
 Technologie-Peripheriegeräte
KI
Erforschung der multimodalen Technologie in Taobao-Hauptsucherinnerungsszenarien
Technologie-Peripheriegeräte
KI
Erforschung der multimodalen Technologie in Taobao-Hauptsucherinnerungsszenarien
Erforschung der multimodalen Technologie in Taobao-Hauptsucherinnerungsszenarien

Sucherinnerung als Grundlage des Suchsystems bestimmt die Obergrenze der Effektverbesserung. Die größte Herausforderung, vor der wir stehen, besteht darin, den bestehenden massiven Rückrufergebnissen weiterhin einen differenzierten Mehrwert zu verleihen. Die Kombination aus multimodalem Pre-Training und Recall eröffnet uns neue Horizonte und bringt eine deutliche Verbesserung der Online-Effekte.
Vorwort
Multimodales Vortraining steht im Mittelpunkt der Forschung in Wissenschaft und Industrie. Durch Vortraining an großen Datenmengen kann die semantische Korrespondenz zwischen verschiedenen Modalitäten ermittelt werden, die auf vielfältige Weise verwendet werden kann Bei nachgelagerten Aufgaben können beispielsweise visuelles Beantworten von Fragen, visuelles Denken sowie das Abrufen von Bildern und Texten den Effekt verbessern. Innerhalb der Gruppe gibt es auch einige Forschungen und Anwendungen zum multimodalen Vortraining. Im Taobao-Hauptsuchszenario besteht ein natürlicher modalübergreifender Abrufbedarf zwischen der vom Benutzer eingegebenen Suchanfrage und den abzurufenden Produkten. In der Vergangenheit wurden jedoch mehr Titel und statistische Merkmale für Produkte verwendet. und intuitivere Funktionen wie Bilder wurden ignoriert. Aber bei bestimmten Suchanfragen mit visuellen Elementen (z. B. weißes Kleid, Blumenkleid) glaube ich, dass jeder von dem Bild zuerst auf der Suchergebnisseite angezogen wird.

Taobao-Hauptsuchszene
Einerseits nimmt das Bild eine prominentere Position ein, andererseits enthält das Bild möglicherweise Informationen, die nicht im Titel enthalten sind. wie weiße, gebrochene visuelle Elemente wie Blumen. Bei Letzterem sind zwei Situationen zu unterscheiden: Zum einen sind zwar Informationen im Titel vorhanden, diese können aber aufgrund von Anzeigeeinschränkungen nicht vollständig angezeigt werden. Zum anderen hat dies keinen Einfluss auf den Rückruf des Produkts Es gibt keine Informationen im Titel, sondern im Bild. Das heißt, das Bild kann relativ zum Text inkrementiert werden. Auf Letzteres müssen wir uns konzentrieren.
▐ Technische Probleme und Lösungen
Bei der Anwendung multimodaler Technologie im Hauptszenario für Suche und Rückruf müssen zwei Hauptprobleme gelöst werden:
- Multimodal Grafik- und Text-Vortraining Das Modell integriert im Allgemeinen zwei Modi: Bild und Text. Aufgrund der Existenz von Query muss die Hauptsuche zusätzliche Textmodi berücksichtigen, die auf den ursprünglichen Grafik- und Textmodi von Produktbildern und -titeln basieren. Gleichzeitig besteht eine semantische Lücke zwischen Suchanfragen und Produkttiteln, die relativ kurz und breit sind, während Produkttitel oft lang und mit Schlüsselwörtern gefüllt sind, weil Verkäufer SEO betreiben.
- Normalerweise besteht die Beziehung zwischen Pre-Training-Aufgaben und Downstream-Aufgaben darin, dass beim Pre-Training umfangreiche unbeschriftete Daten verwendet werden und bei Downstream-Aufgaben eine kleine Menge beschrifteter Daten verwendet wird. Für die Hauptsuche und den Rückruf ist der Umfang der nachgelagerten Vektorrückrufaufgabe jedoch riesig, mit Daten in Milliardenhöhe. Aufgrund der begrenzten GPU-Ressourcen kann das Vortraining jedoch nur eine relativ kleine Datenmenge verwenden. In diesem Fall geht es darum, ob eine Vorschulung auch Vorteile für nachgelagerte Aufgaben bringen kann.
Unsere Lösung lautet wie folgt:
- Text-Bild-Vorschulung : Leiten Sie die Abfrage bzw. das Produktelement durch den Encoder und geben Sie sie als Zwillingstürme in den modalübergreifenden Encoder ein. Wenn wir uns die Abfrage- und Artikeltürme ansehen, interagieren sie erst in einem späteren Stadium, ähnlich wie beim Zwei-Stream-Modell. Wenn wir uns jedoch speziell den Artikelturm ansehen, interagieren die beiden Modi Bild und Titel in diesem Teil ist ein Single-Stream-Modell. Daher unterscheidet sich unsere Modellstruktur von herkömmlichen Single-Stream- oder Dual-Stream-Strukturen. Der Ausgangspunkt dieses Entwurfs besteht darin, Abfragevektoren und Elementvektoren effektiver zu extrahieren, Eingaben für das Downstream-Twin-Tower-Vektorrückrufmodell bereitzustellen und die Methode zur Modellierung des Twin-Tower-Innenprodukts in der Vortrainingsphase einzuführen. Um die semantische Verbindung und Lücke zwischen Abfrage und Titel zu modellieren, teilen wir die Zwillingstürme Encoder of Query und Item und lernen dann das Sprachmodell separat.
