
 Technologie-Peripheriegeräte
KI
Transformer vereinheitlicht voxelbasierte Darstellungen für die 3D-Objekterkennung
Technologie-Peripheriegeräte
KI
Transformer vereinheitlicht voxelbasierte Darstellungen für die 3D-Objekterkennung
Transformer vereinheitlicht voxelbasierte Darstellungen für die 3D-Objekterkennung

arXiv-Artikel „Unifying Voxel-based Representation with Transformer for 3D Object Detection“, 22. Juni, Chinesische Universität Hongkong, Universität Hongkong, Megvii Technology (in Erinnerung an Dr. Sun Jian) und Simou Technology usw.

In diesem Artikel wird ein einheitliches multimodales 3D-Objekterkennungs-Framework namens UVTR vorgeschlagen. Diese Methode zielt darauf ab, multimodale Darstellungen des Voxelraums zu vereinheitlichen und eine genaue und robuste einmodale oder kreuzmodale 3D-Erkennung zu ermöglichen. Zu diesem Zweck werden zunächst modalitätsspezifische Räume entworfen, um verschiedene Eingaben in den Voxel-Merkmalsraum darzustellen. Behalten Sie den Voxelraum ohne Höhenkomprimierung bei, verringern Sie semantische Mehrdeutigkeiten und ermöglichen Sie räumliche Interaktion. Basierend auf diesem einheitlichen Ansatz wird eine modalübergreifende Interaktion vorgeschlagen, um die inhärenten Eigenschaften verschiedener Sensoren, einschließlich Wissenstransfer und Modalfusion, vollständig zu nutzen. Auf diese Weise können geometriebewusste Ausdrücke von Punktwolken und kontextreiche Merkmale in Bildern gut genutzt werden, was zu einer besseren Leistung und Robustheit führt.
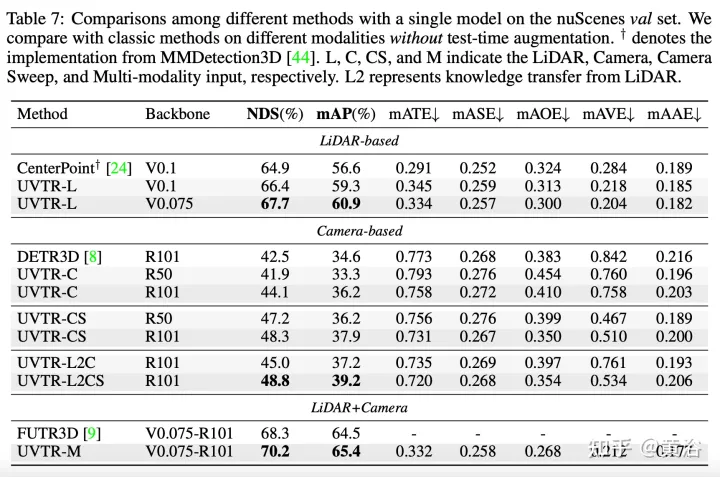
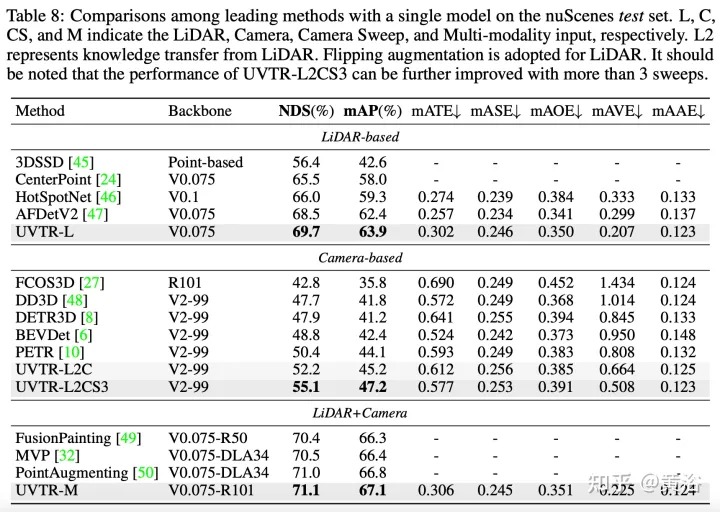
Der Transformer-Decoder wird verwendet, um Features aus einem einheitlichen Raum mit lernbaren Standorten effizient abzutasten, was Interaktionen auf Objektebene erleichtert. Im Allgemeinen stellt UVTR einen frühen Versuch dar, unterschiedliche Modalitäten in einem einheitlichen Rahmen darzustellen. Er übertrifft frühere Arbeiten zu einzelmodalen und multimodalen Eingaben und erreicht eine führende Leistung auf dem nuScenes-Testset, Lidar, Kamera und dem NDS der multimodalen Ausgabe betragen 69,7 %, 55,1 % bzw. 71,1 %.
