
 Technologie-Peripheriegeräte
KI
Erweitern Sie Ihr Wissen! Maschinelles Lernen mit logischen Regeln
Technologie-Peripheriegeräte
KI
Erweitern Sie Ihr Wissen! Maschinelles Lernen mit logischen Regeln
Erweitern Sie Ihr Wissen! Maschinelles Lernen mit logischen Regeln

Auf der Precision-Recall-Kurve werden dieselben Punkte mit unterschiedlichen Achsen aufgetragen. Warnung: Der erste rote Punkt links (0 % Rückruf, 100 % Präzision) entspricht 0 Regeln. Der zweite Punkt links ist die erste Regel und so weiter.
Skope-rules verwendet ein Baummodell, um Regelkandidaten zu generieren. Erstellen Sie zunächst einige Entscheidungsbäume und betrachten Sie die Pfade vom Wurzelknoten zu internen Knoten oder Blattknoten als Regelkandidaten. Diese Kandidatenregeln werden dann nach einigen vordefinierten Kriterien wie Präzision und Rückruf gefiltert. Nur diejenigen, deren Präzision und Erinnerung über ihren Schwellenwerten liegen, werden beibehalten. Abschließend wird eine Ähnlichkeitsfilterung angewendet, um Regeln mit ausreichender Diversität auszuwählen. Im Allgemeinen werden Skope-Regeln angewendet, um die zugrunde liegenden Regeln für jede Grundursache zu lernen.

Projektadresse: https://github.com/scikit-learn-contrib/skope-rules
- Skope-rules ist ein Python-Modul für maschinelles Lernen, das auf scikit-learn basiert und unter 3-Klausel-BSD veröffentlicht wird Erlaubnis.
- Skope-rules zielt darauf ab, logische, interpretierbare Regeln zum „Definieren“ der Zielkategorie zu lernen, d. h. Instanzen dieser Kategorie mit hoher Genauigkeit zu erkennen.
- Skope-Regeln sind ein Kompromiss zwischen der Interpretierbarkeit von Entscheidungsbäumen und den Modellierungsfähigkeiten von Zufallswäldern.

schema
Installation
Sie können pip verwenden, um die neuesten Ressourcen zu erhalten:
pip install skope-rules
Quick Start
SkopeRules können verwendet werden, um Klassen mit logischen Regeln zu beschreiben:
from. sklear n .datasets import load_iri s UFrom Skrules Import Skoperules
dataset = load_iris ()
feature_names = ['SEPAL_LENGTH', 'SEPAL_WIDTH', 'Petal_length'] KClf = Skoperules (MAX_DEPTH_DUPLICATINOTALOW = 2,
n_estimators = 30,
precision_min = 0,3 ,
call_min=0,1,
feature_names=feature_names)
für idx, Arten in enumerate(dataset.target_names):
X, y = dataset.data, dataset.target
clf.fit(X, y == idx)
Regeln = clf.rules_[0:3]
print("Regeln für Iris", Art)
für Regel in Regeln:
print(rule)
print()
print(20*'=')
print()
 Hinweis:
Hinweis:
Wenn der folgende Fehler auftritt:
 Lösung:
Lösung:
Informationen zum Python-Importfehler: Der Name „six“ kann nicht aus „sklearn.externals“ importiert werden. Yun Duojun hat einen ähnlichen Fehler bei „Stack Overflow Question“ gefunden : https://stackoverflow.com/questions/61867945/
Die Lösung ist wie folgt
import six
import syssys.modules['sklearn.externals.six'] = six
import mlrose
Persönlicher Test ist gültig !
SkopeRules können auch als Prädiktoren verwendet werden, wenn die Methode „score_top_rules“ verwendet wird:
aus sklearn.datasets import load_boston
aus sklearn.metrics import precision_recall_curveaus matplotlib import pyplot as plt
aus skrules import SkopeRules
dataset = _boston( )
clf = skoperules (max_depth_duplicatinotallow = none,
n_estimators = 30,
precision_min = 0,2,
usw. min = 0,01,
feature_names = dataset.feature_names)
x, y = dataset.data, dataSet.target & gt; , y_train = X[:len(y)//2], y[:len(y)//2]
X_test, y_test = X[len(y)//2:], y[len(y)/ /2:]
clf.fit(X_train, y_train)
y_score = clf.score_top_rules(X_test) # Erhalten Sie eine Risikobewertung für jedes Testbeispiel
precision, Recall, _ = precision_recall_curve(y_test, y_score)
plt.plot(recall , Präzision)
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision Recall Curve')
plt.show()

- Lösen Sie das Problem der binären Klassifizierung.
