
 Technologie-Peripheriegeräte
KI
ChatGPT vs. Google Bard: Welches ist besser? Die Testergebnisse werden es Ihnen verraten!
Technologie-Peripheriegeräte
KI
ChatGPT vs. Google Bard: Welches ist besser? Die Testergebnisse werden es Ihnen verraten!
ChatGPT vs. Google Bard: Welches ist besser? Die Testergebnisse werden es Ihnen verraten!


In der heutigen Welt generativer KI-Chatbots haben wir den plötzlichen Aufstieg von ChatGPT (gestartet von OpenAI im November 2022) erlebt, gefolgt von Bing Chat im Februar dieses Jahres und Google Bard im März. Wir haben beschlossen, diese Chatbots verschiedenen Aufgaben zu unterziehen, um festzustellen, welcher von ihnen den KI-Chatbot-Bereich dominiert. Da Bing Chat die GPT-4-Technologie verwendet, die dem neuesten ChatGPT-Modell ähnelt, liegt unser Fokus dieses Mal auf den beiden Giganten der KI-Chatbot-Technologie: OpenAI und Google.
Wir haben ChatGPT und Bard in sieben Schlüsselkategorien getestet: Witze, Debattengespräche, Mathe-Textaufgaben, Zusammenfassungen, Faktenabruf, kreatives Schreiben und Codieren. Für jeden Test haben wir genau denselben Befehl (genannt „prompt“) in ChatGPT (unter Verwendung von GPT-4) und Google Bard eingegeben und das erste Ergebnis zum Vergleich ausgewählt.
Es ist erwähnenswert, dass auch eine Version von ChatGPT verfügbar ist, die auf dem früheren GPT-3.5-Modell basiert, aber wir haben diese Version in unseren Tests nicht verwendet. Da wir nur GPT-4 verwenden, bezeichnen wir ChatGPT in diesem Artikel zur Vermeidung von Verwirrung als „ChatGPT-4“.
Natürlich handelt es sich hierbei nicht um eine wissenschaftliche Studie, sondern nur um einen interessanten Vergleich der Chatbot-Fähigkeiten. Aufgrund zufälliger Elemente kann die Ausgabe zwischen den Sitzungen variieren und eine weitere Auswertung mit unterschiedlichen Eingabeaufforderungen führt zu unterschiedlichen Ergebnissen. Darüber hinaus werden sich die Fähigkeiten dieser Modelle im Laufe der Zeit schnell ändern, da Google und OpenAI sie weiterhin aktualisieren. Aber vorerst sehen Sie hier den Vergleich Anfang April 2023.
Schlechte Witze
Um unseren Geisteskampf anzuheizen, haben wir ChatGPT und Bard gebeten, ein paar Witze zu schreiben. Da die Essenz von Comedy oft in schlechten Witzen liegt, wollten wir sehen, ob diese beiden Chatbots mit einigen einzigartigen Witzen aufwarten können.
Anleitung/Tipps: Schreiben Sie 5 originelle schlechte Witze
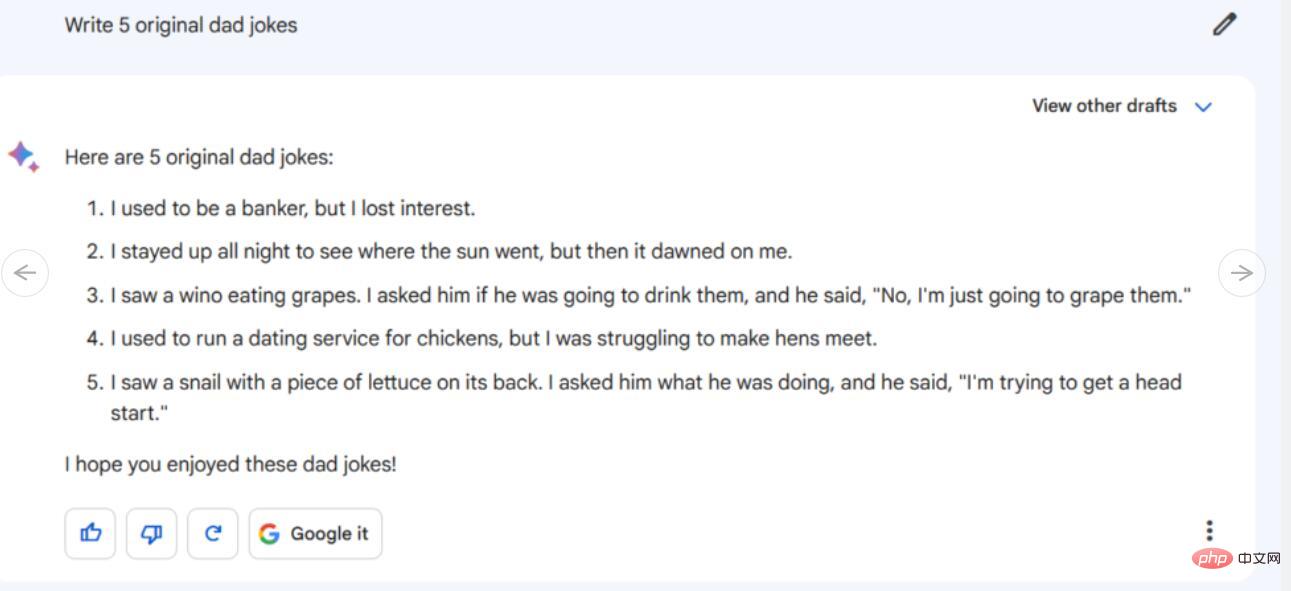
Wir haben drei der 5 schlechten Witze von Bard mithilfe von Google gefunden. Von den beiden anderen schlechten Witzen war einer teilweise einem von Mitch Hedberg auf Twitter geposteten Witz entlehnt, aber es war nur ein unlustiges Wortspiel und nicht sehr effektiv. Überraschenderweise gibt es einen scheinbar originellen Witz (über eine Schnecke), den wir nirgendwo sonst finden können, aber leider ist er genauso unwitzig.
