
 Technologie-Peripheriegeräte
KI
Google führt multimodales Vid2Seq ein, um den Video-IQ online zu verstehen, Untertitel werden nicht offline sein CVPR 2023
Technologie-Peripheriegeräte
KI
Google führt multimodales Vid2Seq ein, um den Video-IQ online zu verstehen, Untertitel werden nicht offline sein CVPR 2023
Google führt multimodales Vid2Seq ein, um den Video-IQ online zu verstehen, Untertitel werden nicht offline sein CVPR 2023

Chinesische Ärzte und Google-Wissenschaftler haben kürzlich das vorab trainierte visuelle Sprachmodell Vid2Seq vorgeschlagen, das mehrere Ereignisse in einem Video unterscheiden und beschreiben kann. Dieses Papier wurde vom CVPR 2023 angenommen.
Kürzlich haben Forscher von Google ein vorab trainiertes visuelles Sprachmodell zur Beschreibung von Videos mit mehreren Ereignissen vorgeschlagen – Vid2Seq, das von CVPR23 akzeptiert wurde.
Früher war das Verstehen von Videoinhalten eine herausfordernde Aufgabe, da Videos oft mehrere Ereignisse enthielten, die in unterschiedlichen Zeitskalen stattfanden.
Zum Beispiel umfasst ein Video, in dem ein Musher einen Hund an einen Schlitten bindet und der Hund dann zu rennen beginnt, einen langen Vorgang (die Hundeschlittenfahrt) und einen kurzen Vorgang (der Hund ist an den Schlitten angebunden).
Eine Möglichkeit, die Forschung zum Videoverständnis voranzutreiben, ist die Aufgabe der dichten Videoannotation, bei der alle Ereignisse in einem einminütigen Video zeitlich lokalisiert und beschrieben werden.

Papieradresse: https://arxiv.org/abs/2302.14115
Die Vid2Seq-Architektur erweitert das Sprachmodell mit speziellen Zeitstempeln und ermöglicht so die nahtlose Vorhersage von Ereignisgrenzen und Textbeschreibungen in derselben Ausgabesequenz.
Um dieses einheitliche Modell vorab zu trainieren, nutzten die Forscher unbeschriftete Erzählvideos, indem sie die Satzgrenzen der transkribierten Sprache in Pseudo-Ereignis-Grenzen umformulierten und die transkribierten Sprachsätze als Pseudo-Ereignis-Anmerkungen verwendeten.

Übersicht über das Vid2Seq-Modell
Das resultierende Vid2Seq-Modell ist auf Millionen von kommentierten Videos vorab trainiert und verbessert so den Stand der Technik bei verschiedenen Benchmarks für dichte Videoanmerkungen, darunter YouCook2, ViTT und ActivityNet Captions.
Vid2Seq eignet sich auch gut für Videoanmerkungseinstellungen mit wenigen Aufnahmen, Videosegmentanmerkungsaufgaben und Standard-Videoanmerkungsaufgaben.

Visuelles Sprachmodell für dichte Videoanmerkungen
Die multimodale Transformer-Architektur hat die SOTA verschiedener Videoaufgaben, wie z. B. Aktionserkennung, aktualisiert. Die Anpassung einer solchen Architektur an die komplexe Aufgabe, Ereignisse in minutenlangen Videos gemeinsam zu lokalisieren und zu kommentieren, ist jedoch nicht einfach.
Um dieses Ziel zu erreichen, erweitern Forscher das visuelle Sprachmodell mit speziellen Zeitmarkierungen (z. B. Textmarkierungen), die diskrete Zeitstempel im Video darstellen, ähnlich wie Pix2Seq im räumlichen Bereich.
Für eine gegebene visuelle Eingabe kann das resultierende Vid2Seq-Modell sowohl die Eingabe akzeptieren als auch Text und zeitgetaggte Sequenzen generieren.
