
 Technologie-Peripheriegeräte
KI
Die Tsinghua-Universität veröffentlicht CurML, die erste Open-Source-Bibliothek für das Lernen von Kursen
Technologie-Peripheriegeräte
KI
Die Tsinghua-Universität veröffentlicht CurML, die erste Open-Source-Bibliothek für das Lernen von Kursen
Die Tsinghua-Universität veröffentlicht CurML, die erste Open-Source-Bibliothek für das Lernen von Kursen

Im Entwicklungsprozess des maschinellen Lernens inspirieren menschliche Lernmethoden häufig die Gestaltung verschiedener Algorithmen. Als wichtiges Paradigma des menschlichen Lernens wurde das Lernen durch Kurse vom maschinellen Lernen übernommen, um eine Forschungsrichtung namens Curriculum Learning zu bilden.
Im Allgemeinen wird die menschliche Bildung durch gut organisierte Kurse abgeschlossen. Jeder Kurs oder jedes Fach beginnt mit einfachen Inhalten und stellt den Studierenden nach und nach komplexere Konzepte vor. Bevor ein Schüler beispielsweise die Konzepte der Infinitesimalrechnung im College akzeptiert, sollte er zunächst in der Grundschule Arithmetik, in der Mittelschule Funktionen und in der Oberstufe Ableitungen lernen. Im Gegensatz zur menschlichen Bildung umfasst das Training herkömmlicher Modelle für maschinelles Lernen jedoch die zufällige Eingabe von Datenproben in das Modell, wobei die unterschiedliche Komplexität zwischen Datenproben und dem aktuellen Lernstatus des Modells ignoriert wird. Daher wurde im Bereich des maschinellen Lernens Lehrplanlernen vorgeschlagen, um menschliches Lernen von einfach bis schwer zu imitieren, bessere Trainingsstrategien für das Modell bereitzustellen und dadurch die Leistung des Modells zu verbessern.

Kurslern-Konzeptkarte
Derzeit wird Kurslernen häufig in verschiedenen Aufgaben des maschinellen Lernens eingesetzt, darunter Bildklassifizierung, Zielerkennung, semantische Segmentierung, maschinelle Übersetzung, Audioerkennung, Audio Verbesserung, Beantwortung von Videofragen usw. haben auch in Szenarien wie überwachtem, unüberwachtem und halbüberwachtem Lernen und verstärkendem Lernen viel Aufmerksamkeit und Forschung erhalten.
Da die Anwendungen und Szenarien des Kurslernens immer vielfältiger werden, ist es insbesondere in diesem Bereich erforderlich, eine detaillierte Sortierung und Zusammenfassung durchzuführen, um eine eingehende Erkundung durch Forscher zu fördern und das Anwendungserlebnis der Benutzer zu verbessern.
Basierend auf der Anhäufung und Veröffentlichung einer Reihe wissenschaftlicher Arbeiten zum Lehrplanlernen veröffentlichte das von Professor Zhu Wenwu von der Tsinghua-Universität geleitete Media and Network Big Data Laboratory, Labormitglied Wang Xin, einen Artikel zum Lehrplanlernen IEEE TPAMI In dem Übersichtsartikel veröffentlichte das Labor außerdem die weltweit erste Open-Source-Bibliothek für das Kurslernen, CurML (Curriculum Machine Learning).
Professor Zhu Wenwu und der stellvertretende Forscher Wang Suche und adaptive kombinatorische Optimierungsproblemlösung basierend auf der Kursschwierigkeit usw. Forschungsergebnisse wurden auf hochrangigen internationalen Konferenzen zum Thema maschinelles Lernen wie SIGKDD, NeurIPS und ACM MM veröffentlicht.

