

Der KI-Interviewroboter nutzt die Mensch-Maschine-Sprachdialogfähigkeit der Lingxi Intelligent Speech Semantic Platform, um mehrere Runden der Sprachkommunikation zwischen Personalvermittlern und Arbeitssuchenden zu simulieren und so den Effekt eines Online-Interviews zu erzielen. In diesem Artikel werden die Zusammensetzung der Back-End-Architektur, das Design der Dialog-Engine, die Strategie zur Schätzung des Ressourcenbedarfs und die Methoden zur Optimierung der Serviceleistung des KI-Interviewroboters ausführlich beschrieben. Der KI-Interviewroboter ist seit mehr als einem Jahr online und hat Millionen von Interviewanfragen erhalten, was die Rekrutierungseffizienz von Personalvermittlern und das Interviewerlebnis von Arbeitssuchenden erheblich verbessert.
58 Die City Life Service Platform umfasst vier große etablierte Unternehmen: Immobilien, Autos, Personalvermittlung und lokale Dienstleistungen (Gelbe Seiten). Die Plattform verbindet eine große Anzahl von C-Seite-Benutzern und B-Seite-Händlern. und B-Seite-Händler können auf der Plattform verschiedene Arten von Informationen veröffentlichen (wir nennen sie „Beiträge“), wie z. B. Wohnraum, Autoverfügbarkeit, Jobs und Lebensdienstleistungen. Die Plattform verteilt diese Beiträge an C-Seite-Benutzer, damit diese sie durchsuchen können. Dies hilft ihnen, die benötigten Informationen zu erhalten, und hilft B-Seiten-Händlern, Informationen zu verbreiten und zu verbreiten, um Zielkunden zu gewinnen und das Benutzererlebnis auf der C-Seite zu verbessern entwickelt weiterhin Produktinnovationen in Aspekten wie personalisierten Empfehlungen und intelligenten Verbindungen.
Nehmen Sie die Personalbeschaffung im Jahr 2020. Die Zahl der Anfragen von Arbeitssuchenden für Online-Bewerbungsgespräche über WeChat, Video usw. hat stark zugenommen Rekrutierung Der Interviewer kann nur mit einem Arbeitssuchenden gleichzeitig einen Online-Video-Interview-Kanal einrichten, was zu einer geringen Erfolgsquote bei der Verknüpfung zwischen dem Arbeitssuchenden und dem Personalvermittler führt. Um das Benutzererlebnis für Arbeitssuchende zu verbessern und die Effizienz von Vorstellungsgesprächen für Personalvermittler zu verbessern, hat 58.com TEG AI Lab mit mehreren Abteilungen wie dem Geschäftsbereich Personalbeschaffung zusammengearbeitet, um ein intelligentes Tool für Bewerbungsgespräche zu entwickeln: den Magic Interview Room. Das Produkt besteht im Wesentlichen aus drei Teilen: Kunden-, Audio- und Videokommunikation und KI-Interviewroboter (siehe: Menschen | Li Zhong: KI-Interviewroboter schafft intelligente Rekrutierung).
Dieser Artikel konzentriert sich hauptsächlich auf den KI-Interviewroboter. Der KI-Interviewroboter nutzt die Mensch-Maschine-Sprachdialogfähigkeit der Lingxi Intelligent Speech Semantic Platform, um mehrere Runden der Sprachkommunikation zwischen Personalvermittlern und Arbeitssuchenden zu erreichen die Wirkung von Online-Interviews. Einerseits kann es das Problem lösen, dass ein Personalvermittler nur auf die Online-Interviewanfrage eines Arbeitssuchenden antworten kann, was die Arbeitseffizienz des Personalvermittlers verbessert, andererseits kann es den Anforderungen von Arbeitssuchenden gerecht werden, unabhängig davon Videointerviews durchzuführen von Zeit und Ort, während persönliche Lebensläufe von der traditionellen Textbeschreibungseinleitung in eine intuitivere und anschaulichere Video-Selbstpräsentation umgewandelt werden. In diesem Artikel werden ausführlich die Back-End-Architektur des KI-Interviewroboters, das Design der Mensch-Maschine-Sprachdialog-Engine, die Schätzung des Ressourcenbedarfs zur Bewältigung der Verkehrsausweitung und die Optimierung der Serviceleistung zur Gewährleistung der Stabilität beschrieben und Verfügbarkeit des gesamten AI-Interview-Roboterdienstes.