Erstens ermöglicht dies dem Vid2Seq-Modell, die zeitlichen Informationen der transkribierten Spracheingabe zu verstehen, die als einzelne Sequenz von Token projiziert wird. Zweitens ermöglicht dies Vid2Seq, gemeinsam zeitlich dichte Ereignisanmerkungen innerhalb des Videos vorherzusagen und gleichzeitig eine einzelne Sequenz von Markierungen zu generieren.
Die Vid2Seq-Architektur umfasst einen visuellen Encoder und einen Text-Encoder, die Videobilder bzw. transkribierte Spracheingaben kodieren. Die resultierenden Kodierungen werden dann an einen Textdecoder weitergeleitet, der automatisch die Ausgabesequenz dichter Ereignisanmerkungen sowie deren zeitliche Positionierung im Video vorhersagt. Die Architektur wird mit einem starken visuellen Rückgrat und einem starken Sprachmodell initialisiert.

Umfangreiche Vorschulung zu Videos
Das manuelle Sammeln von Anmerkungen für eine dichte Videoanmerkung ist aufgrund des intensiven Charakters der Aufgabe besonders kostspielig.
Daher trainierten die Forscher das Vid2Seq-Modell vorab mit unbeschrifteten Erzählvideos, die in großem Maßstab leicht verfügbar sind. Sie verwendeten auch den YT-Temporal-1B-Datensatz, der 18 Millionen kommentierte Videos aus einem breiten Spektrum von Bereichen umfasst.
Zur Überwachung nutzen die Forscher transkribierte Sprachsätze und ihre entsprechenden Zeitstempel, die als einzelne Token-Sequenz projiziert werden.
Vid2Seq wird dann mit einem generativen Ziel vorab trainiert, das dem Decoder beibringt, bei visueller Eingabe nur transkribierte Sprachsequenzen vorherzusagen, und einem Entrauschungsziel, das multimodales Lernen fördert und erfordert, dass das Modell verrauschte transkribierte Sprache vorhersagt und Masken im Kontext vorhersagt von Reihenfolge und visuellem Input. Insbesondere wird der Sprachsequenz durch zufälliges Maskieren von Span-Tokens Rauschen hinzugefügt.

Benchmark-Ergebnisse für Downstream-Aufgaben
Das resultierende vorab trainierte Vid2Seq-Modell kann über ein einfaches Maximum-Likelihood-Ziel, das Lehrerzwang nutzt, auf Downstream-Aufgaben verfeinert werden (d. h. unter Berücksichtigung des vorherigen Ground-Truth-Tokens wird das nächste Token vorhergesagt).
Nach der Feinabstimmung übertrifft Vid2Seq SOTA bei drei Standard-Downstream-Benchmarks für dichte Videoanmerkungen (ActivityNet Captions, YouCook2 und ViTT) und zwei Videoclip-Annotationsbenchmarks (MSR-VTT, MSVD).
In der Arbeit gibt es zusätzliche Ablationsstudien, qualitative Ergebnisse und Ergebnisse in der Einstellung mit wenigen Aufnahmen und Anmerkungsaufgaben für Videoabsätze.
Qualitative Tests
Die Ergebnisse zeigen, dass Vid2Seq aussagekräftige Ereignisgrenzen und -anmerkungen vorhersagen kann und dass sich die vorhergesagten Anmerkungen und Grenzen erheblich von der transkribierten Spracheingabe unterscheiden (dies zeigt auch die Bedeutung visueller Markierungen in der Eingabe).

Das nächste Beispiel handelt von einer Reihe von Anweisungen in einem Kochrezept. Es ist ein Beispiel für die Vorhersage dichter Ereignisanmerkungen von Vid2Seq auf dem YouCook2-Validierungssatz:

Das nächste Beispiel ist die dichte Ereignisanmerkung von Vid2Seq Validierungssatz für ActivityNet-Untertitel. Vorhersagebeispiele. In all diesen Videos gibt es keine transkribierte Sprache.