Rahmendiagramm einiger Forschungsergebnisse
Das Lehrplan-Lernüberprüfungspapier untersucht umfassend die Entstehung, Definition, Theorie und Anwendung des Lehrplan-Lernens und entwirft einen einheitlichen Lehrplan-Lernrahmen Zu den Kernkomponenten innerhalb des Frameworks gehören Kurslernalgorithmen, die in zwei Hauptkategorien und mehrere Unterkategorien unterteilt sind. Dabei werden die Unterschiede und Korrelationen zwischen Kurslernen und anderen Konzepten des maschinellen Lernens unterschieden und die Herausforderungen und die Zukunft aufgezeigt, mit denen dieses Feld konfrontiert ist. Mögliche Forschungsrichtungen.

Klassifizierung von Kurslernmethoden
Die Open-Source-Bibliothek CurML ist eine Unterstützungsplattform für Kurslernalgorithmen. Sie hat mehr als zehn Kurslernalgorithmen integriert und unterstützt sowohl verrauschte als auch nicht-basierte. laut. Ein Anwendungsszenario, das Forschern und Benutzern das Reproduzieren, Bewerten, Vergleichen und Auswählen von Kurslernalgorithmen erleichtert.
CurMLs Hauptmodul ist CL Trainer, das aus zwei Untermodulen besteht: Model Trainer und CL Algorithm. Die beiden interagieren über fünf Schnittstellenfunktionen, um den maschinellen Lernprozess der Kurslernberatung zu realisieren.

CurML-Framework-Diagramm
Hauptmodul: CL Trainer
Dieses Modul ist der Hauptteil der gesamten Open-Source-Bibliothek. Durch den Aufruf dieses Moduls können Benutzer den Kurslernalgorithmus mit nur wenigen Codezeilen implementieren. Nachdem der Datensatz, das Modell und die Hyperparameter angegeben wurden, trainiert das Modul für einen bestimmten Zeitraum und gibt die trainierten Modellparameter und Testergebnisse der Aufgabe aus. Dieses Modul ist hauptsächlich darauf ausgelegt, die Anforderungen an die Benutzerfreundlichkeit zu erfüllen. Daher ist es stark gekapselt und wird Benutzern bereitgestellt, die den Kurslernalgorithmus verwenden möchten, sich aber nicht für die spezifischen Implementierungsdetails interessieren.
Untermodul 1: Modelltrainer
Dieses Modul wird verwendet, um den allgemeinen maschinellen Lernprozess abzuschließen, beispielsweise das Training eines Bildklassifikators oder eines Sprachmodells. Gleichzeitig reserviert es Positionen für fünf Schnittstellenfunktionen für die Interaktion mit dem CL-Algorithmus des zweiten Untermoduls und unterstützt auch benutzerdefinierte Eingabefunktionen.
Untermodul 2: CL-Algorithmus
Dieses Modul kapselt alle von CurML unterstützten Kurslernalgorithmen, wie in der folgenden Tabelle gezeigt:

Das Modul wird über fünf Schnittstellenfunktionen implementiert werden verwendet, um Daten und Modellinformationen aus dem maschinellen Lernprozess zu erhalten und die Lernstrategie des Modells zu steuern, wie in der folgenden Abbildung dargestellt.

CurML-Flussdiagramm
Schnittstellenfunktion: data_prepare
Diese Funktion wird verwendet, um Datensatzinformationen vom Model Trainer-Modul an das CL-Algorithmusmodul bereitzustellen. Viele Kurslernalgorithmen erfordern ein umfassendes Verständnis des Datensatzes, um die Schwierigkeit der Datenstichprobe besser beurteilen zu können. Daher ist diese Schnittstellenfunktion erforderlich.
Schnittstellenfunktion: model_prepare
Diese Funktion ist data_prepare sehr ähnlich. Der Unterschied besteht darin, dass sie keine Datensatzinformationen überträgt, sondern Informationen im Zusammenhang mit dem Modelltraining, wie z. B. Modellarchitektur, Parameteroptimierer und Lernen Rate Adjuster usw. Viele Kurslernalgorithmen steuern das maschinelle Lernen, indem sie diese Faktoren anpassen.