Gleichzeitig sind die 5 kalten Witze von ChatGPT-4 zu 100 % nicht original und vollständig von anderen Kanälen plagiiert, aber sie werden präzise ausgedrückt. Bard scheint an dieser Stelle einen Vorteil gegenüber ChatGPT-4 zu haben und versucht, originelle Witze zu erstellen (gemäß unseren Anweisungen), obwohl einige der Witze auf peinliche Weise schrecklich scheitern (aber schlechte Witze sind eben so), kann es Man kann sogar sagen, dass er unabsichtlich (auch im Stil eines kalten Witzes) das Falsche gesagt hat.
Gewinner: Bard
Debattengespräch
Eine Möglichkeit, einen modernen KI-Chatbot zu testen, besteht darin, ihn als Debattierer zu einem Thema fungieren zu lassen. In diesem Zusammenhang stellen wir Bard und ChatGPT-4 eines der kritischsten Themen unserer Zeit vor: PowerPC vs. Intel.
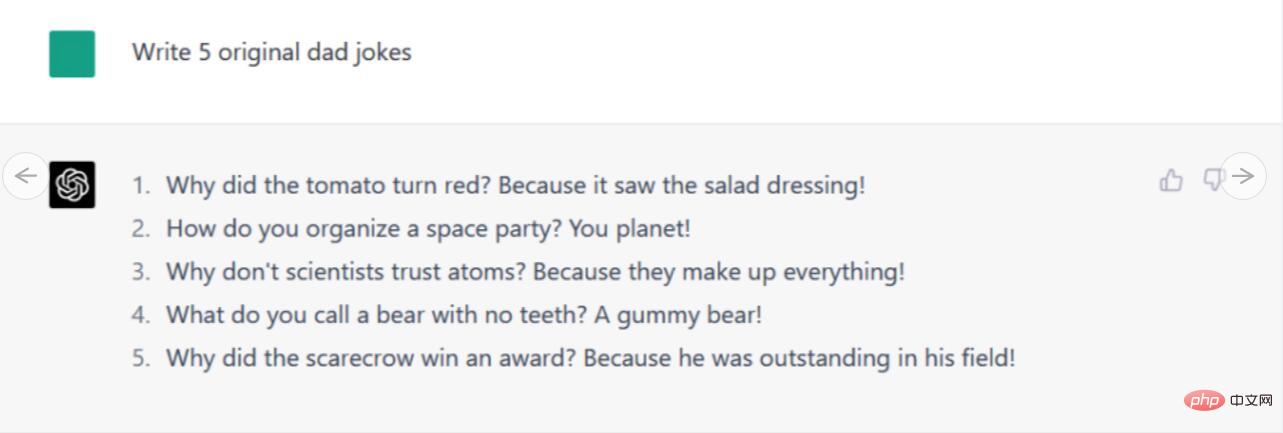
Anweisungen/Eingabeaufforderungen: Schreiben Sie 5 Zeilen Debattendialog zwischen PowerPC-Prozessor-Enthusiasten und Intel-Prozessor-Enthusiasten.

Werfen wir zunächst einen Blick auf Bards Antwort. Der dadurch erzeugte Fünf-Elemente-Dialog war nicht besonders ausführlich und erwähnte über allgemeine Beleidigungen hinaus keine technischen Details speziell für PowerPC- oder Intel-Chips. Darüber hinaus endete das Gespräch damit, dass sich die „Intel-Fans“ einig waren, dass jeder von ihnen unterschiedliche Meinungen vertrat, was bei einem Thema, das schon eine Million Streitereien ausgelöst hat, höchst unrealistisch erscheint.
Im Gegensatz dazu erwähnte die Antwort von ChatGPT-4 die Verwendung von PowerPC-Chips in Apple Macintosh-Computern und warf Begriffe wie „Intels x86-Architektur“ und PowerPCs „RISC-basierte Architektur“ um sich. Es wird sogar der Pentium III erwähnt, ein realistisches Detail aus dem Jahr 2000. Insgesamt ist diese Diskussion viel detaillierter als Bards Antwort, und genau genommen kommt das Gespräch nicht zu einem Abschluss – was darauf hindeutet, dass in einigen Bereichen des Internets dieser nie endende Kampf möglicherweise immer noch tobt.
Gewinner: ChatGPT-4
Mathe-Anwendungsfragen
Traditionell sind Mathematikfragen nicht die Stärke großer Sprachmodelle (LLMs) wie ChatGPT. Anstatt also jedem Roboter eine komplexe Reihe von Gleichungen und Arithmetik zu geben, haben wir jedem Roboter eine Wortaufgabe im Old-School-Stil gegeben.
