
 Technologie-Peripheriegeräte
KI
Um die Alipay-Sucherfahrung zu verbessern, verwenden Ant und die Peking-Universität ein hierarchisches Framework zur vergleichenden Lerntextgenerierung
Technologie-Peripheriegeräte
KI
Um die Alipay-Sucherfahrung zu verbessern, verwenden Ant und die Peking-Universität ein hierarchisches Framework zur vergleichenden Lerntextgenerierung
Um die Alipay-Sucherfahrung zu verbessern, verwenden Ant und die Peking-Universität ein hierarchisches Framework zur vergleichenden Lerntextgenerierung

Aufgaben zur Textgenerierung werden normalerweise mithilfe von Lehrererzwingung trainiert. Diese Trainingsmethode ermöglicht es dem Modell, während des Trainingsprozesses nur positive Proben zu sehen. Es gibt jedoch normalerweise bestimmte Einschränkungen zwischen dem Generierungsziel und der Eingabe. Diese Einschränkungen spiegeln sich normalerweise in Schlüsselelementen im Satz wider. Beispielsweise kann „McDonalds bestellen“ nicht in „KFC bestellen“ geändert werden spielt eine Rolle. Das Schlüsselelement der Zurückhaltung sind Markenschlüsselwörter. Durch die Einführung kontrastiven Lernens und das Hinzufügen negativer Stichprobenmuster zum Generierungsprozess kann das Modell diese Einschränkungen effektiv lernen.
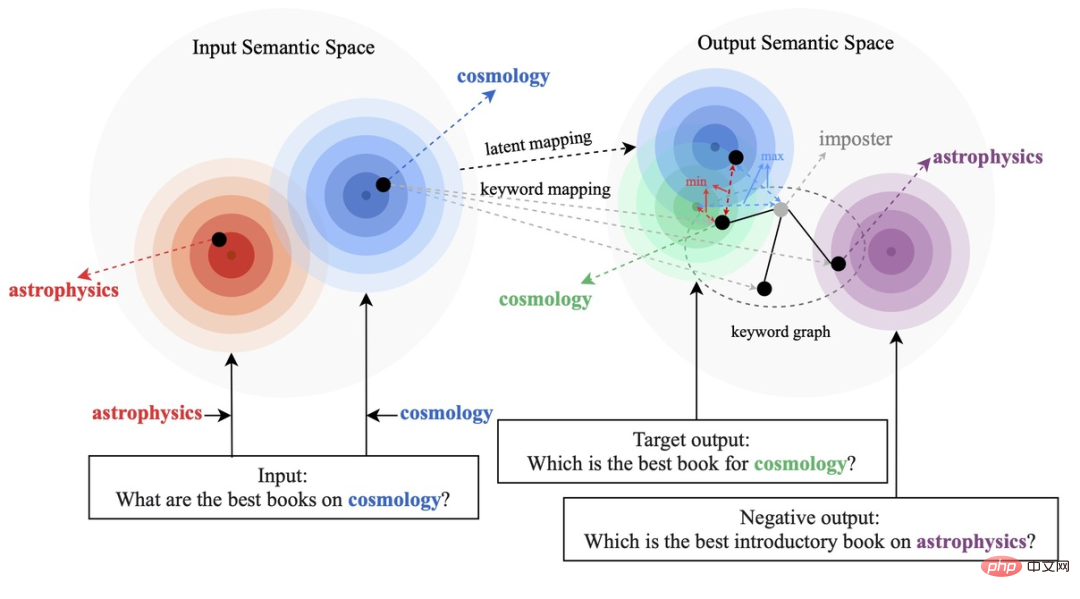
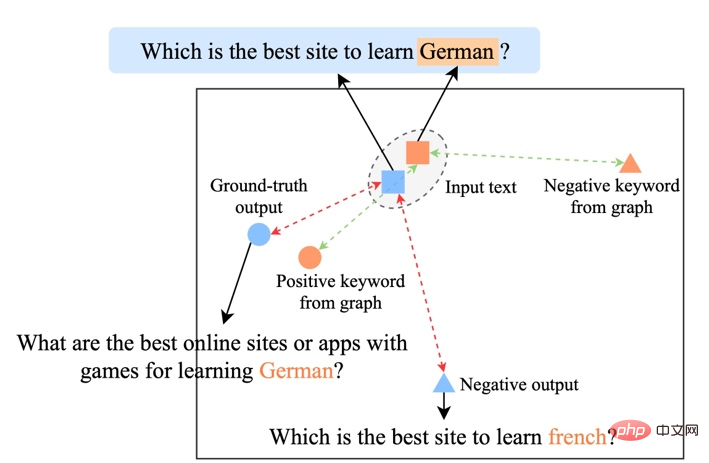
Bestehende kontrastive Lernmethoden konzentrieren sich hauptsächlich auf die gesamte Satzebene [1][2], während die Informationen wortgranularer Entitäten im Satz ignoriert werden. Das Beispiel in der folgenden Abbildung zeigt die Schlüsselwörter im Satz Die wichtige Bedeutung von Wörtern: Wenn die Schlüsselwörter eines Eingabesatzes ersetzt werden (z. B. Kosmologie -> Astrophysik), ändert sich die Bedeutung des Satzes und damit auch die Position im semantischen Raum (dargestellt durch die Verteilung). Als wichtigste Information in einem Satz entsprechen Schlüsselwörter einem Punkt in der semantischen Verteilung, der weitgehend die Position der Satzverteilung bestimmt. Gleichzeitig sind in manchen Fällen die vorhandenen kontrastiven Lernziele für das Modell zu einfach, was dazu führt, dass das Modell nicht in der Lage ist, die Schlüsselinformationen zwischen positiven und negativen Beispielen wirklich zu lernen.
Auf dieser Grundlage haben Forscher der Ant Group, der Peking-Universität und anderer Institutionen eine Methode zur Erzeugung von Kontrasten mit mehreren Granularitäten vorgeschlagen, eine hierarchische Kontraststruktur entworfen, Informationen auf verschiedenen Ebenen verbessert und das Lernen auf Satzgranularität verbessert Die Gesamtsemantik verbessert lokal wichtige Informationen auf Wortgranularität. Forschungsarbeit wurde für ACL 2022 angenommen.

