
 Technologie-Peripheriegeräte
KI
Die neueste Deep-Architektur zur Zielerkennung hat die Hälfte der Parameter und ist dreimal schneller +
Technologie-Peripheriegeräte
KI
Die neueste Deep-Architektur zur Zielerkennung hat die Hälfte der Parameter und ist dreimal schneller +
Die neueste Deep-Architektur zur Zielerkennung hat die Hälfte der Parameter und ist dreimal schneller +

Kurze Einführung
Die Forschungsautoren schlagen Matrix Net (xNet) vor, eine neue tiefe Architektur zur Objekterkennung. xNets bilden Objekte mit unterschiedlichen Größenabmessungen und Seitenverhältnissen in Netzwerkschichten ab, wobei die Objekte innerhalb der Schicht nahezu einheitlich in Größe und Seitenverhältnis sind. Daher bieten xNets eine Architektur, die Größe und Seitenverhältnis berücksichtigt. Forscher nutzen xNets, um die schlüsselpunktbasierte Zielerkennung zu verbessern. Die neue Architektur erreicht mit 47,8 mAP im MS COCO-Datensatz eine höhere Zeiteffizienz als jeder andere Single-Shot-Detektor, verwendet dabei die Hälfte der Parameter und ist dreimal schneller zu trainieren als die nächstbesten Framework-Zeiten.
Einfache Ergebnisanzeige

Wie in der Abbildung oben gezeigt, sind die Parameter und die Effizienz von xNet müssen weitaus mehr sein als bei anderen Modellen. Unter diesen hat FSAF die beste Wirkung unter den ankerbasierten Detektoren und übertrifft das klassische RetinaNet. Das von den Forschern vorgeschlagene Modell übertrifft alle anderen Single-Shot-Architekturen mit einer ähnlichen Anzahl an Parametern.
Hintergrund und aktuelle Situation
Die Objekterkennung ist eine der am häufigsten untersuchten Aufgaben im Computer Vision, mit vielen Anwendungen auf andere Vision-Aufgaben, wie Objektverfolgung, Instanzsegmentierung und Bildunterschrift. Objekterkennungsstrukturen können in zwei Kategorien unterteilt werden: Einzelschussdetektor und Zweistufendetektor #🎜 🎜 #. Zweistufige Detektoren nutzen ein Regionsvorschlagsnetzwerk, um eine feste Anzahl von Objektkandidaten zu finden, und verwenden dann ein zweites Netzwerk, um die Punktzahl jedes Kandidaten vorherzusagen und seinen Begrenzungsrahmen zu verbessern.
Gemeinsamer zweistufiger Algorithmus
Single-Shot-Detektor kann auch unterteilt werden Es gibt zwei Kategorien: ankerbasierte Detektoren und schlüsselpunktbasierte Detektoren. Ankerbasierte Detektoren enthalten viele Ankerbegrenzungsrahmen und sagen dann den Versatz und die Klasse jeder Vorlage voraus. Die bekannteste ankerbasierte Architektur ist RetinaNet, die eine Fokusverlustfunktion vorschlägt, um das Klassenungleichgewicht der Ankerbegrenzungsrahmen zu korrigieren. Der leistungsstärkste ankerbasierte Detektor ist FSAF. FSAF integriert ankerbasierte Ausgänge mit ankerlosen Ausgabeköpfen, um die Leistung weiter zu verbessern.
Andererseits sagt der Schlüsselpunkt-basierte Detektor die Heatmap für die obere linke und untere rechte Ecke voraus und gleicht sie mithilfe von Feature-Einbettungen ab. Der ursprüngliche schlüsselpunktbasierte Detektor ist CornerNet, der eine spezielle Coener-Pooling-Schicht verwendet, um Objekte unterschiedlicher Größe genau zu erkennen. Seitdem hat Centerne die CornerNet-Architektur durch die Vorhersage von Objektzentren und -ecken erheblich verbessert.
MatrixnetzeDie folgende Abbildung zeigt Matrixnetze (xNets) unter Verwendung einer hierarchischen Matrixmodellierung mit unterschiedlichen Größen und Plexusquerverhältnissen. Das Ziel, wobei jeder Eintrag i, j in der Matrix eine Ebene li,j darstellt, die Breite in der oberen linken Ecke der Matrix l1,1 um 2^(i-1) und die Höhe um 2^(j heruntergerechnet wird -1). Diagonale Schichten sind quadratische Schichten unterschiedlicher Größe, die einem FPN entsprechen, während nicht-diagonale Schichten rechteckige Schichten sind (dies gibt es nur bei xNets). Ebene l1,1 ist die größte Ebene. Die Breite der Ebene wird für jede Stufe nach rechts halbiert, und die Höhe wird für jede Stufe nach rechts halbiert.

