

Derzeit gibt es viele Schwierigkeiten bei der groß angelegten Anwendung künstlicher Intelligenz in Unternehmen, wie zum Beispiel: lange F&E-Einführungszyklen, geringer als erwartete Ergebnisse und Schwierigkeiten beim Abgleich von Daten und Modellen. In diesem Zusammenhang entstand MLOps. MLOps entwickelt sich zu einer Schlüsseltechnologie zur Skalierung von maschinellem Lernen im Unternehmen.
Vor ein paar Tagen fand die von 51CTO organisierte AISummit Global Artificial Intelligence Technology Conference erfolgreich statt. In der „MLOps Best Practices“-Sitzung auf der Konferenz diskutierten Tan Zhongyi, stellvertretender Vorsitzender des TOC der Open Atomic Foundation, Lu Mian, Systemarchitekt des vierten Paradigmas, Wu Guanlin, Forscher für künstliche Intelligenz bei NetEase Cloud Music, Big Data und das Software Development Center der Industrial and Commercial Bank of China Künstliche Intelligenz Huang Bing, stellvertretender Direktor des Labors, hielt seine eigene Grundsatzrede und diskutierte den tatsächlichen Kampf von MLOps rund um aktuelle Themen wie den F&E-Betriebszyklus, kontinuierliches Training und kontinuierliche Überwachung, Modellversion und -herkunft, Online- und Offline-Datenkonsistenz, und effiziente Datenversorgung.
Andrew NG hat bei vielen Gelegenheiten zum Ausdruck gebracht, dass sich die KI von der Modellzentrierung zur Datenzentrierung verlagert hat und Daten die größte Herausforderung für die Implementierung von KI darstellen. Um dieses Problem zu lösen, müssen wir die Praxis von MLOps nutzen, um eine schnelle, einfache und kostengünstige Implementierung von KI zu ermöglichen.
Welche Probleme löst MLOps? Wie lässt sich der Reifegrad eines MLOps-Projekts beurteilen? Tan Zhongyi, stellvertretender Vorsitzender der Open Atomic Foundation TOC und Mitglied von LF AI & Data TAC, hielt eine Keynote-Rede mit dem Titel „Von modellzentriert zu datenzentriert – MLOps hilft KI dabei, schnell, einfach und kostengünstig implementiert zu werden“, die in vorgestellt wurde Detail.
Tan Zhongyi teilte zunächst die Ansichten einer Gruppe von Branchenwissenschaftlern und -analysten. Andrew NG glaubt, dass die Verbesserung der Datenqualität die Effektivität der KI-Implementierung stärker verbessern kann als die Verbesserung von Modellalgorithmen. Seiner Ansicht nach besteht die wichtigste Aufgabe von MLOps darin, in allen Phasen des maschinellen Lernlebenszyklus stets eine qualitativ hochwertige Datenversorgung aufrechtzuerhalten.
Um eine groß angelegte Implementierung von KI zu erreichen, müssen MLOps entwickelt werden. Was genau MLOps ist, darüber besteht in der Branche kein Konsens. Er gab seine eigene Erklärung: Es handelt sich um „kontinuierliche Integration, kontinuierliche Bereitstellung, kontinuierliche Schulung und kontinuierliche Überwachung von Code + Modell + Daten“.