Code: https://github.com/dvlab-research/UVTR.
Wie in der Abbildung gezeigt:
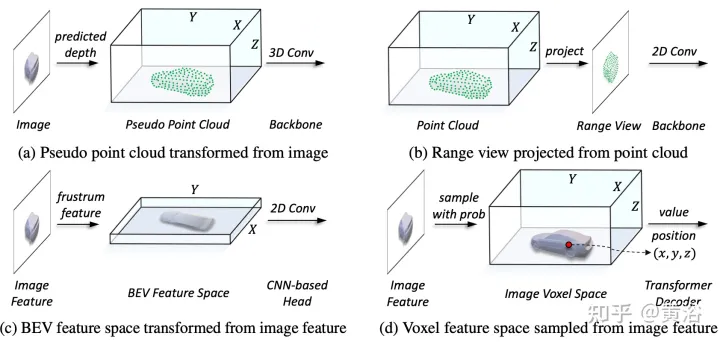
Im Darstellungsvereinheitlichungsprozess kann die Eingabe erfolgen grob unterteilt in Darstellung des Pegelflusses und charakteristischen Pegelfluss. Beim ersten Ansatz werden multimodale Daten am Anfang des Netzwerks ausgerichtet. Insbesondere wird die Pseudopunktwolke in (a) aus dem vorhergesagten tiefengestützten Bild konvertiert, während das Entfernungsansichtsbild in (b) aus der Punktwolke projiziert wird. Aufgrund von Tiefenungenauigkeiten in Pseudopunktwolken und geometrischem 3D-Zusammenbruch in Entfernungsansichtsbildern wird die räumliche Struktur der Daten zerstört, was zu schlechten Ergebnissen führt. Bei Methoden auf Merkmalsebene besteht die typische Methode darin, Bildmerkmale in Kegelstumpf umzuwandeln und sie dann in den BEV-Raum zu komprimieren, wie in Abbildung (c) dargestellt. Aufgrund seiner strahlenähnlichen Flugbahn aggregiert die Komprimierung der Höheninformationen (Höhe) an jeder Position jedoch die Merkmale verschiedener Ziele und führt so zu semantischer Mehrdeutigkeit. Gleichzeitig ist es aufgrund seines impliziten Ansatzes schwierig, explizite Merkmalsinteraktionen im 3D-Raum zu unterstützen, und schränkt den weiteren Wissenstransfer ein. Daher ist eine einheitlichere Darstellung erforderlich, um die modalen Lücken zu schließen und vielfältige Interaktionen zu erleichtern.