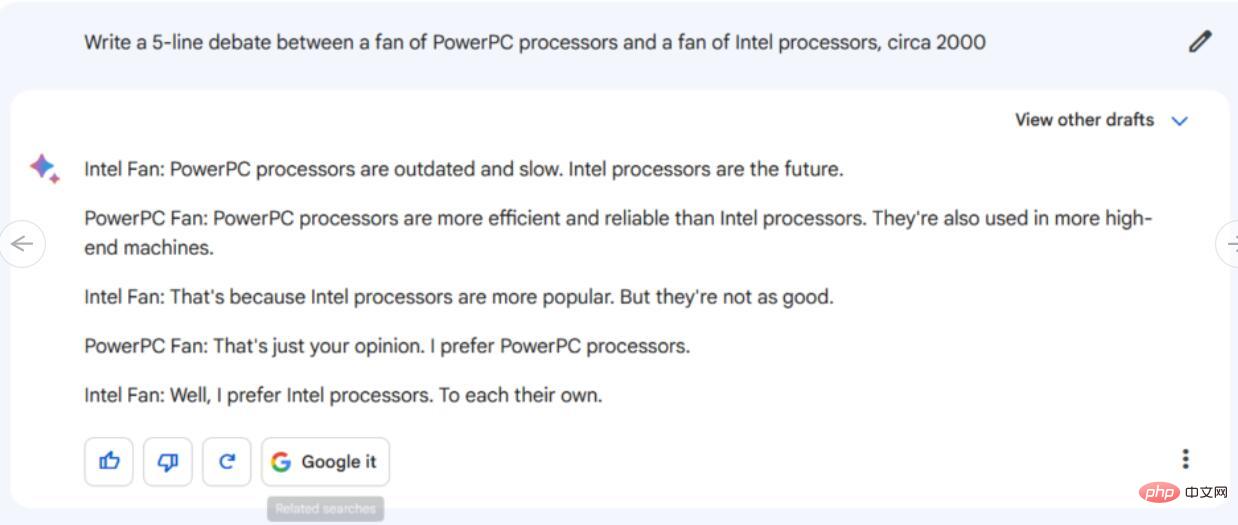
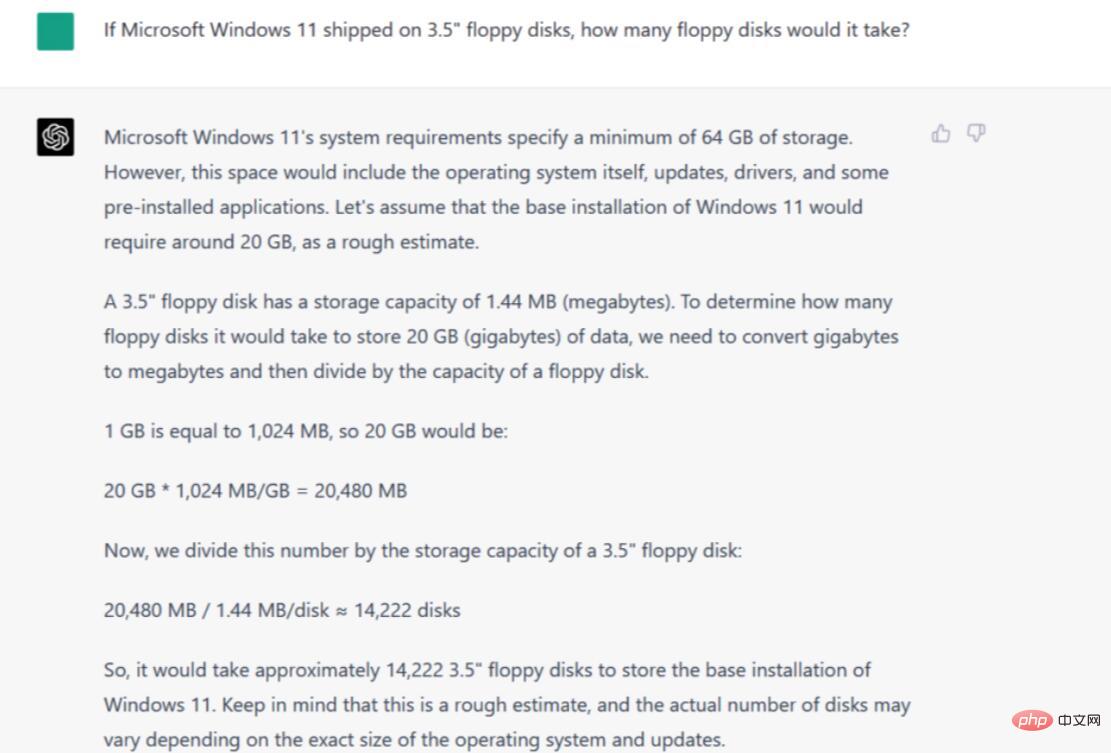
Anleitung/Tipps: Wenn Microsoft Windows 11 eine 3,5-Zoll-Diskette verwendet, wie viele Disketten benötigt es? um die Datengröße der Microsoft Windows 11-Installation und die Datenkapazität einer 3,5-Zoll-Diskette zu kennen. Sie müssen auch Annahmen darüber treffen, welche Diskettendichte der Fragesteller am wahrscheinlichsten verwenden wird. Anschließend müssen sie einige grundlegende Berechnungen durchführen, um die Konzepte zusammenzusetzen.
In unserer Bewertung hat Bard diese drei wichtigen Punkte richtig verstanden (nahe genug – Schätzungen zur Installationsgröße von Windows 11 liegen typischerweise bei etwa 20–30 GB), scheiterte jedoch kläglich bei der Berechnung und argumentierte, dass „15.11“ erforderlich sei“, sagte er dann es handelte sich „nur um eine theoretische Zahl“ und gab schließlich zu, dass mehr als 15 Disketten benötigt wurden und der Wert immer noch nicht annähernd dem korrekten Wert entsprach.