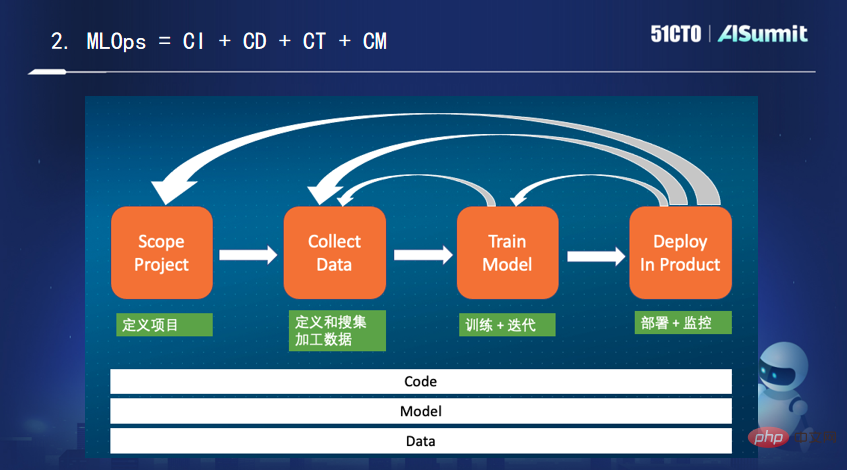
Dann konzentrierte sich Tan Zhongyi auf die Vorstellung der Merkmale von Feature Store, einer einzigartigen Plattform im Bereich des maschinellen Lernens, sowie der derzeit auf dem Markt befindlichen Mainstream-Feature-Plattformprodukte.
Abschließend ging Tan Zhongyi kurz auf das MLOps-Reifemodell ein. Er erwähnte, dass Microsoft Azure das ausgereifte MLOps-Modell entsprechend dem Automatisierungsgrad des gesamten maschinellen Lernprozesses in mehrere Stufen (0, 1, 2, 3, 4) unterteilt hat, wobei 0 keine Automatisierung und 123 teilweise Automatisierung bedeutet ist ein hoher Automatisierungsgrad.
In vielen maschinellen Lernszenarien sind wir mit der Notwendigkeit einer Feature-Berechnung in Echtzeit konfrontiert. Von offline von Datenwissenschaftlern entwickelten Feature-Skripten bis hin zu Online-Echtzeit-Feature-Berechnungen sind die Kosten für die KI-Implementierung sehr hoch.
Als Reaktion auf diesen Problempunkt hob Lu Mian, 4Paradigm-Systemarchitekt, Datenbankteam und Leiter des Hochleistungscomputerteams, in seiner Keynote-Rede „Open Source Machine Learning Database OpenMLDB: A Consistent Online and Offline Production-Level Feature“ hervor „Plattform“ In diesem Artikel wird erläutert, wie OpenMLDB das Ziel erreicht, die Entwicklung von Funktionen für maschinelles Lernen sofort zu starten, und wie die Genauigkeit und Effizienz von Funktionsberechnungen sichergestellt werden kann.
Lu Mian wies darauf hin, dass mit der Weiterentwicklung der technischen Implementierung künstlicher Intelligenz im Feature-Engineering-Prozess die Online-Konsistenzüberprüfung hohe Implementierungskosten mit sich gebracht hat. OpenMLDB bietet eine kostengünstige Open-Source-Lösung. Sie löst nicht nur das Kernproblem – die Konsistenz des Online- und Offline-Maschinenlernens – und löst auch das Problem der Korrektheit, sondern erreicht auch eine Echtzeit-Feature-Berechnung auf Millisekundenebene. Das ist sein zentraler Wert.
Laut Lu Mian ist das indonesische Online-Zahlungsunternehmen Akulaku der erste Community-Unternehmensbenutzer, nachdem OpenMLDB als Open Source verfügbar war. Sie haben OpenMLDB in ihre intelligente Computerarchitektur integriert. Im tatsächlichen Geschäft verarbeitet Akulaku durchschnittlich fast 1 Milliarde Bestelldaten pro Tag. Nach der Verwendung von OpenMLDB beträgt die Datenverarbeitungsverzögerung nur 4 Millisekunden, was ihren Geschäftsanforderungen vollständig entspricht.
