

Was ist saubere Architektur? Wie implementiert man es mit Node?

Was ist saubere Architektur? Dieser Artikel führt Sie durch Clean Architecture und spricht darüber, wie Sie Clean Architecture mit Node.js implementieren. Ich hoffe, er wird Ihnen hilfreich sein!

Clean Architecture
Clean Architecture ist ein von Robert C. Martin vorgeschlagenes Software-Architekturmuster. Der Zweck besteht darin, das System zu schichten und eine Trennung der Belange zu erreichen, wodurch das System leichter zu verstehen, zu warten und zu erweitern ist. Diese Architektur unterteilt das System von innen nach außen in vier Ebenen: Entitätsschicht, Anwendungsfallschicht, Präsentationsschicht, Infrastruktur (Repository, Framework usw.).
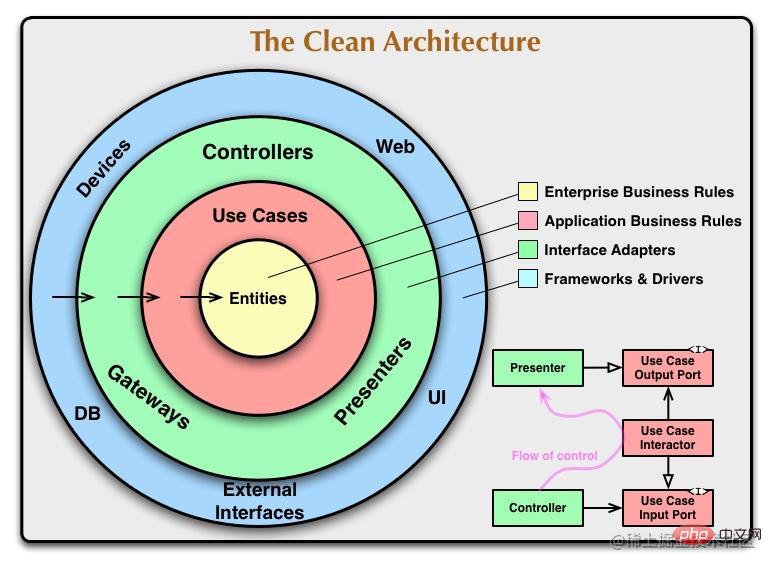
In diesem Artikel stellen wir vor, wie man Clean Architecture mit Node.js implementiert, und stellen einige Beispielcodes zur Verfügung, um die Schlüsselkonzepte der Architektur zu demonstrieren.
Als nächstes verwenden wir das TypeScript-Projektbeispiel (github.com/lulusir/cle…). Das Projekt verwendet eine Monorepo-Struktur und wird mit Rush.js verwaltet. Der Serverordner enthält drei Unterprojekte: Core, Koa und NestJS-App. Core ist die Kerngeschäftslogik, Koa verwendet Koa + Prisma als zugrunde liegendes Framework-Webprojekt und NestJS-App verwendet NestJS + Typeorm zugrunde liegendes Gerüst. Der Zweck besteht darin, zu demonstrieren, wie dieselbe Geschäftslogik verschiedene Frameworks überbrücken kann. [Verwandte Tutorial-Empfehlungen: nodejs-Video-Tutorial, Programmierlehre]
In diesem Projekt enthält die Entitätsschicht Entitätsobjekte und zugehörige Geschäftsregeln und -logik, die Anwendungsfallschicht enthält die Anwendungsfälle und die Geschäftslogik des Systems. und die Repository-Schicht ist dafür verantwortlich, Daten zu speichern und abzurufen. Die Präsentationsschicht wird der externen http-Schnittstelle ausgesetzt.
Projektfunktionen:
Realisieren Sie eine Funktion zum Veröffentlichen und Durchsuchen von Beiträgen.
Benutzererstellung, Abfrage.
-
Veröffentlichung, Bearbeitung, Abfrage und Löschung von Beiträgen
├── server │ ├── core // 核心业务逻辑 │ │ └── src │ │ ├── domain │ │ ├── repository │ │ └── useCase │ ├── koa │ │ └── src │ │ ├── post │ │ └── user │ └── nestjs-app │ ├── src │ ├── post │ │ ├── dto │ │ └── entities │ └── user │ └── entities └── web
Nach dem Login kopieren
Kern: Kern ist der Code der Kerngeschäftslogik.