Papieradresse: https://aclanthology.org/2022.acl-long.304.pdf
Methode
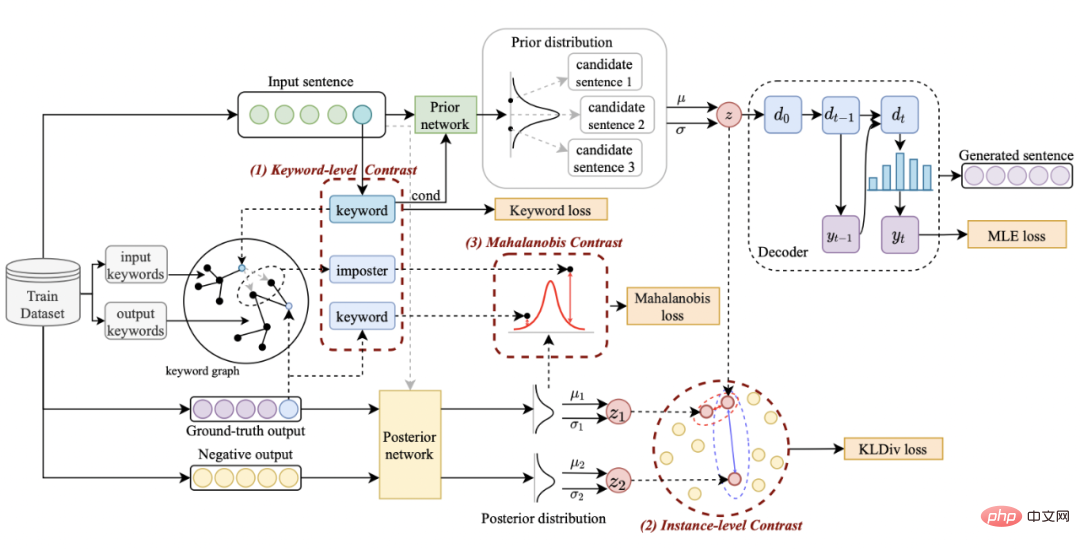
Unser Ansatz basiert auf klassisch Im CVAE-Textgenerierungsframework [3][4] kann jeder Satz einer Verteilung im Vektorraum zugeordnet werden, und die Schlüsselwörter im Satz können als aus dieser Verteilung abgetasteter Punkt betrachtet werden. Einerseits verbessern wir den Ausdruck der latenten Raumvektorverteilung durch den Vergleich der Satzgranularität. Andererseits verbessern wir den Ausdruck der Schlüsselwortpunktgranularität durch den konstruierten globalen Schlüsselwortgraphen Verteilung von Schlüsselwortpunkten und Sätzen zwischen Konstruktebenen, um den Informationsausdruck auf zwei Granularitäten zu verbessern. Die endgültige Verlustfunktion wird durch Addition dreier verschiedener kontrastiver Lernverluste erhalten.
Satzgranulares vergleichendes Lernen
Auf Instanzebene verwenden wir die ursprüngliche Eingabe x, die Zielausgabe