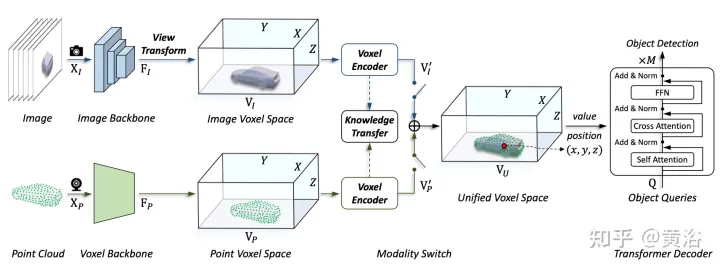
Das in diesem Artikel vorgeschlagene Framework vereinheitlicht die voxelbasierte Darstellung und den Transformator. Insbesondere Merkmalsdarstellung und Interaktion von Bildern und Punktwolken im voxelbasierten expliziten Raum. Für Bilder wird der Voxelraum durch Abtasten von Merkmalen aus der Bildebene entsprechend der vorhergesagten Tiefe und den geometrischen Einschränkungen konstruiert, wie in Abbildung (d) dargestellt. Bei Punktwolken ermöglichen genaue Standorte natürlich die Zuordnung von Merkmalen zu Voxeln. Anschließend wird ein Voxel-Encoder für die räumliche Interaktion eingeführt, um die Beziehung zwischen benachbarten Merkmalen herzustellen. Auf diese Weise verlaufen modalübergreifende Interaktionen mit Merkmalen in jedem Voxelraum auf natürliche Weise. Für Interaktionen auf Zielebene wird ein verformbarer Transformator als Decoder verwendet, um zielabfragespezifische Merkmale an jeder Position (x, y, z) im einheitlichen Voxelraum abzutasten, wie in Abbildung (d) dargestellt. Gleichzeitig wird durch die Einführung von 3D-Abfragepositionen die semantische Mehrdeutigkeit, die durch die Komprimierung von Höheninformationen (Höhe) im BEV-Raum verursacht wird, wirksam gemildert.
Wie in der Abbildung gezeigt, ist die UVTR-Architektur der multimodalen Eingabe: Bei einem Einzelbild- oder Mehrbildbild und einer Punktwolke wird es zunächst in einem einzigen Backbone verarbeitet und in modalitätsspezifische räumliche VI und VP umgewandelt. wobei die Ansichtstransformation zum Bild erfolgt. Bei Voxel-Encodern interagieren Features räumlich und der Wissenstransfer lässt sich während des Trainings leicht unterstützen. Wählen Sie je nach Einstellung über den Modalschalter monomodale oder multimodale Features aus. Schließlich werden Merkmale aus der einheitlichen räumlichen VU mit lernbaren Standorten abgetastet und mithilfe des Transformatordecoders vorhergesagt.
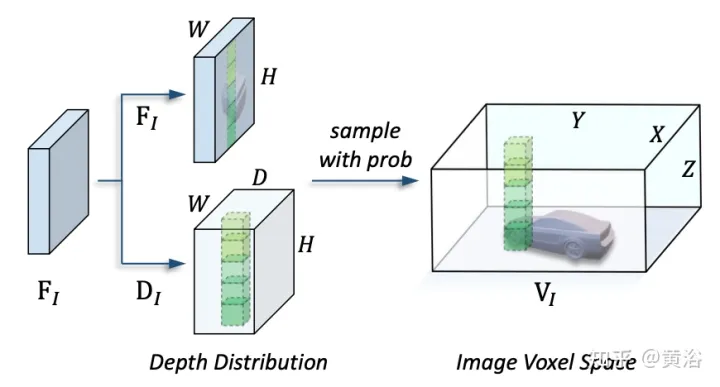
Das Bild zeigt die Details der Ansichtstransformation:
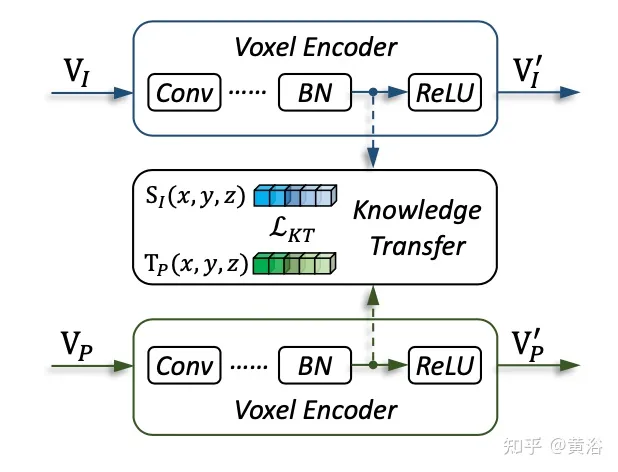
Das Bild zeigt die Details des Wissenstransfers:
Die experimentellen Ergebnisse sind wie folgt:
Das obige ist der detaillierte Inhalt vonTransformer vereinheitlicht voxelbasierte Darstellungen für die 3D-Objekterkennung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 So bewerten Sie die Kosteneffizienz der kommerziellen Unterstützung für Java-Frameworks
Jun 05, 2024 pm 05:25 PM
So bewerten Sie die Kosteneffizienz der kommerziellen Unterstützung für Java-Frameworks
Jun 05, 2024 pm 05:25 PM
Die Bewertung des Kosten-/Leistungsverhältnisses des kommerziellen Supports für ein Java-Framework umfasst die folgenden Schritte: Bestimmen Sie das erforderliche Maß an Sicherheit und Service-Level-Agreement-Garantien (SLA). Die Erfahrung und das Fachwissen des Forschungsunterstützungsteams. Erwägen Sie zusätzliche Services wie Upgrades, Fehlerbehebung und Leistungsoptimierung. Wägen Sie die Kosten für die Geschäftsunterstützung gegen Risikominderung und Effizienzsteigerung ab.