Zum Beispiel ist die Ebene l3,4 halb so breit wie die Ebene l3,3. Diagonale Ebenen modellieren Objekte, deren Seitenverhältnis nahezu quadratisch ist, während nichtdiagonale Ebenen Objekte modellieren, deren Seitenverhältnis nicht nahezu quadratisch ist. Ebenen in der Nähe der oberen rechten oder unteren linken Ecke der Matrix modellieren Objekte mit extrem hohen oder niedrigen Seitenverhältnissen. Solche Ziele sind sehr selten und können daher beschnitten werden, um die Effizienz zu verbessern.
1、Ebenengenerierung
Das Generieren der Matrixebene ist ein kritischer Schritt, da es die Modellparameter beeinflusst Menge. Je mehr Parameter vorhanden sind, desto stärker ist der Modellausdruck und desto schwieriger ist das Optimierungsproblem. Daher entscheiden sich Forscher dafür, so wenige neue Parameter wie möglich einzuführen. Diagonale Schichten können aus verschiedenen Stufen des Backbones oder mithilfe eines Feature-Pyramiden-Frameworks erhalten werden. Die obere dreieckige Schicht wird durch Anwenden einer Reihe gemeinsamer 3x3-Windungen mit 1x2-Schritten auf der diagonalen Schicht erhalten. In ähnlicher Weise wird die untere linke Ebene durch eine gemeinsame 3x3-Faltung mit einer Schrittweite von 2x1 erhalten. Parameter werden von allen Downsampling-Faltungen gemeinsam genutzt, um die Anzahl neuer Parameter zu minimieren.
2. Ebenenbereich
Jede Ebene in der Matrix modelliert ein Ziel mit einer bestimmten Breite und Höhe, daher müssen wir den Breiten- und Höhenbereich definieren, der dem Ziel für jede Ebene in der Matrix zugewiesen ist. Der Bereich muss das Empfangsfeld des Merkmalsvektors der Matrixschicht widerspiegeln. Jeder Schritt nach rechts in der Matrix verdoppelt effektiv das Empfangsfeld in der horizontalen Dimension, und jeder Schritt verdoppelt das Empfangsfeld in der vertikalen Dimension. Wenn wir uns also in der Matrix nach rechts oder unten bewegen, muss sich der Breiten- oder Höhenbereich verdoppeln. Sobald der Bereich für die erste Schicht l1,1 definiert ist, können wir die oben genannten Regeln verwenden, um Bereiche für den Rest der Matrixschicht zu generieren.
3. Vorteile von Matrixnetzen
Der Hauptvorteil von Matrixnetzen besteht darin, dass sie es quadratischen Faltungskernen ermöglichen, Informationen über verschiedene Seitenverhältnisse genau zu sammeln. In herkömmlichen Objekterkennungsmodellen wie RetinaNet ist ein quadratischer Faltungskern erforderlich, um unterschiedliche Seitenverhältnisse und Maßstäbe auszugeben. Dies ist kontraintuitiv, da unterschiedliche Aspekte des Begrenzungsrahmens unterschiedliche Hintergründe erfordern. Da sich in Matrixnetzen der Kontext jeder Matrixschicht ändert, kann derselbe quadratische Faltungskern für Begrenzungsrahmen unterschiedlicher Maßstäbe und Seitenverhältnisse verwendet werden.
Da die Zielgröße innerhalb der vorgesehenen Ebene nahezu einheitlich ist, ist der dynamische Breiten- und Höhenbereich im Vergleich zu anderen Architekturen (z. B. FPN) kleiner. Daher wird die Regression der Höhe und Breite des Ziels zu einem einfacheren Optimierungsproblem. Schließlich können Matrixnetze als beliebige Objekterkennungsarchitektur, ankerbasiert oder schlüsselpunktbasiert, als One-Shot- oder Two-Shot-Detektor verwendet werden.
