
 Technologie-Peripheriegeräte
KI
Google hat ein maschinelles Übersetzungssystem für mehr als 1.000 „Long-Tail'-Sprachen entwickelt und unterstützt bereits einige Nischensprachen.
Technologie-Peripheriegeräte
KI
Google hat ein maschinelles Übersetzungssystem für mehr als 1.000 „Long-Tail'-Sprachen entwickelt und unterstützt bereits einige Nischensprachen.
Google hat ein maschinelles Übersetzungssystem für mehr als 1.000 „Long-Tail'-Sprachen entwickelt und unterstützt bereits einige Nischensprachen.

Die Qualität akademischer und kommerzieller maschineller Übersetzungssysteme (MT) hat sich im letzten Jahrzehnt deutlich verbessert. Diese Verbesserungen sind größtenteils auf Fortschritte beim maschinellen Lernen und die Verfügbarkeit umfangreicher Web-Mining-Datensätze zurückzuführen. Gleichzeitig entstehen Deep-Learning- (DL) und E2E-Modelle, groß angelegte parallele einsprachige Datensätze aus Web-Mining, Methoden zur Datenverbesserung wie Rückübersetzung und Selbsttraining sowie groß angelegte Multi- Die Sprachmodellierung hat dazu geführt, dass mehr als 100 hochwertige maschinelle Übersetzungssysteme für Sprachen unterstützt werden können.
Trotz der enormen Fortschritte bei der ressourcenarmen maschinellen Übersetzung sind die Sprachen, für die allgemein verfügbare und allgemeine maschinelle Übersetzungssysteme entwickelt wurden, jedoch auf etwa 100 begrenzt, was offensichtlich nur zu den mehr als 7000 Sprachen gehört wird heute auf der ganzen Welt gesprochen. Neben der begrenzten Anzahl von Sprachen ist auch die Verbreitung der von aktuellen maschinellen Übersetzungssystemen unterstützten Sprachen stark auf europäische Sprachen ausgerichtet.
Wir können sehen, dass es trotz ihrer großen Bevölkerungszahl weniger Dienste im Zusammenhang mit den in Afrika, Süd- und Südostasien gesprochenen Sprachen und den Sprachen der amerikanischen Ureinwohner gibt. Google Translate unterstützt beispielsweise Friesisch, Maltesisch, Isländisch und Korsisch, die alle weniger als 1 Million Muttersprachler haben. Im Vergleich dazu beträgt die Dialektbevölkerung von Bihar, die nicht von Google Translate bedient wird, etwa 51 Millionen, die Oromo-Bevölkerung etwa 24 Millionen, die Quechua-Bevölkerung etwa 9 Millionen und die Tigrinya-Bevölkerung etwa 9 Millionen (2022). Diese Sprachen werden als „Long-Tail“-Sprachen bezeichnet, und der Mangel an Daten erfordert die Anwendung maschineller Lerntechniken, die über Sprachen mit ausreichenden Trainingsdaten hinaus verallgemeinern können.
Der Aufbau maschineller Übersetzungssysteme für diese Long-Tail-Sprachen wird durch den Mangel an verfügbaren digitalisierten Datensätzen und NLP-Tools wie Sprachidentifikationsmodellen (LangID) weitgehend eingeschränkt. Diese sind in ressourcenintensiven Sprachen allgegenwärtig.
In einem aktuellen Google-Artikel „Building Machine Translation Systems for the Next Thousand Languages“ demonstrierten mehr als zwei Dutzend Forscher die Ergebnisse ihrer Bemühungen, praktische maschinelle Übersetzungssysteme zu entwickeln, die mehr als 1.000 Sprachen unterstützen.

Papieradresse: https://arxiv.org/pdf/2205.03983.pdf
Konkret beschrieben die Forscher ihre Ergebnisse aus den folgenden drei Forschungsbereichen.
Erstellen Sie zunächst saubere, webbasierte Datensätze für mehr als 1500 Sprachen durch halbüberwachtes Vortraining für Spracherkennung und datengesteuerte Filtertechniken.
Zweitens: Erstellen Sie neue Modelle für unterversorgte Sprachen mit groß angelegten mehrsprachigen Modellen, die auf überwachten parallelen Daten für über 100 Sprachen mit hohen Ressourcen sowie einsprachigen Datensätzen für über 1000 andere Sprachen trainiert werden. Praktische und effektive maschinelle Übersetzung Modell.
