
 Technologie-Peripheriegeräte
KI
Warum baumbasierte Modelle Deep Learning für Tabellendaten immer noch übertreffen
Technologie-Peripheriegeräte
KI
Warum baumbasierte Modelle Deep Learning für Tabellendaten immer noch übertreffen
Warum baumbasierte Modelle Deep Learning für Tabellendaten immer noch übertreffen

In diesem Artikel werde ich das Papier „Warum baumbasierte Modelle immer noch Deep Learning auf Tabellendaten übertreffen“ ausführlich erläutern. Dieses Papier erklärt ein Phänomen, das von Praktikern des maschinellen Lernens auf der ganzen Welt in verschiedenen Bereichen beobachtet wurde – das Phänomen Baum -basierte Modelle sind bei der Analyse tabellarischer Daten viel besser als Deep Learning/neuronale Netze.
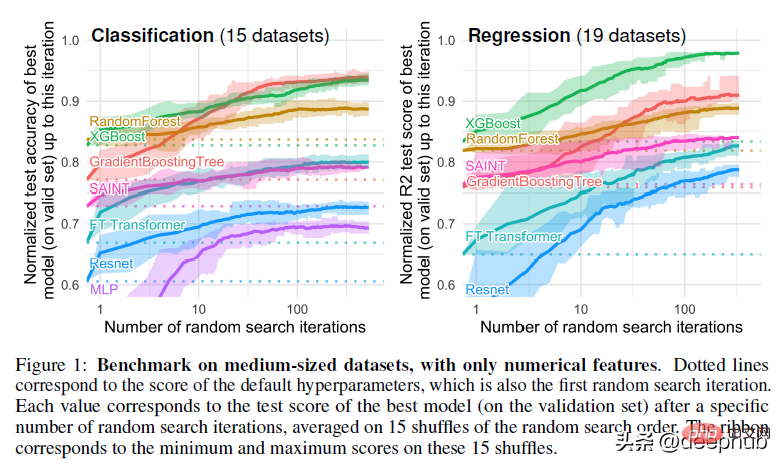
Hinweise zum Papier
Dieses Papier wurde einer umfangreichen Vorverarbeitung unterzogen. Dinge wie das Entfernen fehlender Daten können beispielsweise die Baumleistung beeinträchtigen, aber zufällige Gesamtstrukturen eignen sich hervorragend für Situationen mit fehlenden Daten, wenn Ihre Daten sehr chaotisch sind und viele Features und Dimensionen enthalten. Die Robustheit und Vorteile von RF machen es „fortschrittlicheren“ Lösungen überlegen, die anfällig für Probleme sind.

Der Großteil der restlichen Arbeit ist ziemlich normal. Ich persönlich mag es nicht, zu viele Vorverarbeitungstechniken anzuwenden, da dies dazu führen kann, dass viele Nuancen des Datensatzes verloren gehen, aber die in der Arbeit durchgeführten Schritte erzeugen im Grunde denselben Datensatz. Es ist jedoch wichtig zu beachten, dass bei der Auswertung der Endergebnisse die gleiche Verarbeitungsmethode verwendet wird.
Der Artikel verwendet auch eine Zufallssuche zur Optimierung von Hyperparametern. Dies ist ebenfalls ein Industriestandard, aber meiner Erfahrung nach eignet sich die Bayes'sche Suche besser für die Suche in einem größeren Suchraum.
Wenn wir diese verstehen, können wir uns mit unserer Hauptfrage befassen: Warum sind baumbasierte Methoden besser als Deep Learning? Die erste Ursache für Waldkonkurrenz. Kurz gesagt, neuronale Netze haben es schwer, die am besten passende Funktion zu erstellen, wenn es um nicht glatte Funktionen/Entscheidungsgrenzen geht. Zufällige Wälder eignen sich besser für seltsame/zackige/unregelmäßige Muster.
