
 Technologie-Peripheriegeräte
KI
ST-P3: Durchgängige räumlich-zeitliche Feature-Learning-Vision-Methode für autonomes Fahren
Technologie-Peripheriegeräte
KI
ST-P3: Durchgängige räumlich-zeitliche Feature-Learning-Vision-Methode für autonomes Fahren
ST-P3: Durchgängige räumlich-zeitliche Feature-Learning-Vision-Methode für autonomes Fahren

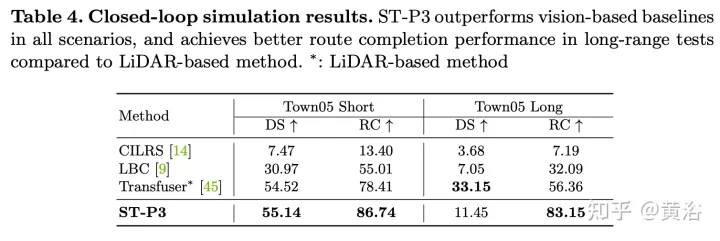
arXiv-Artikel „ST-P3: End-to-end Vision-based Autonomous Driving via Spatial-Temporal Feature Learning“, 22. Juli, Autor von der Shanghai Jiao Tong University, dem Shanghai AI Laboratory, der University of California San Diego und Peking-Forschung von JD .com Krankenhaus.

Schlagen Sie ein Lernschema für räumlich-zeitliche Merkmale vor, das gleichzeitig eine Reihe repräsentativerer Merkmale für Wahrnehmungs-, Vorhersage- und Planungsaufgaben bereitstellen kann, genannt ST-P3. Insbesondere wird eine egozentrisch ausgerichtete Akkumulationstechnik vorgeschlagen, um die geometrischen Informationen im 3D-Raum zu speichern, bevor die BEV-Konvertierung erfasst wird, um vergangene Bewegungsänderungen für zukünftige Vorhersagen zu berücksichtigen Eine Verfeinerungseinheit wird eingeführt, um die geplante visuelle Elementerkennung zu kompensieren. Quellcode, Modell- und Protokolldetails Open Source https://github.com/OpenPercepti onX/ST-P3 .
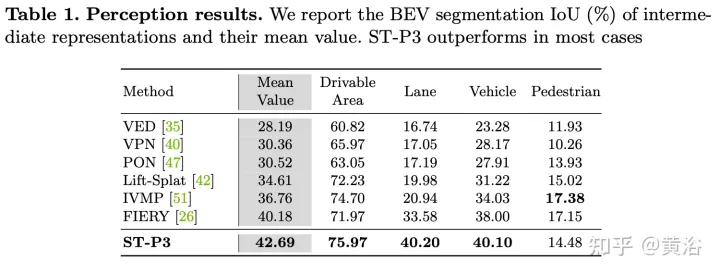
Wegweisende LSS-Methode zum Extrahieren perspektivischer Merkmale aus Multi-View-Kameras über Tiefe. Es ist voraussichtlich auf 3D aufgerüstet und in den BEV-Raum integriert werden. Merkmalskonvertierung zwischen zwei Ansichten, deren latente Tiefenvorhersage entscheidend ist.
Das Upgrade zweidimensionaler Ebeneninformationen auf drei Dimensionen erfordert zusätzliche Dimensionen, dh die Tiefe, die für dreidimensionale geometrische autonome Fahraufgaben geeignet ist. Um die Feature-Darstellung weiter zu verbessern, ist es selbstverständlich, zeitliche Informationen in das Framework einzubeziehen, da die meisten Szenen mit Videoquellen beauftragt sind.
