

12款免费与开源的NoSQL数据库介绍_MySQL

NoSQL
Naresh Kumar是位软件工程师与热情的博主,对于编程与新事物拥有极大的兴趣,非常乐于与其他开发者和程序员分享技术上的研究成果。近日,Naresh撰文谈到了12款知名的免费、开源NoSQL数据库,并对这些数据库的特点进行了分析。

现在,NoSQL数据库变得越来越流行,我在这里总结出了一些非常棒的、免费且开源的NoSQL数据库。在这些数据库中,MongoDB独占鳌头,拥有相当大的使用量。这些免费且开源的NoSQL数据库具有很好的可伸缩性与灵活性,非常适合于大数据存储与处理。相较于传统的关系型数据库,这些NoSQL数据库在性能上具有很大的优势。然而,这些NoSQL数据库未必最适合你。大多数常见的应用仍然可以使用传统的关系型数据库进行开发。NoSQL数据库依然不太适合于那些任务关键型的事务要求。我对这些数据库进行了一些简单介绍,下面就来看看。
1. MongoDB
MongoDB是个面向文档的数据库,使用JSON风格的数据格式。它非常适合于网站的数据存储、内容管理与缓存应用,并且通过配置可以实现复制与高可用性功能。
MongoDB具有很强的可伸缩性,性能表现优异。它使用C++编写,基于文档存储。此外,MongoDB还支持全文检索、跨WAN与LAN的高可用性、易于实现的复制、水平扩展、基于文档的丰富查询、在数据处理与聚合等方面具有很强的灵活性。
2. Cassandra
这是个Apache软件基金会的项目,Cassandra是个分布式数据库,支持分散的数据存储,可以实现容错以及无单点故障等。换句话说,“Cassandra非常适合于那些无法忍受数据丢失的应用”。
3. CouchDB
这也是Apache软件基金会的一个项目,CouchDB是另一个面向文档的数据库,以JSON格式存储数据。它兼容于ACID,像MongoDB一样,CouchDB也可以用于存储网站的数据与内容,以及提供缓存等。你可以通过JavaScript在CouchDB上运行MapReduce查询。此外,CouchDB还提供了一个非常方便的基于Web的管理控制台。它非常适合于Web应用。
4. Hypertable
Hypertable模仿的是Google的BigTable数据库系统。Hypertable的创建者将“成为高可用、PB规模的数据库开源标准”作为Hypertable的目标。换言之,Hypertable的设计目标是跨越多个廉价的服务器可靠地存储大量数据。
5. Redis
这是个开源、高级的键值存储。由于在键中使用了hash、set、string、sorted set及list,因此Redis也称作数据结构服务器。这个系统可以帮助你执行原子操作,比如说增加hash中的值、集合的交集运算、字符串拼接、差集与并集等。Redis通过内存中的数据集实现了高性能。此外,该数据库还兼容于大多数编程语言。
6. Riak
Riak是最为强大的分布式数据库之一,它提供了轻松且可预测的伸缩能力,向用户提供了快速测试、原型与应用部署能力,从而简化应用的开发过程。
7. Neo4j
Neo4j是一款NoSQL图型数据库,具有非常高的性能。它拥有一个健壮且成熟的系统的所有特性,向程序员提供了灵活且面向对象的网络结构,可以让开发者充分享受到拥有完整事务特性的数据库的所有好处。相较于RDBMS,Neo4j还对某些应用提供了不少性能改进。
8. Hadoop HBase
HBase是一款可伸缩、分布式的大数据存储。它可以用在数据的实时与随机访问的场景下。HBase拥有模块化与线性的可伸缩性,并且能够保证读写的严格一致性。HBase提供了一个Java API,可以实现轻松的客户端访问;提供了可配置且自动化的表分区功能;还有Bloom过滤器以及block缓存等特性。
9. Couchbase
虽然Couchbase是CouchDB的派生,不过它已经成为了一款功能完善的数据库产品。它向文档数据库转移的趋势会让MongoDB感到压力。每个节点上它都是多线程的,这是个非常主要的可伸缩性优势,特别是当托管在自定义或是Bare-Metal硬件上时更是如此。借助于一些非常棒的集成特性,诸如与Hadoop的集成,Couchbase对于数据存储来说是个非常不错的选择。
10. MemcacheDB
这是个分布式的键值存储系统,我们不应该将其与缓存解决方案搞混;相反,它是个持久化存储引擎,用于数据存储并以非常快速且可靠的方式检索数据。它遵循memcache协议。其存储后端用于Berkeley DB中,支持诸如复制与事务等特性。
11. REVENDB
RAVENDB是第二代开源数据库,它面向文档存储并且无模式,这样就可以轻松将对象存储到其中了。它提供了非常灵活且快速的查询,通过对复制、多租与分片提供开箱即用的支持使得我们可以非常轻松地实现伸缩功能。它对ACID事务提供了完整的支持,同时又能保证数据的安全性。除了高性能之外,它还通过bundle提供了轻松的可扩展性。
12. Voldemort
这是个自动复制的分布式存储系统。它提供了自动化的数据分区功能,透明的服务器失败处理、可插拔的序列化功能、独立的节点、数据版本化以及跨越各种数据中心的数据分发功能。
各位读者,不知在你的项目中曾经、现在或是未来使用了哪些NoSQL数据库。现今的NoSQL世界纷繁复杂,NoSQL数据库也多如牛毛,而且有一些数据库提供了相似的特性,本文所列出的只是其中比较有代表性的12款NoSQL产品。你是否使用过他们呢?是否使用了本文没有介绍的产品呢?他们有哪些特性打动了你,让你决定使用他们呢?非常欢迎将你的经历与看法与我们一起分享。

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Empfohlen: Ausgezeichnetes JS-Open-Source-Projekt zur Gesichtserkennung und -erkennung
Apr 03, 2024 am 11:55 AM
Empfohlen: Ausgezeichnetes JS-Open-Source-Projekt zur Gesichtserkennung und -erkennung
Apr 03, 2024 am 11:55 AM
