

Bildklassifizierung mit Fow-Shot-Learning mit PyTorch

In den letzten Jahren haben Deep-Learning-basierte Modelle bei Aufgaben wie der Objekterkennung und Bilderkennung gute Leistungen erbracht. Bei anspruchsvollen Bildklassifizierungsdatensätzen wie ImageNet, das 1.000 verschiedene Objektklassifizierungen enthält, übertreffen einige Modelle mittlerweile das menschliche Niveau. Diese Modelle basieren jedoch auf einem überwachten Trainingsprozess, sie werden erheblich von der Verfügbarkeit gekennzeichneter Trainingsdaten beeinflusst und die Klassen, die die Modelle erkennen können, sind auf die Klassen beschränkt, auf denen sie trainiert wurden.
Da es während des Trainings nicht genügend beschriftete Bilder für alle Klassen gibt, sind diese Modelle in realen Umgebungen möglicherweise weniger nützlich. Und wir möchten, dass das Modell Klassen erkennen kann, die es während des Trainings nicht gesehen hat, da es fast unmöglich ist, auf Bildern aller potenziellen Objekte zu trainieren. Das Problem, bei dem wir aus wenigen Beispielen lernen, nennt sich Few-Shot-Lernen.
Was ist Few-Shot-Learning?

Few-Shot-Learning ist ein Teilgebiet des maschinellen Lernens. Dabei geht es darum, neue Daten mit nur wenigen Trainingsbeispielen und Überwachungsdaten zu klassifizieren. Das von uns erstellte Modell funktioniert mit nur einer kleinen Anzahl von Trainingsbeispielen einigermaßen gut.
Stellen Sie sich folgendes Szenario vor: Im medizinischen Bereich stehen für einige seltene Krankheiten möglicherweise nicht genügend Röntgenbilder für die Ausbildung zur Verfügung. Für solche Szenarien ist die Erstellung eines Lernklassifikators mit wenigen Schüssen die perfekte Lösung.
Variation in kleinen Stichproben
Im Allgemeinen haben Forscher vier Typen identifiziert:
- N-Shot Learning (NSL)
- Few-Shot Learning (FSL)
- One-Shot Learning (OSL)
- Zero-Shot Learning (ZSL)
Wenn wir über FSL sprechen, beziehen wir uns normalerweise auf die N-Way-K-Shot-Klassifizierung. N stellt die Anzahl der Klassen dar und K stellt die Anzahl der in jeder Klasse zu trainierenden Proben dar. Daher gilt N-Shot Learning als ein umfassenderes Konzept als alle anderen Konzepte. Man kann sagen, dass Few-Shot, One-Shot und Zero-Shot Unterbereiche von NSL sind. Während Zero-Shot-Learning darauf abzielt, unsichtbare Klassen ohne Trainingsbeispiele zu klassifizieren.
Bei One-Shot Learning gibt es nur eine Probe pro Klasse. Few-Shot verfügt über 2 bis 5 Beispiele pro Klasse, was bedeutet, dass Few-Shot eine flexiblere Version von One-Shot Learning ist.
Lernmethode für kleine Stichproben
Im Allgemeinen sollten bei der Lösung des Few-Shot-Learning-Problems zwei Methoden in Betracht gezogen werden:
Data Level Approach (DLA)
Diese Strategie ist sehr einfach, wenn nicht genügend Daten vorhanden sind, um ein solides Modell zu erstellen Um eine Unter- und Überanpassung zu verhindern, sollten weitere Daten hinzugefügt werden. Aus diesem Grund können viele FSL-Probleme gelöst werden, indem mehr Daten aus einem größeren zugrunde liegenden Datensatz genutzt werden. Ein bemerkenswertes Merkmal des Basisdatensatzes ist, dass ihm die Klassen fehlen, die unseren Unterstützungssatz für die Few-Shot-Herausforderung bilden. Wenn wir beispielsweise eine bestimmte Vogelart klassifizieren möchten, kann der zugrunde liegende Datensatz Bilder von vielen anderen Vögeln enthalten.
