
 Technologie-Peripheriegeräte
KI
Deep Reinforcement Learning befasst sich mit dem realen autonomen Fahren
Technologie-Peripheriegeräte
KI
Deep Reinforcement Learning befasst sich mit dem realen autonomen Fahren
Deep Reinforcement Learning befasst sich mit dem realen autonomen Fahren

Das arXiv-Papier „Tackling Real-World Autonomous Driving using Deep Reinforcement Learning“ wurde am 5. Juli 2022 hochgeladen. Die Autoren stammen von Vislab der Universität Parma in Italien und Ambarella (Übernahme von Vislab).

In einer typischen Montagelinie für autonomes Fahren stellt das Regelungs- und Steuerungssystem die beiden kritischsten Komponenten dar, in denen die vom Sensor abgerufenen Daten und die vom Wahrnehmungsalgorithmus verarbeiteten Daten verwendet werden, um sicheres und komfortables autonomes Fahren zu erreichen Verhalten. Insbesondere sagt das Planungsmodul den Weg voraus, dem das selbstfahrende Auto folgen sollte, um die richtigen Aktionen auf hoher Ebene auszuführen, während das Steuerungssystem eine Reihe von Aktionen auf niedriger Ebene ausführt und dabei Lenkung, Gas und Bremsen steuert.
Diese Arbeit schlägt einen modellfreien Deep Reinforcement Learning (DRL)Planer vor, um ein neuronales Netzwerk zu trainieren, um Beschleunigung und Lenkwinkel vorherzusagen und so die Ausgabe eines Lokalisierungs- und Wahrnehmungsalgorithmus für autonome Fahrzeuge zu erhalten. Die Daten steuern ein einzelnes Modul von das Fahrzeug. Insbesondere kann das System, das vollständig simuliert und trainiert wurde, in simulierten und realen (Stadtgebiet von Palma) barrierefreien Umgebungen reibungslos und sicher fahren, was beweist, dass das System über gute Generalisierungsfähigkeiten verfügt und auch in anderen Umgebungen als Trainingsszenarien fahren kann. Um das System außerdem in realen autonomen Fahrzeugen einzusetzen und die Lücke zwischen simulierter und realer Leistung zu verringern, entwickelten die Autoren außerdem ein Modul, das durch ein Miniatur-Neuronales Netzwerk dargestellt wird, das in der Lage ist, das Verhalten der realen Umgebung während des Simulationstrainings zu reproduzieren . Dynamisches Verhalten des Autos.
In den letzten Jahrzehnten wurden enorme Fortschritte bei der Verbesserung des Automatisierungsgrads von Fahrzeugen erzielt, von einfachen, regelbasierten Ansätzen bis hin zur Implementierung KI-basierter intelligenter Systeme. Diese Systeme zielen insbesondere darauf ab, die Haupteinschränkungen regelbasierter Ansätze zu beseitigen, nämlich die fehlende Verhandlung und Interaktion mit anderen Verkehrsteilnehmern und das schlechte Verständnis der Szenendynamik.
Reinforcement Learning (RL) wird häufig verwendet, um Aufgaben zu lösen, die diskrete Kontrollraumausgänge nutzen, wie z. B. Go, Atari-Spiele oder Schach, sowie autonomes Fahren im kontinuierlichen Kontrollraum. Insbesondere im Bereich des autonomen Fahrens werden RL-Algorithmen häufig zur Entwicklung von Entscheidungs- und Manöverausführungssystemen eingesetzt, beispielsweise für aktive Spurwechsel, Spurhaltung, Überholmanöver, Kreuzungs- und Kreisverkehrsverarbeitung usw.
Dieser Artikel verwendet eine verzögerte Version von D-A3C, die zur sogenannten Actor-Critics-Algorithmusfamilie gehört. Konkret bestehend aus zwei verschiedenen Einheiten: Schauspielern und Kritikern. Der Zweck des Akteurs besteht darin, die Aktionen auszuwählen, die der Agent ausführen muss, während der Kritiker die Zustandswertfunktion schätzt, also wie gut der spezifische Zustand des Agenten ist. Mit anderen Worten: Akteure sind Wahrscheinlichkeitsverteilungen π(a|s; θπ) über Aktionen (wobei θ Netzwerkparameter sind) und Kritiker sind geschätzte Zustandswertfunktionen v(st; θv) = E(Rt|st), wobei R ist Erwartete Rendite.