Die Technologie zur Gesichtserkennung und -erkennung ist bereits eine relativ ausgereifte und weit verbreitete Technologie. Derzeit ist JS die am weitesten verbreitete Internetanwendungssprache. Die Implementierung der Gesichtserkennung und -erkennung im Web-Frontend hat im Vergleich zur Back-End-Gesichtserkennung Vor- und Nachteile. Zu den Vorteilen gehören die Reduzierung der Netzwerkinteraktion und die Echtzeiterkennung, was die Wartezeit des Benutzers erheblich verkürzt und das Benutzererlebnis verbessert. Die Nachteile sind: Es ist durch die Größe des Modells begrenzt und auch die Genauigkeit ist begrenzt. Wie implementiert man mit js die Gesichtserkennung im Web? Um die Gesichtserkennung im Web zu implementieren, müssen Sie mit verwandten Programmiersprachen und -technologien wie JavaScript, HTML, CSS, WebRTC usw. vertraut sein. Gleichzeitig müssen Sie auch relevante Technologien für Computer Vision und künstliche Intelligenz beherrschen. Dies ist aufgrund des Designs der Webseite erwähnenswert
 Gerade erschienen! Ein Open-Source-Modell zum Generieren von Bildern im Anime-Stil mit einem Klick
Apr 08, 2024 pm 06:01 PM
Gerade erschienen! Ein Open-Source-Modell zum Generieren von Bildern im Anime-Stil mit einem Klick
Apr 08, 2024 pm 06:01 PM
Lassen Sie mich Ihnen das neueste AIGC-Open-Source-Projekt vorstellen – AnimagineXL3.1. Dieses Projekt ist die neueste Version des Text-zu-Bild-Modells mit Anime-Thema und zielt darauf ab, Benutzern ein optimiertes und leistungsfähigeres Erlebnis bei der Generierung von Anime-Bildern zu bieten. Bei AnimagineXL3.1 konzentrierte sich das Entwicklungsteam auf die Optimierung mehrerer Schlüsselaspekte, um sicherzustellen, dass das Modell neue Höhen in Bezug auf Leistung und Funktionalität erreicht. Zunächst erweiterten sie die Trainingsdaten, um nicht nur Spielcharakterdaten aus früheren Versionen, sondern auch Daten aus vielen anderen bekannten Anime-Serien in das Trainingsset aufzunehmen. Dieser Schritt erweitert die Wissensbasis des Modells und ermöglicht ihm ein umfassenderes Verständnis verschiedener Anime-Stile und Charaktere. AnimagineXL3.1 führt eine neue Reihe spezieller Tags und Ästhetiken ein
 Das multimodale Dokumentenverständnis-Großmodell Alibaba 7B gewinnt neue SOTA
Apr 02, 2024 am 11:31 AM
Das multimodale Dokumentenverständnis-Großmodell Alibaba 7B gewinnt neue SOTA
Apr 02, 2024 am 11:31 AM
Neues SOTA für multimodale Dokumentverständnisfunktionen! Das Alibaba mPLUG-Team hat die neueste Open-Source-Arbeit mPLUG-DocOwl1.5 veröffentlicht, die eine Reihe von Lösungen zur Bewältigung der vier großen Herausforderungen der hochauflösenden Bildtexterkennung, des allgemeinen Verständnisses der Dokumentstruktur, der Befolgung von Anweisungen und der Einführung externen Wissens vorschlägt. Schauen wir uns ohne weitere Umschweife zunächst die Auswirkungen an. Ein-Klick-Erkennung und Konvertierung von Diagrammen mit komplexen Strukturen in das Markdown-Format: Es stehen Diagramme verschiedener Stile zur Verfügung: Auch eine detailliertere