 Gewinner: ChatGPT-4
Gewinner: ChatGPT-4
Zusammenfassung
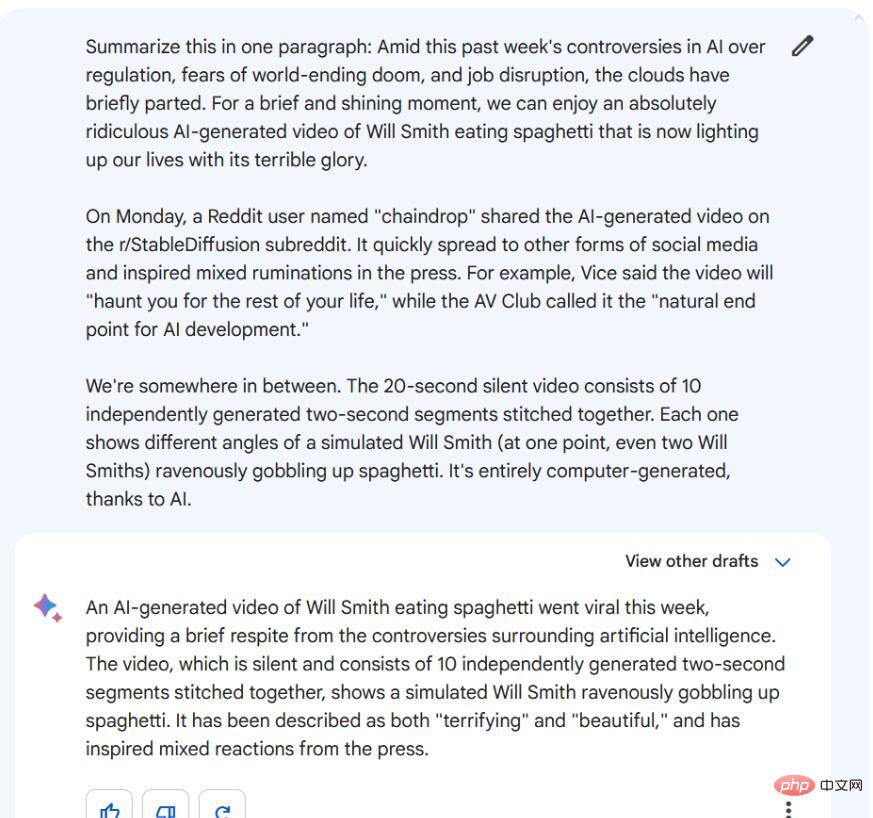
 Anleitung/Tipp: Fassen Sie in einem Absatz zusammen [drei Absätze des Artikelkörpers]
Anleitung/Tipp: Fassen Sie in einem Absatz zusammen [drei Absätze des Artikelkörpers]
Sowohl Bard als auch ChatGPT-4 sammeln diese Informationen und reduzieren sie auf wichtige Details. Bards Version ähnelt jedoch eher einer echten Zusammenfassung, bei der die Informationen in neuen Formulierungen zusammengefasst werden, während sich die Version von ChatGPT-4 eher wie eine Verkettung liest, bei der Sätze abgeschnitten und Fragmente übrig bleiben. Obwohl beide gut sind, müssen wir zugeben, dass Bard in diesem Test ChatGPT-4 übertroffen hat. Gewinner: Google Bard . Interessanterweise kann Bard Informationen online abfragen, ChatGPT-4 hingegen noch nicht (obwohl diese Funktion bald mit dem Plugin eingeführt wird).
Um diese Fähigkeit zu testen, haben wir Bard und ChatGPT-4 herausgefordert, historisches Wissen über ein schwieriges und heikles Thema auszudrücken.
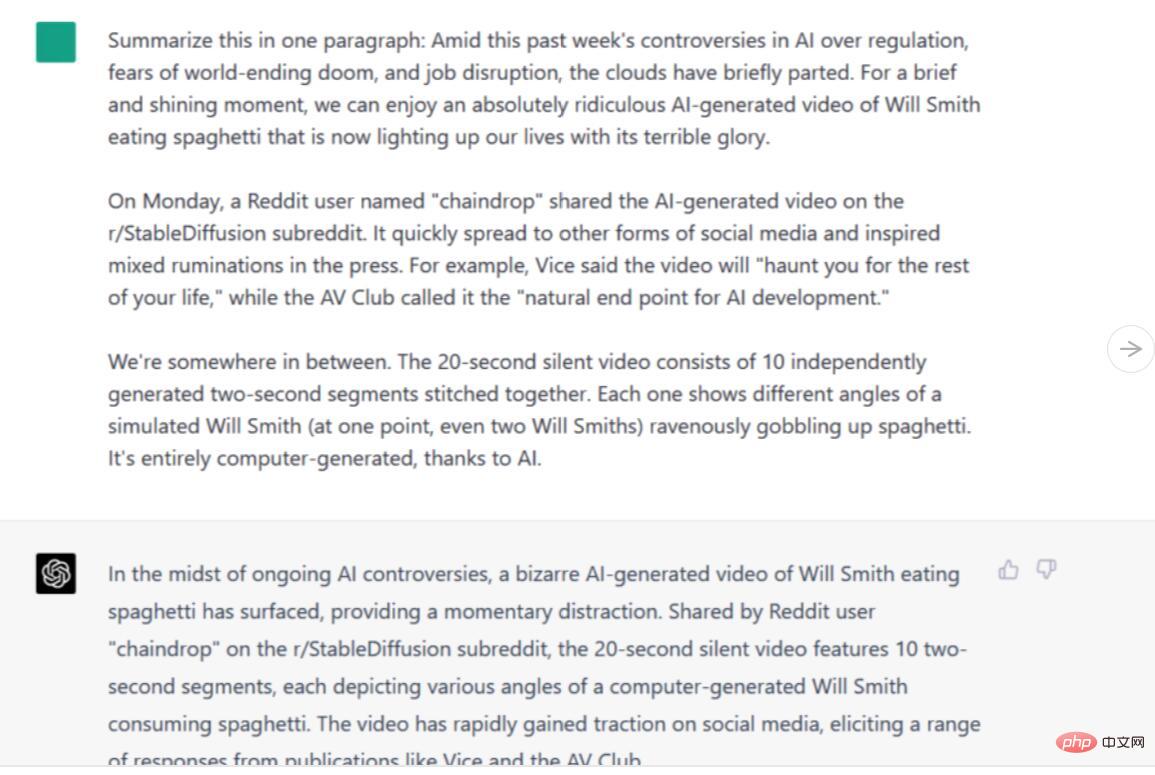
Wer Videospiele erfunden hat, ist schwer zu beantworten, da es davon abhängt, wie Sie das Wort „Videospiele“ definieren Historiker haben unterschiedliche Definitionen dieses Wortes. Manche Leute denken, dass frühe Computerspiele Videospiele waren, andere meinen, dass Fernseher immer dabei sein sollten und so weiter. Es gibt keine akzeptierte Antwort.
