
Dieser Artikel hat 20 klassische Redis-Interviewfragen für Sie zusammengestellt. Ich hoffe, er wird Ihnen hilfreich sein.

Redis, der vollständige englische Name lautet Remote Dictionary Server (Remote Dictionary Service), ist eine Open-Source-Protokolltyp-Schlüsselwertdatenbank, die in ANSI C-Sprache geschrieben ist, das Netzwerk unterstützt, speicherbasiert sein kann und kann bleibt bestehen und bietet eine mehrsprachige API.
Anders als bei der MySQL-Datenbank werden Redis-Daten im Speicher gespeichert. Seine Lese- und Schreibgeschwindigkeiten sind sehr hoch und können mehr als 100.000 Lese- und Schreibvorgänge pro Sekunde bewältigen. Daher wird Redis häufig beim Caching verwendet. Darüber hinaus wird Redis auch häufig für verteilte Sperren verwendet. Darüber hinaus unterstützt Redis Transaktionen, Persistenz, LUA-Skripte, LRU-gesteuerte Ereignisse und verschiedene Clusterlösungen. 2. Lassen Sie uns über die grundlegenden Datenstrukturtypen von Redis sprechen. Die meisten Freunde wissen, dass Redis die folgenden fünf Grundtypen hat:
String (Zeichenfolge) Hash (Hash)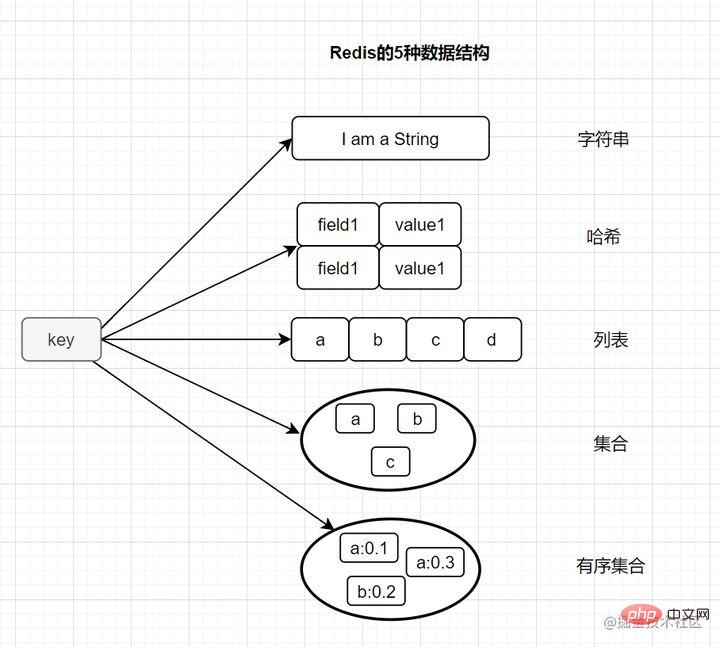
Schlüsselwert festlegen, <code>get key usw.Anwendungsszenarien: gemeinsame Sitzung, verteilte Sperre, Zähler, aktuelles Limit. int (8-Byte lange Ganzzahl)/embstr (kleiner oder gleich 39-Byte-String)/raw (größer als 39-Byte-String)
set key value、get key等int(8字节长整型)/embstr(小于等于39字节字符串)/raw(大于39个字节字符串)
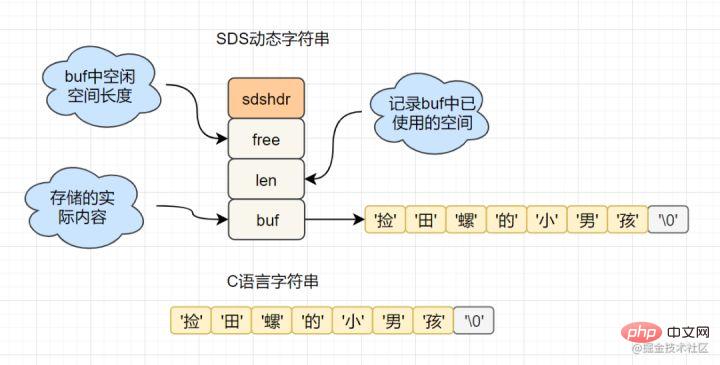
C语言的字符串是char[]实现的,而Redis使用SDS(simple dynamic string) 封装,sds源码如下:
struct sdshdr{
unsigned int len; // 标记buf的长度
unsigned int free; //标记buf中未使用的元素个数
char buf[]; // 存放元素的坑
}SDS 结构图如下:
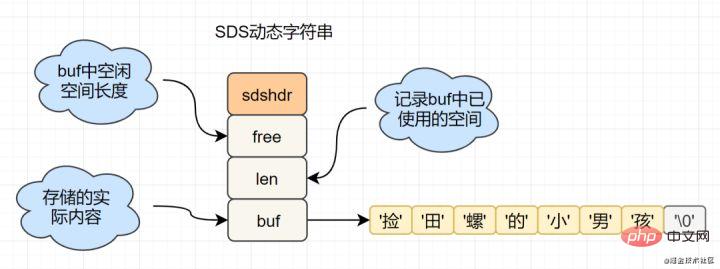
Redis为什么选择SDS结构,而C语言原生的char[]不香吗?
举例其中一点,SDS中,O(1)时间复杂度,就可以获取字符串长度;而C 字符串,需要遍历整个字符串,时间复杂度为O(n)
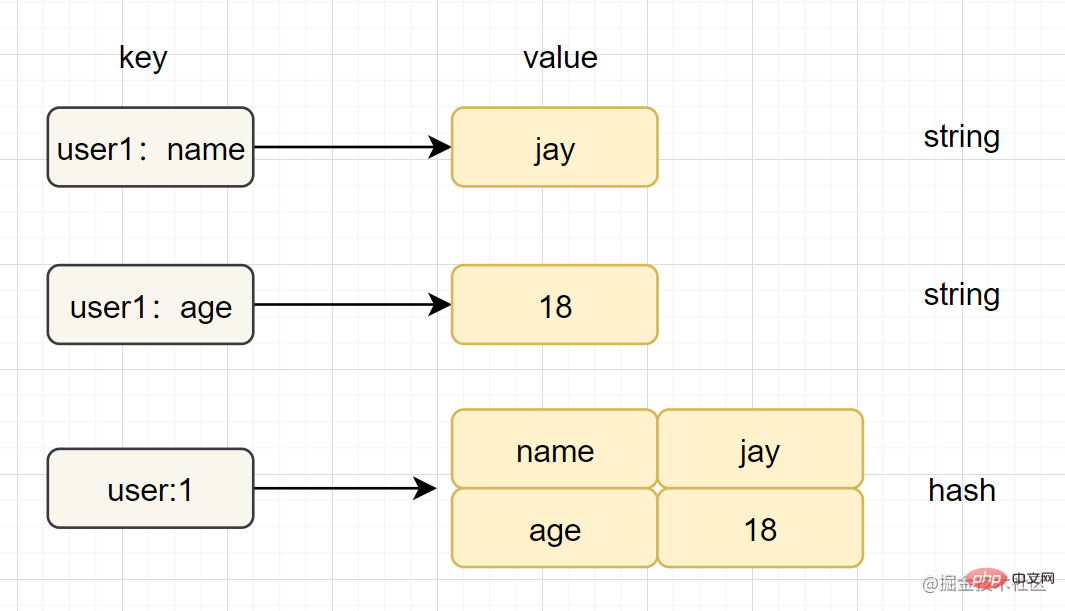
Hash(哈希)
hset key field value 、hget key fieldziplist(压缩列表) 、hashtable(哈希表)字符串和哈希类型对比如下图:
List(列表)
lpush key value [value ...] 、lrange key start end一图看懂list类型的插入与弹出:
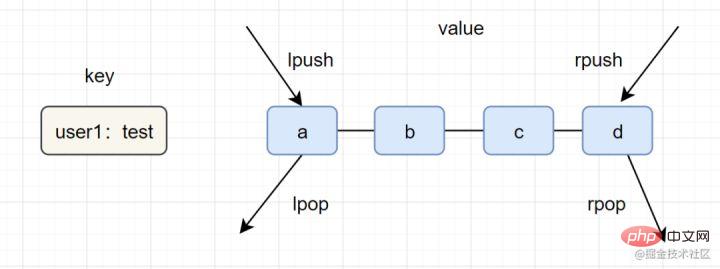
list应用场景参考以下:
- lpush+lpop=Stack(栈)
- lpush+rpop=Queue(队列)
- lpsh+ltrim=Capped Collection(有限集合)
- lpush+brpop=Message Queue(消息队列)
Set(集合)
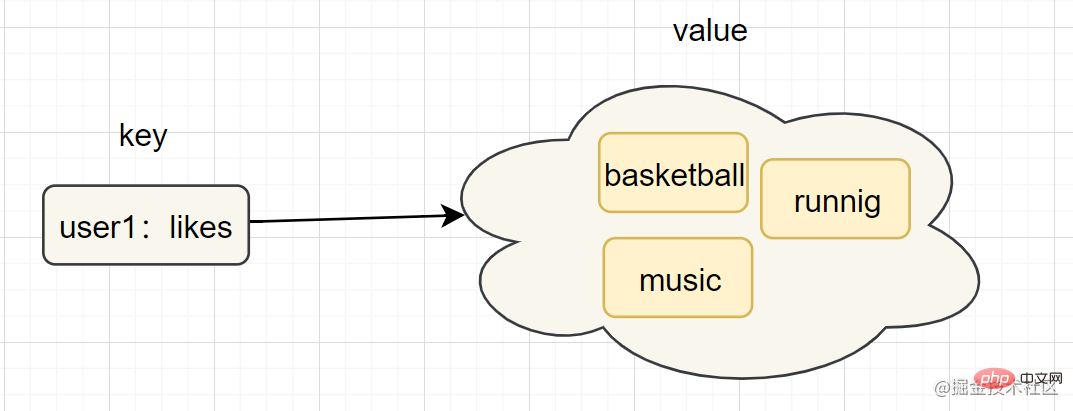
sadd key element [element ...]、smembers keyintset(整数集合)、hashtable(哈希表)C Die Sprachzeichenfolge wird durch char[] implementiert und Redis wird mit zadd user:ranking:2021-03-03 Jay 3
Warum hat sich Redis für das entschieden? Struktur, während die C-Sprache native Ist char[] nicht lecker?
🎜Zum Beispiel können Sie in SDS die Stringlänge mit der Zeitkomplexität O(1) erhalten, während Sie für den C-String den gesamten String durchlaufen müssen und die Zeitkomplexität O(n) beträgt🎜🎜Hash (Hash)🎜🎜🎜Einführung: In Redis bezieht sich der Hash-Typ auf v (Wert) selbst, was eine Schlüssel-Wert-Paar-Struktur (k-v) ist🎜🎜Einfaches Anwendungsbeispiel:hset key field value< /code>, <code>hget key field🎜🎜Interne Codierung:ziplist (komprimierte Liste),hashtable (Hash-Tabelle)🎜🎜Anwendungsszenarien: Caching Benutzerinformationen usw. 🎜🎜🎜Hinweis🎜: Wenn hgetall in der Entwicklung verwendet wird und viele Hash-Elemente vorhanden sind, kann dies dazu führen, dass Redis blockiert. Sie können hscan verwenden. Wenn Sie nur einige Felder abrufen möchten, empfiehlt sich die Verwendung von hmget. 🎜🎜🎜Der Vergleich zwischen String- und Hash-Typen ist wie folgt: 🎜🎜🎜🎜Liste (Liste)🎜🎜🎜Einführung: Der Listentyp (Liste) wird zum Speichern mehrerer geordneter Zeichenfolgen verwendet. Eine Liste kann bis zu 2^32-1 Elemente speichern. 🎜🎜Einfache und praktische Beispiele:
lpush key value [value ...],lrange key start end🎜🎜Interne Codierung: Ziplist (komprimierte Liste), Linkedlist (verknüpfte Liste). )🎜 🎜Anwendungsszenarien: Nachrichtenwarteschlange, Artikelliste, 🎜🎜🎜Sie können das Einfügen und Popup des Listentyps in einem Bild verstehen: 🎜🎜🎜🎜lpush+lpop=Stack (Stack) 🎜🎜lpush+rpop=Queue ( queue) 🎜🎜lpsh+ltrim =Capped Collection (begrenzte Sammlung)🎜🎜lpush+brpop=Message Queue (Nachrichtenwarteschlange)🎜🎜🎜Set (set)🎜🎜sadd key element [element ...],smembers key🎜🎜Interne Codierung:intset (integer set), < code>hashtable (Hash-Tabelle)🎜🎜🎜Hinweis🎜: smembers, lrange und hgetall sind relativ umfangreiche Befehle. Wenn zu viele Elemente vorhanden sind und die Möglichkeit besteht, dass Redis blockiert wird, können Sie es mit sscan vervollständigen . 🎜🎜Anwendungsszenarien: Benutzer-Tags, Generierung von Zufallszahlenlotterien, soziale Bedürfnisse. 🎜🎜🎜Ordered Set (zset)🎜
- Einführung: Eine sortierte Sammlung von Zeichenfolgen und Elementen kann nicht wiederholt werden
- Einfaches Formatbeispiel:
zadd key score member [score member...],zrank key memberzadd key score member [score member ...],zrank key member- 底层内部编码:
Zugrunde liegende interne Codierung:ziplist(压缩列表)、skiplist(跳跃表)ziplist (komprimierte Liste),skiplist (Überspringliste)Anwendungsszenarien: Rankings, soziale Bedürfnisse (z. B. Benutzer-Likes).2.2 Drei spezielle Datentypen von Redis
Geo: Die von Redis 3.2 eingeführte geografische Standortpositionierung wird zum Speichern geografischer Standortinformationen und zum Bearbeiten der gespeicherten Informationen verwendet. HyperLogLog: Eine Datenstruktur, die für statistische Kardinalitätsalgorithmen verwendet wird, wie z. B. UV für statistische Websites. Bitmaps: Verwenden Sie ein Bit, um den Status eines Elements abzubilden. In Redis basiert die unterste Ebene auf dem String-Typ. Sie können Bitmaps in ein Array mit Bits als Einheit umwandeln.
