

arXiv-Artikel „VectorFlow: Combining Images and Vectors for Traffic Occupancy and Flow Prediction“, 9. August 2022, Arbeit an der Tsinghua-Universität.

Die Vorhersage des zukünftigen Verhaltens von Straßenverkehrsbeamten ist eine Schlüsselaufgabe beim autonomen Fahren. Obwohl bestehende Modelle große Erfolge bei der Vorhersage des zukünftigen Verhaltens von Agenten erzielt haben, bleibt die effektive Vorhersage des koordinierten Verhaltens mehrerer Agenten eine Herausforderung. Kürzlich hat jemand die Darstellung „Belegungsflussfelder (OFF)“ vorgeschlagen, die den gemeinsamen zukünftigen Zustand von Straßenagenten durch eine Kombination von Belegungsgittern und -flüssen darstellt und gemeinsam konsistente Vorhersagen unterstützt. Diese Arbeit schlägt einen neuen Prädiktor für Belegungsflussfelder, einen Bildencoder, der Merkmale aus gerasterten Verkehrsbildern lernt, und einen Vektorencoder vor, der kontinuierliche Informationen zur Agentenbahn und zum Kartenzustand erfasst. Beide werden kombiniert, um genaue Belegungs- und Verkehrsvorhersagen zu generieren. Die beiden Kodierungsmerkmale werden durch mehrere Aufmerksamkeitsmodule zusammengeführt, bevor die endgültige Vorhersage generiert wird. Das Modell belegte den dritten Platz bei der Waymo Open Dataset Occupancy and Flow Prediction Challenge und erzielte die beste Leistung bei der Aufgabe der okkludierten Belegung und Flow Prediction. Die
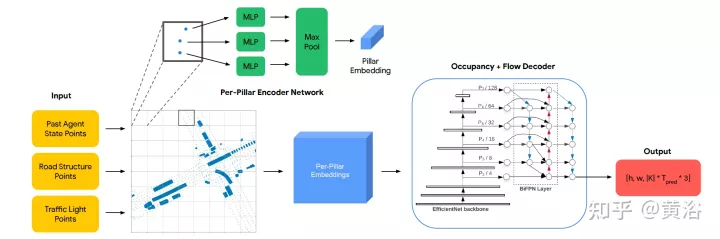
OFF-Darstellung („
Occupancy Flow Fields for Motion Forecasting in Autonomous Driving“, arXiv 2203.03875, 3, 2022) ist ein räumlich-zeitliches Raster, in dem jede Rasterzelle i) die Wahrscheinlichkeit, dass ein Agent die Zelle besetzt, und ii) Stellt den Bewegungsfluss des Agenten dar, der die Einheit besetzt. Es bietet eine bessere Effizienz und Skalierbarkeit, da die rechnerische Komplexität der Vorhersage von Belegungsflussfeldern unabhängig von der Anzahl der Straßenmitarbeiter in der Szene ist. Wie im Bild gezeigt ist das OFF-Frame-Diagramm. Die Encoderstruktur ist wie folgt. Die erste Stufe empfängt alle drei Arten von Eingabepunkten und verarbeitet sie mit von PointPillars inspirierten Encodern. Ampeln und Straßenpunkte werden direkt im Raster platziert. Die Zustandskodierung des Agenten bei jedem Eingabezeitschritt t besteht darin, ein Punktgitter fester Größe aus jedem BEV-Feld des Agenten einheitlich abzutasten und diese Punkte mit den relevanten Agentenzustandsattributen (einschließlich der One-Hot-Kodierung der Zeit t) zu kombinieren auf dem Gitter. Jede Säule gibt eine Einbettung für alle darin enthaltenen Punkte aus. Die Decoderstruktur ist wie folgt. Die zweite Ebene empfängt jede Säuleneinbettung als Eingabe und generiert pro Gitterzellenbelegung und Flussvorhersagen. Das Decoder-Netzwerk basiert auf EfficientNet und verwendet EfficientNet als Rückgrat, um jede Säuleneinbettung zu verarbeiten, um Feature-Maps (P2, ... P7) zu erhalten, wobei Pi von der Eingabe um 2^i heruntergesampelt wird. Das BiFPN-Netzwerk wird dann verwendet, um diese Multiskalenmerkmale bidirektional zu fusionieren. Anschließend wird die Merkmalskarte P2 mit der höchsten Auflösung verwendet, um die Belegungs- und Flussvorhersagen für alle Agentenklassen K in allen Zeitschritten zu regressieren. Konkret gibt der Decoder einen Vektor für jede Gitterzelle aus und prognostiziert gleichzeitig Belegung und Fluss.