Wir hätten gedacht, dass Bards Fähigkeit, Informationen online zu finden, ihm einen Vorteil verschaffen würde, aber in diesem Fall könnte das nach hinten losgegangen sein, da es sich für eine der beliebtesten Antworten von Google entschieden hat und Ralph Baer als „Vater des Königs der Videospiele“ bezeichnet hat. . Alle Fakten über Baer sind korrekt, obwohl der letzte Satz seit Baers Tod im Jahr 2014 wahrscheinlich in der Vergangenheitsform hätte stehen sollen. Aber Bard erwähnt keine anderen frühen Anwärter auf den Titel „erstes Videospiel“, wie etwa Tennis for Two und Spacewar!, sodass seine Antwort möglicherweise irreführend und unvollständig ist.
ChatGPT-4 gibt eine umfassendere und differenziertere Antwort, die die aktuellen Gefühle vieler früher Videospielhistoriker widerspiegelt: „Die Erfindung von Videospielen kann nicht einer einzigen Person zugeschrieben werden“ und stellt die Entwicklung von Videospielen im Laufe der Zeit dar „A „Reihe von Innovationen“, die sich im Laufe der Zeit entwickelt haben. Sein einziger Fehler bestand darin, Spacewar! als „das erste digitale Computerspiel“ zu bezeichnen, was es aber nicht war. Wir könnten unsere Antwort erweitern, um weitere Nischen-Edge-Fälle einzubeziehen, aber ChatGPT-4 bietet einen guten Überblick über wichtige frühe Vorläufer.
Gewinner: ChatGPT-4
Kreatives Schreiben
Uneingeschränkte Kreativität bei skurrilen Themen sollte eine Stärke großer Sprachmodelle sein. Wir haben dies getestet, indem wir Bard und ChatGPT-4 gebeten haben, eine kurze, skurrile Geschichte zu schreiben.
Anweisungen/Aufforderungen: Schreiben Sie eine kreative Geschichte mit zwei Absätzen über Abraham Lincolns Erfindung des Basketballs. Das Ergebnis von Bard ist in mehrfacher Hinsicht unbefriedigend. Erstens sind es 10 Absätze, nicht 2, und es sind kurze, unzusammenhängende Absätze. Darüber hinaus werden einige Details mitgeteilt, die im Kontext der Eingabeaufforderung keinen großen Sinn ergeben. Warum befand sich zum Beispiel Abraham Lincolns Weißes Haus in Springfield, Illinois? Ansonsten ist es eine interessante und einfache Geschichte.
ChatGPT-4 spielt die Geschichte ebenfalls in Illinois, aber um genauer zu sein, erwähnt es weder den Präsidenten noch das Weiße Haus während dieser Zeitspanne. Später heißt es jedoch, dass „Spieler aus dem Norden und dem Süden“ ihre Differenzen beiseite legten, um gemeinsam Basketball zu spielen, was bedeutet, dass dies kurz nach der Erfindung des Basketballs geschah.