Drittens untersuchen Sie die Einschränkungen der Bewertungsmetriken für diese Sprachen und führen eine qualitative Analyse der Ausgabe maschineller Übersetzungsmodelle durch, wobei Sie sich auf mehrere häufige Fehlermuster solcher Modelle konzentrieren.
Wir hoffen, dass diese Arbeit Praktikern, die an der Entwicklung maschineller Übersetzungssysteme für derzeit wenig erforschte Sprachen arbeiten, nützliche Erkenntnisse liefern kann. Darüber hinaus hoffen die Forscher, dass diese Arbeit zu Forschungsrichtungen führen kann, die die Schwächen groß angelegter mehrsprachiger Modelle in datenarmen Umgebungen beheben.
Auf der I/O-Konferenz am 12. Mai gab Google bekannt, dass sein Übersetzungssystem 24 neue Sprachen hinzugefügt hat, darunter einige Nischensprachen der amerikanischen Ureinwohner, wie die oben erwähnten Bihar-Dialekte, Oromo, Quechua und Tigrinya.

Übersicht über den Artikel
Diese Arbeit ist hauptsächlich in vier Hauptkapitel unterteilt. Hier finden Sie nur eine kurze Einführung in den Inhalt jedes Kapitels.
Erstellen eines Webtextdatensatzes mit 1000 Sprachen
In diesem Kapitel werden die Methoden beschrieben, die Forscher beim Crawlen einsprachiger Textdatensätze für mehr als 1500 Sprachen verwenden. Der Schwerpunkt dieser Methoden liegt auf der Wiederherstellung hochpräziser Daten (d. h. eines hohen Anteils an sauberem, sprachinternem Text), daher handelt es sich bei einem großen Teil um verschiedene Filtermethoden.
Im Allgemeinen verwenden Forscher folgende Methoden:
- Entfernen Sie Sprachen mit schlechter Trainingsdatenqualität und schlechter LangID-Leistung aus dem LangID-Modell und trainieren Sie ein 1629-sprachiges CLD3-LangID-Modell und ein halbüberwachtes LangID-Modell (SSLID).
- Fehlerrate im CLD3-Modell nach Sprache Führen Sie eine Clustering-Operation durch.
- Sätze mithilfe der Dokumentkonsistenz filtern.
- Verwenden Sie Half Supervised LangID (SSLID), um alle Korpora zu filtern. Häufigkeitsanomalie-Scores zur Erkennung von Ausreißern und zum manuellen Entwerfen von Filtern für diese.
- Deduplizieren Sie alle Korpora auf Satzebene.
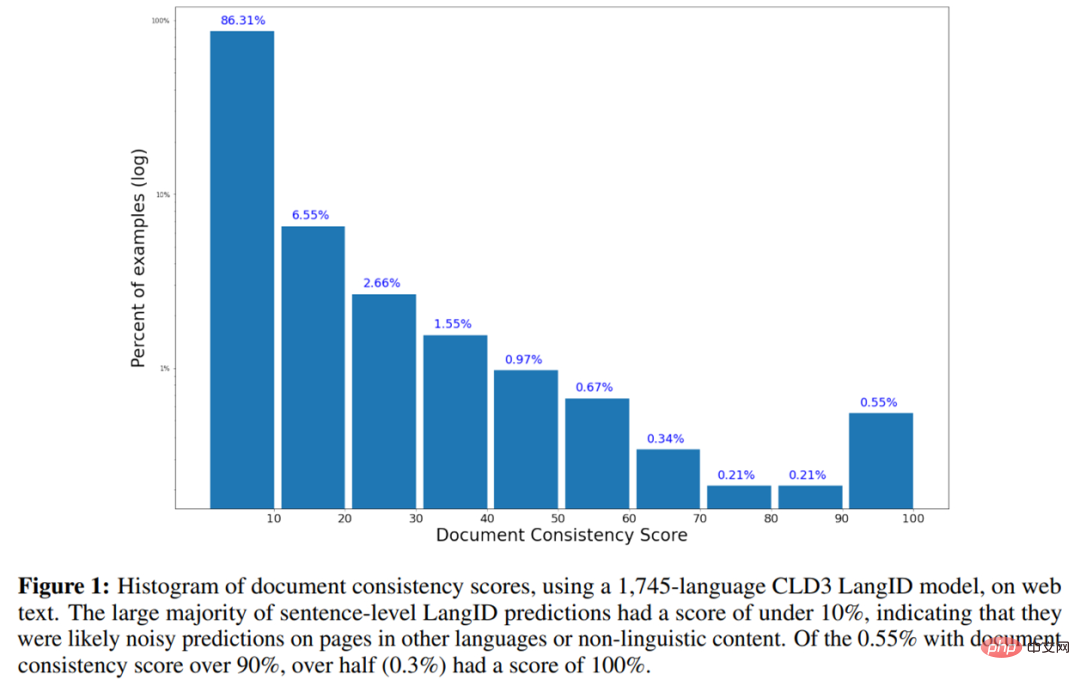
- Das Folgende ist das Histogramm der Dokumentkonsistenzbewertung unter Verwendung des 1745-sprachigen CLD3-LangID-Modells für Webtext.
