
 Technologie-Peripheriegeräte
KI
Interpretation von CRISP-ML(Q): Lebenszyklusprozess des maschinellen Lernens
Technologie-Peripheriegeräte
KI
Interpretation von CRISP-ML(Q): Lebenszyklusprozess des maschinellen Lernens
Interpretation von CRISP-ML(Q): Lebenszyklusprozess des maschinellen Lernens

Übersetzer |. Bugatti
Rezensent |. Derzeit gibt es keine Standardpraktiken für die Erstellung und Verwaltung von Anwendungen für maschinelles Lernen (ML). Projekte für maschinelles Lernen sind schlecht organisiert, nicht wiederholbar und scheitern auf lange Sicht tendenziell. Daher benötigen wir einen Prozess, der uns dabei hilft, Qualität, Nachhaltigkeit, Robustheit und Kostenmanagement während des gesamten Lebenszyklus des maschinellen Lernens aufrechtzuerhalten. Abbildung 1: Lebenszyklusprozess der maschinellen Lernentwicklung Lernen von Produktqualität.
CRISP-ML (Q) besteht aus sechs separaten Phasen:
1. Datenvorbereitung 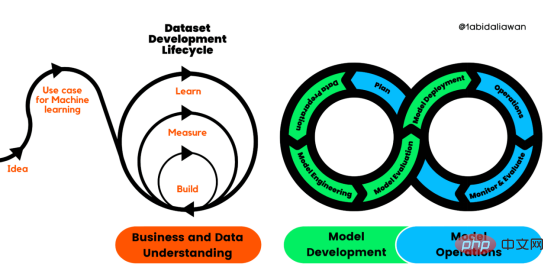
Abbildung 2. Qualitätssicherung in jeder Phase
Qualitätssicherungsmethoden werden in jeder Phase des Frameworks eingeführt. Dieser Ansatz hat Anforderungen und Einschränkungen, wie z. B. Leistungsmetriken, Datenqualitätsanforderungen und Robustheit. Es trägt dazu bei, Risiken zu reduzieren, die den Erfolg von Anwendungen für maschinelles Lernen beeinträchtigen. Dies kann durch kontinuierliche Überwachung und Wartung des gesamten Systems erreicht werden.
Zum Beispiel: In E-Commerce-Unternehmen führen Daten- und Konzeptabweichungen zu einer Modellverschlechterung. Wenn wir keine Systeme zur Überwachung dieser Änderungen einsetzen, wird das Unternehmen Verluste erleiden, d. h. Kunden verlieren.
Geschäfts- und Datenverständnis
Zu Beginn des Entwicklungsprozesses müssen wir den Projektumfang, die Erfolgskriterien und die Machbarkeit der ML-Anwendung bestimmen. Danach begannen wir mit der Datenerfassung und Qualitätsüberprüfung. Der Prozess ist langwierig und herausfordernd.