und die entsprechenden negativen Ausgabeproben Bilden Sie einen Satz Paargrößenvergleich
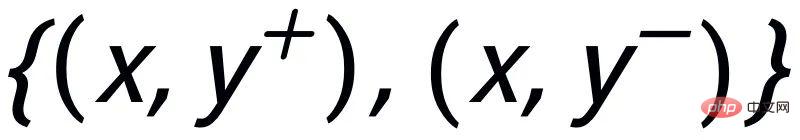
. Wir verwenden ein Prior-Netzwerk, um die Prior-Verteilung zu lernen
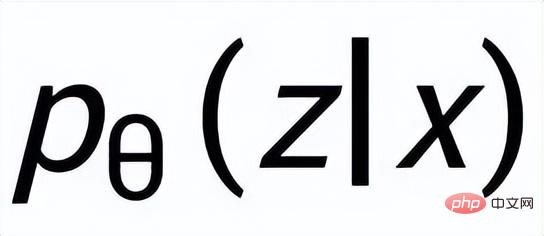
, bezeichnet als
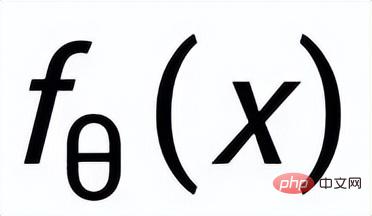
; wir verwenden ein Posterior-Netzwerk, um die ungefähre Posterior-Verteilung zu lernen
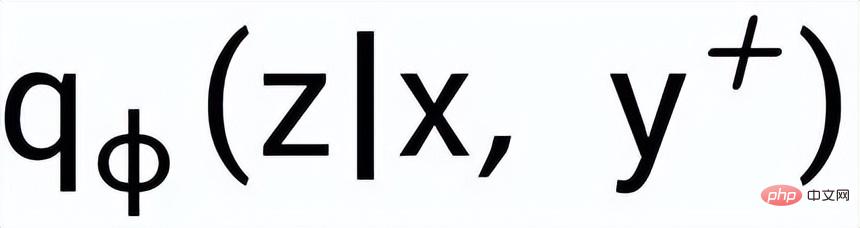
und
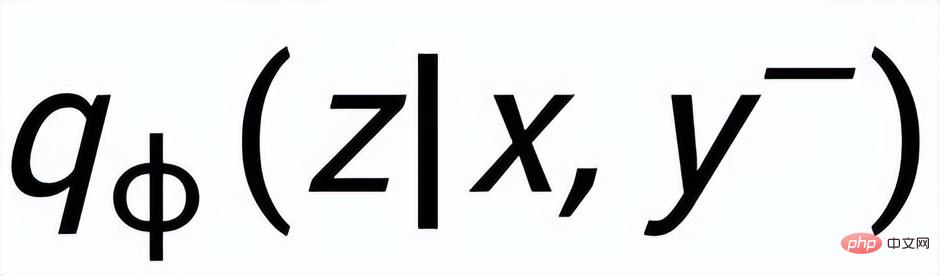
werden als
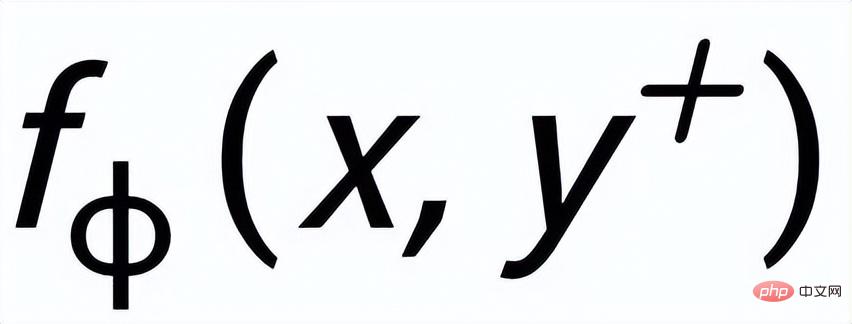
und
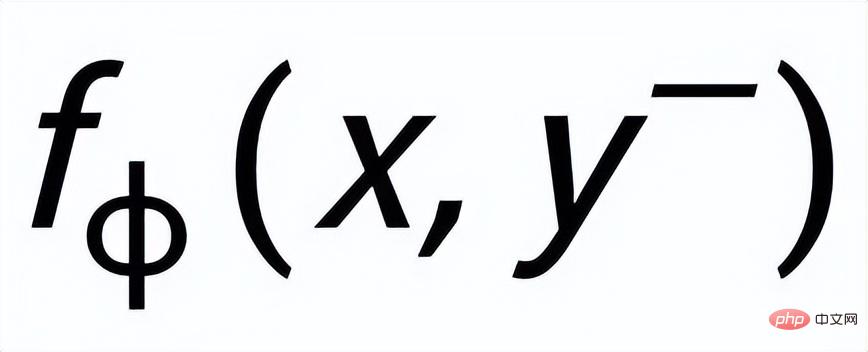
bzw. . Das Ziel des satzgranularen vergleichenden Lernens besteht darin, den Abstand zwischen der vorherigen Verteilung und der positiven hinteren Verteilung so weit wie möglich zu verringern und gleichzeitig den Abstand zwischen der vorherigen Verteilung und der negativen hinteren Verteilung zu maximieren wie folgt:
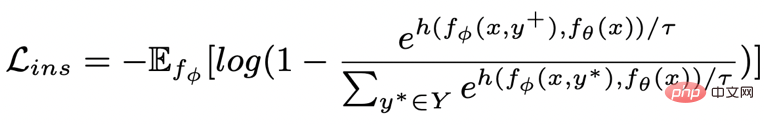
wobei eine positive Probe oder eine negative Probe ist und der Temperaturkoeffizient ist, der zur Darstellung der Abstandsmessung verwendet wird. Hier verwenden wir die KL-Divergenz (Kullback-Leibler-Divergenz) [5 ], um den direkten Abstand zwischen zwei Verteilungen zu messen.
Keyword-granulares vergleichendes Lernen
- Keyword-Netzwerk
Vergleichendes Lernen der Keyword-Granularität wird verwendet, um dem Modell mehr Aufmerksamkeit zu schenken Wörter im Satz Information Dieses Ziel erreichen wir, indem wir ein Keyword-Diagramm erstellen, das die positiven und negativen Beziehungen verwendet, die dem Eingabe- und Ausgabetext entsprechen. Konkret können wir anhand eines gegebenen Satzpaares

jeweils ein Schlüsselwort

und

bestimmen ( Für die Schlüsselwortextraktionsmethode: Ich verwende den klassischen TextRank-Algorithmus [6]).

, wobei jeder Satz

ein Paar positiver und negativer Beispielausgabesätze
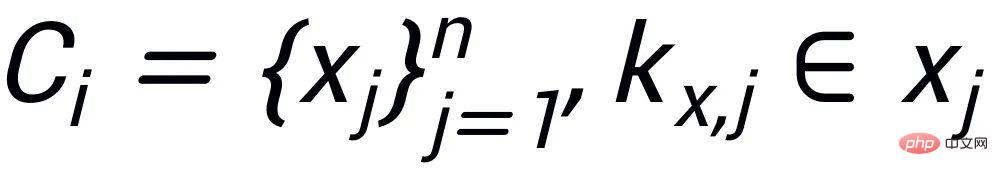
hat, sie haben Ein positives Schlüsselwort
und ausschließende Beispiel-Keywords
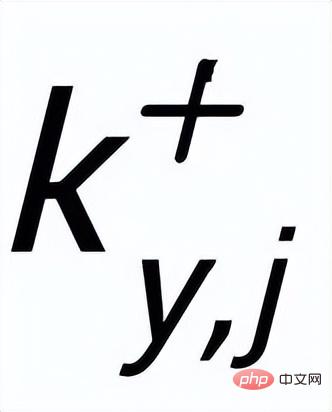
. Auf diese Weise kann in der gesamten Sammlung für jeden Ausgabesatz

das entsprechende Schlüsselwort

und jedes umgebende
 berücksichtigt werden
berücksichtigt werden
(verbunden durch positive und negative Beziehungen zwischen Sätzen)
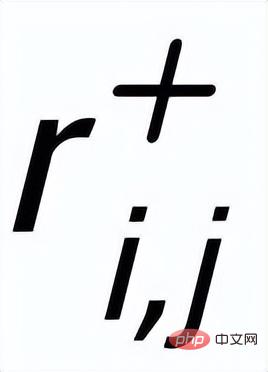
, und es gibt eine positive Kante zwischen jeder umgebenden

