
 Technologie-Peripheriegeräte
KI
Microsoft schlägt OTO vor, ein automatisiertes Trainings-Pruning-Framework für neuronale Netze, um leistungsstarke, leichtgewichtige Modelle aus einer Hand zu erhalten
Technologie-Peripheriegeräte
KI
Microsoft schlägt OTO vor, ein automatisiertes Trainings-Pruning-Framework für neuronale Netze, um leistungsstarke, leichtgewichtige Modelle aus einer Hand zu erhalten
Microsoft schlägt OTO vor, ein automatisiertes Trainings-Pruning-Framework für neuronale Netze, um leistungsstarke, leichtgewichtige Modelle aus einer Hand zu erhalten

OTO ist das branchenweit erste automatisierte, benutzerfreundliche und vielseitige Framework für das Training neuronaler Netze und die Strukturkomprimierung aus einer Hand.
Im Zeitalter der künstlichen Intelligenz ist die Bereitstellung und Wartung neuronaler Netze ein Schlüsselthema für die Produktisierung. Angesichts der Einsparung von Rechenkosten bei gleichzeitiger Minimierung des Verlusts an Modellleistung ist die Komprimierung neuronaler Netze zu einem der Schlüssel zur Produktisierung von DNN geworden.

DNN-Komprimierung verfügt im Allgemeinen über drei Methoden: Beschneiden, Wissensdestillation und Quantisierung. Ziel des Pruning ist es, redundante Strukturen zu identifizieren und zu entfernen, DNN zu verschlanken und gleichzeitig die Modellleistung so weit wie möglich aufrechtzuerhalten. Es ist die vielseitigste und effektivste Komprimierungsmethode. Im Allgemeinen können sich die drei Methoden gegenseitig ergänzen und zusammenarbeiten, um den besten Kompressionseffekt zu erzielen.

Die meisten vorhandenen Bereinigungsmethoden zielen jedoch nur auf bestimmte Modelle und spezifische Aufgaben ab und erfordern umfassende Fachkenntnisse in der Domäne. Daher müssen KI-Entwickler normalerweise viel Aufwand betreiben, um diese Methoden auf ihre eigenen Szenarien anzuwenden. Es kostet viel Personal und Material.
OTO-Übersicht
Um die Probleme bestehender Bereinigungsmethoden zu lösen und KI-Entwicklern Komfort zu bieten, hat das Microsoft-Team das Only-Train-Once OTO-Framework vorgeschlagen. OTO ist das branchenweit erste automatisierte, benutzerfreundliche und universelle Framework für das Training und die Strukturkomprimierung neuronaler Netzwerke. Eine Reihe von Arbeiten wurde in ICLR2023 und NeurIPS2021 veröffentlicht.
Durch den Einsatz von OTO können KI-Ingenieure auf einfache Weise neuronale Zielnetzwerke trainieren und leistungsstarke und leichte Modelle aus einer Hand erhalten. OTO minimiert den Entwicklungsaufwand des Entwicklers und erfordert nicht das zeitaufwändige Vortraining und die zusätzliche Feinabstimmung des Modells, die bei bestehenden Methoden normalerweise erforderlich sind.
- Paper -Link:
- OTOV2 ICLR 2023: https://openreview.net/pdf?id=7ynox1ojpmt
- otov1 Neurips 2021: https://proceceedings.neurips.cc/paper_files/2021/File/a376033f7814f49El 4bfc743c0be3330 -Paper.pdf
- Code-Link:
https://github.com/tianyic/only_train_once
Framework-Kernalgorithmus
Der idealisierte Strukturbereinigungsalgorithmus sollte sein: Eine automatisierte One-Stop-Lösung für allgemeine neuronale Netze Trainieren Sie von Grund auf und erhalten Sie gleichzeitig ein leistungsstarkes und leichtes Modell, ohne dass eine anschließende Feinabstimmung erforderlich ist. Aufgrund der Komplexität neuronaler Netze ist das Erreichen dieses Ziels jedoch äußerst schwierig. Um dieses ultimative Ziel zu erreichen, müssen die folgenden drei Kernfragen systematisch gelöst werden:
- Wie findet man heraus, welche Netzwerkstrukturen entfernt werden können?