Texterkennung und -positionierung ist einfach zu handhaben: Auch ausführliche Erläuterungen zum Dokumentverständnis können gegeben werden: Sie wissen schon, „Document Understanding“. " ist derzeit ein wichtiges Szenario für die Implementierung großer Sprachmodelle. Es gibt viele Produkte auf dem Markt, die das Lesen von Dokumenten unterstützen. Einige von ihnen verwenden hauptsächlich OCR-Systeme zur Texterkennung und arbeiten mit LLM zur Textverarbeitung zusammen.
 Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
FP8 und die geringere Gleitkomma-Quantifizierungsgenauigkeit sind nicht länger das „Patent“ von H100! Lao Huang wollte, dass jeder INT8/INT4 nutzt, und das Microsoft DeepSpeed-Team begann, FP6 auf A100 ohne offizielle Unterstützung von NVIDIA auszuführen. Testergebnisse zeigen, dass die FP6-Quantisierung der neuen Methode TC-FPx auf A100 nahe an INT4 liegt oder gelegentlich schneller als diese ist und eine höhere Genauigkeit aufweist als letztere. Darüber hinaus gibt es eine durchgängige Unterstützung großer Modelle, die als Open-Source-Lösung bereitgestellt und in Deep-Learning-Inferenz-Frameworks wie DeepSpeed integriert wurde. Dieses Ergebnis wirkt sich auch unmittelbar auf die Beschleunigung großer Modelle aus – in diesem Rahmen ist der Durchsatz bei Verwendung einer einzelnen Karte zum Ausführen von Llama 2,65-mal höher als der von Doppelkarten. eins
 Das leistungsstärkste Open-Source-Codemodell aiXcoder-7B der Universität Peking! Konzentrieren Sie sich auf reale Entwicklungsszenarien und sind speziell für die private Bereitstellung in Unternehmen konzipiert
Apr 09, 2024 pm 06:10 PM
Das leistungsstärkste Open-Source-Codemodell aiXcoder-7B der Universität Peking! Konzentrieren Sie sich auf reale Entwicklungsszenarien und sind speziell für die private Bereitstellung in Unternehmen konzipiert
Apr 09, 2024 pm 06:10 PM
Den neuesten Entwicklungen im Technologiekreis nach zu urteilen, ist das Konzept der KI-Codegenerierung in letzter Zeit populär geworden. Freunde, haben Sie jedoch das Gefühl, dass Fragen zur KI-Programmierung auffälliger sind, aber wenn es um reale Unternehmensentwicklungsszenarien geht, haben Sie immer das Gefühl, dass dies nicht ausreicht? In diesem Moment ergriff ein zurückhaltender Senior-Spieler aiXcoder Maßnahmen und veröffentlichte einen großen Schritt: Es handelt sich um ein neues Open-Source-Codemodell – aiXcoder-7BBase-Version, ein Codemodell, das speziell für den Einsatz in Entwicklungsszenarien von Unternehmenssoftware geeignet ist. Moment, welchen KI-Programmierstand kann ein großes Codemodell mit „nur“ 7 Milliarden Parametern aufweisen? Werfen wir zunächst einen Blick auf die Leistung in den drei gängigen Bewertungssätzen HumanEval, MBPP und MultiPL-E. Die durchschnittliche Punktzahl übertrifft tatsächlich die von Co, das 34 Milliarden Parameter aufweist.