Domäne: Speichert entitätsbezogenen Code, z. B. geschäftsspezifische Modelle usw.- Anwendungsfälle: Speichert geschäftslogikbezogenen Code, z. B. die Verarbeitung von Geschäftslogik und Daten Überprüfung und Aufruf des Repositorys usw. Repository: Speicher und zugehörige Schnittstellen für externe Speichersysteme
- koa/nestjs-app: Der tatsächliche Verbraucher des Kerns
- Projektfunktionen
Verwenden Sie die Monorepo-Projektstruktur, um mehrere zusammengehörige Projekte einfach zu verwalten.
Es werden mehrere Beispielanwendungen bereitgestellt, um den schnellen Einstieg zu erleichtern.- Basiert auf TypeScript und verbessert die Lesbarkeit und Wartbarkeit des Codes. Im Kern haben wir den Kerngeschäftslogikcode. Diese Ebene enthält Domänen, Repository-Schnittstellen und Anwendungsfälle. Domänen enthalten Code, der sich auf Entitäten bezieht, beispielsweise auf ein bestimmtes Geschäftsmodell. Das Repository enthält relevante Schnittstellen zu externen Speichersystemen. Anwendungsfälle enthalten Code im Zusammenhang mit der Geschäftslogik, z. B. zur Handhabung der Geschäftslogik, zur Datenvalidierung und zum Aufrufen von Repositorys. Auf der Koa/NestJS-App-Ebene haben wir tatsächliche Verbraucher auf der Kernebene. Sie implementieren spezifische Router und Repositorys basierend auf den von der Kernschicht bereitgestellten Schnittstellen. Einer der Hauptvorteile der Verwendung von Clean Architecture besteht darin, dass die Geschäftslogik von der technischen Implementierung getrennt wird. Dies bedeutet, dass Sie problemlos zwischen verschiedenen Frameworks und Bibliotheken wechseln können, ohne die Kerngeschäftslogik zu ändern. In unserem Beispiel können wir zwischen koa und nestjs-app wechseln und dabei die gleiche Kerngeschäftslogik beibehalten.
// server/core/src/domain/post.ts
import { User } from "./user";
export class Post {
author: User | null = null;
content: string = "";
updateAt: Date = new Date(); // timestamp;
createdAt: Date = new Date(); // timestamp;
title: string = "";
id: number = -1;
}
// server/core/src/domain/user.ts
export class User {
name: string = ''
email: string = ''
id: number = -1
}Nach dem Login kopieren
Speicherschnittstelle definieren// server/core/src/domain/post.ts
import { User } from "./user";
export class Post {
author: User | null = null;
content: string = "";
updateAt: Date = new Date(); // timestamp;
createdAt: Date = new Date(); // timestamp;
title: string = "";
id: number = -1;
}
// server/core/src/domain/user.ts
export class User {
name: string = ''
email: string = ''
id: number = -1
}import { Post } from "../domain/post";
export interface IPostRepository {
create(post: Post): Promise<boolean>;
find(id: number): Promise<Post>;
update(post: Post): Promise<boolean>;
delete(post: Post): Promise<boolean>;
findMany(options: { authorId: number }): Promise<Post[]>;
}
...
import { User } from "../domain/user";
export interface IUserRepository {
create(user: User): Promise<boolean>;
find(id: number): Promise<User>;
}Nach dem Login kopieren
Anwendungsfallschicht definierenimport { Post } from "../domain/post";
export interface IPostRepository {
create(post: Post): Promise<boolean>;
find(id: number): Promise<Post>;
update(post: Post): Promise<boolean>;
delete(post: Post): Promise<boolean>;
findMany(options: { authorId: number }): Promise<Post[]>;
}
...
