

Erfahren Sie mehr über das unsichere Paket in Golang

In einigen Low-Level-Bibliotheken wird häufig das unsichere Paket verwendet. Dieser Artikel wird Ihnen helfen, das unsichere Paket in Golang zu verstehen, die Rolle des unsicheren Pakets und die Verwendung von Pointer vorzustellen. Ich hoffe, er wird Ihnen hilfreich sein!

Das unsichere Paket bietet einige Vorgänge, die die Typsicherheitsprüfung von go umgehen können, wodurch Speicheradressen direkt bearbeitet und einige knifflige Vorgänge ausgeführt werden können. Die Laufumgebung des Beispielcodes ist
go version go1.18 darwin/amd64
Speicherausrichtung
Das unsichere Paket stellt die Sizeof-Methode bereit, um die von Variablen belegte Speichergröße zu ermitteln, „mit Ausnahme der Speichergröße, auf die Zeiger auf Variablen zeigen“, und Alignof ruft die Speicherausrichtung ab Sie können nach bestimmten Speicherausrichtungsregeln googeln.
type demo1 struct {
a bool // 1
b int32 // 4
c int64 // 8
}
type demo2 struct {
a bool // 1
c int64 // 8
b int32 // 4
}
type demo3 struct { // 64 位操作系统, 字长 8
a *demo1 // 8
b *demo2 // 8
}
func MemAlign() {
fmt.Println(unsafe.Sizeof(demo1{}), unsafe.Alignof(demo1{}), unsafe.Alignof(demo1{}.a), unsafe.Alignof(demo1{}.b), unsafe.Alignof(demo1{}.c)) // 16,8,1,4,8
fmt.Println(unsafe.Sizeof(demo2{}), unsafe.Alignof(demo2{}), unsafe.Alignof(demo2{}.a), unsafe.Alignof(demo2{}.b), unsafe.Alignof(demo2{}.c)) // 24,8,1,4,8
fmt.Println(unsafe.Sizeof(demo3{})) // 16
} // 16}复制代码Aus dem obigen Fall können Sie sehen, dass Demo1 und Demo2 die gleichen Attribute enthalten, aber die Reihenfolge der definierten Attribute ist unterschiedlich, was zu unterschiedlichen Speichergrößen führt Variablen. Dies liegt daran, dass eine Speicherausrichtung erfolgt.
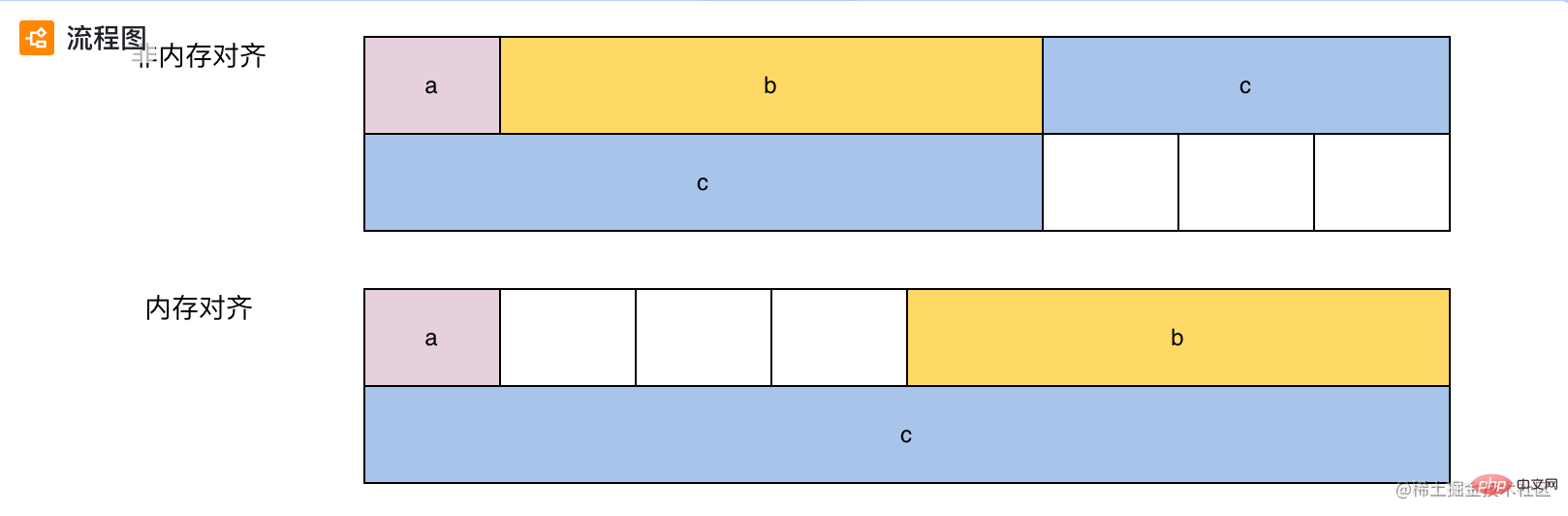
Wenn der Computer Aufgaben verarbeitet, verarbeitet er Daten in Einheiten bestimmter Wortlängen. „Zum Beispiel: 32-Bit-Betriebssystem, Wortlänge beträgt 4; 64-Bit-Betriebssystem, Wortlänge beträgt 8“. Beim Lesen von Daten richtet sich die Einheit dann auch nach der Wortlänge. Beispiel: Bei 64-Bit-Betriebssystemen ist die Anzahl der vom Programm gleichzeitig gelesenen Bytes ein Vielfaches von 8. Das Folgende ist das Layout von Demo1 unter Nicht-Speicherausrichtung und Speicherausrichtung:
Nicht-Speicherausrichtung:
Die Variable c wird in unterschiedlichen Wortlängen platziert. Beim Lesen muss die CPU zweimal gleichzeitig lesen. und lesen Sie beide. Nur durch die Verarbeitung der Ergebnisse der Zeiten können wir den Wert von c erhalten. Obwohl diese Methode Speicherplatz spart, erhöht sie die Verarbeitungszeit.
Speicherausrichtung:
Die Speicherausrichtung verwendet ein Schema, das die Situation derselben Nicht-Speicherausrichtung vermeiden kann, aber etwas zusätzlichen Platz „Raum für Zeit“ beansprucht. Sie können nach bestimmten Regeln für die Speicherausrichtung googeln.
Unsicherer Zeiger
In go können Sie einen Zeigertyp als sicheren Zeiger deklarieren, was bedeutet, dass Sie klarstellen müssen, auf welchen Typ der Zeiger zeigt. Beim Kompilieren tritt ein Fehler auf. Wie im folgenden Beispiel geht der Compiler davon aus, dass MyString und string unterschiedliche Typen sind und nicht zugewiesen werden können.
func main() {
type MyString string
s := "test"
var ms MyString = s // Cannot use 's' (type string) as the type MyString
fmt.Println(ms)
}Gibt es also einen Typ, der auf Variablen jeden Typs verweisen kann? Sie können unsfe.Pointer verwenden, der auf jede Art von Variable verweisen kann. Durch die Deklaration von Pointer können wir erkennen, dass es sich um einen Zeigertyp handelt, der auf die Adresse der Variablen zeigt. Der der spezifischen Adresse entsprechende Wert kann über uinptr konvertiert werden. Zeiger verfügt über die folgenden vier Spezialoperationen:
- Jeder Zeigertyp kann in den Zeigertyp konvertiert werden
- Variablen vom Zeigertyp können in jeden Zeigertyp konvertiert werden
- Variablen vom Typ uintptr können in den Zeigertyp konvertiert werden
- Zeiger Typ Die Variable kann in den Typ uintprt konvertiert werden
type Pointer *ArbitraryType
// uintptr is an integer type that is large enough to hold the bit pattern of
// any pointer.
type uintptr uintptr
func main() {
d := demo1{true, 1, 2}
p := unsafe.Pointer(&d) // 任意类型的指针可以转换为 Pointer 类型
pa := (*demo1)(p) // Pointer 类型变量可以转换成 demo1 类型的指针
up := uintptr(p) // Pointer 类型的变量可以转换成 uintprt 类型
pu := unsafe.Pointer(up) // uintptr 类型的变量可以转换成 Pointer 类型; 当 GC 时, d 的地址可能会发生变更, 因此, 这里的 up 可能会失效
fmt.Println(d.a, pa.a, (*demo1)(pu).a) // true true true
}Sechs Möglichkeiten zur Verwendung von Pointer
Das offizielle Dokument gibt sechs Möglichkeiten zur Verwendung von Pointer an.