- Extrahieren Sie interpretierbare Entscheidungsregeln.
Dieser Fall ist in 5 Teile unterteilt Erläuterung der „Überlebensregeln“ (mithilfe von SkopeRules().rules_property).
- Leistungsanalyse (mit der Methode SkopeRules.predict_top_rules()). 🔜 geteilt
- vom sklearn.tree-Import DecisionTreeClassifier matplotlib.pyplot als plt importieren
- aus sklearn.metrics importieren roc_curve, precision_recall_curve aus matplotlib importieren cm
- numpy als np importieren aus sklearn.metrics importieren confusion_matrix
- aus IPython.display import display
- # Titanic-Daten importieren Daten = pd.read_csv('../data/titanic-train.csv')
Datenvorbereitung
# Zeilen mit fehlendem Alter löschen
data = data.query('Age == Age')
# Codierung für Variable Sex erstellen Wert
data['isFemale'] = (data['Sex'] == 'female') * 1
# Unvaried Embarked erstellt codierten Wert
data = pd.concat(
[data,
pd.get_dummies(data. loc [:,'Embarked'],
dummy_na=False,
prefix='Embarked',
prefix_sep='_')],
axis=1
)
# Nicht verwendete Variablen löschen
data = data.drop( ['Name ', 'Ticket', 'Cabin',
'PassengerId', 'Sex', 'Embarked'],
axis = 1)# Trainings- und Testsätze erstellen
X_train, X_test, y_train, y_test = train_test_split(
data. drop(['Survived'], axis=1),data['Survived'],
test_size=0.25, random_state=42)
feature_names = X_train.columns
print('Spaltennamen sind: ' + ' '. join(feature_names.tolist())+'.')
print('Form des Trainingssatzes ist: ' + str(X_train.shape) + '.')
Spaltennamen sind: Pclass Age SibSp Parch Fare
isFemale Embarked_C Embarked_Q Embarked_S.
Die Form des Trainingssatzes ist: (535, 9).
Modelltraining
# Trainieren Sie einen Gradienten-Boosting-Klassifikator für Benchmark-Tests .fit(X_train, y_train)
# Trainiere einen zufälligen Waldklassifizierer für das Benchmarking
random_forest_clf = RandomForestClassifier(random_state=42, n_estimators=30, max_ Depth = 5)
random_forest_clf.fit(X_train , y_train)
# Trainiere einen Entscheidungsbaum Klassifikator für Benchmarking
decision_tree_clf = DecisionTreeClassifier(random_state=42, max_third = 5)
decision_tree_clf.fit(X_train, y_train)
# Trainieren Sie eine Skope-Regeln-verstärkende Klassifizierung
skope_rules_clf = SkopeRules(feature_names=feature_names, random_state= 42, n_schätzer =30,
call_min=0,05, precision_min=0,9,max_samples=0,7,
max_ Depth_duplicatinotallow= 4, max_ Depth = 5)
skope_rules_clf.fit(X _train, y_train)
# Vorhersage berechnen. Punktzahl
gradient_boost_scoring = gradient_boost_clf.predict_proba( X_test)[:, 1]random_forest_scoring = random_forest_clf.predict_proba (X_test)[:, 1] n")
# Drucken diese Regeln
rules_explanations = [
"Weiblich unter 3 Jahren und unter 37 Jahren in der ersten oder zweiten Klasse. „
“Frauen ab 3 Jahren reisen in der ersten oder zweiten Klasse und zahlen mehr als 26 Euro. „
„Frau, die in der ersten oder zweiten Klasse reist und mehr als 29 Euro bezahlt.“ „
„Frau, die über 39 Jahre alt ist und in der ersten oder zweiten Klasse reist. "
]
print('Die vier leistungsstärksten „Titanic-Überlebensregeln“ lauten wie folgt:/n')
für i_rule, Regel in enumerate(skope_rules_clf.rules_[:4])
print(rule[ 0])
print('->'+rules_explanations[i_rule]+ 'n')
Mit SkopeRules 9 Regeln erstellen
Die besten 4 „Titanic Survival Rules“ sind wie folgt:
Alter und P-Klasse > 0,5-> Frauen unter 3 Jahren und unter 37 Jahren
Alter > ;= 2,5 und isFemale > 0,5
-> Frauen über 3 Jahre, die in der ersten oder zweiten Klasse reisen und mehr als 26 Euro bezahlen.
