

Beim autonomen Fahren wurde die Zielerkennung durch RGB-Bilder oder Lidar-Punktwolken umfassend erforscht. Es bleibt jedoch eine Herausforderung, diese beiden Datenquellen einander ergänzend und vorteilhaft zu gestalten. AutoAlignV1 und AutoAlignV2 sind hauptsächlich die Arbeit der University of Science and Technology of China, des Harbin Institute of Technology und von SenseTime (ursprünglich einschließlich der Chinese University of Hong Kong und der Tsinghua University).
AutoAlignV1 stammt aus dem arXiv-Artikel „AutoAlign: Pixel-Instance Feature Aggregation for Multi-Modal 3D Object Detection“, hochgeladen im April 2022.

Dieses Papier schlägt eine automatische Feature-Fusion-Strategie AutoAlign V1 für die 3D-Zielerkennung vor. Verwenden Sie eine lernbare Ausrichtungskarte, um die Zuordnungsbeziehung zwischen dem Bild und der Punktwolke zu modellieren, anstatt eine deterministische Entsprechung mit der Kameraprojektionsmatrix herzustellen. Dieses Diagramm ermöglicht es dem Modell, nichthomomorphe Merkmale automatisch auf dynamische und datengesteuerte Weise auszurichten. Insbesondere ist ein Modul zur Ausrichtung von Aufmerksamkeitsmerkmalen darauf ausgelegt, Bildmerkmale jedes Voxels auf Pixelebene adaptiv zu aggregieren. Um die semantische Konsistenz im Feature-Alignment-Prozess zu verbessern, wurde außerdem ein selbstüberwachtes modalübergreifendes Feature-Interaktionsmodul entwickelt, mit dem das Modell die Feature-Aggregation anhand von Features auf Instanzebene lernen kann.
Multimodale 3D-Objektdetektoren können grob in zwei Kategorien unterteilt werden: Fusion auf Entscheidungsebene und Fusion auf Merkmalsebene. Ersteres erkennt Objekte in ihren jeweiligen Modi und bringt dann die Begrenzungsrahmen im 3D-Raum zusammen. Im Gegensatz zur Fusion auf Entscheidungsebene kombiniert die Fusion auf Merkmalsebene multimodale Merkmale in einer einzigen Darstellung, um Objekte zu erkennen. Daher kann der Detektor während der Inferenzphase die Merkmale verschiedener Modalitäten vollständig nutzen. Vor diesem Hintergrund wurden in letzter Zeit weitere Fusionsmethoden auf Merkmalsebene entwickelt.
Ein Job projiziert jeden Punkt auf die Bildebene und erhält die entsprechenden Bildmerkmale durch bilineare Interpolation. Obwohl die Merkmalsaggregation auf Pixelebene fein durchgeführt wird, gehen dichte Muster im Bildbereich aufgrund der spärlichen Verschmelzungspunkte verloren, d. h. die semantische Konsistenz der Bildmerkmale wird zerstört.
Eine weitere Arbeit nutzt die anfängliche Lösung des 3D-Detektors, um RoI-Merkmale verschiedener Modalitäten zu erhalten und sie zur Merkmalsfusion miteinander zu verbinden. Durch die Fusion auf Instanzebene bleibt die semantische Konsistenz erhalten, es bestehen jedoch Probleme wie grobe Feature-Aggregation und fehlende 2D-Informationen in der ersten Phase der Angebotserstellung.
Um diese beiden Methoden vollständig zu nutzen, schlagen die Autoren ein integriertes multimodales Feature-Fusion-Framework für die 3D-Objekterkennung mit dem Namen AutoAlign vor. Es ermöglicht dem Detektor, modalübergreifende Merkmale auf adaptive Weise zu aggregieren, was sich bei der Modellierung von Beziehungen zwischen nichthomomorphen Darstellungen als effektiv erweist. Gleichzeitig nutzt es eine feinkörnige Feature-Aggregation auf Pixelebene und behält gleichzeitig die semantische Konsistenz durch Feature-Interaktion auf Instanzebene bei.