import { User } from "../domain/user";
export interface IUserRepository {
create(user: User): Promise<boolean>;
find(id: number): Promise<User>;
}import { User } from "../domain/user";
import { IUserRepository } from "../repository/user";
export class UCUser {
constructor(public userRepo: IUserRepository) {}
find(id: number) {
return this.userRepo.find(id);
}
create(name: string, email: string) {
if (email.includes("@test.com")) {
const user = new User();
user.email = email;
user.name = name;
return this.userRepo.create(user);
}
throw Error("Please use legal email");
}
}Nach dem Login kopieren
koa. Projektimport { User } from "../domain/user";
import { IUserRepository } from "../repository/user";
export class UCUser {
constructor(public userRepo: IUserRepository) {}
find(id: number) {
return this.userRepo.find(id);
}
create(name: string, email: string) {
if (email.includes("@test.com")) {
const user = new User();
user.email = email;
user.name = name;
return this.userRepo.create(user);
}
throw Error("Please use legal email");
}
}im Koa-Projekt implementierte Storage-Layer-Schnittstelle
// server/koa/src/user/user.repo.ts
import { PrismaClient } from "@prisma/client";
import { IUserRepository, User } from "core";
export class UserRepository implements IUserRepository {
prisma = new PrismaClient();
async create(user: User): Promise<boolean> {
const d = await this.prisma.user_orm_entity.create({
data: {
email: user.email,
name: user.name,
},
});
return !!d;
}
async find(id: number): Promise<User> {
const d = await this.prisma.user_orm_entity.findFirst({
where: {
id: id,
},
});
if (d) {
const u = new User();
u.email = d?.email;
u.id = d?.id;
u.name = d?.name;
return u;
}
throw Error("user id " + id + "not found");
}
}Nach dem Login kopieren
Implementieren von HTTP-Routing (Präsentationsschicht) im Koa-Projekt// server/koa/src/user/user.repo.ts
import { PrismaClient } from "@prisma/client";
import { IUserRepository, User } from "core";
export class UserRepository implements IUserRepository {
prisma = new PrismaClient();
async create(user: User): Promise<boolean> {
const d = await this.prisma.user_orm_entity.create({
data: {
email: user.email,
name: user.name,
},
});
return !!d;
}
async find(id: number): Promise<User> {
const d = await this.prisma.user_orm_entity.findFirst({
where: {
id: id,
},
});
if (d) {
const u = new User();
u.email = d?.email;
u.id = d?.id;
u.name = d?.name;
return u;
}
throw Error("user id " + id + "not found");
}
}// server/koa/src/user/user.controller.ts
import Router from "@koa/router";
import { UCUser } from "core";
import { UserRepository } from "./user.repo";
export const userRouter = new Router({
prefix: "/user",
});
userRouter.get("/:id", async (ctx, next) => {
try {
const service = new UCUser(new UserRepository());
if (ctx.params.id) {
const u = await service.find(+ctx.params.id);
ctx.response.body = JSON.stringify(u);
}
} catch (e) {
ctx.throw(400, "some error on get user", e.message);
}
await next();
});Nach dem Login kopierennest-js-Projekt
nestjs-Projektbeispiele finden Sie in diesem Pfad (
github.com/lulusir/cle…Ich werde es nicht veröffentlichen hier Code Abschließend
Bitte beachten Sie, dass wir im eigentlichen Projekt die Kerngeschäftslogik nicht in einem separaten Lager (d. h. Kern) ablegen, sondern lediglich die Verwendung derselben Geschäftslogik unter verschiedenen Frameworks demonstrieren.
Indem wir das Geschäft platzieren Die Logik ist vom Framework getrennt und Sie können problemlos zwischen verschiedenen Frameworks und Bibliotheken wechseln, ohne die Kerngeschäftslogik zu ändern. Wenn Sie skalierbare und wartbare Anwendungen erstellen möchten, ist Clean Architecture auf jeden Fall eine Überlegung wert.
Wenn Sie demonstrieren möchten, wie Sie eine Verbindung zu anderen Frameworks herstellen, können Sie es im Kommentarbereich vorlegen.
Projektadresse (github.com/lulusir/cle… Wenn Sie es gut finden, können Sie ihm einen Stern geben , danke
Weitere Node-bezogene Informationen. Weitere Informationen finden Sie unter: nodejs-Tutorial!
Das obige ist der detaillierte Inhalt vonWas ist saubere Architektur? Wie implementiert man es mit Node?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
// server/koa/src/user/user.controller.ts
import Router from "@koa/router";
import { UCUser } from "core";
import { UserRepository } from "./user.repo";
export const userRouter = new Router({
prefix: "/user",
});
userRouter.get("/:id", async (ctx, next) => {
try {
const service = new UCUser(new UserRepository());
if (ctx.params.id) {
const u = await service.find(+ctx.params.id);
ctx.response.body = JSON.stringify(u);
}
} catch (e) {
ctx.throw(400, "some error on get user", e.message);
}
await next();
});Abschließend
Bitte beachten Sie, dass wir im eigentlichen Projekt die Kerngeschäftslogik nicht in einem separaten Lager (d. h. Kern) ablegen, sondern lediglich die Verwendung derselben Geschäftslogik unter verschiedenen Frameworks demonstrieren.