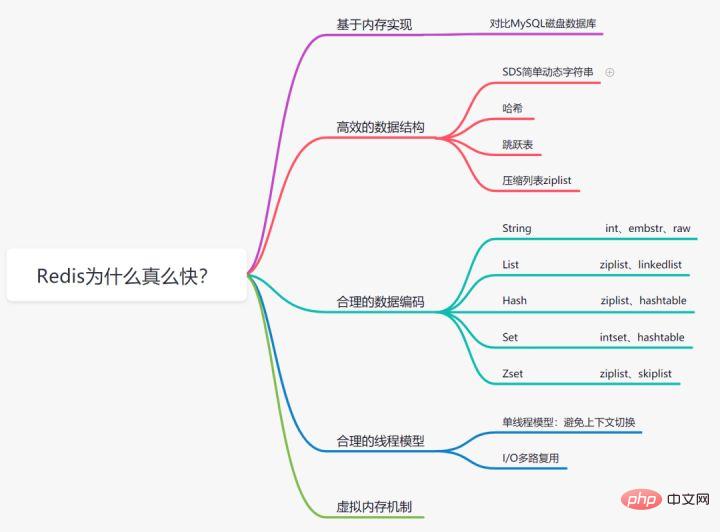
3 Warum so schnell?Warum ist Redis so schnell
3.1 Basierend auf der Speicherspeicherung
Wir alle wissen, dass das Lesen und Schreiben im Speicher im Vergleich zur MySQL-Datenbank viel schneller ist als auf der Festplatte wo Daten auf der Festplatte gespeichert werden, wodurch der Festplatten-E/A-Verbrauch gespart wird.3.2 Effiziente Datenstruktur
Wir wissen, dass der MySQL-Index zur Verbesserung der Effizienz die B+-Baumdatenstruktur wählt. Tatsächlich kann eine vernünftige Datenstruktur Ihre Anwendung/Ihr Programm schneller machen. Werfen wir zunächst einen Blick auf die Datenstruktur und das interne Codierungsdiagramm von Redis:SDS einfache dynamische Zeichenfolge
Verarbeitung der Zeichenfolgenlänge: Redis erhält die Zeichenfolgenlänge, die zeitliche Komplexität beträgt O(1) , und In der C-Sprache muss es von Anfang an durchlaufen werden, und die Komplexität beträgt O(n); verbrauchen Leistung, und SDS-Änderungen und Speicherplatzerweiterungen erfordern zusätzliche Zuweisung von ungenutztem Speicherplatz, um Leistungsverluste zu reduzieren. Lazy Space Release: Wenn SDS gekürzt wird, wird der überschüssige Speicherplatz durch Free aufgezeichnet, und bei späteren Änderungen wird der in Free aufgezeichnete Speicherplatz direkt zur Reduzierung der Zuweisung verwendet. Binäre Sicherheit: Redis kann einige Binärdaten und in der C-Sprache vorkommende Zeichenfolgen speichern.
- E/A: Netzwerk-E/A
- Mehrkanal: mehrere Netzwerkverbindungen
- Multiplexing: Wiederverwendung desselben Threads.
- IO-Multiplexing ist eigentlich ein synchrones E/A-Modell, das einen Thread implementiert, der mehrere Dateihandles überwachen kann. Sobald ein Dateihandle bereit ist, kann es die Anwendung benachrichtigen, entsprechende Lese- und Schreibvorgänge ohne Dateihandle durchzuführen Die Anwendung wird gesperrt und die CPU wird übergeben.
Single-Threaded-Modell
- Redis ist ein Single-Threaded-Modell und Single-Threading vermeidet unnötigen CPU-Kontextwechsel und den Verbrauch von Konkurrenzsperren. Gerade weil es sich um einen einzelnen Thread handelt, führt die Ausführung eines bestimmten Befehls (z. B. des Befehls hgetall) zu einer Blockierung. Redis ist eine Datenbank für schnelle Ausführungsszenarien. Daher sollten Befehle wie smembers, lrange, hgetall usw. mit Vorsicht verwendet werden.
- Redis 6.0 führt Multithreading ein, um die Geschwindigkeit zu erhöhen, und die Ausführung von Befehlen und Speicheroperationen erfolgt immer noch in einem einzelnen Thread.
3.5 Virtueller Speichermechanismus
Redis baut den VM-Mechanismus direkt selbst auf. Es ruft keine Systemfunktionen wie normale Systeme auf und verschwendet eine gewisse Zeit mit dem Verschieben und Anfordern.
Was ist der virtuelle Speichermechanismus von Redis?
Der virtuelle Speichermechanismus verlagert Daten, auf die selten zugegriffen wird (kalte Daten), vorübergehend vom Speicher auf die Festplatte und gibt so wertvollen Speicherplatz für andere Daten frei, auf die zugegriffen werden muss (heiße Daten). Die VM-Funktion kann die Trennung von heißen und kalten Daten realisieren, sodass sich die heißen Daten noch im Speicher befinden und die kalten Daten auf der Festplatte gespeichert werden. Dadurch kann das Problem einer langsamen Zugriffsgeschwindigkeit vermieden werden, die durch unzureichenden Speicher verursacht wird.
4. Was ist Cache-Aufschlüsselung, Cache-Penetration, Cache-Lawine?
4.1 Cache-Penetrationsproblem
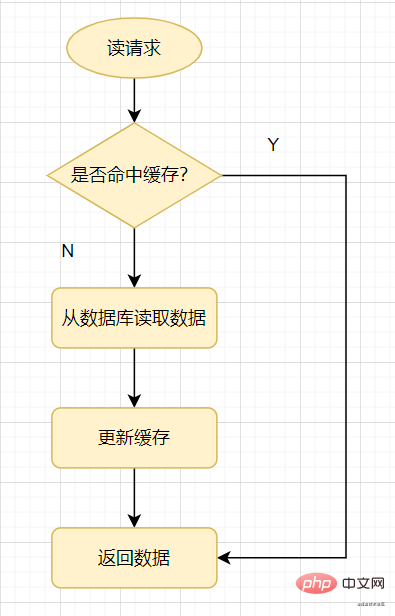
Schauen wir uns zunächst eine gängige Methode zur Verwendung des Caches an: Wenn eine Leseanforderung eintrifft, überprüfen Sie zuerst den Cache. Wenn es einen Treffer gibt, wird dieser direkt zurückgegeben Kein Treffer im Cache, überprüfen Sie die Datenbank. Aktualisieren Sie dann den Datenbankwert im Cache und kehren Sie zurück.
Cache lesen
Cache-Penetration: bezieht sich auf das Abfragen von Daten, die definitiv nicht vorhanden sind, und müssen aus der Datenbank abgefragt werden nicht in den Cache geschrieben werden, was dazu führt, dass nicht vorhandene Daten bei jeder Anfrage in der Datenbank abgefragt werden müssen, was die Datenbank belastet.
Um es einfach auszudrücken: Wenn auf eine Leseanforderung zugegriffen wird, haben weder der Cache noch die Datenbank einen bestimmten Wert, was dazu führt, dass jede Abfrageanforderung für diesen Wert in die Datenbank eindringt. Dies ist eine Cache-Penetration.Cache-Penetration wird im Allgemeinen durch die folgenden Situationen verursacht:
- Unangemessenes Geschäftsdesign Beispielsweise haben die meisten Benutzer keinen Schutz aktiviert, aber jede Anfrage, die Sie stellen, geht in den Cache und fragt eine bestimmte Benutzer-ID ab Sehen Sie nach, ob es einen Schutz gibt.
- Geschäfts-/Betriebs- und Wartungs-/Entwicklungsfehler, wie z. B. versehentliches Löschen von Cache- und Datenbankdaten.
- Illegaler Anforderungsangriff durch Hacker Beispielsweise fabrizieren Hacker absichtlich eine große Anzahl illegaler Anforderungen, um nicht vorhandene Geschäftsdaten zu lesen.
Wie vermeide ich das Eindringen in den Cache? Generell gibt es drei Methoden.
1. Wenn es sich um eine illegale Anfrage handelt, überprüfen wir die Parameter am API-Eingang und filtern illegale Werte heraus. 2. Wenn die Abfragedatenbank leer ist, können wir einen Nullwert oder einen Standardwert für den Cache festlegen. Wenn jedoch eine Schreibanforderung eingeht, muss der Cache aktualisiert werden, um die Cache-Konsistenz sicherzustellen. Gleichzeitig wird schließlich die entsprechende Ablaufzeit für den Cache festgelegt. (In der Wirtschaft häufig verwendet, einfach und effektiv) 3. Verwenden Sie den Bloom-Filter, um schnell festzustellen, ob Daten vorhanden sind. Das heißt, wenn eine Abfrageanforderung eingeht, beurteilt sie zunächst mithilfe des Bloom-Filters, ob der Wert vorhanden ist, und prüft dann weiter, ob er vorhanden ist.
Bloom-Filterprinzip: Es besteht aus einem Bitmap-Array mit einem Anfangswert von 0 und N Hash-Funktionen. Führen Sie N Hash-Algorithmen für einen Schlüssel aus, um N Werte im Bitarray zu erhalten, und setzen Sie sie auf 1. Wenn dann überprüft wird, ob diese spezifischen Positionen alle 1 sind, stellt der Bloom-Filter fest, dass der Schlüssel vorhanden ist .4.2 Cache-Snowrun-Problem
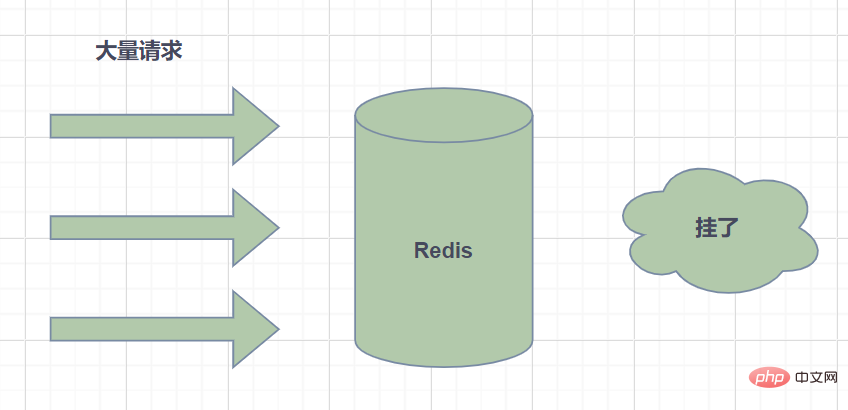
Cache-Snowrun: bezieht sich auf die Ablaufzeit einer großen Datenmenge im Cache, die Abfragedaten sind riesig und die Anforderungen greifen direkt auf die Datenbank zu, was zu übermäßigem Druck führt die Datenbank und sogar Ausfallzeiten.
Cache-Schneefall wird im Allgemeinen dadurch verursacht, dass eine große Datenmenge gleichzeitig abläuft. Aus diesem Grund kann das Problem gelöst werden, indem die Ablaufzeit gleichmäßig eingestellt wird, dh die Ablaufzeit relativ diskret gestaltet wird. Wenn Sie einen größeren Festwert + einen kleineren Zufallswert verwenden, 5 Stunden + 0 bis 1800 Sekunden. Redis-Fehler können auch zu Cache-Schneefall führen. Dies erfordert den Aufbau eines Redis-Hochverfügbarkeitsclusters.
4.3 Cache-Aufschlüsselungsproblem
Cache-Aufschlüsselung: bezieht sich darauf, dass der Hotspot-Schlüssel zu einem bestimmten Zeitpunkt abläuft und es zu diesem Zeitpunkt zufällig eine große Anzahl gleichzeitiger Anforderungen für diesen Schlüssel gibt. Dies führt zu einer großen Anzahl von Anfragen. Klicken Sie auf db.
Der Cache-Ausfall sieht ein wenig ähnlich aus. Tatsächlich besteht der Unterschied darin, dass ein Cache-Absturz bedeutet, dass die Datenbank übermäßig belastet ist oder sogar ausfällt, weil eine große Anzahl gleichzeitiger Anforderungen an die DB-Datenbankebene vorliegt. Es kann davon ausgegangen werden, dass die Aufschlüsselung eine Teilmenge des Cache-Snowruns ist. Einige Artikel glauben, dass der Unterschied zwischen den beiden darin besteht, dass die Aufschlüsselung auf einen bestimmten Hotkey-Cache abzielt, während Xuebeng auf viele Schlüssel abzielt.
Es gibt zwei Lösungen:
- 1. Verwenden Sie das Mutex-Sperrschema. Wenn der Cache fehlschlägt, laden Sie die Datenbankdaten nicht sofort, sondern verwenden bei erfolgreicher Rückkehr zunächst einige atomare Operationsbefehle, z. B. (Setnx von Redis), um den Vorgang durchzuführen. Laden Sie bei Erfolg die Datenbankdatenbankdaten und richten Sie den Cache ein. Versuchen Sie andernfalls erneut, den Cache abzurufen.
- 2. „Lässt nie ab“ bedeutet, dass keine Ablaufzeit festgelegt ist, aber wenn die Hotspot-Daten bald ablaufen, aktualisiert der asynchrone Thread die Ablaufzeit und legt sie fest.