Umfang:Was wir durch den Einsatz eines maschinellen Lernprozesses erreichen wollen. Geht es darum, Kunden zu binden oder die Betriebskosten durch Automatisierung zu senken? 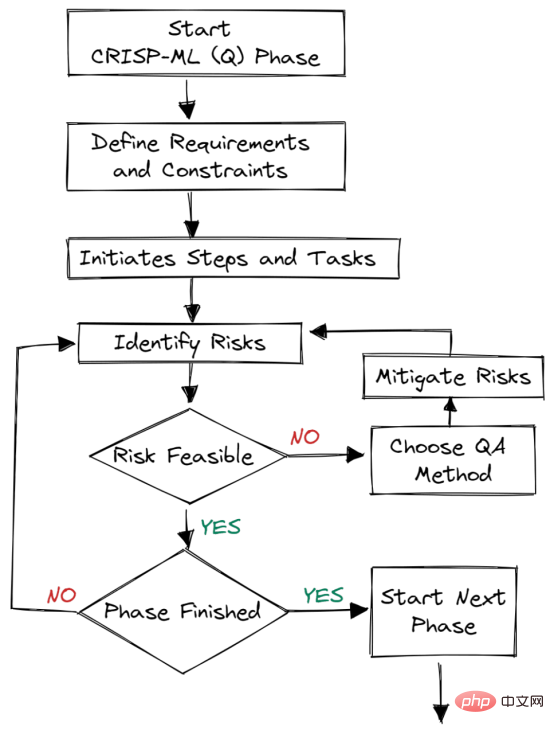
Erfolgskriterien:
Wir müssen klare und messbare geschäftliche, maschinelle Lern- (statistische Indikatoren) und wirtschaftliche (KPI) Erfolgsindikatoren definieren.Machbarkeit:
Wir müssen Datenverfügbarkeit, Eignung für maschinelle Lernanwendungen, rechtliche Einschränkungen, Robustheit, Skalierbarkeit, Interpretierbarkeit und Ressourcenanforderungen sicherstellen.Datenerfassung:
Ermöglichen Sie die Reproduzierbarkeit, indem Sie Daten sammeln, diese versionieren und einen konstanten Fluss realer und generierter Daten sicherstellen.Überprüfung der Datenqualität:
Stellen Sie die Qualität sicher, indem Sie Datenbeschreibungen, Anforderungen und Validierungen pflegen.Um Qualität und Reproduzierbarkeit sicherzustellen, müssen wir die statistischen Eigenschaften der Daten und den Datengenerierungsprozess aufzeichnen.
DatenvorbereitungDer zweite Schritt ist sehr einfach. Wir bereiten die Daten für die Modellierungsphase vor. Dazu gehören Datenauswahl, Datenbereinigung, Feature-Engineering, Datenverbesserung und -normalisierung.
1. Wir beginnen mit der Funktionsauswahl, der Datenauswahl und dem Umgang mit unausgeglichenen Klassen durch Überabtastung oder Unterabtastung.2. Konzentrieren Sie sich dann auf die Reduzierung von Rauschen und den Umgang mit fehlenden Werten. Zur Qualitätssicherung werden wir Dateneinheitstests hinzufügen, um fehlerhafte Werte zu reduzieren.
3. Je nach Modell führen wir Feature Engineering und Datenerweiterung wie One-Hot-Encoding und Clustering durch.4. Daten normalisieren und erweitern. Dadurch wird das Risiko verzerrter Merkmale verringert.
Um die Reproduzierbarkeit sicherzustellen, haben wir Datenmodellierungs-, Transformations- und Feature-Engineering-Pipelines erstellt. ModellentwicklungDie Einschränkungen und Anforderungen der Geschäfts- und Datenverständnisphase bestimmen die Modellierungsphase. Wir müssen die Geschäftsprobleme verstehen und wissen, wie wir Modelle für maschinelles Lernen entwickeln, um sie zu lösen. Wir werden uns auf die Modellauswahl, -optimierung und -schulung konzentrieren, um Modellleistungsmetriken, Robustheit, Skalierbarkeit, Interpretierbarkeit sowie die Optimierung von Speicher- und Rechenressourcen sicherzustellen. 1. Forschung zu Modellarchitektur und ähnlichen Geschäftsproblemen. 2. Definieren Sie Modellleistungsindikatoren. 3. Modellauswahl. 4. Fachwissen durch Einbindung von Experten verstehen. 5. Modeltraining. 6. Modellkomprimierung und -integration. Um Qualität und Reproduzierbarkeit sicherzustellen, speichern und versionieren wir Modellmetadaten, wie z. B. Modellarchitektur, Trainings- und Validierungsdaten, Hyperparameter und Umgebungsbeschreibungen. Abschließend werden wir ML-Experimente verfolgen und ML-Pipelines erstellen, um wiederholbare Trainingsprozesse zu erstellen. ModellbewertungIn dieser Phase testen wir das Modell und stellen sicher, dass es für den Einsatz bereit ist.- Wir testen die Modellleistung anhand des Testdatensatzes.