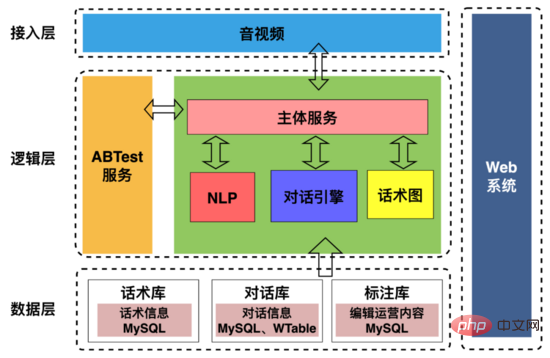
Die AI-Interview-Roboter-Architektur ist in der Abbildung oben dargestellt, einschließlich:
1 Zugriffsschicht: Wird hauptsächlich zur Abwicklung von Interaktionen mit Upstream- und Downstream-Anwendungen verwendet, einschließlich vereinbarter Kommunikation mit Audio- und Videoterminals Protokoll; Extrahieren von Benutzerporträts während Interviews, Extrahieren von Zeitleisteninformationen zur Roboterbenutzerinteraktion und Senden an die Personalbeschaffungsabteilung.
2. Logikschicht: Wird hauptsächlich zur Abwicklung der Dialoginteraktion zwischen dem Roboter und dem Benutzer verwendet, einschließlich der Synthese des Fragetextes des Roboters in Sprachdaten und dem Senden dieser an den Benutzer, wobei dem Benutzer Fragen gestellt werden, damit der Roboter „sprechen“ kann; Nachdem der Benutzer geantwortet hat, werden die Antwort-Sprachdaten des Benutzers durch VAD (Voice Activity Detection) segmentiert und die Streaming-Sprache wird als Text erkannt, sodass der Roboter sie „hören“ kann, um den Antwortinhalt basierend auf dem des Benutzers zu bestimmen Antworttext und Konversationsfähigkeiten, synthetisiert dann die Sprache und sendet sie an den Benutzer, wodurch eine „Kommunikation“ zwischen dem Roboter und dem Benutzer realisiert wird.
3. Datenschicht: Speichert grundlegende Daten wie Sprachdiagramme, Gesprächsaufzeichnungen und Anmerkungsinformationen.
4. Websystem: Diskursstruktur und Dialogstrategien visuell konfigurieren und Interviewdialogdaten kommentieren.
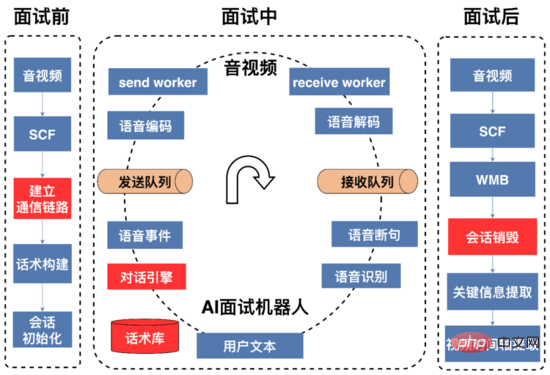
In der Abbildung oben ist ein vollständiger AI-Interviewprozess dargestellt, der in drei Phasen unterteilt werden kann: vor dem Interview, während des Interviews und nach dem Interview Interview.
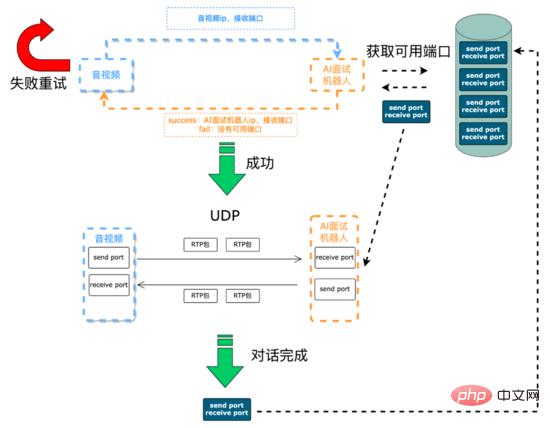
Vor dem Interview: Die Hauptsache ist, Kommunikationsverbindungen herzustellen und Ressourcen zu initialisieren. Die Sprachsignale zwischen dem KI-Interviewroboter und den Audio- und Videoterminals werden über UDP übertragen Video und der KI-Interviewroboter müssen dynamisch gepflegt werden. Die Audio- und Videoseite initiiert eine Interviewanfrage über die SCF-Schnittstelle (SCF ist ein von 58 unabhängig entwickeltes RPC-Framework). Einerseits erhält die Anfrage dynamisch IP- und Portressourcen vom KI-Interviewroboter in Echtzeit für die weitere Bearbeitung Audio- und Videosammlung des Interviewprozesses wird an den KI-Roboter gesendet. Andererseits wird dem KI-Roboter die IP und der Port mitgeteilt, die als Reaktion auf das Sprachsignal des Benutzers gesendet werden müssen. Da SCF den Lastausgleich unterstützt, werden die von der Audio- und Videoseite initiierten Interviewanfragen zufällig an den AI-Interview-Roboterdienst weitergeleitet. Auf einem bestimmten Computer im Cluster erhält der AI-Interviewroboter auf diesem Computer die IP-Adresse Als Nächstes versucht der AI-Interview-Roboterdienst zunächst, aus der verfügbaren Portwarteschlange (die während der Dienstinitialisierung erstellt wurde) das erste verfügbare Portpaar (ein Paar bestehend aus) auszuwählen eines sendenden Ports und eines empfangenden Ports) in einer Warteschlangendatenstruktur, die verfügbare Portpaare speichert. Wenn die Erfassung erfolgreich ist, leitet der Dienst die IP und den Port dieser Maschine über das SCF-Interview weiter und Video beenden, und die beiden Parteien können dann eine UDP-Kommunikation durchführen. Nach Abschluss des Interviews verschiebt der Dienst das Portpaar in die verfügbare Portwarteschlange. Wenn das Abrufen des Portpaars fehlschlägt, gibt der Dienst über die SCF-Schnittstelle einen Kommunikationsfehlercode an das Audio- und Videoterminal zurück. Das Audio- und Videoterminal kann die Interviewanfrage erneut versuchen oder ablehnen.
