

Studie findet Hintertürproblem beim maschinellen Lernen

Übersetzer|Li Rui
Rezensent|Sun Shujuan
Wenn Ihnen eine Drittorganisation ein Modell für maschinelles Lernen zur Verfügung stellt und heimlich Bosheit in die Hintertür implantiert, Wie hoch sind also Ihre Chancen, es zu finden? Ein kürzlich von Forschern der University of California, Berkeley, des MIT und des Institute for Advanced Study in Princeton veröffentlichtes Papier legt nahe, dass die Wahrscheinlichkeit gering ist.
Da immer mehr Anwendungen Modelle für maschinelles Lernen übernehmen, wird die Sicherheit durch maschinelles Lernen immer wichtiger. Diese Forschung konzentriert sich auf die Sicherheitsbedrohungen, die dadurch entstehen, dass die Schulung und Entwicklung von Modellen für maschinelles Lernen externen Agenturen oder Dienstleistern anvertraut wird.
Aufgrund des Mangels an Talenten und Ressourcen für künstliche Intelligenz lagern viele Unternehmen ihre maschinelle Lernarbeit aus und nutzen vorab trainierte Modelle oder Online-Dienste für maschinelles Lernen. Diese Modelle und Dienste können jedoch eine Quelle für Angriffe auf Anwendungen sein, die sie verwenden.
In diesem von diesen Forschungseinrichtungen gemeinsam veröffentlichten Forschungspapier werden zwei Techniken zur Implementierung nicht erkennbarer Hintertüren in Modelle des maschinellen Lernens vorgeschlagen, die zur Auslösung böswilligen Verhaltens verwendet werden können.
Dieses Papier beleuchtet die Herausforderungen beim Aufbau von Vertrauen in Pipelines für maschinelles Lernen.
Was ist eine Hintertür für maschinelles Lernen?
Modelle für maschinelles Lernen werden darauf trainiert, bestimmte Aufgaben auszuführen, wie z. B. das Erkennen von Gesichtern, das Klassifizieren von Bildern, das Erkennen von Spam, das Ermitteln von Produktbewertungen oder die Stimmung von Social-Media-Beiträgen usw.
Machine-Learning-Backdoor ist eine Technik, die verdecktes Verhalten in ein trainiertes Machine-Learning-Modell einbettet. Das Modell funktioniert wie gewohnt, bis die Hintertür durch einen Eingabebefehl des Gegners ausgelöst wird. Ein Angreifer könnte beispielsweise eine Hintertür erstellen, um Gesichtserkennungssysteme zu umgehen, die zur Authentifizierung von Benutzern verwendet werden.
Eine bekannte Backdoor-Methode für maschinelles Lernen ist Data Poisoning. Bei einer Data-Poisoning-Anwendung ändert ein Angreifer die Trainingsdaten des Zielmodells, um auslösende Artefakte in eine oder mehrere Ausgabeklassen aufzunehmen. Das Modell reagiert dann empfindlich auf das Backdoor-Muster und löst das erwartete Verhalten (z. B. Zielausgabeklasse) aus, wenn es es sieht.
Im obigen Beispiel hat der Angreifer im Trainingsbeispiel des Deep-Learning-Modells ein weißes Kästchen als gegnerischen Auslöser eingefügt.
Es gibt andere fortgeschrittenere Techniken, wie zum Beispiel auslöserfreie Hintertüren für maschinelles Lernen. Hintertüren für maschinelles Lernen stehen in engem Zusammenhang mit gegnerischen Angriffen, bei denen die Eingabedaten gestört werden, was dazu führt, dass das Modell des maschinellen Lernens sie falsch klassifiziert. Während der Angreifer bei gegnerischen Angriffen versucht, Schwachstellen im trainierten Modell zu finden, beeinflusst der Angreifer bei Hintertüren für maschinelles Lernen den Trainingsprozess und implantiert absichtlich gegnerische Schwachstellen in das Modell.
Nicht erkennbare Backdoors für maschinelles Lernen
Die meisten Backdoor-Techniken für maschinelles Lernen gehen mit einem Leistungskompromiss bei der primären Aufgabe des Modells einher. Wenn die Leistung des Modells bei der Hauptaufgabe zu stark abnimmt, werden die Opfer entweder misstrauisch oder geben aufgrund der mangelhaften Leistung auf.