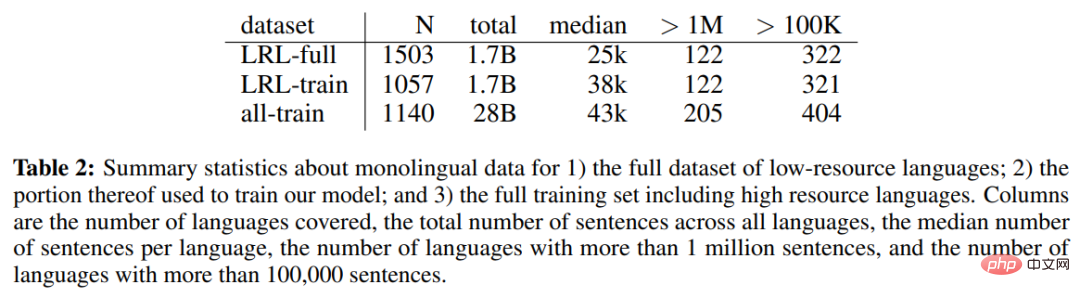
- Tabelle 2 unten zeigt die einsprachigen Daten des vollständigen Datensatzes ressourcenarmer Sprachen (LRL), einen Teil der zum Trainieren des Modells verwendeten einsprachigen Daten und die einsprachige Datenstatistik des gesamten Trainingssatzes einschließlich ressourcenintensiver Sprachen.
Für einsprachige Daten aus dem Web besteht die nächste Herausforderung im Training aus einer begrenzten Anzahl einsprachiger Personen Erstellen Sie hochwertige, universelle maschinelle Übersetzungsmodelle aus Daten. Zu diesem Zweck verfolgten die Forscher einen pragmatischen Ansatz und nutzten alle parallelen Daten, die für Sprachen mit höheren Ressourcen verfügbar sind, um die Qualität von Long-Tail-Sprachen zu verbessern, in denen nur einsprachige Daten verfügbar sind. Sie nennen dieses Setup „Null-Ressourcen“, da es keine direkte Aufsicht für Long-Tail-Sprachen gibt.
Forscher nutzen mehrere Technologien, die in den letzten Jahren für die maschinelle Übersetzung entwickelt wurden, um die Qualität der ressourcenfreien Übersetzung von Long-Tail-Sprachen zu verbessern. Zu diesen Techniken gehören selbstüberwachtes Lernen aus einsprachigen Daten, groß angelegtes mehrsprachiges überwachtes Lernen, groß angelegte Rückübersetzung und Selbsttraining sowie Hochleistungsmodelle. Sie nutzten diese Tools, um maschinelle Übersetzungsmodelle zu erstellen, die in der Lage sind, mehr als 1.000 Sprachen zu übersetzen, und nutzten dabei bestehende parallele Korpora, die etwa 100 Sprachen abdecken, sowie einen aus dem Internet erstellten einsprachigen Datensatz mit 1.000 Sprachen.
Konkret betonten die Forscher zunächst die Bedeutung der Modellkapazität in hochgradig mehrsprachigen Modellen, indem sie die Leistung von 1,5-Milliarden- und 6-Milliarden-Parameter-Transformatoren bei der ressourcenfreien Übersetzung verglichen (3.2) und dann die Anzahl selbstüberwachter Sprachen erhöhten auf 1000 zeigt, dass sich die Leistung für die meisten Long-Tail-Sprachen verbessert, wenn mehr einsprachige Daten aus ähnlichen Sprachen verfügbar werden (3.3). Während das 1000-Sprachen-Modell der Forscher eine angemessene Leistung zeigte, integrierten sie umfangreiche Datenerweiterungen, um die Stärken und Grenzen ihres Ansatzes zu verstehen. 
Darüber hinaus optimierten die Forscher das generative Modell anhand einer Teilmenge von 30 Sprachen, die große Mengen synthetischer Daten enthielten, durch Selbsttraining und Rückübersetzung (3.4). Sie beschreiben außerdem praktische Methoden zum Filtern synthetischer Daten, um die Robustheit dieser fein abgestimmten Modelle gegenüber Halluzinationen und falscher Sprachübersetzung zu verbessern (3.5).
