darüber sprechen, was in jedem Schritt getan werden muss Eine Anfrage an die Zieladresse wird in einem Schritt abgeschlossenLaden Sie diesen Artikel herunterBing Wallpaper
Daten analysieren: Hier müssen wir die angeforderten Daten analysieren, da wir nicht die gesamten angeforderten Daten benötigen, sondern nur bestimmte spezifische Schlüsseldaten. Dieser Schritt wird auch als Datenbereinigung bezeichnet Beobachten und führen Sie einen Crawler durch. Wenn ja, müssen Sie besonders sensibel mit den Daten umgehen. Dies sind die Homepage-Informationen. Die gesamte Seite ist sehr prägnant. Laden = „lazy“/>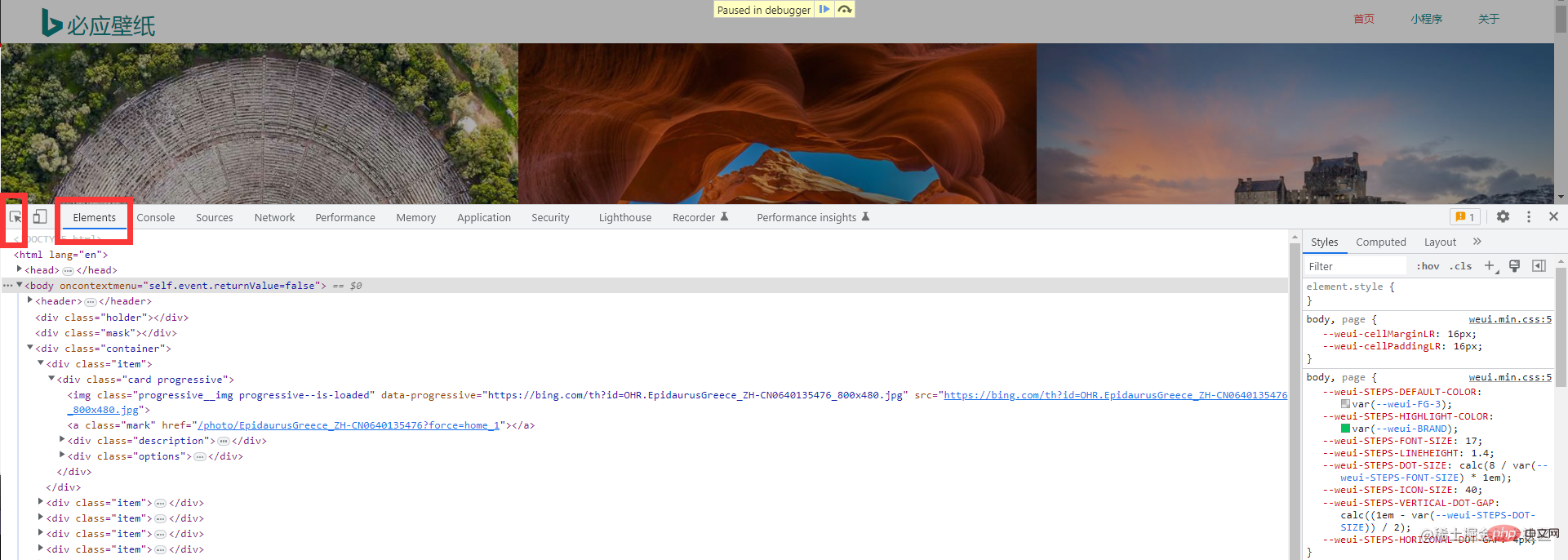
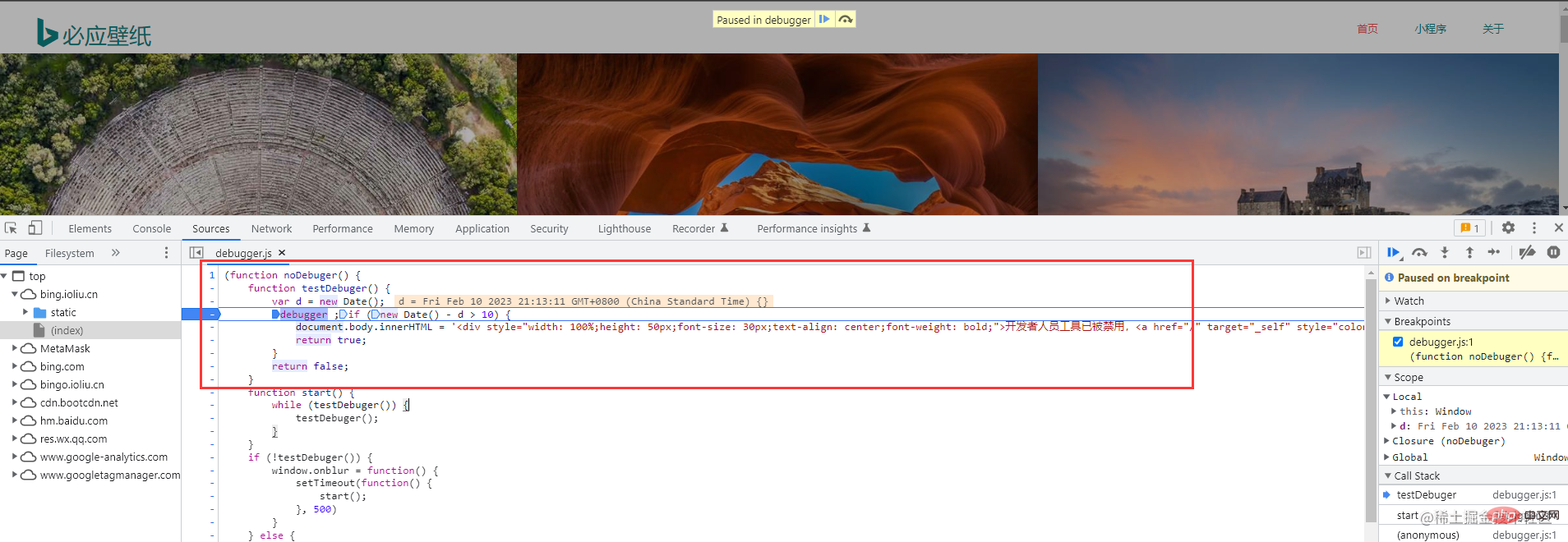
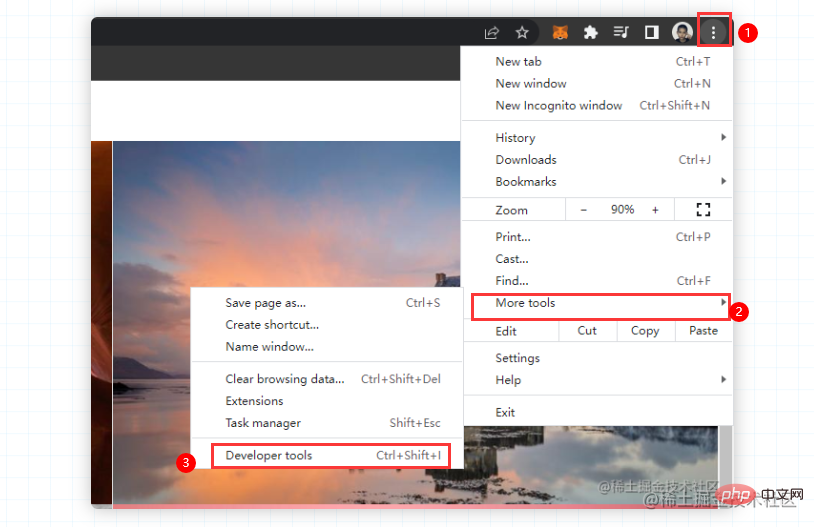
F12 oder klicken Sie mit der rechten Maustaste, um zu überprüfen 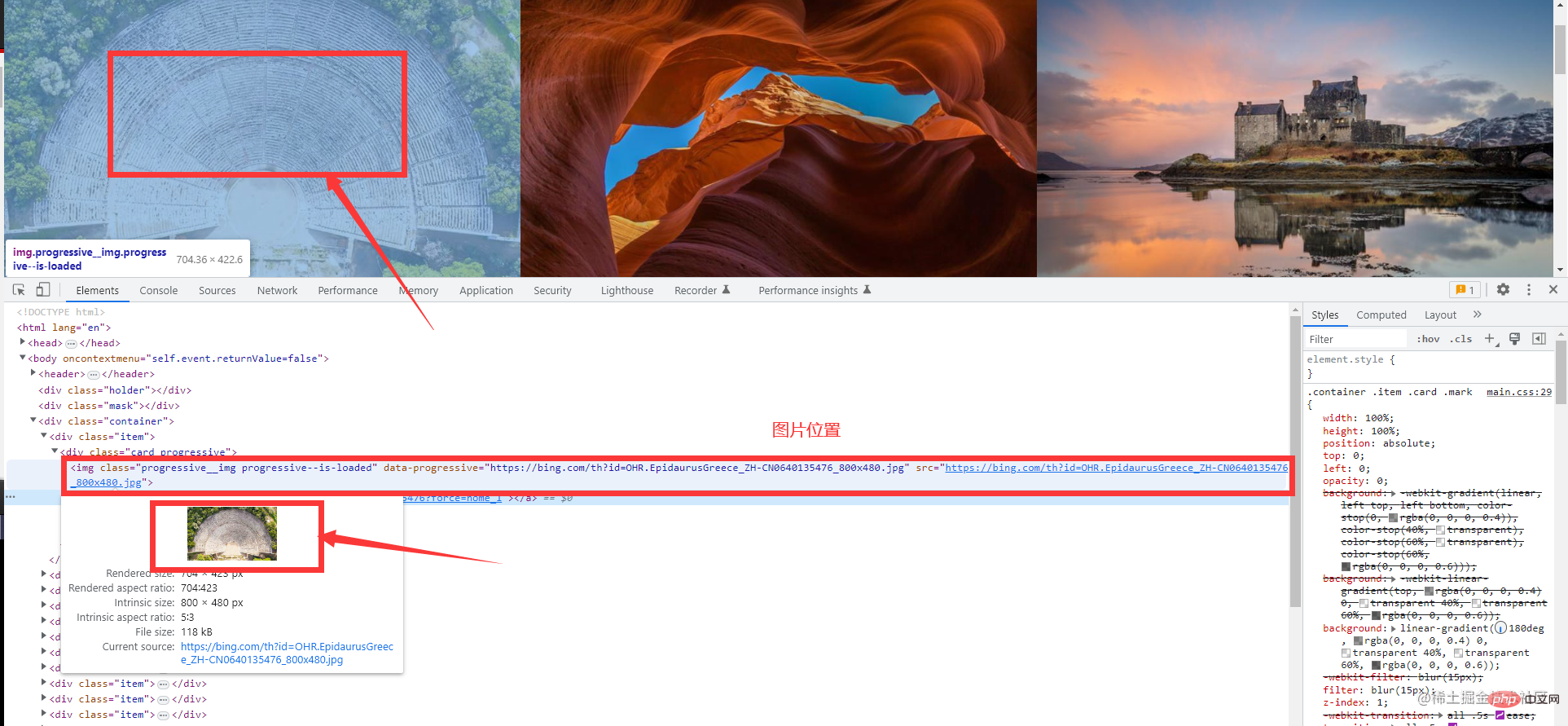 Aber was? Auf dem Bing-Hintergrundbild kann die Konsole nicht per Rechtsklick aufgerufen werden, sondern nur manuell aufgerufen werden. Machen Sie sich keine Sorgen, folgen Sie einfach dem ersten Bild. Wenn das Chrome eines Klassenkameraden auf Chinesisch ist, wird derselbe Vorgang ausgeführt. Wählen Sie weitere Tools und Entwicklertools aus.
Aber was? Auf dem Bing-Hintergrundbild kann die Konsole nicht per Rechtsklick aufgerufen werden, sondern nur manuell aufgerufen werden. Machen Sie sich keine Sorgen, folgen Sie einfach dem ersten Bild. Wenn das Chrome eines Klassenkameraden auf Chinesisch ist, wird derselbe Vorgang ausgeführt. Wählen Sie weitere Tools und Entwicklertools aus.