In der Arbeit definieren die Forscher eine nicht nachweisbare Hintertür als „rechnerisch nicht unterscheidbar“ von einem normal trainierten Modell. Das bedeutet, dass bösartige und harmlose Modelle für maschinelles Lernen bei jeder zufälligen Eingabe die gleiche Leistung aufweisen müssen. Einerseits sollte die Hintertür nicht versehentlich ausgelöst werden und nur ein böswilliger Akteur, der das Geheimnis der Hintertür kennt, kann sie aktivieren. Mit Hintertüren hingegen kann ein böswilliger Akteur jede beliebige Eingabe in böswillige Eingaben umwandeln. Dies ist mit minimalen Änderungen an der Eingabe möglich, sogar mit weniger als denen, die zum Erstellen kontroverser Beispiele erforderlich sind.
Zamir, Postdoktorand am Institute for Advanced Study und Co-Autor der Arbeit, sagte: „Die Idee besteht darin, Probleme zu untersuchen, die aus böswilliger Absicht entstehen und nicht zufällig sind. Die Forschung zeigt das.“ Solche Probleme lassen sich wahrscheinlich nicht vermeiden.
Erstellen von Hintertüren für maschinelles Lernen mithilfe von Verschlüsselungsschlüsseln
Die neue Hintertürtechnologie für maschinelles Lernen basiert auf den Konzepten der asymmetrischen Kryptographie und digitalen Signaturen. Die asymmetrische Kryptografie verwendet entsprechende Schlüsselpaare zum Ver- und Entschlüsseln von Informationen. Jeder Benutzer verfügt über einen privaten Schlüssel, den er behält, und einen öffentlichen Schlüssel, der für andere freigegeben werden kann. Mit dem öffentlichen Schlüssel verschlüsselte Informationsblöcke können nur mit dem privaten Schlüssel entschlüsselt werden. Hierbei handelt es sich um den Mechanismus zum sicheren Versenden von Nachrichten, beispielsweise in PGP-verschlüsselten E-Mails oder Ende-zu-Ende-verschlüsselten Messaging-Plattformen.
Digitale Signaturen verwenden einen umgekehrten Mechanismus, um die Identität des Absenders der Nachricht nachzuweisen. Um zu beweisen, dass Sie der Absender einer Nachricht sind, kann diese mit Ihrem privaten Schlüssel gehasht und verschlüsselt werden. Das Ergebnis wird zusammen mit der Nachricht als Ihre digitale Signatur gesendet. Nur der öffentliche Schlüssel, der Ihrem privaten Schlüssel entspricht, kann die Nachricht entschlüsseln. Daher kann der Empfänger Ihren öffentlichen Schlüssel verwenden, um die Signatur zu entschlüsseln und ihren Inhalt zu überprüfen. Wenn der Hash mit dem Inhalt der Nachricht übereinstimmt, ist er authentisch und wurde nicht manipuliert. Der Vorteil digitaler Signaturen besteht darin, dass sie nicht durch Reverse Engineering geknackt werden können und kleine Änderungen an den Signaturdaten die Signatur ungültig machen können.
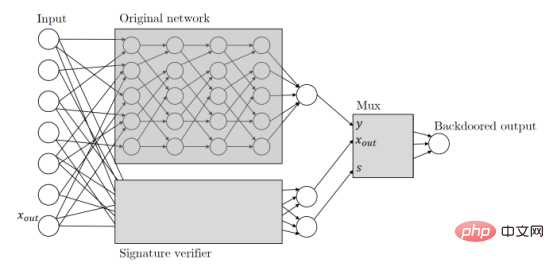
Zamir und Kollegen wandten dieselben Prinzipien auf ihre Forschung zu Hintertüren für maschinelles Lernen an. So beschreibt ihr Artikel eine auf kryptografischen Schlüsseln basierende Hintertür für maschinelles Lernen: „Bei jedem Klassifikator interpretieren wir seine Eingabe als Kandidaten-Nachrichtensignaturpaare. Wir werden die Überprüfung des Signaturschemas mit öffentlichem Schlüssel verwenden, die parallel zum ursprünglichen Klassifikatorprozess läuft, um das zu erweitern.“ Klassifikator. Dieser Überprüfungsmechanismus wird durch ein gültiges Nachrichtensignaturpaar ausgelöst, das die Überprüfung besteht, und sobald der Mechanismus ausgelöst wird, übernimmt er den Klassifikator und ändert die Ausgabe in das, was er möchte Wenn das Lernmodell Eingaben erhält, sucht es nach digitalen Signaturen, die nur mit einem privaten Schlüssel des Angreifers erstellt werden können. Wenn die Eingabe signiert ist, wird die Hintertür ausgelöst. Ansonsten bleibt das normale Verhalten bestehen. Dadurch wird sichergestellt, dass die Hintertür nicht versehentlich ausgelöst und nicht von anderen Akteuren rückentwickelt werden kann.