Wie in der Abbildung gezeigt: Die Feature-Interaktion funktioniert auf zwei Ebenen: (i) Feature-Aggregation auf Pixelebene; (ii) Feature-Interaktion auf Instanzebene.
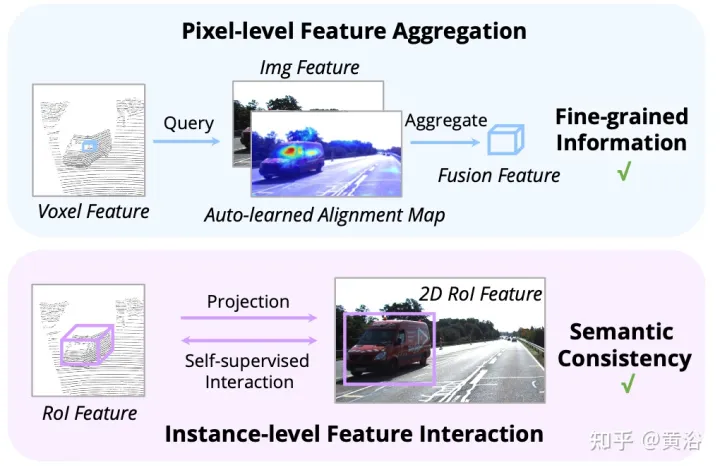
Frühere Arbeiten nutzen hauptsächlich Kameraprojektionsmatrizen, um Bild- und Punktmerkmale deterministisch auszurichten. Dieser Ansatz ist effektiv, kann jedoch zwei potenzielle Probleme mit sich bringen: 1) Der Punkt kann keine umfassendere Sicht auf die Bilddaten erhalten und 2) nur die Positionskonsistenz bleibt erhalten, während die semantische Korrelation ignoriert wird. Aus diesem Grund hat AutoAlign das Modul „Cross Attention Feature Alignment (CAFA)“ entwickelt, um Merkmale zwischen nicht homomorphen Darstellungen adaptiv auszurichten. CAFA (Cross-Attention Feature Alignment)Das Modul verwendet keinen Eins-zu-Eins-Anpassungsmodus, sondern macht jedes Voxel auf das gesamte Bild aufmerksam und konzentriert sich dynamisch auf 2D-Features auf Pixelebene basierend auf einer lernbaren Ausrichtungskarte. Wie in der Abbildung gezeigt: AutoAlign besteht aus zwei Kernkomponenten, die eine Feature-Aggregation auf der Bildebene durchführen und feinkörnige Informationen auf Pixelebene für jedes Voxel-Feature extrahieren Führt eine modalübergreifende Funktionsinteraktion durch und nutzt die Anleitung auf Instanzebene, um die semantische Konsistenz des CAFA-Moduls zu verbessern.
CAFA ist ein feinkörniges Paradigma zum Aggregieren von Bildfunktionen. Es können jedoch keine Informationen auf Instanzebene erfasst werden. Im Gegensatz dazu behält die RoI-basierte Feature-Fusion die Integrität des Objekts bei, leidet jedoch unter grober Feature-Aggregation und fehlenden 2D-Informationen während der Angebotserstellungsphase.
Um die Lücke zwischen der Fusion auf Pixel- und Instanzebene zu schließen, wird das Modul „Selbstüberwachte Cross-modal Feature Interaction (SCFI)“ eingeführt, um das Erlernen von CAFA zu leiten. Es nutzt die endgültigen Vorhersagen des 3D-Detektors direkt als Vorschläge und nutzt Bild- und Punktmerkmale für die genaue Erstellung von Vorschlägen. Anstatt modalübergreifende Merkmale zur weiteren Optimierung des Begrenzungsrahmens miteinander zu verketten, werden außerdem Ähnlichkeitsbeschränkungen zu modalübergreifenden Merkmalspaaren als Anleitung auf Instanzebene für die Merkmalsausrichtung hinzugefügt. Anhand einer 2D-Feature-Karte und entsprechender voxelisierter 3D-Features werden N regionale 3D-Erkennungsrahmen zufällig abgetastet und dann mithilfe der Kameraprojektionsmatrix auf eine 2D-Ebene projiziert, wodurch ein Satz von 2D-Rahmenpaaren generiert wird. Sobald die gepaarten Boxen erhalten wurden, werden 2DRoIAlign und 3DRoIPooling in 2D- und 3D-Feature-Räumen verwendet, um die jeweiligen RoI-Features zu erhalten.