- Verknüpfung zwischen Vortrainings- und Rückrufaufgaben : Basierend auf der Beispielkonstruktionsmethode und dem Verlust der nachgeschalteten Vektorrückrufaufgabe werden die Aufgaben und Modellierungsmethoden in der Vortrainingsphase entworfen. Im Gegensatz zu herkömmlichen Bild- und Textabgleichsaufgaben verwenden wir Abfrage-Element- und Abfrage-Bild-Abgleichsaufgaben und verwenden das Element mit den meisten Klicks unter Abfrage als positive Stichprobe und andere Stichproben im Stapel als negative Stichproben die Zwillingstürme von Query und Item, die nach dem Prinzip eines inneren Produkts modelliert werden. Der Ausgangspunkt dieses Entwurfs besteht darin, das Vortraining näher an die Vektorrückrufaufgabe heranzuführen und mit begrenzten Ressourcen so weit wie möglich effektive Eingaben für nachgelagerte Aufgaben bereitzustellen. Wenn bei der Vektorrückrufaufgabe der Eingabevektor vor dem Training während des Trainingsprozesses festgelegt wird, kann er außerdem nicht effektiv an große Datenmengen angepasst werden. Aus diesem Grund haben wir auch den Eingabevektor vor dem Training im Vektor modelliert Rückrufaufgabe. Aktualisierung der Trainingsvektoren. Vorab trainiertes Modell Es gibt drei Hauptmethoden zum Extrahieren von Features aus Bildern: Verwenden eines im CV-Bereich trainierten Modells zum Extrahieren von RoI-Features, Grid-Features und Patch-Features des Bildes. Aus Sicht der Modellstruktur gibt es je nach den unterschiedlichen Fusionsmethoden von Bildmerkmalen und Textmerkmalen zwei Haupttypen: Single-Stream-Modell oder Dual-Stream-Modell. Im Single-Stream-Modell werden Bildmerkmale und Textmerkmale zusammengefügt und in einem frühen Stadium in den Encoder eingegeben, während im Dual-Stream-Modell Bildmerkmale und Textmerkmale jeweils in zwei unabhängige Encoder eingegeben werden Eingabe in den Cross-Modal-Encoder zur Verarbeitung von Fusion.
▐
Erste ErkundungDie Art und Weise, wie wir Bildmerkmale extrahieren, ist: Teilen Sie das Bild in eine Folge von Patches und extrahieren Sie mit ResNet die Bildmerkmale jedes Patches. In Bezug auf die Modellstruktur haben wir eine Single-Stream-Struktur ausprobiert, das heißt, Abfrage, Titel und Bild zusammengefügt und in den Encoder eingegeben. Nach mehreren Versuchsreihen haben wir herausgefunden, dass es bei dieser Struktur schwierig ist, reine Abfragevektoren und Elementvektoren als Eingabe für die Downstream-Zwillingsturm-Vektorrückrufaufgabe zu extrahieren. Wenn Sie beim Extrahieren eines bestimmten Vektors unnötige Modi ausblenden, stimmt die Vorhersage nicht mit dem Training überein. Dieses Problem ähnelt dem direkten Extrahieren des Zwillingsturmmodells aus einem interaktiven Modell. Unserer Erfahrung nach ist dieses Modell nicht so effektiv wie das trainierte Zwillingsturmmodell. Darauf aufbauend schlagen wir eine neue Modellstruktur vor. ▐
Modellstruktur
Der untere Teil des Modells besteht aus Zwillingstürmen und der obere Teil ist mit dem Zwilling verschmolzen Türme durch einen modalübergreifenden Encoder. Im Gegensatz zur Dual-Stream-Struktur bestehen die Zwillingstürme nicht aus einer einzigen Modalität: Titel und Bild werden zusammengefügt und in den Encoder eingegeben Single-Stream-Modell. Um die semantische Verbindung und Lücke zwischen Abfrage und Titel zu modellieren, teilen wir den Encoder der Zwillingstürme Abfrage und Element und lernen dann das Sprachmodell separat. Für die Vorbereitung auf das Training ist auch die Gestaltung geeigneter Aufgaben von entscheidender Bedeutung. Wir haben die häufig verwendeten Bild-Text-Übereinstimmungsaufgaben von Titel und Bild ausprobiert. Obwohl damit ein relativ hoher Übereinstimmungsgrad erzielt werden kann, bringt dies nur einen geringen Gewinn für die nachgelagerte Vektorabrufaufgabe. Dies liegt daran, dass bei der Verwendung von Query der Titel verwendet wird Der Artikel und ob das Bild übereinstimmt, ist nicht der entscheidende Faktor. Daher berücksichtigen wir beim Entwerfen von Aufgaben stärker die Beziehung zwischen Abfrage und Element. Derzeit werden insgesamt 5 Vortrainingsaufgaben verwendet.