Kommunikationsprozess einrichten:
Beim Sprachsignalübertragungsprozess verwenden wir das RTP-Protokoll als Audiomedienprotokoll im System. Das RTP-Protokoll (Real-Time Transport Protocol) bietet End-to-End-Echtzeitübertragungsdienste für verschiedene Multimediadaten wie Sprache, Bild, Fax usw., die in Echtzeit über IP übertragen werden müssen. RTP-Nachrichten bestehen aus zwei Teilen: Header und Payload.
RTP-Header:
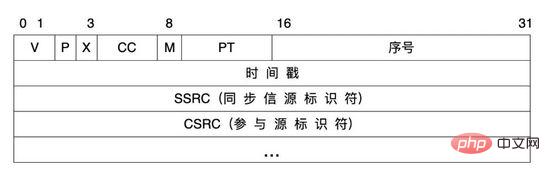
Attributerklärung:
Attribut |
Erklärung |
V |
Die Versionsnummer der RTP-Protokollversion, Abrechnung für 2 Ziffern ist die aktuelle Protokollversionsnummer 2 |
P |
Fill-Flag, das 1 Bit belegt, wenn P=1, dann wird das Ende der Nachricht mit einem oder mehreren zusätzlichen 8- aufgefüllt. Bit-Arrays, die nicht gültig sind Teil der Last |
X |
Erweiterungsflag, belegt 1 Bit, wenn die Anzahl der |
| 1 Position ausmacht. Bei Videos markiert es das Ende eines Frames Audio markiert es den Beginn einer Sitzung. | |
| Der Nutzlasttyp, der 7 Bits belegt, wird verwendet, um die Art der Nutzlast in der RTP-Nachricht zu beschreiben, z. B. Audio, Bild usw. In Streaming-Medien wird dies hauptsächlich verwendet Unterscheiden Sie zwischen Audio-Streams und Video-Streams, die für den Client einfach zu analysieren sind. | |
| belegt 16 Bit und dient zur Identifizierung der Sequenznummer der vom Absender gesendeten RTP-Nachricht. Bei jedem Versand einer Nachricht erhöht sich die Sequenznummer um 1. Wenn das Trägerprotokoll der unteren Schicht UDP verwendet, kann dieses Feld verwendet werden, um den Paketverlust zu überprüfen, wenn der Netzwerkzustand nicht gut ist. Gleichzeitig kann Netzwerk-Jitter zur Neuordnung von Daten genutzt werden. | |
| belegt 32 Bit und spiegelt die Abtastzeit des ersten Oktetts der RTP-Nachricht wider. Der Empfänger kann den Zeitstempel verwenden, um Verzögerung und Verzögerungsjitter zu berechnen und eine Synchronisationssteuerung durchzuführen. | |
| wird verwendet, um die Synchronisationsquelle zu identifizieren. Diese Identifikation kann zufällig ausgewählt werden. Zwei Synchronisationsquellen, die an derselben Videokonferenz teilnehmen, können nicht den gleichen SSRC haben | Jede CSRC-Kennung belegt 32 Bit und kann 0 bis 15 haben. Jeder CSRC identifiziert alle privilegierten Quellen, die in der Nutzlast der RTP-Nachricht enthalten sind. |
Während des Interviews: Während dieses Prozesses sendet der KI-Interviewroboter zunächst eine Eröffnungserklärung. Der Text der Eröffnungserklärung wird durch tts (Text To Speech) in Sprachdaten umgewandelt Anhand der vereinbarten IP-Adresse und des Ports des Audio- und Videoterminals dekodiert der KI-Interviewroboter den empfangenen Benutzersprachstrom und wandelt ihn durch VAD-Segmentierung und Streaming-Spracherkennung um Die Dialog-Engine bestimmt den Antwortinhalt basierend auf dem Antworttext des Benutzers und dem Sprachstruktur-Zustandsdiagramm. Der KI-Interviewroboter interagiert kontinuierlich mit dem Benutzer, bis das Gespräch endet oder der Benutzer das Interview beendet.