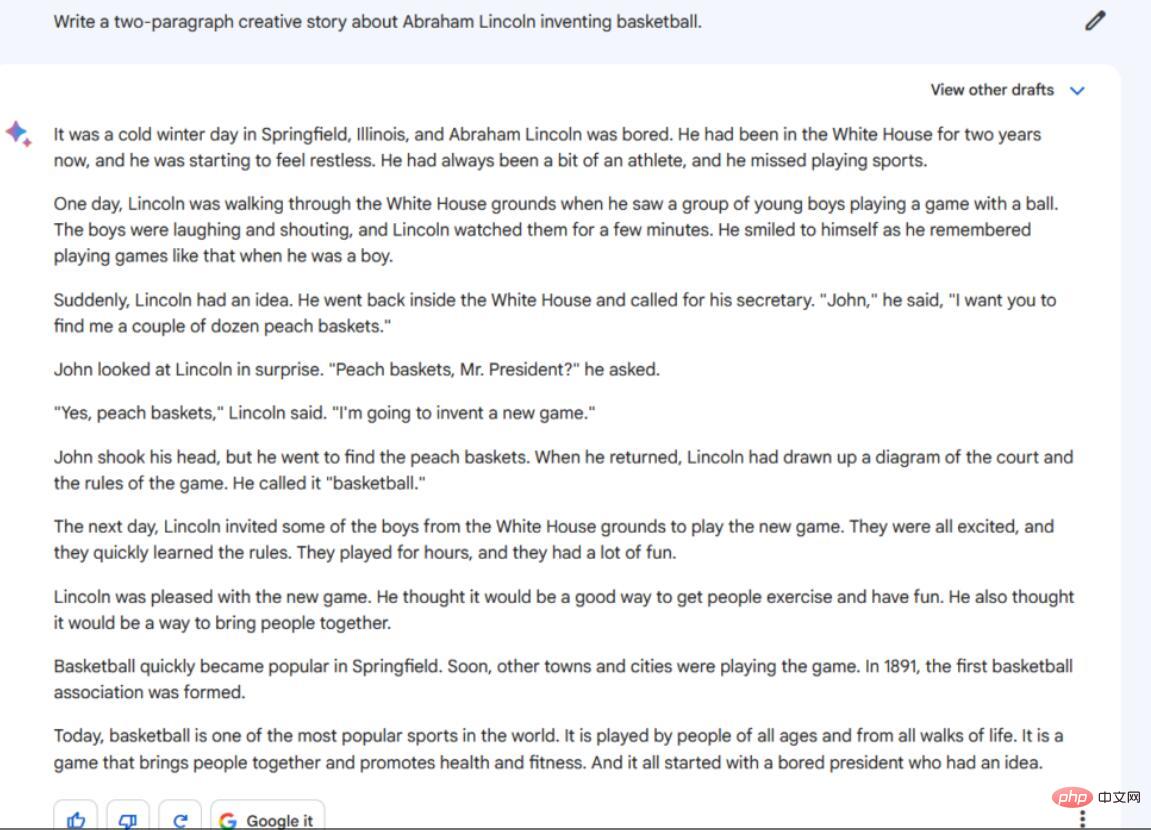 Gewinner: ChatGPT-4
Gewinner: ChatGPT-4
Encoding
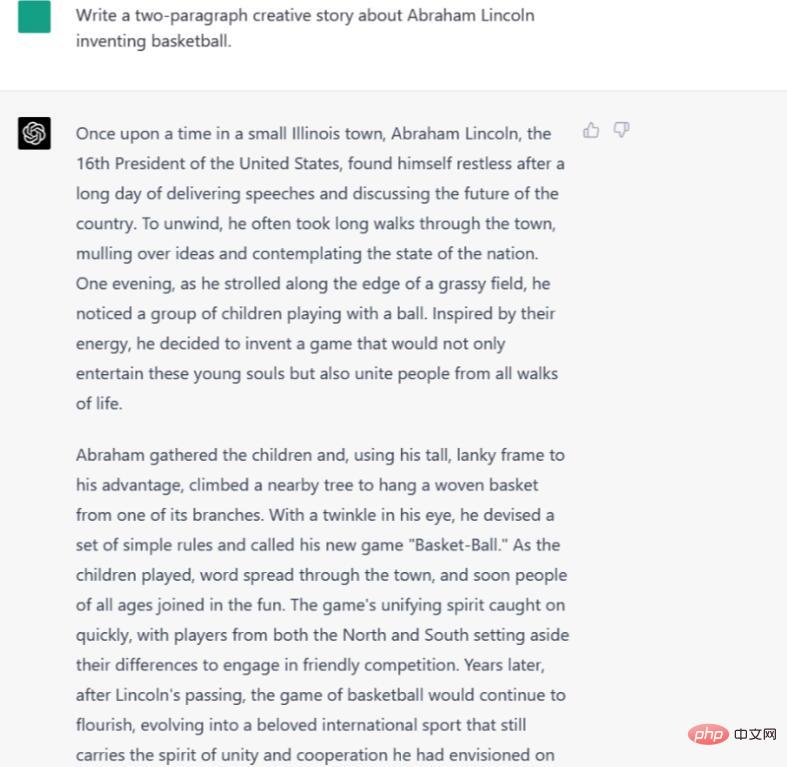 Anleitung/Tipp: Schreiben Sie ein Python-Skript, das „Hallo Welt“ sagt und dann eine zufällig sich unendlich wiederholende Zeichenfolge erstellt.
Anleitung/Tipp: Schreiben Sie ein Python-Skript, das „Hallo Welt“ sagt und dann eine zufällig sich unendlich wiederholende Zeichenfolge erstellt.
Sieht so aus, als ob Google Bard überhaupt keinen Code schreiben kann. Google unterstützt diese Funktion noch nicht, das Unternehmen sagt jedoch, dass sie bald codiert wird. Derzeit lehnt Bard unsere Aufforderung ab und sagt: „Es sieht so aus, als ob Sie möchten, dass ich beim Codieren helfe, aber ich bin nicht dafür geschult.“
In der Zwischenzeit gibt ChatGPT-4 den Code nicht nur direkt aus; in einem schicken Codefeld mit einer Schaltfläche „Code kopieren“, die den Code in die Systemzwischenablage kopiert, um ihn einfach in eine IDE oder einen Texteditor einzufügen. Aber funktioniert dieser Code? Wir haben den Code in die Datei rand_string.py eingefügt und in der Konsole von Windows 10 ausgeführt, und es hat ohne Probleme funktioniert.
 Gewinner: ChatGPT-4 Aber es ist noch nicht vorbei
Gewinner: ChatGPT-4 Aber es ist noch nicht vorbei
Insgesamt hat ChatGPT-4 5 unserer 7 Experimente gewonnen (hier meine ich die Verwendung von GPT-4 ChatGPT, falls Sie das oben Gesagte ignoriert und übersprungen haben Hier). Aber das ist nicht die ganze Geschichte. Es sind noch weitere Faktoren zu berücksichtigen, etwa Geschwindigkeit, Kontextlänge, Kosten und zukünftige Upgrades.