 . Basierend auf diesen Schlüsselwortknoten und ihren direkten Kanten können wir ein Schlüsselwortdiagramm erstellen. Wir verwenden BERT-Einbettung [7], während jeder Knoten initialisiert und verwendet wird eine MLP-Ebene, um die Darstellung jeder Kante zu lernen
. Basierend auf diesen Schlüsselwortknoten und ihren direkten Kanten können wir ein Schlüsselwortdiagramm erstellen. Wir verwenden BERT-Einbettung [7], während jeder Knoten initialisiert und verwendet wird eine MLP-Ebene, um die Darstellung jeder Kante zu lernen
 . Wir aktualisieren die Knoten und Kanten im Schlüsselwortnetzwerk iterativ über eine GAT-Schicht (Graph Attention) und eine MLP-Schicht. In jeder Iteration aktualisieren wir zunächst die Kantendarstellung auf folgende Weise:
. Wir aktualisieren die Knoten und Kanten im Schlüsselwortnetzwerk iterativ über eine GAT-Schicht (Graph Attention) und eine MLP-Schicht. In jeder Iteration aktualisieren wir zunächst die Kantendarstellung auf folgende Weise:
Hier

kann
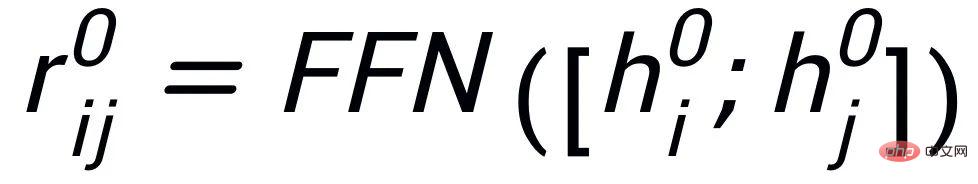
oder
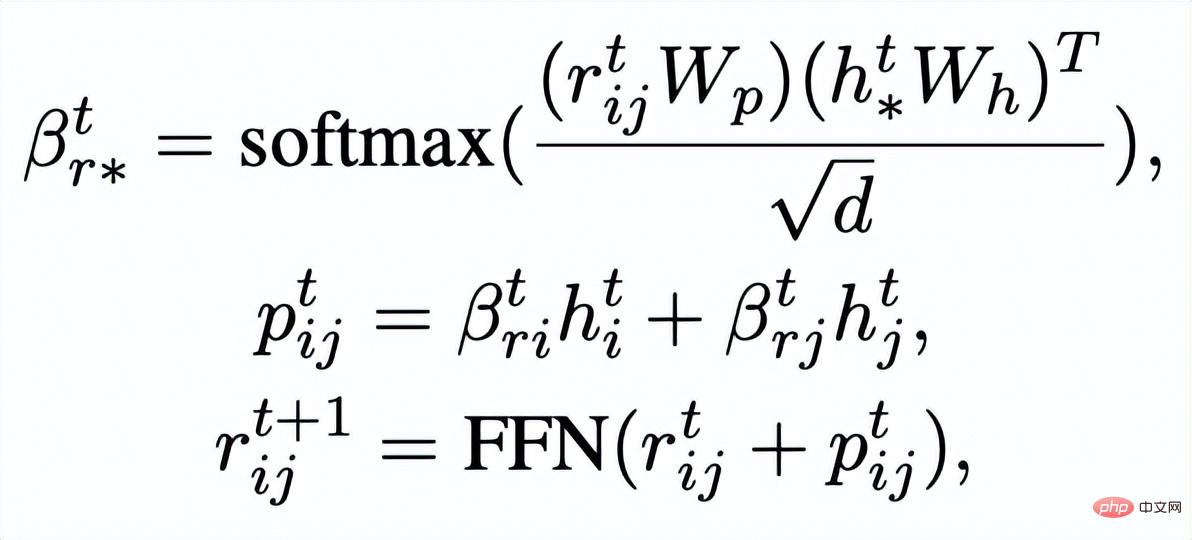
sein.

Dann basierend auf den aktualisierten Kanten
 Wir aktualisieren die Darstellung jedes Knotens über eine Diagramm-Aufmerksamkeitsschicht:
Wir aktualisieren die Darstellung jedes Knotens über eine Diagramm-Aufmerksamkeitsschicht:

ist das Aufmerksamkeitsgewicht. Um das Problem des verschwindenden Gradienten zu vermeiden, fügen wir eine Restverbindung zu
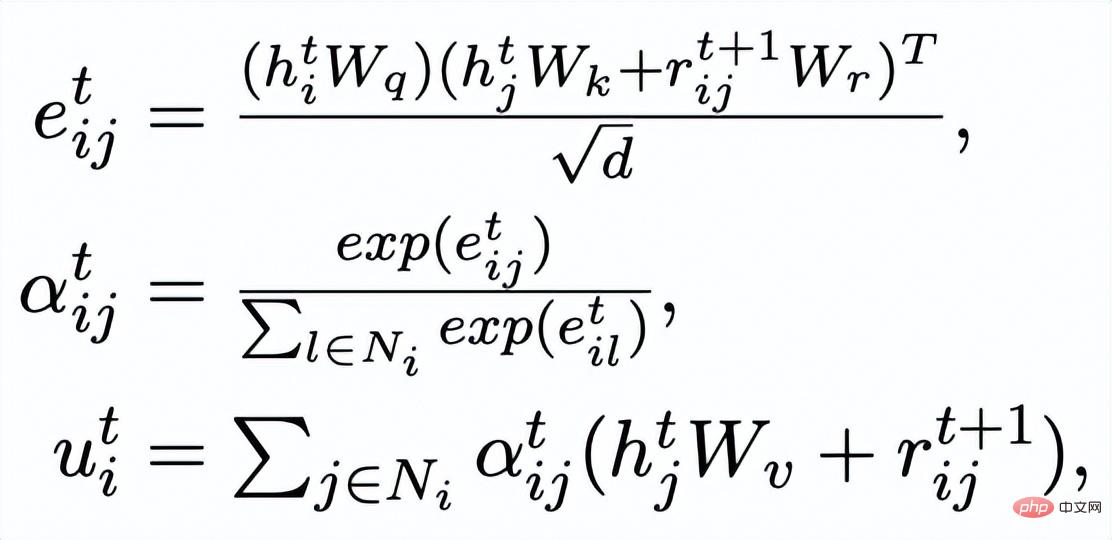
hinzu, um die Darstellung der Knoten in dieser Iteration zu erhalten
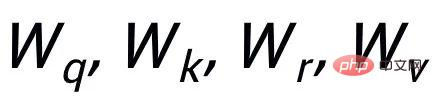
. Wir verwenden die Knotendarstellung der letzten Iteration als Darstellung des Schlüsselworts, bezeichnet als u.