 Teilen Sie mehrere .NET-Open-Source-KI- und LLM-bezogene Projekt-Frameworks
May 06, 2024 pm 04:43 PM
Teilen Sie mehrere .NET-Open-Source-KI- und LLM-bezogene Projekt-Frameworks
May 06, 2024 pm 04:43 PM
Die Entwicklung von Technologien der künstlichen Intelligenz (KI) ist heute in vollem Gange und sie haben in verschiedenen Bereichen großes Potenzial und Einfluss gezeigt. Heute wird Dayao Ihnen 4 .NET Open-Source-KI-Modell-LLM-bezogene Projekt-Frameworks vorstellen und hofft, Ihnen einige Referenzen zu geben. https://github.com/YSGStudyHards/DotNetGuide/blob/main/docs/DotNet/DotNetProjectPicks.mdSemanticKernelSemanticKernel ist ein Open-Source-Softwareentwicklungskit (SDK), das für die Integration großer Sprachmodelle (LLM) wie OpenAI und Azure entwickelt wurde
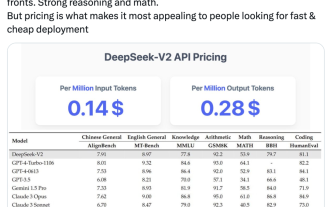 Inländische Open-Source-MoE-Indikatoren explodieren: GPT-4-Level-Fähigkeiten, API-Preis beträgt nur ein Prozent
May 07, 2024 pm 05:34 PM
Inländische Open-Source-MoE-Indikatoren explodieren: GPT-4-Level-Fähigkeiten, API-Preis beträgt nur ein Prozent
May 07, 2024 pm 05:34 PM
Das neueste groß angelegte inländische Open-Source-MoE-Modell erfreute sich gleich nach seinem Debüt großer Beliebtheit. Die Leistung von DeepSeek-V2 erreicht GPT-4-Niveau, es ist jedoch Open Source, kostenlos für die kommerzielle Nutzung und der API-Preis beträgt nur ein Prozent von GPT-4-Turbo. Daher löste es sofort nach seiner Veröffentlichung viele Diskussionen aus. Den veröffentlichten Leistungsindikatoren zufolge übertreffen die umfassenden chinesischen Fähigkeiten von DeepSeekV2 die vieler Open-Source-Modelle. Gleichzeitig befinden sich auch Closed-Source-Modelle wie GPT-4Turbo und Wenkuai 4.0 auf der ersten Stufe. Die umfassenden Englischkenntnisse liegen ebenfalls auf der gleichen ersten Stufe wie LLaMA3-70B und übertreffen Mixtral8x22B, das ebenfalls ein MoE ist. Es zeigt auch gute Leistungen in den Bereichen Wissen, Mathematik, logisches Denken, Programmieren usw. Und unterstützt 128K-Kontext. Stellen Sie sich das vor
 Ausführliches Tutorial zum Herstellen einer Datenbankverbindung mit MySQLi in PHP
Jun 04, 2024 pm 01:42 PM
Ausführliches Tutorial zum Herstellen einer Datenbankverbindung mit MySQLi in PHP
Jun 04, 2024 pm 01:42 PM
So verwenden Sie MySQLi zum Herstellen einer Datenbankverbindung in PHP: MySQLi-Erweiterung einbinden (require_once) Verbindungsfunktion erstellen (functionconnect_to_db) Verbindungsfunktion aufrufen ($conn=connect_to_db()) Abfrage ausführen ($result=$conn->query()) Schließen Verbindung ( $conn->close())