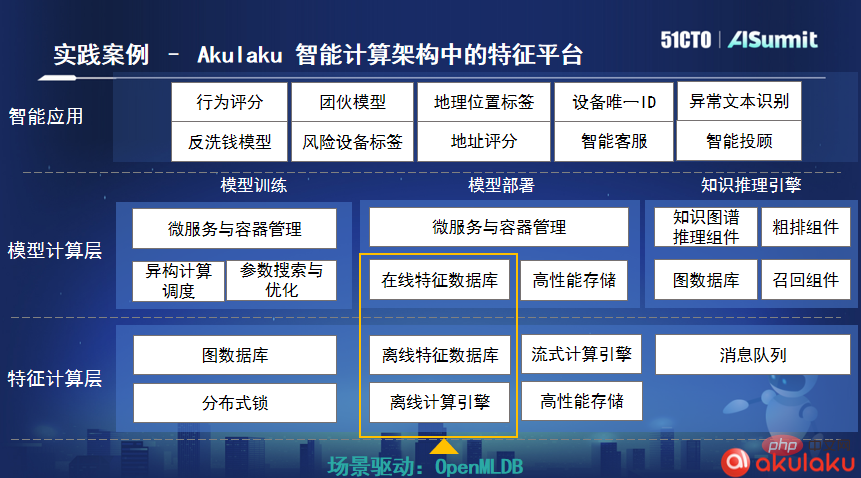
Verlassen Sie sich auf die riesigen Datenmengen, präzisen Algorithmen und Echtzeitsysteme von NetEase Cloud Music, um mehrere Szenarien der Inhaltsverteilung und -kommerzialisierung zu bedienen und gleichzeitig die Anforderungen einer hohen Modellierungseffizienz und einer niedrigen Modellierungseffizienz zu erfüllen Nutzungsschwellen, aber auch eine Reihe von Algorithmen-Engineering-Aktivitäten wie signifikante Modelleffekte Aus diesem Grund begann das NetEase Cloud-Musikalgorithmus-Engineering-Team in Zusammenarbeit mit dem Musikgeschäft mit der praktischen Implementierung einer End-to-End-Plattform für maschinelles Lernen.
Wu Guanlin, Forscher für künstliche Intelligenz und technischer Leiter von NetEase Cloud Music, hielt eine Grundsatzrede zum Thema „Technische Praxis der NetEase Cloud Music Feature Platform“ und erläuterte den Echtzeit-Implementierungsplan von das Modell, kombiniert mit dem Feature Store, um mit den Teilnehmern weiter zu diskutieren. Der Autor teilte seine Gedanken.
Wu Guanlin erwähnte, dass es bei der Erstellung von Cloud-Musikmodellalgorithmusprojekten drei Hauptprobleme gibt: niedrige Echtzeitebene, geringe Modellierungseffizienz und begrenzte Modellfunktionen aufgrund von Online- und Offline-Inkonsistenzen. Als Reaktion auf diese Schwachstellen begannen sie mit dem Echtzeitmodell und bauten die entsprechende Feature-Store-Plattform auf, während das Modell das Geschäft in Echtzeit abdeckte.
Wu Guanlin gab bekannt, dass sie das Echtzeitmodell zunächst in Live-Übertragungsszenarien untersucht und bestimmte Ergebnisse erzielt haben. Im Hinblick auf die Technik wurde auch eine vollständige Verbindung untersucht und einige grundlegende technische Konstruktionen umgesetzt. Das Echtzeitmodell konzentriert sich jedoch auf die Feinabstimmung von Echtzeitszenarien, aber mehr als 80 % der Szenarien sind Offline-Modelle. Beim Full-Link-Modellierungsprozess beginnt jeder Szenarioentwickler am Ursprung der Daten, was zu Problemen wie einem langen Modellierungszyklus, unvorhersehbaren Auswirkungen und einer hohen Entwicklungsschwelle für Anfänger führt. Betrachtet man einen Modelleinführungszyklus, sind 80 % der Zeit datenbezogen, wobei Features bis zu 50 % ausmachen. Sie begannen mit der Gründung der Feature-Plattform Feature Store.