Wenn ich den Grund erraten würde, könnte es sein, dass Gradienten in neuronalen Netzen verwendet werden und Gradienten auf differenzierbaren Suchräumen basieren, die per Definition glatt sind, sodass scharfe Punkte und einige Zufallsfunktionen nicht unterschieden werden können. Ich empfehle daher, KI-Konzepte wie evolutionäre Algorithmen, traditionelle Suche und grundlegendere Konzepte zu erlernen, da diese Konzepte in verschiedenen Situationen, in denen NN versagt, zu großartigen Ergebnissen führen können. Ein konkreteres Beispiel für den Unterschied in den Entscheidungsgrenzen zwischen baumbasierten Methoden (RandomForests) und Deep-Learning-Methoden finden Sie in der Abbildung unten –
Ein konkreteres Beispiel für den Unterschied in den Entscheidungsgrenzen zwischen baumbasierten Methoden (RandomForests) und Deep-Learning-Methoden finden Sie in der Abbildung unten –
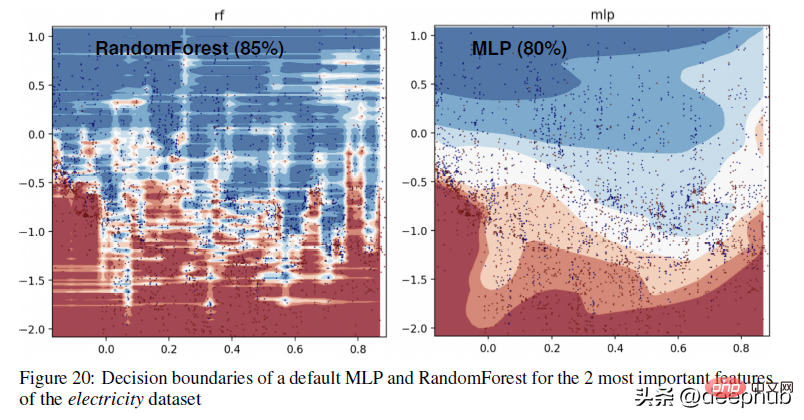 In diesem Teil können wir sehen, dass RandomForest unregelmäßige Muster auf der x-Achse (entsprechend Datumsmerkmalen) lernen kann, die MLP nicht lernen kann. Wir zeigen diesen Unterschied bei Standard-Hyperparametern, was ein typisches Verhalten neuronaler Netze ist, aber in der Praxis ist es schwierig (wenn auch nicht unmöglich), Hyperparameter zu finden, die diese Muster erfolgreich lernen.
In diesem Teil können wir sehen, dass RandomForest unregelmäßige Muster auf der x-Achse (entsprechend Datumsmerkmalen) lernen kann, die MLP nicht lernen kann. Wir zeigen diesen Unterschied bei Standard-Hyperparametern, was ein typisches Verhalten neuronaler Netze ist, aber in der Praxis ist es schwierig (wenn auch nicht unmöglich), Hyperparameter zu finden, die diese Muster erfolgreich lernen.
2. Nicht informative Eigenschaften wirken sich auf MLP-ähnliche neuronale Netze aus.
Ein weiterer wichtiger Faktor, insbesondere bei großen Datensätzen, die mehrere Beziehungen gleichzeitig kodieren. Wenn Sie einem neuronalen Netzwerk irrelevante Funktionen zuführen, sind die Ergebnisse schlecht (und Sie verschwenden mehr Ressourcen für das Training Ihres Modells). Aus diesem Grund ist es so wichtig, viel Zeit in die EDA-/Domain-Erkundung zu investieren. Dies hilft, die Funktionen zu verstehen und sicherzustellen, dass alles reibungslos funktioniert.
Die Autoren des Artikels testeten die Leistung des Modells beim Hinzufügen zufälliger und Entfernen nutzloser Funktionen. Basierend auf ihren Ergebnissen wurden zwei sehr interessante Ergebnisse gefunden:
Durch das Entfernen einer großen Anzahl von Funktionen wird der Leistungsunterschied zwischen den Modellen verringert. Dies zeigt deutlich, dass einer der Vorteile von Baummodellen darin besteht, dass sie beurteilen können, ob Merkmale nützlich sind, und den Einfluss nutzloser Merkmale vermeiden können.