Schnittstellenfunktion: data_curriculum
Diese Funktion wird verwendet, um die Schwierigkeit der Datenstichprobe zu berechnen und basierend auf der Datenschwierigkeit und dem aktuellen Modellstatus geeignete Daten für das Modell bereitzustellen .
Schnittstellenfunktion: model_curriculum
Diese Funktion wird verwendet, um das Modell zu aktualisieren, die Menge an Informationen anzupassen, die das Modell aus Datenproben erhält, und indirekt das Lernen des Modells zu steuern. Derzeit ist die Anzahl solcher Algorithmen sind noch klein, aber CurML unterstützt auch die Implementierung solcher Algorithmen.
Schnittstellenfunktion: loss_curriculum
Diese Funktion wird verwendet, um den Wert der Verlustfunktion neu zu gewichten und indirekt die Auswirkungen verschiedener Daten auf das Modell anzupassen. Diese Art von Algorithmus kommt beim Kurslernen häufiger vor, da der Verlust Bei der Wertgewichtung handelt es sich im Wesentlichen um eine sanfte Stichprobenziehung der Daten.
Durch die Zusammenfassung von mehr als zehn Kurslernmethoden der letzten Jahre können verschiedene Arten von Kurslernalgorithmen unter Verwendung der oben genannten Module und Schnittstellenparameter vereinheitlicht und implementiert werden, sodass die Kurslernalgorithmen unter fairen Szenarien evaluiert werden können Aufgaben vergleichen und auswählen.
Zukunftsausblick
Das Forschungs- und Entwicklungsteam von CurML erklärte, dass es diese Open-Source-Bibliothek auch in Zukunft weiter aktualisieren wird, um weitere Unterstützung für die Entwicklung und Anwendung des Kurslernens bereitzustellen.
Verwandte Links:
- Link zur Open-Source-Codebibliothek von CurML: https:// github .com/THUMNLab/CurML
- CurML Open-Source-Softwarepapier-Link: https://dl.acm.org/doi/pdf/10.1145/3503161.3548549#🎜🎜 ## 🎜🎜# Link zum Zusammenfassungspapier zum Kurslernen: https://ieeexplore.ieee.org/abstract/document/9392296/
- #🎜🎜 #Link zum Kurs-Meta-Lernpapier: https://dl.acm.org/doi/abs/10.1145/3447548.3467132
- Link zum Kurs-Entkopplungs-Lernpapier: https:/ /proceedings .neurips.cc/paper/2021/file/e242660df1b69b74dcc7fde711f924ff-Paper.pdf
- Kurs-Suchpapier-Link zur neuronalen Architektur: https://dl.acm.org /doi /abs/10.1145/3503161.3548271
- Link zum Kursschwierigkeitsanpassungspapier: https://ojs.aaai.org/index.php/AAAI/article/download/ 20899 /version/19196/20658
Das obige ist der detaillierte Inhalt vonDie Tsinghua-Universität veröffentlicht CurML, die erste Open-Source-Bibliothek für das Lernen von Kursen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In den Bereichen maschinelles Lernen und Datenwissenschaft stand die Interpretierbarkeit von Modellen schon immer im Fokus von Forschern und Praktikern. Mit der weit verbreiteten Anwendung komplexer Modelle wie Deep Learning und Ensemble-Methoden ist das Verständnis des Entscheidungsprozesses des Modells besonders wichtig geworden. Explainable AI|XAI trägt dazu bei, Vertrauen in maschinelle Lernmodelle aufzubauen, indem es die Transparenz des Modells erhöht. Eine Verbesserung der Modelltransparenz kann durch Methoden wie den weit verbreiteten Einsatz mehrerer komplexer Modelle sowie der Entscheidungsprozesse zur Erläuterung der Modelle erreicht werden. Zu diesen Methoden gehören die Analyse der Merkmalsbedeutung, die Schätzung des Modellvorhersageintervalls, lokale Interpretierbarkeitsalgorithmen usw. Die Merkmalswichtigkeitsanalyse kann den Entscheidungsprozess des Modells erklären, indem sie den Grad des Einflusses des Modells auf die Eingabemerkmale bewertet. Schätzung des Modellvorhersageintervalls