 Für diesen Artikel wird die folgende Problemstellung vorgenommen: Angesichts des 1-Sekunden-Verlaufs des Verkehrsagenten in der Szene und des Szenenkontexts, wie z. B. Kartenkoordinaten, besteht das Ziel darin, i) die zukünftige beobachtete Belegung vorherzusagen, ii) zukünftige Okklusionsbelegungsrate und iii) der zukünftige Fluss aller Fahrzeuge an 8 Wegpunkten in der Zukunft in einem Szenario, in dem jeder Wegpunkt ein Intervall von 1 Sekunde abdeckt.
Für diesen Artikel wird die folgende Problemstellung vorgenommen: Angesichts des 1-Sekunden-Verlaufs des Verkehrsagenten in der Szene und des Szenenkontexts, wie z. B. Kartenkoordinaten, besteht das Ziel darin, i) die zukünftige beobachtete Belegung vorherzusagen, ii) zukünftige Okklusionsbelegungsrate und iii) der zukünftige Fluss aller Fahrzeuge an 8 Wegpunkten in der Zukunft in einem Szenario, in dem jeder Wegpunkt ein Intervall von 1 Sekunde abdeckt.
Verarbeiten Sie die Eingabe in ein gerastertes Bild und eine Reihe von Vektoren. Um das Bild zu erhalten, wird bei jedem Zeitschritt in der Vergangenheit ein gerastertes Gitter relativ zu den lokalen Koordinaten des selbstfahrenden Autos (SDC) unter Berücksichtigung der Flugbahn des Beobachtungsagenten und der Kartendaten erstellt. Um eine vektorisierte Eingabe zu erhalten, die mit dem gerasterten Bild übereinstimmt, werden dieselben Transformationen durchgeführt, wobei der Eingabeagent und die Kartenkoordinaten relativ zur lokalen Ansicht des SDC gedreht und verschoben werden.
Der Encoderbesteht aus zwei Teilen: dem VGG-16-Modell, das die gerasterte Darstellung kodiert, und dem VectorNe-Modell, das die vektorisierte Darstellung kodiert. Die vektorisierten Merkmale werden durch das Cross-Attention-Modul mit den Merkmalen der letzten beiden Schritte von VGG-16 verschmolzen. Über das Netzwerk im FPN-Stil werden die fusionierten Features auf die ursprüngliche Auflösung hochgesampelt und als gerasterte Eingabe-Features verwendet. Der
Decoderist eine einzelne 2D-Faltungsschicht, die den Encoderausgang einer Vorhersage von Belegungsflussfeldern zuordnet, die aus einer Reihe von 8 Gitterkarten besteht, die die Belegungs- und Flussvorhersagen für jeden Zeitschritt in den nächsten 8 Sekunden darstellen. Wie im Bild gezeigt:
Verwenden Sie das Standard-VGG-16-Modell von Torchvision als Rasterisierungs-Encoder und befolgen Sie die Implementierung von VectorNet (Codehttps://github.com/Tsinghua-MARS-Lab/DenseTNT). Die Eingabe in VectorNet besteht aus i) einem Satz von Straßenelementvektoren der Form B×Nr×9, wobei B die Stapelgröße ist, Nr=10000 die maximale Anzahl von Straßenelementvektoren ist und die letzte Dimension 9 jeden Vektor darstellt und die Vektor-ID Die Position (x, y) und Richtung (cosθ, sinθ) der beiden Endpunkte; ii) ein Satz von Agentenvektoren mit einer Form von B×1280×9, einschließlich Vektoren von bis zu 128 Agenten in der Szene, wo jeder Agent Mit 10 Vektoren von der Beobachtungsposition.