Es wird jedoch immer noch Fälle von Fehlern geben, wie zum Beispiel das unten rot markierte Bild, in dem Vid2Seq besagt, dass es sich um eine Person handelt, die vor der Kamera ihren Hut abnimmt.
Benchmarking SOTA
Tabelle 5 vergleicht Vid2Seq mit den fortschrittlichsten dichten Videoannotationsmethoden: Vid2Seq aktualisiert SOTA für drei Datensätze: YouCook2, ViTT und ActivityNet Captions.

Vid2Seqs SODA-Indikatoren auf YouCook2 und ActivityNet Captions sind 3,5 bzw. 0,3 Punkte höher als PDVC und UEDVC. Und E2ESG verwendet domäneninternes Klartext-Vortraining auf Wikihow, und Vid2Seq ist besser als diese Methode. Diese Ergebnisse zeigen, dass das vorab trainierte Vid2Seq-Modell über eine starke Fähigkeit verfügt, dichte Ereignisse zu kennzeichnen.
Tabelle 6 bewertet die Ereignislokalisierungsleistung des dichten Videoannotationsmodells. Im Vergleich zu YouCook2 und ViTT ist Vid2Seq besser darin, dichte Videoanmerkungen als einzelne Sequenzgenerierungsaufgabe zu verarbeiten.

Allerdings schneidet Vid2Seq bei ActivityNet-Untertiteln im Vergleich zu PDVC und UEDVC nicht gut ab. Im Vergleich zu diesen beiden Methoden beinhaltet Vid2Seq weniger Vorwissen über die zeitliche Lokalisierung, während die anderen beiden Methoden aufgabenspezifische Komponenten wie Ereigniszähler umfassen oder ein Modell separat für die Teilaufgabe der Lokalisierung trainieren. Details zur Implementierung
Die Sequenzen des Text-Encoders und -Decoders werden während des Vortrainings auf L=S=1000 Token und während der Feinabstimmung auf S=1000 und L=256 Token gekürzt oder aufgefüllt. Während der Inferenz wird die Beam-Search-Dekodierung verwendet, die ersten 4 Sequenzen werden verfolgt und eine Längennormalisierung von 0,6 wird angewendet.
- Training
Der Autor verwendet den Adam-Optimierer, β=(0,9, 0,999), ohne Gewichtsabnahme.
Während des Vortrainings wird eine Lernrate von 1e^-4 verwendet, in den ersten 1000 Iterationen linear aufgewärmt (beginnend bei 0) und in den verbleibenden Iterationen konstant gehalten.
- Verwenden Sie während der Feinabstimmung eine Lernrate von 3e^-4, eine lineare Aufwärmphase (beginnend bei 0) in den ersten 10 % der Iterationen und die Beibehaltung des Kosinusabfalls (bis auf 0) in den verbleibenden 90 % der Iterationen. Dabei wird eine Batchgröße von 32 Videos verwendet und auf 16 TPU v4-Chips aufgeteilt.
- Der Autor hat 40 Epochenanpassungen an YouCook2, 20 Epochenanpassungen an ActivityNet Captions und ViTT, 5 Epochenanpassungen an MSR-VTT und 10 Epochenanpassungen an MSVD vorgenommen.
Fazit
Vid2Seq ist ein neues visuelles Sprachmodell für dichte Videoanmerkungen. Es kann effektiv ein umfangreiches Vortraining für unbeschriftete Erzählvideos durchführen und verschiedene nachgelagerte dichte Videoanmerkungen für den Benchmark durchführen.
Vorstellung des Autors
Erster Autor des Artikels: Antoine Yang
Antoine Yang ist Doktorand im dritten Jahr im WILLOW-Team von Inria und der École Normale Supérieure in Paris. Seine Betreuer sind Antoine Miech, Josef Sivic, Ivan Laptev und Cordelia Schmid.