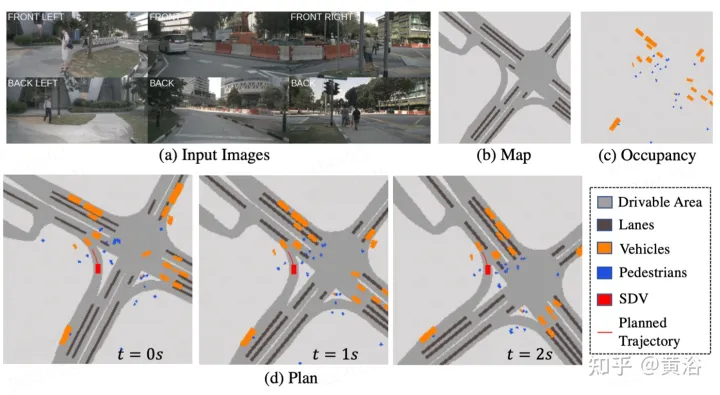
Wie in der Abbildung beschriebenST-P3Gesamtrahmen: Geben Sie insbesondere anhand einer Reihe umgebender Kameravideos diese in das Backbone ein, um vorläufige Vorderansichtsfunktionen zu generieren. Führt eine zusätzliche Tiefenschätzung durch, um 2D-Features in 3D-Raum umzuwandeln. Das selbstzentrierte Ausrichtungsakkumulationsschema richtet zunächst vergangene Features am aktuellen Ansichtskoordinatensystem aus. Aktuelle und vergangene Features werden dann im dreidimensionalen Raum aggregiert, wobei die geometrischen Informationen vor der Konvertierung in die BEV-Darstellung erhalten bleiben. Zusätzlich zum häufig verwendeten Zeitbereichsmodell „Vorhersage“ wird die Leistung durch die Konstruktion eines zweiten Pfads zur Erklärung vergangener Bewegungsänderungen weiter verbessert. Diese Dual-Path-Modellierung gewährleistet eine stärkere Merkmalsdarstellung, um auf zukünftige semantische Ergebnisse zu schließen. Um das ultimative Ziel der Trajektorienplanung zu erreichen, werden die frühen Feature-Vorkenntnisse des Netzwerks integriert. Ein Verfeinerungsmodul wurde entwickelt, um die endgültige Flugbahn mithilfe von Befehlen auf hoher Ebene zu generieren, wenn keine HD-Karten vorhanden sind.
Wie im Bild gezeigt, handelt es sich um die egozentrische Ausrichtungsakkumulationsmethode der 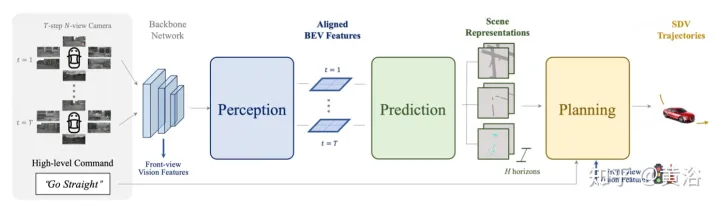 Wahrnehmung
Wahrnehmung
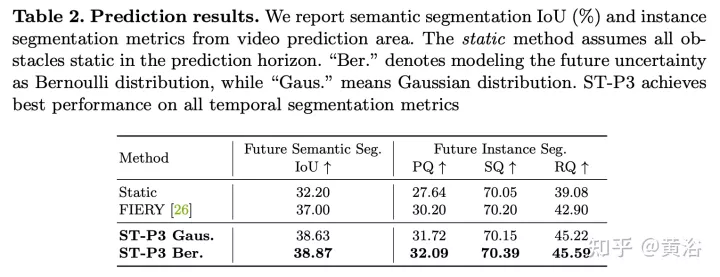
Wie in der Abbildung gezeigt, handelt es sich um ein Zwei-Wege-Modell für 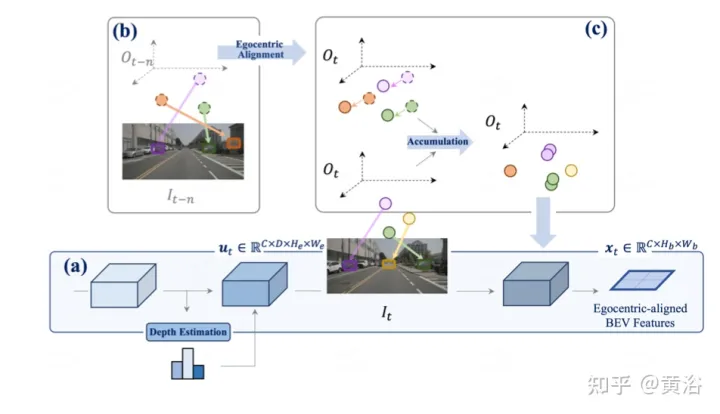 Vorhersage
Vorhersage
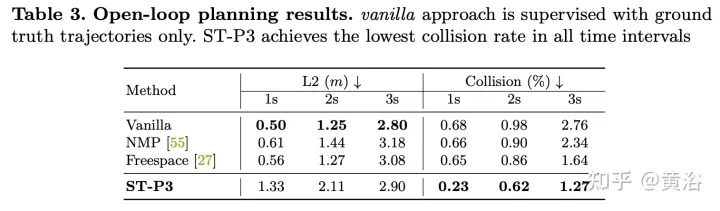