Folgen Sie VectorNet, führen Sie zunächst die lokale Karte basierend auf der ID jedes Verkehrselements aus und führen Sie dann die globale Karte für alle lokalen Features aus, um vektorisierte Features der Form B×128×N zu erhalten, wobei N die Gesamtzahl der Verkehrselemente ist , einschließlich Straßenelemente und Intelligenz. Die Größe des Merkmals wird durch die MLP-Schicht weiter um das Vierfache erhöht, um das endgültige vektorisierte Merkmal V zu erhalten, dessen Form B × 512 × N ist und dessen Merkmalsgröße mit der Kanalgröße des Bildmerkmals übereinstimmt.
Die Ausgabemerkmale jeder VGG-Ebene werden als {C1, C2, C3, C4, C5} relativ zum Eingabebild und 512 versteckten Dimensionen dargestellt, die Schritte betragen {1, 2, 4, 8, 16} Pixel . Das vektorisierte Merkmal V wird mit dem gerasterten Bildmerkmal C5 der Form B×512×16×16 über das Queraufmerksamkeitsmodul fusioniert, um F5 derselben Form zu erhalten. Das Abfrageelement der Queraufmerksamkeit ist das Bildmerkmal C5, das mit 256 Token auf eine B×512×256-Form abgeflacht wird, und die Schlüssel- und Wertelemente sind das vektorisierte Merkmal V mit N Token.
Verbinden Sie dann F5 und C5 auf der Kanaldimension und durchlaufen Sie zwei 3×3-Faltungsschichten, um P5 mit einer Form von B×512×16×16 zu erhalten. P5 wird durch das 2×2-Upsampling-Modul im FPN-Stil hochgetastet und mit C4 (B×512×32x32) verbunden, um U4 mit der gleichen Form wie C4 zu erzeugen. Anschließend wird eine weitere Fusionsrunde zwischen V und U4 durchgeführt, wobei das gleiche Verfahren, einschließlich Queraufmerksamkeit, angewendet wird, um P4 (B × 512 × 32 × 32) zu erhalten. Schließlich wird P4 durch das FPN-Netzwerk schrittweise hochgetastet und mit {C3, C2, C1} verbunden, um EP1 mit einer Form von B×512×256×256 zu erzeugen. Führen Sie P1 durch zwei 3×3-Faltungsschichten, um das endgültige Ausgabemerkmal mit einer Form von B×128×256 zu erhalten.
Der Decoder ist eine einzelne 2D-Faltungsschicht mit einer Eingangskanalgröße von 128 und einer Ausgangskanalgröße von 32 (8 Wegpunkte × 4 Ausgangsabmessungen).
Die Ergebnisse sind wie folgt:
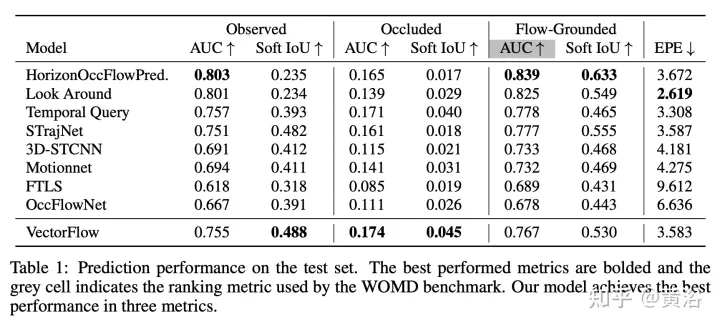
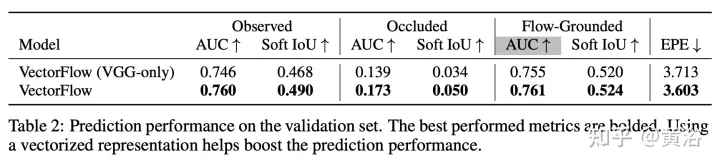
Das obige ist der detaillierte Inhalt vonVectorFlow: Kombination von Bildern und Vektoren zur Vorhersage der Verkehrsbelegung und des Verkehrsflusses. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