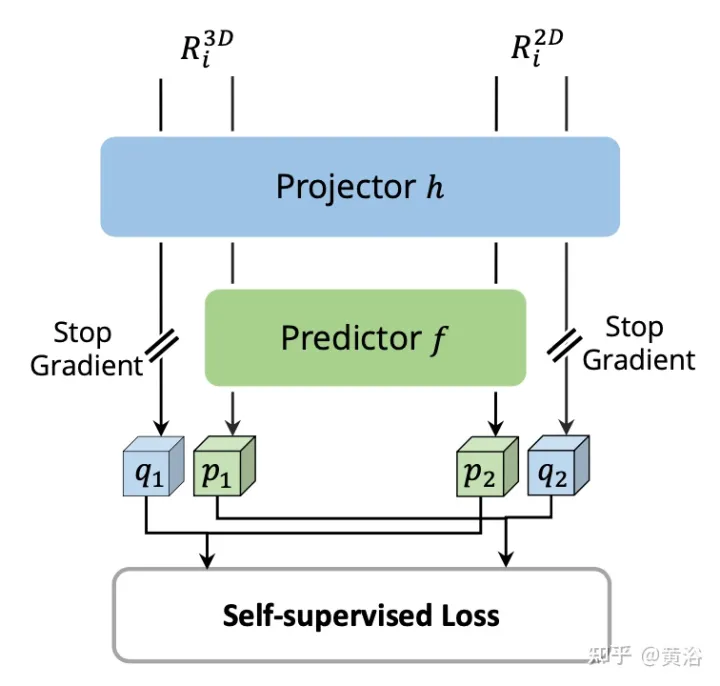
Führen Sie für jedes Paar von 2D- und 3D-RoI-Features eine
Selbstüberwachte modalübergreifende Feature-Interaktion (SCFI)für die Features aus dem Bildzweig und die voxelisierten Features aus dem Punktzweig durch. Beide Merkmale werden in einen Projektionskopf eingespeist, der die Ausgabe einer Modalität an die andere anpasst. Führen Sie einen Vorhersagekopf mit zwei vollständig verbundenen Schichten ein. Wie in der Abbildung gezeigt:
 Obwohl das Lernen mit mehreren Aufgaben sehr effektiv ist, diskutieren nur wenige Arbeiten die gemeinsame Erkennung von Bilddomänen und Punktdomänen. Bei den meisten bisherigen Methoden wird das Bild-Backbone direkt mit vorab trainierten Gewichten aus einem externen Datensatz initialisiert. Während der Trainingsphase ist die einzige Überwachung der 3D-Erkennungsverlust, der sich von Punktzweigen ausbreitet. Angesichts der großen Anzahl von Parametern des Bild-Backbones ist es wahrscheinlicher, dass der 2D-Zweig unter impliziter Überwachung eine Überanpassung erreicht. Um die aus Bildern extrahierten Darstellungen zu regulieren, wird der Bildzweig auf Faster R-CNN erweitert und mit einem 2D-Erkennungsverlust überwacht.
Obwohl das Lernen mit mehreren Aufgaben sehr effektiv ist, diskutieren nur wenige Arbeiten die gemeinsame Erkennung von Bilddomänen und Punktdomänen. Bei den meisten bisherigen Methoden wird das Bild-Backbone direkt mit vorab trainierten Gewichten aus einem externen Datensatz initialisiert. Während der Trainingsphase ist die einzige Überwachung der 3D-Erkennungsverlust, der sich von Punktzweigen ausbreitet. Angesichts der großen Anzahl von Parametern des Bild-Backbones ist es wahrscheinlicher, dass der 2D-Zweig unter impliziter Überwachung eine Überanpassung erreicht. Um die aus Bildern extrahierten Darstellungen zu regulieren, wird der Bildzweig auf Faster R-CNN erweitert und mit einem 2D-Erkennungsverlust überwacht.