Als ultimatives Ziel müssen Sie eine sichere und bequeme Flugbahn planen, um den Zielpunkt zu erreichen. Dieser Bewegungsplaner tastet eine Reihe verschiedener Trajektorien ab und wählt eine aus, die die erlernte Kostenfunktion minimiert. Die Integration von Informationen von Zielpunkten und Ampeln über ein Zeitbereichsmodell bringt jedoch zusätzliche Optimierungsschritte mit sich. 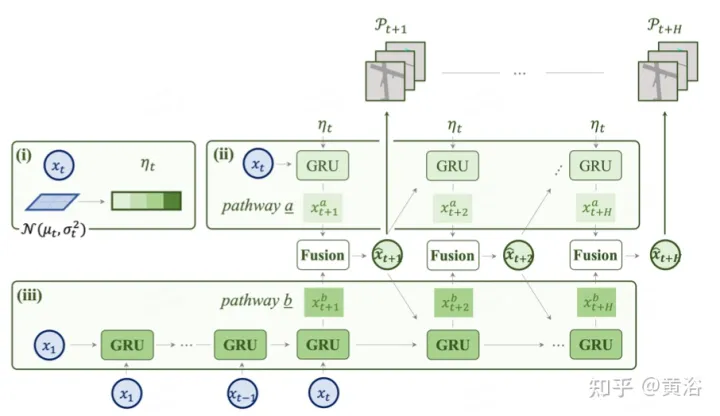
Planung
: Das Gesamtkostendiagramm umfasst zwei Teilkosten. Flugbahnen mit minimalen Kosten werden mithilfe zukunftsweisender Funktionen zur Aggregation visionsbasierter Informationen aus Kameraeingaben weiter neu definiert.
Trajektorien mit großer Querbeschleunigung, Ruck oder Krümmung bestrafen. Hoffentlich wird dieser Weg sein Ziel effizient erreichen, so dass Fortschritte belohnt werden. Die oben genannten Kostenpositionen enthalten jedoch keine Zielinformationen, die normalerweise von Routenkarten bereitgestellt werden. Verwenden Sie übergeordnete Befehle, einschließlich Vorwärts, Linksabbiegen und Rechtsabbiegen, und bewerten Sie Flugbahnen nur anhand der entsprechenden Befehle. 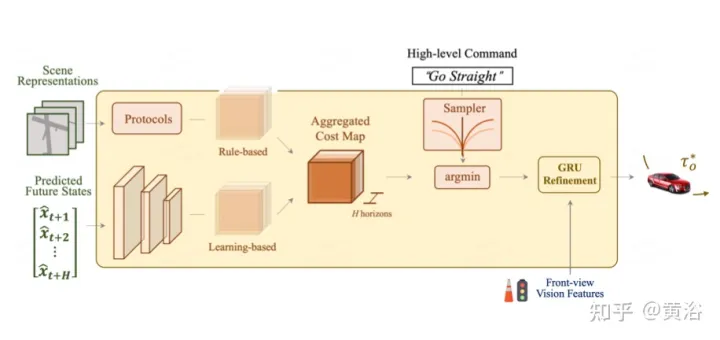
Das obige ist der detaillierte Inhalt vonST-P3: Durchgängige räumlich-zeitliche Feature-Learning-Vision-Methode für autonomes Fahren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Oben geschrieben und persönliches Verständnis des Autors. Dreidimensionales Gaussplatting (3DGS) ist eine transformative Technologie, die in den letzten Jahren in den Bereichen explizite Strahlungsfelder und Computergrafik entstanden ist. Diese innovative Methode zeichnet sich durch die Verwendung von Millionen von 3D-Gaußkurven aus, was sich stark von der Neural Radiation Field (NeRF)-Methode unterscheidet, die hauptsächlich ein implizites koordinatenbasiertes Modell verwendet, um räumliche Koordinaten auf Pixelwerte abzubilden. Mit seiner expliziten Szenendarstellung und differenzierbaren Rendering-Algorithmen