Tarif > 29,356250762939453
und Pclass 0,5
-> Frauen, die mehr als 29 Euro für die erste oder zweite Klasse bezahlen.
Alter > 38,5 und Klasse und weiblich > 0,5
->
def compute_y_pred_from_query(X, Regel):
score = np.zeros(X.shape[0])
X = X.reset_index(drop=True)
score[list(X.query(rule).index)] = 1
return(score)
def compute_performances_from_y_pred(y_true, y_pred, index_name='default_index'):
df = pd.DataFrame(data=
{
'precision':[sum(y_true * y_pred)/sum(y_pred )],
'recall':[sum(y_true * y_pred)/sum(y_true)]
},
index=[index_name],
columns=['precision', 'recall']
)
return(df) ?? _performances_from_y_pred( y_test, y_test_pred, 'test_set')],
axis=0)
return(performances)
print('Präzision = 0,96 bedeutet, dass 96 % der durch die Regel identifizierten Personen Überlebende sind.')
print(' Recall = 0,12 bedeutet, dass die durch die Regel identifizierten Überlebenden 12 % der gesamten Überlebenden ausmachen.')
für i in range(4):
print('Rule '+str(i+1)+':')
display(compute_train_test_query_performances(X_train, y_train,
X_test, y_test,
skope_rules_clf.rules_[i][ 0])
)
Precision = 0,96 bedeutet, dass 96 % der durch die Regeln bestimmten Personen Überlebende sind.
Recall = 0,12 bedeutet, dass die durch die Regel identifizierten Überlebenden 12 % der Gesamtüberlebenden ausmachen. Modellleistungstests 'skope-rules']):
gradient = np.linspace(0, 1, 10)
color_list = [ cm.tab10(x) für x im Farbverlauf ]
fig, axis = plt.subplots(1, 2, figsize=(12, 5),
sharex=True, sharey=True)
ax = axis[0]
n_line = 0
für i_score, Score in enumerate(scores_with_line):
n_line = n_line + 1
fpr, tpr, _ = roc_curve(y_true, Score)
ax.plot(fpr, tpr, linestyle='-.', c=color_list[i_score], lw=1, label=labels_with_line[i_score])für i_score, Score in enumerate( scores_with_points):
fpr, tpr, _ = roc_curve(y_true, score)
ax.scatter(fpr[:-1], tpr[:-1], c=color_list[n_line + i_score], s=10, label= labels_with_points[i_score])ax.set_title("ROC", fnotallow=20)
ax.set_ylabel('True-Positiv-Rate (Rückruf)', fnotallow=18 ) ax.legend(loc='lower center', fnotallow=8)
ax.legend(loc='lower center', fnotallow=8)
ax = axis[1]
n_line = 0für i_score, Punkte in enumerate(scores_with_line):
n_line = n_line + 1
precision, Recall , _ = precision_recall_curve(y_true, score)
ax.step(recall, precision, linestyle='-.', c=color_list[i_score], lw=1, where='post', label=labels_with_line[i_score])
für i_score, Punktzahl in enumerate(scores_with_points):
precision, Recall, _ = precision_recall_curve(y_true, score)
ax.scatter(recall, precision, c=color_list[n_line + i_score], s=10, label=labels_with_points[i_score ])
ax.set_title("Precision-Recall", fnotallow=20)
ax.set_xlabel('Recall (True Positive Rate)', fnotallow=18)
ax.set_ylabel('Precision', fnotallow=18)
ax .legend(loc='lower center', fnotallow=8)
plt.show()
plot_titanic_scores(y_test,
scores_with_line=[gradient_boost_scoring, random_forest_scoring, Decision_tree_scoring],
scores_with_points=[skope_rules_scoring]
)
Auf der ROC-Kurve entspricht jeder rote Punkt der Anzahl der aktivierten Regeln (aus Skope-Regeln). Der niedrigste Punkt ist beispielsweise der Ergebnispunkt einer Regel (der besten). Der zweitniedrigste Punkt ist der 2-Regel-Ergebnispunkt und so weiter.