Keyword-Vergleich

Der Vergleich der Keyword-Granularität erfolgt anhand der Keywords des Eingabesatzes

und ein Betrügerknoten
- . Wir zeichnen das aus der positiven Ausgabeprobe des Eingabesatzes extrahierte Schlüsselwort als
auf, und sein negativer Nachbarknoten im obigen Schlüsselwortnetzwerk wird als

aufgezeichnet, dann

, der vergleichende Lernverlust der Keyword-Granularität wird wie folgt berechnet:

hier

wird verwendet, um sich auf
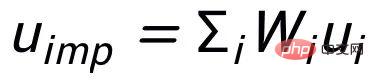
zu beziehen
oder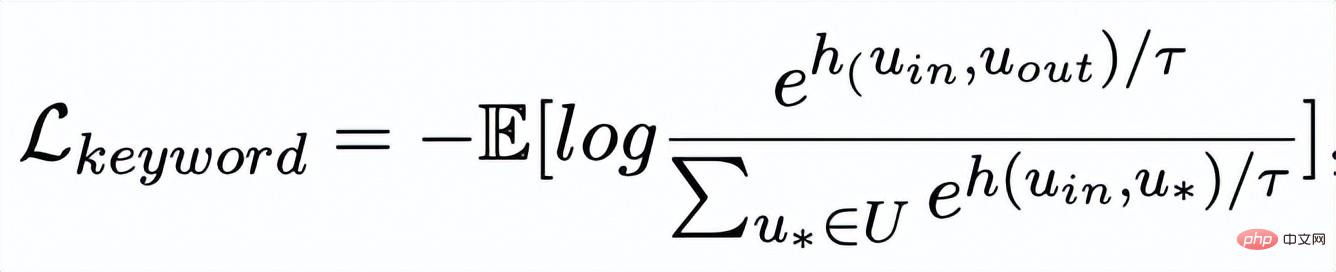
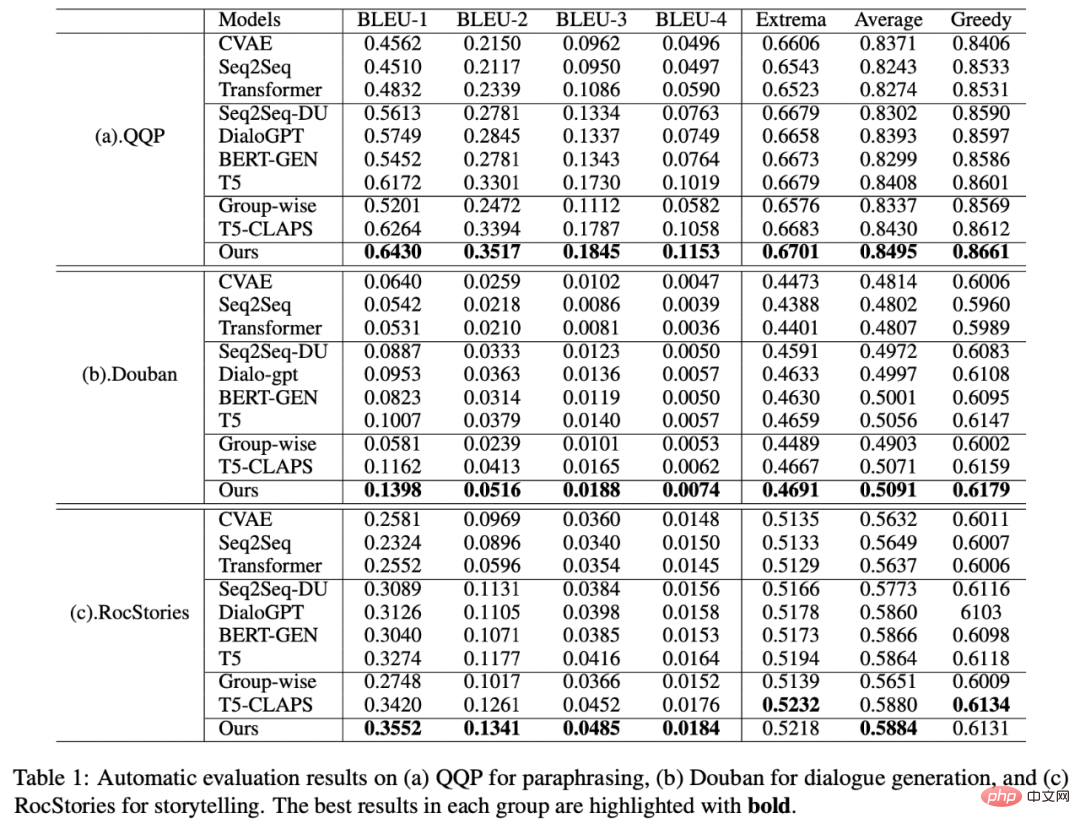
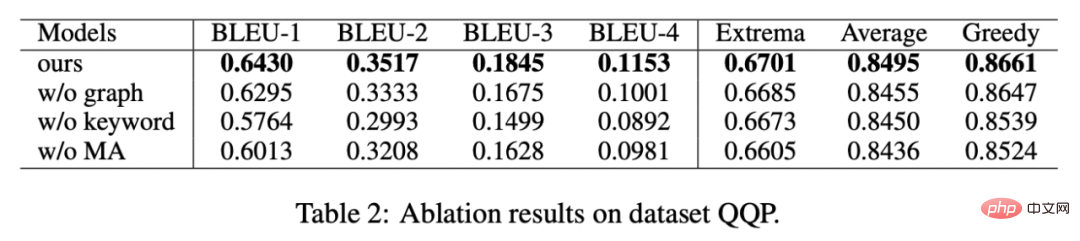
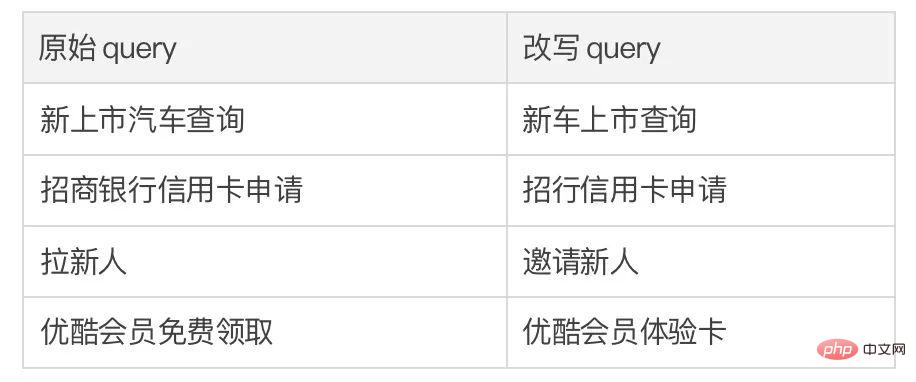
, h(·) wird verwendet, um das Abstandsmaß darzustellen. Beim vergleichenden Lernen der Schlüsselwortgranularität wählen wir die Kosinusähnlichkeit, um den Abstand zwischen zwei Punkten zu berechnen. Es ist zu beachten, dass das obige kontrastive Lernen der Satzgranularität und der Schlüsselwortgranularität jeweils an der Verteilung und am Punkt implementiert wird, so dass ein unabhängiger Vergleich der zwei Granularitäten sind möglich. Der Verstärkungseffekt wird durch kleinere Unterschiede abgeschwächt. In diesem Zusammenhang konstruieren wir eine vergleichende Assoziation zwischen verschiedenen Granularitäten basierend auf dem Mahalanobis-Abstand [8] zwischen Punkten und Verteilungen, sodass der Abstand zwischen dem Zielausgabeschlüsselwort und der Satzverteilung so gering wie möglich ist, sodass der Abstand zwischen den Imposter und die Verteilung ist so klein wie möglich. Dies gleicht den Mangel aus, dass der unabhängige Vergleich jeder Partikelgröße zum Verschwinden des Kontrasts führen kann. Insbesondere hofft das granularitätsübergreifende Mahalanobis-Distanzkontrastlernen, den Abstand zwischen der hinteren semantischen Verteilung der Sätze und so weit wie möglich zu verringern und gleichzeitig den Abstand dazwischen zu vergrößern Sie so weit wie möglich. Der Abstand zwischen ihm und ist wie folgt: hier wird auch verwendet. Siehe oder , und h(·) ist der Mahalanobis-Abstand. Wir haben an drei öffentlichen Datensätzen gearbeitet: Douban (Dialog) [9], QQP (Paraphrasierung) [10][11] und cStories-Experimente wurden am Thema (Storytelling) [12] durchgeführt und erzielten SOTA-Ergebnisse. Die von uns verglichenen Basislinien umfassen traditionelle generative Modelle (z. B. CVAE[13], Seq2Seq[14], Transformer[15]) und Methoden, die auf vorab trainierten Modellen basieren (z. B. Seq2Seq-DU[16], DialoGPT[17], BERT-GEN [7], T5[18]) und Methoden, die auf kontrastivem Lernen basieren (z. B. Group-wise[9], T5-CLAPS[19]). Wir berechnen den BLEU-Score[20] und den BOW-Einbettungsabstand (extrema/durchschnittlich/gierig)[21] zwischen Satzpaaren als automatisierte Bewertungsindikatoren. Die Ergebnisse sind in der folgenden Abbildung dargestellt: Wir Für den QQP-Datensatz werden auch drei Annotatoren verwendet: T5-CLAPS, DialoGPT, Seq2Seq-DU und die von unserem Modell generierten Ergebnisse Wir haben Ablationsanalyseexperimente durchgeführt, um herauszufinden, ob Schlüsselwörter, Schlüsselwortnetzwerke