Konvertieren Sie *T1 in *T2 über den Zeiger
Der Zeiger zeigt direkt auf einen Speicherabschnitt, sodass diese Speicheradresse in einen beliebigen Typ konvertiert werden kann. Hierbei ist zu beachten, dass T1 und T2 das gleiche Speicherlayout haben müssen und es zu abnormalen Daten kommt.
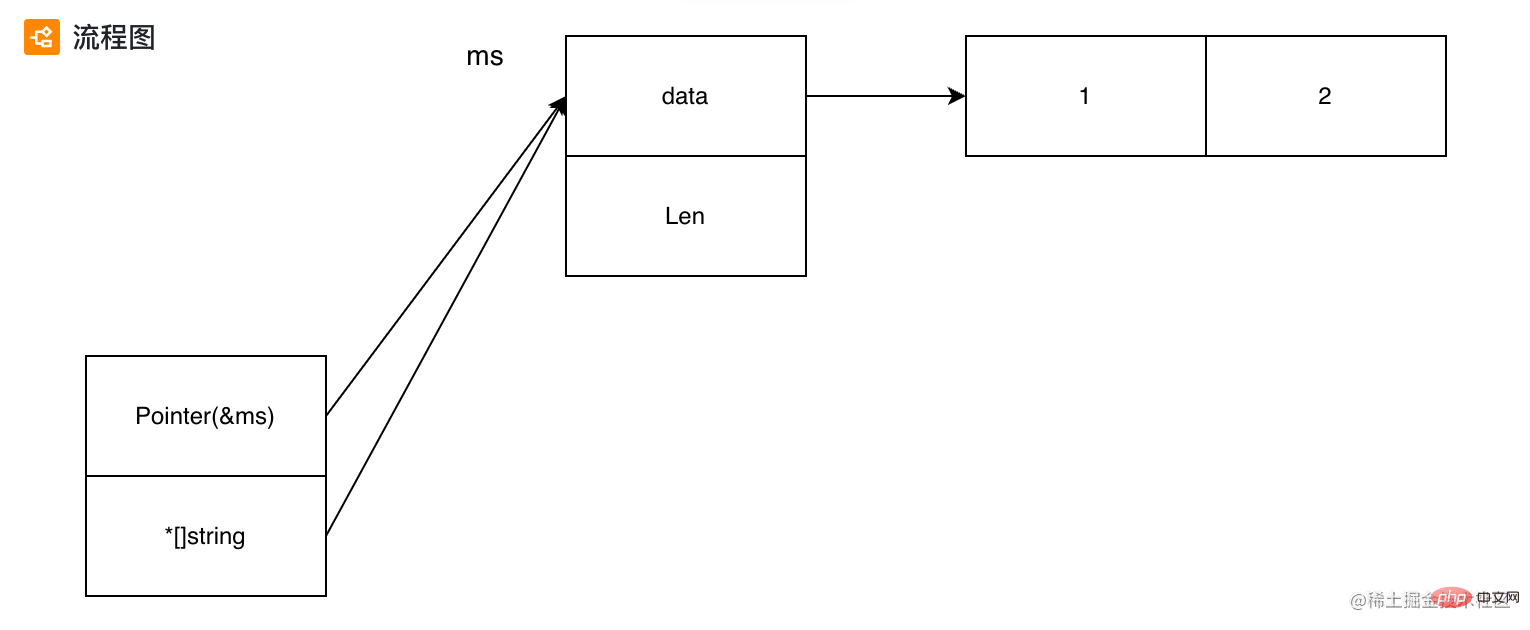
func main() {
type myStr string
ms := []myStr{"1", "2"}
//ss := ([]string)(ms) Cannot convert an expression of the type '[]myStr' to the type '[]string'
ss := *(*[]string)(unsafe.Pointer(&ms)) // 将 pointer 指向的内存地址直接转换成 *[]string
fmt.Println(ms, ss)
}
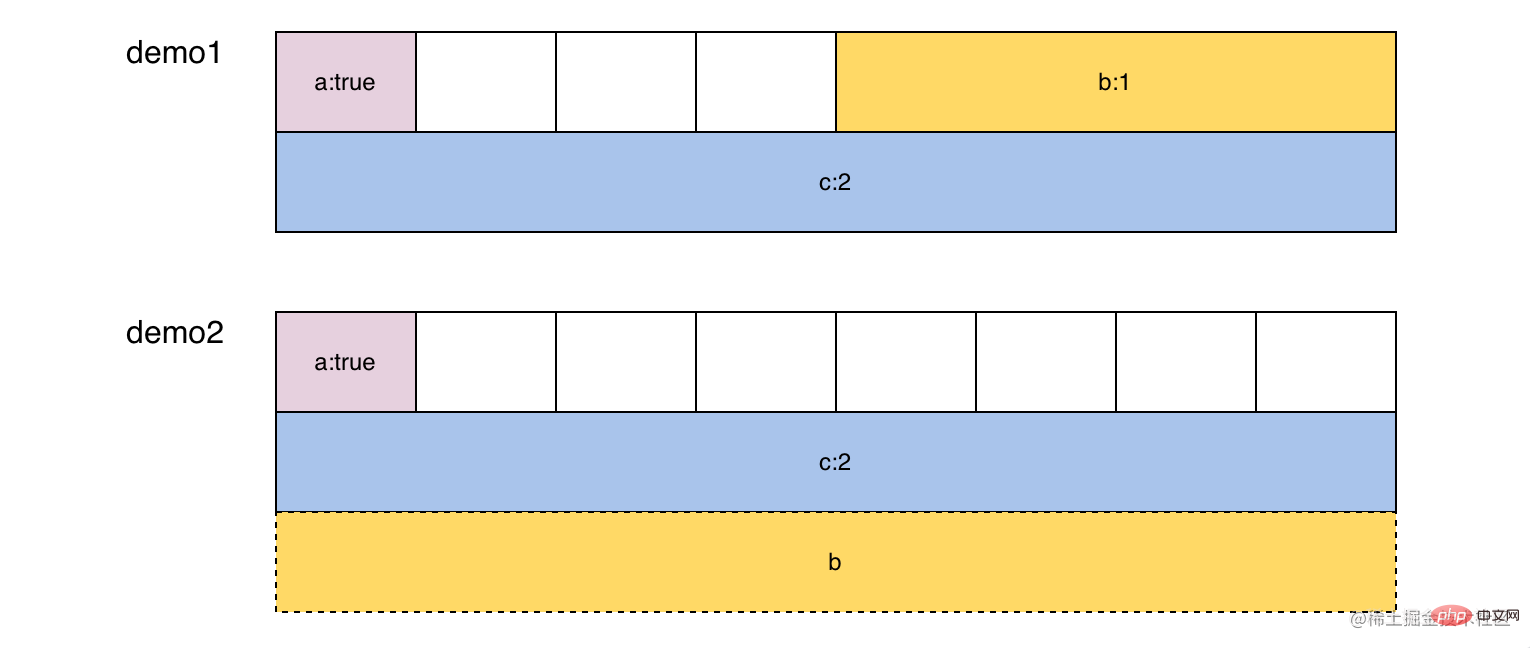
Was passiert, wenn das Speicherlayout von T1 und T2 unterschiedlich ist? Im folgenden Beispiel enthalten Demo1 und Demo2 zwar dieselbe Struktur, weisen jedoch aufgrund der Speicherausrichtung unterschiedliche Speicherlayouts auf. Beim Konvertieren des Zeigers werden 24 „sizeof“-Bytes beginnend mit der Adresse von Demo1 gelesen und die Konvertierung gemäß den Speicherausrichtungsregeln von Demo2 durchgeführt. Das erste Byte wird in a:true und 8-16 Bytes konvertiert wird in c konvertiert: 2, 16-24 Bytes liegen außerhalb des Bereichs von Demo1, können aber dennoch direkt gelesen werden und es wird der unerwartete Wert b: 17368000 erhalten.
