
 Technologie-Peripheriegeräte
KI
Mithilfe von maschinellem Lernen Gesichter in Videos rekonstruieren
Technologie-Peripheriegeräte
KI
Mithilfe von maschinellem Lernen Gesichter in Videos rekonstruieren
Mithilfe von maschinellem Lernen Gesichter in Videos rekonstruieren

Übersetzer |. Cui Hao
Rezensent |. Eröffnung
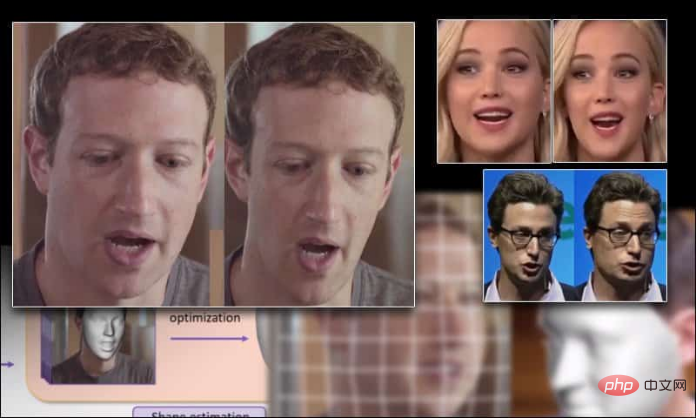 Eine gemeinsame Forschung aus China und Großbritannien hat eine neue Methode zur Umgestaltung von Gesichtern in Videos entwickelt. Diese Technologie kann die Gesichtsstruktur mit hoher Konsistenz und ohne Spuren künstlicher Beschneidung vergrößern und verkleinern.
Eine gemeinsame Forschung aus China und Großbritannien hat eine neue Methode zur Umgestaltung von Gesichtern in Videos entwickelt. Diese Technologie kann die Gesichtsstruktur mit hoher Konsistenz und ohne Spuren künstlicher Beschneidung vergrößern und verkleinern.
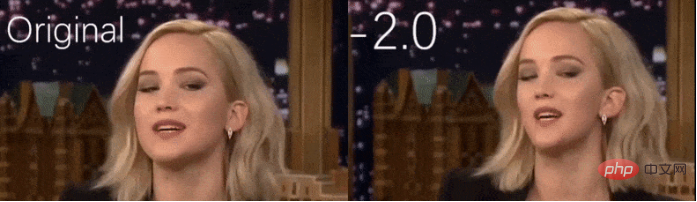 Typischerweise wird diese Transformation der Gesichtsstruktur durch traditionelle CGI-Methoden erreicht, die auf detaillierten und teuren Motion-Capping-, Rigging- und Texturierungsverfahren angewiesen sind, um das Gesicht vollständig zu rekonstruieren.
Typischerweise wird diese Transformation der Gesichtsstruktur durch traditionelle CGI-Methoden erreicht, die auf detaillierten und teuren Motion-Capping-, Rigging- und Texturierungsverfahren angewiesen sind, um das Gesicht vollständig zu rekonstruieren.
Anders als herkömmliche Methoden wird CGI in der neuen Technologie als Parameter für 3D-Gesichtsinformationen in die neuronale Pipeline integriert und dient als Grundlage für den maschinellen Lernworkflow.
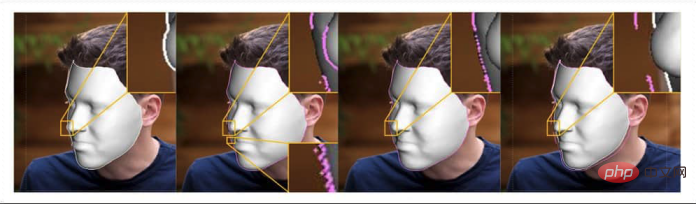 Der Autor weist darauf hin:
Der Autor weist darauf hin:
„Unser Ziel ist es, natürliche Gesichter in der realen Welt als Grundlage zu verwenden, um ihre Gesichtskonturen zu verformen und zu bearbeiten, um hochwertige Porträtrekonstruktionsvideos zu erzeugen.“ Wird für Anwendungen mit visuellen Effekten wie Gesichtsverschönerung und Gesichtsübertreibung verwendet.