▐ Aufgabe vor dem Training
- Masked Language Modeling (MLM): Maskieren Sie im Text-Token zufällig 15 % und verwenden Sie den verbleibenden Text und die verbleibenden Bilder, um das maskierte Text-Token vorherzusagen. Für Query und Title gibt es entsprechende MLM-Aufgaben. MLM minimiert den Kreuzentropieverlust:
 wobei das verbleibende Text-Token darstellt
wobei das verbleibende Text-Token darstellt
- Masked Patch Modeling (MPM): Maskieren Sie im Patch-Token des Bildes zufällig 25 % und verwenden Sie das verbleibende Bild und den verbleibenden Text Maskiertes Bild-Token. MPM minimiert KL-Divergenzverlust: wobei die verbleibenden Bildtoken darstellt
-
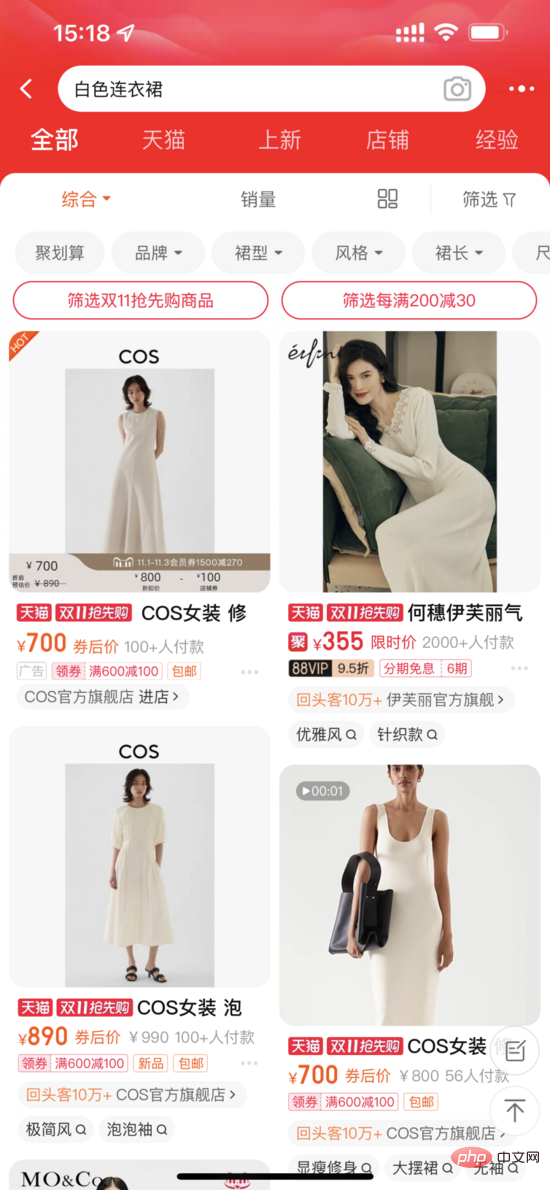
Query Item Classification (QIC): Das Element mit den meisten Klicks unter einer Abfrage wird als positive Stichprobe und andere Stichproben verwendet im Batch werden als Negativprobe verwendet. QIC reduziert die Dimensionalität des Query Tower- und Item Tower-Tokens [CLS] über die lineare Schicht auf 256 Dimensionen und führt dann eine Ähnlichkeitsberechnung durch, um die vorhergesagte Wahrscheinlichkeit zu erhalten und den Kreuzentropieverlust zu minimieren: Darunter kann Zur Berechnung stehen verschiedene Methoden zur Verfügung:
 wobei das verbleibende Text-Token darstellt
wobei das verbleibende Text-Token darstellt
 wobei die verbleibenden Bildtoken darstellt
wobei die verbleibenden Bildtoken darstellt
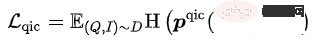 Darunter
Darunter  kann Zur Berechnung stehen verschiedene Methoden zur Verfügung:
kann Zur Berechnung stehen verschiedene Methoden zur Verfügung:
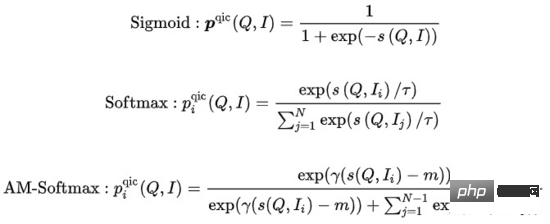
wobei die Ähnlichkeitsberechnung darstellt, den Temperaturhyperparameter darstellt, und m den Skalierungsfaktor bzw. den Relaxationsfaktor darstellen
- Query Item Matching (QIM): Das Element mit den meisten Klicks unter einer Abfrage wird als positive Stichprobe verwendet, und andere Elemente im Stapel, die der aktuellen Abfrage am ähnlichsten sind, werden als negative Stichproben verwendet. QIM verwendet das [CLS]-Token des Cross-Modal-Encoders, um die Vorhersagewahrscheinlichkeit zu berechnen und den Kreuzentropieverlust zu minimieren:
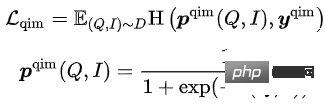
- Query Image Matching (QIM2): In QIM-Beispielen entfernt Mask Titel und Verstärkt die Abfrageübereinstimmung mit dem Bild. QIM2 minimiert den Kreuzentropieverlust:
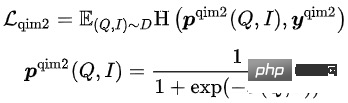
Das Trainingsziel des Modells besteht darin, den Gesamtverlust zu minimieren:
Unter diesen 5 Vortrainingsaufgaben befinden sich die MLM-Aufgabe und die MPM-Aufgabe über dem Item Tower, Modellierung Titel Oder die Fähigkeit, modalübergreifende Informationen zu verwenden, um sich gegenseitig wiederherzustellen, nachdem ein Teil des Tokens des Bildes maskiert wurde. Über dem Abfrageturm gibt es eine unabhängige MLM-Aufgabe. Durch die gemeinsame Nutzung des Encoders des Abfrageturms und des Artikelturms werden die semantische Beziehung und die Lücke zwischen Abfrage und Titel modelliert. Die QIC-Aufgabe verwendet das innere Produkt der beiden Türme, um die Vortrainings- und Downstream-Vektorrückrufaufgaben bis zu einem gewissen Grad auszurichten, und verwendet AM-Softmax, um den Abstand zwischen der Darstellung der Abfrage und der Darstellung der am häufigsten angeklickten Elemente unter der Abfrage zu schließen , und verschieben Sie den Abstand zwischen der Abfrage und den am häufigsten angeklickten Elementen. Die QIM-Aufgabe befindet sich oberhalb des modalübergreifenden Encoders und verwendet modalübergreifende Informationen, um die Übereinstimmung von Abfrage und Element zu modellieren. Aufgrund des Rechenaufwands beträgt das positive und negative Stichprobenverhältnis der üblichen NSP-Aufgabe 1:1. Um den Abstand zwischen positiven und negativen Stichproben weiter zu vergrößern, wird eine schwierige negative Stichprobe basierend auf den Ergebnissen der Ähnlichkeitsberechnung erstellt QIC-Aufgabe. Die QIM2-Aufgabe befindet sich an derselben Stelle wie die QIM-Aufgabe und modelliert explizit die inkrementellen Informationen, die Bilder relativ zu Text liefern. „Vektorrückrufmodell“ Aus Leistungsgründen wird häufig die Struktur der Benutzer- und Artikel-Zwillingstürme zur Berechnung des inneren Produkts von Vektoren verwendet. Ein Kernproblem des Vektorrückrufmodells ist: Wie werden positive und negative Proben erstellt und wie groß ist die Anzahl der negativen Proben. Unsere Lösung besteht darin, den Klick des Benutzers auf einen Artikel auf einer Seite als positive Stichprobe zu verwenden, Zehntausende negativer Stichproben basierend auf der Klickverteilung im gesamten Produktpool abzutasten und mithilfe von „Sampled Softmax Loss“ aus der Stichprobe abzuleiten, dass die Der Artikel befindet sich im vollständigen Produktpool mit Klickwahrscheinlichkeit.