garantiert 3DGS nicht nur Echtzeit-Rendering-Fähigkeiten, sondern führt auch ein beispielloses Maß an Kontrolle und Szenenbearbeitung ein. Dies positioniert 3DGS als potenziellen Game-Changer für die 3D-Rekonstruktion und -Darstellung der nächsten Generation. Zu diesem Zweck geben wir erstmals einen systematischen Überblick über die neuesten Entwicklungen und Anliegen im Bereich 3DGS.
 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
0. Vorab geschrieben&& Persönliches Verständnis, dass autonome Fahrsysteme auf fortschrittlichen Wahrnehmungs-, Entscheidungs- und Steuerungstechnologien beruhen, indem sie verschiedene Sensoren (wie Kameras, Lidar, Radar usw.) verwenden, um die Umgebung wahrzunehmen, und Algorithmen und Modelle verwenden für Echtzeitanalysen und Entscheidungsfindung. Dies ermöglicht es Fahrzeugen, Verkehrszeichen zu erkennen, andere Fahrzeuge zu erkennen und zu verfolgen, das Verhalten von Fußgängern vorherzusagen usw. und sich so sicher an komplexe Verkehrsumgebungen anzupassen. Diese Technologie erregt derzeit große Aufmerksamkeit und gilt als wichtiger Entwicklungsbereich für die Zukunft des Transportwesens . eins. Aber was autonomes Fahren schwierig macht, ist herauszufinden, wie man dem Auto klarmachen kann, was um es herum passiert. Dies erfordert, dass der dreidimensionale Objekterkennungsalgorithmus im autonomen Fahrsystem Objekte in der Umgebung, einschließlich ihrer Standorte, genau wahrnehmen und beschreiben kann.
 Das Stable Diffusion 3-Papier wird endlich veröffentlicht und die architektonischen Details werden enthüllt. Wird es helfen, Sora zu reproduzieren?
Mar 06, 2024 pm 05:34 PM
Das Stable Diffusion 3-Papier wird endlich veröffentlicht und die architektonischen Details werden enthüllt. Wird es helfen, Sora zu reproduzieren?