type demo1 struct {
a bool // 1
b int32 // 4
c int64 // 8
}
type demo2 struct {
a bool // 1
c int64 // 8
b int32 // 4
}
func main() {
d := demo1{true, 1, 2}
pa := (*demo2)(unsafe.Pointer(&d)) // Pointer 类型变量可以转换成 demo2 类型的指针
fmt.Println(pa.a, pa.b, pa.c) // true, 17368000, 2,
}
Zeigertyp in uintptr-Typ konvertieren „Sie sollten uinptr nicht in Zeiger konvertieren“
Pointer ist ein Zeigertyp, der auf jede Variable zeigen kann und durch Konvertieren von Pointer in uintptr-Zeiger gedruckt werden kann zeigt auf die Adresse der Variablen. Zusätzlich: uintptr sollte nicht in Pointer konvertiert werden. Nehmen Sie das folgende Beispiel: Wenn GC auftritt, kann sich die Adresse von d ändern, dann zeigt up aufgrund nicht synchronisierter Aktualisierungen auf den falschen Speicher.
func main() {
d := demo1{true, 1, 2}
p := unsafe.Pointer(&d)
up := uintptr(p)
fmt.Printf("uintptr: %x, ptr: %p \n", up, &d) // uintptr: c00010c010, ptr: 0xc00010c010
fmt.Println(*(*demo1)(unsafe.Pointer(up))) // 不允许
}通过算数计算将 Pointer 转换为 uinptr 再转换回 Pointer
当 Piointer 指向一个结构体时, 可以通过此方式获取到结构体内部特定属性的 Pointer。
func main() {
d := demo1{true, 1, 2}
// 等同于 unsafe.Pointer(&d.b); unsafe.Add(unsafe.Pointer(&d), unsafe.Offsetof(d.b))
pb := unsafe.Pointer(uintptr(unsafe.Pointer(&d)) + unsafe.Offsetof(d.b))
fmt.Println(pb)
}当调用 syscall.Syscall 的时候, 可以讲 Pointer 转换为 uintptr
前面说过, 由于 GC 会导致变量的地址发生变更, 因此不可以直接处理 uintptr。但是, 在调用 syscall.Syscall 时候可以允许传递一个 uintptr, 这里可以简单理解为是编译器做了特殊处理, 来保证 uintptr 是安全的。
- 调用方式:
- syscall.Syscall(SYS_READ, uintptr( fd ), uintptr(unsafe.Pointer(p)), uintptr(n))
下面这种方式是不允许的:
u := uintptr(unsafe.Pointer(p)) // 不应该保存到一个变量上 syscall.Syscall(SYS_READ, uintptr( fd ), u, uintptr(n))
可以将 reflect.Value.Pointer 或 reflect.Value.UnsafeAddr 的结果「uintptr」转换为 Pointer
在 reflect 包中的 Value.Pointer 和 Value.UnsafeAddr 直接返回了地址对应的值「uintptr」, 可以直接将其结果转为 Pointer
func main() {
d := demo1{true, 1, 2}
// 等同于 unsafe.Pointer(&d.b); unsafe.Add(unsafe.Pointer(&d), unsafe.Offsetof(d.b))
pb := unsafe.Pointer(uintptr(unsafe.Pointer(&d)) + unsafe.Offsetof(d.b))
// up := reflect.ValueOf(&d.b).Pointer(), pc := unsafe.Pointer(up); 不安全, 不应存储到变量中
pc := unsafe.Pointer(reflect.ValueOf(&d.b).Pointer())
fmt.Println(pb, pc)
}可以将 reflect.SliceHeader 或者 reflect.StringHeader 的 Data 字段与 Pointer 相互转换
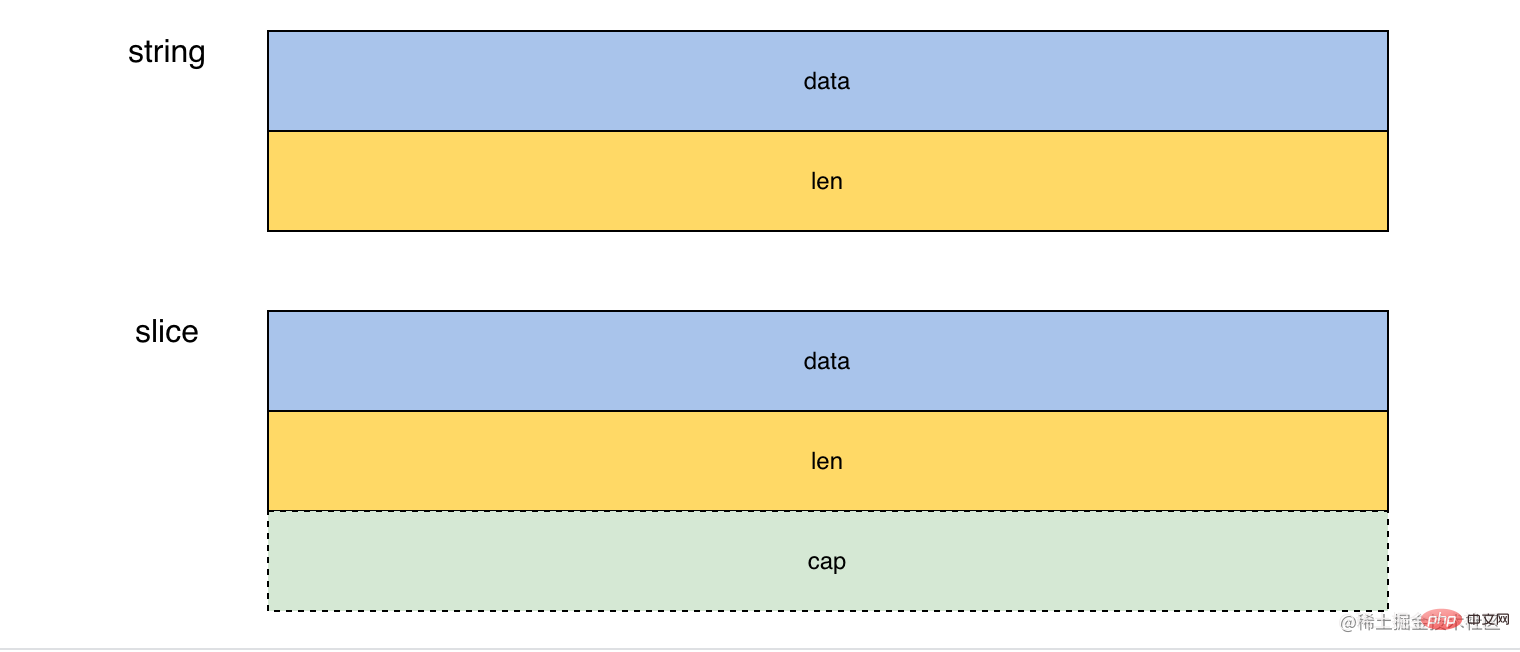
SliceHeader 和 StringHeader 其实是 slice 和 string 的内部实现, 里面都包含了一个字段 Data「uintptr」, 存储的是指向 []T 的地址, 这里之所以使用 uinptr 是为了不依赖 unsafe 包。
func main() {
s := "a"
hdr := (*reflect.StringHeader)(unsafe.Pointer(&s)) // *string to *StringHeader
fmt.Println(*(*[1]byte)(unsafe.Pointer(hdr.Data))) // 底层存储的是 utf 编码后的 byte 数组
arr := [1]byte{65}
hdr.Data = uintptr(unsafe.Pointer(&arr))
hdr.Len = len(arr)
ss := *(*string)(unsafe.Pointer(hdr))
fmt.Println(ss) // A
arr[0] = 66
fmt.Println(ss) //B
}应用
string、byte 转换
在业务上, 经常遇到 string 和 []byte 的相互转换。我们知道, string 底层其实也是存储的一个 byte 数组, 可以通过 reflect 直接获取 string 指向的 byte 数组, 赋值给 byte 切片, 避免内存拷贝。
func StrToByte(str string) []byte {
return []byte(str)
}
func StrToByteV2(str string) (b []byte) {
bh := (*reflect.SliceHeader)(unsafe.Pointer(&b))
sh := (*reflect.StringHeader)(unsafe.Pointer(&str))
bh.Data = sh.Data
bh.Cap = sh.Len
bh.Len = sh.Len
return b
}
// go test -bench .