Parameter Level Approach (PLA)
Aus der Perspektive der Parameterebene lassen sich Few-Shot-Learning-Beispiele relativ leicht überanpassen, da sie normalerweise große hochdimensionale Räume haben. Die Einschränkung des Parameterraums, die Verwendung von Regularisierung und die Verwendung einer geeigneten Verlustfunktion helfen, dieses Problem zu lösen. Das Modell verwendet eine kleine Anzahl von Trainingsbeispielen zur Verallgemeinerung.
Die Leistung kann verbessert werden, indem das Modell in einen breiten Parameterraum geführt wird. Normale Optimierungsmethoden liefern aufgrund fehlender Trainingsdaten möglicherweise keine genauen Ergebnisse.
Aus den oben genannten Gründen führt das Training unseres Modells, um den besten Pfad durch den Parameterraum zu finden, zu den besten Vorhersageergebnissen. Dieser Ansatz wird Meta-Learning genannt.
Bildklassifizierungsalgorithmus für das Lernen kleiner Stichproben
Es gibt 4 gängige Lernmethoden für kleine Stichproben:
Modellunabhängiges Meta-Lernen Modellunabhängiges Meta-Lernen
Gradientenbasiertes Meta-Lernen (GBML) Das Prinzip ist MAML Base. In GBML sammeln Meta-Lernende Vorerfahrungen, indem sie an einem Basismodell trainieren und gemeinsame Funktionen in allen Aufgabendarstellungen erlernen. Jedes Mal, wenn es eine neue Aufgabe zu lernen gibt, wird der Meta-Lernende anhand seiner vorhandenen Erfahrung und der minimalen Menge neuer Trainingsdaten, die die neue Aufgabe bereitstellt, verfeinert.
Wenn wir Parameter zufällig initialisieren und mehrmals aktualisieren, wird der Algorithmus im Allgemeinen keine gute Leistung erzielen. MAML versucht, dieses Problem zu lösen. MAML ermöglicht eine zuverlässige Initialisierung des Metaparameter-Lerners mit nur wenigen Gradientenschritten und ohne Überanpassung, sodass neue Aufgaben optimal und schnell erlernt werden können.
Die Schritte sind wie folgt:
- Der Meta-Lernende erstellt zu Beginn jeder Episode eine eigene Kopie C,
- C wird auf diese Episode trainiert (mit Hilfe des Basismodells),
- C paart Vorhersagen werden für den Abfragesatz vorgenommen,
- Der aus diesen Vorhersagen berechnete Verlust wird zur Aktualisierung von C verwendet,
- Dies wird fortgesetzt, bis das Training für alle Episoden abgeschlossen ist.

Der größte Vorteil dieser Technik besteht darin, dass sie als unabhängig von der Wahl des Meta-Lernalgorithmus betrachtet wird. Daher werden MAML-Methoden häufig in vielen Algorithmen des maschinellen Lernens verwendet, die eine schnelle Anpassung erfordern, insbesondere in tiefen neuronalen Netzen.
Matching Networks
Die erste metrische Lernmethode, die zur Lösung des FSL-Problems entwickelt wurde, war das Matching Network (MN).
Ein großer Basisdatensatz ist erforderlich, wenn die Matching-Network-Methode zur Lösung des Few-Shot-Learning-Problems verwendet wird. .
Nachdem der Datensatz in mehrere Episoden unterteilt wurde, führt das Matching-Netzwerk für jede Episode die folgenden Operationen durch: Jedes Bild wird einem CNN zugeführt, das eine Einbettung der Funktionen für sie ausgibt
# 🎜🎜#Das Abfragebild verwendet ein auf dem Support-Set trainiertes Modell, um den Kosinusabstand der eingebetteten Features zu erhalten, der durch Softmax klassifiziert wird.- #🎜 🎜#Der Kreuzentropieverlust der Klassifizierungsergebnisse wird durch die zurückpropagiert CNN aktualisiert das Feature-Einbettungsmodell
- Das Matching-Netzwerk kann auf diese Weise lernen, Bildeinbettungen zu erstellen. MN ist in der Lage, Fotos mit dieser Methode zu klassifizieren, ohne dass besondere Vorkenntnisse in den Kategorien erforderlich sind. Es vergleicht einfach mehrere Instanzen der Klasse.