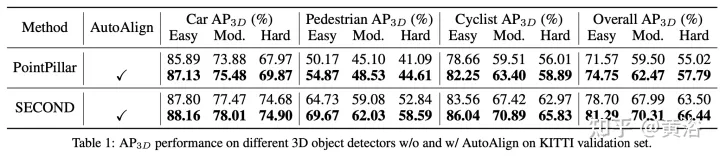
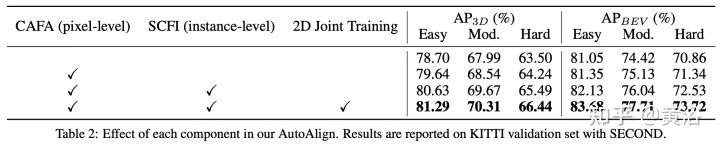
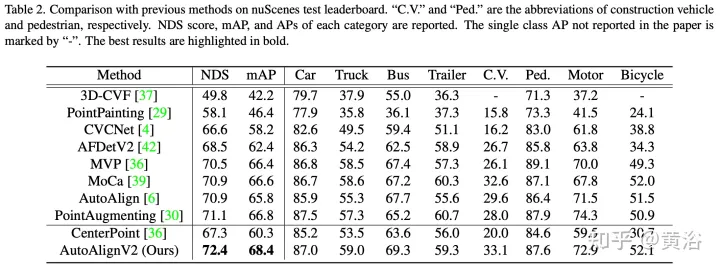
Experimentelle Ergebnisse
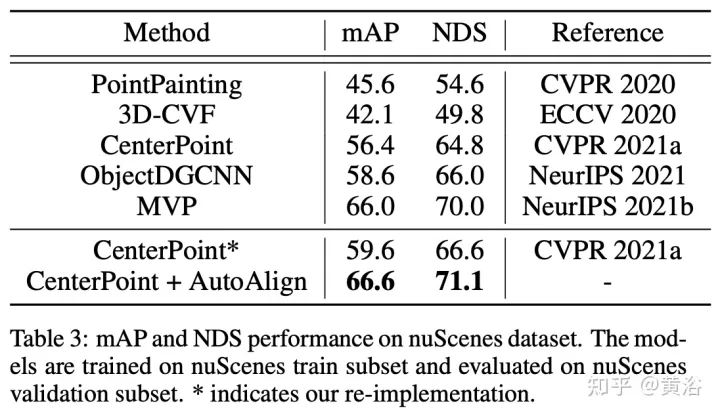
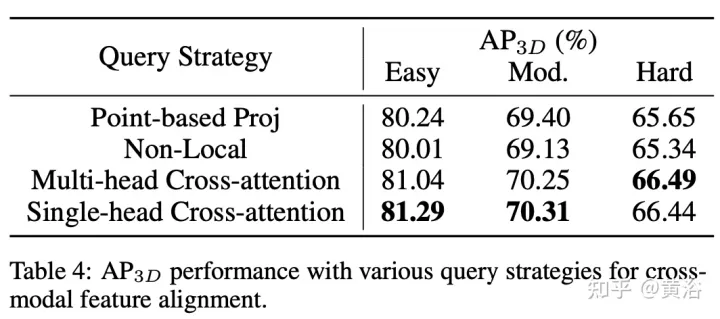 AutoAlignV2 stammt aus „AutoAlignV2: Deformable Feature Aggregation for Dynamic Multi-Modal 3D Object Detection“, hochgeladen im Juli 2022.
AutoAlignV2 stammt aus „AutoAlignV2: Deformable Feature Aggregation for Dynamic Multi-Modal 3D Object Detection“, hochgeladen im Juli 2022.