Obwohl 2D-Gesichtsverzerrungstechniken seit dem Aufkommen von Photoshop für Verbraucher verfügbar sind (und eine Subkultur von Gesichtsverzerrungen und Körperdysmorphien für Videos ohne Verwendung hervorgebracht haben). CGI ist immer noch eine schwierige Technologie
 Mark Zuckerbergs Gesichtsgröße hat sich aufgrund neuer Technologien vergrößert und verkleinert
Mark Zuckerbergs Gesichtsgröße hat sich aufgrund neuer Technologien vergrößert und verkleinert
Derzeit ist die Körperumformung computergestützt ein heißes Thema im Sehbereich, vor allem wegen seines Potenzials in der Mode E-Commerce, wie zum Beispiel Menschen größer und mit vielfältigeren Knochen aussehen zu lassen, aber es gibt immer noch einige Herausforderungen
Auch hier war die Veränderung der Gesichtsform in Videos der Kern der Arbeit der Forscher Die Implementierung der Technologie wurde durch menschliche Verarbeitung und andere Einschränkungen behindert. Das neue Produkt migriert daher zuvor untersuchte Funktionen von statischen Erweiterungen auf dynamische Videoausgabe.
Das neue System wird auf einem Desktop-PC trainiert, der mit AMD Ryzen 9 3950X und 32 GB Speicher ausgestattet ist und verwendet den optischen Flussalgorithmus von OpenCV, um Bewegungskarten zu generieren und diese über das StructureFlow-Framework (FAN) zur Merkmalsschätzung zu glätten. Wird auch im beliebten Deepfakes-Komponentenpaket zur Lösung von Gesichtsoptimierungsproblemen verwendet
Beispiel für die Verwendung des neuen Systems zur Vergrößerung von Gesichtern Der Titel dieses Artikels lautet „Parametrische Umformung von Porträts in Videos“ und sein Autor ist „Über Gesichter“. Im neuen System werden Videos in Bildsequenzen extrahiert, wobei zunächst ein Basismodell für das Gesicht erstellt und dann repräsentative Folgebilder verkettet werden, wodurch konsistente Persönlichkeitsparameter entlang der gesamten Bildlaufrichtung (d. h. der Richtung des Videobilds) erstellt werden.
Der Titel dieses Artikels lautet „Parametrische Umformung von Porträts in Videos“ und sein Autor ist „Über Gesichter“. Im neuen System werden Videos in Bildsequenzen extrahiert, wobei zunächst ein Basismodell für das Gesicht erstellt und dann repräsentative Folgebilder verkettet werden, wodurch konsistente Persönlichkeitsparameter entlang der gesamten Bildlaufrichtung (d. h. der Richtung des Videobilds) erstellt werden.
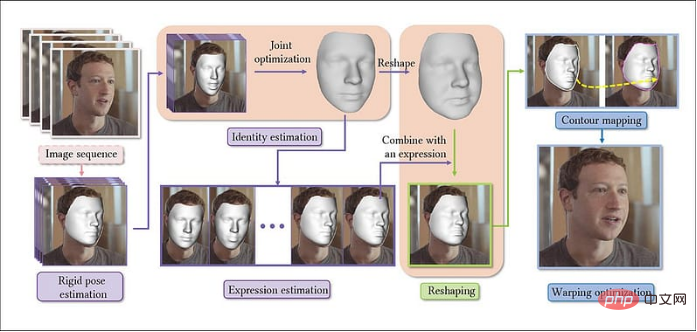
Der Arbeitsablauf des neuen Systems berücksichtigt Verdeckungssituationen, etwa wenn sich ein Objekt aus der Sicht entfernt. Dies ist auch eine der größten Herausforderungen für Deepfake-Software, da FAN-Markierungen diese Situationen kaum berücksichtigen können und ihre Übersetzungsqualität dazu neigt, sich zu verschlechtern, wenn Gesichter vermieden oder verdeckt werden.
Das neue System vermeidet die oben genannten Probleme, indem es „Konturenergie“ definiert, die den Grenzen von 3D-Gesichtern (3DMM) und 2D-Gesichtern (definiert durch FAN-Landmarken) entspricht.
Optimierung
Das Anwendungsszenario dieses Systems ist die Echtzeitverformung, beispielsweise die Gesichtsformtransformation in Echtzeit durch Filter im Video-Chat. Derzeit können Frameworks dies nicht erreichen, sodass die Bereitstellung der notwendigen Rechenressourcen, um eine „Echtzeit“-Verformung zu ermöglichen, eine erhebliche Herausforderung darstellt.