und die Mahalanobis-Distanzvergleichsverteilung verwendet werden sollen. Die Ergebnisse zeigen, dass diese drei Designs tatsächlich eine Rolle spielen Endergebnisse spielen eine wichtige Rolle. Die experimentellen Ergebnisse sind in der folgenden Abbildung dargestellt. Um die Rolle des kontrastiven Lernens auf verschiedenen Ebenen zu untersuchen, visualisierten wir die zufällig ausgewählten Fälle und führten eine Dimensionsreduktion durch t-sne[22] durch, um die zu erhalten folgendes Bild. Aus der Abbildung ist ersichtlich, dass die Darstellung des Eingabesatzes nahe an der Darstellung des extrahierten Schlüsselworts liegt, was zeigt, dass Schlüsselwörter als wichtigste Informationen im Satz normalerweise die Position der semantischen Verteilung bestimmen. Darüber hinaus können wir beim kontrastiven Lernen sehen, dass die Verteilung der Eingabesätze nach dem Training näher an positiven Stichproben und weiter von negativen Stichproben entfernt ist, was zeigt, dass kontrastives Lernen dabei helfen kann, die semantische Verteilung zu korrigieren. Abschließend untersuchen wir die Auswirkungen der Stichprobe verschiedener Schlüsselwörter. Wie in der folgenden Tabelle dargestellt, stellen wir für eine Eingabefrage Schlüsselwörter als Bedingungen bereit, um die semantische Verteilung durch TextRank-Extraktion bzw. Zufallsauswahlmethoden zu steuern und die Qualität des generierten Texts zu überprüfen. Schlüsselwörter sind die wichtigste Informationseinheit in einem Satz. Unterschiedliche Schlüsselwörter führen zu unterschiedlichen semantischen Verteilungen und führen zu unterschiedlichen Tests. Je mehr Schlüsselwörter ausgewählt werden, desto genauer sind die generierten Sätze. Mittlerweile sind auch die von anderen Modellen generierten Ergebnisse in der folgenden Tabelle aufgeführt. In diesem Artikel schlagen wir einen granularitätsübergreifenden hierarchischen kontrastiven Lernmechanismus vor, der bei der Arbeit mit mehreren textgenerierten Datensätzen mehr als wettbewerbsfähig ist. Das auf dieser Arbeit basierende Modell zum Umschreiben von Abfragen wurde erfolgreich in das tatsächliche Geschäftsszenario der Alipay-Suche implementiert und erzielte bemerkenswerte Ergebnisse. Die Dienste in der Suche von Alipay decken ein breites Spektrum an Bereichen ab und weisen erhebliche Domänenmerkmale auf. Es besteht ein großer wörtlicher Unterschied zwischen dem Suchabfrageausdruck des Benutzers und dem Dienstausdruck, was es schwierig macht, ideale Ergebnisse durch direkten Abgleich anhand von Schlüsselwörtern zu erzielen Wenn der Benutzer beispielsweise die Abfrage „Neu gestartete Autoabfrage“ eingibt, kann er sich nicht an den Dienst „Neu gestartete Autoabfrage“ erinnern. Das Ziel des Umschreibens der Abfrage besteht darin, die vom Benutzer eingegebene Abfrage so umzuschreiben, dass sie näher an der Abfrage liegt Dienstausdruck, während die Abfrageabsicht unverändert bleibt, um eine bessere Übereinstimmung mit dem Zieldienst zu erzielen. Hier sind einige Beispiele für Umformulierungen: 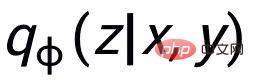