Code-Praxis
 Das Folgende sind die Daten zum Crawlen einer Seite
Das Folgende sind die Daten zum Crawlen einer Seite
package main
import (
"fmt"
"github.com/PuerkitoBio/goquery"
"io"
"io/ioutil"
"log"
"net/http"
"os"
"time"
)
func Run(method, url string, body io.Reader, client *http.Client) {
req, err := http.NewRequest(method, url, body)
if err != nil {
log.Println("获取请求对象失败")
return
}
req.Header.Set("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36")
resp, err := client.Do(req)
if err != nil {
log.Println("发起请求失败")
return
}
if resp.StatusCode != http.StatusOK {
log.Printf("请求失败,状态码:%d", resp.StatusCode)
return
}
defer resp.Body.Close() // 关闭响应对象中的body
query, err := goquery.NewDocumentFromReader(resp.Body)
if err != nil {
log.Println("生成goQuery对象失败")
return
}
query.Find(".container .item").Each(func(i int, s *goquery.Selection) {
imgUrl, _ := s.Find("a.ctrl.download").Attr("href")
imgName := s.Find(".description>h3").Text()
fmt.Println(imgUrl)
fmt.Println(imgName)
DownloadImage(imgUrl, i, client)
time.Sleep(time.Second)
fmt.Println("-------------------------")
})
}
func DownloadImage(url string, index int, client *http.Client) {
req, err := http.NewRequest("POST", url, nil)
if err != nil {
log.Println("获取请求对象失败")
return
}
req.Header.Set("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36")
resp, err := client.Do(req)
if err != nil {
log.Println("发起请求失败")
return
}
data, err := ioutil.ReadAll(resp.Body)
if err != nil {
log.Println("读取请求体失败")
return
}
baseDir := "./image/image-%d.jpg"
f, err := os.OpenFile(fmt.Sprintf(baseDir, index), os.O_CREATE|os.O_TRUNC|os.O_WRONLY, 0666)
if err != nil {
log.Println("打开文件失败", err.Error())
return
}
defer f.Close()
_, err = f.Write(data)
if err != nil {
log.Println("写入数据失败")
return
}
fmt.Println("下载图片成功")
}
func main() {
client := &http.Client{}
url := "https://bing.ioliu.cn/?p=%d"
method := "GET"
Run(method, url, nil, client)
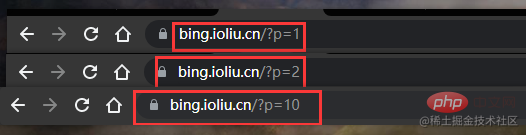
}Haben Sie etwas gefunden? Die erste Seite ist p=1, die zweite Seite ist p=2 und die zehnte Seite ist p=10 In unserem Beispiel verwenden wir ein Toolpaket eines Drittanbieters zum Parsen von Webseitendaten, da die Verwendung regulärer Ausdrücke wirklich zu mühsam ist
regulär: Integriertes Paket, nicht empfohlen, reguläre Regeln sind schwer zu schreibenDas obige ist der detaillierte Inhalt vonAusführliche Erklärung, wie Sie mit Golang Bing-Hintergrundbilder crawlen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Nodejs implementiert Crawler
Nodejs implementiert Crawler
 So definieren Sie Variablen in Golang
So definieren Sie Variablen in Golang
 Welche Datenkonvertierungsmethoden gibt es in Golang?
Welche Datenkonvertierungsmethoden gibt es in Golang?
 Welche sind die am häufigsten verwendeten Bibliotheken in Golang?
Welche sind die am häufigsten verwendeten Bibliotheken in Golang?
 Was ist der Unterschied zwischen Golang und Python?
Was ist der Unterschied zwischen Golang und Python?
 So löschen Sie Array-Elemente in JavaScript
So löschen Sie Array-Elemente in JavaScript
 So lesen Sie Excel-Daten in HTML
So lesen Sie Excel-Daten in HTML
 An welcher Börse gibt es FIL-Münzen?
An welcher Börse gibt es FIL-Münzen?

 Laden Sie diesen Artikel herunter
Laden Sie diesen Artikel herunter Probieren wir es zuerst aus. Der Kopf des Hundes rettet sein Leben. Der Kopf des Hundes rettet sein Leben.
Probieren wir es zuerst aus. Der Kopf des Hundes rettet sein Leben. Der Kopf des Hundes rettet sein Leben. 



![Beginnen Sie schnell mit dem Golang Gin-Framework [Verwenden Sie Gin, um ein gleichzeitiges IM-Instant-Messaging-System auf Millionenebene aufzubauen]](https://img.php.cn/upload/course/000/000/068/63a2b21046723283.jpg)






![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