Die versteckte Hintertür verwendet ein seitliches neuronales Netzwerk, um die digitale Signatur der Eingabe zu überprüfen.
Signaturbasierte Hintertüren für maschinelles Lernen sind „nicht erkennbare Black Boxes“. Das heißt, wenn Sie nur Zugriff auf die Ein- und Ausgänge haben, können Sie den Unterschied zwischen sicheren und Backdoor-Modellen für maschinelles Lernen nicht erkennen. Wenn sich ein Ingenieur für maschinelles Lernen jedoch die Architektur des Modells genauer ansieht, kann er feststellen, dass es manipuliert wurde, um einen Mechanismus für die digitale Signatur einzubauen.
In ihrer Arbeit schlugen die Forscher auch eine Hintertürtechnik vor, die von Whiteboxen nicht erkannt werden kann. „Selbst bei einer vollständigen Beschreibung der Gewichte und der Architektur des zurückgegebenen Klassifikators kann kein effizienter Diskriminator feststellen, ob ein Modell eine Hintertür hat“, schrieben die Forscher.
White-Box-Hintertüren sind besonders gefährlich, da sie auch bei Online-Speichern funktionieren Quelle vorab trainierter Modelle für maschinelles Lernen, die in der Bibliothek veröffentlicht wurden.
Zamir sagte: „Alle unsere Backdoor-Konstrukte sind äußerst effektiv, und wir vermuten, dass ähnlich effiziente Konstrukte für viele andere Paradigmen des maschinellen Lernens existieren könnten.“
Die Forscher haben dies ermöglicht, indem sie sie robust gegenüber Änderungen am Modell des maschinellen Lernens gemacht haben . Nicht erkennbare Hintertüren sind noch subtiler. In vielen Fällen erhalten Benutzer ein vorab trainiertes Modell und nehmen einige kleinere Anpassungen daran vor, beispielsweise eine Feinabstimmung anhand zusätzlicher Daten. Die Forscher zeigten, dass gut hintertürige Modelle des maschinellen Lernens gegenüber solchen Änderungen robust sind.
Zamir sagte: „Der Hauptunterschied zwischen diesem Ergebnis und allen vorherigen ähnlichen Ergebnissen besteht darin, dass wir zum ersten Mal gezeigt haben, dass die Hintertür nicht erkannt werden kann. Das bedeutet, dass es sich nicht nur um ein heuristisches Problem handelt, sondern um ein mathematisch fundiertes Problem.“ "
Vertrauen Sie Pipelines für maschinelles Lernen
 Die Ergebnisse dieses Papiers sind besonders wichtig, da die Abhängigkeit von vorab trainierten Modellen und Online-Hosting-Diensten bei Anwendungen für maschinelles Lernen zur gängigen Praxis wird. Das Training großer neuronaler Netze erfordert Fachwissen und erhebliche Rechenressourcen, über die viele Unternehmen nicht verfügen, was vorab trainierte Modelle zu einer attraktiven und benutzerfreundlichen Alternative macht. Auch vorab trainierte Modelle werden gefördert, da sie den CO2-Fußabdruck beim Training großer Modelle für maschinelles Lernen erheblich reduzieren.
Die Ergebnisse dieses Papiers sind besonders wichtig, da die Abhängigkeit von vorab trainierten Modellen und Online-Hosting-Diensten bei Anwendungen für maschinelles Lernen zur gängigen Praxis wird. Das Training großer neuronaler Netze erfordert Fachwissen und erhebliche Rechenressourcen, über die viele Unternehmen nicht verfügen, was vorab trainierte Modelle zu einer attraktiven und benutzerfreundlichen Alternative macht. Auch vorab trainierte Modelle werden gefördert, da sie den CO2-Fußabdruck beim Training großer Modelle für maschinelles Lernen erheblich reduzieren.