wobei
die Ähnlichkeitsberechnung darstellt, den Temperatur-Hyperparameter
darstellt▐ Erste Erkundung
Nach dem gängigen FineTune-Paradigma haben wir versucht, vorab trainierte Vektoren direkt in Twin Towers MLP einzugeben und dabei groß angelegte negative Stichproben und Sampled Softmax zu kombinieren, um den multimodalen Vektorabruf zu trainieren Modell. Im Gegensatz zu den üblichen kleinen Downstream-Aufgaben ist die Trainingsstichprobengröße der Vektorrückrufaufgabe jedoch riesig und liegt in der Größenordnung von Milliarden. Wir haben beobachtet, dass die Parametermenge von MLP das Training des Modells nicht unterstützen kann und bald seinen eigenen Konvergenzzustand erreichen wird, aber der Effekt ist nicht gut. Gleichzeitig werden vorab trainierte Vektoren im Vektorabrufmodell als Eingaben und nicht als Parameter verwendet und können im Verlauf des Trainings nicht aktualisiert werden. Infolgedessen steht das Vortraining für relativ kleine Datenmengen im Widerspruch zu nachgelagerten Aufgaben für große Datenmengen.
Es gibt mehrere Lösungen, das Pre-Training-Modell in das Vektor-Recall-Modell zu integrieren. Allerdings ist die Anzahl der Parameter des Pre-Training-Modells zu groß und mit der Stichprobengröße des Vektor-Recall-Modells verbunden , es kann bei begrenzten Ressourcen nicht verwendet werden. Führen Sie als Nächstes regelmäßige Schulungen zu einem angemessenen Zeitpunkt durch. Eine andere Methode besteht darin, im Vektorabrufmodell eine Parametermatrix zu erstellen, die vorab trainierten Vektoren in die Matrix zu laden und die Parameter der Matrix im Verlauf des Trainings zu aktualisieren. Nach Untersuchungen ist diese Methode hinsichtlich der technischen Umsetzung relativ aufwändig. Auf dieser Grundlage schlagen wir eine Modellstruktur vor, die Vektoraktualisierungen vor dem Training einfach und machbar modelliert.
▐ Modellstruktur
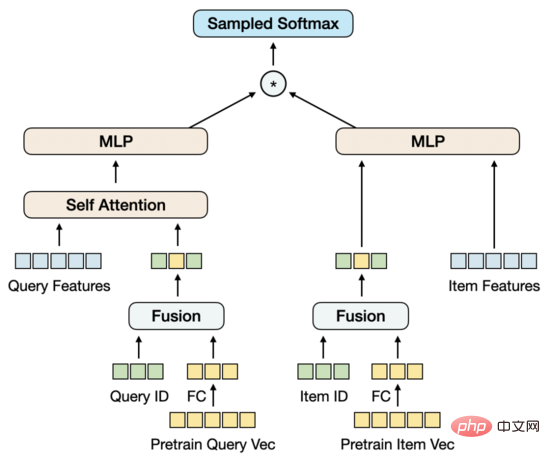
Wir reduzieren zunächst die Dimension des Pre-Training-Vektors durch FC. Der Grund, warum die Dimension hier statt im Pre-Training reduziert wird, liegt im Strom Der hochdimensionale Vektor liegt für eine negative Probenentnahme immer noch im akzeptablen Leistungsbereich. In diesem Fall entspricht die Dimensionsreduzierung bei der Vektorrückrufaufgabe eher dem Trainingsziel. Gleichzeitig führen wir die ID-Einbettungsmatrix von Abfrage und Element ein. Die Einbettungsdimension stimmt mit der Dimension des reduzierten Vortrainingsvektors überein und führt dann die ID und den Vortrainingsvektor zusammen. Der Ausgangspunkt dieses Entwurfs besteht darin, eine Parametermenge einzuführen, die ausreicht, um umfangreiche Trainingsdaten zu unterstützen, und gleichzeitig eine adaptive Aktualisierung des Vortrainingsvektors im Verlauf des Trainings zu ermöglichen.
Bei der Fusion nur von ID- und Pre-Training-Vektoren übersteigt die Wirkung des Modells nicht nur die Wirkung des Twin-Tower-MLP, das nur Pre-Training-Vektoren verwendet, sondern auch das Basismodell MGDSPR, das enthält weitere Funktionen. Darüber hinaus kann die Einführung weiterer Funktionen auf dieser Basis den Effekt weiter verbessern.