Die Forscher nutzten auch die Destillation auf Sequenzebene, um diese Modelle in kleinere, leichter zu verstehende Architekturen zu verfeinern, und hoben die Leistungslücke zwischen Lehrer- und Schülermodellen hervor (3.6).
Das Inhaltsverzeichnis des Kapitels lautet wie folgt:
Bewertung
Um ihr maschinelles Übersetzungsmodell zu evaluieren, übersetzten die Forscher zunächst englische Sätze in diese Sprachen und erstellten ein Modell für die 38 Ausgewählte Long-Tail-Sprachen. Sie heben die Einschränkungen von BLEU in Long-Tail-Umgebungen hervor und bewerten diese Sprachen mithilfe von CHRF (4.2).
Die Forscher schlugen außerdem eine ungefähre referenzfreie Metrik basierend auf der Round-Trip-Übersetzung vor, um die Qualität des Modells in Sprachen zu verstehen, in denen der Referenzsatz nicht verfügbar ist, und berichteten über die anhand dieser Metrik gemessene Modellqualität (). 4.3). Sie führten eine menschliche Evaluierung des Modells für eine Teilmenge von 28 Sprachen durch und berichteten über die Ergebnisse. Dies bestätigte, dass es möglich ist, nützliche maschinelle Übersetzungssysteme zu erstellen, indem man dem im Artikel (4.4) beschriebenen Ansatz folgt.
Um die Schwächen groß angelegter mehrsprachiger Null-Ressourcen-Modelle zu verstehen, führten Forscher eine qualitative Fehleranalyse für mehrere Sprachen durch. Es wurde festgestellt, dass das Modell häufig Wörter und Konzepte mit ähnlicher Verbreitung verwechselte, wie zum Beispiel „Tiger“ wurde zu „kleines Krokodil“ (4.5). Und bei niedrigeren Ressourceneinstellungen (4.6) nimmt die Fähigkeit des Modells, Token zu übersetzen, bei Token ab, die weniger häufig erscheinen.
Forscher fanden außerdem heraus, dass diese Modelle kurze oder einzelne Worteingaben häufig nicht genau übersetzen können (4.7). Untersuchungen an verfeinerten Modellen zeigen, dass alle Modelle mit größerer Wahrscheinlichkeit die in den Trainingsdaten vorhandene Verzerrung oder das Rauschen verstärken (4.8).
Das Inhaltsverzeichnis des Kapitels lautet wie folgt:

Zusätzliche Experimente und Notizen
Die Forscher führten einige zusätzliche Experimente mit den oben genannten Modellen durch und zeigten, dass sie bei der direkten Übersetzung zwischen ähnlichen Sprachen im Allgemeinen eine bessere Leistung erbringen , ohne Englisch als Dreh- und Angelpunkt zu verwenden (5.1), und sie können für die Zero-Shot-Transliteration zwischen verschiedenen Skripten verwendet werden (5.2).
Sie beschreiben einen praktischen Trick zum Anhängen von Endzeichen an jede Eingabe, den sogenannten „Punkt-Trick“, mit dem sich die Übersetzungsqualität verbessern lässt (5.3).
Darüber hinaus zeigen wir, dass diese Modelle robust gegenüber der Verwendung von nicht standardmäßigen Unicode-Glyphen in einigen, aber nicht allen Sprachen sind (5.4), und untersuchen mehrere Nicht-Unicode-Schriftarten (5.5).
Das Inhaltsverzeichnis des Kapitels lautet wie folgt:

Weitere Forschungsdetails finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonGoogle hat ein maschinelles Übersetzungssystem für mehr als 1.000 „Long-Tail'-Sprachen entwickelt und unterstützt bereits einige Nischensprachen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Wie man Deepseek kommentiert
Feb 19, 2025 pm 05:42 PM
Wie man Deepseek kommentiert
Feb 19, 2025 pm 05:42 PM
Deepseek ist ein leistungsstarkes Informations -Abruf -Tool. .
 So suchen Sie Deepseek
Feb 19, 2025 pm 05:39 PM
So suchen Sie Deepseek
Feb 19, 2025 pm 05:39 PM
Deepseek ist eine proprietäre Suchmaschine, die nur schneller und genauer in einer bestimmten Datenbank oder einem bestimmten System sucht. Bei der Verwendung wird den Benutzern empfohlen, das Dokument zu lesen, verschiedene Suchstrategien auszuprobieren, Hilfe und Feedback zur Benutzererfahrung zu suchen, um die Vorteile optimal zu nutzen.