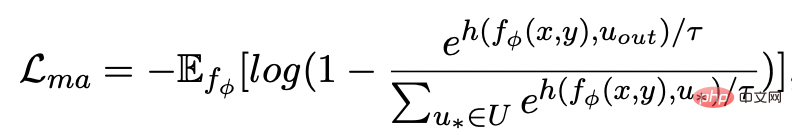



Experiment & Analyse
Experimentelle Ergebnisse
Ablationsanalyse
Visuelle Analyse
Keyword-Wichtigkeitsanalyse

Geschäftsanwendungen
Das obige ist der detaillierte Inhalt vonUm die Alipay-Sucherfahrung zu verbessern, verwenden Ant und die Peking-Universität ein hierarchisches Framework zur vergleichenden Lerntextgenerierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 So entfernen Sie Nachrichten und Trendinhalte aus der Windows 11-Suche
Oct 16, 2023 pm 08:13 PM
So entfernen Sie Nachrichten und Trendinhalte aus der Windows 11-Suche
Oct 16, 2023 pm 08:13 PM
Wenn Sie in Windows 11 auf das Suchfeld klicken, wird die Suchoberfläche automatisch erweitert. Es zeigt links eine Liste der zuletzt verwendeten Programme und rechts Webinhalte an. Dort zeigt Microsoft Neuigkeiten und Trendinhalte an. Der heutige Check bewirbt Bings neue Bildgenerierungsfunktion DALL-E3, das Angebot „Chat Dragons with Bing“, weitere Informationen zu Drachen, Top-News aus dem Web-Bereich, Spielempfehlungen und den Trending Search-Bereich. Die gesamte Liste der Elemente ist unabhängig von Ihrer Aktivität auf Ihrem Computer. Während einige Benutzer die Möglichkeit, Nachrichten anzuzeigen, zu schätzen wissen, ist all dies anderswo in Hülle und Fülle verfügbar. Andere können es direkt oder indirekt als Verkaufsförderung oder sogar als Werbung einstufen. Microsoft nutzt Schnittstellen, um eigene Inhalte zu bewerben,
 Ein tiefer Einblick in Modelle, Daten und Frameworks: eine ausführliche 54-seitige Übersicht über effiziente große Sprachmodelle
Jan 14, 2024 pm 07:48 PM
Ein tiefer Einblick in Modelle, Daten und Frameworks: eine ausführliche 54-seitige Übersicht über effiziente große Sprachmodelle
Jan 14, 2024 pm 07:48 PM
Large-Scale Language Models (LLMs) haben überzeugende Fähigkeiten bei vielen wichtigen Aufgaben bewiesen, darunter das Verständnis natürlicher Sprache, die Sprachgenerierung und das komplexe Denken, und hatten tiefgreifende Auswirkungen auf die Gesellschaft. Diese herausragenden Fähigkeiten erfordern jedoch erhebliche Schulungsressourcen (im linken Bild dargestellt) und lange Inferenzzeiten (im rechten Bild dargestellt). Daher müssen Forscher wirksame technische Mittel entwickeln, um ihre Effizienzprobleme zu lösen. Darüber hinaus wurden, wie auf der rechten Seite der Abbildung zu sehen ist, einige effiziente LLMs (LanguageModels) wie Mistral-7B erfolgreich beim Entwurf und Einsatz von LLMs eingesetzt. Diese effizienten LLMs können den Inferenzspeicher erheblich reduzieren und gleichzeitig eine ähnliche Genauigkeit wie LLaMA1-33B beibehalten
 So suchen Sie nach Benutzern in Xianyu
Feb 24, 2024 am 11:25 AM
So suchen Sie nach Benutzern in Xianyu
Feb 24, 2024 am 11:25 AM
Wie sucht Xianyu nach Benutzern? In der Software Xianyu können wir die Benutzer, mit denen wir kommunizieren möchten, direkt in der Software finden. Aber ich weiß nicht, wie ich nach Benutzern suchen soll. Sehen Sie es sich nach der Suche einfach unter den Benutzern an. Als nächstes gibt der Herausgeber den Benutzern eine Einführung in die Suche nach Benutzern. Wenn Sie interessiert sind, schauen Sie vorbei! Wie suche ich nach Benutzern in Xianyu? Antwort: Details zu den Benutzern nach der Suche anzeigen: 1. Geben Sie die Software ein und klicken Sie auf das Suchfeld. 2. Geben Sie den Benutzernamen ein und klicken Sie auf Suchen. 3. Wählen Sie dann im Suchfeld [Benutzer] aus, um den entsprechenden Benutzer zu finden.
 So verwenden Sie die erweiterte Baidu-Suche
Feb 22, 2024 am 11:09 AM
So verwenden Sie die erweiterte Baidu-Suche
Feb 22, 2024 am 11:09 AM
So verwenden Sie die erweiterte Suche von Baidu: Die Baidu-Suchmaschine ist derzeit eine der am häufigsten verwendeten Suchmaschinen in China. Sie bietet zahlreiche Suchfunktionen, darunter die erweiterte Suche. Die erweiterte Suche kann Benutzern helfen, genauer nach den benötigten Informationen zu suchen und die Sucheffizienz zu verbessern. Wie nutzt man also die erweiterte Baidu-Suche? Der erste Schritt besteht darin, die Startseite der Baidu-Suchmaschine zu öffnen. Zuerst müssen wir die offizielle Website von Baidu öffnen, nämlich www.baidu.com. Dies ist der Eingang zur Baidu-Suche. Klicken Sie im zweiten Schritt auf die Schaltfläche Erweiterte Suche. Auf der rechten Seite des Baidu-Suchfelds befindet sich
 Die WPS-Tabelle kann die gesuchten Daten nicht finden. Bitte überprüfen Sie den Speicherort der Suchoption
Mar 19, 2024 pm 10:13 PM
Die WPS-Tabelle kann die gesuchten Daten nicht finden. Bitte überprüfen Sie den Speicherort der Suchoption