Experimentelle Analyse
▐ Bewertungsindikatoren
Für die Wirkung des Pre-Training-Modells werden normalerweise die Indikatoren der nachgelagerten Aufgaben zur Bewertung verwendet, und einzelne Bewertungsindikatoren werden selten verwendet . Auf diese Weise sind jedoch die Iterationskosten des vorab trainierten Modells relativ hoch, da für jede Iteration einer Version des Modells die entsprechende Vektorrückrufaufgabe trainiert und anschließend die Indikatoren der Vektorrückrufaufgabe ausgewertet werden müssen Der gesamte Prozess wird sehr lang sein. Gibt es wirksame Metriken für die alleinige Bewertung vorab trainierter Modelle? Wir haben Rank@K zum ersten Mal in einigen Artikeln ausprobiert. Dieser Indikator wird hauptsächlich zur Bewertung der Bild-Text-Übereinstimmungsaufgabe verwendet: Verwenden Sie zunächst das vorab trainierte Modell, um den künstlich erstellten Kandidatensatz zu bewerten, und berechnen Sie dann die Top-K-Ergebnisse, sortiert nach Trefferquote für Bild und Text Der Anteil übereinstimmender positiver Proben. Wir haben Rank@K direkt auf die Abfrage-Element-Zuordnungsaufgabe angewendet und festgestellt, dass die Ergebnisse nicht den Erwartungen entsprachen. Ein besseres Pre-Training-Modell mit Rank@K kann im Downstream-Vektor-Recall-Modell schlechtere Ergebnisse erzielen und kann Pre-Training nicht leiten. Training. Iterationen des Trainings des Modells. Auf dieser Grundlage vereinheitlichen wir die Bewertung des Vortrainingsmodells und die Bewertung des Vektorrückrufmodells und verwenden dieselben Bewertungsindikatoren und -prozesse, die die Iteration des Vortrainingsmodells relativ effektiv steuern können.
Recall@K: Der Bewertungsdatensatz besteht aus den Daten des nächsten Tages des Trainingssatzes. Zuerst werden die Klick- und Transaktionsergebnisse verschiedener Benutzer unter derselben Abfrage in  aggregiert Die vom Modell vorhergesagten Top-K-Ergebnisse werden berechnet Pre-Training/Vektor-Recall-Modell und verwenden Sie den Abruf des nächsten Nachbarn, um eine Abfrage der Top-K-Elemente zu erhalten. Dieser Prozess simuliert den Vektorrückruf in der Online-Engine, um die Konsistenz zwischen Offline und Online aufrechtzuerhalten. Für das vorab trainierte Modell besteht der Unterschied zwischen diesem Indikator und Rank@K darin, dass die Abfrage- und Elementvektoren aus dem Modell für den Abruf des inneren Vektorprodukts extrahiert werden, anstatt direkt das Modalfusionsmodell zu verwenden, um zusätzlich eine Abfrage zu bewerten Um nicht nur übereinstimmende Elemente abzurufen, ist es auch erforderlich, Klicks und Transaktionselemente verschiedener Benutzer im Rahmen dieser Abfrage abzurufen.
aggregiert Die vom Modell vorhergesagten Top-K-Ergebnisse werden berechnet Pre-Training/Vektor-Recall-Modell und verwenden Sie den Abruf des nächsten Nachbarn, um eine Abfrage der Top-K-Elemente zu erhalten. Dieser Prozess simuliert den Vektorrückruf in der Online-Engine, um die Konsistenz zwischen Offline und Online aufrechtzuerhalten. Für das vorab trainierte Modell besteht der Unterschied zwischen diesem Indikator und Rank@K darin, dass die Abfrage- und Elementvektoren aus dem Modell für den Abruf des inneren Vektorprodukts extrahiert werden, anstatt direkt das Modalfusionsmodell zu verwenden, um zusätzlich eine Abfrage zu bewerten Um nicht nur übereinstimmende Elemente abzurufen, ist es auch erforderlich, Klicks und Transaktionselemente verschiedener Benutzer im Rahmen dieser Abfrage abzurufen.
Für das Vektorrückrufmodell müssen Sie nach dem Anstieg von Recall@K auf ein bestimmtes Niveau auch auf die Korrelation zwischen Abfrage und Element achten. Ein Modell mit geringer Relevanz wird, selbst wenn es die Sucheffizienz verbessern kann, auch mit einer Verschlechterung der Benutzererfahrung und einer Zunahme von Beschwerden und einer Zunahme der öffentlichen Meinung aufgrund einer Zunahme schlechter Fälle konfrontiert sein. Wir verwenden ein Offline-Modell, das mit dem Online-Korrelationsmodell konsistent ist, um die Korrelation zwischen Abfrage und Artikel sowie zwischen Abfrage- und Artikelkategorien zu bewerten.
▐ Experiment vor dem Training
Wir haben in einigen Kategorien einen Produktpool mit einer Ebene von 100 Millionen ausgewählt, um einen Datensatz vor dem Training zu erstellen.
Unser Basismodell ist ein optimiertes FashionBert, das QIM- und QIM2-Aufgaben hinzufügt. Beim Extrahieren von Abfrage- und Elementvektoren verwenden wir Mean Pooling nur für Nicht-Padding-Tokens. Die folgenden Experimente untersuchen die Vorteile, die die Modellierung mit zwei Türmen im Vergleich zu einem einzelnen Turm mit sich bringt, und geben die Rolle wichtiger Teile durch Ablationsexperimente an.

Aus diesen Experimenten können wir folgende Schlussfolgerungen ziehen:
- Experiment 8 vs. Experiment 3: Das optimierte Zwei-Turm-Modell liegt deutlich höher als die Einzelturm-Basislinie in Recall@1000.
- Experiment 3 vs. Experiment 1/2: Für das Einzelturmmodell ist es wichtig, wie die Abfrage- und Elementvektoren extrahiert werden. Wir haben versucht, das [CLS]-Token sowohl für die Abfrage als auch für das Element zu verwenden, und haben schlechte Ergebnisse erhalten. Experiment 1 verwendet entsprechende Token für Abfrage bzw. Element, um Mean Pooling durchzuführen, und der Effekt ist besser, aber ein weiteres Entfernen des Padding-Tokens und die anschließende Durchführung von Mean Pooling bringen eine größere Verbesserung. Experiment 2 bestätigte, dass die explizite Modellierung des Query-Image-Matchings zur Hervorhebung von Bildinformationen Verbesserungen bringen wird.