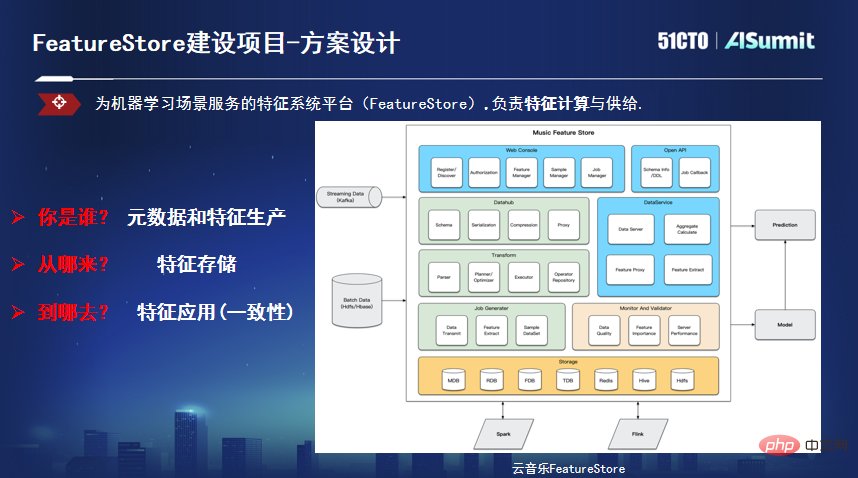
Feature Store löst hauptsächlich drei Probleme: Erstens die Definition von Metadaten, die Vereinheitlichung der Feature-Herkunft, der Berechnung und des Push-Prozesses und die Realisierung einer effizienten Feature-Produktionsverknüpfung basierend auf der Batch- und Flow-Integration Features Führen Sie eine Transformation durch, um das Problem der Feature-Speicherung zu lösen, und stellen Sie verschiedene Arten von Speicher-Engines entsprechend den Unterschieden in Latenz und Durchsatz der tatsächlichen Nutzungsszenarien bereit. Drittens lösen Sie das Problem der Feature-Konsistenz und lesen Daten in einem bestimmten Format aus einem einheitlichen Format API und verwenden Sie sie als maschinelle Eingabe für das Lernmodell, die für Schlussfolgerungen, Schulungen usw. verwendet wird.
Huang Bing, stellvertretender Direktor des Big Data and Artificial Intelligence Laboratory des Software Development Center der Industrial and Commercial Bank of China, hob in seiner Grundsatzrede „Building a new Infrastruktur für künstliche Intelligenz für die innovative Entwicklung intelligenter Finanzen“ Die MLOps-Praxis von ICBC umfasst den Konstruktionsprozess und die technische Praxis des gesamten Lebenszyklus-Managementsystems aus Modellentwicklung, Modellbereitstellung, Modellmanagement und modelliterativem Betrieb.
Der Grund, warum MLOps benötigt wird, liegt darin, dass hinter der rasanten Entwicklung der künstlichen Intelligenz viele bestehende oder potenzielle „KI-technische Schulden“ nicht ignoriert werden können. Huang Bing glaubt, dass das Konzept von MLOps diese technischen Schulden lösen kann: „Wenn DevOps ein Werkzeug zur Lösung des technischen Schuldenproblems von Softwaresystemen ist und DataOps der Schlüssel zur Lösung des technischen Schuldenproblems von Datenbeständen ist, dann ist MLOps das.“ Entstanden aus dem DevOps-Konzept, ist eine Behandlungsmaschine. „Lernen Sie die Lösung für Ihr technisches Schuldenproblem.“
Im Bauprozess lässt sich die praktische MLOps-Erfahrung von ICBC in vier Punkte zusammenfassen: Konsolidierung der „Grundlage“ der öffentlichen Fähigkeiten, Aufbau eines Rechenzentrums auf Unternehmensebene und Senkung des „Instruments“ von Anwendungsschwellenwerte und der Bau relevanter Modellierungs- und Service-Montagelinien bilden ein prozessbasiertes und bausteinartiges F&E-Modell zur Etablierung einer „Methode“ für die Akkumulation und gemeinsame Nutzung von KI-Assets, um die Kosten für die KI-Konstruktion zu minimieren und den Schlüssel zu einer gemeinsamen und gemeinsamen Nutzung zu bilden Mitkonstruierte Ökologie; Modelloperationen bilden Die „Technik“ der Iteration besteht darin, ein Modelloperationssystem basierend auf Daten und Geschäftswert zu etablieren, das die Grundlage für kontinuierliche Iteration und quantitative Bewertung der Modellqualität bildet.