- Da Kategorien von Episode zu Episode variieren, berechnet das Matching-Netzwerk Bildattribute (Merkmale), die für die Kategorienunterscheidung wichtig sind. Bei Verwendung der Standardklassifizierung wählt der Algorithmus Merkmale aus, die für jede Kategorie einzigartig sind.
Verwenden von Open-AI Clip für Zero-Shot-Lernen
CLIP (Contrastive Language-Image Pre-Training) ist ein Neuronale Netze, die auf verschiedene (Bild-, Text-)Paare trainiert werden. Es kann die relevantesten Textfragmente für ein bestimmtes Bild vorhersagen, ohne direkt für die Aufgabe optimiert zu werden (ähnlich der Zero-Shot-Funktionalität von GPT-2 und 3).
CLIP kann die Leistung des ursprünglichen ResNet50 auf ImageNet „Zero Samples“ erreichen und erfordert keine Verwendung von gekennzeichneten Beispielen. Im Folgenden verwenden wir Pytorch zur Implementierung ein einfaches Klassifizierungsmodell.
Einführungspaket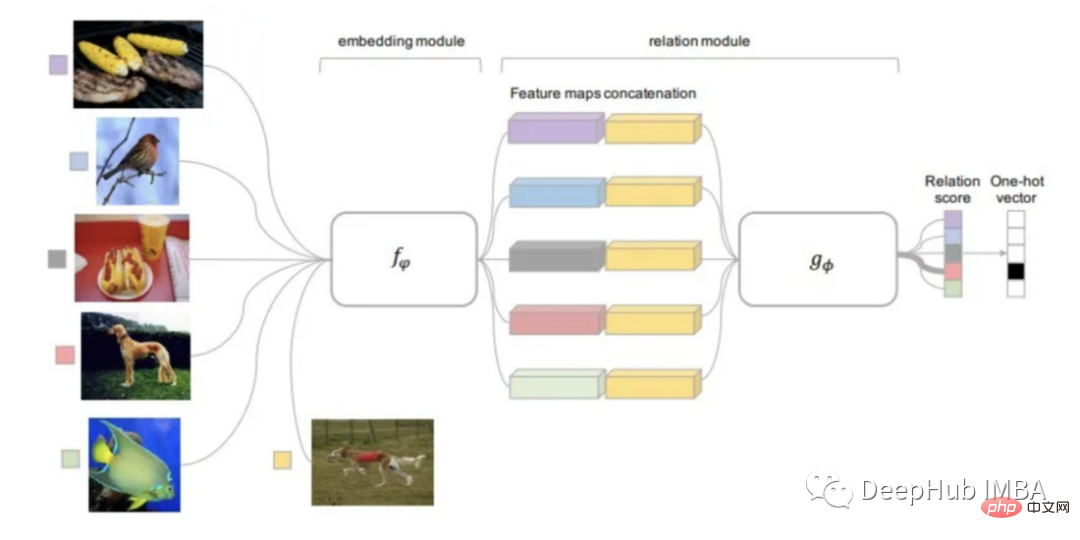
! pip install ftfy regex tqdm
! pip install git+https://github.com/openai/CLIP.gitimport numpy as np
import torch
from pkg_resources import packaging
print("Torch version:", torch.__version__)import clipclip.available_models() # it will list the names of available CLIP modelsmodel, preprocess = clip.load("ViT-B/32")
model.cuda().eval()
input_resolution = model.visual.input_resolution
context_length = model.context_length
vocab_size = model.vocab_size
print("Model parameters:", f"{np.sum([int(np.prod(p.shape)) for p in model.parameters()]):,}")
print("Input resolution:", input_resolution)
print("Context length:", context_length)
print("Vocab size:", vocab_size)Nach dem Login kopieren
BildvorverarbeitungWir werden 8 Beispielbilder in das Modell eingeben und ihre Textbeschreibungen und vergleichen Sie die Ähnlichkeiten zwischen entsprechenden Merkmalen. Der Tokenizer unterscheidet nicht zwischen Groß- und Kleinschreibung und es steht uns frei, jede geeignete Textbeschreibung anzugeben. import clipclip.available_models() # it will list the names of available CLIP modelsmodel, preprocess = clip.load("ViT-B/32")
model.cuda().eval()
input_resolution = model.visual.input_resolution
context_length = model.context_length
vocab_size = model.vocab_size
print("Model parameters:", f"{np.sum([int(np.prod(p.shape)) for p in model.parameters()]):,}")
print("Input resolution:", input_resolution)
print("Context length:", context_length)
print("Vocab size:", vocab_size) import os
import skimage
import IPython.display
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
from collections import OrderedDict
import torch
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
# images in skimage to use and their textual descriptions
descriptions = {
"page": "a page of text about segmentation",
"chelsea": "a facial photo of a tabby cat",
"astronaut": "a portrait of an astronaut with the American flag",
"rocket": "a rocket standing on a launchpad",
"motorcycle_right": "a red motorcycle standing in a garage",
"camera": "a person looking at a camera on a tripod",