Aktuelle Forschung konzentriert sich auf das Erlernen visueller Sprachmodelle für das Videoverständnis. Er absolvierte 2019 ein Praktikum im Noah's Ark Laboratory von Huawei, erhielt einen Ingenieurabschluss von der Ecole Polytechnique in Paris und einen Master-Abschluss in Mathematik, Vision und Lernen von der Nationalen Universität Paris-Saclay im Jahr 2020 und absolvierte 2022 ein Praktikum bei Google Research.
Das obige ist der detaillierte Inhalt vonGoogle führt multimodales Vid2Seq ein, um den Video-IQ online zu verstehen, Untertitel werden nicht offline sein CVPR 2023. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 So entfernen Sie unerwünschte Anzeigesprachen unter Windows 11 vollständig
Sep 24, 2023 pm 04:25 PM
So entfernen Sie unerwünschte Anzeigesprachen unter Windows 11 vollständig
Sep 24, 2023 pm 04:25 PM
Arbeiten Sie zu lange am gleichen Setup oder teilen Sie Ihren PC mit anderen. Möglicherweise sind einige Sprachpakete installiert, die häufig zu Konflikten führen. Es ist also an der Zeit, unerwünschte Anzeigesprachen in Windows 11 zu entfernen. Apropos Konflikte: Wenn mehrere Sprachpakete vorhanden sind, ändert sich durch versehentliches Drücken von Strg+Umschalt das Tastaturlayout. Wenn dies nicht beachtet wird, kann dies ein Hindernis für die anstehende Aufgabe sein. Also, fangen wir gleich mit der Methode an! Wie entferne ich die Anzeigesprache von Windows 11? 1. Drücken Sie in den Einstellungen +, um die Einstellungen-App zu öffnen, gehen Sie im Navigationsbereich zu Zeit & Sprache und klicken Sie auf Sprache & Region. Windows: Ich klicke auf die Auslassungspunkte neben der Anzeigesprache, die Sie entfernen möchten, und wähle im Popup-Menü die Option „Entfernen“ aus. Klicken Sie auf „
 3 Möglichkeiten, die Sprache auf dem iPhone zu ändern
Feb 02, 2024 pm 04:12 PM
3 Möglichkeiten, die Sprache auf dem iPhone zu ändern
Feb 02, 2024 pm 04:12 PM
Es ist kein Geheimnis, dass das iPhone eines der benutzerfreundlichsten elektronischen Geräte ist, und einer der Gründe dafür ist, dass es ganz einfach nach Ihren Wünschen personalisiert werden kann. In der Personalisierung können Sie die Sprache auf eine andere Sprache ändern als die, die Sie beim Einrichten Ihres iPhones ausgewählt haben. Wenn Sie mit mehreren Sprachen vertraut sind oder die Spracheinstellung Ihres iPhones falsch ist, können Sie sie wie unten erläutert ändern. So ändern Sie die Sprache des iPhone [3 Methoden] iOS ermöglicht Benutzern, die bevorzugte Sprache auf dem iPhone frei zu wechseln, um sie an unterschiedliche Bedürfnisse anzupassen. Sie können die Sprache der Interaktion mit Siri ändern, um die Kommunikation mit dem Sprachassistenten zu erleichtern. Gleichzeitig können Sie bei Verwendung der lokalen Tastatur problemlos zwischen mehreren Sprachen wechseln, um die Eingabeeffizienz zu verbessern.