- Experiment 6 vs. Experiment 4/5: Experiment 4 hat die MLM/MPM-Aufgabe des Item-Towers auf den modalübergreifenden Encoder verschoben, und der Effekt wird schlimmer sein, da das Platzieren dieser beiden Aufgaben im Item-Tower das Lernen verbessern kann Artikeldarstellung; Darüber hinaus weist die modalübergreifende Wiederherstellung basierend auf Titel und Bild im Artikelturm eine stärkere Übereinstimmung auf. Experiment 5 bestätigte, dass das Hinzufügen der L2-Norm zu Abfrage- und Elementvektoren während des Trainings und der Vorhersage zu Verbesserungen führt.
- Experiment 6/7/8: Die Änderung des Verlusts der QIC-Aufgabe bringt eine Verbesserung. Im Vergleich zu Sigmoid liegt Softmax näher an der Downstream-Vektorrückrufaufgabe, und AM-Softmax vergrößert den Abstand zwischen positiven und negativen Proben weiter. .
▐ Vector Recall Experiment
Wir haben 1 Milliarde angeklickte Seiten ausgewählt, um einen Vektor-Recall-Datensatz zu erstellen. Jede Seite enthält 3 Klickelemente als positive Proben, und 10.000 negative Proben werden basierend auf der Klickverteilung aus dem Produktpool entnommen. Auf dieser Grundlage konnte keine signifikante Verbesserung des Effekts durch eine weitere Ausweitung der Trainingsdatenmenge oder eine negative Probenentnahme beobachtet werden.
Unser Basismodell ist das MGDSPR-Modell der Hauptsuche. Die folgenden Experimente untersuchen die Vorteile, die durch die Kombination von multimodalem Vortraining mit Vektorrückruf im Vergleich zur Grundlinie erzielt werden, und geben die Rolle wichtiger Teile durch Ablationsexperimente an.
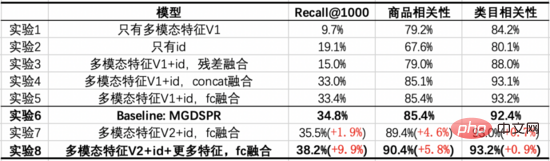
Aus diesen Experimenten können wir die folgenden Schlussfolgerungen ziehen:
- Experiment 7/8 vs. Experiment 6: Nach der Fusion multimodaler Merkmale und ID durch FC übertraf es den Ausgangswert in drei Indikatoren und stieg gleichzeitig an Durch Recall@1000 wird auch die Produktrelevanz noch weiter verbessert. Auf dieser Grundlage kann das Hinzufügen derselben Funktionen wie Baseline drei Indikatoren weiter verbessern und Recall@1000 noch weiter verbessern.
- Experiment 1 vs. Experiment 2: Im Vergleich zu nur ID weisen nur multimodale Merkmale einen geringeren Recall@1000, aber eine höhere Korrelation auf, und die Korrelation liegt nahe an dem online verfügbaren Grad. Dies zeigt, dass das multimodale Rückrufmodell zu diesem Zeitpunkt weniger schlechte Fälle aus den Rückrufergebnissen aufweist, die Effizienz von Klicks und Transaktionen jedoch nicht ausreichend berücksichtigt wird.
- Experiment 3/4/5 vs. Experiment 1/2: Nach der Fusion multimodaler Features mit ID können alle drei Indikatoren verbessert werden. Darunter wird ID durch FC geleitet und dann mit den dimensionsreduzierten multimodalen Features kombiniert. Zusammengenommen ist die Wirkung besser. Im Vergleich zu Baseline gibt es jedoch immer noch eine Lücke bei Recall@1000.
- Experiment 7 vs. Experiment 5: Nach der Überlagerung der Optimierung des vorab trainierten Modells werden Recall@1000 und Produktkorrelation verbessert, und die Kategoriekorrelation ist im Wesentlichen dieselbe.
Wir haben aus den Top-1000-Ergebnissen des Vektorrückrufmodells die Elemente herausgefiltert, die das Online-System abrufen konnte, und festgestellt, dass die Korrelation der verbleibenden inkrementellen Ergebnisse im Wesentlichen unverändert ist. Bei einer großen Anzahl von Abfragen sehen wir, dass diese inkrementellen Ergebnisse Bildinformationen über den Produkttitel hinaus erfassen und eine gewisse Rolle in der semantischen Lücke zwischen Abfrage und Titel spielen. Suchanfrage: Hübscher Anzug
Suchanfrage: Taillenbetontes Damenhemd
Zusammenfassung und Ausblick
Um die Anwendungsanforderungen des Hauptsuchszenarios zu erfüllen, haben wir ein Text-Bild-Vortrainingsmodell vorgeschlagen, das die Struktur des quermodalen Dual-Tower-Eingabe-Encoders für Abfragen und Elemente übernimmt, in dem die Der Artikelturm enthält mehrere Bilder und Texte. Die Matching-Aufgaben „Query-Item“ und „Query-Image“ sowie die Multiklassifizierungsaufgabe „Query-Item“, die durch das innere Produkt der Zwillingstürme „Query“ und „Item“ modelliert wird, bringen das Vortraining näher an die nachgelagerte Vektorabrufaufgabe heran. Gleichzeitig wird die Aktualisierung vorab trainierter Vektoren im Vektorabruf modelliert. Bei begrenzten Ressourcen kann ein Vortraining mit relativ kleinen Datenmengen dennoch die Leistung nachgelagerter Aufgaben verbessern, die große Datenmengen verwenden.
In anderen Hauptsuchszenarien, wie z. B. Produktverständnis, Relevanz und Sortierung, besteht auch die Notwendigkeit, multimodale Technologie anzuwenden. Wir haben uns auch an der Erforschung dieser Szenarien beteiligt und sind davon überzeugt, dass die multimodale Technologie in Zukunft für immer mehr Szenarien Vorteile bringen wird.
Teamvorstellung
Taobao-Hauptsuchrückrufteam: Das Team ist für den Rückruf und die grobe Sortierung der Links im Hauptsuchlink verantwortlich. Die aktuelle technische Hauptrichtung ist der personalisierte Vektorrückruf mit mehreren Zielen basierend auf Vollraumproben. und groß angelegte Vorhersagen basierend auf trainiertem multimodalem Rückruf, ähnlichem semantischem Umschreiben von Abfragen basierend auf kontrastivem Lernen und groben Ranking-Modellen usw.