"horse": "a black-and-white silhouette of a horse",
"coffee": "a cup of coffee on a saucer"
}original_images = []
images = []
texts = []
plt.figure(figsize=(16, 5))
for filename in [filename for filename in os.listdir(skimage.data_dir) if filename.endswith(".png") or filename.endswith(".jpg")]:
name = os.path.splitext(filename)[0]
if name not in descriptions:
continue
image = Image.open(os.path.join(skimage.data_dir, filename)).convert("RGB")
plt.subplot(2, 4, len(images) + 1)
plt.imshow(image)
plt.title(f"{filename}n{descriptions[name]}")
plt.xticks([])
plt.yticks([])
original_images.append(image)
images.append(preprocess(image))
texts.append(descriptions[name])
plt.tight_layout()Wir normalisieren das Bild, beschriften jede Texteingabe und führen es aus Die Vorwärtsausbreitung des Modells erhält die Merkmale von Bildern und Texten.
image_input = torch.tensor(np.stack(images)).cuda() text_tokens = clip.tokenize(["This is " + desc for desc in texts]).cuda() with torch.no_grad():
Wir normalisieren die Merkmale und berechnen das Skalarprodukt jedes Paares, um eine Kosinusähnlichkeitsberechnung durchzuführen
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = text_features.cpu().numpy() @ image_features.cpu().numpy().T
count = len(descriptions)
plt.figure(figsize=(20, 14))
plt.imshow(similarity, vmin=0.1, vmax=0.3)
# plt.colorbar()
plt.yticks(range(count), texts, fontsize=18)
plt.xticks([])
for i, image in enumerate(original_images):
plt.imshow(image, extent=(i - 0.5, i + 0.5, -1.6, -0.6), origin="lower")
for x in range(similarity.shape[1]):
for y in range(similarity.shape[0]):
plt.text(x, y, f"{similarity[y, x]:.2f}", ha="center", va="center", size=12)
for side in ["left", "top", "right", "bottom"]:
plt.gca().spines[side].set_visible(False)
plt.xlim([-0.5, count - 0.5])
plt.ylim([count + 0.5, -2])
plt.title("Cosine similarity between text and image features", size=20)#🎜🎜 #Nullstichprobe Bildklassifizierung
from torchvision.datasets import CIFAR100
cifar100 = CIFAR100(os.path.expanduser("~/.cache"), transform=preprocess, download=True)
text_descriptions = [f"This is a photo of a {label}" for label in cifar100.classes]
text_tokens = clip.tokenize(text_descriptions).cuda()
with torch.no_grad():
text_features = model.encode_text(text_tokens).float()
text_features /= text_features.norm(dim=-1, keepdim=True)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
top_probs, top_labels = text_probs.cpu().topk(5, dim=-1)
plt.figure(figsize=(16, 16))
for i, image in enumerate(original_images):
plt.subplot(4, 4, 2 * i + 1)
plt.imshow(image)
plt.axis("off")
plt.subplot(4, 4, 2 * i + 2)
y = np.arange(top_probs.shape[-1])
plt.grid()
plt.barh(y, top_probs[i])
plt.gca().invert_yaxis()
plt.gca().set_axisbelow(True)
plt.yticks(y, [cifar100.classes[index] for index in top_labels[i].numpy()])
plt.xlabel("probability")
plt.subplots_adjust(wspace=0.5)
plt.show()Es ist ersichtlich, dass der Klassifizierungseffekt immer noch sehr gut ist.