Nach der Hypothese des Papiers beträgt die Latenz jedes Bildvorgangs von 24-fps-Videos in der Pipeline im Verhältnis zum Material pro Sekunde 16,344 Sekunden. Gleichzeitig ist dies bei der Merkmalsschätzung und 3D-Gesichtsverformung der Fall ein Treffer (321 Millisekunden bzw. 160 Millisekunden) Millisekunde).
Dadurch hat die Optimierung wichtige Fortschritte bei der Reduzierung der Latenz gemacht. Da eine gemeinsame Optimierung über alle Frames den Systemaufwand erheblich erhöhen würde und die Optimierung des Initialisierungsstils (unter der Annahme durchgehend konsistenter Sprechereigenschaften) zu Anomalien führen könnte, haben die Autoren einen Sparse-Modus übernommen, um Koeffizienten in realistischen Intervallen abgetasteter Frames zu berechnen.
Dann wird eine gemeinsame Optimierung dieser Teilmenge von Frames durchgeführt, was zu einem schlankeren Rekonstruktionsprozess führt.
Facial Surfaces
Die in diesem Projekt verwendete Morphing-Technologie ist eine Adaption des Werks Deep Shapely Portraits (DSP) des Autors aus dem Jahr 2020.
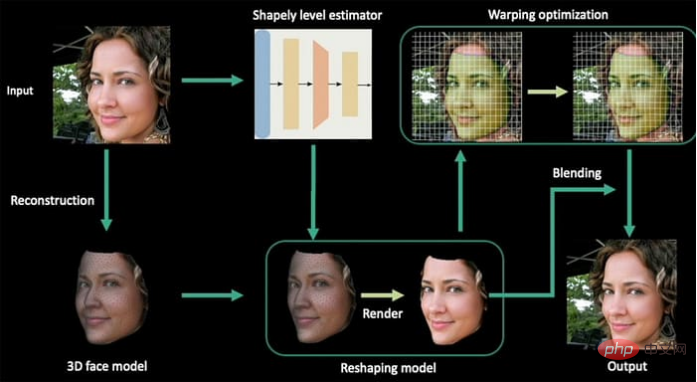
Deep Shapely Portraits, 2020 Einreichung bei ACM Multimedia. Das Papier wurde von Forschern des Joint Laboratory der Zhejiang University-Tencent Game and Intelligent Graphics Innovation Technology geleitet. Die Autoren stellten fest, dass „wir diese Methode von der Umformung eines einzelnen Bildes auf die Umformung einer gesamten Bildsequenz ausgeweitet haben.“ Das Papier stellt fest, dass es keine vergleichbaren historischen Daten zur Bewertung des neuen Ansatzes gibt. Daher verglichen die Autoren ihre gekrümmten Videoausgaberahmen mit der statischen DSP-Ausgabe.
Testen des neuen Systems anhand statischer Bilder von Deep Shapely Portraits Die Autoren weisen darauf hin, dass die DSP-Methode aufgrund der Verwendung von Sparse Mapping Spuren künstlicher Modifikation aufweist – das neue Framework löst dieses Problem durch Dense Mapping. Darüber hinaus argumentiert das Papier, dass es den von DSP produzierten Videos an Glätte und visueller Kohärenz mangele. Der Autor weist darauf hin:
Der Autor weist darauf hin:
„Die Ergebnisse zeigen, dass unsere Methode stabil und kohärent umgeformte Porträtvideos erzeugen kann, während bildbasierte Methoden leicht zu offensichtlichen Flackerartefakten (künstliche Änderungsspuren) führen können.“
Übersetzte Einführung des Autors
Cui Hao, 51CTO-Community-Redakteur, leitender Architekt, verfügt über 18 Jahre Erfahrung in Softwareentwicklung und -architektur sowie 10 Jahre Erfahrung in verteilter Architektur. Ehemals technischer Experte bei HP. Er ist bereit zu teilen und hat viele beliebte Fachartikel geschrieben, die mehr als 600.000 Mal gelesen wurden. Autor von „Distributed Architecture Principles and Practice“.