Die intern entwickelte hochauflösende Karte implementiert den Simulationssimulator. Ein Beispiel für die Szene ist in Abbildung a dargestellt. Dabei handelt es sich um einen Teilkartenbereich des realen autonomen Fahrzeugtestsystems, während Abbildung b die Umgebungsansicht zeigt intelligente Körperwahrnehmung, entsprechend 50× Der 50-Meter-Bereich ist in vier Kanäle unterteilt: Hindernisse (Abbildung c), befahrbarer Raum (Abbildung d), der Weg, dem der Agent folgen sollte (Abbildung e) und die Stopplinie (Abbildung). F). Die hochauflösende Karte im Simulator ermöglicht den Abruf mehrerer Informationen über die äußere Umgebung, wie z. B. Lage oder Anzahl der Fahrspuren, Geschwindigkeitsbegrenzungen usw.
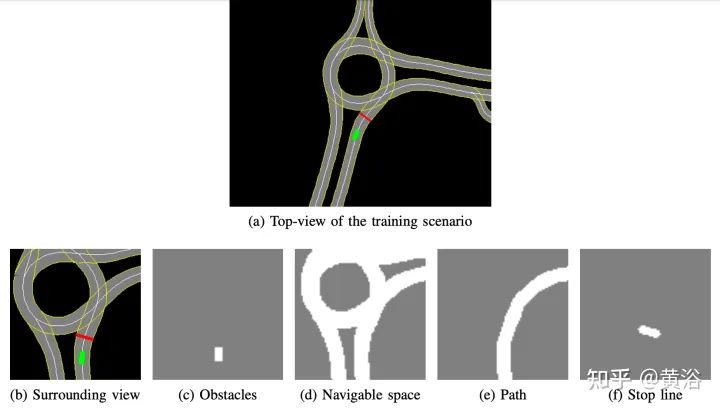
Konzentrieren Sie sich auf einen reibungslosen und sicheren Fahrstil, sodass der Agent in statischen Szenen geschult wird, Hindernisse oder andere Verkehrsteilnehmer ausschließt und lernt, Routen zu befolgen und Geschwindigkeitsbegrenzungen einzuhalten.
Verwenden Sie das in der Abbildung gezeigte neuronale Netzwerk, um den Agenten zu trainieren und alle 100 Millisekunden den Lenkwinkel und die Beschleunigung vorherzusagen. Es gliedert sich in zwei Untermodule: Das erste Untermodul kann den Lenkwinkel sa definieren, das zweite Untermodul dient der Definition der Beschleunigung gem. Die Eingaben in diese beiden Submodule werden durch 4 Kanäle (fahrbarer Raum, Weg, Hindernis und Stopplinie) dargestellt, die der Umgebungsansicht des Agenten entsprechen. Jeder visuelle Eingabekanal enthält vier 84×84 Pixel große Bilder, um dem Agenten einen Verlauf vergangener Zustände zu liefern. Zusammen mit dieser visuellen Eingabe empfängt das Netzwerk fünf skalare Parameter, darunter die Zielgeschwindigkeit (Geschwindigkeitsbegrenzung auf der Straße), die aktuelle Geschwindigkeit des Agenten, das Verhältnis von aktueller Geschwindigkeit zu Zielgeschwindigkeit und die endgültige Aktion in Bezug auf Lenkwinkel und Beschleunigung.
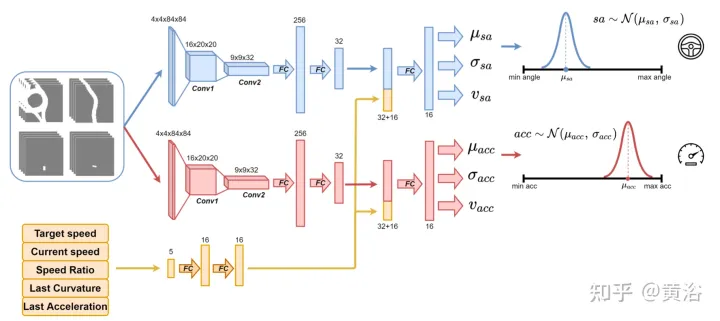
Um die Erkundung sicherzustellen, werden zwei Gaußsche Verteilungen verwendet, um die Ausgabe der beiden Untermodule abzutasten und die relative Beschleunigung (acc=N (μacc, σacc)) und den Lenkwinkel (sa=N (μsa) zu erhalten , σsa) ). Die Standardabweichungen σacc und σsa werden vom neuronalen Netzwerk während der Trainingsphase vorhergesagt und moduliert, um die Unsicherheit des Modells abzuschätzen. Darüber hinaus verwendet das Netzwerk zwei verschiedene Belohnungsfunktionen R-acc-t und R-sa-t, die sich auf Beschleunigung bzw. Lenkwinkel beziehen, um entsprechende Zustandswertschätzungen (vacc und vsa) zu generieren.