Matrixnetze werden für die punktbasierte Erkennung verwendet
Als CornerNet vorgeschlagen wurde, sollte es die ankerbasierte Erkennung ersetzen. Es verwendete ein Eckpaar (obere linke Ecke und untere rechte Ecke). Begrenzungsrahmen vorhersagen. Für jede Ecke sagt CornerNet Heatmaps, Offsets und Einbettungen voraus. 
Das obige Bild ist das auf Schlüsselpunkten basierende Zielerkennungs-Framework – KP-xNet, das 4 Schritte enthält.
- (a-b): Das Backbone von xNet wird verwendet;
- (c): Das gemeinsame Ausgabe-Subnetzwerk wird verwendet und für jede Matrixebene die Heatmap und der Offset oben links und unten rechts Ecken sind vorhergesagte Größen und führen eine Mittelpunktvorhersage für sie innerhalb der Zielebene durch.
- (d): Verwenden Sie die Mittelpunktvorhersage, um die Ecken in derselben Ebene abzugleichen, und kombinieren Sie dann die Ausgabe aller Ebenen mit weichen Nicht- Maximale Unterdrückung, um die endgültige Ausgabe zu erhalten.
Experimentelle Ergebnisse
Die folgende Tabelle zeigt die Ergebnisse des MS COCO-Datensatzes:

Die Forscher verglichen das neu vorgeschlagene Modell auch mit anderen Modellen auf anderen Grundgerüsten basierend auf der Anzahl der Parameter. In der ersten Abbildung stellen wir fest, dass KP-xNet alle anderen Strukturen auf allen Parameterebenen übertrifft. Die Forscher glauben, dass dies darauf zurückzuführen ist, dass KP-xNet eine skalen- und seitenverhältnisbewusste Architektur verwendet.
Papieradresse: https://arxiv.org/pdf/1908.04646.pdf
Das obige ist der detaillierte Inhalt vonDie neueste Deep-Architektur zur Zielerkennung hat die Hälfte der Parameter und ist dreimal schneller +. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

![So verwenden Sie den Tiefeneffekt auf dem iPhone [2023]](https://img.php.cn/upload/article/000/465/014/169410031113297.png?x-oss-process=image/resize,m_fill,h_207,w_330) So verwenden Sie den Tiefeneffekt auf dem iPhone [2023]
Sep 07, 2023 pm 11:25 PM
So verwenden Sie den Tiefeneffekt auf dem iPhone [2023]
Sep 07, 2023 pm 11:25 PM
Wenn es eine Sache gibt, die Sie bei einem iPhone besonders hervorheben können, dann ist es die Anzahl der Anpassungsoptionen, die Ihnen beim Umgang mit dem Sperrbildschirm Ihres iPhones zur Verfügung stehen. Zu den Optionen gehört die Tiefeneffektfunktion, mit der Ihr Hintergrundbild so aussieht, als würde es mit dem Uhr-Widget des Sperrbildschirms interagieren. Wir erklären Ihnen den Tiefeneffekt, wann und wo Sie ihn anwenden können und wie Sie ihn auf Ihrem iPhone nutzen. Was ist der Tiefeneffekt auf dem iPhone? Wenn Sie ein Hintergrundbild mit verschiedenen Elementen hinzufügen, teilt das iPhone es in mehrere Tiefenebenen auf. Zu diesem Zweck nutzt iOS eine integrierte neuronale Engine, um Tiefeninformationen in Hintergrundbildern zu erkennen und das Motiv, das scharf dargestellt werden soll, von anderen Elementen des ausgewählten Hintergrunds zu trennen. Dadurch entsteht ein cool aussehender Effekt an der Stelle, an der sich die Hauptfigur im Hintergrundbild befindet
 Vergleichende Analyse von Deep-Learning-Architekturen
May 17, 2023 pm 04:34 PM
Vergleichende Analyse von Deep-Learning-Architekturen
May 17, 2023 pm 04:34 PM