- Wie kann die Netzwerkstruktur so weit wie möglich entfernt werden, ohne die Modellleistung zu beeinträchtigen?
- Wie können wir die beiden oben genannten Punkte automatisch erreichen?
Das Microsoft-Team hat drei Sätze von Kernalgorithmen entworfen und implementiert und damit diese drei Kernprobleme erstmals systematisch und umfassend gelöst.
Automatisierte nullinvariante Gruppen
Aufgrund der Komplexität und Korrelation der Netzwerkstruktur kann das Löschen einer Netzwerkstruktur dazu führen, dass die verbleibende Netzwerkstruktur ungültig wird. Daher besteht eines der größten Probleme bei der automatisierten Netzwerkstrukturkomprimierung darin, die Modellparameter zu finden, die zusammengeschnitten werden müssen, damit das verbleibende Netzwerk weiterhin gültig ist. Um dieses Problem zu lösen, schlug das Microsoft-Team in OTOv1 Zero-Invariante Groups (ZIGs) vor. Die nullinvariante Gruppe kann als eine Art kleinste entfernbare Einheit verstanden werden, sodass das verbleibende Netzwerk auch nach Entfernung der entsprechenden Netzwerkstruktur der Gruppe weiterhin gültig ist. Eine weitere großartige Eigenschaft einer nullinvarianten Gruppe besteht darin, dass, wenn eine nullinvariante Gruppe gleich Null ist, der Ausgabewert unabhängig vom Eingabewert immer Null ist. In OTOv2 haben die Forscher außerdem eine Reihe automatisierter Algorithmen vorgeschlagen und implementiert, um das Gruppierungsproblem nullinvarianter Gruppen in allgemeinen Netzwerken zu lösen. Der automatisierte Gruppierungsalgorithmus ist eine sorgfältig entworfene Kombination einer Reihe von Diagrammalgorithmen. Der gesamte Algorithmus ist sehr effizient und weist eine lineare Zeit- und Raumkomplexität auf.

Dual Half Plane Projected Gradient Optimization Algorithm (DHSPG)
Nach der Aufteilung aller nullinvarianten Gruppen des Zielnetzwerks müssen die nächsten Modelltrainings- und Bereinigungsaufgaben herausfinden, welche nullinvarianten Gruppen redundant sind . Der Rest, welche sind wichtig. Die Netzwerkstruktur, die den redundanten nullinvarianten Gruppen entspricht, muss gelöscht werden, und die wichtigen nullinvarianten Gruppen müssen beibehalten werden, um die Leistung des Komprimierungsmodells sicherzustellen. Die Forscher formulierten dieses Problem als strukturelles Sparsifizierungsproblem und schlugen einen neuen DHSPG-Optimierungsalgorithmus (Dual Half-Space Projected Gradient) zu seiner Lösung vor.

DHSPG kann sehr effektiv redundante nullinvariante Gruppen finden und auf Null projizieren und wichtige nullinvariante Gruppen kontinuierlich trainieren, um eine mit dem Originalmodell vergleichbare Leistung zu erzielen.
Im Vergleich zu herkömmlichen Sparse-Optimierungsalgorithmen verfügt DHSPG über stärkere und stabilere Funktionen zur Erkundung spärlicher Strukturen und erweitert den Trainingssuchraum, sodass in der Regel höhere tatsächliche Leistungsergebnisse erzielt werden.