Das neuronale Netzwerk wird an vier Szenen in der Stadt Palma trainiert. Für jedes Szenario werden mehrere Instanzen erstellt und die Agenten sind auf diesen Instanzen unabhängig voneinander. Jeder Agent folgt dem kinematischen Fahrradmodell mit einem Lenkwinkel von [-0,2, +0,2] und einer Beschleunigung von [-2,0 m, +2,0 m]. Zu Beginn des Segments beginnt jeder Agent mit einer zufälligen Geschwindigkeit ([0,0, 8,0]) zu fahren und folgt seinem beabsichtigten Weg unter Einhaltung der Geschwindigkeitsbegrenzungen auf der Straße. Die Geschwindigkeitsbegrenzungen auf der Straße in diesem Stadtgebiet liegen zwischen 4 ms und 8,3 ms.
Da es schließlich keine Hindernisse in der Trainingsszene gibt, kann der Clip in einem der folgenden Endzustände enden:
- Ziel erreicht: Der Agent erreicht die endgültige Zielposition.
- Fahrt abseits der Straße: Der Agent verlässt seinen vorgesehenen Weg und sagt den Lenkwinkel falsch voraus.
- Die Zeit ist abgelaufen: Die Zeit zum Abschließen des Fragments ist hauptsächlich auf vorsichtige Vorhersagen der Beschleunigungsleistung beim Fahren unterhalb der Straßengeschwindigkeitsbegrenzung zurückzuführen.
Um eine Strategie zu erhalten, mit der ein Auto in simulierten und realen Umgebungen erfolgreich gefahren werden kann, ist die Gestaltung der Belohnungen entscheidend, um das gewünschte Verhalten zu erreichen. Insbesondere werden zwei verschiedene Belohnungsfunktionen definiert, um die beiden Aktionen jeweils zu bewerten: R-acc-t und R-sa-t beziehen sich auf die Beschleunigung bzw. den Lenkwinkel und sind wie folgt definiert:
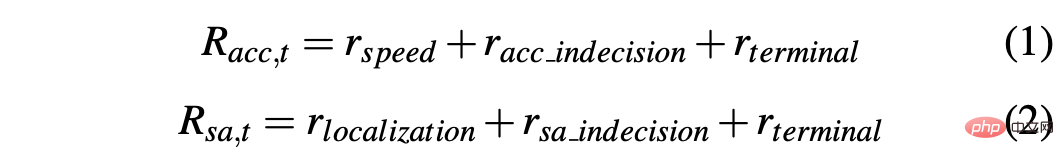
wobei
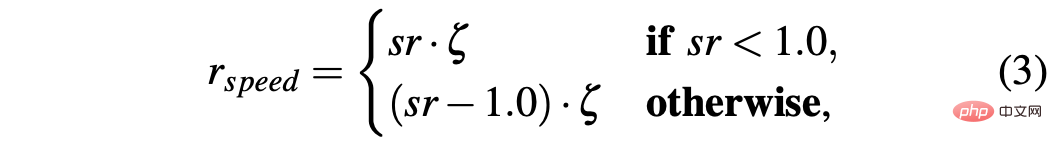
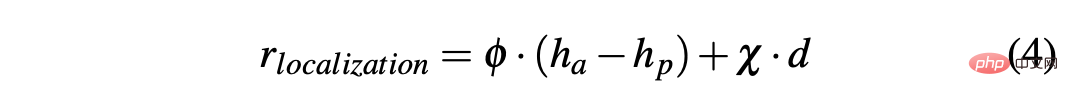
R-sa-t und R-acc-t haben beide ein Element in der Formel, um zwei aufeinanderfolgende Aktionen zu bestrafen, deren Beschleunigungs- und Lenkwinkelunterschied größer als ein bestimmter Schwellenwert δacc bzw. δsa ist. Insbesondere wird die Differenz zwischen zwei aufeinanderfolgenden Beschleunigungen wie folgt berechnet: Δacc=|acc(t)−acc(t−1)|, während rac_indecision wie folgt definiert ist:
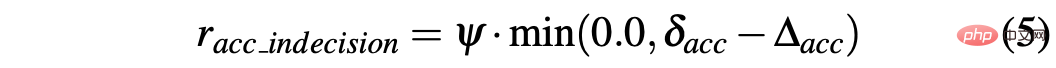
Im Gegensatz dazu sind die beiden Lenkwinkel The Die Differenz zwischen aufeinanderfolgenden Vorhersagen wird als Δsa=|sa(t)−sa(t−1)| berechnet, während rsa_indecision wie folgt definiert ist:
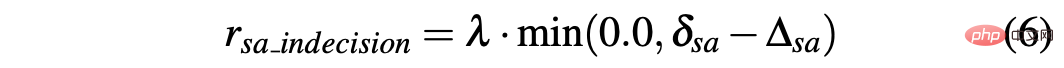
Schließlich hängen R-acc-t und R-sa-t vom Terminal ab Vom Agenten erreichte Zustände:
- Ziel erreicht: Der Agent erreicht die Zielposition, daher wird das Rterminal für beide Belohnungen auf +1,0 gesetzt.