- Bewerten Sie die Robustheit des Modells, indem Sie zufällige oder gefälschte Daten bereitstellen.
- Verbessern Sie die Interpretierbarkeit des Modells, um regulatorische Anforderungen zu erfüllen.
- Vergleichen Sie die Ergebnisse automatisch oder mit Domänenexperten mit ersten Erfolgskennzahlen.
Jeder Schritt der Beurteilungsphase wird zur Qualitätssicherung protokolliert.
Modellbereitstellung
Die Modellbereitstellung ist die Phase, in der wir Modelle für maschinelles Lernen in bestehende Systeme integrieren. Das Modell kann auf Servern, Browsern, Software und Edge-Geräten bereitgestellt werden. Vorhersagen aus dem Modell sind in BI-Dashboards, APIs, Webanwendungen und Plug-ins verfügbar.
Modellbereitstellungsprozess:
- Definieren Sie Hardware-Inferenz.
- Modellbewertung in der Produktionsumgebung.
- Stellen Sie die Benutzerakzeptanz und Benutzerfreundlichkeit sicher.
- Stellen Sie Backup-Pläne bereit, um Verluste zu minimieren.
- Bereitstellungsstrategie.
Überwachung und Wartung
Modelle in Produktionsumgebungen erfordern eine kontinuierliche Überwachung und Wartung. Wir überwachen die Aktualität des Modells, die Hardwareleistung und die Softwareleistung.
Kontinuierliche Überwachung ist der erste Teil des Prozesses; wenn die Leistung unter einen Schwellenwert fällt, wird automatisch entschieden, das Modell anhand neuer Daten neu zu trainieren. Darüber hinaus beschränkt sich der Wartungsteil nicht nur auf die Umschulung des Modells. Es erfordert Entscheidungsmechanismen, die Erfassung neuer Daten, die Aktualisierung von Software und Hardware sowie die Verbesserung von ML-Prozessen auf der Grundlage von Geschäftsanwendungsfällen.
Kurz gesagt handelt es sich um die kontinuierliche Integration, Schulung und Bereitstellung von ML-Modellen.
Fazit
Das Training und die Validierung von Modellen ist ein kleiner Teil von ML-Anwendungen. Um eine erste Idee in die Realität umzusetzen, sind mehrere Prozesse erforderlich. In diesem Artikel stellen wir CRISP-ML(Q) vor und wie es sich auf Risikobewertung und Qualitätssicherung konzentriert.
Wir definieren zunächst die Geschäftsziele, sammeln und bereinigen Daten, erstellen das Modell, verifizieren das Modell mit Testdatensätzen und stellen es dann in der Produktionsumgebung bereit.
Die Schlüsselkomponenten dieses Frameworks sind die kontinuierliche Überwachung und Wartung. Wir überwachen Daten sowie Software- und Hardware-Metriken, um zu entscheiden, ob das Modell neu trainiert oder das System aktualisiert werden soll.
Wenn Sie neu im Bereich maschineller Lernvorgänge sind und mehr erfahren möchten, lesen Sie den kostenlosen MLOps-Kurs, der von DataTalks.Club geprüft wurde. In allen sechs Phasen sammeln Sie praktische Erfahrungen und verstehen die praktische Umsetzung von CRISP-ML.
Originaltitel: Making Sense of CRISP-ML(Q): The Machine Learning Lifecycle Process, Autor: Abid Ali Awan
Das obige ist der detaillierte Inhalt vonInterpretation von CRISP-ML(Q): Lebenszyklusprozess des maschinellen Lernens. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 KI-Startups wechselten gemeinsam ihre Jobs zu OpenAI, und das Sicherheitsteam formierte sich neu, nachdem Ilya gegangen war!