Am Ende der Rede machte Huang Bing zwei Ausblicke: Erstens müssen MLOps sicherer und konformer sein. In Zukunft wird die Unternehmensentwicklung viele Modelle erfordern, um eine datengesteuerte intelligente Entscheidungsfindung zu erreichen, was zu mehr Anforderungen auf Unternehmensebene in Bezug auf Modellentwicklung, Betrieb und Wartung, Berechtigungskontrolle, Datenschutz, Sicherheit und Prüfung führen wird. Zweitens müssen MLOps mit anderen Ops kombiniert werden. Die Lösung des technischen Schuldenproblems ist ein komplexer Prozess. DevOps-Lösungen, DataOps-Lösungen und MLOps-Lösungen müssen koordiniert und miteinander verbunden werden, um alle Vorteile der drei voll auszuschöpfen und den Effekt von „1+1+“ zu erzielen 1>3".
Laut IDC-Prognosen werden bis 2024 60 % der Unternehmen MLOps verwenden, um Arbeitsabläufe für maschinelles Lernen zu implementieren. IDC-Analyst Sriram Subramanian kommentierte einmal: „MLOps reduziert die Modellgeschwindigkeit auf Wochen – manchmal sogar auf Tage, genau wie der Einsatz von DevOps, um die durchschnittliche Zeit zum Erstellen einer Anwendung zu verkürzen. Deshalb braucht man MLOps.“ Derzeit befinden wir uns an einem Wendepunkt der rasanten Ausbreitung der künstlichen Intelligenz. Durch die Einführung von MLOps können Unternehmen mehr Modelle erstellen, Geschäftsinnovationen schneller realisieren und die Implementierung von KI schneller und kostengünstiger vorantreiben. Tausende Branchen sind Zeugen und bestätigen die Tatsache, dass MLOps zum Katalysator für das Ausmaß der Unternehmens-KI wird. Für weitere spannende Inhalte klicken Sie bitte, um anzusehen.
Das obige ist der detaillierte Inhalt vonUm den Weg zur MLOps-Implementierung in Unternehmen zu erkunden, wurde die AISummit Global Artificial Intelligence Technology Conference „MLOps Best Practices' erfolgreich abgehalten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Die übergeordnete Vue-Komponente ruft die Methode der untergeordneten Komponente auf
Die übergeordnete Vue-Komponente ruft die Methode der untergeordneten Komponente auf
 Was ist der Handel mit digitalen Währungen?
Was ist der Handel mit digitalen Währungen?
 So verwenden Sie fusioncharts.js
So verwenden Sie fusioncharts.js
 Verwendung der Längenfunktion
Verwendung der Längenfunktion
 Kosteneffizienzanalyse des Lernens von Python, Java und C++
Kosteneffizienzanalyse des Lernens von Python, Java und C++
 Darstellungsmethode der String-Konstante
Darstellungsmethode der String-Konstante
 Isolationsstufe für MySQL-Transaktionen
Isolationsstufe für MySQL-Transaktionen
 So öffnen Sie .dat-Dateien
So öffnen Sie .dat-Dateien
 wie man eine Website erstellt
wie man eine Website erstellt








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