 Abstract
Abstract
in multimodalen Umgebungen zu überwinden, wird eine einfache und effektive modalübergreifende Verbesserungsstrategie für die konvexe Kombination basierend auf Bildfeldern mit Tiefeninformationen entwickelt. Darüber hinaus ist das Modell durch ein Dropout-Trainingsschema auf Bildebene in der Lage, Schlussfolgerungen auf dynamische Weise durchzuführen. Der Code wird Open Source sein: https://
github.com/zehuichen123/AutoAlignV2.Hinweis: GT-AUG („ZWEITER: Sparsely eingebettete Faltungserkennung“. Sensoren, 2018), Eine Methode zur Datenerweiterung
Hintergrund Wie man die heterogenen Darstellungen von Lidar und Kameras für die 3D-Objekterkennung effektiv kombinieren kann, ist noch nicht vollständig erforscht. Die derzeitige Schwierigkeit beim Training modalübergreifender Detektoren wird auf zwei Aspekte zurückgeführt. Einerseits sind Fusionsstrategien, die Bild- und Rauminformationen kombinieren, noch suboptimal. Aufgrund der heterogenen Darstellung zwischen RGB-Bildern und Punktwolken ist eine sorgfältige Ausrichtung erforderlich, bevor Features zu Clustern zusammengefasst werden. AutoAlign bietet ein erlernbares globales Ausrichtungsmodul zur automatischen Registrierung und erzielt eine gute Leistung. Es muss jedoch mit Hilfe des CSFI-Moduls trainiert werden, um die interne Positionsanpassungsbeziehung zwischen Punkten und Bildpixeln zu erhalten.
Beachten Sie außerdem, dass die operative Komplexität des Stils quadratisch in der Bildgröße ist, sodass es unpraktisch ist, Abfragen auf hochauflösende Feature-Maps anzuwenden. Diese Einschränkung kann zu groben und ungenauen Bildinformationen sowie zum durch FPN verursachten Verlust der hierarchischen Darstellung führen. Andererseits ist die Datenerweiterung, insbesondere GT-AUG, ein wichtiger Schritt für 3D-Detektoren, um wettbewerbsfähige Ergebnisse zu erzielen. Im Hinblick auf multimodale Ansätze besteht eine wichtige Frage darin, wie die Synchronisierung zwischen Bildern und Punktwolken bei der Durchführung von Ausschneide- und Einfügevorgängen aufrechterhalten werden kann. MoCa verwendet arbeitsintensive Maskenannotationen im 2D-Bereich, um genaue Bildmerkmale zu erhalten. Anmerkungen auf Randebene sind ebenfalls geeignet, erfordern jedoch eine ausgefeilte Punktfilterung.
AutoAlignV2 zielt darauf ab, Bildmerkmale effizient zu aggregieren, um die Leistung von 3D-Objektdetektoren weiter zu verbessern. Ausgehend von der Grundarchitektur von AutoAlign: Geben Sie die gepaarten Bilder in ein leichtes Backbone-Netzwerk ResNet ein und geben Sie sie dann in FPN ein, um die Feature-Map zu erhalten. Anschließend werden relevante Bildinformationen über eine lernbare Ausrichtungskarte aggregiert, um die 3D-Darstellung nicht leerer Voxel in der Voxelisierungsphase anzureichern. Schließlich werden die erweiterten Funktionen in die nachfolgende 3D-Erkennungspipeline eingespeist, um Instanzvorhersagen zu generieren.
Das Bild zeigt den Vergleich zwischen AutoAlignV1 und AutoAlignV2: AutoAlignV2 fordert das Ausrichtungsmodul auf, eine allgemeine Zuordnungsbeziehung zu haben, die durch eine deterministische Projektionsmatrix garantiert wird, während die Fähigkeit beibehalten wird, die Feature-Aggregationsposition automatisch anzupassen. Aufgrund seines geringen Rechenaufwands ist AutoAlignV2 in der Lage, mehrschichtige Merkmale hierarchischer Bildinformationen zu aggregieren.