func BenchmarkStrToArr(b *testing.B) {
for i := 0; i < b.N; i++ {
StrToByte(`{"f": "v"}`)
}
}
func BenchmarkStrToArrV2(b *testing.B) {
for i := 0; i < b.N; i++ {
StrToByteV2(`{"f": "v"}`)
}
}
//goos: darwin
//goarch: amd64
//pkg: github.com/demo/lsafe
//cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz
//BenchmarkStrToArr-12 264733503 4.311 ns/op
//BenchmarkStrToArrV2-12 1000000000 0.2528 ns/op通过观察 string 和 byte 的内存布局我们可以知道, 无法直接将 string 转为 []byte 「确实 cap 字段」, 但是可以直接将 []byte 转为 string
func ByteToStr(b []byte) string {
return string(b)
}
func ByteToStrV2(b []byte) string {
return *(*string)(unsafe.Pointer(&b))
}
// go test -bench .
func BenchmarkArrToStr(b *testing.B) {
for i := 0; i < b.N; i++ {
ByteToStr([]byte{65})
}
}
func BenchmarkArrToStrV2(b *testing.B) {
for i := 0; i < b.N; i++ {
ByteToStrV2([]byte{65})
}
}
//goos: darwin
//goarch: amd64
//pkg: github.com/demo/lsafe
//cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz
//BenchmarkArrToStr-12 536188455 2.180 ns/op
//BenchmarkArrToStrV2-12 1000000000 0.2526 ns/op总结
本文介绍了如何使用 unsafe 包绕过类型检查, 直接操作内存。正如 go 作者对包的命名一样, 它是 unsafe 的, 随着 go 版本的迭代, 有些机制可能会发生变更。如无必要, 不应使用这个包。如果要使用 unsafe 包, 一定要理解清楚Pointer、uinptr、对齐系数等概念。
推荐学习:Golang教程
Das obige ist der detaillierte Inhalt vonErfahren Sie mehr über das unsichere Paket in Golang. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Vertiefendes Verständnis des Golang-Funktionslebenszyklus und des Variablenumfangs
Apr 19, 2024 am 11:42 AM
Vertiefendes Verständnis des Golang-Funktionslebenszyklus und des Variablenumfangs
Apr 19, 2024 am 11:42 AM
In Go umfasst der Funktionslebenszyklus Definition, Laden, Verknüpfen, Initialisieren, Aufrufen und Zurückgeben; der Variablenbereich ist in Funktionsebene und Blockebene unterteilt. Variablen innerhalb einer Funktion sind intern sichtbar, während Variablen innerhalb eines Blocks nur innerhalb des Blocks sichtbar sind .
 Wie kann ich Zeitstempel mithilfe regulärer Ausdrücke in Go abgleichen?
Jun 02, 2024 am 09:00 AM
Wie kann ich Zeitstempel mithilfe regulärer Ausdrücke in Go abgleichen?
Jun 02, 2024 am 09:00 AM
In Go können Sie reguläre Ausdrücke verwenden, um Zeitstempel abzugleichen: Kompilieren Sie eine Zeichenfolge mit regulären Ausdrücken, z. B. die, die zum Abgleich von ISO8601-Zeitstempeln verwendet wird: ^\d{4}-\d{2}-\d{2}T \d{ 2}:\d{2}:\d{2}(\.\d+)?(Z|[+-][0-9]{2}:[0-9]{2})$ . Verwenden Sie die Funktion regexp.MatchString, um zu überprüfen, ob eine Zeichenfolge mit einem regulären Ausdruck übereinstimmt.
 Wie sende ich Go WebSocket-Nachrichten?
Jun 03, 2024 pm 04:53 PM
Wie sende ich Go WebSocket-Nachrichten?
Jun 03, 2024 pm 04:53 PM
In Go können WebSocket-Nachrichten mit dem Paket gorilla/websocket gesendet werden. Konkrete Schritte: Stellen Sie eine WebSocket-Verbindung her. Senden Sie eine Textnachricht: Rufen Sie WriteMessage(websocket.TextMessage,[]byte("message")) auf. Senden Sie eine binäre Nachricht: Rufen Sie WriteMessage(websocket.BinaryMessage,[]byte{1,2,3}) auf.