5. Was ist das Hotkey-Problem und wie löst man das Hotkey-Problem
Was ist der Hotkey? In Redis bezeichnen wir Tasten mit hoher Zugriffshäufigkeit als Hotkeys.
Wenn aufgrund eines besonders großen Anforderungsvolumens eine Anfrage nach einem bestimmten Hotspot-Schlüssel an den Server-Host gesendet wird, kann dies zu unzureichenden Host-Ressourcen oder sogar Ausfallzeiten führen und somit die normalen Dienste beeinträchtigen.
Und wie wird der Hotspot-Schlüssel generiert? Dafür gibt es zwei Hauptgründe:
- Die von den Benutzern verbrauchten Daten sind viel größer als die produzierten Daten, wie z. B. Flash-Sales, aktuelle Nachrichten und andere Szenarien, in denen mehr gelesen und weniger geschrieben wird.
- Das Anforderungs-Sharding ist konzentriert, was die Leistung eines einzelnen Redi-Servers übersteigt. Wenn beispielsweise der Schlüssel mit dem festen Namen und der Hash auf denselben Server fallen, ist der Umfang des sofortigen Zugriffs enorm, übersteigt den Maschinenengpass und verursacht Hot Schlüsselprobleme.
Wie erkennt man also Hotkeys in der täglichen Entwicklung?
- Bestimmen Sie, welche Hotkeys auf Erfahrung basieren.
- Client-Statistikberichte;
- Reporting an die Service-Agent-Ebene.
Redis-Cluster-Erweiterung: Shard-Kopien hinzufügen, um den Leseverkehr auszugleichen;
Hotkeys auf verschiedene Server verteilen;
- Zwischenspeicher der zweiten Ebene, d. h. lokalen JVM-Cache, verwenden, um Redis-Leseanforderungen zu reduzieren.
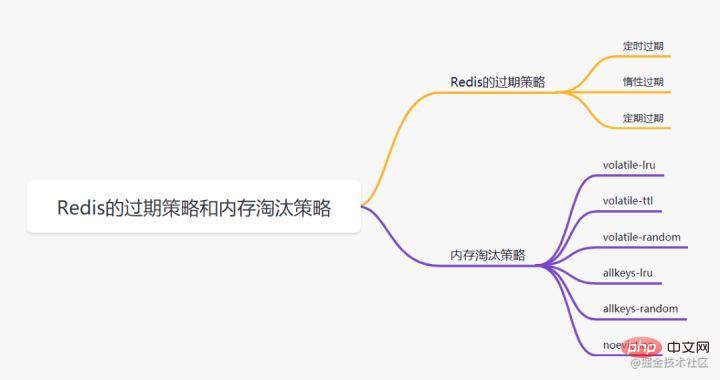
6. Redis-Ablaufstrategie und Speichereliminierungsstrategie6.1 Redis-Ablaufstrategie
Wir sind hier. Geben Sie an, dass dieser Schlüssel nach 60 Sekunden abläuft. Wie wird Redis nach 60 Sekunden damit umgehen? Lassen Sie uns zunächst mehrere Ablaufstrategien vorstellen:
Zeitgesteuerter AblaufJeder Schlüssel mit einer Ablaufzeit muss einen Timer erstellen, und der Schlüssel wird sofort gelöscht, wenn die Ablaufzeit erreicht ist. Diese Strategie kann abgelaufene Daten sofort löschen und ist sehr speicherschonend; sie beansprucht jedoch eine große Menge an CPU-Ressourcen für die Verarbeitung abgelaufener Daten, was sich auf die Cache-Reaktionszeit und den Durchsatz auswirkt.
set key的时候,可以给它设置一个过期时间,比如expire key 60Verzögerter AblaufNur wenn auf einen Schlüssel zugegriffen wird, wird beurteilt, ob der Schlüssel abgelaufen ist, und er wird gelöscht, wenn er abläuft. Diese Strategie kann CPU-Ressourcen maximal einsparen, ist jedoch sehr speicherunfreundlich. In extremen Fällen kann es vorkommen, dass auf eine große Anzahl abgelaufener Schlüssel nicht erneut zugegriffen werden kann, sodass sie nicht gelöscht werden und viel Speicher belegen.Periodischer AblaufZu jedem bestimmten Zeitpunkt wird eine bestimmte Anzahl von Schlüsseln im Ablaufwörterbuch einer bestimmten Anzahl von Datenbanken gescannt und die abgelaufenen Schlüssel werden gelöscht. Diese Strategie ist ein Kompromiss zwischen den ersten beiden. Durch Anpassen des Zeitintervalls geplanter Scans und des begrenzten Zeitverbrauchs jedes Scans kann unter verschiedenen Umständen das optimale Gleichgewicht zwischen CPU- und Speicherressourcen erreicht werden. Das Expires-Wörterbuch speichert die Ablaufzeitdaten aller Schlüssel mit festgelegter Ablaufzeit, wobei „key“ ein Zeiger auf einen Schlüssel im Schlüsselraum und „value“ die Ablaufzeit ist, die durch den UNIX-Zeitstempel des Schlüssels mit Millisekundengenauigkeit dargestellt wird. Der Schlüsselraum bezieht sich auf alle im Redis-Cluster gespeicherten Schlüssel.Redis verwendet sowohlLazy Expiration als auch Periodic Expiration
zwei Ablaufstrategien.
- 假设Redis当前存放30万个key,并且都设置了过期时间,如果你每隔100ms就去检查这全部的key,CPU负载会特别高,最后可能会挂掉。
- 因此,redis采取的是定期过期,每隔100ms就随机抽取一定数量的key来检查和删除的。
- 但是呢,最后可能会有很多已经过期的key没被删除。这时候,redis采用惰性删除。在你获取某个key的时候,redis会检查一下,这个key如果设置了过期时间并且已经过期了,此时就会删除。
但是呀,如果定期删除漏掉了很多过期的key,然后也没走惰性删除。就会有很多过期key积在内存内存,直接会导致内存爆的。或者有些时候,业务量大起来了,redis的key被大量使用,内存直接不够了,运维小哥哥也忘记加大内存了。难道redis直接这样挂掉?不会的!Redis用8种内存淘汰策略保护自己~
6.2 Redis 内存淘汰策略
- volatile-lru:当内存不足以容纳新写入数据时,从设置了过期时间的key中使用LRU(最近最少使用)算法进行淘汰;
- allkeys-lru:当内存不足以容纳新写入数据时,从所有key中使用LRU(最近最少使用)算法进行淘汰。
- volatile-lfu:4.0版本新增,当内存不足以容纳新写入数据时,在过期的key中,使用LFU算法进行删除key。
- allkeys-lfu:4.0版本新增,当内存不足以容纳新写入数据时,从所有key中使用LFU算法进行淘汰;
- volatile-random:当内存不足以容纳新写入数据时,从设置了过期时间的key中,随机淘汰数据;。
- allkeys-random:当内存不足以容纳新写入数据时,从所有key中随机淘汰数据。
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的key中,根据过期时间进行淘汰,越早过期的优先被淘汰;
- noeviction:默认策略,当内存不足以容纳新写入数据时,新写入操作会报错。
7.说说Redis的常用应用场景
- 缓存
- 排行榜
- 计数器应用
- 共享Session
- 分布式锁
- 社交网络
- 消息队列
- 位操作
7.1 缓存
我们一提到redis,自然而然就想到缓存,国内外中大型的网站都离不开缓存。合理的利用缓存,比如缓存热点数据,不仅可以提升网站的访问速度,还可以降低数据库DB的压力。并且,Redis相比于memcached,还提供了丰富的数据结构,并且提供RDB和AOF等持久化机制,强的一批。
7.2 排行榜
当今互联网应用,有各种各样的排行榜,如电商网站的月度销量排行榜、社交APP的礼物排行榜、小程序的投票排行榜等等。Redis提供的
zset数据类型能够实现这些复杂的排行榜。比如,用户每天上传视频,获得点赞的排行榜可以这样设计:
- 1.用户Jay上传一个视频,获得6个赞,可以酱紫:
zadd user:ranking:2021-03-03 Jay 3Nach dem Login kopierenNach dem Login kopieren
- 2.过了一段时间,再获得一个赞,可以这样:
zincrby user:ranking:2021-03-03 Jay 1Nach dem Login kopieren
- 3.如果某个用户John作弊,需要删除该用户:
zrem user:ranking:2021-03-03 JohnNach dem Login kopieren
- 4.展示获取赞数最多的3个用户
zrevrangebyrank user:ranking:2021-03-03 0 2Nach dem Login kopieren7.3 计数器应用
各大网站、APP应用经常需要计数器的功能,如短视频的播放数、电商网站的浏览数。这些播放数、浏览数一般要求实时的,每一次播放和浏览都要做加1的操作,如果并发量很大对于传统关系型数据的性能是一种挑战。Redis天然支持计数功能而且计数的性能也非常好,可以说是计数器系统的重要选择。
7.4 共享Session
如果一个分布式Web服务将用户的Session信息保存在各自服务器,用户刷新一次可能就需要重新登录了,这样显然有问题。实际上,可以使用Redis将用户的Session进行集中管理,每次用户更新或者查询登录信息都直接从Redis中集中获取。
7.5 分布式锁
几乎每个互联网公司中都使用了分布式部署,分布式服务下,就会遇到对同一个资源的并发访问的技术难题,如秒杀、下单减库存等场景。
- Die Verwendung der lokalen Sperre „synchonize“ oder „reentrantlock“ funktioniert definitiv nicht.
- Wenn die Parallelität nicht groß ist, ist die Verwendung der pessimistischen Sperre und der optimistischen Sperre der Datenbank kein Problem.
- In Situationen mit hoher Parallelität wirkt sich die Verwendung von Datenbanksperren zur Steuerung des gleichzeitigen Zugriffs auf Ressourcen jedoch auf die Leistung der Datenbank aus.
- Tatsächlich kann setnx von Redis verwendet werden, um verteilte Sperren zu implementieren.
7.6 Soziales Netzwerk
Likes/Dislikes, Fans, gemeinsame Freunde/Likes, Push, Pulldown-Aktualisierung usw. sind wesentliche Funktionen von Social-Networking-Sites, da die Anzahl der Besuche auf Social-Networking-Sites normalerweise relativ ist groß, und herkömmliche relationale Daten können nicht. Es ist sehr gut geeignet, diese Art von Daten zu speichern, und die von Redis bereitgestellte Datenstruktur kann diese Funktionen relativ einfach realisieren.
7.7 Nachrichtenwarteschlange
Nachrichtenwarteschlange ist eine notwendige Middleware für große Websites wie ActiveMQ, RabbitMQ, Kafka und andere beliebte Nachrichtenwarteschlangen-Middleware. Sie wird hauptsächlich zur geschäftlichen Entkopplung, zur Reduzierung von Verkehrsspitzen und zur asynchronen Verarbeitung niedriger Realwerte verwendet -Zeitgeschäft. Redis bietet Veröffentlichungs-/Abonnement- und Blockierungswarteschlangenfunktionen, mit denen ein einfaches Nachrichtenwarteschlangensystem implementiert werden kann. Zudem ist dies nicht mit einer professionellen Nachrichten-Middleware zu vergleichen.
7,8-Bit-Betrieb
wird in Szenarien mit Hunderten Millionen Daten verwendet, z. B. System-Check-ins für Hunderte Millionen Benutzer, Statistiken über die Anzahl der Anmeldungen ohne Duplikate, ob ein Benutzer online ist usw . Tencent hat 1 Milliarde Nutzer. Wie können wir innerhalb weniger Millisekunden überprüfen, ob ein Nutzer online ist? Sagen Sie niemals, dass Sie für jeden Benutzer einen Schlüssel erstellen und ihn dann einzeln aufzeichnen sollen (Sie können den erforderlichen Speicher berechnen, was sehr beängstigend sein wird, und es gibt viele ähnliche Anforderungen. Hier müssen die richtigen Vorgänge verwendet werden – verwenden Sie setbit, getbit, Das Prinzip lautet: Erstellen Sie in Redis ein ausreichend langes Array. Jedes Array-Element kann nur zwei Werte haben. 0 und 1, und dann wird der Index dieses Arrays verwendet, um die Benutzer-ID darzustellen (muss sein). eine Zahl), dann kann dieses Hunderte Millionen große Array durch Indizes und Elementwerte (0 und 1) aufbauen
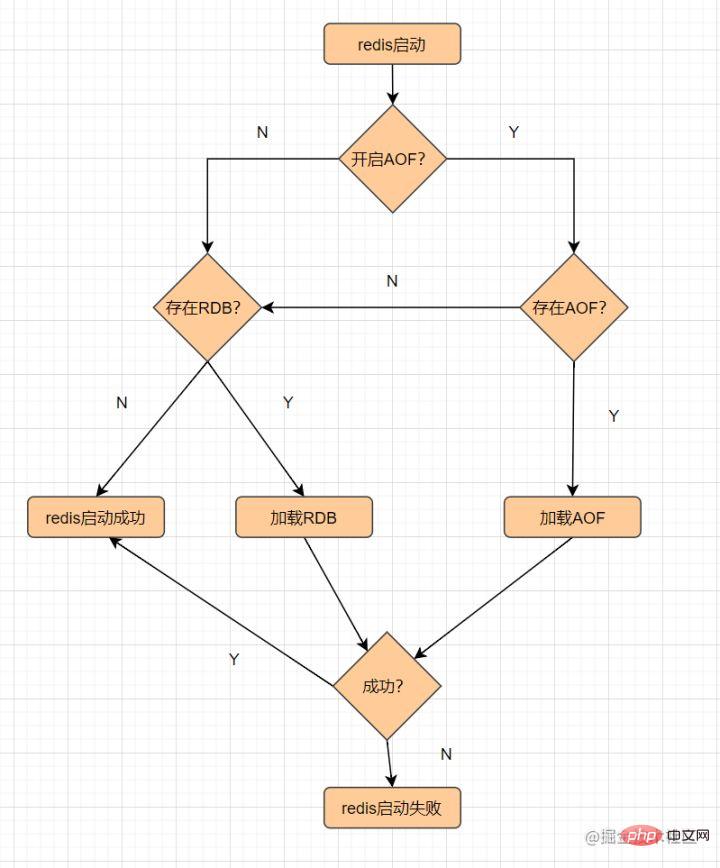
8 Was sind die Vor- und Nachteile von Redis? Da die nicht relationale K-V-Datenbank auf Speicher basiert, gehen die Daten verloren, wenn der Redis-Server abstürzt. Um Datenverlust zu vermeiden, bietet Redis „Persistenz“, was bedeutet, dass die Daten auf der Festplatte gespeichert werden. Es gibt zwei Persistenzmechanismen: RDB und AOF
Der Prozess zum dauerhaften Laden von Dateien ist wie folgt:8.1 RDB
, das die Speicherdaten in Form eines Snapshots auf der Festplatte speichert .