Nach dem Interview: Sobald der KI-Interviewroboter die Audio- und Videoanfrage für das Ende des Interviews erhält, recycelt der KI-Interviewroboter die während der Interviewvorbereitungsphase verwendeten Ressourcen wie Ports, Threads usw. ; Erstellen Sie ein Porträt des Benutzers (einschließlich der schnellsten Ankunftszeit des Benutzers, Informationen wie z. B. ob Sie sich für den Job engagiert haben, Alter usw.) und werden dem Personalvermittler zur Verfügung gestellt, um den Händlern die Überprüfung, Aufzeichnung und Speicherung des Interviewgesprächs zu erleichtern.
Aufzeichnungsplan:
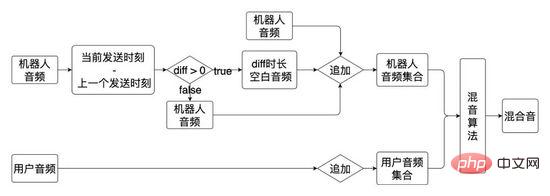
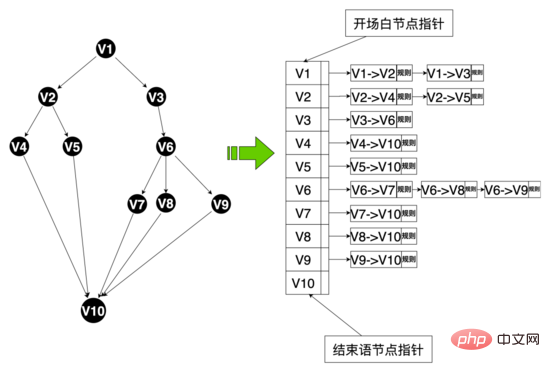
Im gesamten Interviewprozess werden der KI-Interviewroboter und die Benutzerinteraktion von der Dialog-Engine basierend auf dem Konversationsprozess gesteuert, wobei das Gespräch gezielt ist Anfänglich handelte es sich bei dem Dialogdiagramm um einen Dialog mit zwei Zweigen (Kanten aller Knoten
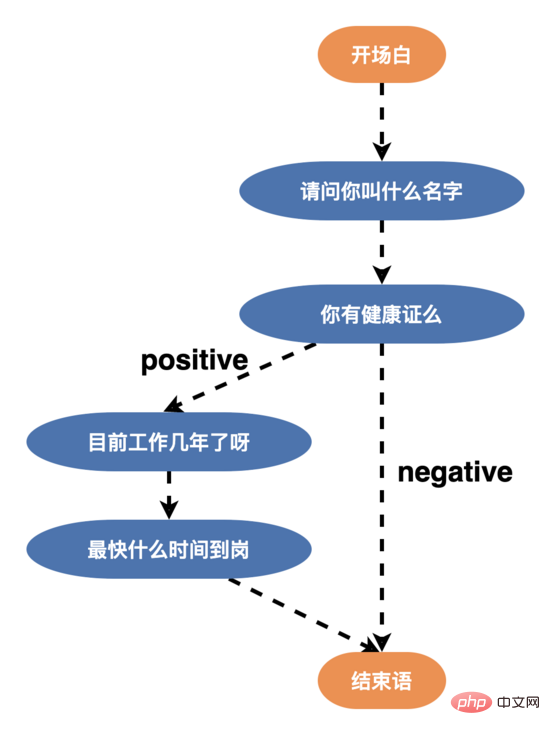
Um die Gesprächsbereitschaft der Benutzer zu erhöhen und die intelligenten Dialogfähigkeiten des Roboters zu verbessern, haben wir daher die Sprachstruktur rekonstruiert und eine Sprache mit mehreren Zweigen (Knotenrand >= 3) entworfen, wie gezeigt Unten kann der Benutzer je nach Alter, Bildung und Persönlichkeit individuell auf die unterschiedlichen Sprachfähigkeiten der Benutzer reagieren. Nach der Einführung der neuen Sprachstruktur überstieg die Abschlussquote des Interviews 50 %.