Originaltitel:
Restructuring Faces in Videos With Machine Learning
Das obige ist der detaillierte Inhalt vonMithilfe von maschinellem Lernen Gesichter in Videos rekonstruieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1383
1383
 52
52

 In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In den Bereichen maschinelles Lernen und Datenwissenschaft stand die Interpretierbarkeit von Modellen schon immer im Fokus von Forschern und Praktikern. Mit der weit verbreiteten Anwendung komplexer Modelle wie Deep Learning und Ensemble-Methoden ist das Verständnis des Entscheidungsprozesses des Modells besonders wichtig geworden. Explainable AI|XAI trägt dazu bei, Vertrauen in maschinelle Lernmodelle aufzubauen, indem es die Transparenz des Modells erhöht. Eine Verbesserung der Modelltransparenz kann durch Methoden wie den weit verbreiteten Einsatz mehrerer komplexer Modelle sowie der Entscheidungsprozesse zur Erläuterung der Modelle erreicht werden. Zu diesen Methoden gehören die Analyse der Merkmalsbedeutung, die Schätzung des Modellvorhersageintervalls, lokale Interpretierbarkeitsalgorithmen usw. Die Merkmalswichtigkeitsanalyse kann den Entscheidungsprozess des Modells erklären, indem sie den Grad des Einflusses des Modells auf die Eingabemerkmale bewertet. Schätzung des Modellvorhersageintervalls
 Identifizieren Sie Über- und Unteranpassung anhand von Lernkurven
Apr 29, 2024 pm 06:50 PM
Identifizieren Sie Über- und Unteranpassung anhand von Lernkurven
Apr 29, 2024 pm 06:50 PM
In diesem Artikel wird vorgestellt, wie Überanpassung und Unteranpassung in Modellen für maschinelles Lernen mithilfe von Lernkurven effektiv identifiziert werden können. Unteranpassung und Überanpassung 1. Überanpassung Wenn ein Modell mit den Daten übertrainiert ist, sodass es daraus Rauschen lernt, spricht man von einer Überanpassung des Modells. Ein überangepasstes Modell lernt jedes Beispiel so perfekt, dass es ein unsichtbares/neues Beispiel falsch klassifiziert. Für ein überangepasstes Modell erhalten wir einen perfekten/nahezu perfekten Trainingssatzwert und einen schrecklichen Validierungssatz-/Testwert. Leicht geändert: „Ursache der Überanpassung: Verwenden Sie ein komplexes Modell, um ein einfaches Problem zu lösen und Rauschen aus den Daten zu extrahieren. Weil ein kleiner Datensatz als Trainingssatz möglicherweise nicht die korrekte Darstellung aller Daten darstellt. 2. Unteranpassung Heru.“
 Transparent! Eine ausführliche Analyse der Prinzipien der wichtigsten Modelle des maschinellen Lernens!
Apr 12, 2024 pm 05:55 PM
Transparent! Eine ausführliche Analyse der Prinzipien der wichtigsten Modelle des maschinellen Lernens!
Apr 12, 2024 pm 05:55 PM
Laienhaft ausgedrückt ist ein Modell für maschinelles Lernen eine mathematische Funktion, die Eingabedaten einer vorhergesagten Ausgabe zuordnet. Genauer gesagt ist ein Modell für maschinelles Lernen eine mathematische Funktion, die Modellparameter anpasst, indem sie aus Trainingsdaten lernt, um den Fehler zwischen der vorhergesagten Ausgabe und der wahren Bezeichnung zu minimieren. Beim maschinellen Lernen gibt es viele Modelle, z. B. logistische Regressionsmodelle, Entscheidungsbaummodelle, Support-Vektor-Maschinenmodelle usw. Jedes Modell verfügt über seine anwendbaren Datentypen und Problemtypen. Gleichzeitig gibt es viele Gemeinsamkeiten zwischen verschiedenen Modellen oder es gibt einen verborgenen Weg für die Modellentwicklung. Am Beispiel des konnektionistischen Perzeptrons können wir es durch Erhöhen der Anzahl verborgener Schichten des Perzeptrons in ein tiefes neuronales Netzwerk umwandeln. Wenn dem Perzeptron eine Kernelfunktion hinzugefügt wird, kann es in eine SVM umgewandelt werden. Dieses hier
 Die Entwicklung der künstlichen Intelligenz in der Weltraumforschung und der Siedlungstechnik
Apr 29, 2024 pm 03:25 PM
Die Entwicklung der künstlichen Intelligenz in der Weltraumforschung und der Siedlungstechnik
Apr 29, 2024 pm 03:25 PM
