

Wo ist das Linux-Absturzprotokoll?

Linux-Ausfallzeitprotokoll befindet sich in „/var/log/“; das Protokollprotokoll von „/var/log/“ unter Linux enthält Meldungen, Kernel-Fehlerprotokolle usw.; der SA-Datensatz zeichnet den Betrieb von CPU, Speicher usw. auf. usw. Leistungsdatei; verwenden Sie die SA-Datei, um die CPU- und Speicherbedingungen während des Absturzes anzuzeigen.

Die Betriebsumgebung dieses Tutorials: Linux5.9.8-System, Dell G3-Computer.
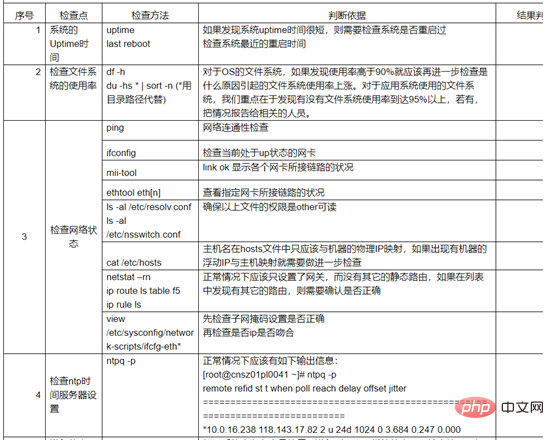
Wo sind die Linux-Ausfallzeitprotokolle?
Ideen zur Fehlerbehebung bei Ausfallzeiten von Linux-Hosts
Ursachenanalyse
Serverklassifizierung, Webserver, Datenbankserver, Dateiserver, Middleware, andere Server.
Webserver-Analyse: gängige Webanwendungen Apache, Nginx, IIS usw.
Es gibt viele Gründe für Ausfallzeiten, wie z. B. CPU-, Speicher-, E/A-Festplattenfehler, Anwendungsfehler, Kernelfehler, Hardware usw.
System- und Kernelversion
Prozess
1 Zeitaufzeichnung von Ausfallzeiten, historischen Anmeldungen und Neustarts Zeit
 last -F |. Überprüfen Sie den Anmeldeverlauf auf ungewöhnliche Benutzer
last -F |. Überprüfen Sie den Anmeldeverlauf auf ungewöhnliche Benutzer
letzter

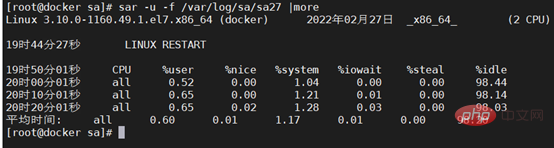
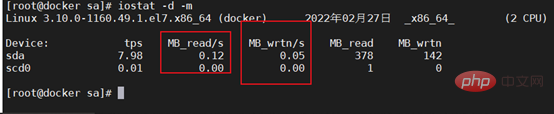
2. Erste Überprüfung das Systemprotokoll. Beispielsweise enthält das Protokollprotokoll unter /var/log/ unter Linux Nachrichten, Kernel-Fehlerprotokolle, Demsg usw. Der SA-Datensatz ist eine Leistungsdatei, die den Betrieb von CPU, Speicher usw. aufzeichnet und den Betriebsstatus aufzeichnet CPU während des Betriebs wie in der Abbildung gezeigt.
Verwenden Sie die SA-Datei, um den CPU-Status während des Herunterfahrens zu überprüfen