Das obige ist der detaillierte Inhalt vonBildklassifizierung mit Fow-Shot-Learning mit PyTorch. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In den Bereichen maschinelles Lernen und Datenwissenschaft stand die Interpretierbarkeit von Modellen schon immer im Fokus von Forschern und Praktikern. Mit der weit verbreiteten Anwendung komplexer Modelle wie Deep Learning und Ensemble-Methoden ist das Verständnis des Entscheidungsprozesses des Modells besonders wichtig geworden. Explainable AI|XAI trägt dazu bei, Vertrauen in maschinelle Lernmodelle aufzubauen, indem es die Transparenz des Modells erhöht. Eine Verbesserung der Modelltransparenz kann durch Methoden wie den weit verbreiteten Einsatz mehrerer komplexer Modelle sowie der Entscheidungsprozesse zur Erläuterung der Modelle erreicht werden. Zu diesen Methoden gehören die Analyse der Merkmalsbedeutung, die Schätzung des Modellvorhersageintervalls, lokale Interpretierbarkeitsalgorithmen usw. Die Merkmalswichtigkeitsanalyse kann den Entscheidungsprozess des Modells erklären, indem sie den Grad des Einflusses des Modells auf die Eingabemerkmale bewertet. Schätzung des Modellvorhersageintervalls
 Transparent! Eine ausführliche Analyse der Prinzipien der wichtigsten Modelle des maschinellen Lernens!
Apr 12, 2024 pm 05:55 PM
Transparent! Eine ausführliche Analyse der Prinzipien der wichtigsten Modelle des maschinellen Lernens!
Apr 12, 2024 pm 05:55 PM
Laienhaft ausgedrückt ist ein Modell für maschinelles Lernen eine mathematische Funktion, die Eingabedaten einer vorhergesagten Ausgabe zuordnet. Genauer gesagt ist ein Modell für maschinelles Lernen eine mathematische Funktion, die Modellparameter anpasst, indem sie aus Trainingsdaten lernt, um den Fehler zwischen der vorhergesagten Ausgabe und der wahren Bezeichnung zu minimieren. Beim maschinellen Lernen gibt es viele Modelle, z. B. logistische Regressionsmodelle, Entscheidungsbaummodelle, Support-Vektor-Maschinenmodelle usw. Jedes Modell verfügt über seine anwendbaren Datentypen und Problemtypen. Gleichzeitig gibt es viele Gemeinsamkeiten zwischen verschiedenen Modellen oder es gibt einen verborgenen Weg für die Modellentwicklung. Am Beispiel des konnektionistischen Perzeptrons können wir es durch Erhöhen der Anzahl verborgener Schichten des Perzeptrons in ein tiefes neuronales Netzwerk umwandeln. Wenn dem Perzeptron eine Kernelfunktion hinzugefügt wird, kann es in eine SVM umgewandelt werden. Dieses hier
 Identifizieren Sie Über- und Unteranpassung anhand von Lernkurven
Apr 29, 2024 pm 06:50 PM
Identifizieren Sie Über- und Unteranpassung anhand von Lernkurven
Apr 29, 2024 pm 06:50 PM
In diesem Artikel wird vorgestellt, wie Überanpassung und Unteranpassung in Modellen für maschinelles Lernen mithilfe von Lernkurven effektiv identifiziert werden können. Unteranpassung und Überanpassung 1. Überanpassung Wenn ein Modell mit den Daten übertrainiert ist, sodass es daraus Rauschen lernt, spricht man von einer Überanpassung des Modells. Ein überangepasstes Modell lernt jedes Beispiel so perfekt, dass es ein unsichtbares/neues Beispiel falsch klassifiziert. Für ein überangepasstes Modell erhalten wir einen perfekten/nahezu perfekten Trainingssatzwert und einen schrecklichen Validierungssatz-/Testwert. Leicht geändert: „Ursache der Überanpassung: Verwenden Sie ein komplexes Modell, um ein einfaches Problem zu lösen und Rauschen aus den Daten zu extrahieren. Weil ein kleiner Datensatz als Trainingssatz möglicherweise nicht die korrekte Darstellung aller Daten darstellt. 2. Unteranpassung Heru.“