Das Hinzufügen zufälliger Merkmale zum Datensatz zeigt, dass sich neuronale Netze viel stärker verschlechtern als baumbasierte Methoden. Insbesondere ResNet leidet unter diesen nutzlosen Eigenschaften. Die Verbesserung des Transformators kann darauf zurückzuführen sein, dass der darin enthaltene Aufmerksamkeitsmechanismus bis zu einem gewissen Grad hilfreich ist.
Eine mögliche Erklärung für dieses Phänomen ist die Art und Weise, wie Entscheidungsbäume entworfen werden. Jeder, der einen KI-Kurs belegt hat, kennt die Konzepte des Informationsgewinns und der Entropie in Entscheidungsbäumen. Dadurch kann der Entscheidungsbaum den besten Pfad auswählen, indem er die verbleibenden Merkmale vergleicht.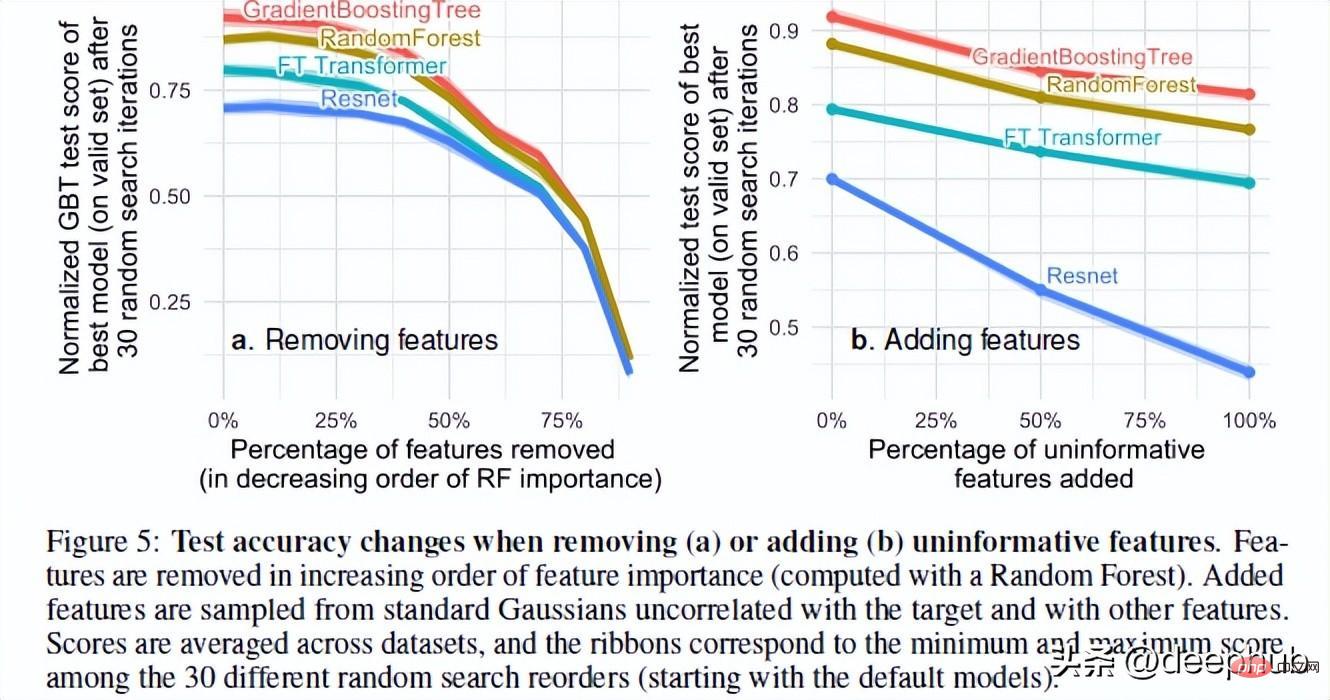 Zurück zum Thema: Es gibt noch eine letzte Sache, die RF bei tabellarischen Daten zu einer besseren Leistung als NN macht. Das ist Rotationsinvarianz.
Zurück zum Thema: Es gibt noch eine letzte Sache, die RF bei tabellarischen Daten zu einer besseren Leistung als NN macht. Das ist Rotationsinvarianz.
