

Den Informationen zufolge hat der ehemalige Google-Forscher für künstliche Intelligenz, Jacob Devlin, kürzlich das Unternehmen verlassen, um sich OpenAI anzuschließen. Zuvor gab er jedoch bekannt, dass er Sundar Pichai, CEO von Googles Muttergesellschaft Alphabet, vor Googles Chat gewarnt hat, von dem der Bot Bard Daten erhält ChatGPT auf indirekte Weise.

Erinnern Sie sich noch daran, dass Baidu Wenxinyiyan als „Shell“-Vorfall befragt wurde? Kürzlich brachten ausländische Medien die Nachricht, dass Google offenbar dasselbe getan hat.
Laut The Information hat der ehemalige Google-Forscher für künstliche Intelligenz, Jacob Devlin, das Unternehmen kürzlich verlassen, um sich OpenAI anzuschließen. Zuvor gab er jedoch bekannt, dass er Sundar Pichai, CEO von Googles Muttergesellschaft Alphabet, gewarnt hatte, dass Googles Chatbot Bard Daten erhält von ChatGPT auf indirekte Weise.
Devlins Beschreibung zufolge besuchte Bards Entwicklungsteam eine Website namens ShareGPT, die eine große Anzahl von Chat-Inhalten teilte und veröffentlichte, die Benutzer über ChatGPT erhalten hatten. Dies bedeutet, dass Bard die vorgefertigten Daten von ChatGPT verwendet hat, um sich zu „bewaffnen“, was einem Diebstahl der ersten Ergebnisse von ChatGPT gleichkommt.