Jun 08, 2024 pm 01:00 PM
KI-Startups wechselten gemeinsam ihre Jobs zu OpenAI, und das Sicherheitsteam formierte sich neu, nachdem Ilya gegangen war!
Jun 08, 2024 pm 01:00 PM
Letzte Woche wurde OpenAI inmitten der Welle interner Kündigungen und externer Kritik von internen und externen Problemen geplagt: - Der Verstoß gegen die Schwester der Witwe löste weltweit hitzige Diskussionen aus - Mitarbeiter, die „Overlord-Klauseln“ unterzeichneten, wurden einer nach dem anderen entlarvt – Internetnutzer listeten Ultramans „ Sieben Todsünden“ – Gerüchtebekämpfung: Laut durchgesickerten Informationen und Dokumenten, die Vox erhalten hat, war sich die leitende Führung von OpenAI, darunter Altman, dieser Eigenkapitalrückgewinnungsbestimmungen wohl bewusst und hat ihnen zugestimmt. Darüber hinaus steht OpenAI vor einem ernsten und dringenden Problem – der KI-Sicherheit. Die jüngsten Abgänge von fünf sicherheitsrelevanten Mitarbeitern, darunter zwei der prominentesten Mitarbeiter, und die Auflösung des „Super Alignment“-Teams haben die Sicherheitsprobleme von OpenAI erneut ins Rampenlicht gerückt. Das Fortune-Magazin berichtete, dass OpenA
 So bewerten Sie die Kosteneffizienz der kommerziellen Unterstützung für Java-Frameworks
Jun 05, 2024 pm 05:25 PM
So bewerten Sie die Kosteneffizienz der kommerziellen Unterstützung für Java-Frameworks
Jun 05, 2024 pm 05:25 PM
Die Bewertung des Kosten-/Leistungsverhältnisses des kommerziellen Supports für ein Java-Framework umfasst die folgenden Schritte: Bestimmen Sie das erforderliche Maß an Sicherheit und Service-Level-Agreement-Garantien (SLA). Die Erfahrung und das Fachwissen des Forschungsunterstützungsteams. Erwägen Sie zusätzliche Services wie Upgrades, Fehlerbehebung und Leistungsoptimierung. Wägen Sie die Kosten für die Geschäftsunterstützung gegen Risikominderung und Effizienzsteigerung ab.
 Das 70B-Modell generiert 1.000 Token in Sekunden, das Umschreiben des Codes übertrifft GPT-4o, vom Cursor-Team, einem von OpenAI investierten Code-Artefakt
Jun 13, 2024 pm 03:47 PM
Das 70B-Modell generiert 1.000 Token in Sekunden, das Umschreiben des Codes übertrifft GPT-4o, vom Cursor-Team, einem von OpenAI investierten Code-Artefakt
Jun 13, 2024 pm 03:47 PM
Beim Modell 70B können 1000 Token in Sekunden generiert werden, was fast 4000 Zeichen entspricht! Die Forscher haben Llama3 verfeinert und einen Beschleunigungsalgorithmus eingeführt. Im Vergleich zur nativen Version ist die Geschwindigkeit 13-mal höher! Es ist nicht nur schnell, seine Leistung bei Code-Rewriting-Aufgaben übertrifft sogar GPT-4o. Diese Errungenschaft stammt von anysphere, dem Team hinter dem beliebten KI-Programmierartefakt Cursor, und auch OpenAI beteiligte sich an der Investition. Sie müssen wissen, dass bei Groq, einem bekannten Framework zur schnellen Inferenzbeschleunigung, die Inferenzgeschwindigkeit von 70BLlama3 nur mehr als 300 Token pro Sekunde beträgt. Aufgrund der Geschwindigkeit von Cursor kann man sagen, dass eine nahezu sofortige vollständige Bearbeitung der Codedatei möglich ist. Manche Leute nennen es einen guten Kerl, wenn man Curs sagt
 Wie ist die Lernkurve von PHP-Frameworks im Vergleich zu anderen Sprach-Frameworks?