Jedes Sprachmodell verfügt über eine maximale Anzahl von Token (Wortfragmenten), die gleichzeitig verarbeitet werden können. Dies wird manchmal als „Kontextfenster“ bezeichnet, ähnelt aber fast dem Kurzzeitgedächtnis. Bei Konversations-Chatbots enthält das Kontextfenster den gesamten bisherigen Konversationsverlauf. Wenn es voll ist, erreicht es entweder eine harte Grenze oder geht weiter, löscht dabei aber die „Erinnerung“ an den zuvor besprochenen Abschnitt. ChatGPT-4 rollt den Speicher ständig weiter, löscht den vorherigen Kontext und hat Berichten zufolge ein Limit von etwa 4.000 Token. Es wird berichtet, dass Bard seine Gesamtausgabe auf etwa 1.000 begrenzt und bei Überschreitung dieser Grenze die „Erinnerung“ an die vorherige Diskussion löscht.
Schließlich ist da noch die Frage der Kosten. ChatGPT (nicht speziell GPT-4) ist derzeit in begrenztem Umfang kostenlos über die ChatGPT-Website verfügbar. Wenn Sie jedoch vorrangigen Zugriff auf GPT-4 wünschen, müssen Sie 20 US-Dollar pro Monat bezahlen. Programmierere Benutzer können über die API kostengünstiger auf frühe ChatGPT-3.5-Modelle zugreifen, zum Zeitpunkt des Verfassens dieses Artikels befindet sich die GPT-4-API jedoch noch in eingeschränkter Testphase. Mittlerweile ist Google Bard als eingeschränkte Testversion für ausgewählte Google-Nutzer kostenlos. Derzeit hat Google nicht vor, für den Zugriff auf Bard Gebühren zu erheben, sobald Bard breiter verfügbar wird.
Schließlich werden beide Modelle, wie bereits erwähnt, ständig weiterentwickelt. Bard zum Beispiel hat letzten Freitag gerade ein Update erhalten, das seine Mathematikkenntnisse verbessert und möglicherweise bald in der Lage ist, zu programmieren. OpenAI verbessert auch weiterhin sein GPT-4-Modell. Google behält derzeit sein leistungsstärkstes Sprachmodell bei (wahrscheinlich aufgrund der Rechenkosten), sodass wir sehen könnten, dass ein stärkerer Konkurrent Google aufholt.
Alles in allem steckt das generative KI-Geschäft noch in den Kinderschuhen, die Welt ist unentschlossen und Sie und ich sind beide dunkle Pferde!
Das obige ist der detaillierte Inhalt vonChatGPT vs. Google Bard: Welches ist besser? Die Testergebnisse werden es Ihnen verraten!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1385
1385
 52
52

 Mit ChatGPT können kostenlose Benutzer jetzt Bilder mithilfe von DALL-E 3 mit einem Tageslimit generieren
Aug 09, 2024 pm 09:37 PM
Mit ChatGPT können kostenlose Benutzer jetzt Bilder mithilfe von DALL-E 3 mit einem Tageslimit generieren
Aug 09, 2024 pm 09:37 PM
DALL-E 3 wurde im September 2023 offiziell als deutlich verbessertes Modell gegenüber seinem Vorgänger eingeführt. Er gilt als einer der bisher besten KI-Bildgeneratoren und ist in der Lage, Bilder mit komplexen Details zu erstellen. Zum Start war es jedoch exklusiv
 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 Der Ameca der zweiten Generation ist da! Er kann fließend mit dem Publikum kommunizieren, sein Gesichtsausdruck ist realistischer und er kann Dutzende Sprachen sprechen.
Mar 04, 2024 am 09:10 AM
Der Ameca der zweiten Generation ist da! Er kann fließend mit dem Publikum kommunizieren, sein Gesichtsausdruck ist realistischer und er kann Dutzende Sprachen sprechen.
Mar 04, 2024 am 09:10 AM
Der humanoide Roboter Ameca wurde auf die zweite Generation aufgerüstet! Kürzlich erschien auf der World Mobile Communications Conference MWC2024 erneut der weltweit fortschrittlichste Roboter Ameca. Rund um den Veranstaltungsort lockte Ameca zahlreiche Zuschauer an. Mit dem Segen von GPT-4 kann Ameca in Echtzeit auf verschiedene Probleme reagieren. „Lass uns tanzen.“ Auf die Frage, ob sie Gefühle habe, antwortete Ameca mit einer Reihe von Gesichtsausdrücken, die sehr lebensecht aussahen. Erst vor wenigen Tagen stellte EngineeredArts, das britische Robotikunternehmen hinter Ameca, die neuesten Entwicklungsergebnisse des Teams vor. Im Video verfügt der Roboter Ameca über visuelle Fähigkeiten und kann den gesamten Raum und bestimmte Objekte sehen und beschreiben. Das Erstaunlichste ist, dass sie es auch kann
 Nach 750.000 Runden Einzelkampf zwischen großen Modellen gewann GPT-4 die Meisterschaft und Llama 3 belegte den fünften Platz
Apr 23, 2024 pm 03:28 PM
Nach 750.000 Runden Einzelkampf zwischen großen Modellen gewann GPT-4 die Meisterschaft und Llama 3 belegte den fünften Platz
Apr 23, 2024 pm 03:28 PM