Das obige ist der detaillierte Inhalt vonErforschung der multimodalen Technologie in Taobao-Hauptsucherinnerungsszenarien. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1384
1384
 52
52

 Wie überprüfe ich, wo sich die Lieferadresse von Taobao befindet? Wie überprüfe ich die Lieferadresse von Bestellungen, die in der Taobao-App aufgegeben werden?
Mar 12, 2024 pm 04:00 PM
Wie überprüfe ich, wo sich die Lieferadresse von Taobao befindet? Wie überprüfe ich die Lieferadresse von Bestellungen, die in der Taobao-App aufgegeben werden?
Mar 12, 2024 pm 04:00 PM
Die Taobao-App kann alle Ihre Einkaufsprobleme lösen. Es gibt so viele Händler, die darauf warten, von Ihnen ausgewählt zu werden, egal welche Art von Produkten Sie kaufen möchten, sodass jeder sie direkt finden kann Bestellungen aufgeben und kaufen, und alle Funktionen können frei bedient werden. Wenn Sie eine Bestellung erfolgreich aufgeben, müssen Sie nur darauf warten, dass der Händler die Waren versendet und die Logistiklieferung durchführt. Dies ist sehr praktisch und kann von jedem angezeigt werden Informieren Sie sich über die Versandorte dieser Produkte und wissen Sie, wohin ihre Produkte geliefert werden. Insbesondere beim Kauf einiger elektronischer Produkte können Sie einige entsprechende Versandorte überprüfen, um das Problem des Kaufs einiger generalüberholter Geräte zu vermeiden.
 So erhalten Sie den kostenlosen roten Umschlag von Taobao 2024
May 09, 2024 pm 03:22 PM
So erhalten Sie den kostenlosen roten Umschlag von Taobao 2024
May 09, 2024 pm 03:22 PM
Die Gratis-Bestellveranstaltung 2024 findet dreimal täglich statt. Jeder muss zum entsprechenden Zeitpunkt eine Bestellung aufgeben und die entsprechende Menge an Waren bezahlen. Der Gratis-Bestellbetrag wird in Form von roten Umschlägen mit gleichen Beträgen verteilt. Als Nächstes erkläre ich Ihnen, wie Sie im Jahr 2024 den roten Umschlag für die kostenlose Bestellung von Taobao erhalten: Schnappen Sie sich ihn. Für Benutzer, die kostenlos sind, wird die Qualifikation für den roten Umschlag auf das Karten- und Couponpaket ausgestellt, das sich im Aktivierungszustand befindet; Die Webversion von Taobao verfügt derzeit nicht über das Karten- und Coupon-Paket und zeigt nur die Gewinnaufzeichnungen der kostenlosen Bestellveranstaltung an. Das Karten- und Coupon-Paket befindet sich in [Taobao APP – Mein Taobao] – Meine Rechte – Roter Umschlag. So erhalten Sie kostenlose rote Umschläge von Taobao 20241. Für Benutzer, die kostenlose Bestellungen erhalten, werden die Qualifikationen für rote Umschläge an die Karten- und Couponpakete verteilt, die auf Aktivierung warten 2. Die Webversion von Taobao ist derzeit nicht verfügbar haben Karten- und Coupon-Pakete und zeigen nur die Gewinnaufzeichnungen der kostenlosen Bestellaktivitäten an;3 Das Karten-Coupon-Paket befindet sich in [Taobao APP-My Taobao-My Rights-Red Envelope].
 So deaktivieren Sie die passwortfreie Zahlung auf Taobao. So brechen Sie die Einstellungsmethode für die passwortfreie Zahlung ab.
Mar 12, 2024 pm 12:07 PM
So deaktivieren Sie die passwortfreie Zahlung auf Taobao. So brechen Sie die Einstellungsmethode für die passwortfreie Zahlung ab.
Mar 12, 2024 pm 12:07 PM
Es gibt so viele Funktionen in der Taobao-App, dass jeder ein besseres Einkaufserlebnis haben kann. Die große Anzahl an Produkttypen kann den Einkaufsbedürfnissen verschiedener Benutzer gerecht werden Sie können nach Kategorien suchen oder direkt nach diesen Produkten suchen. Wir bieten Ihnen natürlich alles, was Sie wollen Wenn Sie hier einkaufen, finden Sie hier eine Vielzahl von Einkaufsmethoden, mit denen Sie wählen können, und einige mögen sie nicht so sehr, aber ich denke, die Sicherheit ist nicht so hoch . Natürlich kann jeder jederzeit kündigen.
 So ändern Sie den Namen auf Taobao
Mar 24, 2024 pm 03:31 PM
So ändern Sie den Namen auf Taobao
Mar 24, 2024 pm 03:31 PM
Mit der Namensänderungsfunktion können Benutzer ihre Namen und Spitznamen in Taobao frei ändern. Klicken Sie einfach auf das Taobao-Konto des Avatars in den Einstellungen in „Mein Taobao“, um es zu ändern. Der Herausgeber wird es Ihnen bringen. Dies ist eine Einführung, wie Sie Ihren Namen und Spitznamen ändern können. Wenn Sie es noch nicht wissen, laden Sie es bitte herunter und probieren Sie es aus. Tutorial zur Verwendung von Taobao: Wie ändere ich den Namen auf Taobao? Antwort: Klicken Sie in den Einstellungen in „Mein Taobao“ auf das Taobao-Konto des Avatars, um es zu ändern: 1. Geben Sie Taobao ein und klicken Sie unten rechts auf „Mein Taobao“. . 2. Klicken Sie oben rechts auf das Symbol [Einstellungen]. 3. Klicken Sie auf den Avatar. 4. Klicken Sie erneut auf [Taobao-Konto]. 5. Klicken Sie auf [Kontonamen ändern], geben Sie ihn ein und ändern Sie ihn.