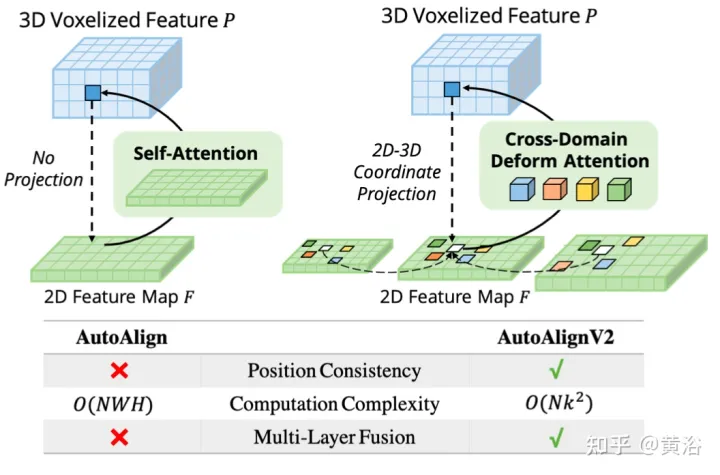
Dieses Paradigma kann heterogene Merkmale datengesteuert aggregieren. Allerdings behindern immer noch zwei große Engpässe die Leistung. Der erste Grund ist die ineffiziente Feature-Aggregation. Obwohl globale Aufmerksamkeitskarten automatisch eine Merkmalsausrichtung zwischen RGB-Bildern und LIDAR-Punkten erreichen, ist der Rechenaufwand hoch. Die zweite Möglichkeit besteht in der komplexen datengestützten Synchronisierung zwischen Bildern und Punkten. GT-AUG ist ein wichtiger Schritt für leistungsstarke 3D-Objektdetektoren, aber wie die semantische Konsistenz zwischen Punkten und Bildern während des Trainings aufrechterhalten werden kann, bleibt ein komplexes Problem.
Wie in der Abbildung gezeigt, besteht AutoAlignV2 aus zwei Teilen: Cross-Domain DeformCAFAModul und Tiefenbewusste GT-AUGDatenverbesserungsstrategie. Es wird auch eine Dropout-Trainingsstrategie auf Bildebene vorgeschlagen, um dies zu ermöglichen dynamischerer Weg zur Vernunft.
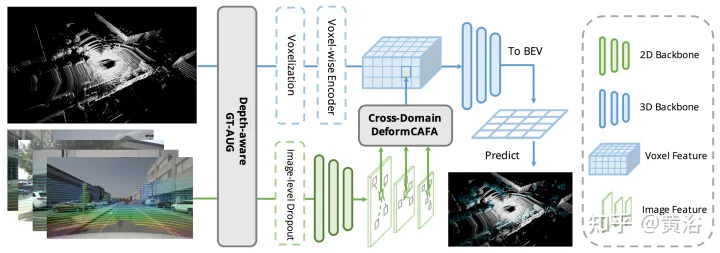
Der Flaschenhals von CAFA besteht darin, alle Pixel als mögliche räumliche Orte zu behandeln. Basierend auf den Eigenschaften von 2D-Bildern befinden sich die relevantesten Informationen hauptsächlich an geometrisch benachbarten Orten. Daher ist es nicht erforderlich, alle Standorte zu berücksichtigen, sondern nur einige Schlüsselpunktbereiche. Wie in der Abbildung gezeigt, wird hier eine neue domänenübergreifende DeformCAFA-Operation eingeführt, die die Stichprobenkandidaten erheblich reduziert und Schlüsselpunktbereiche der Bildebene für jedes Voxel-Abfragemerkmal dynamisch bestimmt.