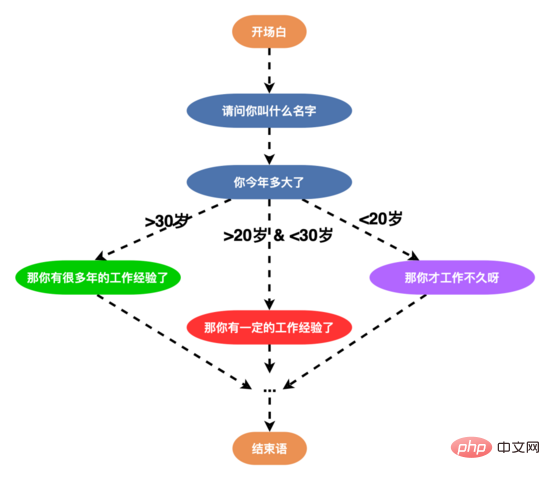
Um die Dialogstrategie detaillierter zu gestalten, haben wir gleichzeitig eine Strategiekette auf Knotenebene in der Strategiekette entworfen, mit der eine personalisierte Dialogstrategie für einen einzelnen Knoten angepasst werden kann um personalisierte Dialogbedürfnisse zu erfüllen.
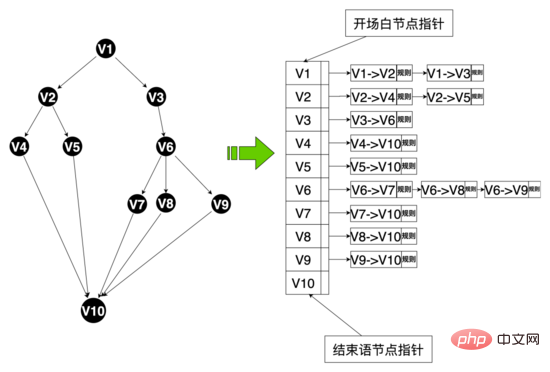
Datenebene: Um Mehrzweigsprache zu realisieren, haben wir die sprachbezogene Datenstruktur neu gestaltet und einige Dateneinheiten abstrahiert, darunter: Sprachtabelle, Sprachknoten, Sprachkante usw. Hua Shu-Knoten sind über Hua Shu-Nummern an Hua Shu gebunden, und gleichzeitig behalten Hua Shu-Kanten die topologische Beziehung zwischen Knoten bei, einschließlich der Bindung von Startknoten und Hua Shu-Kanten durch Kantennummern, Regelmäßigkeit, Korpus und andere Regeln, und Sie können die Kanten-ID verwenden, um Ihre eigenen Regeln für diese Kante anzupassen. Die Richtlinienkette bindet unterschiedliche Richtlinien über die Richtlinienkettennummer, und die Wörter und Knoten binden unterschiedliche Richtlinienketten über die Richtlinienkettennummer.
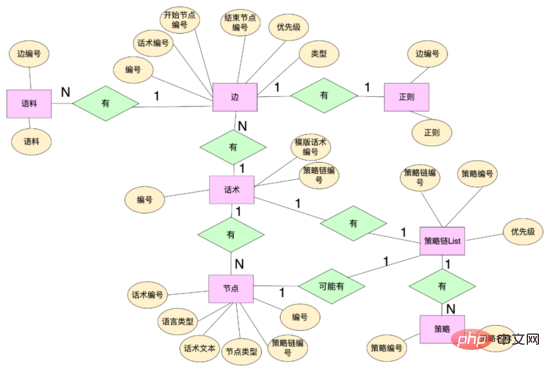
Codeebene: Die Konzepte von Kanten, Knoten, Sprachklassen und Sprachstatusklassen werden abstrahiert. Kanten und Knoten sind Abbildungen der Datenschicht, und Trefferlogik wie Regelmäßigkeit und Korpus wird auch an den Kanten beibehalten. Die Sprachklassen werden verwaltet. Schlüsselinformationen wie der Eröffnungsknoten und der Sprachgraph sind eine Abbildung der gesamten Sprachtopologie. Er verwaltet die Zuordnung zwischen Knoten und der Menge von Knoten und Kanten, die von diesem Knoten ausgehen Die Klasse behält den aktuellen Zustand der Sprache bei, einschließlich der Hua Shu-Klasse und des aktuellen Knotens. Das System kann alle Kanten ausgehend von diesem Knoten aus dem Hua Shu-Diagramm basierend auf dem aktuellen Knoten von Hua Shu erhalten (ähnlich einer Adjazenzliste) und Passen Sie die Regeln auf verschiedenen Kanten basierend auf der aktuellen Antwort des Benutzers an. Wenn es einen Treffer gibt, fließt das Sprachdiagramm zum Endknoten der Trefferkante und der Antwortinhalt des Roboters wird von diesem Knoten und der Sprachstruktur abgerufen wird fließen.