Auf der Precision-Recall-Kurve werden dieselben Punkte mit unterschiedlichen Koordinatenachsen aufgetragen. Warnung: Der erste rote Punkt links (0 % Rückruf, 100 % Präzision) entspricht 0 Regeln. Der zweite Punkt links ist die erste Regel und so weiter.
Aus diesem Beispiel lassen sich einige Schlussfolgerungen ziehen.
- Skope-Regeln sind leistungsfähiger als Entscheidungsbäume.
- skope-rules funktionieren ähnlich wie Random Forest/Gradient Boosting (in diesem Beispiel).
- Durch die Verwendung von 4 Regeln kann eine sehr gute Leistung erzielt werden (61 % Rückruf, 94 % Präzision) (in diesem Beispiel).
n_rule_chosen = 4
y_pred = skope_rules_clf.predict_top_rules(X_test, n_rule_chosen)
print('Die mit '+str(n_rule_chosen)+' ermittelten Regeln erreichten Leistungen sind die folgenden:')
compute_performances_from_y_pred (y_test, y_pred, ' test_set')

predict_top_rules(new_data, n_r) Methode wird verwendet, um die Vorhersage von new_data zu berechnen, die die ersten n_r Skope-Rules-Regeln enthält.
Das obige ist der detaillierte Inhalt vonErweitern Sie Ihr Wissen! Maschinelles Lernen mit logischen Regeln. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1379
1379
 52
52

 Erweitern Sie Ihr Wissen! Maschinelles Lernen mit logischen Regeln
Apr 01, 2023 pm 10:07 PM
Erweitern Sie Ihr Wissen! Maschinelles Lernen mit logischen Regeln
Apr 01, 2023 pm 10:07 PM
Auf der Precision-Recall-Kurve werden dieselben Punkte mit unterschiedlichen Achsen aufgetragen. Warnung: Der erste rote Punkt links (0 % Rückruf, 100 % Präzision) entspricht 0 Regeln. Der zweite Punkt links ist die erste Regel und so weiter. Skope-rules verwendet ein Baummodell, um Regelkandidaten zu generieren. Erstellen Sie zunächst einige Entscheidungsbäume und betrachten Sie die Pfade vom Wurzelknoten zu internen Knoten oder Blattknoten als Regelkandidaten. Diese Kandidatenregeln werden dann nach einigen vordefinierten Kriterien wie Präzision und Rückruf gefiltert. Nur diejenigen, deren Präzision und Erinnerung über ihren Schwellenwerten liegen, werden beibehalten. Abschließend wird eine Ähnlichkeitsfilterung angewendet, um Regeln mit ausreichender Diversität auszuwählen. Im Allgemeinen werden Skope-Regeln angewendet, um die Ursache jedes einzelnen Problems herauszufinden
 OpenOOD-Update v1.5: umfassende und genaue Bibliothek und Testplattform zur Erkennung von Out-of-Distribution-Codes, die Online-Rankings und One-Click-Tests unterstützt
Jul 03, 2023 pm 04:41 PM
OpenOOD-Update v1.5: umfassende und genaue Bibliothek und Testplattform zur Erkennung von Out-of-Distribution-Codes, die Online-Rankings und One-Click-Tests unterstützt
Jul 03, 2023 pm 04:41 PM
Die Out-of-Distribution (OOD)-Erkennung ist für den zuverlässigen Betrieb offener intelligenter Systeme von entscheidender Bedeutung, aktuelle objektorientierte Erkennungsmethoden leiden jedoch unter „Bewertungsinkonsistenzen“ (Bewertungsinkonsistenzen). Frühere Arbeiten OpenOODv1 vereinheitlichen die Auswertung der OOD-Erkennung, weisen jedoch immer noch Einschränkungen hinsichtlich Skalierbarkeit und Benutzerfreundlichkeit auf. Kürzlich hat das Entwicklungsteam erneut OpenOODv1.5 vorgeschlagen. Im Vergleich zur Vorgängerversion wurde die Bewertung der neuen OOD-Erkennungsmethode erheblich verbessert, um Genauigkeit, Standardisierung und Benutzerfreundlichkeit zu gewährleisten. Bildpapier: https://arxiv.org/abs/2306.09301OpenOODCodebase:htt
 Wie finde ich die Anzahl der von der Laufzeit in Java bereitgestellten Parameter?