Automatisch ein leichtes Komprimierungsmodell erstellen
Durch die Verwendung von DHSPG zum Trainieren des Modells erhalten wir eine Lösung, die der hohen strukturellen Sparsamkeit der nullinvarianten Gruppe entspricht, das heißt, es gibt viele in der Lösung die in eine nullinvariante Menge von Nullen projiziert werden, und diese Lösung weist auch eine hohe Modellleistung auf. Als nächstes löschten die Forscher alle Strukturen, die redundanten nullinvarianten Gruppen entsprachen, um automatisch ein Komprimierungsnetzwerk aufzubauen. Aufgrund der Eigenschaften von nullinvarianten Gruppen, das heißt, wenn eine nullinvariante Gruppe gleich Null ist, ist der Ausgabewert unabhängig vom Eingabewert immer Null, sodass das Löschen redundanter nullinvarianter Gruppen nicht der Fall ist Auswirkungen auf das Netzwerk haben. Daher hat das durch OTO erhaltene komprimierte Netzwerk die gleiche Ausgabe wie das gesamte Netzwerk, ohne dass eine weitere Feinabstimmung des Modells erforderlich ist, die bei herkömmlichen Methoden erforderlich ist.
Zahlreiche Experimente 任 VGG16- und VGG16-BN-Modelle in CIFAR10 und VGG16-BN-Modelle in CIFAR10. Im VGG16-Experiment von CIFAR10 wurde die Lautstärke um 97,5 % reduziert und die Leistung war beeindruckend.
 Tabelle 2: ResNet50-Experiment zu CIFAR10
Tabelle 2: ResNet50-Experiment zu CIFAR10
Im ResNet50-Experiment zu CIFAR10 übertrifft OTO die SOTA-Komprimierungsframeworks für neuronale Netzwerke AMC und ANNC ohne Quantisierung und verwendet nur 7,8 % der FLOPs und 4,1 % Parameter.
 Tabelle 3. ImageNets ResNet50-Experiment
Tabelle 3. ImageNets ResNet50-Experiment
Im ImageNets ResNet50-Experiment zeigte OTOv2 unter verschiedenen strukturellen Sparsifizierungszielen eine vergleichbare oder sogar bessere Leistung als die bestehende SOTA-Methode.
 Tabelle 4: Mehr Strukturen und Datensätze
Tabelle 4: Mehr Strukturen und Datensätze
OTO erzielt auch bei mehr Datensätzen und Modellstrukturen eine gute Leistung. Low-Level-Vision-Aufgabe Leistung und komprimierte den Rechenaufwand und die Modellgröße um mehr als 75 %.
Sprachmodellaufgabe

Darüber hinaus führten die Forscher auch Vergleichsexperimente an Bert mit einem der Kernalgorithmen, dem DHSPG-Optimierungsalgorithmus, durch und überprüften dessen hohe Leistung im Vergleich zu anderen spärlichen Optimierungsalgorithmen. Es kann festgestellt werden, dass bei Squad die Parameterreduzierung und die Modellleistung, die durch die Verwendung von DHSPG für das Training erzielt werden, anderen Algorithmen zur spärlichen Optimierung weit überlegen sind.
FazitDas Microsoft-Team schlug ein automatisiertes One-Stop-Framework zur Bereinigung der Trainingsstruktur neuronaler Netze namens OTO (Only-Train-Once) vor. Es kann ein vollständiges neuronales Netzwerk automatisch in ein leichtes Netzwerk komprimieren und gleichzeitig eine hohe Leistung beibehalten. OTO vereinfacht den komplexen mehrstufigen Prozess bestehender Strukturbereinigungsmethoden erheblich, eignet sich für verschiedene Netzwerkarchitekturen und Anwendungen und minimiert den zusätzlichen technischen Aufwand der Benutzer. Es ist vielseitig, effektiv und einfach zu verwenden.Das obige ist der detaillierte Inhalt vonMicrosoft schlägt OTO vor, ein automatisiertes Trainings-Pruning-Framework für neuronale Netze, um leistungsstarke, leichtgewichtige Modelle aus einer Hand zu erhalten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

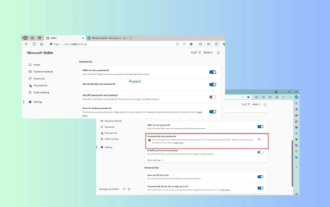 Microsoft Edge-Upgrade: Funktion zum automatischen Speichern von Passwörtern verboten? ! Die Benutzer waren schockiert!