 Identifizieren Sie Über- und Unteranpassung anhand von Lernkurven
Apr 29, 2024 pm 06:50 PM
Identifizieren Sie Über- und Unteranpassung anhand von Lernkurven
Apr 29, 2024 pm 06:50 PM
In diesem Artikel wird vorgestellt, wie Überanpassung und Unteranpassung in Modellen für maschinelles Lernen mithilfe von Lernkurven effektiv identifiziert werden können. Unteranpassung und Überanpassung 1. Überanpassung Wenn ein Modell mit den Daten übertrainiert ist, sodass es daraus Rauschen lernt, spricht man von einer Überanpassung des Modells. Ein überangepasstes Modell lernt jedes Beispiel so perfekt, dass es ein unsichtbares/neues Beispiel falsch klassifiziert. Für ein überangepasstes Modell erhalten wir einen perfekten/nahezu perfekten Trainingssatzwert und einen schrecklichen Validierungssatz-/Testwert. Leicht geändert: „Ursache der Überanpassung: Verwenden Sie ein komplexes Modell, um ein einfaches Problem zu lösen und Rauschen aus den Daten zu extrahieren. Weil ein kleiner Datensatz als Trainingssatz möglicherweise nicht die korrekte Darstellung aller Daten darstellt. 2. Unteranpassung Heru.“
 Die Entwicklung der künstlichen Intelligenz in der Weltraumforschung und der Siedlungstechnik
Apr 29, 2024 pm 03:25 PM
Die Entwicklung der künstlichen Intelligenz in der Weltraumforschung und der Siedlungstechnik
Apr 29, 2024 pm 03:25 PM
In den 1950er Jahren wurde die künstliche Intelligenz (KI) geboren. Damals entdeckten Forscher, dass Maschinen menschenähnliche Aufgaben wie das Denken ausführen können. Später, in den 1960er Jahren, finanzierte das US-Verteidigungsministerium künstliche Intelligenz und richtete Labore für die weitere Entwicklung ein. Forscher finden Anwendungen für künstliche Intelligenz in vielen Bereichen, etwa bei der Erforschung des Weltraums und beim Überleben in extremen Umgebungen. Unter Weltraumforschung versteht man die Erforschung des Universums, das das gesamte Universum außerhalb der Erde umfasst. Der Weltraum wird als extreme Umgebung eingestuft, da sich seine Bedingungen von denen auf der Erde unterscheiden. Um im Weltraum zu überleben, müssen viele Faktoren berücksichtigt und Vorkehrungen getroffen werden. Wissenschaftler und Forscher glauben, dass die Erforschung des Weltraums und das Verständnis des aktuellen Zustands aller Dinge dazu beitragen können, die Funktionsweise des Universums zu verstehen und sich auf mögliche Umweltkrisen vorzubereiten
 Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Zu den häufigsten Herausforderungen, mit denen Algorithmen für maschinelles Lernen in C++ konfrontiert sind, gehören Speicherverwaltung, Multithreading, Leistungsoptimierung und Wartbarkeit. Zu den Lösungen gehören die Verwendung intelligenter Zeiger, moderner Threading-Bibliotheken, SIMD-Anweisungen und Bibliotheken von Drittanbietern sowie die Einhaltung von Codierungsstilrichtlinien und die Verwendung von Automatisierungstools. Praktische Fälle zeigen, wie man die Eigen-Bibliothek nutzt, um lineare Regressionsalgorithmen zu implementieren, den Speicher effektiv zu verwalten und leistungsstarke Matrixoperationen zu nutzen.
 Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
FP8 und die geringere Gleitkomma-Quantifizierungsgenauigkeit sind nicht länger das „Patent“ von H100! Lao Huang wollte, dass jeder INT8/INT4 nutzt, und das Microsoft DeepSpeed-Team begann, FP6 auf A100 ohne offizielle Unterstützung von NVIDIA auszuführen. Testergebnisse zeigen, dass die FP6-Quantisierung der neuen Methode TC-FPx auf A100 nahe an INT4 liegt oder gelegentlich schneller als diese ist und eine höhere Genauigkeit aufweist als letztere. Darüber hinaus gibt es eine durchgängige Unterstützung großer Modelle, die als Open-Source-Lösung bereitgestellt und in Deep-Learning-Inferenz-Frameworks wie DeepSpeed integriert wurde. Dieses Ergebnis wirkt sich auch unmittelbar auf die Beschleunigung großer Modelle aus – in diesem Rahmen ist der Durchsatz bei Verwendung einer einzelnen Karte zum Ausführen von Llama 2,65-mal höher als der von Doppelkarten. eins
 Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Übersetzer |. Rezensiert von Li Rui |. Chonglou Modelle für künstliche Intelligenz (KI) und maschinelles Lernen (ML) werden heutzutage immer komplexer, und die von diesen Modellen erzeugten Ergebnisse sind eine Blackbox, die den Stakeholdern nicht erklärt werden kann. Explainable AI (XAI) zielt darauf ab, dieses Problem zu lösen, indem es Stakeholdern ermöglicht, die Funktionsweise dieser Modelle zu verstehen, sicherzustellen, dass sie verstehen, wie diese Modelle tatsächlich Entscheidungen treffen, und Transparenz in KI-Systemen, Vertrauen und Verantwortlichkeit zur Lösung dieses Problems gewährleistet. In diesem Artikel werden verschiedene Techniken der erklärbaren künstlichen Intelligenz (XAI) untersucht, um ihre zugrunde liegenden Prinzipien zu veranschaulichen. Mehrere Gründe, warum erklärbare KI von entscheidender Bedeutung ist. Vertrauen und Transparenz: Damit KI-Systeme allgemein akzeptiert und vertrauenswürdig sind, müssen Benutzer verstehen, wie Entscheidungen getroffen werden
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
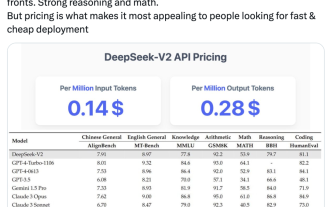 Inländische Open-Source-MoE-Indikatoren explodieren: GPT-4-Level-Fähigkeiten, API-Preis beträgt nur ein Prozent
May 07, 2024 pm 05:34 PM
Inländische Open-Source-MoE-Indikatoren explodieren: GPT-4-Level-Fähigkeiten, API-Preis beträgt nur ein Prozent
May 07, 2024 pm 05:34 PM
Das neueste groß angelegte inländische Open-Source-MoE-Modell erfreute sich gleich nach seinem Debüt großer Beliebtheit. Die Leistung von DeepSeek-V2 erreicht GPT-4-Niveau, es ist jedoch Open Source, kostenlos für die kommerzielle Nutzung und der API-Preis beträgt nur ein Prozent von GPT-4-Turbo. Daher löste es sofort nach seiner Veröffentlichung viele Diskussionen aus. Den veröffentlichten Leistungsindikatoren zufolge übertreffen die umfassenden chinesischen Fähigkeiten von DeepSeekV2 die vieler Open-Source-Modelle. Gleichzeitig befinden sich auch Closed-Source-Modelle wie GPT-4Turbo und Wenkuai 4.0 auf der ersten Stufe. Die umfassenden Englischkenntnisse liegen ebenfalls auf der gleichen ersten Stufe wie LLaMA3-70B und übertreffen Mixtral8x22B, das ebenfalls ein MoE ist. Es zeigt auch gute Leistungen in den Bereichen Wissen, Mathematik, logisches Denken, Programmieren usw. Und unterstützt 128K-Kontext. Stellen Sie sich das vor