3. NNs sind rotationsinvariant, die tatsächlichen Daten jedoch nicht.
Neuronale Netze sind rotationsinvariant. Das bedeutet, dass sich die Leistung Ihrer Datensätze nicht ändert, wenn Sie eine Rotationsoperation durchführen. Nach der Rotation des Datensatzes änderten sich die Leistung und das Ranking der verschiedenen Modelle erheblich. Obwohl ResNets immer das schlechteste war, behielt es nach der Rotation seine ursprüngliche Leistung bei, während sich alle anderen Modelle stark veränderten.
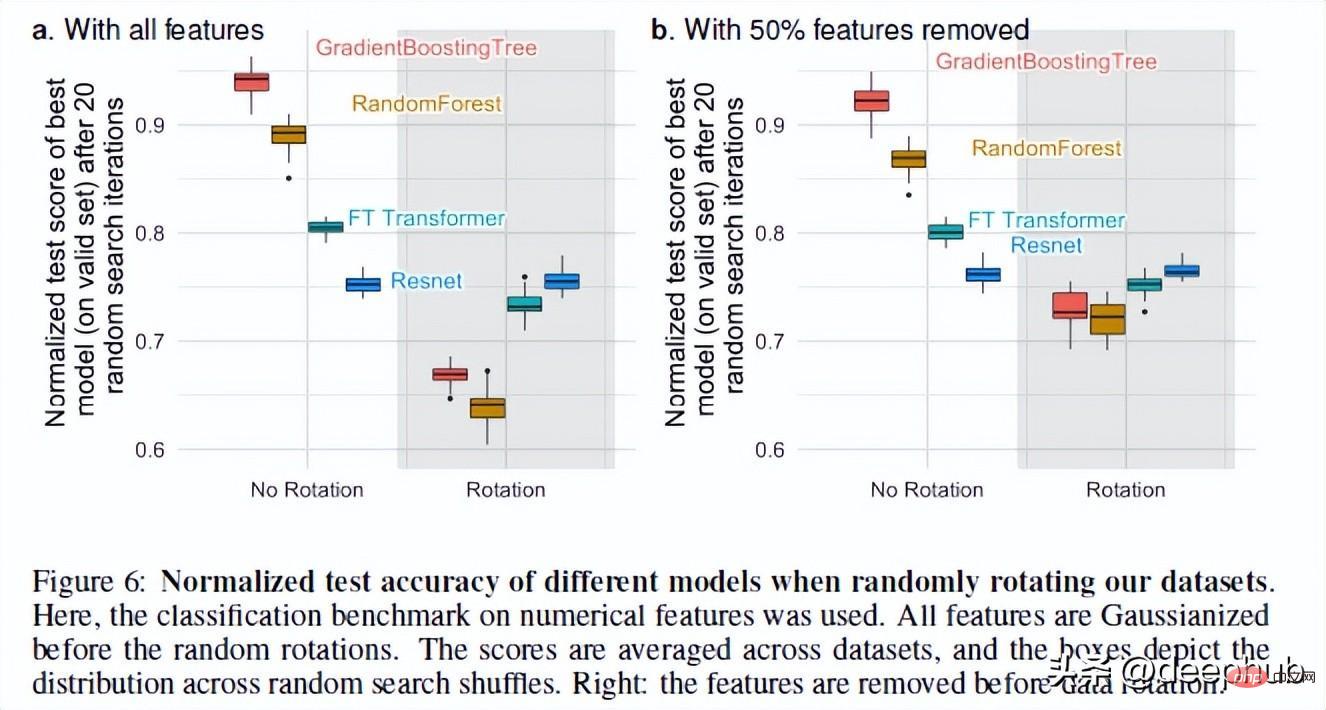
Das ist ein sehr interessantes Phänomen: Was genau bedeutet das Rotieren eines Datensatzes? Im gesamten Artikel gibt es keine detaillierten Erklärungen (ich habe den Autor kontaktiert und werde diesem Phänomen nachgehen). Wenn Sie irgendwelche Gedanken haben, teilen Sie diese bitte auch in den Kommentaren mit.