Als Reaktion darauf gab Google-Sprecher Chris Pappas schnell eine Erklärung an die Medien ab, in der er klar und deutlich erklärte: „Bard ist nicht auf Daten von ShareGPT oder ChatGPT geschult.“
Auf Nachfrage der Medien Ob Google Bard jemals zuvor ChatGPT-Daten verwendet hatte, weigerte sich Pappas zu beantworten und bestand darauf, dass er nur die obige Aussage sagen könne.
Dieser Vorfall muss die Menschen an ähnliche Zweifel erinnern, mit denen Baidu Wenxin Yiyan kürzlich konfrontiert war.
Ende März veröffentlichten einige Internetnutzer einen Artikel, in dem sie Baidu Wenxins Yiyan-Gemälde in Frage stellten, was im Wesentlichen bedeutet: „Maschinelle Übersetzung chinesischer Sätze in englische Wörter, Verwendung der künstlichen Intelligenz Stable Diffusion, die gerade im Ausland als Open-Source-Lösung bereitgestellt wurde, um Bilder zu generieren, und dann Rückkehr.“ „Ich habe es selbst gezeichnet.“ „mouse“ und „bus“ sind auf Englisch „Maus“ und „Bus“.
Baidu antwortete ebenfalls dringend. Am 23. März gab Baidu eine Erklärung heraus, in der es hieß, dass Wenxin Yiyan vollständig ein von Baidu entwickeltes großes Sprachmodell sei und die Wenxin-Grafikfähigkeit aus dem modalübergreifenden großen Wenxin-Modell ERNIE-ViLG stamme. Beim Training großer Modelle verwendet Baidu globale öffentliche Internetdaten, was der Branchenpraxis entspricht. Gleichzeitig sagte er, dass Wen Xinyiyan während des Nutzungsprozesses ständig lerne und wachse und hoffe, dass jeder ein gewisses Vertrauen in die selbstentwickelten Technologien und Produkte habe.
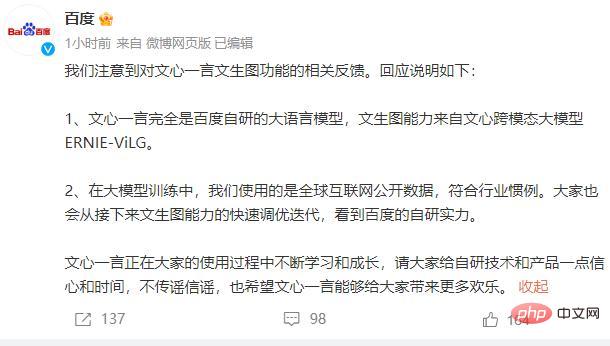 Anschließend korrigierte Baidu ähnliche Probleme, und die Benutzer stellten schnell fest, dass die damit verbundenen Probleme nicht mehr bestanden, was darauf hindeutet, dass ähnliche Situationen auf der Grundlage des Benutzerfeedbacks korrigiert wurden.
Anschließend korrigierte Baidu ähnliche Probleme, und die Benutzer stellten schnell fest, dass die damit verbundenen Probleme nicht mehr bestanden, was darauf hindeutet, dass ähnliche Situationen auf der Grundlage des Benutzerfeedbacks korrigiert wurden.
Zu Baidu Wen Xinyiyans Frage sagten Branchenexperten auch, dass die Nutzung öffentlicher Online-Daten ein grundlegender Vorgang der Branche sei. In dieser Branche gibt es eine Reihe von Zwischendienstleistern, die sich auf das Training von Daten für KI-Anwendungen spezialisiert haben. Die KI-Datensätze, die sie auf der Grundlage öffentlicher Datenannotationen trainieren, werden tatsächlich von mehreren KI-Anwendungen gleichzeitig verwendet.
Allerdings erhalten die grundlegenden Vorgänge in der Branche möglicherweise nicht das gleiche Verständnis und die gleiche Anerkennung auf Verbraucherebene. Diesmal wurde Google Bard aufgedeckt, ChatGPT-Daten für Schulungen zu verwenden, was auch im Ausland für Aufruhr sorgte und Google Diebstahl vorwarf die Ergebnisse von OpenAI.
Öffentliche Daten im Internet, einschließlich Website-Informationen, können mit technischen Mitteln leicht erfasst werden, was für Google, eine Suchmaschine, noch einfacher ist. Darüber hinaus stammen solche Enthüllungen von gerade gekündigten Google-Mitarbeitern, und die Glaubwürdigkeit hat sich natürlich erheblich verbessert.
Einige Internetnutzer wiesen jedoch darauf hin, dass Devlin nach seinem Ausscheiden aus dem Google AI-Team zum Konkurrenten OpenAI wechselte und seine Enthüllungen zwangsläufig kommerzielle Interessen beinhalten und die Authentizität noch weiter bestätigt werden muss.
Nach Ansicht von Geek.com zeigt ein solcher Vorfall jedoch unabhängig von der Echtheit eine „eiserne Regel“ voll und ganz: Das Feld der großen KI-Modelle hinkt Schritt für Schritt hinterher, und Nachzügler wollen aufholen Mit First Movern ist das nicht einfach.
Dahinter stecken viele Einflussfaktoren, darunter Algorithmen, Rechenleistung und die Qualität der Trainingsdaten. Wichtiger ist, dass das erste große KI-Modell, nachdem es seinen Weg zum Erfolg gefunden hat, weiter trainiert und weiterentwickelt und nicht stehen bleibt und auf Verfolger wartet.
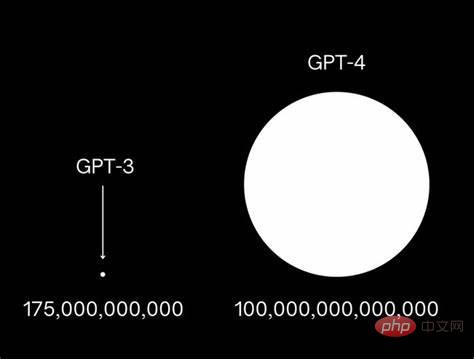
Aus diesem Grund wurde das GPT von OpenAI schnell von GPT-3 auf die GPT-4-Ära aktualisiert. Dies hat auch eine Reihe von Prominenten, darunter Musk, dazu veranlasst, gemeinsam einen offenen Brief herauszugeben, in dem große Unternehmen aufgefordert werden, die Entwicklung großer Modelle auszusetzen . , um eine Bedrohung für Menschen zu vermeiden.
Robin Li sagte in einem früheren Interview mit den Medien auch, dass es zwar in einigen Bereichen besser abschnitt, insgesamt aber immer noch ein oder zwei Monate Abstand zwischen dem Niveau von Baidu Wenxinyiyan und OpenAI ChatGPT besteht. Er wies auch darauf hin, dass das externe Feedback bei der Einführung von ChatGPT in der Anfangsphase noch schlechter war als das von Wen Xinyiyan.
Es gibt auch schlechte Nachrichten für Google Bard. Es wird gemunkelt, dass das Team für künstliche Intelligenz von Google mit DeepMind, einem anderen mit Alphabet verbundenen Unternehmen für künstliche Intelligenz, zusammenarbeitet, um gemeinsam ein neues Projekt mit dem Codenamen Gemini durchzuführen Produkte, die mit OpenAIs GPT konkurrieren können. Dies scheint darauf hinzudeuten, dass Google kein Vertrauen in Bard hat und hofft, ein fortschrittlicheres KI-Großmodell zu entwickeln und einen fortschrittlicheren KI-Chat-Roboter zu schaffen.
Das obige ist der detaillierte Inhalt vonGoogle hat es auch gemacht? Bard wurde ausgesetzt, um ChatGPT-Daten für das Training zu verwenden. Das große Modell gerät Schritt für Schritt ins Hintertreffen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 ChatGPT-Registrierung
ChatGPT-Registrierung
 Inländische kostenlose ChatGPT-Enzyklopädie
Inländische kostenlose ChatGPT-Enzyklopädie
 So installieren Sie ChatGPT auf einem Mobiltelefon
So installieren Sie ChatGPT auf einem Mobiltelefon
 Kann Chatgpt in China verwendet werden?
So installieren Sie ChatGPT auf einem Mobiltelefon
Kann Chatgpt in China verwendet werden?
So installieren Sie ChatGPT auf einem Mobiltelefon
 Die Rolle der Parseint-Funktion
Die Rolle der Parseint-Funktion
 Windows kann nicht auf den freigegebenen Computer zugreifen
Windows kann nicht auf den freigegebenen Computer zugreifen
 Das neueste Ranking der zehn besten Börsen im Währungskreis
Das neueste Ranking der zehn besten Börsen im Währungskreis
 Der Windows-Bildbetrachter kann nicht genügend Speicher anzeigen
Der Windows-Bildbetrachter kann nicht genügend Speicher anzeigen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