- Fahrt von der Straße ab: Der Agent weicht hauptsächlich aufgrund der Vorhersage von seinem Weg ab des Lenkwinkels Nicht genau. Weisen Sie daher Rsa,t ein negatives Signal von -1,0 und R-acc-t ein negatives Signal von 0,0 zu vorsichtig; daher geht rterminal für R-acc-t von −1,0 und für R-sa-t von 0,0 aus.
- Eines der Hauptprobleme bei Simulatoren ist der Unterschied zwischen simulierten und realen Daten, der durch die Schwierigkeit verursacht wird, reale Situationen im Simulator wirklich zu reproduzieren. Um dieses Problem zu lösen, wird ein synthetischer Simulator verwendet, um die Eingabe in das neuronale Netzwerk zu vereinfachen und die Lücke zwischen simulierten und realen Daten zu verringern. Tatsächlich können die in den vier Kanälen (Hindernisse, Fahrraum, Weg und Haltelinie) enthaltenen Informationen als Eingabe in das neuronale Netzwerk leicht durch Wahrnehmungs- und Lokalisierungsalgorithmen und hochauflösende Karten reproduziert werden, die in echte autonome Fahrzeuge eingebettet sind.
Darüber hinaus hängt ein weiteres damit zusammenhängendes Problem bei der Verwendung von Simulatoren mit dem Unterschied zwischen den beiden Arten zusammen, wie ein simulierter Agent eine Zielaktion ausführt und ein selbstfahrendes Auto diesen Befehl ausführt. Tatsächlich kann die zum Zeitpunkt t berechnete Zielaktion im Idealfall sofort und genau zum gleichen Zeitpunkt in der Simulation wirksam werden. Der Unterschied besteht darin, dass dies bei einem realen Fahrzeug nicht der Fall ist, da solche Zielaktionen in der Realität mit einer gewissen Dynamik ausgeführt werden, was zu einer Ausführungsverzögerung (t+δ) führt. Daher ist es notwendig, solche Reaktionszeiten in Simulationen einzuführen, um Agenten in echten selbstfahrenden Autos zu schulen, mit solchen Verzögerungen umzugehen.
Um ein realistischeres Verhalten zu erreichen, wird der Agent zunächst darauf trainiert, dem neuronalen Netzwerk einen Tiefpassfilter hinzuzufügen, den der Agent ausführen muss, um die Zielaktion vorherzusagen. Wie in der Abbildung dargestellt, stellt die blaue Kurve die idealen und sofortigen Reaktionszeiten dar, die in der Simulation unter Verwendung der Zielaktion (dem Lenkwinkel ihres Beispiels) auftreten. Nach der Einführung eines Tiefpassfilters identifiziert die grüne Kurve dann die simulierte Reaktionszeit des Agenten. Im Gegensatz dazu zeigt die orangefarbene Kurve das Verhalten eines autonomen Fahrzeugs, das das gleiche Lenkmanöver durchführt. Aus der Abbildung ist jedoch ersichtlich, dass der Unterschied in der Reaktionszeit zwischen simulierten und realen Fahrzeugen immer noch relevant ist.