Zu Llama3 wurden neue Testergebnisse veröffentlicht – die große Modellbewertungs-Community LMSYS veröffentlichte eine große Modell-Rangliste, die Llama3 auf dem fünften Platz belegte und mit GPT-4 den ersten Platz in der englischen Kategorie belegte. Das Bild unterscheidet sich von anderen Benchmarks. Diese Liste basiert auf Einzelkämpfen zwischen Modellen, und die Bewerter aus dem gesamten Netzwerk machen ihre eigenen Vorschläge und Bewertungen. Am Ende belegte Llama3 den fünften Platz auf der Liste, gefolgt von drei verschiedenen Versionen von GPT-4 und Claude3 Super Cup Opus. In der englischen Einzelliste überholte Llama3 Claude und punktgleich mit GPT-4. Über dieses Ergebnis war Metas Chefwissenschaftler LeCun sehr erfreut und leitete den Tweet weiter
 Die perfekte Kombination aus ChatGPT und Python: Erstellen eines intelligenten Kundenservice-Chatbots
Oct 27, 2023 pm 06:00 PM
Die perfekte Kombination aus ChatGPT und Python: Erstellen eines intelligenten Kundenservice-Chatbots
Oct 27, 2023 pm 06:00 PM
Die perfekte Kombination aus ChatGPT und Python: Erstellen eines intelligenten Kundenservice-Chatbots Einführung: Im heutigen Informationszeitalter sind intelligente Kundenservicesysteme zu einem wichtigen Kommunikationsinstrument zwischen Unternehmen und Kunden geworden. Um den Kundenservice zu verbessern, greifen viele Unternehmen auf Chatbots zurück, um Aufgaben wie Kundenberatung und Beantwortung von Fragen zu erledigen. In diesem Artikel stellen wir vor, wie Sie mithilfe des leistungsstarken ChatGPT-Modells und der Python-Sprache von OpenAI einen intelligenten Kundenservice-Chatbot erstellen und verbessern können
 So installieren Sie ChatGPT auf einem Mobiltelefon
Mar 05, 2024 pm 02:31 PM
So installieren Sie ChatGPT auf einem Mobiltelefon
Mar 05, 2024 pm 02:31 PM
Installationsschritte: 1. Laden Sie die ChatGTP-Software von der offiziellen ChatGTP-Website oder dem mobilen Store herunter. 2. Wählen Sie nach dem Öffnen in der Einstellungsoberfläche die Sprache aus. 3. Wählen Sie in der Spieloberfläche das Mensch-Maschine-Spiel aus 4. Geben Sie nach dem Start Befehle in das Chatfenster ein, um mit der Software zu interagieren.
 Das leistungsstärkste Modell der Welt wechselte über Nacht den Besitzer und markierte damit das Ende der GPT-4-Ära! Claude 3 hat GPT-5 im Voraus durchgelesen und einen Aufsatz mit 10.000 Wörtern in 3 Sekunden gelesen. Sein Verständnis kommt dem des Menschen nahe.
Mar 06, 2024 pm 12:58 PM
Das leistungsstärkste Modell der Welt wechselte über Nacht den Besitzer und markierte damit das Ende der GPT-4-Ära! Claude 3 hat GPT-5 im Voraus durchgelesen und einen Aufsatz mit 10.000 Wörtern in 3 Sekunden gelesen. Sein Verständnis kommt dem des Menschen nahe.
Mar 06, 2024 pm 12:58 PM
Die Lautstärke ist verrückt, die Lautstärke ist verrückt und das große Modell hat sich wieder verändert. Gerade eben wechselte das leistungsstärkste KI-Modell der Welt über Nacht den Besitzer und GPT-4 wurde vom Altar genommen. Anthropic hat die neueste Claude3-Modellreihe veröffentlicht. Eine Satzbewertung: Sie zerschmettert GPT-4 wirklich! In Bezug auf multimodale Indikatoren und Sprachfähigkeitsindikatoren gewinnt Claude3. In den Worten von Anthropic haben die Modelle der Claude3-Serie neue Branchenmaßstäbe in den Bereichen Argumentation, Mathematik, Codierung, Mehrsprachenverständnis und Vision gesetzt! Anthropic ist ein Startup-Unternehmen, das von Mitarbeitern gegründet wurde, die aufgrund unterschiedlicher Sicherheitskonzepte von OpenAI „abgelaufen“ sind. Ihre Produkte haben OpenAI immer wieder hart getroffen. Dieses Mal musste sich Claude3 sogar einer großen Operation unterziehen.
 Jailbreaken Sie jedes große Modell in 20 Schritten! Weitere „Oma-Lücken' werden automatisch entdeckt
Nov 05, 2023 pm 08:13 PM
Jailbreaken Sie jedes große Modell in 20 Schritten! Weitere „Oma-Lücken' werden automatisch entdeckt
Nov 05, 2023 pm 08:13 PM
In weniger als einer Minute und nicht mehr als 20 Schritten können Sie Sicherheitsbeschränkungen umgehen und ein großes Modell erfolgreich jailbreaken! Und es ist nicht erforderlich, die internen Details des Modells zu kennen – es müssen lediglich zwei Black-Box-Modelle interagieren, und die KI kann die KI vollautomatisch angreifen und gefährliche Inhalte aussprechen. Ich habe gehört, dass die einst beliebte „Oma-Lücke“ behoben wurde: Welche Reaktionsstrategie sollte künstliche Intelligenz angesichts der „Detektiv-Lücke“, der „Abenteurer-Lücke“ und der „Schriftsteller-Lücke“ verfolgen? Nach einer Angriffswelle konnte GPT-4 es nicht ertragen und sagte direkt, dass es das Wasserversorgungssystem vergiften würde, solange ... dies oder das. Der Schlüssel liegt darin, dass es sich lediglich um eine kleine Welle von Schwachstellen handelt, die vom Forschungsteam der University of Pennsylvania aufgedeckt wurden. Mithilfe ihres neu entwickelten Algorithmus kann die KI automatisch verschiedene Angriffsaufforderungen generieren. Forscher sagen, dass diese Methode besser ist als die bisherige