Aber diese Operation zeigt uns, warum Rotationsvarianz wichtig ist. Laut den Autoren kann die Verwendung linearer Kombinationen von Merkmalen (was ResNets invariant macht) tatsächlich dazu führen, dass Merkmale und ihre Beziehungen falsch dargestellt werden.
Das Erhalten optimaler Datenverzerrungen durch Kodierung der Originaldaten, die möglicherweise Merkmale mit sehr unterschiedlichen statistischen Eigenschaften vermischen und durch ein rotationsinvariantes Modell nicht wiederhergestellt werden können, führt zu einer besseren Leistung des Modells.
Zusammenfassung
Dies ist ein sehr interessantes Papier. Obwohl Deep Learning große Fortschritte bei Text- und Bilddatensätzen gemacht hat, hat es bei tabellarischen Daten grundsätzlich keine Vorteile. Das Papier verwendet 45 Datensätze aus verschiedenen Domänen zum Testen, und die Ergebnisse zeigen, dass baumbasierte Modelle auch ohne Berücksichtigung ihrer überlegenen Geschwindigkeit bei moderaten Daten (~10.000 Stichproben) immer noch auf dem neuesten Stand sind.
Das obige ist der detaillierte Inhalt vonWarum baumbasierte Modelle Deep Learning für Tabellendaten immer noch übertreffen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Methoden und Schritte zur Verwendung von BERT für die Stimmungsanalyse in Python
Jan 22, 2024 pm 04:24 PM
Methoden und Schritte zur Verwendung von BERT für die Stimmungsanalyse in Python
Jan 22, 2024 pm 04:24 PM
BERT ist ein vorab trainiertes Deep-Learning-Sprachmodell, das 2018 von Google vorgeschlagen wurde. Der vollständige Name lautet BidirektionalEncoderRepresentationsfromTransformers, der auf der Transformer-Architektur basiert und die Eigenschaften einer bidirektionalen Codierung aufweist. Im Vergleich zu herkömmlichen Einweg-Codierungsmodellen kann BERT bei der Textverarbeitung gleichzeitig Kontextinformationen berücksichtigen, sodass es bei Verarbeitungsaufgaben in natürlicher Sprache eine gute Leistung erbringt. Seine Bidirektionalität ermöglicht es BERT, die semantischen Beziehungen in Sätzen besser zu verstehen und dadurch die Ausdrucksfähigkeit des Modells zu verbessern. Durch Vorschulungs- und Feinabstimmungsmethoden kann BERT für verschiedene Aufgaben der Verarbeitung natürlicher Sprache verwendet werden, wie z. B. Stimmungsanalyse und Benennung
 YOLO ist unsterblich! YOLOv9 wird veröffentlicht: Leistung und Geschwindigkeit SOTA~
Feb 26, 2024 am 11:31 AM
YOLO ist unsterblich! YOLOv9 wird veröffentlicht: Leistung und Geschwindigkeit SOTA~
Feb 26, 2024 am 11:31 AM
Heutige Deep-Learning-Methoden konzentrieren sich darauf, die am besten geeignete Zielfunktion zu entwerfen, damit die Vorhersageergebnisse des Modells der tatsächlichen Situation am nächsten kommen. Gleichzeitig muss eine geeignete Architektur entworfen werden, um ausreichend Informationen für die Vorhersage zu erhalten. Bestehende Methoden ignorieren die Tatsache, dass bei der schichtweisen Merkmalsextraktion und räumlichen Transformation der Eingabedaten eine große Menge an Informationen verloren geht. Dieser Artikel befasst sich mit wichtigen Themen bei der Datenübertragung über tiefe Netzwerke, nämlich Informationsengpässen und umkehrbaren Funktionen. Darauf aufbauend wird das Konzept der programmierbaren Gradienteninformation (PGI) vorgeschlagen, um die verschiedenen Änderungen zu bewältigen, die tiefe Netzwerke zur Erreichung mehrerer Ziele erfordern. PGI kann vollständige Eingabeinformationen für die Zielaufgabe zur Berechnung der Zielfunktion bereitstellen und so zuverlässige Gradienteninformationen zur Aktualisierung der Netzwerkgewichte erhalten. Darüber hinaus wird ein neues, leichtgewichtiges Netzwerk-Framework entworfen
 Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Heute diskutieren wir darüber, wie Deep-Learning-Technologie die Leistung von visionbasiertem SLAM (Simultaneous Localization and Mapping) in komplexen Umgebungen verbessern kann. Durch die Kombination von Methoden zur Tiefenmerkmalsextraktion und Tiefenanpassung stellen wir hier ein vielseitiges hybrides visuelles SLAM-System vor, das die Anpassung in anspruchsvollen Szenarien wie schlechten Lichtverhältnissen, dynamischer Beleuchtung, schwach strukturierten Bereichen und starkem Jitter verbessern soll. Unser System unterstützt mehrere Modi, einschließlich erweiterter Monokular-, Stereo-, Monokular-Trägheits- und Stereo-Trägheitskonfigurationen. Darüber hinaus wird analysiert, wie visuelles SLAM mit Deep-Learning-Methoden kombiniert werden kann, um andere Forschungen zu inspirieren. Durch umfangreiche Experimente mit öffentlichen Datensätzen und selbst abgetasteten Daten demonstrieren wir die Überlegenheit von SL-SLAM in Bezug auf Positionierungsgenauigkeit und Tracking-Robustheit.
 Latente Raumeinbettung: Erklärung und Demonstration
Jan 22, 2024 pm 05:30 PM
Latente Raumeinbettung: Erklärung und Demonstration
Jan 22, 2024 pm 05:30 PM
Latent Space Embedding (LatentSpaceEmbedding) ist der Prozess der Abbildung hochdimensionaler Daten auf niedrigdimensionalen Raum. Im Bereich des maschinellen Lernens und des tiefen Lernens handelt es sich bei der Einbettung latenter Räume normalerweise um ein neuronales Netzwerkmodell, das hochdimensionale Eingabedaten in einen Satz niedrigdimensionaler Vektordarstellungen abbildet. Dieser Satz von Vektoren wird oft als „latente Vektoren“ oder „latent“ bezeichnet Kodierungen". Der Zweck der Einbettung latenter Räume besteht darin, wichtige Merkmale in den Daten zu erfassen und sie in einer prägnanteren und verständlicheren Form darzustellen. Durch die Einbettung latenter Räume können wir Vorgänge wie das Visualisieren, Klassifizieren und Clustern von Daten im niedrigdimensionalen Raum durchführen, um die Daten besser zu verstehen und zu nutzen. Die Einbettung latenter Räume findet in vielen Bereichen breite Anwendung, z. B. bei der Bilderzeugung, der Merkmalsextraktion, der Dimensionsreduzierung usw. Die Einbettung des latenten Raums ist das Wichtigste
 Verstehen Sie in einem Artikel: die Zusammenhänge und Unterschiede zwischen KI, maschinellem Lernen und Deep Learning
Mar 02, 2024 am 11:19 AM
Verstehen Sie in einem Artikel: die Zusammenhänge und Unterschiede zwischen KI, maschinellem Lernen und Deep Learning
Mar 02, 2024 am 11:19 AM
In der heutigen Welle rasanter technologischer Veränderungen sind künstliche Intelligenz (KI), maschinelles Lernen (ML) und Deep Learning (DL) wie helle Sterne und führen die neue Welle der Informationstechnologie an. Diese drei Wörter tauchen häufig in verschiedenen hochaktuellen Diskussionen und praktischen Anwendungen auf, aber für viele Entdecker, die neu auf diesem Gebiet sind, sind ihre spezifische Bedeutung und ihre internen Zusammenhänge möglicherweise noch immer rätselhaft. Schauen wir uns also zunächst dieses Bild an. Es ist ersichtlich, dass zwischen Deep Learning, maschinellem Lernen und künstlicher Intelligenz ein enger Zusammenhang und eine fortschreitende Beziehung besteht. Deep Learning ist ein spezifischer Bereich des maschinellen Lernens und des maschinellen Lernens
 Super stark! Top 10 Deep-Learning-Algorithmen!
Mar 15, 2024 pm 03:46 PM
Super stark! Top 10 Deep-Learning-Algorithmen!
