

Der Typ char belegt 1 Byte in C oder C++ und 2 Bytes in Java. char wird in C oder C++ zum Definieren von Zeichenvariablen verwendet. Der Datentyp char ist ein Ganzzahltyp und belegt nur 1 Byte. In Java belegt der Typ char 2 Bytes, da der Java-Compiler standardmäßig die Unicode-Codierung verwendet, sodass 2 Bytes (16 Bit) alle Zeichen darstellen können.

Die Betriebsumgebung dieses Tutorials: Windows 7-System, Dell G3-Computer.
Ich habe auf Baidu nach „Wie viele Bytes belegt char“ gesucht und die folgende Antwort erhalten:

Char wird zum Definieren von Zeichenvariablen in C oder C++ verwendet. Es ist ein ganzzahliger Typ und belegt nur einen Byte. Der Wertebereich liegt zwischen -128 und +127 (-27 und 27-1).
Der char-Typ belegt 1 Byte, also 8 Bit. Die speicherbaren positiven Ganzzahlen sind 0111 1111, also 127.
Offensichtlich ist dies nicht das gewünschte Ergebnis, also suchte ich weiter nach „Wie viele Bytes belegt char in Java?“

Char in Java ist ein Datentyp, der zum Speichern von Zeichen verwendet wird und 2 Bytes belegt Bei Verwendung der Unicode-Kodierung sind die ersten 128 Bytes der Kodierung mit ASCII kompatibel, für die Darstellung einiger Zeichen sind jedoch zwei Zeichen erforderlich.
Warum belegen Zeichen in C oder C++ und Java unterschiedlich viele Bytes?
Was bedeutet es, dass für die Darstellung einiger Zeichen zwei Zeichen erforderlich sind?
Codierung
Bevor wir dieses Problem diskutieren, wollen wir zunächst einige Wissenspunkte bekannt machen.
Zuallererst wissen wir alle, dass die im Computer gespeicherten Informationen durch Binärzahlen dargestellt werden. Wie können wir also zulassen, dass der Computer die von uns Menschen verwendeten chinesischen Schriftzeichen oder Englisch speichert?
Zum Beispiel wird die Umwandlung von „a“ in eine Binärzahl und die Speicherung im Computer als „Kodierung“ bezeichnet. Und das Analysieren und Anzeigen der im Computer gespeicherten Binärzahlen wird als „Dekodierung“ bezeichnet.
Zeichensatz
Zeichen (Zeichen) ist ein allgemeiner Begriff für verschiedene Zeichen und Symbole, einschließlich verschiedener nationaler Zeichen, Satzzeichen, grafischer Symbole, Zahlen usw. Der Zeichensatz (Zeichensatz) ist eine Sammlung mehrerer Zeichen. Es gibt viele Arten von Zeichensätzen, und jeder Zeichensatz enthält eine unterschiedliche Anzahl gemeinsamer Zeichensatznamen: ASCII-Zeichensatz, GB2312-Zeichensatz, GB18030 Zeichensatz, Unicode-Zeichensatz usw. Dies ist die Erklärung von Baidu Encyclopedia. Wie dem auch sei, ein Zeichensatz ist eine Sammlung von Zeichen. Es gibt viele Arten von Zeichensätzen, und auch die Anzahl der Zeichen in einem Zeichensatz ist unterschiedlich. Damit ein Computer Text in verschiedenen Zeichensätzen genau verarbeiten kann, ist eine Zeichenkodierung erforderlich, damit der Computer verschiedene Texte erkennen und speichern kann. unicode
Der Name ist Unicode, auch Universalcode genannt. Die Anzahl der Symbole nimmt ständig zu und hat die Grenze von einer Million überschritten.
Bevor Unicode erstellt wurde, gab es Hunderte von Kodierungssystemen. Keine Kodierung kann genügend Zeichen enthalten. Wie aus dem Namen hervorgeht, handelt es sich um eine Kodierung aller Symbole, sodass das durch unterschiedliche Kodierungen verursachte Problem mit dem verstümmelten Code verschwindet. Die meisten Computer verwenden ASCII (American Standard Code for Information Interchange), ein 7-Bit-Kodierungsschema, das alle Groß- und Kleinbuchstaben, Zahlen, Satzzeichen und Steuerzeichen darstellt. Unicode enthält ASCII-Codes und „u0000“ bis „u007F“ entsprechen allen 128 ACSII-Zeichen.
Ich kann nicht anders, als zu spüren, dass nur diejenigen, die stark sind, Maßstäbe setzen können. Unicode ist nur ein Symbolsatz. Es gibt nur den Binärcode des Symbols an. Es stellt nur die Zuordnung zwischen Zeichen und Zahlen bereit, legt jedoch nicht fest, wie dieser Binärcode gespeichert werden soll. Wir wissen, dass die Anzahl der englischen Buchstaben sehr gering ist und durch ein Byte dargestellt werden kann, aber die Anzahl der chinesischen Symbole in Unicode ist sehr groß und ein Byte kann überhaupt nicht verwendet werden. Infolgedessen erschienen später verschiedene Implementierungsmethoden für die Unicode-Zeichenspeicherung, wie UTF-8, UTF-16 usw. UTF-8 ist die am weitesten verbreitete Unicode-Implementierung im Internet.