 So überprüfen Sie die Gesamtverbrauchsmenge auf Taobao. So überprüfen Sie die Gesamtverbrauchsmenge
Mar 12, 2024 pm 03:07 PM
So überprüfen Sie die Gesamtverbrauchsmenge auf Taobao. So überprüfen Sie die Gesamtverbrauchsmenge
Mar 12, 2024 pm 03:07 PM
Wenn wir normalerweise online einkaufen müssen, wählen wir alle Taobao als Plattform, die alle unsere Einkaufsbedürfnisse vollständig erfüllen kann. Es verfügt über viele Ressourcen für verschiedene Waren, und es werden wirklich alle Arten von Waren gesammelt Diese Plattform hat festgestellt, dass es hier viele Produktkategorien gibt, die Sie nach Ihren Wünschen auswählen können. Es gibt also definitiv viele Produkte Die Preise dieser Produkte können sehr unterschiedlich sein, sodass jeder sie jederzeit überprüfen kann. Wie viel Geld haben Sie hier ausgegeben? Sie müssen sehr neugierig sein. Hier sind die Redakteure
 So deaktivieren Sie die Erinnerung an rote Umschläge auf Taobao
Apr 01, 2024 pm 06:25 PM
So deaktivieren Sie die Erinnerung an rote Umschläge auf Taobao
Apr 01, 2024 pm 06:25 PM
Taobao ist eine häufig verwendete Online-Shopping-Software, die Sie normalerweise bei Taobao aufgeben und kaufen. Einige Freunde möchten diese Funktion deaktivieren, also beeilen Sie sich und schauen Sie sich die PHP-Chinesen an Website. Schauen Sie mal vorbei. Liste der Schritte zum Deaktivieren der Erinnerungen an rote Umschläge auf Taobao 1. Öffnen Sie das persönliche Zentrum der Taobao-APP und wählen Sie die Schaltfläche [Einstellungen], um die Seite aufzurufen. 2. Suchen Sie die Option [Nachrichtenbenachrichtigung]. Hier können Sie den Nachrichten-Push-Schalter auswählen und den Schalter ausschalten. 3. Oder Sie können die Benachrichtigungsberechtigung der Taobao-App über die Einstellungsseite Ihres Mobiltelefons deaktivieren, sodass nicht alle Nachrichten von Taobao in den Push gelangen und erst nach dem Einschalten angezeigt werden können. 4. Benutzer können festlegen, welche Arten von Nachrichten sie erhalten möchten, was die Verwendung vereinfacht.
 So verwenden Sie den kostenlosen roten Umschlag „Taobao' 510
May 08, 2024 pm 10:00 PM
So verwenden Sie den kostenlosen roten Umschlag „Taobao' 510
May 08, 2024 pm 10:00 PM
Wie verwende ich den kostenlosen roten Umschlag Taobao 510? Taobao hat vor Kurzem eine kostenlose Bestellveranstaltung zur Feier seines 510-jährigen Jubiläums gestartet. Bei dieser Veranstaltung können Sie kostenlos rote Umschläge bestellen, und ich glaube, dass viele Freunde an dieser Veranstaltung teilnehmen möchten , aber das ist nicht der Fall. Wenn Sie die spezifische Verwendung kennen, werfen wir heute einen Blick auf die entsprechende Einführung. Anweisungen zur Verwendung des kostenlosen roten Bestellpakets zum 510-jährigen Jubiläum von Taobao: Das kostenlose rote Bestellpaket kann verwendet werden, nachdem alle für Ratefragen aufgegebenen Bestellungen bestätigt und eingegangen sind. 1. Benutzer können über die Webversion von Taobao kostenlose rote Umschläge ausstellen und zurückerhalten. Derzeit gibt es kein Karten- und Couponpaket, aber es kann unter [Taobao APP – Mein Taobao – Meine Rechte – Rote Umschläge] eingesehen werden. Für Benutzer, die die kostenlose Bestellung abschließen, wird der rote Umschlag mit der Qualifikation an das Karten- und Coupon-Paket verteilt, das sich im Aktivierungsstatus des Karten- und Coupon-Pakets befindet, um Preise zu gewinnen.
 Werden kostenlose Rückerstattungen für rote Umschläge von „Taobao' zurückgegeben?
May 08, 2024 am 08:16 AM
Werden kostenlose Rückerstattungen für rote Umschläge von „Taobao' zurückgegeben?
May 08, 2024 am 08:16 AM
Beim Einkaufen auf Taobao nutzen wir oft kostenlose rote Umschläge, um von Rabatten zu profitieren. Aber wenn wir eine Rückerstattung benötigen, werden diese kostenlosen roten Umschläge dann zurückgegeben? Werfen wir einen Blick auf die Antwort auf diese Frage. Werden die kostenlosen roten Umschläge von Taobao erstattet? Wenn Sie einen roten Umschlag erhalten, befindet sich der rote Umschlag in einem ausstehenden Aktivierungsstatus. Vor der Einlösung des Produkts ist der zu aktivierende rote Umschlag nicht aktiviert und kann nicht verwendet werden Sie warten vorübergehend, bis der Erhalt der gekauften Ware bestätigt ist. Der rote Umschlag, der aktiviert werden muss, kann verwendet werden. Wenn nach Verwendung des kostenlosen roten Umschlags ein Problem mit dem Produkt auftritt und es zurückgegeben werden muss, muss die Rückgabe des roten Umschlags entsprechend der tatsächlichen Situation beurteilt werden: 1. Rückerstattungsregeln 11. Wenn eine Rückerstattung nach erfolgt Wenn ein roter Umschlag verwendet wird, wird der rote Umschlag anteilig zurückgesandt. 2. Wenn er nicht überfällig ist, entspricht die Nutzungsdauer des zurückgegebenen roten Umschlags der ursprünglichen Nutzungsdauer. Wenn er überfällig ist, wird er innerhalb von 7 Tagen ausgestellt.