Apr 19, 2024 am 08:13 AM
Microsoft Edge-Upgrade: Funktion zum automatischen Speichern von Passwörtern verboten? ! Die Benutzer waren schockiert!
Apr 19, 2024 am 08:13 AM
Neuigkeiten vom 18. April: Kürzlich berichteten einige Benutzer des Microsoft Edge-Browsers, die den Canary-Kanal nutzten, dass sie nach dem Upgrade auf die neueste Version festgestellt hätten, dass die Option zum automatischen Speichern von Passwörtern deaktiviert sei. Nach einer Untersuchung stellte sich heraus, dass es sich hierbei um eine geringfügige Anpassung nach dem Browser-Upgrade und nicht um eine Aufhebung der Funktionalität handelte. Vor der Verwendung des Edge-Browsers für den Zugriff auf eine Website berichteten Benutzer, dass der Browser ein Fenster öffnete, in dem sie gefragt wurden, ob sie das Anmeldekennwort für die Website speichern wollten. Nachdem Sie sich zum Speichern entschieden haben, gibt Edge bei der nächsten Anmeldung automatisch die gespeicherte Kontonummer und das gespeicherte Passwort ein, was den Benutzern großen Komfort bietet. Aber das neueste Update ähnelt einer Optimierung, bei der die Standardeinstellungen geändert werden. Benutzer müssen das Speichern des Passworts auswählen und dann in den Einstellungen das automatische Ausfüllen des gespeicherten Kontos und Passworts manuell aktivieren.
 Microsoft veröffentlicht das kumulative August-Update für Win11: Verbesserung der Sicherheit, Optimierung des Sperrbildschirms usw.
Aug 14, 2024 am 10:39 AM
Microsoft veröffentlicht das kumulative August-Update für Win11: Verbesserung der Sicherheit, Optimierung des Sperrbildschirms usw.
Aug 14, 2024 am 10:39 AM
Laut Nachrichten dieser Website vom 14. August veröffentlichte Microsoft während des heutigen August-Patch-Dienstags kumulative Updates für Windows 11-Systeme, darunter das Update KB5041585 für 22H2 und 23H2 sowie das Update KB5041592 für 21H2. Nachdem das oben genannte Gerät mit dem kumulativen Update vom August installiert wurde, sind die mit dieser Site verbundenen Versionsnummernänderungen wie folgt: Nach der Installation des 21H2-Geräts wurde die Versionsnummer auf Build22000.314722H2 erhöht. Die Versionsnummer wurde auf Build22621.403723H2 erhöht. Nach der Installation des Geräts wurde die Versionsnummer auf Build22631.4037 erhöht. Die Hauptinhalte des KB5041585-Updates für Windows 1121H2 sind wie folgt: Verbesserung: Verbessert
 Das Vollbild-Popup von Microsoft fordert Benutzer von Windows 10 auf, sich zu beeilen und auf Windows 11 zu aktualisieren
Jun 06, 2024 am 11:35 AM
Das Vollbild-Popup von Microsoft fordert Benutzer von Windows 10 auf, sich zu beeilen und auf Windows 11 zu aktualisieren
Jun 06, 2024 am 11:35 AM
Laut Nachrichten vom 3. Juni sendet Microsoft aktiv Vollbildbenachrichtigungen an alle Windows 10-Benutzer, um sie zu einem Upgrade auf das Betriebssystem Windows 11 zu ermutigen. Dabei handelt es sich um Geräte, deren Hardwarekonfigurationen das neue System nicht unterstützen. Seit 2015 hat Windows 10 fast 70 % des Marktanteils eingenommen und seine Dominanz als Windows-Betriebssystem fest etabliert. Der Marktanteil liegt jedoch weit über dem Marktanteil von 82 %, und der Marktanteil übersteigt den von Windows 11, das 2021 erscheinen wird, bei weitem. Obwohl Windows 11 seit fast drei Jahren auf dem Markt ist, ist die Marktdurchdringung immer noch langsam. Microsoft hat angekündigt, den technischen Support für Windows 10 nach dem 14. Oktober 2025 einzustellen, um sich stärker darauf zu konzentrieren