In den 1950er Jahren wurde die künstliche Intelligenz (KI) geboren. Damals entdeckten Forscher, dass Maschinen menschenähnliche Aufgaben wie das Denken ausführen können. Später, in den 1960er Jahren, finanzierte das US-Verteidigungsministerium künstliche Intelligenz und richtete Labore für die weitere Entwicklung ein. Forscher finden Anwendungen für künstliche Intelligenz in vielen Bereichen, etwa bei der Erforschung des Weltraums und beim Überleben in extremen Umgebungen. Unter Weltraumforschung versteht man die Erforschung des Universums, das das gesamte Universum außerhalb der Erde umfasst. Der Weltraum wird als extreme Umgebung eingestuft, da sich seine Bedingungen von denen auf der Erde unterscheiden. Um im Weltraum zu überleben, müssen viele Faktoren berücksichtigt und Vorkehrungen getroffen werden. Wissenschaftler und Forscher glauben, dass die Erforschung des Weltraums und das Verständnis des aktuellen Zustands aller Dinge dazu beitragen können, die Funktionsweise des Universums zu verstehen und sich auf mögliche Umweltkrisen vorzubereiten
 Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Zu den häufigsten Herausforderungen, mit denen Algorithmen für maschinelles Lernen in C++ konfrontiert sind, gehören Speicherverwaltung, Multithreading, Leistungsoptimierung und Wartbarkeit. Zu den Lösungen gehören die Verwendung intelligenter Zeiger, moderner Threading-Bibliotheken, SIMD-Anweisungen und Bibliotheken von Drittanbietern sowie die Einhaltung von Codierungsstilrichtlinien und die Verwendung von Automatisierungstools. Praktische Fälle zeigen, wie man die Eigen-Bibliothek nutzt, um lineare Regressionsalgorithmen zu implementieren, den Speicher effektiv zu verwalten und leistungsstarke Matrixoperationen zu nutzen.
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Übersetzer |. Rezensiert von Li Rui |. Chonglou Modelle für künstliche Intelligenz (KI) und maschinelles Lernen (ML) werden heutzutage immer komplexer, und die von diesen Modellen erzeugten Ergebnisse sind eine Blackbox, die den Stakeholdern nicht erklärt werden kann. Explainable AI (XAI) zielt darauf ab, dieses Problem zu lösen, indem es Stakeholdern ermöglicht, die Funktionsweise dieser Modelle zu verstehen, sicherzustellen, dass sie verstehen, wie diese Modelle tatsächlich Entscheidungen treffen, und Transparenz in KI-Systemen, Vertrauen und Verantwortlichkeit zur Lösung dieses Problems gewährleistet. In diesem Artikel werden verschiedene Techniken der erklärbaren künstlichen Intelligenz (XAI) untersucht, um ihre zugrunde liegenden Prinzipien zu veranschaulichen. Mehrere Gründe, warum erklärbare KI von entscheidender Bedeutung ist. Vertrauen und Transparenz: Damit KI-Systeme allgemein akzeptiert und vertrauenswürdig sind, müssen Benutzer verstehen, wie Entscheidungen getroffen werden
 Ist Flash Attention stabil? Meta und Harvard stellten fest, dass die Gewichtsabweichungen ihrer Modelle um Größenordnungen schwankten
May 30, 2024 pm 01:24 PM
Ist Flash Attention stabil? Meta und Harvard stellten fest, dass die Gewichtsabweichungen ihrer Modelle um Größenordnungen schwankten
May 30, 2024 pm 01:24 PM
MetaFAIR hat sich mit Harvard zusammengetan, um einen neuen Forschungsrahmen zur Optimierung der Datenverzerrung bereitzustellen, die bei der Durchführung groß angelegten maschinellen Lernens entsteht. Es ist bekannt, dass das Training großer Sprachmodelle oft Monate dauert und Hunderte oder sogar Tausende von GPUs verwendet. Am Beispiel des Modells LLaMA270B erfordert das Training insgesamt 1.720.320 GPU-Stunden. Das Training großer Modelle stellt aufgrund des Umfangs und der Komplexität dieser Arbeitsbelastungen einzigartige systemische Herausforderungen dar. In letzter Zeit haben viele Institutionen über Instabilität im Trainingsprozess beim Training generativer SOTA-KI-Modelle berichtet. Diese treten normalerweise in Form von Verlustspitzen auf. Beim PaLM-Modell von Google kam es beispielsweise während des Trainingsprozesses zu Instabilitäten. Numerische Voreingenommenheit ist die Hauptursache für diese Trainingsungenauigkeit.