Mar 19, 2024 pm 10:13 PM
In der von Intelligenz dominierten Ära ist auch Bürosoftware populär geworden, und WPS-Formulare werden aufgrund ihrer Flexibilität von der Mehrheit der Büroangestellten übernommen. Bei der Arbeit müssen wir nicht nur das einfache Erstellen von Formularen und die Texteingabe erlernen, sondern auch mehr operative Fähigkeiten beherrschen, um die Aufgaben in der tatsächlichen Arbeit erledigen zu können. Berichte mit Daten und die Verwendung von Formularen sind bequemer, klarer und genauer. Die Lektion, die wir Ihnen heute bringen, ist: Die WPS-Tabelle kann die von Ihnen gesuchten Daten nicht finden. Warum überprüfen Sie bitte den Speicherort der Suchoption? 1. Wählen Sie zunächst die Excel-Tabelle aus und doppelklicken Sie, um sie zu öffnen. Wählen Sie dann in dieser Schnittstelle alle Zellen aus. 2. Klicken Sie dann in dieser Benutzeroberfläche in der oberen Symbolleiste unter „Datei“ auf die Option „Bearbeiten“. 3. Zweitens klicken Sie in dieser Benutzeroberfläche auf „
 Nvidias GPU der nächsten Generation zerschmettert H100 und wird enthüllt! Das erste 3-nm-Multichip-Moduldesign, vorgestellt im Jahr 2024
Sep 30, 2023 pm 12:49 PM
Nvidias GPU der nächsten Generation zerschmettert H100 und wird enthüllt! Das erste 3-nm-Multichip-Moduldesign, vorgestellt im Jahr 2024
Sep 30, 2023 pm 12:49 PM
3-nm-Prozess, Leistung übertrifft H100! Kürzlich brachten die ausländischen Medien DigiTimes die Nachricht, dass Nvidia die GPU der nächsten Generation, die B100, mit dem Codenamen „Blackwell“ entwickelt, angeblich als Produkt für Anwendungen im Bereich der künstlichen Intelligenz (KI) und des Hochleistungsrechnens (HPC). Der B100 wird den 3-nm-Prozess von TSMC sowie ein komplexeres Multi-Chip-Modul (MCM)-Design nutzen und im vierten Quartal 2024 erscheinen. Nvidia, das mehr als 80 % des GPU-Marktes für künstliche Intelligenz monopolisiert, kann mit dem B100 zuschlagen, solange das Eisen heiß ist, und in dieser Welle des KI-Einsatzes weitere Herausforderer wie AMD und Intel angreifen. Nach Schätzungen von NVIDIA wird erwartet, dass der Produktionswert dieses Bereichs bis 2027 ungefähr erreicht
 So suchen Sie auf Mobilgeräten nach Geschäften Taobao So suchen Sie nach Geschäftsnamen
Mar 13, 2024 am 11:00 AM
So suchen Sie auf Mobilgeräten nach Geschäften Taobao So suchen Sie nach Geschäftsnamen
Mar 13, 2024 am 11:00 AM
Die mobile Taobao-App-Software bietet viele gute Produkte, die Sie jederzeit und überall kaufen können. Der Preis für jedes Produkt ist völlig klar, sodass Sie bequemer einkaufen können. Sie können nach Belieben suchen und einkaufen. Fügen Sie Ihre persönliche Lieferadresse und Kontaktnummer hinzu, um die Kontaktaufnahme mit Ihnen zu erleichtern und die neuesten Logistiktrends in Echtzeit zu überprüfen Benutzer verwenden es zum ersten Mal. Wenn Sie nicht wissen, wie man nach Produkten sucht, müssen Sie natürlich nur Schlüsselwörter in die Suchleiste eingeben, um alle Produktergebnisse zu finden Der Herausgeber stellt mobilen Taobao-Benutzern detaillierte Online-Methoden für die Suche nach Geschäftsnamen zur Verfügung. 1. Öffnen Sie zunächst die Taobao-App auf Ihrem Mobiltelefon.
 Die umfassendste Übersicht über multimodale Großmodelle finden Sie hier! 7 Microsoft-Forscher arbeiteten intensiv zusammen, 5 Hauptthemen, 119 Seiten Dokument
Sep 25, 2023 pm 04:49 PM
Die umfassendste Übersicht über multimodale Großmodelle finden Sie hier! 7 Microsoft-Forscher arbeiteten intensiv zusammen, 5 Hauptthemen, 119 Seiten Dokument
Sep 25, 2023 pm 04:49 PM
Die umfassendste Übersicht über multimodale Großmodelle finden Sie hier! Es wurde von sieben chinesischen Forschern bei Microsoft verfasst und umfasst 119 Seiten. Es geht von zwei Arten multimodaler Forschungsrichtungen für große Modelle aus, die abgeschlossen wurden und immer noch an der Spitze stehen, und fasst fünf spezifische Forschungsthemen umfassend zusammen: visuelles Verständnis und visuelle Generierung Der vom einheitlichen visuellen Modell LLM unterstützte multimodale Großmodell-Multimodalagent konzentriert sich auf ein Phänomen: Das multimodale Grundmodell hat sich von spezialisiert zu universell entwickelt. Ps. Aus diesem Grund hat der Autor am Anfang des Artikels direkt ein Bild von Doraemon gezeichnet. Wer sollte diese Rezension (Bericht) lesen? Mit den ursprünglichen Worten von Microsoft: Solange Sie daran interessiert sind, das Grundwissen und die neuesten Fortschritte multimodaler Grundmodelle zu erlernen, egal ob Sie ein professioneller Forscher oder ein Student sind, ist dieser Inhalt sehr gut für Sie geeignet.