Jun 06, 2024 pm 12:41 PM
Wie ist die Lernkurve von PHP-Frameworks im Vergleich zu anderen Sprach-Frameworks?
Jun 06, 2024 pm 12:41 PM
Die Lernkurve eines PHP-Frameworks hängt von Sprachkenntnissen, Framework-Komplexität, Dokumentationsqualität und Community-Unterstützung ab. Die Lernkurve von PHP-Frameworks ist im Vergleich zu Python-Frameworks höher und im Vergleich zu Ruby-Frameworks niedriger. Im Vergleich zu Java-Frameworks haben PHP-Frameworks eine moderate Lernkurve, aber eine kürzere Einstiegszeit.
 Wie wirken sich die Lightweight-Optionen von PHP-Frameworks auf die Anwendungsleistung aus?
Jun 06, 2024 am 10:53 AM
Wie wirken sich die Lightweight-Optionen von PHP-Frameworks auf die Anwendungsleistung aus?
Jun 06, 2024 am 10:53 AM
Das leichte PHP-Framework verbessert die Anwendungsleistung durch geringe Größe und geringen Ressourcenverbrauch. Zu seinen Merkmalen gehören: geringe Größe, schneller Start, geringer Speicherverbrauch, verbesserte Reaktionsgeschwindigkeit und Durchsatz sowie reduzierter Ressourcenverbrauch. Praktischer Fall: SlimFramework erstellt eine REST-API, nur 500 KB, hohe Reaktionsfähigkeit und hoher Durchsatz
 Welche Anwendungen gibt es für Go-Coroutinen in der künstlichen Intelligenz und im maschinellen Lernen?
Jun 05, 2024 pm 03:23 PM
Welche Anwendungen gibt es für Go-Coroutinen in der künstlichen Intelligenz und im maschinellen Lernen?
Jun 05, 2024 pm 03:23 PM
Zu den Anwendungen von Go-Coroutinen im Bereich der künstlichen Intelligenz und des maschinellen Lernens gehören: Echtzeittraining und -vorhersage: parallele Verarbeitungsaufgaben zur Verbesserung der Leistung. Parallele Hyperparameteroptimierung: Erkunden Sie verschiedene Einstellungen gleichzeitig, um das Training zu beschleunigen. Verteiltes Computing: Aufgaben einfach verteilen und die Vorteile der Cloud oder des Clusters nutzen.
 China Mobile: Die Menschheit tritt in die vierte industrielle Revolution ein und kündigte offiziell „drei Pläne' an
Jun 27, 2024 am 10:29 AM
China Mobile: Die Menschheit tritt in die vierte industrielle Revolution ein und kündigte offiziell „drei Pläne' an
Jun 27, 2024 am 10:29 AM
Laut Nachrichten vom 26. Juni hielt Yang Jie, Vorsitzender von China Mobile, bei der Eröffnungszeremonie der World Mobile Communications Conference Shanghai (MWC Shanghai) 2024 eine Rede. Er sagte, dass die menschliche Gesellschaft derzeit in die vierte industrielle Revolution eintritt, die von Informationen dominiert und tief in Informationen und Energie integriert ist, d. h. die „Revolution der digitalen Intelligenz“, und dass sich die Bildung neuer Produktivkräfte beschleunigt. Yang Jie glaubt, dass jede Runde der industriellen Revolution darauf basiert, von der „Mechanisierungsrevolution“, angetrieben durch Dampfmaschinen, über die „Elektrifizierungsrevolution“, angetrieben durch Elektrizität und Verbrennungsmotoren, bis hin zur „Informationsrevolution“, angetrieben durch Computer und das Internet „Information und „Energie“ ist die Hauptlinie, die Produktivitätsentwicklung bringt