Tatsächlich sind die vom neuronalen Netzwerk voreingestellten Beschleunigungs- und Lenkwinkelpunkte keine realisierbaren Befehle und berücksichtigen einige Faktoren nicht, wie z. B. die Trägheit des Systems, die Verzögerung des Aktuators und andere nicht ideale Faktoren. Um die Dynamik eines realen Fahrzeugs möglichst realistisch abzubilden, wurde daher ein Modell bestehend aus einem kleinen neuronalen Netzwerk bestehend aus 3 vollständig verbundenen Schichten (Deep Response) entwickelt. Das Diagramm des Tiefenreaktionsverhaltens ist in der Abbildung oben als rote gestrichelte Linie dargestellt. Es ist zu erkennen, dass es der orangefarbenen Kurve, die ein echtes selbstfahrendes Auto darstellt, sehr ähnlich ist. Da es in der Trainingsszene keine Hindernisse und Verkehrsfahrzeuge gibt, ist das beschriebene Problem bei der Lenkwinkelaktivität ausgeprägter, die gleiche Idee wurde jedoch auf die Beschleunigungsleistung angewendet.
Trainieren Sie ein Deep-Response-Modell mithilfe eines Datensatzes, der an einem selbstfahrenden Auto gesammelt wurde, wobei die Eingaben den Befehlen entsprechen, die der menschliche Fahrer dem Fahrzeug erteilt (Gaspedaldruck und Lenkraddrehungen), und die Ausgaben der Drosselklappe des Fahrzeugs entsprechen , Bremsen und Biegen, was mithilfe von GPS, Kilometerzähler oder anderen technischen Messungen erfolgen kann. Auf diese Weise führt die Einbettung solcher Modelle in einen Simulator zu einem besser skalierbaren System, das das Verhalten autonomer Fahrzeuge nachbildet. Das Tiefenreaktionsmodul ist daher für die Korrektur des Lenkwinkels unerlässlich, aber auch in weniger offensichtlicher Weise ist es für die Beschleunigung notwendig, und dies wird bei der Einführung von Hindernissen deutlich sichtbar.
Zwei verschiedene Strategien wurden anhand realer Daten getestet, um die Auswirkungen des Deep-Response-Modells auf das System zu überprüfen. Überprüfen Sie anschließend, ob das Fahrzeug dem Weg korrekt folgt und die aus der HD-Karte abgeleiteten Geschwindigkeitsbegrenzungen einhält. Schließlich ist erwiesen, dass das Vortraining des neuronalen Netzwerks durch „Imitation Learning“ die Gesamttrainingszeit erheblich verkürzen kann. Die Strategie lautet wie folgt:
Strategie 1: Verwenden Sie für das Training nicht das Deep-Response-Modell, sondern verwenden Sie einen Tiefpassfilter, um die Reaktion des realen Fahrzeugs auf die Zielaktion zu simulieren.- Strategie 2: Sorgen Sie für eine realistischere Dynamik, indem Sie ein Deep-Response-Modell für das Training einführen.
- In Simulationen durchgeführte Tests ergaben für beide Strategien gute Ergebnisse. Unabhängig davon, ob es sich um eine trainierte Szene oder einen nicht trainierten Kartenbereich handelt, kann der Agent das Ziel zu 100 % mit reibungslosem und sicherem Verhalten erreichen.
Durch das Testen der Strategie in realen Szenarien wurden unterschiedliche Ergebnisse erzielt. Strategie 1 kann die Fahrzeugdynamik nicht verarbeiten und führt die vorhergesagten Aktionen anders aus als der Agent in der Simulation. Auf diese Weise beobachtet Strategie 1 unerwartete Zustände seiner Vorhersagen, was zu lautem Verhalten am autonomen Fahrzeug und unangenehmen Verhaltensweisen führt.
Dieses Verhalten wirkt sich auch auf die Zuverlässigkeit des Systems aus. Tatsächlich ist manchmal menschliche Hilfe erforderlich, um zu verhindern, dass selbstfahrende Autos von der Straße abkommen.
Im Gegensatz dazu erfordert Strategie 2 bei allen realen Tests selbstfahrender Autos nie, dass ein Mensch das Kommando übernimmt, da er die Fahrzeugdynamik und die Entwicklung des Systems kennt, um Aktionen vorherzusagen. Die einzigen Situationen, in denen ein menschliches Eingreifen erforderlich ist, bestehen darin, anderen Verkehrsteilnehmern auszuweichen. Diese Situationen gelten jedoch nicht als Fehlschläge, da beide Strategien 1 und 2 in barrierefreien Szenarien trainiert werden.