Indem wir das Geschäft platzieren Die Logik ist vom Framework getrennt und Sie können problemlos zwischen verschiedenen Frameworks und Bibliotheken wechseln, ohne die Kerngeschäftslogik zu ändern. Wenn Sie skalierbare und wartbare Anwendungen erstellen möchten, ist Clean Architecture auf jeden Fall eine Überlegung wert.
Wenn Sie demonstrieren möchten, wie Sie eine Verbindung zu anderen Frameworks herstellen, können Sie es im Kommentarbereich vorlegen.
Projektadresse (github.com/lulusir/cle… Wenn Sie es gut finden, können Sie ihm einen Stern geben , danke
Weitere Node-bezogene Informationen. Weitere Informationen finden Sie unter: nodejs-Tutorial!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So implementieren Sie ein Online-Spracherkennungssystem mit WebSocket und JavaScript
Dec 17, 2023 pm 02:54 PM
So implementieren Sie ein Online-Spracherkennungssystem mit WebSocket und JavaScript
Dec 17, 2023 pm 02:54 PM
So implementieren Sie mit WebSocket und JavaScript ein Online-Spracherkennungssystem. Einführung: Mit der kontinuierlichen Weiterentwicklung der Technologie ist die Spracherkennungstechnologie zu einem wichtigen Bestandteil des Bereichs der künstlichen Intelligenz geworden. Das auf WebSocket und JavaScript basierende Online-Spracherkennungssystem zeichnet sich durch geringe Latenz, Echtzeit und plattformübergreifende Eigenschaften aus und hat sich zu einer weit verbreiteten Lösung entwickelt. In diesem Artikel wird erläutert, wie Sie mit WebSocket und JavaScript ein Online-Spracherkennungssystem implementieren.
 WebSocket und JavaScript: Schlüsseltechnologien zur Implementierung von Echtzeitüberwachungssystemen
Dec 17, 2023 pm 05:30 PM
WebSocket und JavaScript: Schlüsseltechnologien zur Implementierung von Echtzeitüberwachungssystemen
Dec 17, 2023 pm 05:30 PM
WebSocket und JavaScript: Schlüsseltechnologien zur Realisierung von Echtzeit-Überwachungssystemen Einführung: Mit der rasanten Entwicklung der Internet-Technologie wurden Echtzeit-Überwachungssysteme in verschiedenen Bereichen weit verbreitet eingesetzt. Eine der Schlüsseltechnologien zur Erzielung einer Echtzeitüberwachung ist die Kombination von WebSocket und JavaScript. In diesem Artikel wird die Anwendung von WebSocket und JavaScript in Echtzeitüberwachungssystemen vorgestellt, Codebeispiele gegeben und deren Implementierungsprinzipien ausführlich erläutert. 1. WebSocket-Technologie
 Was ist die Architektur und das Arbeitsprinzip von Spring Data JPA?
Apr 17, 2024 pm 02:48 PM
Was ist die Architektur und das Arbeitsprinzip von Spring Data JPA?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA basiert auf der JPA-Architektur und interagiert mit der Datenbank über Mapping, ORM und Transaktionsmanagement. Sein Repository bietet CRUD-Operationen und abgeleitete Abfragen vereinfachen den Datenbankzugriff. Darüber hinaus nutzt es Lazy Loading, um Daten nur bei Bedarf abzurufen und so die Leistung zu verbessern.