 Die Funktion von Microsoft Win11 zum Komprimieren von 7z- und TAR-Dateien wurde von den Versionen 24H2 auf 23H2/22H2 herabgestuft
Apr 28, 2024 am 09:19 AM
Die Funktion von Microsoft Win11 zum Komprimieren von 7z- und TAR-Dateien wurde von den Versionen 24H2 auf 23H2/22H2 herabgestuft
Apr 28, 2024 am 09:19 AM
Laut Nachrichten dieser Website vom 27. April hat Microsoft Anfang dieses Monats das Vorschauversionsupdate für Windows 11 Build 26100 auf den Canary- und Dev-Kanälen veröffentlicht, das voraussichtlich eine mögliche RTM-Version des Windows 1124H2-Updates werden wird. Die wichtigsten Änderungen in der neuen Version sind der Datei-Explorer, die Integration von Copilot, die Bearbeitung von PNG-Dateimetadaten, die Erstellung von TAR- und 7z-komprimierten Dateien usw. @PhantomOfEarth hat herausgefunden, dass Microsoft einige Funktionen der 24H2-Version (Germanium) auf die 23H2/22H2-Version (Nickel) übertragen hat, beispielsweise die Erstellung von TAR- und 7z-komprimierten Dateien. Wie im Diagramm gezeigt, unterstützt Windows 11 die native Erstellung von TAR
 Microsoft Edge-Browser-Update: Funktion „Bild vergrößern' hinzugefügt, um die Benutzererfahrung zu verbessern
Mar 21, 2024 pm 01:40 PM
Microsoft Edge-Browser-Update: Funktion „Bild vergrößern' hinzugefügt, um die Benutzererfahrung zu verbessern
Mar 21, 2024 pm 01:40 PM
Einer Nachricht vom 21. März zufolge hat Microsoft kürzlich seinen Microsoft Edge-Browser aktualisiert und eine praktische „Bild vergrößern“-Funktion hinzugefügt. Wenn Benutzer den Edge-Browser verwenden, können Benutzer diese neue Funktion jetzt ganz einfach im Popup-Menü finden, indem sie einfach mit der rechten Maustaste auf das Bild klicken. Noch praktischer ist, dass Benutzer auch mit der Maus über das Bild fahren und dann die Strg-Taste doppelklicken können, um schnell die Funktion zum Vergrößern des Bildes aufzurufen. Nach Angaben des Herausgebers wurde der neueste veröffentlichte Microsoft Edge-Browser im kanarischen Kanal auf neue Funktionen getestet. Die stabile Version des Browsers hat außerdem offiziell die praktische Funktion „Bild vergrößern“ eingeführt, die Benutzern ein komfortableres Durchsuchen von Bildern ermöglicht. Darauf haben auch ausländische Wissenschafts- und Technologiemedien geachtet
 Erforschung siamesischer Netzwerke unter Verwendung von Kontrastverlust zum Vergleich der Bildähnlichkeit
Apr 02, 2024 am 11:37 AM
Erforschung siamesischer Netzwerke unter Verwendung von Kontrastverlust zum Vergleich der Bildähnlichkeit
Apr 02, 2024 am 11:37 AM