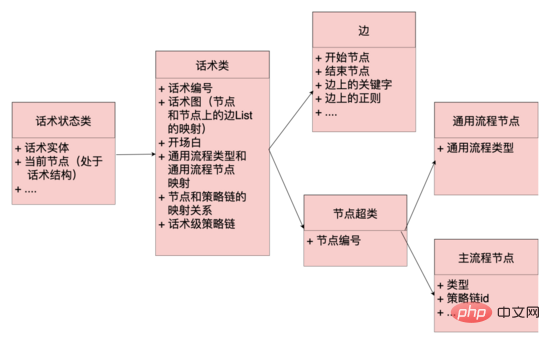
Diagrammdatenstruktur:
Durch die oben genannte Datenstruktur kann die Systemplattform schnell auf die Anpassungsanforderungen der Unternehmensseite für die Sprache reagieren. Beispielsweise kann der Personalvermittler die Fragen für jede Einstellungsposition anpassen. Wir abstrahieren diese Fragen in virtuellen Knoten und verwenden sie virtuell Kanten verbinden die virtuellen Knoten miteinander, um personalisierte Interviewfragen für verschiedene Positionen bereitzustellen und so die Wirkung von Tausenden von Menschen zu erzielen.
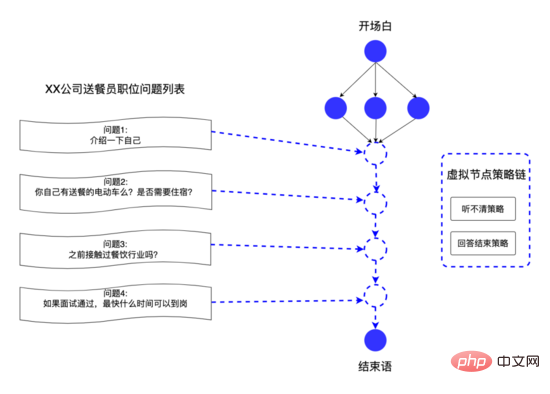
Der magische Interviewraum hat nach seiner Online-Schaltung gute Ergebnisse erzielt. Daher hofft die Geschäftsseite, dass der KI-Interviewroboter mehr als tausend Menschen online unterstützen kann Gleichzeitig konzentrieren wir uns auf vier Aspekte, einschließlich Leistungstests und -überwachung, um die Leistung des KI-Interview-Roboters effektiv zu verbessern gleichzeitig Interviewanfragen zu erhalten, war nach der Optimierung 20-mal höher als vor der Optimierung.
Ressourcenmanagementlösung: Um die im Dienst verwendeten Ressourcen besser zu verwalten und eine Ressourcenerschöpfung zu verhindern, haben wir die Ressourcenmanagementlösung wie unten gezeigt entworfen. Zunächst einigen sich der KI-Interviewroboter und die Audio- und Videokamera über SCF auf ein Kommunikationsprotokoll. Da SCF einen Lastausgleich durchführt, wird die Anfrage des Anrufers zufällig an eine bestimmte Maschine im Cluster weitergeleitet Die Anforderung trifft auf Dienstinstanz 1. Das Kommunikationsprotokoll kann an die Instanz gebunden werden. Anschließend wird das Konzept einer Sitzung abstrahiert (die Codeebene ist eine Sitzungsklasse und jede Sitzung ist ein Thread). Denn in diesem Interview werden beispielsweise Sende- und Empfangsports, Programmierung Die Dekodierungsklasse und verschiedene Thread-Ressourcen werden in der Sitzung registriert, und der Code stellt sicher, dass die in der Sitzung registrierten Ressourcen freigegeben werden, wenn die Sitzung freigegeben wird. Verschiedene Videointerviews erreichen eine Ressourcenisolation durch Thread-Isolation und erleichtern so die Ressourcenverwaltung.
Gleichzeitig ist die Sitzungsinstanz über die Sitzungs-ID (vom Anrufer über das Kommunikationsprotokoll vereinbart, das global eindeutig ist) an den Sitzungscontainer gebunden. Wenn der Benutzer auflegt, wird SCF aufgerufen, Ressourcen freizugeben. Aufgrund der Zufälligkeit von SCF kann die Anforderung Dienstinstanz 3 treffen. Auf Instanz 3 gibt es keine solche Interviewsitzung. Um Ressourcen freizugeben, verwenden wir WMB (Wuba Tongcheng). Selbstentwickelte Nachrichtenwarteschlange) Senden Sie diese Ressourcenfreigabenachricht, der Nachrichtentext enthält die Sitzungs-ID, alle Dienstinstanzen konsumieren diese Nachricht, Dienstinstanz 1 enthält die Sitzungs-ID, suchen Sie die an die Sitzungs-ID gebundene Sitzung und rufen Sie die Ressourcenfreigabefunktion auf der Sitzung wird die Ressource freigegeben (verbleibende Instanzen verwerfen die Nachricht).