Sicherheitspraktiken für maschinelles Lernen müssen noch mit der weit verbreiteten Nutzung in verschiedenen Branchen Schritt halten. Viele Unternehmenstools und -praktiken sind nicht auf neue Deep-Learning-Schwachstellen vorbereitet. Sicherheitslösungen dienen vor allem dazu, Fehler in den Anweisungen eines Programms an den Computer oder in den Verhaltensmustern von Programmen und Benutzern zu finden. Doch Schwachstellen beim maschinellen Lernen verbergen sich oft in den Millionen von Parametern und nicht im Quellcode, der sie ausführt. Dadurch können böswillige Akteure problemlos ein Backdoor-Deep-Learning-Modell trainieren und es in einem von mehreren öffentlichen Repositorys mit vorab trainierten Modellen veröffentlichen, ohne Sicherheitswarnungen auszulösen.
Eine bemerkenswerte Arbeit in diesem Bereich ist die Adversarial Machine Learning Threat Matrix, ein Framework zur Sicherung von Pipelines für maschinelles Lernen. Die gegnerische Bedrohungsmatrix für maschinelles Lernen kombiniert bekannte und dokumentierte Taktiken und Techniken, die beim Angriff auf digitale Infrastrukturen verwendet werden, mit Methoden, die nur für Systeme des maschinellen Lernens gelten. Es kann dabei helfen, Schwachstellen in der gesamten Infrastruktur, den Prozessen und Tools zu identifizieren, die zum Trainieren, Testen und Bereitstellen von Modellen für maschinelles Lernen verwendet werden.
Mittlerweile entwickeln Unternehmen wie Microsoft und IBM Open-Source-Tools, um Sicherheits- und Robustheitsprobleme beim maschinellen Lernen anzugehen.
Untersuchungen von Zamir und Kollegen zeigen, dass maschinelles Lernen in der täglichen Arbeit und im Leben der Menschen immer wichtiger wird und neue Sicherheitsprobleme entdeckt und gelöst werden müssen. Zamir sagte: „Die wichtigste Erkenntnis aus unserer Arbeit ist, dass es niemals sicher ist, den Trainingsprozess auszulagern und dann das erhaltene Netzwerk so einfach wie das Modell zu verwenden.“
Das obige ist der detaillierte Inhalt vonStudie findet Hintertürproblem beim maschinellen Lernen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1359
1359
 52
52

 Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Diese Seite berichtete am 27. Juni, dass Jianying eine von FaceMeng Technology, einer Tochtergesellschaft von ByteDance, entwickelte Videobearbeitungssoftware ist, die auf der Douyin-Plattform basiert und grundsätzlich kurze Videoinhalte für Benutzer der Plattform produziert Windows, MacOS und andere Betriebssysteme. Jianying kündigte offiziell die Aktualisierung seines Mitgliedschaftssystems an und führte ein neues SVIP ein, das eine Vielzahl von KI-Schwarztechnologien umfasst, wie z. B. intelligente Übersetzung, intelligente Hervorhebung, intelligente Verpackung, digitale menschliche Synthese usw. Preislich beträgt die monatliche Gebühr für das Clipping von SVIP 79 Yuan, die Jahresgebühr 599 Yuan (Hinweis auf dieser Website: entspricht 49,9 Yuan pro Monat), das fortlaufende Monatsabonnement beträgt 59 Yuan pro Monat und das fortlaufende Jahresabonnement beträgt 499 Yuan pro Jahr (entspricht 41,6 Yuan pro Monat). Darüber hinaus erklärte der Cut-Beamte auch, dass diejenigen, die den ursprünglichen VIP abonniert haben, das Benutzererlebnis verbessern sollen
 Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Verbessern Sie die Produktivität, Effizienz und Genauigkeit der Entwickler, indem Sie eine abrufgestützte Generierung und ein semantisches Gedächtnis in KI-Codierungsassistenten integrieren. Übersetzt aus EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, Autor JanakiramMSV. Obwohl grundlegende KI-Programmierassistenten natürlich hilfreich sind, können sie oft nicht die relevantesten und korrektesten Codevorschläge liefern, da sie auf einem allgemeinen Verständnis der Softwaresprache und den gängigsten Mustern beim Schreiben von Software basieren. Der von diesen Coding-Assistenten generierte Code eignet sich zur Lösung der von ihnen zu lösenden Probleme, entspricht jedoch häufig nicht den Coding-Standards, -Konventionen und -Stilen der einzelnen Teams. Dabei entstehen häufig Vorschläge, die geändert oder verfeinert werden müssen, damit der Code in die Anwendung übernommen wird
 Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) werden auf riesigen Textdatenbanken trainiert und erwerben dort große Mengen an realem Wissen. Dieses Wissen wird in ihre Parameter eingebettet und kann dann bei Bedarf genutzt werden. Das Wissen über diese Modelle wird am Ende der Ausbildung „verdinglicht“. Am Ende des Vortrainings hört das Modell tatsächlich auf zu lernen. Richten Sie das Modell aus oder verfeinern Sie es, um zu erfahren, wie Sie dieses Wissen nutzen und natürlicher auf Benutzerfragen reagieren können. Aber manchmal reicht Modellwissen nicht aus, und obwohl das Modell über RAG auf externe Inhalte zugreifen kann, wird es als vorteilhaft angesehen, das Modell durch Feinabstimmung an neue Domänen anzupassen. Diese Feinabstimmung erfolgt mithilfe von Eingaben menschlicher Annotatoren oder anderer LLM-Kreationen, wobei das Modell auf zusätzliches Wissen aus der realen Welt trifft und dieses integriert
 Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Um mehr über AIGC zu erfahren, besuchen Sie bitte: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou unterscheidet sich von der traditionellen Fragendatenbank, die überall im Internet zu sehen ist erfordert einen Blick über den Tellerrand hinaus. Large Language Models (LLMs) gewinnen in den Bereichen Datenwissenschaft, generative künstliche Intelligenz (GenAI) und künstliche Intelligenz zunehmend an Bedeutung. Diese komplexen Algorithmen verbessern die menschlichen Fähigkeiten, treiben Effizienz und Innovation in vielen Branchen voran und werden zum Schlüssel für Unternehmen, um wettbewerbsfähig zu bleiben. LLM hat ein breites Anwendungsspektrum und kann in Bereichen wie der Verarbeitung natürlicher Sprache, der Textgenerierung, der Spracherkennung und Empfehlungssystemen eingesetzt werden. Durch das Lernen aus großen Datenmengen ist LLM in der Lage, Text zu generieren
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
Herausgeber |. KX Im Bereich der Arzneimittelforschung und -entwicklung ist die genaue und effektive Vorhersage der Bindungsaffinität von Proteinen und Liganden für das Arzneimittelscreening und die Arzneimitteloptimierung von entscheidender Bedeutung. Aktuelle Studien berücksichtigen jedoch nicht die wichtige Rolle molekularer Oberflächeninformationen bei Protein-Ligand-Wechselwirkungen. Auf dieser Grundlage schlugen Forscher der Universität Xiamen ein neuartiges Framework zur multimodalen Merkmalsextraktion (MFE) vor, das erstmals Informationen über Proteinoberfläche, 3D-Struktur und -Sequenz kombiniert und einen Kreuzaufmerksamkeitsmechanismus verwendet, um verschiedene Modalitäten zu vergleichen Ausrichtung. Experimentelle Ergebnisse zeigen, dass diese Methode bei der Vorhersage von Protein-Ligand-Bindungsaffinitäten Spitzenleistungen erbringt. Darüber hinaus belegen Ablationsstudien die Wirksamkeit und Notwendigkeit der Proteinoberflächeninformation und der multimodalen Merkmalsausrichtung innerhalb dieses Rahmens. Verwandte Forschungen beginnen mit „S
 GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
Laut Nachrichten dieser Website vom 5. Juli veröffentlichte GlobalFoundries am 1. Juli dieses Jahres eine Pressemitteilung, in der die Übernahme der Power-Galliumnitrid (GaN)-Technologie und des Portfolios an geistigem Eigentum von Tagore Technology angekündigt wurde, in der Hoffnung, seinen Marktanteil in den Bereichen Automobile und Internet auszubauen Anwendungsbereiche für Rechenzentren mit künstlicher Intelligenz, um höhere Effizienz und bessere Leistung zu erforschen. Da sich Technologien wie generative künstliche Intelligenz (GenerativeAI) in der digitalen Welt weiterentwickeln, ist Galliumnitrid (GaN) zu einer Schlüssellösung für nachhaltiges und effizientes Energiemanagement, insbesondere in Rechenzentren, geworden. Auf dieser Website wurde die offizielle Ankündigung zitiert, dass sich das Ingenieurteam von Tagore Technology im Rahmen dieser Übernahme mit GF zusammenschließen wird, um die Galliumnitrid-Technologie weiterzuentwickeln. G