 Der Unterschied zwischen Golang und Go-Sprache
May 31, 2024 pm 08:10 PM
Der Unterschied zwischen Golang und Go-Sprache
May 31, 2024 pm 08:10 PM
Go und die Go-Sprache sind unterschiedliche Einheiten mit unterschiedlichen Eigenschaften. Go (auch bekannt als Golang) ist bekannt für seine Parallelität, schnelle Kompilierungsgeschwindigkeit, Speicherverwaltung und plattformübergreifende Vorteile. Zu den Nachteilen der Go-Sprache gehören ein weniger umfangreiches Ökosystem als andere Sprachen, eine strengere Syntax und das Fehlen dynamischer Typisierung.
 Wie vermeidet man Speicherlecks bei der technischen Leistungsoptimierung von Golang?
Jun 04, 2024 pm 12:27 PM
Wie vermeidet man Speicherlecks bei der technischen Leistungsoptimierung von Golang?
Jun 04, 2024 pm 12:27 PM
Speicherlecks können dazu führen, dass der Speicher des Go-Programms kontinuierlich zunimmt, indem: Ressourcen geschlossen werden, die nicht mehr verwendet werden, wie z. B. Dateien, Netzwerkverbindungen und Datenbankverbindungen. Verwenden Sie schwache Referenzen, um Speicherlecks zu verhindern, und zielen Sie auf Objekte für die Garbage Collection ab, wenn sie nicht mehr stark referenziert sind. Bei Verwendung von Go-Coroutine wird der Speicher des Coroutine-Stapels beim Beenden automatisch freigegeben, um Speicherverluste zu vermeiden.
 Wie kann ich die Golang-Funktionsdokumentation in der IDE anzeigen?
Apr 18, 2024 pm 03:06 PM
Wie kann ich die Golang-Funktionsdokumentation in der IDE anzeigen?
Apr 18, 2024 pm 03:06 PM
Go-Funktionsdokumentation mit der IDE anzeigen: Bewegen Sie den Cursor über den Funktionsnamen. Drücken Sie den Hotkey (GoLand: Strg+Q; VSCode: Nach der Installation von GoExtensionPack F1 und wählen Sie „Go:ShowDocumentation“).
 Wie verwende ich den Fehler-Wrapper von Golang?
Jun 03, 2024 pm 04:08 PM
Wie verwende ich den Fehler-Wrapper von Golang?
Jun 03, 2024 pm 04:08 PM
In Golang können Sie mit Fehler-Wrappern neue Fehler erstellen, indem Sie Kontextinformationen an den ursprünglichen Fehler anhängen. Dies kann verwendet werden, um die von verschiedenen Bibliotheken oder Komponenten ausgelösten Fehlertypen zu vereinheitlichen und so das Debuggen und die Fehlerbehandlung zu vereinfachen. Die Schritte lauten wie folgt: Verwenden Sie die Funktion „errors.Wrap“, um die ursprünglichen Fehler in neue Fehler umzuwandeln. Der neue Fehler enthält Kontextinformationen zum ursprünglichen Fehler. Verwenden Sie fmt.Printf, um umschlossene Fehler auszugeben und so mehr Kontext und Umsetzbarkeit bereitzustellen. Wenn Sie verschiedene Fehlertypen behandeln, verwenden Sie die Funktion „errors.Wrap“, um die Fehlertypen zu vereinheitlichen.
 Eine Anleitung zum Unit-Testen gleichzeitiger Go-Funktionen
May 03, 2024 am 10:54 AM
Eine Anleitung zum Unit-Testen gleichzeitiger Go-Funktionen
May 03, 2024 am 10:54 AM
Das Testen gleichzeitiger Funktionen in Einheiten ist von entscheidender Bedeutung, da dies dazu beiträgt, ihr korrektes Verhalten in einer gleichzeitigen Umgebung sicherzustellen. Beim Testen gleichzeitiger Funktionen müssen grundlegende Prinzipien wie gegenseitiger Ausschluss, Synchronisation und Isolation berücksichtigt werden. Gleichzeitige Funktionen können Unit-Tests unterzogen werden, indem Rennbedingungen simuliert, getestet und Ergebnisse überprüft werden.