Wenn die Freigabeanforderung aus irgendeinem Grund nicht ausgeführt wird, verfügt der Sitzungscontainer über einen Sitzungsüberwachungsthread, der den Lebenszyklus aller Sitzungen im Sitzungscontainer scannen und einen maximalen Lebenszyklus für die Sitzung festlegen kann (z. B. 10 Minuten). Wenn die Sitzung abläuft, lösen Sie aktiv das Recycling von Sitzungsressourcen aus und geben Sie Sitzungsressourcen frei. Gleichzeitig verwenden wir für die begrenzten Ressourcen wie Threads und Ports, die in der Sitzung angewendet werden, eine zentrale Verwaltung, verwenden den Thread-Pool zur zentralen Verwaltung von Threads, stellen alle verfügbaren Ports in eine Warteschlange und überwachen die verbleibenden Ports in der Warteschlange Gewährleistung der Stabilität und Verfügbarkeit des Dienstes. Schätzung der Maschinenressourcen: von der Sitzung
Ob temporäre Ressourcen wie Ports, Threads, Codecs und andere Ressourcen rechtzeitig recycelt werden können.
Maschinennetzwerkbandbreite
1000 MB/s >> 2500 * 32 KB/s
Maschinen-Festplattenressourcen
LRU-Beseitigung durch Händler Strategie
Thread
Indikatoren wie Aufgabengröße, Aufgabenausführungszeit und Anzahl der erstellten Threads in der Thread-Pool-Warteschlange
Leistungsexperiment:
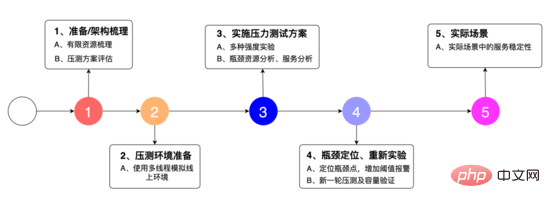
Wir haben den experimentellen Plan wie im Bild oben gezeigt entworfen: 1. Um die Systemarchitektur zu klären, die begrenzten Ressourcen zu ermitteln und den Stresstestplan zu organisieren. 2. Um die Multithread-Simulation zu verwenden Linien zur Umwelt, 3. Es handelt sich um eine Vielzahl von Festigkeitstests, Engpassressourcenanalysen und Serviceanalysen. 4. Lokalisieren Sie Engpasspunkte, fügen Sie Schwellenwertalarme hinzu und testen Sie 5. Die Stabilität des Dienstes in tatsächlichen Szenarien.
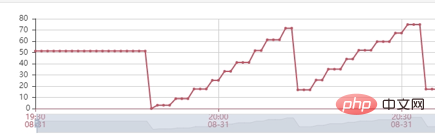
Stresstest: Als Nächstes haben wir einen Stresstest durchgeführt und verschiedene Stärke-Anforderungsvolumentests ausprobiert. Bei der Verwendung von 2500 Anfragen/Minute zum Stresstest der Schnittstelle haben wir festgestellt, dass der Hauptengpass des Dienstes der Heap-Speicher des Dienstes ist. Wie Sie im Bild unten sehen können, erreicht der Heap-Speicher des Dienstes schnell 100 % und die Schnittstelle reagiert nicht mehr. Nachdem wir den Heap-Speicher gelöscht hatten, stellten wir fest, dass sich im Heap-Speicher Hunderte von DialingInfo-Objekten befanden. Jedes Objekt belegte 18,75 MB. Wenn wir uns den Code ansehen, können wir sehen, dass dieses Objekt zum Speichern des Konversationsinhalts zwischen der KI verwendet wird Interviewroboter und Benutzer. Die beiden Objekte allRobotVoiceBuffer und allUserVoiceBuffer belegen jeweils die Hälfte der Speichergröße, allRobotVoiceBuffer wird zum Speichern der Sprachinformationen des Roboters verwendet (Speicherformat: Byte-Array) und allUserVoiceBuffer wird zum Speichern der Sprachinformationen des Benutzers verwendet.