Was ist ein Schnappschuss? Sie können es so verstehen: Machen Sie ein Foto der Daten zum aktuellen Zeitpunkt und speichern Sie es dann.
RDB-Persistenz bezieht sich auf die Ausführung einer bestimmten Anzahl von Schreibvorgängen innerhalb einer bestimmten Zeit Intervall zum Speichern der Daten im Speicher. Dies ist die Standard-Persistenzmethode von Redis. Nach Abschluss des Vorgangs wird eine -Datei im angegebenen Verzeichnis generiert Die wichtigsten RDB-Auslösemechanismen sind wie folgt:
Vorteile von RDB
dump.rdb文件,Redis 重启的时候,通过加载dump.rdb
Nachteile von RDB
Es kann keine Echtzeit-Persistenz/Second-Level-Persistenz erreicht werden.
Es bestehen Kompatibilitätsprobleme mit dem RDB-Format.
AOFAOF (nur Datei anhängen)
Persistenz, Protokollierung aller Schreibvorgänge wird verwendet , an die Datei anhängen und den Befehl beim Neustart in der AOF-Datei erneut ausführen. Es löst hauptsächlich das Echtzeitproblem der Datenpersistenz:Die Vorteile von AOF ist eine höhere Konsistenz und Integrität.
Je größer die Datei, desto langsamer ist die Datenwiederherstellung.Wir verwenden Redis Das Projekt wird definitiv keine Single-Point-Bereitstellung sein, denn sobald die Single-Point-Bereitstellung ausfällt, ist es üblich, mehrere Kopien davon zu kopieren Datenbank und stellen Sie sie auf verschiedenen Servern bereit. Auch wenn ein Computer ausfällt, kann er weiterhin Dienste bereitstellen. Es gibt drei Bereitstellungsmodi für Redis, um eine hohe Verfügbarkeit zu erreichen:
Master-Slave-Modus, Sentinel-Modus und Cluster-Modus
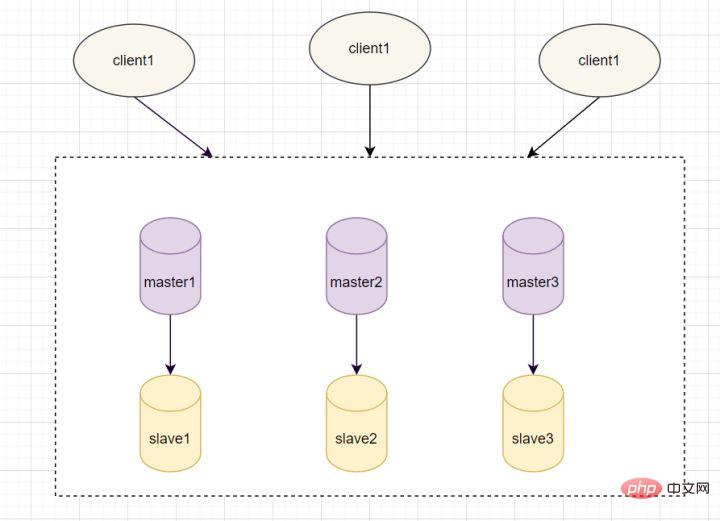
9.1 Master-Slave-ModusIm Master-Slave-Modus stellt Redis mehrere bereit. Jede Maschine verfügt über einen Masterknoten, der für Lese- und Schreibvorgänge verantwortlich ist, und einen Slave-Knoten, der nur für Lesevorgänge verantwortlich ist. Die Daten des Slave-Knotens stammen vom Master-Knoten, und das Implementierungsprinzip ist der
Master-Slave-Replikationsmechanismus
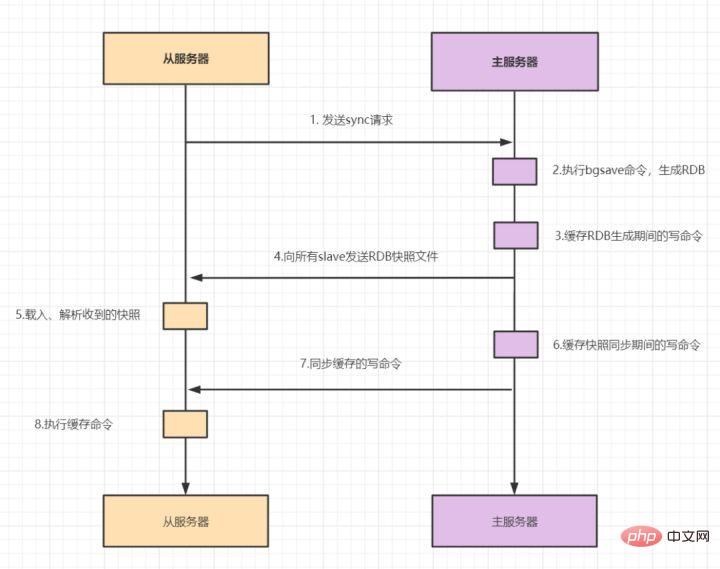
Die Master-Slave-Replikation umfasst die vollständige Replikation und die inkrementelle Replikation. Wenn der Slave zum ersten Mal eine Verbindung zum Master herstellt oder die Verbindung zum ersten Mal hergestellt wird, wird im Allgemeinen eine vollständige Kopie verwendet. Der vollständige Kopiervorgang läuft wie folgt ab: 1 . Der Slave sendet einen Sync-Befehl an den Master. 2. Nach Erhalt des SYNC-Befehls führt der Master den bgsave-Befehl aus, um die vollständige RDB-Datei zu generieren.
3. Der Master verwendet einen Puffer, um alle Schreibbefehle während der RDB-Snapshot-Generierung aufzuzeichnen.
4. Nachdem der Master bgsave ausgeführt hat, sendet er RDB-Snapshot-Dateien an alle Slaves.
- 5. Nach Erhalt der RDB-Snapshot-Datei lädt und analysiert der Slave den empfangenen Snapshot.
- 6. Der Master verwendet einen Puffer, um alle während der RDB-Synchronisierung generierten geschriebenen Befehle aufzuzeichnen.
- 7. Nachdem der Master-Snapshot gesendet wurde, beginnt er, den Schreibbefehl im Puffer an den Slave zu senden
- 8.salve akzeptiert die Befehlsanforderung und führt den Schreibbefehl aus dem Master-Puffer aus
Nach redis2.8 Version wurde- psync als Ersatz für sync
verwendet, da der sync-Befehl Systemressourcen verbraucht und psync effizienter ist. Nachdem der Slave vollständig mit dem Master synchronisiert ist und die Daten auf dem Master erneut aktualisiert werden, wird eine- inkrementelle Replikation
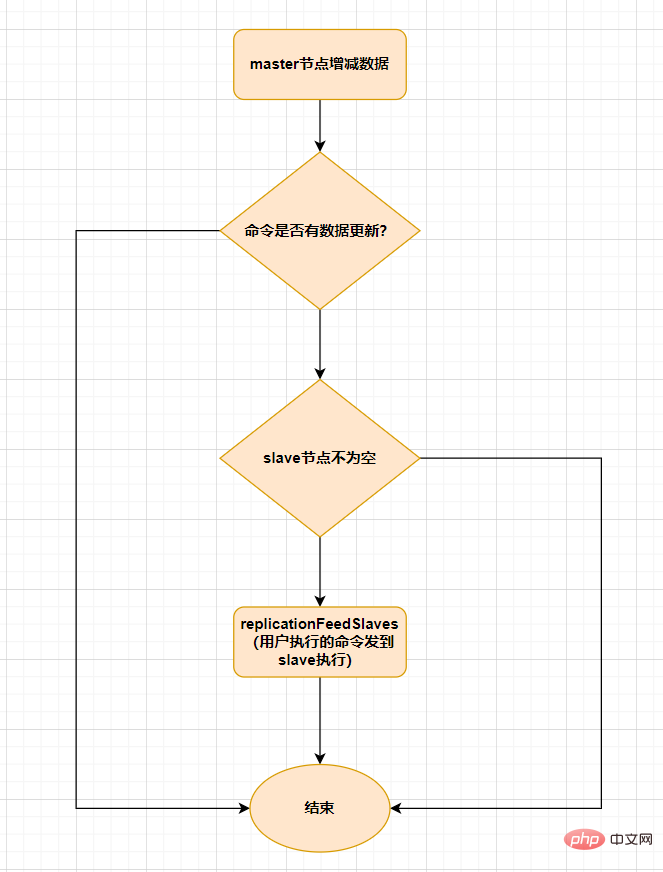
ausgelöst.Wenn die Datenmenge auf dem Master-Knoten zunimmt oder abnimmt, wird eine Synchronisierung mit dem Slave-Knoten ausgelöst. Vor der Ausführung dieser Funktion ermittelt der Masterknoten, ob der vom Benutzer ausgeführte Befehl über Datenaktualisierungen verfügt. Wenn eine Datenaktualisierung vorliegt und der Slaveknoten nicht leer ist, wird diese Funktion ausgeführt. Die Funktion dieser Funktion ist: Senden Sie den vom Benutzer ausgeführten Befehl an alle Slave-Knoten
und lassen Sie ihn vom Slave-Knoten ausführen. Der Prozess ist wie folgt:Sobald der Master-Knoten im Master-Slave-Modus aufgrund eines Fehlers keine Dienste bereitstellen kann, muss der Slave-Knoten manuell zum Master-Knoten heraufgestuft werden. und gleichzeitig die Anwendung benachrichtigen, die Master-Knotenadresse zu aktualisieren. Offensichtlich ist diese Methode der Fehlerbehandlung in den meisten Geschäftsszenarien inakzeptabel. Redis stellt seit 2.8 offiziell die Redis Sentinel-Architektur zur Verfügung, um dieses Problem zu lösen.
replicationFeedSalves()函数,接下来在 Master节点上调用的每一个命令会使用replicationFeedSlaves()9.2 Sentinel-ModusSentinel-Modus
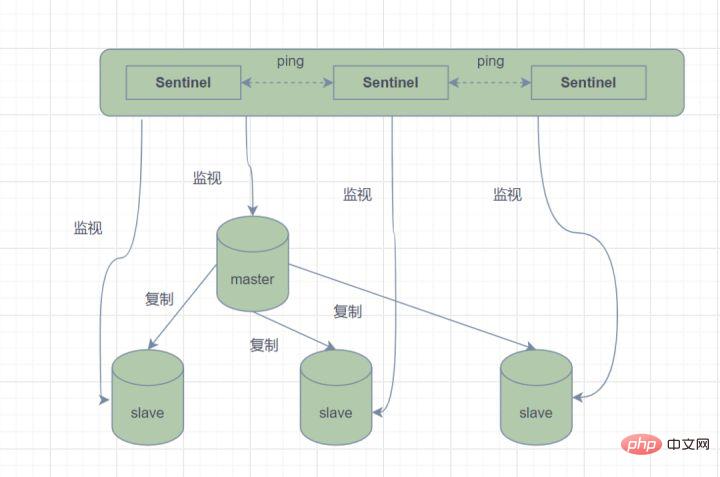
, ein Sentinel-System, das aus einer oder mehreren Sentinel-Instanzen besteht, kann alle Redis-Masterknoten und Slave-Knoten überwachen. Wenn der überwachte Masterknoten in den Offline-Zustand wechselt, wird der Offline-Master automatisch entfernt Server wird auf einen neuen Masterknoten aktualisiert. Wenn jedoch ein Sentinel-Prozess einen Redis-Knoten überwacht, können Probleme auftreten (
Einzelpunktproblem). Daher können mehrere Sentinels zur Überwachung von Redis-Knoten verwendet werden, und jeder Sentinel überwacht sich auch gegenseitig.
Sentinel-ModusEinfach ausgedrückt hat der Sentinel-Modus drei Funktionen:
Befehle senden und darauf warten, dass der Redis-Server (einschließlich Master-Server und Slave-Server) zurückkehrt, um seinen Betriebsstatus zu überwachen;
Sentinel-Überwachungen der Master Wenn ein Knoten ausfällt, wechselt er automatisch vom Slave-Knoten zum Master-Knoten und benachrichtigt dann andere Slave-Knoten über den Veröffentlichungs- und Abonnementmodus, ändert die Konfigurationsdatei und lässt sie den Host wechseln Die Sentinels werden es tun überwachen sich auch gegenseitig, um eine hohe Verfügbarkeit zu erreichen.
- Was ist der Failover-Prozess?