Mar 06, 2024 pm 05:34 PM
Der Artikel von StableDiffusion3 ist endlich da! Dieses Modell wurde vor zwei Wochen veröffentlicht und verwendet die gleiche DiT-Architektur (DiffusionTransformer) wie Sora. Nach seiner Veröffentlichung sorgte es für großes Aufsehen. Im Vergleich zur Vorgängerversion wurde die Qualität der von StableDiffusion3 generierten Bilder erheblich verbessert. Es unterstützt jetzt Eingabeaufforderungen mit mehreren Themen, und der Textschreibeffekt wurde ebenfalls verbessert, und es werden keine verstümmelten Zeichen mehr angezeigt. StabilityAI wies darauf hin, dass es sich bei StableDiffusion3 um eine Reihe von Modellen mit Parametergrößen von 800 M bis 8 B handelt. Durch diesen Parameterbereich kann das Modell direkt auf vielen tragbaren Geräten ausgeführt werden, wodurch der Einsatz von KI deutlich reduziert wird
 Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Die Trajektorienvorhersage spielt eine wichtige Rolle beim autonomen Fahren. Unter autonomer Fahrtrajektorienvorhersage versteht man die Vorhersage der zukünftigen Fahrtrajektorie des Fahrzeugs durch die Analyse verschiedener Daten während des Fahrvorgangs. Als Kernmodul des autonomen Fahrens ist die Qualität der Trajektorienvorhersage von entscheidender Bedeutung für die nachgelagerte Planungssteuerung. Die Trajektorienvorhersageaufgabe verfügt über einen umfangreichen Technologie-Stack und erfordert Vertrautheit mit der dynamischen/statischen Wahrnehmung des autonomen Fahrens, hochpräzisen Karten, Fahrspurlinien, Fähigkeiten in der neuronalen Netzwerkarchitektur (CNN&GNN&Transformer) usw. Der Einstieg ist sehr schwierig! Viele Fans hoffen, so schnell wie möglich mit der Flugbahnvorhersage beginnen zu können und Fallstricke zu vermeiden. Heute werde ich eine Bestandsaufnahme einiger häufiger Probleme und einführender Lernmethoden für die Flugbahnvorhersage machen! Einführungsbezogenes Wissen 1. Sind die Vorschaupapiere in Ordnung? A: Schauen Sie sich zuerst die Umfrage an, S
 SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
Originaltitel: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper-Link: https://arxiv.org/pdf/2402.02519.pdf Code-Link: https://github.com/HKUST-Aerial-Robotics/SIMPL Autor: Hong Kong University of Science und Technologie DJI-Papieridee: Dieses Papier schlägt eine einfache und effiziente Bewegungsvorhersagebasislinie (SIMPL) für autonome Fahrzeuge vor. Im Vergleich zum herkömmlichen Agent-Cent
 nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
Vorab geschrieben und Ausgangspunkt Das End-to-End-Paradigma verwendet ein einheitliches Framework, um Multitasking in autonomen Fahrsystemen zu erreichen. Trotz der Einfachheit und Klarheit dieses Paradigmas bleibt die Leistung von End-to-End-Methoden für das autonome Fahren bei Teilaufgaben immer noch weit hinter Methoden für einzelne Aufgaben zurück. Gleichzeitig erschweren die in früheren End-to-End-Methoden weit verbreiteten Funktionen der dichten Vogelperspektive (BEV) die Skalierung auf mehr Modalitäten oder Aufgaben. Hier wird ein Sparse-Search-zentriertes End-to-End-Paradigma für autonomes Fahren (SparseAD) vorgeschlagen, bei dem die Sparse-Suche das gesamte Fahrszenario, einschließlich Raum, Zeit und Aufgaben, ohne dichte BEV-Darstellung vollständig abbildet. Insbesondere ist eine einheitliche, spärliche Architektur für die Aufgabenerkennung einschließlich Erkennung, Verfolgung und Online-Zuordnung konzipiert. Zudem schwer
 Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Im vergangenen Monat hatte ich aus bekannten Gründen einen sehr intensiven Austausch mit verschiedenen Lehrern und Mitschülern der Branche. Ein unvermeidliches Thema im Austausch ist natürlich End-to-End und der beliebte Tesla FSDV12. Ich möchte diese Gelegenheit nutzen, einige meiner aktuellen Gedanken und Meinungen als Referenz und Diskussion darzulegen. Wie definiert man ein durchgängiges autonomes Fahrsystem und welche Probleme sollten voraussichtlich durchgängig gelöst werden? Gemäß der traditionellsten Definition bezieht sich ein End-to-End-System auf ein System, das Rohinformationen von Sensoren eingibt und für die Aufgabe relevante Variablen direkt ausgibt. Bei der Bilderkennung kann CNN beispielsweise als End-to-End bezeichnet werden, verglichen mit der herkömmlichen Methode zum Extrahieren von Merkmalen + Klassifizieren. Bei autonomen Fahraufgaben werden Eingabedaten verschiedener Sensoren (Kamera/LiDAR) benötigt