Innerer Code und äußerer CodeWir sagen oft, dass char in Java mehrere Bytes belegt, was char im inneren Code in Java sein sollte.
Interner Code bezieht sich auf die Codierungsmethode von Zeichen und Zeichenfolgen im Speicher, wenn Java ausgeführt wird. Externer Code ist die Zeichencodierung, die extern verwendet wird, wenn das Programm mit der Außenwelt interagiert, z. B. die Serialisierungstechnologie. Unter Fremdcode versteht man: Solange es sich nicht um einen internen Code handelt, handelt es sich um einen Fremdcode. Es ist zu beachten, dass die Codierungsmethode in der durch die Quellcodekompilierung generierten Objektcodedatei (ausführbare Datei oder Klassendatei) zu Fremdcode gehört. Der interne Code in der JVM verwendet UTF16. Die 16 in UTF-16 bezieht sich auf die Mindesteinheit von 16 Bit, das heißt, zwei Bytes sind eine Einheit. In den Anfängen wurde UTF16 mit einer 2-Byte-Methode mit fester Länge codiert. Zwei Bytes können 65536 Symbole darstellen (tatsächlich kann es sogar weniger als diese Zahl darstellen), was damals ausreichte, um alle Zeichen in Unicode darzustellen. Mit der Zunahme der Zeichen in Unicode können 2 Bytes jedoch nicht alle Zeichen darstellen. UTF16 verwendet 2 Bytes oder 4 Bytes, um die Codierung abzuschließen. Um mit dieser Situation umzugehen, verwendet Java ein Zeichenpaar zur Darstellung von Zeichen, die 4 Bytes erfordern, wobei Vorwärtskompatibilitätsanforderungen berücksichtigt werden. Daher nimmt char in Java zwei Bytes ein, aber einige Zeichen erfordern zwei Zeichen, um sie darzustellen. Dies erklärt, warum einige Zeichen zwei Zeichen benötigen, um sie darzustellen.
Außerdem: Java-Klassendateien verwenden UTF8 zum Speichern von Zeichen, d. h. die Zeichen in der Klasse belegen 1 bis 6 Bytes. Bei der Java-Serialisierung werden Zeichen auch in UTF8 codiert, was 1 bis 6 Zeichen entspricht.
length()
Dann ist hier noch eine Frage: Was ist die String.length() eines Zeichens in Java?
Nachdem ich die vorherigen Wissenspunkte gelesen habe, kann ich meinen Mund und die Antwort nicht mehr öffnen ist 1... ...Schreiben Sie eine Demo und schauen Sie sich Folgendes an: Verwenden Sie im Jahr des Tigers Tiger zum Testen. TigerUTF stellt die entsprechende Unicode-Codierung dar.
String tiger = "?"; String tigerUTF = "\uD83D\uDC05"; System.out.println(tigerUTF); System.out.println(tiger.length()); System.out.println(tiger.codePointCount(0,tiger.length()));
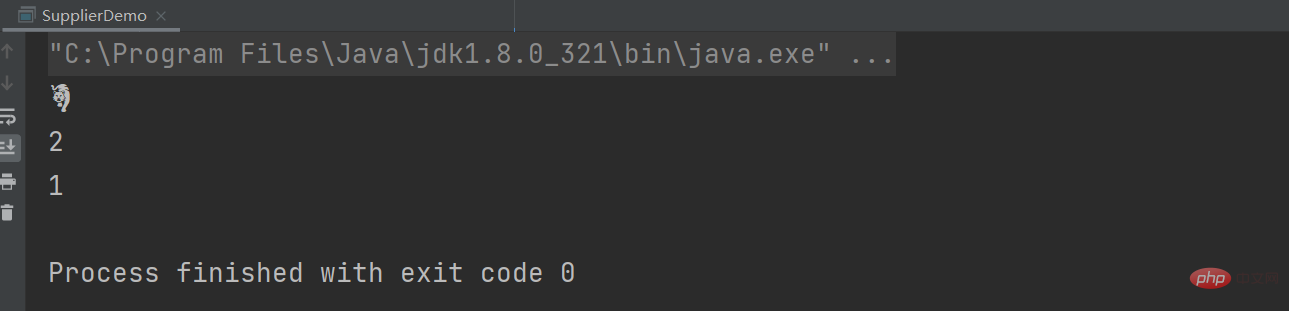
kann durch Aufrufen der String.length()得到的结果为2,表示的是stirng的char数组占UTF-16格式的2个代码单元(即4个字节),而不是有多少个字符。 当然我们想要获取多少个字符,可以使用codePointCount-Methode erhalten werden.
Weitere Informationen zu diesem Thema finden Sie in der Spalte „FAQ“!
Das obige ist der detaillierte Inhalt vonWie viele Bytes belegt der Typ char?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So verbinden Sie Breitband mit einem Server
So verbinden Sie Breitband mit einem Server
 HTTP 503-Fehlerlösung
HTTP 503-Fehlerlösung
 So überspringen Sie die Verbindung zum Internet nach dem Hochfahren von Windows 11
So überspringen Sie die Verbindung zum Internet nach dem Hochfahren von Windows 11
 So aktivieren Sie den abgesicherten Word-Modus
So aktivieren Sie den abgesicherten Word-Modus
 Die Rolle des HTML-Titel-Tags
Die Rolle des HTML-Titel-Tags
 jquery animieren
jquery animieren
 kb4012212 Was tun, wenn das Update fehlschlägt?
kb4012212 Was tun, wenn das Update fehlschlägt?
 Was tun, wenn das eingebettete Bild nicht vollständig angezeigt wird?
Was tun, wenn das eingebettete Bild nicht vollständig angezeigt wird?
 So exportieren Sie Word aus Powerdesigner
So exportieren Sie Word aus Powerdesigner

![HarmonyOS 2.0-Anwendungsentwicklungspraxis [Hongmeng-System-APP-Entwicklung]](https://img.php.cn/upload/course/000/000/041/61c970d04644f402.jpg)

![Praktische Entwicklung einer Nachahmung der Meituan APP [Ein unverzichtbares JavaScript-Projekt für Front-End-Programmierer]](https://img.php.cn/upload/course/000/000/068/6242bebc05ca9210.png)







![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