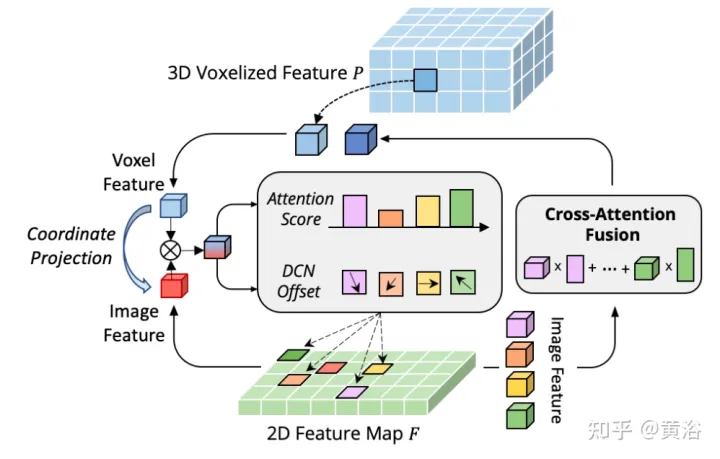
Mit Hilfe dynamisch generierter Sampling-Offsets ist DeformCAFA in der Lage, domänenübergreifende Beziehungen schneller zu modellieren als normale Operationen. Kann eine mehrschichtige Feature-Aggregation durchführen, d. h. die von der FPN-Schicht bereitgestellten hierarchischen Informationen vollständig nutzen. Ein weiterer Vorteil von DeformCAFA besteht darin, dass die Positionskonsistenz mit der Kameraprojektionsmatrix explizit beibehalten wird, um Referenzpunkte zu erhalten. Daher kann DeformCAFA semantisch und positionell konsistente Ausrichtungen erzeugen, auch ohne das in AutoAlign vorgeschlagene CFSI-Modul zu übernehmen.
Im Vergleich zu gewöhnlichen nicht lokalen Vorgängen verbessert DeformCAFA im Sparse-Stil die Effizienz erheblich. Wenn Voxelmerkmale jedoch direkt als Token angewendet werden, um Aufmerksamkeitsgewichte und verformbare Offsets zu generieren, ist die Erkennungsleistung kaum mit der bilinearen Interpolation vergleichbar oder sogar schlechter als diese. Nach sorgfältiger Analyse liegt im Token-Generierungsprozess ein domänenübergreifendes Wissensübersetzungsproblem vor. Im Gegensatz zur ursprünglichen Verformungsoperation, die normalerweise in einer unimodalen Umgebung durchgeführt wird, erfordert die domänenübergreifende Aufmerksamkeit Informationen von beiden Modalitäten. Voxelmerkmale bestehen jedoch nur aus räumlichen Domänendarstellungen und es ist schwierig, Informationen im Bildbereich wahrzunehmen. Daher ist es wichtig, die Interaktion zwischen verschiedenen Modalitäten zu reduzieren.
Angenommen, die Darstellung jedes Ziels kann eindeutig in zwei Komponenten zerlegt werden: domänenspezifische Informationen und instanzspezifische Informationen. Ersteres bezieht sich auf Daten, die sich auf die Darstellung selbst beziehen, einschließlich der integrierten Attribute von Domänenmerkmalen, während letzteres die ID-Informationen über das Ziel darstellt, unabhängig davon, in welcher Domäne das Ziel codiert ist.
Für die meisten Deep-Learning-Modelle ist die Datenerweiterung ein entscheidender Bestandteil, um wettbewerbsfähige Ergebnisse zu erzielen. Im Hinblick auf die multimodale 3D-Objekterkennung ist es jedoch bei der Kombination von Punktwolken und Bildern bei der Datenerweiterung schwierig, die Synchronisation zwischen beiden aufrechtzuerhalten, hauptsächlich aufgrund von Objektverdeckungen oder Blickwinkeländerungen. Um dieses Problem zu lösen, wurde ein einfacher, aber effektiver Algorithmus zur modalübergreifenden Datenerweiterung namens Depth-Aware GT-AUG entwickelt. Diese Methode macht komplexe Punktwolkenfilterprozesse oder feine Maskenanmerkungen der Bilddomäne überflüssig. Stattdessen werden Tiefeninformationen aus 3D-Objektanmerkungen in verwechselte Bildbereiche eingeführt.
Befolgen Sie insbesondere bei gegebenem virtuellen Ziel P zum Einfügen die gleiche 3D-Implementierung von GT-AUG. Die Bilddomäne wird zunächst von fern nach nah sortiert. Für jedes einzufügende Ziel wird derselbe Bereich aus dem Originalbild ausgeschnitten und mit einem Mischverhältnis von α auf dem Zielbild kombiniert. Die detaillierte Implementierung ist im folgenden Algorithmus 1 dargestellt.