 Sesame Open Door Exchange -Webseite Registrierung Link Gate Trading App Registrierung Website Neueste
Feb 28, 2025 am 11:06 AM
Sesame Open Door Exchange -Webseite Registrierung Link Gate Trading App Registrierung Website Neueste
Feb 28, 2025 am 11:06 AM
In diesem Artikel wird der Registrierungsprozess der Webversion Sesam Open Exchange (GATE.IO) und die Gate Trading App im Detail vorgestellt. Unabhängig davon, ob es sich um eine Webregistrierung oder eine App -Registrierung handelt, müssen Sie die offizielle Website oder den offiziellen App Store besuchen, um die Genuine App herunterzuladen, und dann den Benutzernamen, das Kennwort, die E -Mail, die Mobiltelefonnummer und die anderen Informationen eingeben und eine E -Mail- oder Mobiltelefonüberprüfung abschließen.
 Warum kann der Bybit -Exchange -Link nicht direkt heruntergeladen und installiert werden?
Feb 21, 2025 pm 10:57 PM
Warum kann der Bybit -Exchange -Link nicht direkt heruntergeladen und installiert werden?
Feb 21, 2025 pm 10:57 PM
Warum kann der Bybit -Exchange -Link nicht direkt heruntergeladen und installiert werden? Bitbit ist eine Kryptowährungsbörse, die den Benutzern Handelsdienste anbietet. Die mobilen Apps der Exchange können aus den folgenden Gründen nicht direkt über AppStore oder Googleplay heruntergeladen werden: 1. App Store -Richtlinie beschränkt Apple und Google daran, strenge Anforderungen an die im App Store zulässigen Anwendungsarten zu haben. Kryptowährungsanträge erfüllen diese Anforderungen häufig nicht, da sie Finanzdienstleistungen einbeziehen und spezifische Vorschriften und Sicherheitsstandards erfordern. 2. Die Einhaltung von Gesetzen und Vorschriften In vielen Ländern werden Aktivitäten im Zusammenhang mit Kryptowährungstransaktionen reguliert oder eingeschränkt. Um diese Vorschriften einzuhalten, kann die Bitbit -Anwendung nur über offizielle Websites oder andere autorisierte Kanäle verwendet werden
 Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download -Adresse
Feb 28, 2025 am 10:51 AM
Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download -Adresse
Feb 28, 2025 am 10:51 AM
Es ist wichtig, einen formalen Kanal auszuwählen, um die App herunterzuladen und die Sicherheit Ihres Kontos zu gewährleisten.
 Sesam Open Door Exchange Webseite Login Neueste Version Gateio Offizieller Website Eingang
Mar 04, 2025 pm 11:48 PM
Sesam Open Door Exchange Webseite Login Neueste Version Gateio Offizieller Website Eingang
Mar 04, 2025 pm 11:48 PM
Eine detaillierte Einführung in den Anmeldungsbetrieb der Sesame Open Exchange -Webversion, einschließlich Anmeldeschritte und Kennwortwiederherstellungsprozess.
 Gate.io Exchange Official Registration Portal
Feb 20, 2025 pm 04:27 PM
Gate.io Exchange Official Registration Portal
Feb 20, 2025 pm 04:27 PM
Gate.io ist ein führender Kryptowährungsaustausch, der eine breite Palette von Krypto -Vermögenswerten und Handelspaaren bietet. Registrierung von Gate.io ist sehr einfach. Vervollständigen Sie die Registrierung. Mit Gate.io können Benutzer ein sicheres und bequemes Kryptowährungshandelserlebnis genießen.
 Binance Binance Offizielle Website Neueste Version Anmeldeportal
Feb 21, 2025 pm 05:42 PM
Binance Binance Offizielle Website Neueste Version Anmeldeportal
Feb 21, 2025 pm 05:42 PM
Befolgen Sie diese einfachen Schritte, um auf die neueste Version des Binance -Website -Login -Portals zuzugreifen. Gehen Sie zur offiziellen Website und klicken Sie in der oberen rechten Ecke auf die Schaltfläche "Anmeldung". Wählen Sie Ihre vorhandene Anmeldemethode. Geben Sie Ihre registrierte Handynummer oder E -Mail und Kennwort ein und vervollständigen Sie die Authentifizierung (z. B. Mobilfifizierungscode oder Google Authenticator). Nach einer erfolgreichen Überprüfung können Sie auf das neueste Version des offiziellen Website -Login -Portals von Binance zugreifen.