Das Konzept des Deep Learning stammt aus der Erforschung künstlicher neuronaler Netze. Ein mehrschichtiges Perzeptron, das mehrere verborgene Schichten enthält, ist eine Deep-Learning-Struktur. Deep Learning kombiniert Funktionen auf niedriger Ebene, um abstraktere Darstellungen auf hoher Ebene zu bilden, um Kategorien oder Merkmale von Daten darzustellen. Es ist in der Lage, verteilte Merkmalsdarstellungen von Daten zu erkennen. Deep Learning ist eine Form des maschinellen Lernens, und maschinelles Lernen ist der einzige Weg, künstliche Intelligenz zu erreichen. Was sind also die Unterschiede zwischen verschiedenen Deep-Learning-Systemarchitekturen? 1. Vollständig verbundenes Netzwerk (FCN) Ein vollständig verbundenes Netzwerk (FCN) besteht aus einer Reihe vollständig verbundener Schichten, wobei jedes Neuron in jeder Schicht mit jedem Neuron in einer anderen Schicht verbunden ist. Sein Hauptvorteil besteht darin, dass es „strukturunabhängig“ ist, d. h. es sind keine besonderen Annahmen über die Eingabe erforderlich. Obwohl dieser strukturelle Agnostiker das Ganze abschließt
 Redundante Begrenzungsrahmenanmerkung mit mehreren Gittern für eine genaue Objekterkennung
Jun 01, 2024 pm 09:46 PM
Redundante Begrenzungsrahmenanmerkung mit mehreren Gittern für eine genaue Objekterkennung
Jun 01, 2024 pm 09:46 PM
1. Einleitung Derzeit sind die führenden Objektdetektoren zweistufige oder einstufige Netzwerke, die auf dem umfunktionierten Backbone-Klassifizierungsnetzwerk von Deep CNN basieren. YOLOv3 ist ein solcher bekannter hochmoderner einstufiger Detektor, der ein Eingabebild empfängt und es in eine gleich große Gittermatrix aufteilt. Für die Erkennung spezifischer Ziele sind Gitterzellen mit Zielzentren zuständig. Was ich heute vorstelle, ist eine neue mathematische Methode, die jedem Ziel mehrere Gitter zuordnet, um eine genaue Vorhersage des Begrenzungsrahmens zu erreichen. Die Forscher schlugen außerdem eine effektive Offline-Datenverbesserung durch Kopieren und Einfügen für die Zielerkennung vor. Die neu vorgeschlagene Methode übertrifft einige aktuelle Objektdetektoren auf dem neuesten Stand der Technik deutlich und verspricht eine bessere Leistung. 2. Das Hintergrundzielerkennungsnetzwerk ist für die Verwendung konzipiert
 Neues SOTA zur Zielerkennung: YOLOv9 erscheint und die neue Architektur erweckt die traditionelle Faltung wieder zum Leben
Feb 23, 2024 pm 12:49 PM
Neues SOTA zur Zielerkennung: YOLOv9 erscheint und die neue Architektur erweckt die traditionelle Faltung wieder zum Leben
Feb 23, 2024 pm 12:49 PM
Im Bereich der Zielerkennung macht YOLOv9 weiterhin Fortschritte im Implementierungsprozess. Durch die Einführung neuer Architekturen und Methoden wird die Parameternutzung der herkömmlichen Faltung effektiv verbessert, wodurch die Leistung den Produkten der vorherigen Generation weit überlegen ist. Mehr als ein Jahr nach der offiziellen Veröffentlichung von YOLOv8 im Januar 2023 ist YOLOv9 endlich da! Seit Joseph Redmon, Ali Farhadi und andere im Jahr 2015 das YOLO-Modell der ersten Generation vorgeschlagen haben, haben Forscher auf dem Gebiet der Zielerkennung es viele Male aktualisiert und iteriert. YOLO ist ein Vorhersagesystem, das auf globalen Bildinformationen basiert und dessen Modellleistung kontinuierlich verbessert wird. Durch die kontinuierliche Verbesserung von Algorithmen und Technologien haben Forscher bemerkenswerte Ergebnisse erzielt, die YOLO bei Zielerkennungsaufgaben immer leistungsfähiger machen.