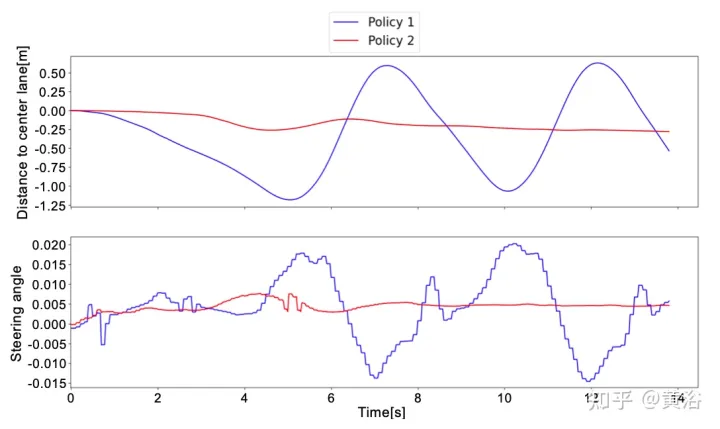
Um den Unterschied zwischen Strategie 1 und Strategie 2 besser zu verstehen, finden Sie hier den vom neuronalen Netzwerk vorhergesagten Lenkwinkel und den Abstand zur Mittelspur innerhalb eines kurzen Zeitfensters realer Tests. Es ist zu erkennen, dass sich die beiden Strategien im Vergleich zu Strategie 2 (rote Kurve) völlig unterschiedlich verhalten, was beweist, dass das Deep-Response-Modul für den Einsatz in wirklich autonomen Fahrzeugen von entscheidender Bedeutung ist .
 Um die Einschränkungen von RL zu überwinden, die Millionen von Segmenten erfordern, um die optimale Lösung zu erreichen, wird ein Vortraining durch Imitation Learning (IL) durchgeführt. Darüber hinaus wird, auch wenn der Trend in IL dahin geht, große Modelle zu trainieren, dasselbe kleine neuronale Netzwerk (~1 Million Parameter) verwendet, da die Idee darin besteht, das System weiterhin mit dem RL-Framework zu trainieren, um mehr Robustheit und Generalisierungsfähigkeiten sicherzustellen. Auf diese Weise wird die Nutzung von Hardware-Ressourcen nicht erhöht, was im Hinblick auf ein mögliches zukünftiges Multi-Agent-Training von entscheidender Bedeutung ist.
Um die Einschränkungen von RL zu überwinden, die Millionen von Segmenten erfordern, um die optimale Lösung zu erreichen, wird ein Vortraining durch Imitation Learning (IL) durchgeführt. Darüber hinaus wird, auch wenn der Trend in IL dahin geht, große Modelle zu trainieren, dasselbe kleine neuronale Netzwerk (~1 Million Parameter) verwendet, da die Idee darin besteht, das System weiterhin mit dem RL-Framework zu trainieren, um mehr Robustheit und Generalisierungsfähigkeiten sicherzustellen. Auf diese Weise wird die Nutzung von Hardware-Ressourcen nicht erhöht, was im Hinblick auf ein mögliches zukünftiges Multi-Agent-Training von entscheidender Bedeutung ist.
Der in der IL-Trainingsphase verwendete Datensatz wird von simulierten Agenten generiert, die einem regelbasierten Bewegungsansatz folgen. Insbesondere beim Biegen wird ein reiner Verfolgungsverfolgungsalgorithmus verwendet, bei dem der Agent darauf abzielt, sich entlang eines bestimmten Wegpunkts zu bewegen. Verwenden Sie stattdessen das IDM-Modell, um die Längsbeschleunigung des Agenten zu steuern.
Um den Datensatz zu erstellen, wurde ein regelbasierter Agent über vier Trainingsszenen bewegt, wobei alle 100 Millisekunden skalare Parameter und vier visuelle Eingaben gespeichert wurden. Stattdessen wird die Ausgabe durch den reinen Verfolgungsalgorithmus und das IDM-Modell bereitgestellt.
Die beiden horizontalen und vertikalen Steuerelemente, die der Ausgabe entsprechen, stellen einfach Tupel (μacc, μsa) dar. Daher werden während der IL-Trainingsphase weder die Werte der Standardabweichung (σacc, σsa) noch die Wertfunktionen (vacc, vsa) geschätzt. Diese Funktionen und das Tiefenreaktionsmodul werden in der IL+RL-Trainingsphase erlernt.
Wie in der Abbildung gezeigt, zeigt es das Training desselben neuronalen Netzwerks ab der Vortrainingsphase (blaue Kurve, IL+RL) und vergleicht es mit den RL-Ergebnissen (rote Kurve, reines RL) in vier Fällen . Auch wenn das IL+RL-Training weniger Zeiten erfordert als reines RL und der Trend stabiler ist, erzielen beide Methoden gute Erfolgsquoten (Abbildung a).