Sep 23, 2023 pm 01:13 PM
Wie finde ich die Anzahl der von der Laufzeit in Java bereitgestellten Parameter?
Sep 23, 2023 pm 01:13 PM
In Java besteht eine Möglichkeit, Parameter zur Laufzeit zu übergeben, darin, die Befehlszeile oder das Terminal zu verwenden. Beim Abrufen dieser Werte für Befehlszeilenparameter müssen wir möglicherweise die Anzahl der vom Benutzer zur Laufzeit bereitgestellten Parameter ermitteln, was mithilfe des Längenattributs erreicht werden kann. Ziel dieses Artikels ist es, den Prozess des Übergebens und Abrufens einer vom Benutzer bereitgestellten Anzahl von Parametern mithilfe eines Beispielprogramms zu erläutern. Ermitteln Sie die Anzahl der vom Benutzer zur Laufzeit bereitgestellten Argumente. Bevor wir die Anzahl der Befehlszeilenargumente ermitteln, besteht unser erster Schritt darin, ein Programm zu erstellen, das dem Benutzer die Übergabe von Argumenten zur Laufzeit ermöglicht. String[]-Parameter Beim Schreiben von Java-Programmen stoßen wir häufig auf die Methode main(). Wenn die JVM diese Methode aufruft, beginnt die Ausführung der Java-Anwendung. Es wird mit einem Argument namens String[]args verwendet
 Linux-Befehl: So überprüfen Sie die Anzahl der Telnet-Prozesse
Mar 01, 2024 am 11:39 AM
Linux-Befehl: So überprüfen Sie die Anzahl der Telnet-Prozesse
Mar 01, 2024 am 11:39 AM
Linux-Befehle sind eines der unverzichtbaren Werkzeuge in der täglichen Arbeit von Systemadministratoren. Sie können uns bei der Erledigung verschiedener Systemverwaltungsaufgaben helfen. Bei Betriebs- und Wartungsarbeiten ist es manchmal notwendig, die Nummer eines bestimmten Prozesses im System zu überprüfen, um Probleme zu erkennen und rechtzeitig Anpassungen vorzunehmen. In diesem Artikel wird erläutert, wie Sie mithilfe von Linux-Befehlen die Anzahl der Telnet-Prozesse überprüfen. Lassen Sie uns gemeinsam lernen. In Linux-Systemen können wir den Befehl ps in Kombination mit dem Befehl grep verwenden, um die Anzahl der Telnet-Prozesse anzuzeigen. Zuerst müssen wir ein Terminal öffnen,
 Ermitteln Sie die Anzahl der Möglichkeiten, einen N-stufigen Baum mit C++ zu durchlaufen
Sep 04, 2023 pm 05:01 PM
Ermitteln Sie die Anzahl der Möglichkeiten, einen N-stufigen Baum mit C++ zu durchlaufen
Sep 04, 2023 pm 05:01 PM
Bei einem gegebenen N-ary-Baum besteht unsere Aufgabe darin, die Gesamtzahl der Möglichkeiten zum Durchqueren des Baums zu ermitteln, z. B. − Für den obigen Baum beträgt unsere Ausgabe 192. Für dieses Problem benötigen wir einige Kenntnisse der Kombinatorik. Bei diesem Problem müssen wir nun nur noch alle möglichen Kombinationen jedes Pfades prüfen und schon erhalten wir die Antwort. Methode zum Finden der Lösung Bei dieser Methode müssen wir lediglich einen Hierarchiedurchlauf durchführen, überprüfen, wie viele Kinder jeder Knoten hat, und ihn dann faktoriell mit der Antwort multiplizieren. Beispiel-C++-Code der oben genannten Methode #include<bits/stdc++.h>usingnamespacestd;structNode{//s