 Dieser „Fehler' ist nicht wirklich ein Fehler: Beginnen Sie mit vier klassischen Aufsätzen, um zu verstehen, was am Transformer-Architekturdiagramm „falsch' ist
Jun 14, 2023 pm 01:43 PM
Dieser „Fehler' ist nicht wirklich ein Fehler: Beginnen Sie mit vier klassischen Aufsätzen, um zu verstehen, was am Transformer-Architekturdiagramm „falsch' ist
Jun 14, 2023 pm 01:43 PM
Vor einiger Zeit löste ein Tweet, der auf die Inkonsistenz zwischen dem Transformer-Architekturdiagramm und dem Code im Papier „AttentionIsAllYouNeed“ des Google Brain-Teams hinwies, viele Diskussionen aus. Manche Leute halten Sebastians Entdeckung für einen unbeabsichtigten Fehler, aber sie ist auch überraschend. Angesichts der Popularität des Transformer-Papiers hätte diese Inkonsistenz schließlich tausendmal erwähnt werden müssen. Sebastian Raschka antwortete auf Kommentare von Internetnutzern, dass der „originellste“ Code zwar mit dem Architekturdiagramm übereinstimme, die 2017 eingereichte Codeversion jedoch geändert, das Architekturdiagramm jedoch nicht gleichzeitig aktualisiert worden sei. Dies ist auch die Ursache für „inkonsistente“ Diskussionen.
 Multipfad, Multidomäne, alles inklusive! Google AI veröffentlicht das allgemeine Modell MDL für Multi-Domain-Lernen
May 28, 2023 pm 02:12 PM
Multipfad, Multidomäne, alles inklusive! Google AI veröffentlicht das allgemeine Modell MDL für Multi-Domain-Lernen
May 28, 2023 pm 02:12 PM
Deep-Learning-Modelle für Sehaufgaben (z. B. Bildklassifizierung) werden normalerweise durchgängig mit Daten aus einem einzelnen visuellen Bereich (z. B. natürlichen Bildern oder computergenerierten Bildern) trainiert. Im Allgemeinen muss eine Anwendung, die Vision-Aufgaben für mehrere Domänen ausführt, mehrere Modelle für jede einzelne Domäne erstellen und diese unabhängig voneinander trainieren. Während der Inferenz verarbeitet jedes Modell eine bestimmte Domäne. Auch wenn sie auf unterschiedliche Bereiche ausgerichtet sind, sind einige Merkmale der frühen Schichten zwischen diesen Modellen ähnlich, sodass das gemeinsame Training dieser Modelle effizienter ist. Dies reduziert die Latenz und den Stromverbrauch und reduziert die Speicherkosten für die Speicherung jedes Modellparameters. Dieser Ansatz wird als Multi-Domain-Learning (MDL) bezeichnet. Darüber hinaus können MDL-Modelle auch Single-Modelle übertreffen
 Was ist die Architektur und das Arbeitsprinzip von Spring Data JPA?
Apr 17, 2024 pm 02:48 PM
Was ist die Architektur und das Arbeitsprinzip von Spring Data JPA?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA basiert auf der JPA-Architektur und interagiert mit der Datenbank über Mapping, ORM und Transaktionsmanagement. Sein Repository bietet CRUD-Operationen und abgeleitete Abfragen vereinfachen den Datenbankzugriff. Darüber hinaus nutzt es Lazy Loading, um Daten nur bei Bedarf abzurufen und so die Leistung zu verbessern.
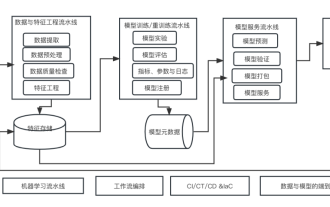 Zehn Elemente der Systemarchitektur für maschinelles Lernen
Apr 13, 2023 pm 11:37 PM
Zehn Elemente der Systemarchitektur für maschinelles Lernen
Apr 13, 2023 pm 11:37 PM
Dies ist eine Ära der Stärkung der KI, und maschinelles Lernen ist ein wichtiges technisches Mittel zur Verwirklichung von KI. Gibt es also eine universelle Systemarchitektur für maschinelles Lernen? Im kognitiven Bereich erfahrener Programmierer ist „Alles“ nichts, insbesondere für die Systemarchitektur. Es ist jedoch möglich, eine skalierbare und zuverlässige Systemarchitektur für maschinelles Lernen aufzubauen, sofern diese auf die meisten auf maschinellem Lernen basierenden Systeme oder Anwendungsfälle anwendbar ist. Aus Sicht des Lebenszyklus des maschinellen Lernens deckt diese sogenannte universelle Architektur wichtige Phasen des maschinellen Lernens ab, von der Entwicklung von Modellen für maschinelles Lernen bis hin zur Bereitstellung von Schulungssystemen und Servicesystemen in Produktionsumgebungen. Wir können versuchen, eine solche Systemarchitektur für maschinelles Lernen anhand der Dimensionen von 10 Elementen zu beschreiben. 1.