 Wie ist die Lernkurve von PHP-Frameworks im Vergleich zu anderen Sprach-Frameworks?
Jun 06, 2024 pm 12:41 PM
Wie ist die Lernkurve von PHP-Frameworks im Vergleich zu anderen Sprach-Frameworks?
Jun 06, 2024 pm 12:41 PM
Die Lernkurve eines PHP-Frameworks hängt von Sprachkenntnissen, Framework-Komplexität, Dokumentationsqualität und Community-Unterstützung ab. Die Lernkurve von PHP-Frameworks ist im Vergleich zu Python-Frameworks höher und im Vergleich zu Ruby-Frameworks niedriger. Im Vergleich zu Java-Frameworks haben PHP-Frameworks eine moderate Lernkurve, aber eine kürzere Einstiegszeit.
 Wie wirken sich die Lightweight-Optionen von PHP-Frameworks auf die Anwendungsleistung aus?
Jun 06, 2024 am 10:53 AM
Wie wirken sich die Lightweight-Optionen von PHP-Frameworks auf die Anwendungsleistung aus?
Jun 06, 2024 am 10:53 AM
Das leichte PHP-Framework verbessert die Anwendungsleistung durch geringe Größe und geringen Ressourcenverbrauch. Zu seinen Merkmalen gehören: geringe Größe, schneller Start, geringer Speicherverbrauch, verbesserte Reaktionsgeschwindigkeit und Durchsatz sowie reduzierter Ressourcenverbrauch. Praktischer Fall: SlimFramework erstellt eine REST-API, nur 500 KB, hohe Reaktionsfähigkeit und hoher Durchsatz
 Die RedMagic Tablet 3D Explorer Edition bietet eine brillenlose 3D-Anzeige
Sep 06, 2024 am 06:45 AM
Die RedMagic Tablet 3D Explorer Edition bietet eine brillenlose 3D-Anzeige
Sep 06, 2024 am 06:45 AM
Die RedMagic Tablet 3D Explorer Edition wurde zusammen mit dem Gaming Tablet Pro auf den Markt gebracht. Während sich Letzteres jedoch eher an Gamer richtet, ist Ersteres eher auf Unterhaltung ausgerichtet. Das neue Android-Tablet verfügt über das, was das Unternehmen als „3D-Funktion mit bloßem Auge“ bezeichnet
 Best Practices für die Dokumentation des Golang-Frameworks
Jun 04, 2024 pm 05:00 PM
Best Practices für die Dokumentation des Golang-Frameworks
Jun 04, 2024 pm 05:00 PM
Das Verfassen einer klaren und umfassenden Dokumentation ist für das Golang-Framework von entscheidender Bedeutung. Zu den Best Practices gehört die Befolgung eines etablierten Dokumentationsstils, beispielsweise des Go Coding Style Guide von Google. Verwenden Sie eine klare Organisationsstruktur, einschließlich Überschriften, Unterüberschriften und Listen, und sorgen Sie für eine Navigation. Bietet umfassende und genaue Informationen, einschließlich Leitfäden für den Einstieg, API-Referenzen und Konzepte. Verwenden Sie Codebeispiele, um Konzepte und Verwendung zu veranschaulichen. Halten Sie die Dokumentation auf dem neuesten Stand, verfolgen Sie Änderungen und dokumentieren Sie neue Funktionen. Stellen Sie Support und Community-Ressourcen wie GitHub-Probleme und Foren bereit. Erstellen Sie praktische Beispiele, beispielsweise eine API-Dokumentation.