- Angenommen, der Hauptserver ist ausgefallen und Sentinel 1 erkennt dieses Ergebnis nicht sofort. Es ist nur so, dass Sentinel 1 subjektiv davon ausgeht Wenn der Hauptserver nicht verfügbar ist, wird dieses Phänomen offline subjektiv. Wenn die nachfolgenden Sentinels ebenfalls feststellen, dass der Hauptserver nicht verfügbar ist und die Anzahl einen bestimmten Wert erreicht, findet eine Abstimmung zwischen den Sentinels statt. Das Ergebnis der Abstimmung wird von einem Sentinel veranlasst, einen Failover-Vorgang durchzuführen. Nachdem der Wechsel erfolgreich war, wechselt jeder Sentinel im Publish-Subscribe-Modus den von ihm überwachten Slave-Server zum Host. Dieser Vorgang wird als objektiv offline bezeichnet. Auf diese Weise ist für den Kunden alles transparent.
Der Arbeitsmodus von Sentinel ist wie folgt:
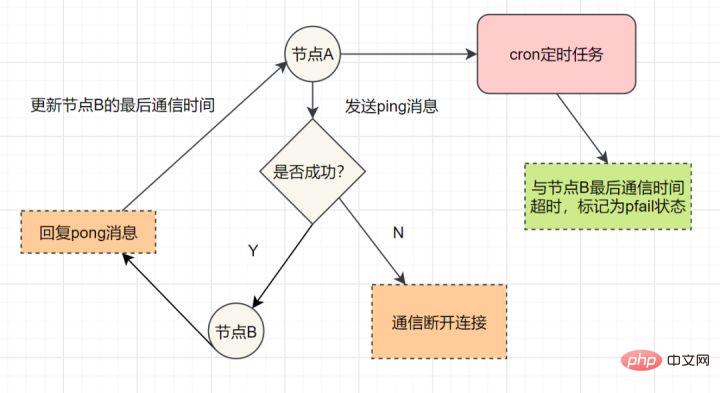
Jeder Sentinel sendet einmal pro Sekunde einen PING-Befehl an den Master, den Slave und andere ihm bekannte Sentinel-Instanzen.Wenn die Zeit seit der letzten gültigen Antwort auf den PING-Befehl den durch die Option down-after-milliseconds angegebenen Wert überschreitet, wird die Instanz von Sentinel als subjektiv offline markiert.
Wenn ein Master als subjektiv offline markiert ist, müssen alle Sentinels, die diesen Master überwachen, einmal pro Sekunde bestätigen, dass der Master tatsächlich in den subjektiven Offline-Status übergegangen ist.
Wenn eine ausreichende Anzahl von Sentinels (größer oder gleich dem in der Konfigurationsdatei angegebenen Wert) bestätigt, dass der Master innerhalb des angegebenen Zeitraums tatsächlich in einen subjektiven Offline-Zustand eingetreten ist, wird der Master als objektiv offline markiert.
Unter normalen Umständen sendet jeder Sentinel alle 10 Sekunden INFO-Befehle an alle ihm bekannten Master und Slaves.
Wenn der Master von Sentinel als objektiv offline markiert wird, wird die Häufigkeit, mit der Sentinel INFO-Befehle an alle Slaves des Offline-Masters sendet, von einmal alle 10 Sekunden auf einmal jede Sekunde geändert.
Wenn nicht genug davon vorhanden sind Sentinels stimmen zu: Wenn der Master offline ist, wird der objektive Offline-Status des Masters entfernt; wenn der Master erneut eine gültige Antwort auf den PING-Befehl des Sentinel zurückgibt, wird der subjektive Offline-Status des Masters entfernt.
9.3 Cluster-Cluster-Modus
Der Sentinel-Modus basiert auf dem Master-Slave-Modus, der die Trennung von Lesen und Schreiben realisiert und auch automatisch umschalten kann und die Systemverfügbarkeit höher ist. Allerdings sind die in jedem Knoten gespeicherten Daten gleich, was Speicher verschwendet und online nicht einfach zu erweitern ist. Aus diesem Grund entstand der Cluster-Cluster, der in Redis 3.0 hinzugefügt wurde und den „verteilten Speicher“ von Redis implementierte. Segmentieren Sie die Daten, was bedeutet, dass Sie auf jedem Redis-Knoten unterschiedliche Inhalte speichern müssen, um das Problem der Online-Erweiterung zu lösen. Darüber hinaus bietet es Replikations- und Failover-Funktionen. Kommunikation von Cluster-Cluster-KnotenEin Redis-Cluster besteht aus mehreren Knoten
Wie kommunizieren die einzelnen Knoten miteinander? Durch dasGossip-Protokoll
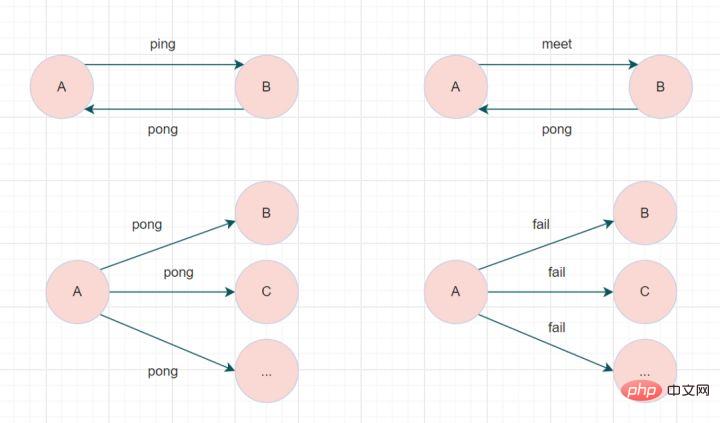
!Der Redis-Cluster-Cluster kommuniziert über das Gossip-Protokoll. Zu den ausgetauschten Informationen gehören Knotenfehler, neue Knotenbeitritte, Master-Slave-Knotenwechselinformationen, Slot-Informationen usw. Häufig verwendete Klatschnachrichten werden in vier Typen unterteilt: Ping, Pong, Meet und Fail.
Meet-Nachricht: Benachrichtigen Sie neue Knoten zum Beitritt. Der Absender der Nachricht benachrichtigt den Empfänger, dem aktuellen Cluster beizutreten. Nachdem die Meet-Nachrichtenkommunikation normal abgeschlossen wurde, tritt der empfangende Knoten dem Cluster bei und führt einen regelmäßigen Ping- und Pong-Nachrichtenaustausch durch.
Ping-Nachricht: Die am häufigsten ausgetauschte Nachricht im Cluster. Jeder Knoten im Cluster sendet jede Sekunde Ping-Nachrichten an mehrere andere Knoten, die verwendet werden, um zu erkennen, ob die Knoten online sind, und um Statusinformationen untereinander auszutauschen.Hash-Slot-AlgorithmusPong-Nachricht: Beim Empfang einer Ping- oder Meet-Nachricht antwortet diese dem Absender als Antwortnachricht, um die normale Kommunikation der Nachricht zu bestätigen. Die Pong-Nachricht kapselt intern ihre eigenen Statusdaten. Ein Knoten kann auch seine eigene Pong-Nachricht an den Cluster senden, um den gesamten Cluster zu benachrichtigen, seinen Status zu aktualisieren. Fehlermeldung: Wenn ein Knoten feststellt, dass ein anderer Knoten im Cluster offline ist, sendet er eine Fehlernachricht an den Cluster. Nach Erhalt der Fehlernachricht versetzen andere Knoten den entsprechenden Knoten in den Offline-Status. Insbesondere kommuniziert jeder Knoten mit anderen Knoten über den
- Cluster-Bus
. Verwenden Sie bei der Kommunikation eine spezielle Portnummer, d. h. die Portnummer des externen Dienstes plus 10000. Wenn die Portnummer eines Knotens beispielsweise 6379 ist, lautet die Portnummer, über die er mit anderen Knoten kommuniziert, 16379. Die Kommunikation zwischen Knoten verwendet ein spezielles Binärprotokoll.Da es sich um verteilten Speicher handelt, ist der vom Cluster-Cluster verwendete verteilte Algorithmus Konsistenter Hash
? Nein, es ist derHash-Slot-Algorithmus
.Slot-AlgorithmusDie gesamte Datenbank ist in 16384 Slots (Slots) unterteilt. Jedes in Redis eingegebene Schlüssel-Wert-Paar wird entsprechend dem Schlüssel gehasht und einem dieser 16384 Slots zugewiesen. Die verwendete Hash-Map ist ebenfalls relativ einfach. Sie verwendet den CRC16-Algorithmus zur Berechnung eines 16-Bit-Werts und dann Modulo 16384. Jeder Schlüssel in der Datenbank gehört zu einem dieser 16384 Slots, und jeder Knoten im Cluster kann diese 16384 Slots verarbeiten.
Jeder Knoten im Cluster ist für einen Teil der Hash-Slots verantwortlich. Der aktuelle Cluster hat beispielsweise die Knoten A, B und C und die Anzahl der Hash-Slots auf jedem Knoten = 16384/3, dann gibt es:Knoten A ist verantwortlich für die Hash-Slots 0~5460
Knoten B ist verantwortlich für die Hash-Slots 5461~10922
Knoten C ist verantwortlich für die Hash-Slots 10923~16383
Um eine hohe Verfügbarkeit sicherzustellen, führt der Cluster-Cluster eine Master-Slave-Replikation ein, und ein Masterknoten entspricht einem oder mehreren Slave-Knoten. Wenn andere Master-Knoten einen Master-Knoten A anpingen und mehr als die Hälfte der Master-Knoten mit A kommunizieren, kommt es zu einer Zeitüberschreitung, dann gilt der Master-Knoten A als ausgefallen. Wenn der Master-Knoten ausfällt, wird der Slave-Knoten aktiviert. Auf jedem Knoten von Redis gibt es zwei Dinge, eines ist der Slot, sein Wertebereich liegt zwischen 0 und 16383. Das andere ist Cluster, das als Cluster-Management-Plug-In verstanden werden kann. Wenn der Schlüssel, auf den wir zugreifen, eintrifft, erhält Redis einen 16-Bit-Wert basierend auf dem CRC16-Algorithmus und nimmt dann das Ergebnis modulo 16384. Jeder Schlüssel in Jiangzi entspricht einem Hash-Slot mit einer Nummer zwischen 0 und 16383. Verwenden Sie diesen Wert, um den Knoten zu finden, der dem entsprechenden Slot entspricht, und springen Sie dann automatisch zum entsprechenden Knoten, um Zugriffsvorgänge durchzuführen.- Redis-Cluster-Cluster
- Im Redis-Cluster-Cluster ist Es muss sichergestellt werden, dass 16384 Steckplätze übereinstimmen. Alle Knoten funktionieren normal. Wenn ein Knoten ausfällt, wird auch der Steckplatz, für den er verantwortlich ist, ungültig und der gesamte Cluster funktioniert nicht.
虽然数据是分开存储在不同节点上的,但是对客户端来说,整个集群Cluster,被看做一个整体。客户端端连接任意一个node,看起来跟操作单实例的Redis一样。当客户端操作的key没有被分配到正确的node节点时,Redis会返回转向指令,最后指向正确的node,这就有点像浏览器页面的302 重定向跳转。
故障转移
Redis集群实现了高可用,当集群内节点出现故障时,通过故障转移,以保证集群正常对外提供服务。
redis集群通过ping/pong消息,实现故障发现。这个环境包括主观下线和客观下线。
主观下线: 某个节点认为另一个节点不可用,即下线状态,这个状态并不是最终的故障判定,只能代表一个节点的意见,可能存在误判情况。
主观下线
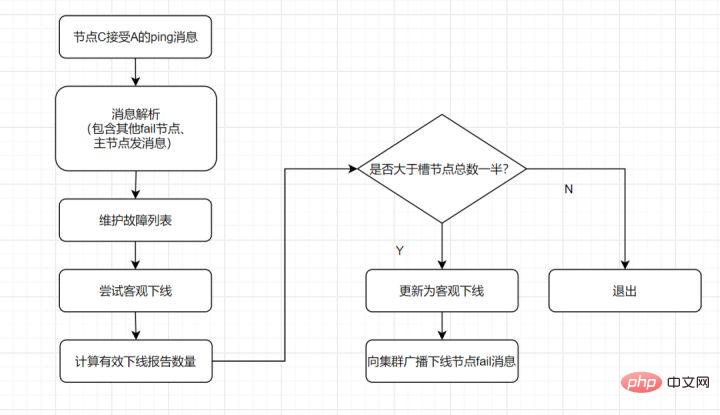
客观下线: 指标记一个节点真正的下线,集群内多个节点都认为该节点不可用,从而达成共识的结果。如果是持有槽的主节点故障,需要为该节点进行故障转移。
- 假如节点A标记节点B为主观下线,一段时间后,节点A通过消息把节点B的状态发到其它节点,当节点C接受到消息并解析出消息体时,如果发现节点B的pfail状态时,会触发客观下线流程;
- 当下线为主节点时,此时Redis Cluster集群为统计持有槽的主节点投票,看投票数是否达到一半,当下线报告统计数大于一半时,被标记为客观下线状态。
流程如下:
客观下线
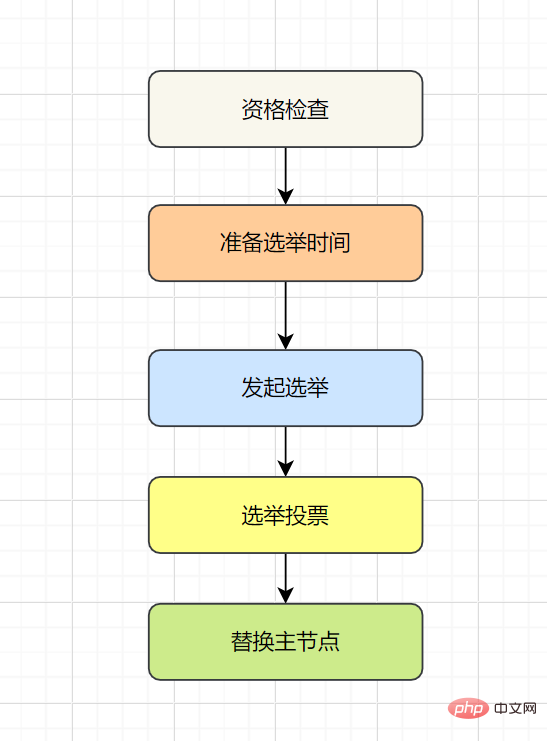
故障恢复:故障发现后,如果下线节点的是主节点,则需要在它的从节点中选一个替换它,以保证集群的高可用。流程如下:
- 资格检查:检查从节点是否具备替换故障主节点的条件。
- 准备选举时间:资格检查通过后,更新触发故障选举时间。
- 发起选举:到了故障选举时间,进行选举。
- 选举投票:只有持有槽的主节点才有票,从节点收集到足够的选票(大于一半),触发替换主节点操作
10. 使用过Redis分布式锁嘛?有哪些注意点呢?