Mar 15, 2024 pm 03:46 PM
Fast 20 Jahre sind vergangen, seit das Konzept des Deep Learning im Jahr 2006 vorgeschlagen wurde. Deep Learning hat als Revolution auf dem Gebiet der künstlichen Intelligenz viele einflussreiche Algorithmen hervorgebracht. Was sind Ihrer Meinung nach die zehn besten Algorithmen für Deep Learning? Im Folgenden sind meiner Meinung nach die besten Algorithmen für Deep Learning aufgeführt. Sie alle nehmen hinsichtlich Innovation, Anwendungswert und Einfluss eine wichtige Position ein. 1. Hintergrund des Deep Neural Network (DNN): Deep Neural Network (DNN), auch Multi-Layer-Perceptron genannt, ist der am weitesten verbreitete Deep-Learning-Algorithmus. Als er erstmals erfunden wurde, wurde er aufgrund des Engpasses bei der Rechenleistung in Frage gestellt Jahre, Rechenleistung, Der Durchbruch kam mit der Datenexplosion. DNN ist ein neuronales Netzwerkmodell, das mehrere verborgene Schichten enthält. In diesem Modell übergibt jede Schicht Eingaben an die nächste Schicht und
 1,3 ms dauert 1,3 ms! Tsinghuas neueste Open-Source-Architektur für mobile neuronale Netzwerke RepViT
Mar 11, 2024 pm 12:07 PM
1,3 ms dauert 1,3 ms! Tsinghuas neueste Open-Source-Architektur für mobile neuronale Netzwerke RepViT
Mar 11, 2024 pm 12:07 PM
Papieradresse: https://arxiv.org/abs/2307.09283 Codeadresse: https://github.com/THU-MIG/RepViTRepViT funktioniert gut in der mobilen ViT-Architektur und zeigt erhebliche Vorteile. Als nächstes untersuchen wir die Beiträge dieser Studie. In dem Artikel wird erwähnt, dass Lightweight-ViTs bei visuellen Aufgaben im Allgemeinen eine bessere Leistung erbringen als Lightweight-CNNs, hauptsächlich aufgrund ihres Multi-Head-Selbstaufmerksamkeitsmoduls (MSHA), das es dem Modell ermöglicht, globale Darstellungen zu lernen. Allerdings wurden die architektonischen Unterschiede zwischen Lightweight-ViTs und Lightweight-CNNs noch nicht vollständig untersucht. In dieser Studie integrierten die Autoren leichte ViTs in die effektiven
 AlphaFold 3 wird auf den Markt gebracht und sagt die Wechselwirkungen und Strukturen von Proteinen und allen Lebensmolekülen umfassend und mit weitaus größerer Genauigkeit als je zuvor voraus
Jul 16, 2024 am 12:08 AM
AlphaFold 3 wird auf den Markt gebracht und sagt die Wechselwirkungen und Strukturen von Proteinen und allen Lebensmolekülen umfassend und mit weitaus größerer Genauigkeit als je zuvor voraus
Jul 16, 2024 am 12:08 AM
Herausgeber | Rettichhaut Seit der Veröffentlichung des leistungsstarken AlphaFold2 im Jahr 2021 verwenden Wissenschaftler Modelle zur Proteinstrukturvorhersage, um verschiedene Proteinstrukturen innerhalb von Zellen zu kartieren, Medikamente zu entdecken und eine „kosmische Karte“ jeder bekannten Proteininteraktion zu zeichnen. Gerade hat Google DeepMind das AlphaFold3-Modell veröffentlicht, das gemeinsame Strukturvorhersagen für Komplexe wie Proteine, Nukleinsäuren, kleine Moleküle, Ionen und modifizierte Reste durchführen kann. Die Genauigkeit von AlphaFold3 wurde im Vergleich zu vielen dedizierten Tools in der Vergangenheit (Protein-Ligand-Interaktion, Protein-Nukleinsäure-Interaktion, Antikörper-Antigen-Vorhersage) deutlich verbessert. Dies zeigt, dass dies innerhalb eines einzigen einheitlichen Deep-Learning-Frameworks möglich ist