Tiefenbewusstes GT-AUG folgt der Augmentationsstrategie nur im 3D-Bereich, hält aber gleichzeitig die Bildebenen durch verwechslungsbasiertes Ausschneiden und Einfügen synchronisiert. Der entscheidende Punkt ist, dass die MixUp-Technologie nach dem Einfügen verbesserter Patches in das ursprüngliche 2D-Bild die entsprechenden Informationen nicht vollständig entfernt. Stattdessen wird die Kompaktheit solcher Informationen relativ zur Tiefe verringert, um sicherzustellen, dass die Merkmale entsprechender Punkte vorhanden sind. Insbesondere wenn ein Ziel n-mal durch andere Instanzen verdeckt wird, nimmt die Transparenz des Zielbereichs entsprechend seiner Tiefenordnung um einen Faktor (1− α)^n ab.
Wie in der Abbildung gezeigt, sind einige erweiterte Beispiele:

Tatsächlich sind Bilder normalerweise eine Eingabeoption, die nicht von allen 3D-Erkennungssystemen unterstützt wird. Daher sollte eine realistischere und anwendbarere multimodale Erkennungslösung einen dynamischen Fusionsansatz verfolgen: Wenn das Bild nicht verfügbar ist, erkennt das Modell das Ziel anhand der ursprünglichen Punktwolke, wenn das Bild verfügbar ist, führt das Modell eine Merkmalsfusion durch führt zu besseren Vorhersagen. Um dieses Ziel zu erreichen, wird eine Dropout-Trainingsstrategie auf Bildebene vorgeschlagen, um die geclusterten Bildmerkmale auf Bildebene zufällig auszublenden und sie während des Trainings mit Nullen zu füllen. Wie in der Abbildung gezeigt: (a) Bildfusion; (b) Dropout-Fusion auf Bildebene.
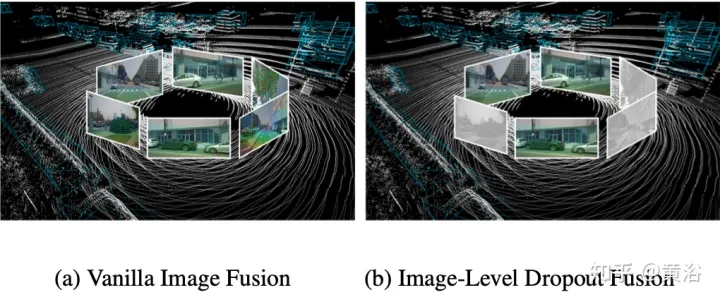
Aufgrund des zeitweiligen Verlusts von Bildinformationen sollte das Modell nach und nach lernen, 2D-Features als alternative Eingabe zu verwenden.



Das obige ist der detaillierte Inhalt vonMultimodale Fusions-BEV-Zielerkennungsmethode AutoAlign V1 und V2. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Einführung in das von vscode verwendete Framework
Einführung in das von vscode verwendete Framework
 So überprüfen Sie die JVM-Speichernutzung
So überprüfen Sie die JVM-Speichernutzung
 So beantragen Sie die Registrierung einer E-Mail-Adresse
So beantragen Sie die Registrierung einer E-Mail-Adresse
 So verwenden Sie fprintf in Matlab
So verwenden Sie fprintf in Matlab
 Java-Ausnahmebehandlung
Java-Ausnahmebehandlung
 Aktivierungscode für den Vista-Schlüssel
Aktivierungscode für den Vista-Schlüssel
 Vorteile des Herunterladens der offiziellen Website der Yiou Exchange App
Vorteile des Herunterladens der offiziellen Website der Yiou Exchange App
 So laden Sie die heutigen Schlagzeilenvideos herunter und speichern sie
So laden Sie die heutigen Schlagzeilenvideos herunter und speichern sie
 So führen Sie HTML-Code in vscode aus
So führen Sie HTML-Code in vscode aus








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