Verwenden Sie die SA-Datei, um den Speicherstatus während des Herunterfahrens zu überprüfen
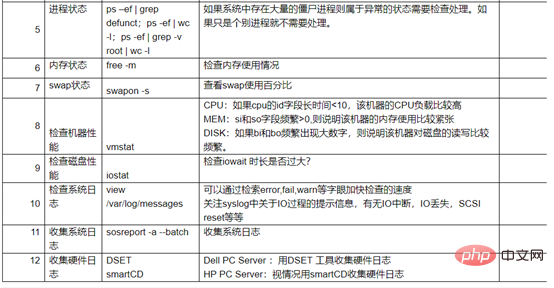
 Das Protokollvolumen ist oft groß
Das Protokollvolumen ist oft groß
Sie können auch Fuzzy-Abfragen durchführen , wie zum Beispiel
Fehlerberichte anzeigen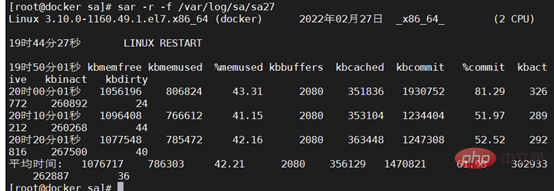
tail -200 /var/log/messages |grep "Error" cat /var/log/dmesg |grep "Error"
tail -200 /car/log/messages |grep "crash"
cat /var/log/messages |grep -i "kill"
cat /vat/log/messages |grep "Feb 11 15*"
4. Io- und Dateisystemnutzung anzeigen
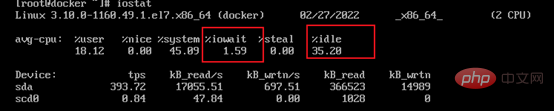
Leerlauf und iowait beobachten. Der Cache wird beim Lesen und Schreiben auf die Festplatte verwendet, was im Allgemeinen 40 % des Systemspeichers ausmacht. In der Mitte wird jedoch eine Pufferzeit von 120 Sekunden eingehalten 120 Sekunden vor dem Schreiben auf die Festplatte. Wenn häufig gelesen und geschrieben wird, kann es manchmal leicht zum Hängenbleiben kommen.