Einleitung Im Bereich Computer Vision ist die genaue Messung der Bildähnlichkeit eine wichtige Aufgabe mit einem breiten Spektrum praktischer Anwendungen. Von Bildsuchmaschinen über Gesichtserkennungssysteme bis hin zu inhaltsbasierten Empfehlungssystemen ist die Fähigkeit, ähnliche Bilder effektiv zu vergleichen und zu finden, wichtig. Das siamesische Netzwerk bietet in Kombination mit Kontrastverlust einen leistungsstarken Rahmen für das datengesteuerte Erlernen der Bildähnlichkeit. In diesem Blogbeitrag werden wir uns mit den Details siamesischer Netzwerke befassen, das Konzept des Kontrastverlusts untersuchen und untersuchen, wie diese beiden Komponenten zusammenarbeiten, um ein effektives Bildähnlichkeitsmodell zu erstellen. Erstens besteht das siamesische Netzwerk aus zwei identischen Teilnetzwerken mit denselben Gewichten und Parametern. Jedes Subnetzwerk codiert das Eingabebild in einen Merkmalsvektor, der
 Microsoft plant, NTLM in Windows 11 in der zweiten Jahreshälfte 2024 auslaufen zu lassen und vollständig auf Kerberos-Authentifizierung umzustellen
Jun 09, 2024 pm 04:17 PM
Microsoft plant, NTLM in Windows 11 in der zweiten Jahreshälfte 2024 auslaufen zu lassen und vollständig auf Kerberos-Authentifizierung umzustellen
Jun 09, 2024 pm 04:17 PM
In der zweiten Hälfte des Jahres 2024 veröffentlichte der offizielle Microsoft-Sicherheitsblog eine Nachricht als Reaktion auf den Aufruf der Sicherheits-Community. Das Unternehmen plant, das in der zweiten Jahreshälfte 2024 veröffentlichte NTLAN Manager (NTLM)-Authentifizierungsprotokoll in Windows 11 zu eliminieren, um die Sicherheit zu verbessern. Nach bisherigen Erläuterungen hat Microsoft bereits zuvor ähnliche Schritte unternommen. Am 12. Oktober letzten Jahres schlug Microsoft in einer offiziellen Pressemitteilung einen Übergangsplan vor, der darauf abzielt, NTLM-Authentifizierungsmethoden auslaufen zu lassen und mehr Unternehmen und Benutzer dazu zu bewegen, auf Kerberos umzusteigen. Um Unternehmen zu helfen, die möglicherweise Probleme mit fest verdrahteten Anwendungen und Diensten haben, nachdem sie die NTLM-Authentifizierung deaktiviert haben, stellt Microsoft IAKerb und zur Verfügung
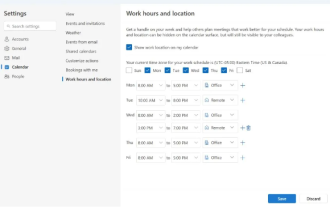 Microsoft bringt neue Version von Outlook für Windows auf den Markt: umfassende Aktualisierung der Kalenderfunktionen
Apr 27, 2024 pm 03:44 PM
Microsoft bringt neue Version von Outlook für Windows auf den Markt: umfassende Aktualisierung der Kalenderfunktionen
Apr 27, 2024 pm 03:44 PM
In den Nachrichten vom 27. April gab Microsoft bekannt, dass es bald einen Test einer neuen Version des Outlook für Windows-Clients veröffentlichen wird. Dieses Update konzentriert sich hauptsächlich auf die Optimierung der Kalenderfunktion mit dem Ziel, die Arbeitseffizienz der Benutzer zu verbessern und den täglichen Arbeitsablauf weiter zu vereinfachen. Die Verbesserung der neuen Version des Outlook für Windows-Clients liegt in seiner leistungsfähigeren Kalenderverwaltungsfunktion. Jetzt können Benutzer persönliche Arbeitszeit- und Standortinformationen einfacher teilen und so die Besprechungsplanung effizienter gestalten. Darüber hinaus verfügt Outlook über benutzerfreundliche Einstellungen, die es Benutzern ermöglichen, Besprechungen so einzustellen, dass sie automatisch früher enden oder später beginnen. Dies bietet Benutzern mehr Flexibilität, unabhängig davon, ob sie Besprechungsräume wechseln, eine Pause einlegen oder eine Tasse Kaffee vereinbaren möchten . entsprechend