 So wählen Sie das beste Golang-Framework für verschiedene Anwendungsszenarien aus
Jun 05, 2024 pm 04:05 PM
So wählen Sie das beste Golang-Framework für verschiedene Anwendungsszenarien aus
Jun 05, 2024 pm 04:05 PM
Wählen Sie das beste Go-Framework basierend auf Anwendungsszenarien aus: Berücksichtigen Sie Anwendungstyp, Sprachfunktionen, Leistungsanforderungen und Ökosystem. Gängige Go-Frameworks: Gin (Webanwendung), Echo (Webdienst), Fiber (hoher Durchsatz), gorm (ORM), fasthttp (Geschwindigkeit). Praktischer Fall: Erstellen einer REST-API (Fiber) und Interaktion mit der Datenbank (gorm). Wählen Sie ein Framework: Wählen Sie fasthttp für die Schlüsselleistung, Gin/Echo für flexible Webanwendungen und gorm für die Datenbankinteraktion.
 Detaillierte praktische Erklärung der Golang-Framework-Entwicklung: Fragen und Antworten
Jun 06, 2024 am 10:57 AM
Detaillierte praktische Erklärung der Golang-Framework-Entwicklung: Fragen und Antworten
Jun 06, 2024 am 10:57 AM
Bei der Go-Framework-Entwicklung treten häufige Herausforderungen und deren Lösungen auf: Fehlerbehandlung: Verwenden Sie das Fehlerpaket für die Verwaltung und Middleware zur zentralen Fehlerbehandlung. Authentifizierung und Autorisierung: Integrieren Sie Bibliotheken von Drittanbietern und erstellen Sie benutzerdefinierte Middleware zur Überprüfung von Anmeldeinformationen. Parallelitätsverarbeitung: Verwenden Sie Goroutinen, Mutexe und Kanäle, um den Ressourcenzugriff zu steuern. Unit-Tests: Verwenden Sie Gotest-Pakete, Mocks und Stubs zur Isolierung sowie Code-Coverage-Tools, um die Angemessenheit sicherzustellen. Bereitstellung und Überwachung: Verwenden Sie Docker-Container, um Bereitstellungen zu verpacken, Datensicherungen einzurichten und Leistung und Fehler mit Protokollierungs- und Überwachungstools zu verfolgen.
 Was sind die häufigsten Missverständnisse im Lernprozess des Golang-Frameworks?
Jun 05, 2024 pm 09:59 PM
Was sind die häufigsten Missverständnisse im Lernprozess des Golang-Frameworks?
Jun 05, 2024 pm 09:59 PM
Beim Go-Framework-Lernen gibt es fünf Missverständnisse: übermäßiges Vertrauen in das Framework und eingeschränkte Flexibilität. Wenn Sie die Framework-Konventionen nicht befolgen, wird es schwierig, den Code zu warten. Die Verwendung veralteter Bibliotheken kann zu Sicherheits- und Kompatibilitätsproblemen führen. Die übermäßige Verwendung von Paketen verschleiert die Codestruktur. Das Ignorieren der Fehlerbehandlung führt zu unerwartetem Verhalten und Abstürzen.