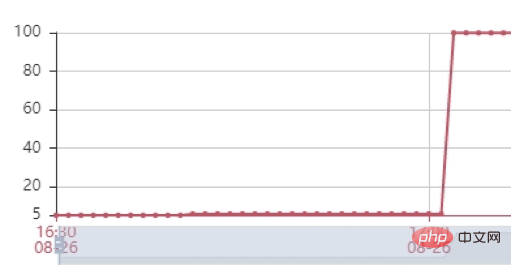
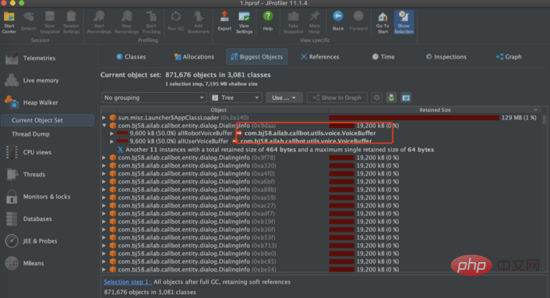
Wenn Sie sich den Code ansehen, können Sie feststellen, dass die beiden Objekte allRobotVoiceBuffer und allUserVoiceBuffer beim Initialisieren des Dienstes zusammen 18,75 MB belegen (dieser Wert liegt daran, dass 5 Minuten Audiodaten gespeichert werden müssen). Überlegen Sie, ob die Initialisierungsgröße angemessen ist. Bei der Analyse der historischen Anrufdaten im Magic Interview Room ist ersichtlich, dass 63 % der Benutzer die erste Frage des Roboters nicht beantwortet und das Interview direkt aufgelegt haben. Daher haben wir versucht, sie zu reduzieren Die anfängliche Speichergröße dieser beiden Objekte wurde auf 0,47 MB geändert (dieser Wert ist die Größe des ersten Frageaudios des Roboters), allUserVoiceBuffer beträgt gleichzeitig 0 MB, da die beiden Objekte allRobotVoiceBuffer und allUserVoiceBuffer um die ms erweitert werden können Wenn der Konversationsinhalt die Objektgröße überschreitet, kann die Erweiterung ohne Auswirkungen auf den Dienst erreicht werden. Nach der Änderung verwenden wir weiterhin Stresstests, und der Dienst kann eine stabile Speicherbereinigung erreichen.
Feingranulare Überwachung:
Indikatortyp |
Übersicht |
|
Servicekritische Indikatoren | Anfragevolumen, Erfolgsvolumen, Fehlervolumen, Da Es gibt 13 Indikatoren wie z. B. kein verfügbarer Port |
Ressourcenindikatoren |
Die verfügbare Port-Warteschlangenlänge liegt unter dem Schwellenwert, Cache-Personalisierungsprobleme überschreiten den Schwellenwert usw. 5 Indikatoren |
Prozessindikatoren |
Fehler beim Bilden von Wörtern, Fehler bei der Bereitstellung wichtiger Informationen, Fehler bei der Bereitstellung des Zeitplans usw. 52 Indikatoren |
Thread-Pool-Überwachungsindikatoren |
Anzahl der angeforderten Threads erstellt werden, die Anzahl der ausgeführten Aufgaben, die durchschnittliche Aufgabenzeit 6 Indikatoren |
Positionsindikatoren für Frage- und Antwortsitzungen |
Anomalien beim Erhalten von Sprachantworten, durchschnittliche Aufwärmzeit für Antworten usw. 9 Indikatoren |
ASR-Indikatoren |
18 Indikatoren, einschließlich der durchschnittlichen Dauer der selbst entwickelten Spracherkennung, des selbst entwickelten Erkennungsfehlers usw. |
Vad-Indikatoren |
Anzahl der Anrufe, maximaler Zeitverbrauch usw. 4 Indikatoren |
Dieser Artikel stellt hauptsächlich die Back-End-Architektur des KI-Interviewroboters vor, den gesamten Interaktionsprozess zwischen dem KI-Interviewroboter und dem Benutzer. die Kernfunktionen der Dialog-Engine und Praktiken zur Optimierung der Serviceleistung. Auch in Zukunft werden wir die funktionale Iteration und Leistungsoptimierung des Magic Interview Room-Projekts unterstützen und den KI-Interviewroboter weiter in verschiedenen Unternehmen implementieren.
1. RTP: Ein Transportprotokoll für Echtzeitanwendungen
Zhang Chi, 58 City AI Lab Backend Senior Development Engineer, 2019 Kam im Dezember 2016 zu 58.com und beschäftigt sich derzeit hauptsächlich mit Back-End-Forschungs- und Entwicklungsarbeiten im Zusammenhang mit Sprachinteraktion. 2016 schloss er sein Masterstudium an der North China University of Technology ab. Er arbeitete bei Bianlifeng und China Electronics im Bereich Backend-Entwicklung.
Das obige ist der detaillierte Inhalt vonKI-Interview-Roboter-Back-End-Architekturpraxis. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So installieren Sie den Druckertreiber unter Linux
So installieren Sie den Druckertreiber unter Linux
 Detaillierte Erläuterung der Symbolklasse in JS
Detaillierte Erläuterung der Symbolklasse in JS
 So zeigen Sie den Tomcat-Quellcode an
So zeigen Sie den Tomcat-Quellcode an
 Der Unterschied zwischen vscode und vs
Der Unterschied zwischen vscode und vs
 Mein Computer kann es nicht durch Doppelklick öffnen.
Mein Computer kann es nicht durch Doppelklick öffnen.
 Welche Software ist ae
Welche Software ist ae
 So starten Sie den Dienst im Swoole-Framework neu
So starten Sie den Dienst im Swoole-Framework neu
 So fangen Sie belästigende Anrufe ab
So fangen Sie belästigende Anrufe ab
 Einführung in den Unterschied zwischen Javascript und Java
Einführung in den Unterschied zwischen Javascript und Java








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