 Die DAMO Academy erweitert große Sprachmodelle um umfassende audiovisuelle Funktionen und ist Open-Source-Video-LLaMA
Jun 09, 2023 pm 09:28 PM
Die DAMO Academy erweitert große Sprachmodelle um umfassende audiovisuelle Funktionen und ist Open-Source-Video-LLaMA
Jun 09, 2023 pm 09:28 PM
Videos spielen in der heutigen Social-Media- und Internetkultur eine immer wichtigere Rolle. Douyin, Kuaishou, Bilibili usw. sind zu beliebten Plattformen für Hunderte Millionen Nutzer geworden. Benutzer teilen ihre Lebensmomente, kreativen Arbeiten, interessanten Momente und andere Inhalte rund um Videos, um mit anderen zu interagieren und zu kommunizieren. In jüngster Zeit haben große Sprachmodelle beeindruckende Fähigkeiten unter Beweis gestellt. Können wir große Models mit „Augen“ und „Ohren“ ausstatten, damit sie Videos verstehen und mit Nutzern interagieren können? Ausgehend von diesem Problem schlugen Forscher der DAMO Academy Video-LLaMA vor, ein großes Modell mit umfassenden audiovisuellen Fähigkeiten. Video-LLaMA kann die Video- und Audiosignale im Video wahrnehmen und verstehen und die vom Benutzer eingegebenen Anweisungen verstehen, um eine Reihe komplexer Aufgaben auf der Grundlage von Audio und Video auszuführen.
 Wie stelle ich die Sprache des Win10-Computers auf Chinesisch ein?
Jan 05, 2024 pm 06:51 PM
Wie stelle ich die Sprache des Win10-Computers auf Chinesisch ein?
Jan 05, 2024 pm 06:51 PM
Manchmal installieren wir einfach das Computersystem und stellen fest, dass das System auf Englisch ist. In diesem Fall müssen wir die Computersprache im Win10-System auf Chinesisch ändern . So ändern Sie die Computersprache in Win10 auf Chinesisch 1. Schalten Sie den Computer ein und klicken Sie auf die Startschaltfläche in der unteren linken Ecke. 2. Klicken Sie links auf die Einstellungsoption. 3. Wählen Sie auf der sich öffnenden Seite „Zeit und Sprache“. 4. Klicken Sie nach dem Öffnen links auf „Sprache“. 5. Hier können Sie die gewünschte Computersprache einstellen.
 Was für ein Lärm! Versteht ChatGPT die Sprache? PNAS: Lassen Sie uns zunächst untersuchen, was „Verstehen' ist
Apr 07, 2023 pm 06:21 PM
Was für ein Lärm! Versteht ChatGPT die Sprache? PNAS: Lassen Sie uns zunächst untersuchen, was „Verstehen' ist
Apr 07, 2023 pm 06:21 PM
Die Frage, ob eine Maschine darüber nachdenken kann, ist wie die Frage, ob ein U-Boot schwimmen kann. ——Dijkstra Schon vor der Veröffentlichung von ChatGPT hatte die Branche die Veränderungen gerochen, die große Modelle mit sich brachten. Am 14. Oktober letzten Jahres veröffentlichten die Professoren Melanie Mitchell und David C. Krakauer vom Santa Fe Institute eine Rezension zu arXiv, in der sie umfassend alle Aspekte untersuchten, „ob groß angelegte vorab trainierte Sprachmodelle Sprache verstehen können“, heißt es in dem Artikel beschreibt die „Pro“- und „Contra“-Argumente sowie die aus diesen Argumenten abgeleiteten Schlüsselthemen in der breiteren Intelligenzwissenschaft. Papierlink: https://arxiv.o
 Fix: Alt + Umschalt ändert die Sprache unter Windows 11 nicht
Oct 11, 2023 pm 02:17 PM
Fix: Alt + Umschalt ändert die Sprache unter Windows 11 nicht
Oct 11, 2023 pm 02:17 PM
Während Alt+Umschalt die Sprache unter Windows 11 nicht ändert, können Sie Win+Leertaste verwenden, um den gleichen Effekt zu erzielen. Stellen Sie außerdem sicher, dass Sie die linke Alt+Umschalttaste und nicht die auf der rechten Seite der Tastatur verwenden. Warum kann Alt+Shift die Sprache nicht ändern? Sie haben keine weiteren Sprachen zur Auswahl. Die Hotkeys für die Eingabesprache wurden geändert. Ein Fehler im neuesten Windows-Update verhindert, dass Sie die Sprache Ihrer Tastatur ändern können. Deinstallieren Sie die neuesten Updates, um dieses Problem zu beheben. Sie befinden sich im aktiven Fenster einer Anwendung, die dieselben Hotkeys zum Ausführen anderer Aktionen verwendet. Wie ändert man mit AltShift die Sprache unter Windows 11? 1. Verwenden Sie die richtige Tastenfolge. Stellen Sie zunächst sicher, dass Sie die richtige Methode zur Verwendung der +-Kombination verwenden.