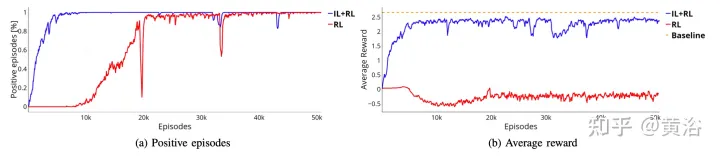
Darüber hinaus beweist die in Abbildung b dargestellte Belohnungskurve, dass die mit dem reinen RL-Ansatz (rote Kurve) erhaltene Richtlinie nicht einmal die akzeptable Lösung für mehr Trainingszeit erreicht, während die IL+RL-Richtlinie dies innerhalb weniger Minuten erreicht Fragmente Optimale Lösung (blaue Kurve in Abbildung b). In diesem Fall wird die optimale Lösung durch die orange gestrichelte Linie dargestellt. Diese Basislinie stellt die durchschnittliche Belohnung dar, die ein simulierter Agent erhält, der 50.000 Segmente in 4 Szenarien ausführt. Der simulierte Agent folgt den deterministischen Regeln, die mit denen zur Erfassung des IL-Vortrainingsdatensatzes identisch sind, d. h. die reine Verfolgungsregel wird für die Biegung und die IDM-Regel für die Längsbeschleunigung verwendet. Die Kluft zwischen den beiden Ansätzen könnte sogar noch größer sein, wenn es darum geht, Systeme für die Durchführung komplexerer Manöver zu trainieren, bei denen möglicherweise eine Interaktion zwischen Intelligenz und Körper erforderlich ist.
Das obige ist der detaillierte Inhalt vonDeep Reinforcement Learning befasst sich mit dem realen autonomen Fahren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1662
1662
 14
1419
52
1312
25
1262
29
1235
24
14
1419
52
1312
25
1262
29
1235
24

 Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Oben geschrieben und persönliches Verständnis des Autors. Dreidimensionales Gaussplatting (3DGS) ist eine transformative Technologie, die in den letzten Jahren in den Bereichen explizite Strahlungsfelder und Computergrafik entstanden ist. Diese innovative Methode zeichnet sich durch die Verwendung von Millionen von 3D-Gaußkurven aus, was sich stark von der Neural Radiation Field (NeRF)-Methode unterscheidet, die hauptsächlich ein implizites koordinatenbasiertes Modell verwendet, um räumliche Koordinaten auf Pixelwerte abzubilden. Mit seiner expliziten Szenendarstellung und differenzierbaren Rendering-Algorithmen garantiert 3DGS nicht nur Echtzeit-Rendering-Fähigkeiten, sondern führt auch ein beispielloses Maß an Kontrolle und Szenenbearbeitung ein. Dies positioniert 3DGS als potenziellen Game-Changer für die 3D-Rekonstruktion und -Darstellung der nächsten Generation. Zu diesem Zweck geben wir erstmals einen systematischen Überblick über die neuesten Entwicklungen und Anliegen im Bereich 3DGS.
 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
0. Vorab geschrieben&& Persönliches Verständnis, dass autonome Fahrsysteme auf fortschrittlichen Wahrnehmungs-, Entscheidungs- und Steuerungstechnologien beruhen, indem sie verschiedene Sensoren (wie Kameras, Lidar, Radar usw.) verwenden, um die Umgebung wahrzunehmen, und Algorithmen und Modelle verwenden für Echtzeitanalysen und Entscheidungsfindung. Dies ermöglicht es Fahrzeugen, Verkehrszeichen zu erkennen, andere Fahrzeuge zu erkennen und zu verfolgen, das Verhalten von Fußgängern vorherzusagen usw. und sich so sicher an komplexe Verkehrsumgebungen anzupassen. Diese Technologie erregt derzeit große Aufmerksamkeit und gilt als wichtiger Entwicklungsbereich für die Zukunft des Transportwesens . eins. Aber was autonomes Fahren schwierig macht, ist herauszufinden, wie man dem Auto klarmachen kann, was um es herum passiert. Dies erfordert, dass der dreidimensionale Objekterkennungsalgorithmus im autonomen Fahrsystem Objekte in der Umgebung, einschließlich ihrer Standorte, genau wahrnehmen und beschreiben kann.