 Schreiben Sie mit C++ einen Code, um die Anzahl der Subarrays mit denselben Mindest- und Höchstwerten zu ermitteln
Aug 25, 2023 pm 11:33 PM
Schreiben Sie mit C++ einen Code, um die Anzahl der Subarrays mit denselben Mindest- und Höchstwerten zu ermitteln
Aug 25, 2023 pm 11:33 PM
In diesem Artikel werden wir C++ verwenden, um das Problem zu lösen, die Anzahl der Subarrays zu ermitteln, deren Maximal- und Minimalwert gleich sind. Das Folgende ist ein Beispiel für das Problem: −Input:array={2,3,6,6,2,4,4,4}Output:12Explanation:{2},{3},{6},{6}, {2 },{4},{4},{4},{6,6},{4,4},{4,4}und {4,4,4}sind die Teilarrays, die mit dem gleichen maximalen und minimalen Element gebildet werden können. Eingabe: array={3, 3, 1,5,
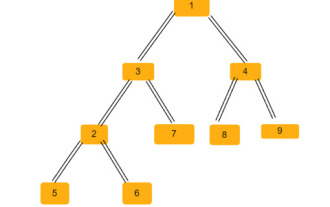 Die Anzahl gleichschenkliger Dreiecke in einem Binärbaum
Sep 05, 2023 am 09:41 AM
Die Anzahl gleichschenkliger Dreiecke in einem Binärbaum
Sep 05, 2023 am 09:41 AM
Ein Binärbaum ist eine Datenstruktur, in der jeder Knoten bis zu zwei untergeordnete Knoten haben kann. Diese Kinder werden linke Kinder bzw. rechte Kinder genannt. Angenommen, wir erhalten eine übergeordnete Array-Darstellung, Sie müssen diese verwenden, um einen Binärbaum zu erstellen. Ein Binärbaum kann mehrere gleichschenklige Dreiecke haben. Wir müssen die Gesamtzahl der möglichen gleichschenkligen Dreiecke in diesem Binärbaum ermitteln. In diesem Artikel werden wir verschiedene Techniken zur Lösung dieses Problems in C++ untersuchen. Wenn Sie das Problem verstehen, erhalten Sie ein übergeordnetes Array. Sie müssen es in Form eines Binärbaums darstellen, sodass der Array-Index den Wert des Baumknotens bildet und der Wert im Array den übergeordneten Knoten dieses bestimmten Index angibt. Beachten Sie, dass -1 immer das Root-Elternteil ist. Nachfolgend finden Sie ein Array und seine binäre Baumdarstellung. Parentarray=[0,-1,3,1,
 Schreiben Sie mit C++ einen Code, um die Anzahl der Unterarrays mit ungeraden Summen zu ermitteln
Sep 21, 2023 am 08:45 AM
Schreiben Sie mit C++ einen Code, um die Anzahl der Unterarrays mit ungeraden Summen zu ermitteln
Sep 21, 2023 am 08:45 AM
Ein Subarray ist ein zusammenhängender Teil eines Arrays. Betrachten wir beispielsweise ein Array [5,6,7,8], dann gibt es zehn nicht leere Unterarrays, wie zum Beispiel (5), (6), (7), (8), (5,6). (6, 7), (7,8), (5,6,7), (6,7,8) und (5,6,7,8). In diesem Leitfaden erklären wir alle möglichen Informationen in C++, um die Anzahl der Subarrays mit ungeraden Summen zu ermitteln. Um die Anzahl der Unterarrays ungerader Summen zu ermitteln, können wir verschiedene Methoden verwenden. Hier ist ein einfaches Beispiel: Input:array={9,8,7,6,5}Output:9Explanation:Sumofsubarray-{9}= 9{7