分布式锁,是控制分布式系统不同进程共同访问共享资源的一种锁的实现。秒杀下单、抢红包等等业务场景,都需要用到分布式锁,我们项目中经常使用Redis作为分布式锁。
选了Redis分布式锁的几种实现方法,大家来讨论下,看有没有啥问题哈。
- 命令setnx + expire分开写
- setnx + value值是过期时间
- set的扩展命令(set ex px nx)
- set ex px nx + 校验唯一随机值,再删除
10.1 命令setnx + expire分开写
if(jedis.setnx(key,lock_value) == 1){ //加锁 expire(key,100); //设置过期时间 try { do something //业务请求 }catch(){ } finally { jedis.del(key); //释放锁 } }Nach dem Login kopieren如果执行完
setnx加锁,正要执行expire设置过期时间时,进程crash掉或者要重启维护了,那这个锁就“长生不老”了,别的线程永远获取不到锁啦,所以分布式锁不能这么实现。10.2 setnx + value值是过期时间
long expires = System.currentTimeMillis() + expireTime; //系统时间+设置的过期时间 String expiresStr = String.valueOf(expires); // 如果当前锁不存在,返回加锁成功 if (jedis.setnx(key, expiresStr) == 1) { return true; } // 如果锁已经存在,获取锁的过期时间 String currentValueStr = jedis.get(key); // 如果获取到的过期时间,小于系统当前时间,表示已经过期 if (currentValueStr != null && Long.parseLong(currentValueStr) < System.currentTimeMillis()) { // 锁已过期,获取上一个锁的过期时间,并设置现在锁的过期时间(不了解redis的getSet命令的小伙伴,可以去官网看下哈) String oldValueStr = jedis.getSet(key_resource_id, expiresStr); if (oldValueStr != null && oldValueStr.equals(currentValueStr)) { // 考虑多线程并发的情况,只有一个线程的设置值和当前值相同,它才可以加锁 return true; } } //其他情况,均返回加锁失败 return false; }Nach dem Login kopieren笔者看过有开发小伙伴是这么实现分布式锁的,但是这种方案也有这些缺点:
- 过期时间是客户端自己生成的,分布式环境下,每个客户端的时间必须同步。
- 没有保存持有者的唯一标识,可能被别的客户端释放/解锁。
- 锁过期的时候,并发多个客户端同时请求过来,都执行了
jedis.getSet(),最终只能有一个客户端加锁成功,但是该客户端锁的过期时间,可能被别的客户端覆盖。10.3:set的扩展命令(set ex px nx)(注意可能存在的问题)
if(jedis.set(key, lock_value, "NX", "EX", 100s) == 1){ //加锁 try { do something //业务处理 }catch(){ } finally { jedis.del(key); //释放锁 } }Nach dem Login kopieren这个方案可能存在这样的问题:
- 锁过期释放了,业务还没执行完。
- 锁被别的线程误删。
10.4 set ex px nx + 校验唯一随机值,再删除
if(jedis.set(key, uni_request_id, "NX", "EX", 100s) == 1){ //加锁 try { do something //业务处理 }catch(){ } finally { //判断是不是当前线程加的锁,是才释放 if (uni_request_id.equals(jedis.get(key))) { jedis.del(key); //释放锁 } } }Nach dem Login kopieren在这里,判断当前线程加的锁和释放锁是不是一个原子操作。如果调用jedis.del()释放锁的时候,可能这把锁已经不属于当前客户端,会解除他人加的锁。
一般也是用lua脚本代替。lua脚本如下:
if redis.call('get',KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end;Nach dem Login kopieren这种方式比较不错了,一般情况下,已经可以使用这种实现方式。但是存在锁过期释放了,业务还没执行完的问题(实际上,估算个业务处理的时间,一般没啥问题了)。
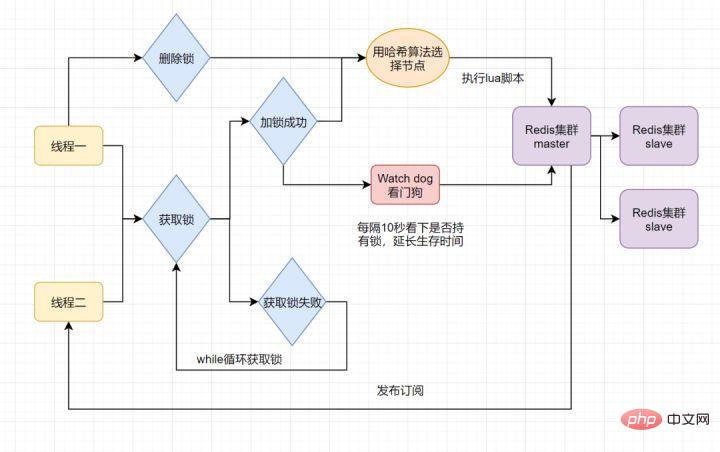
11. 使用过Redisson嘛?说说它的原理
分布式锁可能存在锁过期释放,业务没执行完的问题。有些小伙伴认为,稍微把锁过期时间设置长一些就可以啦。其实我们设想一下,是否可以给获得锁的线程,开启一个定时守护线程,每隔一段时间检查锁是否还存在,存在则对锁的过期时间延长,防止锁过期提前释放。
当前开源框架Redisson就解决了这个分布式锁问题。我们一起来看下Redisson底层原理是怎样的吧:
只要线程一加锁成功,就会启动一个
watch dog看门狗,它是一个后台线程,会每隔10秒检查一下,如果线程1还持有锁,那么就会不断的延长锁key的生存时间。因此,Redisson就是使用Redisson解决了锁过期释放,业务没执行完问题。12. 什么是Redlock算法
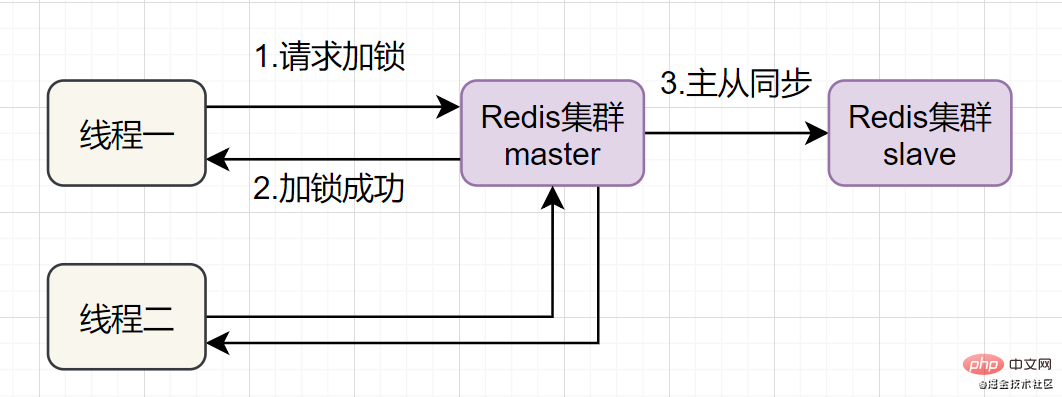
Redis一般都是集群部署的,假设数据在主从同步过程,主节点挂了,Redis分布式锁可能会有哪些问题呢?一起来看些这个流程图:
如果线程一在Redis的master节点上拿到了锁,但是加锁的key还没同步到slave节点。恰好这时,master节点发生故障,一个slave节点就会升级为master节点。线程二就可以获取同个key的锁啦,但线程一也已经拿到锁了,锁的安全性就没了。
为了解决这个问题,Redis作者 antirez提出一种高级的分布式锁算法:Redlock。Redlock核心思想是这样的:
搞多个Redis master部署,以保证它们不会同时宕掉。并且这些master节点是完全相互独立的,相互之间不存在数据同步。同时,需要确保在这多个master实例上,是与在Redis单实例,使用相同方法来获取和释放锁。
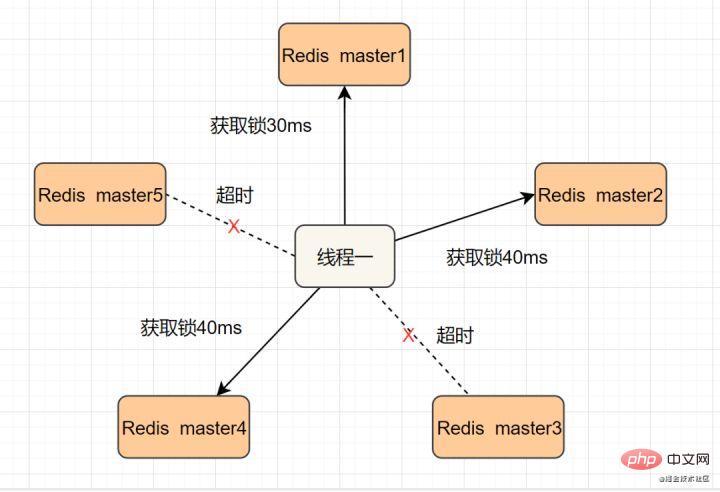
我们假设当前有5个Redis master节点,在5台服务器上面运行这些Redis实例。
RedLock的实现步骤:如下
- 1.获取当前时间,以毫秒为单位。
- 2.按顺序向5个master节点请求加锁。客户端设置网络连接和响应超时时间,并且超时时间要小于锁的失效时间。(假设锁自动失效时间为10秒,则超时时间一般在5-50毫秒之间,我们就假设超时时间是50ms吧)。如果超时,跳过该master节点,尽快去尝试下一个master节点。
- 3.客户端使用当前时间减去开始获取锁时间(即步骤1记录的时间),得到获取锁使用的时间。当且仅当超过一半(N/2+1,这里是5/2+1=3个节点)的Redis master节点都获得锁,并且使用的时间小于锁失效时间时,锁才算获取成功。(如上图,10s> 30ms+40ms+50ms+4m0s+50ms)
- 如果取到了锁,key的真正有效时间就变啦,需要减去获取锁所使用的时间。
- 如果获取锁失败(没有在至少N/2+1个master实例取到锁,有或者获取锁时间已经超过了有效时间),客户端要在所有的master节点上解锁(即便有些master节点根本就没有加锁成功,也需要解锁,以防止有些漏网之鱼)。
简化下步骤就是:
- 按顺序向5个master节点请求加锁
- 根据设置的超时时间来判断,是不是要跳过该master节点。
- 如果大于等于三个节点加锁成功,并且使用的时间小于锁的有效期,即可认定加锁成功啦。
- 如果获取锁失败,解锁!
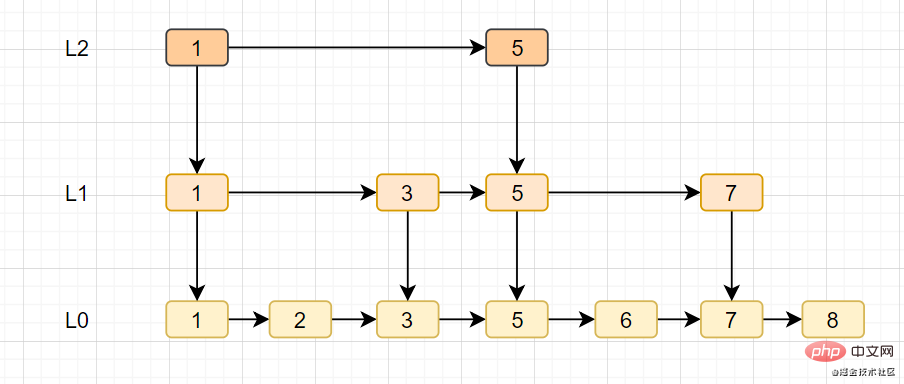
13. Redis的跳跃表
跳跃表
- Die Skip-Tabelle ist eine der zugrunde liegenden Implementierungen des geordneten Satzes zset
- Die Skip-Tabelle unterstützt die Suche nach durchschnittlichen O(logN)- und Worst-Case-O(N)-Komplexitätsknoten und kann Knoten auch stapelweise durch sequentielle Verarbeitung verarbeiten Operationen.
- Die Skip-List-Implementierung besteht aus zwei Strukturen: zskiplist und zskiplistNode, wobei zskiplist zum Speichern von Skip-Tabelleninformationen (z. B. Header-Knoten, Tail-Knoten, Länge) und zskiplistNode zur Darstellung von Skip-List-Knoten verwendet wird.
- Die Sprungliste basiert auf der verknüpften Liste und fügt mehrstufige Indizes hinzu, um die Sucheffizienz zu verbessern.
14. Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
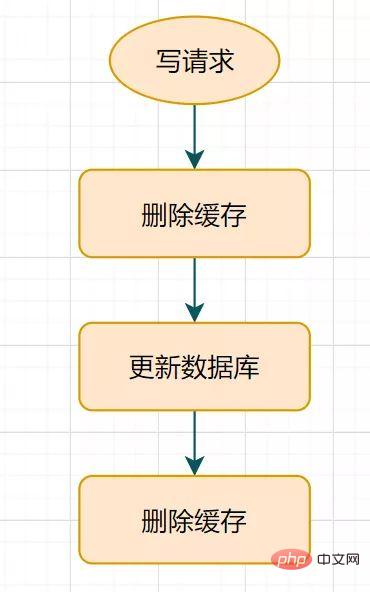
Was ist eine verzögerte doppelte Löschung? Das Flussdiagramm sieht wie folgt aus:
- Verzögerter Doppellöschvorgang
Löschen Sie zuerst den Cache
und aktualisieren Sie dann die Datenbank
Rufen Sie eine Weile (z. B. 1 Sekunde) und löschen Sie den Cache erneut.
Wie lange dauert es normalerweise, eine Weile einzuschlafen? Sind sie alle 1 Sekunde lang?
- Diese Ruhezeit = die Zeit, die zum Lesen von Geschäftslogikdaten benötigt wird + ein paar hundert Millisekunden. Um sicherzustellen, dass die Leseanforderung endet, kann die Schreibanforderung zwischengespeicherte fehlerhafte Daten löschen, die möglicherweise durch die Leseanforderung mitgebracht wurden.
- Diese Lösung ist nicht schlecht. Nur während der Ruhephase (z. B. nur 1 Sekunde) können schmutzige Daten vorhanden sein, und allgemeine Unternehmen werden dies akzeptieren. Was aber, wenn das
- Löschen des Caches zum zweiten Mal fehlschlägt
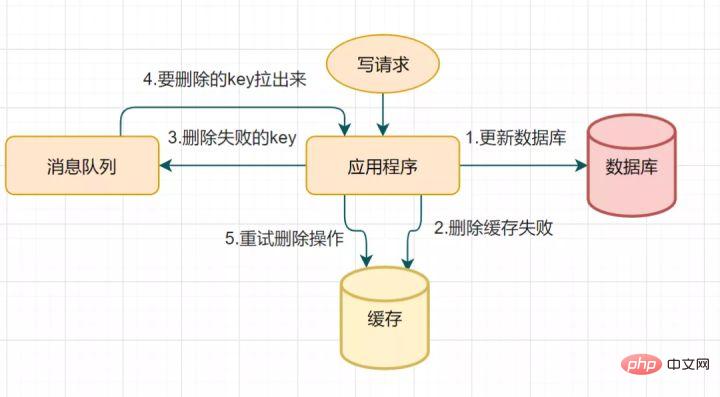
? Die Cache- und Datenbankdaten sind möglicherweise immer noch inkonsistent, oder? Wie wäre es, wenn Sie eine natürliche Ablaufzeit für den Schlüssel festlegen und ihn automatisch ablaufen lassen? Muss das Unternehmen Dateninkonsistenzen innerhalb der Ablauffrist akzeptieren? Oder gibt es eine andere bessere Lösung?14.2 Cache-Löschwiederholungsmechanismus
Aufgrund des verzögerten doppelten Löschens schlägt der zweite Schritt des Cache-Löschens möglicherweise fehl, was zu Dateninkonsistenzen führt. Sie können diese Lösung zur Optimierung verwenden: Wenn das Löschen fehlschlägt, löschen Sie es einfach noch ein paar Mal, um sicherzustellen, dass das Löschen des Caches erfolgreich ist. Sie können also einen Wiederholungsmechanismus für den Löschcache einführen Schreibanforderung zum Aktualisieren der DatenbankDer Cache konnte aus irgendeinem Grund nicht gelöscht werden
Legen Sie den Schlüssel, der nicht gelöscht werden konnte, in die NachrichtenwarteschlangeVerbrauchen Sie Nachrichten aus der Nachrichtenwarteschlange und rufen Sie den zu löschenden Schlüssel ab
Versuchen Sie es erneut Cache-Löschvorgang
14.3 Lesen Sie Biglog und löschen Sie den Cache asynchron.Einbrüchen in den Geschäftscode
. Tatsächlich kann es auch so optimiert werden: Schlüssel asynchron über das Binlog der Datenbank entfernen.
15. Warum wird Multithreading nach Redis 6.0 geändert?
- Nehmen Sie MySQL als Beispiel
- Sie können Alibabas Kanal verwenden, um Binlog-Protokolle zu sammeln und an die MQ-Warteschlange zu senden
- Bestätigen und verarbeiten Sie dann diese Aktualisierungsnachricht über den ACK-Mechanismus, löschen Sie den Cache und stellen Sie den Datencache sicher Konsistenz
Vor Redis 6.0 wurden Clientanforderungen, einschließlich Lesen von Sockets, Parsen, Ausführen, Schreiben von Sockets usw., alle von einem sequentiellen und seriellen Hauptthread verarbeitet. Dies ist der sogenannte „einzelne Thread“. Warum wurde Multithreading vor Redis6.0 nicht verwendet? Bei der Verwendung von Redis kommt es fast nie zu Situationen, in denen die CPU zum Engpass wird. Redis wird hauptsächlich durch Speicher und Netzwerk begrenzt. Auf einem normalen Linux-System kann Redis beispielsweise mithilfe von Pipelining 1 Million Anfragen pro Sekunde verarbeiten. Wenn die Anwendung also hauptsächlich O(N)- oder O(log(N))-Befehle verwendet, wird sie kaum viel CPU beanspruchen.
Der Zweck besteht darin, dass der Leistungsengpass von Redis im Netzwerk-IO und nicht in der CPU liegt. Durch die Verwendung von Multithreading kann die Effizienz des IO-Lesens und -Schreibens verbessert werden, wodurch die Gesamtleistung von Redis verbessert wird.
16. Lassen Sie uns über den Redis-Transaktionsmechanismus sprechen
- Redis implementiert den Transaktionsmechanismus durch eine Reihe von Befehlen wie
- MULTI, EXEC, WATCH
. Transaktionen unterstützen die gleichzeitige Ausführung mehrerer Befehle und alle Befehle in einer Transaktion werden serialisiert. Während des Transaktionsausführungsprozesses werden die Befehle in der Warteschlange serialisiert und der Reihe nach ausgeführt, und von anderen Clients übermittelte Befehlsanforderungen werden nicht in die Befehlssequenz zur Transaktionsausführung eingefügt.Kurz gesagt ist eine Redis-Transaktion
sequentielle, einmalige und exklusive Ausführung einer Reihe von Befehlen in einer Warteschlange.
- Der Prozess der Redis-Transaktionsausführung ist wie folgt:
- Transaktion starten (MULTI)
Befehl in die Warteschlange stellen
Transaktion ausführen (EXEC), Transaktion abbrechen (DISCARD)
17. Was tun bei Redis-Hash-Konflikten?Redis als K-V-In-Memory-Datenbank, die einen globalen Hash verwendet, um alle Schlüssel-Wert-Paare zu speichern. Diese Hash-Tabelle besteht aus mehreren Hash-Buckets. Das Eintragselement im Hash-Bucket speichert die key- und value-Zeiger, wobei *key auf den tatsächlichen Schlüssel und *value auf den tatsächlichen Wert zeigt.
Die Geschwindigkeit der Hash-Tabellensuche ist sehr hoch, ähnlich wie bei HashMap in Java, wodurch wir schnell Schlüssel-Wert-Paare in O(1)-Zeitkomplexität finden können. Berechnen Sie zunächst den Hash-Wert über den Schlüssel, suchen Sie den entsprechenden Hash-Bucket-Speicherort, suchen Sie dann den Eintrag und suchen Sie die entsprechenden Daten im Eintrag.
Was ist eine Hash-Kollision?
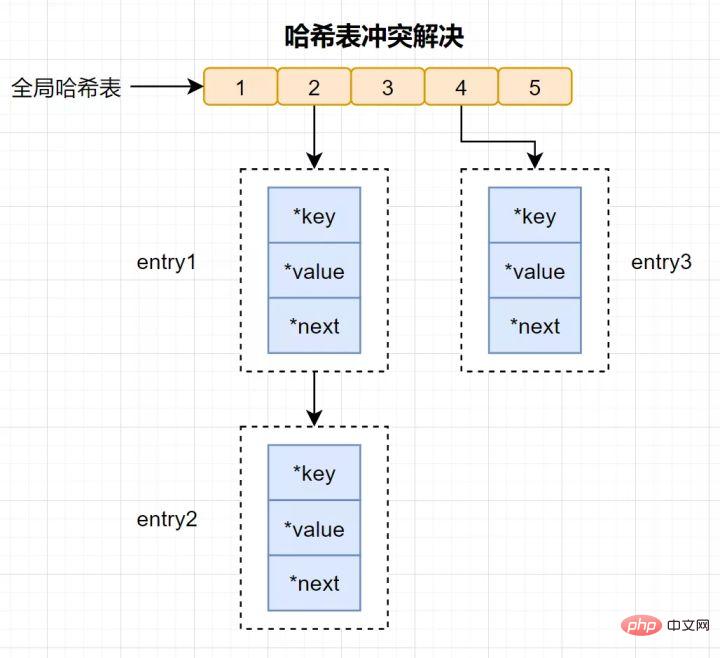
Hash-Konflikt: Derselbe Hash-Wert wird über verschiedene Schlüssel berechnet, was zu demselben Hash-Bucket führt.
Um Hash-Konflikte zu lösen, verwendet Redis Chain Hash. Verkettetes Hashing bedeutet, dass mehrere Elemente im selben Hash-Bucket in einer verknüpften Liste gespeichert und nacheinander mithilfe von Zeigern verbunden werden.
Einige Leser haben möglicherweise noch Fragen: Elemente in der Hash-Konfliktkette können nur einzeln über Zeiger durchsucht und dann bearbeitet werden. Wenn viele Daten in die Hash-Tabelle eingefügt werden, wird die Konfliktverknüpfungsliste umso länger, je mehr Konflikte auftreten, und die Abfrageeffizienz wird verringert.
Um die Effizienz aufrechtzuerhalten, führt Redis einen Rehash-Vorgang für die Hash-Tabelle durch, was bedeutet, dass Hash-Buckets hinzugefügt und Konflikte reduziert werden. Um die Wiederaufbereitung effizienter zu gestalten, verwendet Redis außerdem standardmäßig zwei globale Hash-Tabellen, eine für die aktuelle Verwendung, die sogenannte Haupt-Hash-Tabelle, und eine für die Erweiterung, die sogenannte Backup-Hash-Tabelle. 18. Kann Redis während der RDB-Generierung gleichzeitig Schreibanfragen verarbeiten?
Ja, Redis bietet zwei Anweisungen zum Generieren von RDB, nämlichsave und bgsave
.Wenn es sich um eine Speicheranweisung handelt, wird sie blockiert, da sie vom Hauptthread ausgeführt wird. Wenn es sich um eine bgsave-Anweisung handelt, gibt sie einen untergeordneten Prozess zum Schreiben der RDB-Datei weiter. Die Snapshot-Persistenz wird vollständig vom untergeordneten Prozess verwaltet und der übergeordnete Prozess kann weiterhin Clientanforderungen verarbeiten.
RESP bietet vor allem die Vorteile einer einfachen Implementierung, einer schnellen Analysegeschwindigkeit und einer guten Lesbarkeit
- 19. Welches Protokoll wird am Ende von Redis verwendet?
- RESP, der vollständige englische Name ist Redis Serialization Protocol, eine Reihe von Serialisierungsprotokollen, die speziell für Redis entwickelt wurden. Dieses Protokoll erschien tatsächlich in Version 1.2 von Redis. Aber erst mit Redis2.0 wurde es schließlich zum Standard für das Redis-Kommunikationsprotokoll.
.
20. Bloom-Filter
Um das Problem der Cache-Penetration zu lösen, können wir den
Bloom-Filterverwenden. Was ist ein Bloomfilter?
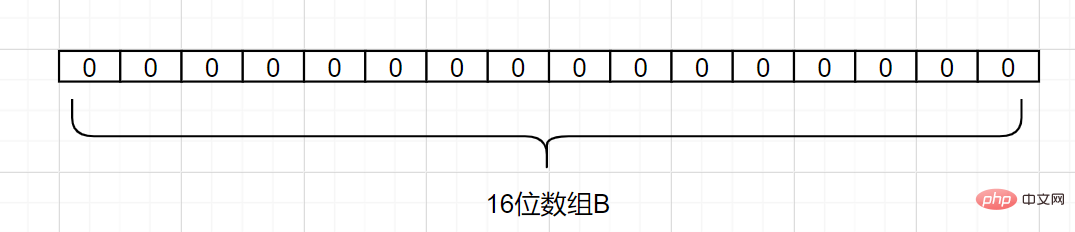
Ein Bloom-Filter ist eine Datenstruktur, die sehr wenig Platz einnimmt. Er besteht aus einem langen Binärvektor und einer Reihe von Hash-Mapping-Funktionen. Er wird verwendet, um abzurufen, ob sich ein Element in einer Menge befindet, um Platzeffizienz und Abfragezeit zu ermitteln. Sie sind viel besser als gewöhnliche Algorithmen. Die Nachteile sind eine gewisse Fehlerkennungsrate und Schwierigkeiten beim Löschen. Was ist das Prinzip des Bloom-Filters? Angenommen, wir haben eine Menge A und es gibt n Elemente in A. Mithilfe von
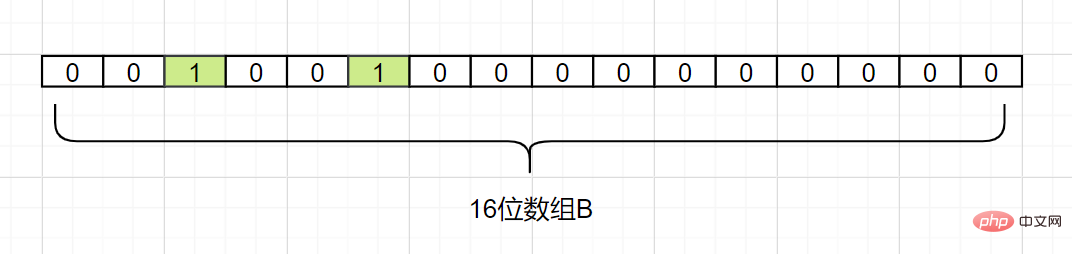
k-Hashing-Funktionen wird jedes Elementin A verschiedenen Positionen in einem Array B mit einer Länge von einem Bit zugeordnet
und die Binärzahlen an diesen Positionen werden alle auf 1 gesetzt. Wenn das zu prüfende Element durch diese k Hash-Funktionen abgebildet wird und sich herausstellt, dass die Binärzahlenan seinen k Positionen alle 1 sind, gehört dieses Element wahrscheinlich zur Menge A. Im Gegenteil, darf nicht zur Menge A gehören . . Schauen wir uns ein einfaches Beispiel an. Angenommen, Menge A hat 3 Elemente, nämlich {d1, d2, d3}. Es gibt 1 Hash-Funktion, nämlich Hash1. Ordnen Sie nun jedes Element von A einem Array B mit einer Länge von 16 Bit zu.