 Die Entwicklung der künstlichen Intelligenz in der Weltraumforschung und der Siedlungstechnik
Apr 29, 2024 pm 03:25 PM
Die Entwicklung der künstlichen Intelligenz in der Weltraumforschung und der Siedlungstechnik
Apr 29, 2024 pm 03:25 PM
In den 1950er Jahren wurde die künstliche Intelligenz (KI) geboren. Damals entdeckten Forscher, dass Maschinen menschenähnliche Aufgaben wie das Denken ausführen können. Später, in den 1960er Jahren, finanzierte das US-Verteidigungsministerium künstliche Intelligenz und richtete Labore für die weitere Entwicklung ein. Forscher finden Anwendungen für künstliche Intelligenz in vielen Bereichen, etwa bei der Erforschung des Weltraums und beim Überleben in extremen Umgebungen. Unter Weltraumforschung versteht man die Erforschung des Universums, das das gesamte Universum außerhalb der Erde umfasst. Der Weltraum wird als extreme Umgebung eingestuft, da sich seine Bedingungen von denen auf der Erde unterscheiden. Um im Weltraum zu überleben, müssen viele Faktoren berücksichtigt und Vorkehrungen getroffen werden. Wissenschaftler und Forscher glauben, dass die Erforschung des Weltraums und das Verständnis des aktuellen Zustands aller Dinge dazu beitragen können, die Funktionsweise des Universums zu verstehen und sich auf mögliche Umweltkrisen vorzubereiten
 Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Zu den häufigsten Herausforderungen, mit denen Algorithmen für maschinelles Lernen in C++ konfrontiert sind, gehören Speicherverwaltung, Multithreading, Leistungsoptimierung und Wartbarkeit. Zu den Lösungen gehören die Verwendung intelligenter Zeiger, moderner Threading-Bibliotheken, SIMD-Anweisungen und Bibliotheken von Drittanbietern sowie die Einhaltung von Codierungsstilrichtlinien und die Verwendung von Automatisierungstools. Praktische Fälle zeigen, wie man die Eigen-Bibliothek nutzt, um lineare Regressionsalgorithmen zu implementieren, den Speicher effektiv zu verwalten und leistungsstarke Matrixoperationen zu nutzen.
 Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Übersetzer |. Rezensiert von Li Rui |. Chonglou Modelle für künstliche Intelligenz (KI) und maschinelles Lernen (ML) werden heutzutage immer komplexer, und die von diesen Modellen erzeugten Ergebnisse sind eine Blackbox, die den Stakeholdern nicht erklärt werden kann. Explainable AI (XAI) zielt darauf ab, dieses Problem zu lösen, indem es Stakeholdern ermöglicht, die Funktionsweise dieser Modelle zu verstehen, sicherzustellen, dass sie verstehen, wie diese Modelle tatsächlich Entscheidungen treffen, und Transparenz in KI-Systemen, Vertrauen und Verantwortlichkeit zur Lösung dieses Problems gewährleistet. In diesem Artikel werden verschiedene Techniken der erklärbaren künstlichen Intelligenz (XAI) untersucht, um ihre zugrunde liegenden Prinzipien zu veranschaulichen. Mehrere Gründe, warum erklärbare KI von entscheidender Bedeutung ist. Vertrauen und Transparenz: Damit KI-Systeme allgemein akzeptiert und vertrauenswürdig sind, müssen Benutzer verstehen, wie Entscheidungen getroffen werden
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