 Beherrschen Sie die Koordinatensystemkonvertierung wirklich? Multisensorik-Themen, die für das autonome Fahren unverzichtbar sind
Oct 12, 2023 am 11:21 AM
Beherrschen Sie die Koordinatensystemkonvertierung wirklich? Multisensorik-Themen, die für das autonome Fahren unverzichtbar sind
Oct 12, 2023 am 11:21 AM
Der erste Pilot- und Schlüsselartikel stellt hauptsächlich mehrere häufig verwendete Koordinatensysteme in der autonomen Fahrtechnologie vor und erläutert, wie die Korrelation und Konvertierung zwischen ihnen abgeschlossen und schließlich ein einheitliches Umgebungsmodell erstellt werden kann. Der Schwerpunkt liegt hier auf dem Verständnis der Umrechnung vom Fahrzeug in den starren Kamerakörper (externe Parameter), der Kamera-in-Bild-Konvertierung (interne Parameter) und der Bild-in-Pixel-Einheitenkonvertierung. Die Konvertierung von 3D in 2D führt zu entsprechenden Verzerrungen, Verschiebungen usw. Wichtige Punkte: Das Fahrzeugkoordinatensystem und das Kamerakörperkoordinatensystem müssen neu geschrieben werden: Das Ebenenkoordinatensystem und das Pixelkoordinatensystem. Schwierigkeit: Sowohl die Entzerrung als auch die Verzerrungsaddition müssen auf der Bildebene kompensiert werden. 2. Einführung Insgesamt gibt es vier visuelle Systeme Koordinatensystem: Pixelebenenkoordinatensystem (u, v), Bildkoordinatensystem (x, y), Kamerakoordinatensystem () und Weltkoordinatensystem (). Es gibt eine Beziehung zwischen jedem Koordinatensystem,
 SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
Originaltitel: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper-Link: https://arxiv.org/pdf/2402.02519.pdf Code-Link: https://github.com/HKUST-Aerial-Robotics/SIMPL Autor: Hong Kong University of Science und Technologie DJI-Papieridee: Dieses Papier schlägt eine einfache und effiziente Bewegungsvorhersagebasislinie (SIMPL) für autonome Fahrzeuge vor. Im Vergleich zum herkömmlichen Agent-Cent
 Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Die Trajektorienvorhersage spielt eine wichtige Rolle beim autonomen Fahren. Unter autonomer Fahrtrajektorienvorhersage versteht man die Vorhersage der zukünftigen Fahrtrajektorie des Fahrzeugs durch die Analyse verschiedener Daten während des Fahrvorgangs. Als Kernmodul des autonomen Fahrens ist die Qualität der Trajektorienvorhersage von entscheidender Bedeutung für die nachgelagerte Planungssteuerung. Die Trajektorienvorhersageaufgabe verfügt über einen umfangreichen Technologie-Stack und erfordert Vertrautheit mit der dynamischen/statischen Wahrnehmung des autonomen Fahrens, hochpräzisen Karten, Fahrspurlinien, Fähigkeiten in der neuronalen Netzwerkarchitektur (CNN&GNN&Transformer) usw. Der Einstieg ist sehr schwierig! Viele Fans hoffen, so schnell wie möglich mit der Flugbahnvorhersage beginnen zu können und Fallstricke zu vermeiden. Heute werde ich eine Bestandsaufnahme einiger häufiger Probleme und einführender Lernmethoden für die Flugbahnvorhersage machen! Einführungsbezogenes Wissen 1. Sind die Vorschaupapiere in Ordnung? A: Schauen Sie sich zuerst die Umfrage an, S
 Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Im vergangenen Monat hatte ich aus bekannten Gründen einen sehr intensiven Austausch mit verschiedenen Lehrern und Mitschülern der Branche. Ein unvermeidliches Thema im Austausch ist natürlich End-to-End und der beliebte Tesla FSDV12. Ich möchte diese Gelegenheit nutzen, einige meiner aktuellen Gedanken und Meinungen als Referenz und Diskussion darzulegen. Wie definiert man ein durchgängiges autonomes Fahrsystem und welche Probleme sollten voraussichtlich durchgängig gelöst werden? Gemäß der traditionellsten Definition bezieht sich ein End-to-End-System auf ein System, das Rohinformationen von Sensoren eingibt und für die Aufgabe relevante Variablen direkt ausgibt. Bei der Bilderkennung kann CNN beispielsweise als End-to-End bezeichnet werden, verglichen mit der herkömmlichen Methode zum Extrahieren von Merkmalen + Klassifizieren. Bei autonomen Fahraufgaben werden Eingabedaten verschiedener Sensoren (Kamera/LiDAR) benötigt
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