 Sie können spielen, indem Sie einfach Ihren Mund bewegen! Benutze KI, um Charaktere zu wechseln und Feinde anzugreifen: „Ayaka, benutze Kamiri-ryu Frost Destruction.'
May 13, 2023 pm 07:52 PM
Sie können spielen, indem Sie einfach Ihren Mund bewegen! Benutze KI, um Charaktere zu wechseln und Feinde anzugreifen: „Ayaka, benutze Kamiri-ryu Frost Destruction.'
May 13, 2023 pm 07:52 PM
Wenn es um heimische Spiele geht, die in den letzten zwei Jahren auf der ganzen Welt populär geworden sind, hat Genshin Impact definitiv die Nase vorn. Laut der im Mai veröffentlichten Umsatzumfrage für Mobilspiele im ersten Quartal dieses Jahres belegte „Genshin Impact“ mit einem absoluten Vorsprung von 567 Millionen US-Dollar den ersten Platz In nur 18 Jahren war das Unternehmen online. Der Gesamtumsatz allein mit der mobilen Plattform überstieg 3 Milliarden US-Dollar (ca. 13 Milliarden RM). Nun ist die letzte Inselversion 2.8 vor der Eröffnung von Xumi längst überfällig. Nach einer langen Entwurfszeit gibt es endlich neue Handlungsstränge und Gebiete zum Spielen. Aber ich weiß nicht, wie viele „Leberkaiser“ es gibt. Jetzt, wo die Insel vollständig erkundet ist, beginnt wieder Gras zu wachsen. Es gibt insgesamt 182 Schatztruhen + 1 Mora-Box (nicht im Lieferumfang enthalten). Es besteht kein Grund zur Sorge, dass es im Genshin Impact-Bereich nie an Arbeit mangelt. Nein, während des hohen Grases
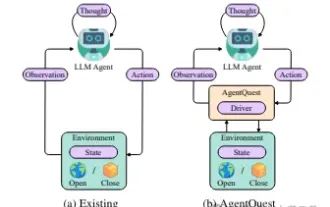 Erkundung der Grenzen von Agenten: AgentQuest, ein modulares Benchmark-Framework zur umfassenden Messung und Verbesserung der Leistung großer Sprachmodellagenten
Apr 11, 2024 pm 08:52 PM
Erkundung der Grenzen von Agenten: AgentQuest, ein modulares Benchmark-Framework zur umfassenden Messung und Verbesserung der Leistung großer Sprachmodellagenten
Apr 11, 2024 pm 08:52 PM
Basierend auf der kontinuierlichen Optimierung großer Modelle haben LLM-Agenten – diese leistungsstarken algorithmischen Einheiten – das Potenzial gezeigt, komplexe mehrstufige Argumentationsaufgaben zu lösen. Von der Verarbeitung natürlicher Sprache bis hin zum Deep Learning rücken LLM-Agenten nach und nach in den Fokus von Forschung und Industrie. Sie können nicht nur menschliche Sprache verstehen und generieren, sondern auch Strategien formulieren, Aufgaben in verschiedenen Umgebungen ausführen und sogar API-Aufrufe und Codierung zum Erstellen verwenden Lösungen. In diesem Zusammenhang ist die Einführung des AgentQuest-Frameworks ein Meilenstein. Es bietet nicht nur eine modulare Benchmarking-Plattform für die Bewertung und Weiterentwicklung von LLM-Agenten, sondern bietet Forschern auch leistungsstarke Tools, um die Leistung dieser Agenten gleichzeitig zu verfolgen und zu verbessern granularerer Ebene