Überprüfen Sie die E/A-Lese- und Schreibgeschwindigkeit. Wenn sie sehr langsam ist, liegt ein Engpass in der Festplattenleistung vor.
 Dateisystemnutzung
Dateisystemnutzung
 5. Überprüfen Sie das Sicherheitsprotokoll.
5. Überprüfen Sie das Sicherheitsprotokoll.
Das Sicherheitsprotokoll lautet /var/log/secure. Überprüfen Sie den Verlaufsdatensatz, um festzustellen, ob sich jemand beim Host angemeldet und böswillige Aktionen ausgeführt hat. wie zum Beispiel Herunterfahren.
6. Verwenden Sie kdump und Crash-Tools, um den Kernel zu analysieren.
Überprüfen Sie, ob der kdump-Dienst auf dem Server aktiviert ist, und suchen Sie die an diesem Tag generierte vmcore-Datei im Verzeichnis /var/crash. Verwenden Sie das Crash-Tool, um die vmcore-Datei zu analysieren.
Kdump wird zum Speichern von Speicherabbildern verwendet. Es kann nicht nur das Speicherabbild auf die lokale Festplatte übertragen, sondern auch über NFS, SSH und andere Protokolle auf Geräte auf verschiedenen Computern übertragen. 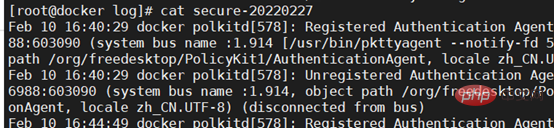
8. Zusammenfassung
Es gibt viele Gründe für Systemausfälle, die wir entsprechend dem Prozess sorgfältig analysieren müssen,
Verwandte Empfehlungen: „Linux-Video-Tutorial“
Das obige ist der detaillierte Inhalt vonWo ist das Linux-Absturzprotokoll?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Unterschied zwischen CentOS und Ubuntu
Apr 14, 2025 pm 09:09 PM
Unterschied zwischen CentOS und Ubuntu
Apr 14, 2025 pm 09:09 PM
Die wichtigsten Unterschiede zwischen CentOS und Ubuntu sind: Ursprung (CentOS stammt von Red Hat, für Unternehmen; Ubuntu stammt aus Debian, für Einzelpersonen), Packungsmanagement (CentOS verwendet yum, konzentriert sich auf Stabilität; Ubuntu verwendet apt, für hohe Aktualisierungsfrequenz), Support Cycle (Centos) (CENTOS bieten 10 Jahre. Tutorials und Dokumente), Verwendungen (CentOS ist auf Server voreingenommen, Ubuntu ist für Server und Desktops geeignet). Weitere Unterschiede sind die Einfachheit der Installation (CentOS ist dünn)
 CentOS stoppt die Wartung 2024
Apr 14, 2025 pm 08:39 PM
CentOS stoppt die Wartung 2024
Apr 14, 2025 pm 08:39 PM
CentOS wird 2024 geschlossen, da seine stromaufwärts gelegene Verteilung RHEL 8 geschlossen wurde. Diese Abschaltung wirkt sich auf das CentOS 8 -System aus und verhindert, dass es weiterhin Aktualisierungen erhalten. Benutzer sollten eine Migration planen, und empfohlene Optionen umfassen CentOS Stream, Almalinux und Rocky Linux, um das System sicher und stabil zu halten.
 So installieren Sie CentOs
Apr 14, 2025 pm 09:03 PM
So installieren Sie CentOs
Apr 14, 2025 pm 09:03 PM
CentOS -Installationsschritte: Laden Sie das ISO -Bild herunter und verbrennen Sie bootfähige Medien. Starten und wählen Sie die Installationsquelle; Wählen Sie das Layout der Sprache und Tastatur aus. Konfigurieren Sie das Netzwerk; Partition die Festplatte; Setzen Sie die Systemuhr; Erstellen Sie den Root -Benutzer; Wählen Sie das Softwarepaket aus; Starten Sie die Installation; Starten Sie nach Abschluss der Installation von der Festplatte neu und starten Sie von der Festplatte.
 Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Backup- und Wiederherstellungsrichtlinie von GitLab im Rahmen von CentOS -System Um die Datensicherheit und Wiederherstellung der Daten zu gewährleisten, bietet GitLab on CentOS eine Vielzahl von Sicherungsmethoden. In diesem Artikel werden mehrere gängige Sicherungsmethoden, Konfigurationsparameter und Wiederherstellungsprozesse im Detail eingeführt, um eine vollständige GitLab -Sicherungs- und Wiederherstellungsstrategie aufzubauen. 1. Manuell Backup Verwenden Sie den GitLab-RakegitLab: Backup: Befehl erstellen, um die manuelle Sicherung auszuführen. Dieser Befehl unterstützt wichtige Informationen wie GitLab Repository, Datenbank, Benutzer, Benutzergruppen, Schlüssel und Berechtigungen. Die Standardsicherungsdatei wird im Verzeichnis/var/opt/gitlab/backups gespeichert. Sie können /etc /gitlab ändern
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 So verwenden Sie Docker Desktop
Apr 15, 2025 am 11:45 AM
So verwenden Sie Docker Desktop
Apr 15, 2025 am 11:45 AM
Wie benutze ich Docker Desktop? Docker Desktop ist ein Werkzeug zum Ausführen von Docker -Containern auf lokalen Maschinen. Zu den zu verwendenden Schritten gehören: 1.. Docker Desktop installieren; 2. Start Docker Desktop; 3.. Erstellen Sie das Docker -Bild (mit Dockerfile); 4. Build Docker Image (mit Docker Build); 5. Docker -Container ausführen (mit Docker Run).
 Wie man in CentOS fester Festplatten montiert
Apr 14, 2025 pm 08:15 PM
Wie man in CentOS fester Festplatten montiert
Apr 14, 2025 pm 08:15 PM
CentOS -Festplattenhalterung ist in die folgenden Schritte unterteilt: Bestimmen Sie den Namen der Festplattengeräte (/dev/sdx); Erstellen Sie einen Mountspunkt (es wird empfohlen, /mnt /newDisk zu verwenden). Führen Sie den Befehl montage (mont /dev /sdx1 /mnt /newdisk) aus; Bearbeiten Sie die Datei /etc /fstab, um eine permanente Konfiguration des Montings hinzuzufügen. Verwenden Sie den Befehl uMount, um das Gerät zu deinstallieren, um sicherzustellen, dass kein Prozess das Gerät verwendet.
 Was zu tun ist, nachdem CentOS die Wartung gestoppt hat
Apr 14, 2025 pm 08:48 PM
Was zu tun ist, nachdem CentOS die Wartung gestoppt hat
Apr 14, 2025 pm 08:48 PM
Nachdem CentOS gestoppt wurde, können Benutzer die folgenden Maßnahmen ergreifen, um sich damit zu befassen: Wählen Sie eine kompatible Verteilung aus: wie Almalinux, Rocky Linux und CentOS Stream. Migrieren Sie auf kommerzielle Verteilungen: wie Red Hat Enterprise Linux, Oracle Linux. Upgrade auf CentOS 9 Stream: Rolling Distribution und bietet die neueste Technologie. Wählen Sie andere Linux -Verteilungen aus: wie Ubuntu, Debian. Bewerten Sie andere Optionen wie Container, virtuelle Maschinen oder Cloud -Plattformen.