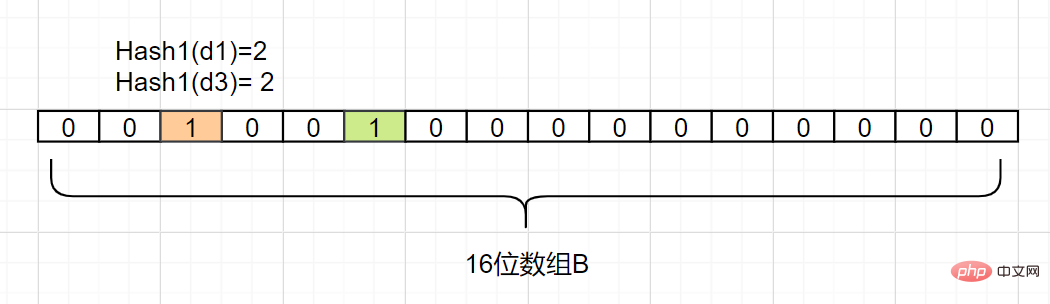
Unter der Annahme, dass Hash1(d1) = 2 ist, ändern wir das Raster mit Index 2 in Array B wie folgt auf 1:
d2 ab, vorausgesetzt Hash1 (d2) = 5, wir ändern das Raster mit Index 5 in Array B wie folgt auf 1:
Dann ordnen wir auch
d3 zu, vorausgesetzt Hash1(d3) ist ebenfalls gleich 2, es markiert auch das Raster mit Index 2 als 1:
Daher möchten wir bestätigen, ob sich ein Element dn in Satz A befindet. Wir müssen nur den durch Hash1 (dn) erhaltenen Indexindex berechnen, solange er 0 ist. es bedeutet, dass dieses Element
nicht in der Menge A ist. Was ist, wenn der Indexindex 1 ist? Dann kann das Element ein Element in A sein. Wie Sie sehen, können die von d1 und d3 erhaltenen Indexwerte beide 1 sein oder durch andere Zahlen abgebildet werden. Der Bloom-Filter hat diesen Nachteil: Es kommt zu Fehlalarmen, die durch eine Hash-Kollision verursacht werden ist ein Fehler im Urteil.
Wie
?
- Erstellen Sie mehr Hash-Funktionszuordnungen, um die Wahrscheinlichkeit einer Hash-Kollision zu verringern
Wir fügen eine weitere Hash2- Hash-Map
-Funktion hinzu, vorausgesetzt Hash2(d1)=6, Hash2(d3)=8, es kommt zu keinem Konflikt, wie folgt:Auch wenn ein Fehler vorliegt, können wir ihn finden , Der Bloom-Filter speichert nicht die vollständigen Daten, sondern verwendet lediglich eine Reihe von Hash-Map-Funktionen, um die Position zu berechnen, und füllt dann den Binärvektor. Wenn die
Anzahl groß ist
Derzeit verfügen Bloom-Filter bereits über Open-Source-Klassenbibliotheken, die entsprechende Implementierungen implementieren, wie z. B. die Guava-Klassenbibliothek von Google und die Algebird-Klassenbibliothek von Twitter. Sie können sie problemlos erhalten oder Ihr eigenes Design basierend auf den mitgelieferten Bitmaps implementieren mit Redis. Weitere Kenntnisse zum Thema Programmierung finden Sie unter: Programmiervideos! !
Das obige ist der detaillierte Inhalt vonZusammenfassung von 20 klassischen Redis-Interviewfragen und -antworten (teilen). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Häufig verwendete Datenbanksoftware
Häufig verwendete Datenbanksoftware
 Was sind In-Memory-Datenbanken?
Was sind In-Memory-Datenbanken?
 Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
 So verwenden Sie Redis als Cache-Server
So verwenden Sie Redis als Cache-Server
 Wie Redis die Datenkonsistenz löst
Wie Redis die Datenkonsistenz löst
 Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
 Welche Daten speichert der Redis-Cache im Allgemeinen?
Welche Daten speichert der Redis-Cache im Allgemeinen?
 Was sind die 8 Datentypen von Redis?
Was sind die 8 Datentypen von Redis?


 🎜🎜Liste (Liste)🎜🎜🎜Einführung: Der Listentyp (Liste) wird zum Speichern mehrerer geordneter Zeichenfolgen verwendet. Eine Liste kann bis zu 2^32-1 Elemente speichern. 🎜🎜Einfache und praktische Beispiele:
🎜🎜Liste (Liste)🎜🎜🎜Einführung: Der Listentyp (Liste) wird zum Speichern mehrerer geordneter Zeichenfolgen verwendet. Eine Liste kann bis zu 2^32-1 Elemente speichern. 🎜🎜Einfache und praktische Beispiele: 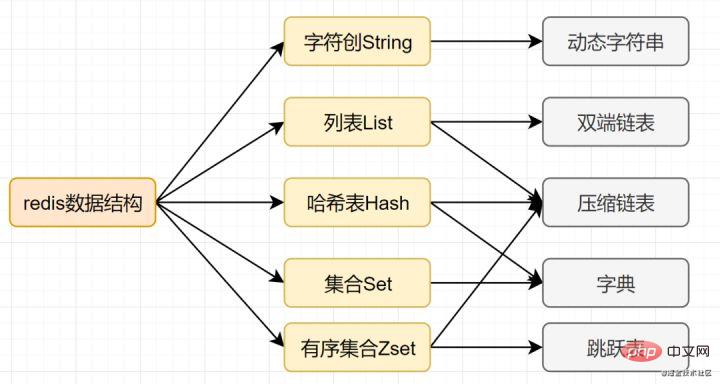
 RDB
RDB Geeignet für umfangreiche Datenwiederherstellungsszenarien wie Backup, vollständige Replikation usw.
Geeignet für umfangreiche Datenwiederherstellungsszenarien wie Backup, vollständige Replikation usw. 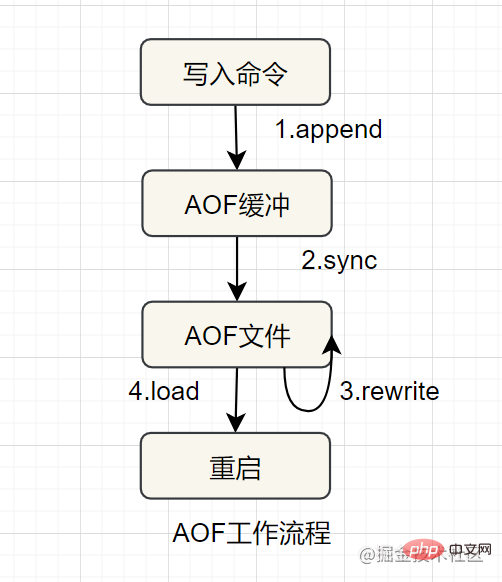

 Es ist in Ordnung, den Cache-Mechanismus erneut zu löschen, aber dies führt zu vielen
Es ist in Ordnung, den Cache-Mechanismus erneut zu löschen, aber dies führt zu vielen 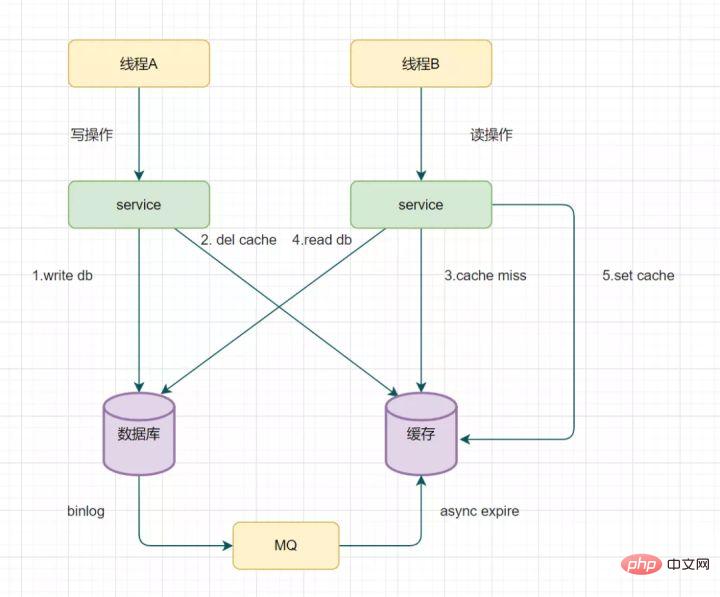 Die Verwendung von Multi-Threading durch Redis bedeutet nicht, dass Redis weiterhin ein Single-Thread-Modell zur Verarbeitung von Client-Anfragen verwendet. Es verwendet nur Multi-Threading, um das Lesen und Schreiben von Daten sowie die Protokollanalyse zu verarbeiten es verwendet immer noch einen einzelnen Thread, um Befehle auszuführen.
Die Verwendung von Multi-Threading durch Redis bedeutet nicht, dass Redis weiterhin ein Single-Thread-Modell zur Verarbeitung von Client-Anfragen verwendet. Es verwendet nur Multi-Threading, um das Lesen und Schreiben von Daten sowie die Protokollanalyse zu verarbeiten es verwendet immer noch einen einzelnen Thread, um Befehle auszuführen. 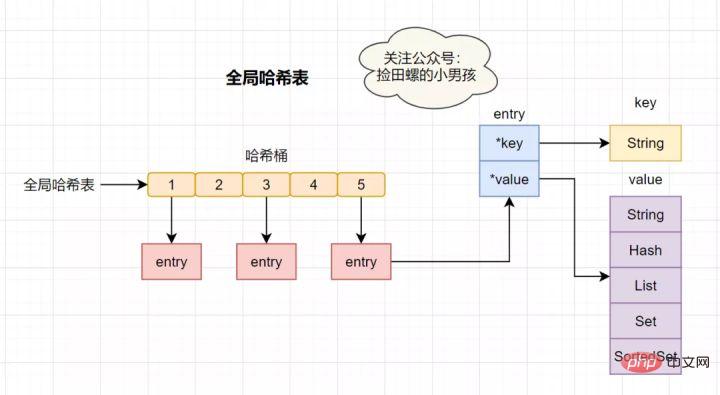
 Wir bilden jetzt auch
Wir bilden jetzt auch 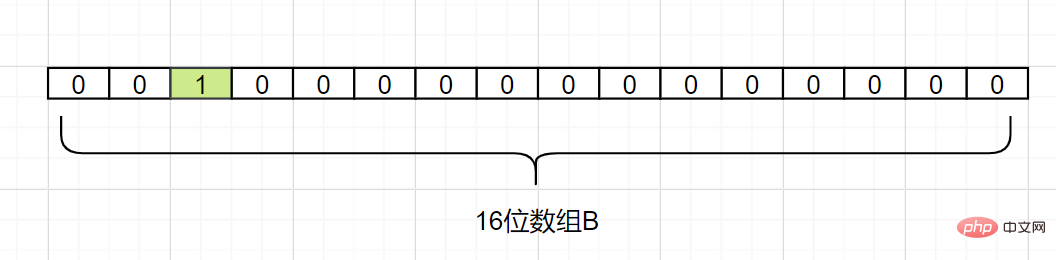
 diesen Fehler reduzieren
diesen Fehler reduzieren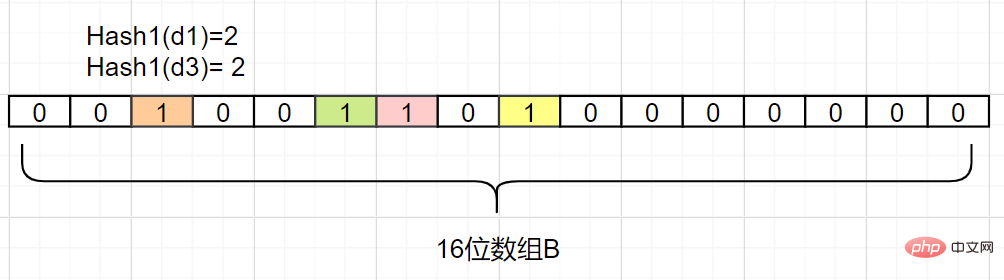 , kann der Bloom-Filter durch eine sehr geringe Fehlerquote viel Speicherplatz sparen, was recht kostengünstig ist.
, kann der Bloom-Filter durch eine sehr geringe Fehlerquote viel Speicherplatz sparen, was recht kostengünstig ist. 








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