 1,3 ms dauert 1,3 ms! Tsinghuas neueste Open-Source-Architektur für mobile neuronale Netzwerke RepViT
Mar 11, 2024 pm 12:07 PM
1,3 ms dauert 1,3 ms! Tsinghuas neueste Open-Source-Architektur für mobile neuronale Netzwerke RepViT
Mar 11, 2024 pm 12:07 PM
Papieradresse: https://arxiv.org/abs/2307.09283 Codeadresse: https://github.com/THU-MIG/RepViTRepViT funktioniert gut in der mobilen ViT-Architektur und zeigt erhebliche Vorteile. Als nächstes untersuchen wir die Beiträge dieser Studie. In dem Artikel wird erwähnt, dass Lightweight-ViTs bei visuellen Aufgaben im Allgemeinen eine bessere Leistung erbringen als Lightweight-CNNs, hauptsächlich aufgrund ihres Multi-Head-Selbstaufmerksamkeitsmoduls (MSHA), das es dem Modell ermöglicht, globale Darstellungen zu lernen. Allerdings wurden die architektonischen Unterschiede zwischen Lightweight-ViTs und Lightweight-CNNs noch nicht vollständig untersucht. In dieser Studie integrierten die Autoren leichte ViTs in die effektiven
 Wie steil ist die Lernkurve der Golang-Framework-Architektur?
Jun 05, 2024 pm 06:59 PM
Wie steil ist die Lernkurve der Golang-Framework-Architektur?
Jun 05, 2024 pm 06:59 PM
Die Lernkurve der Go-Framework-Architektur hängt von der Vertrautheit mit der Go-Sprache und der Backend-Entwicklung sowie der Komplexität des gewählten Frameworks ab: einem guten Verständnis der Grundlagen der Go-Sprache. Es ist hilfreich, Erfahrung in der Backend-Entwicklung zu haben. Frameworks mit unterschiedlicher Komplexität führen zu unterschiedlichen Lernkurven.
 JavaScript und WebSocket: Aufbau eines effizienten Echtzeit-Wettervorhersagesystems
Dec 17, 2023 pm 05:13 PM
JavaScript und WebSocket: Aufbau eines effizienten Echtzeit-Wettervorhersagesystems
Dec 17, 2023 pm 05:13 PM
JavaScript und WebSocket: Aufbau eines effizienten Echtzeit-Wettervorhersagesystems Einführung: Heutzutage ist die Genauigkeit von Wettervorhersagen für das tägliche Leben und die Entscheidungsfindung von großer Bedeutung. Mit der Weiterentwicklung der Technologie können wir genauere und zuverlässigere Wettervorhersagen liefern, indem wir Wetterdaten in Echtzeit erhalten. In diesem Artikel erfahren Sie, wie Sie mit JavaScript und WebSocket-Technologie ein effizientes Echtzeit-Wettervorhersagesystem aufbauen. In diesem Artikel wird der Implementierungsprozess anhand spezifischer Codebeispiele demonstriert. Wir
 Einfaches JavaScript-Tutorial: So erhalten Sie den HTTP-Statuscode
Jan 05, 2024 pm 06:08 PM
Einfaches JavaScript-Tutorial: So erhalten Sie den HTTP-Statuscode
Jan 05, 2024 pm 06:08 PM
JavaScript-Tutorial: So erhalten Sie HTTP-Statuscode. Es sind spezifische Codebeispiele erforderlich. Vorwort: Bei der Webentwicklung ist häufig die Dateninteraktion mit dem Server erforderlich. Bei der Kommunikation mit dem Server müssen wir häufig den zurückgegebenen HTTP-Statuscode abrufen, um festzustellen, ob der Vorgang erfolgreich ist, und die entsprechende Verarbeitung basierend auf verschiedenen Statuscodes durchführen. In diesem Artikel erfahren Sie, wie Sie mit JavaScript HTTP-Statuscodes abrufen und einige praktische Codebeispiele bereitstellen. Verwenden von XMLHttpRequest
 Handzerreißen von Llama3 Schicht 1: Implementierung von llama3 von Grund auf
Jun 01, 2024 pm 05:45 PM
Handzerreißen von Llama3 Schicht 1: Implementierung von llama3 von Grund auf
Jun 01, 2024 pm 05:45 PM
1. Architektur von Llama3 In dieser Artikelserie implementieren wir llama3 von Grund auf. Die Gesamtarchitektur von Llama3: Stellen Sie sich die Modellparameter von Llama3 vor: Werfen wir einen Blick auf die tatsächlichen Werte dieser Parameter im Llama3-Modell. Bild [1] Kontextfenster (Kontextfenster) Beim Instanziieren der LlaMa-Klasse definiert die Variable max_seq_len das Kontextfenster. Es gibt andere Parameter in der Klasse, aber dieser Parameter steht in direktem Zusammenhang mit dem Transformatormodell. Die max_seq_len beträgt hier 8K. Bild [2] Wortschatzgröße und AufmerksamkeitL
