
 Technologie-Peripheriegeräte
KI
GitHub Open Source 130+Sterne: Bringen Sie Ihnen Schritt für Schritt bei, den Zielerkennungsalgorithmus basierend auf der PPYOLO-Serie zu reproduzieren
Technologie-Peripheriegeräte
KI
GitHub Open Source 130+Sterne: Bringen Sie Ihnen Schritt für Schritt bei, den Zielerkennungsalgorithmus basierend auf der PPYOLO-Serie zu reproduzieren
GitHub Open Source 130+Sterne: Bringen Sie Ihnen Schritt für Schritt bei, den Zielerkennungsalgorithmus basierend auf der PPYOLO-Serie zu reproduzieren

Objekterkennung ist eine grundlegende Aufgabe im Bereich Computer Vision. Wie können wir das ohne einen guten Modellzoo schaffen?
Heute präsentiere ich Ihnen eine einfache und benutzerfreundliche Modellbibliothek für Zielerkennungsalgorithmen miemiedetection. Sie hat derzeit mehr als 130 Sterne auf GitHub erhalten
Code-Link: https://github.com/miemie2013/miemiedetection
miemiedetection Es handelt sich um eine persönliche Erkennungsbibliothek, die auf YOLOX basiert und auch Algorithmen wie PPYOLO, PPYOLOv2, PPYOLOE und FCOS unterstützt.
Dank der hervorragenden Architektur von YOLOX ist die Trainingsgeschwindigkeit des Algorithmus bei miemiedetection sehr hoch und das Lesen von Daten stellt nicht mehr den Engpass der Trainingsgeschwindigkeit dar.
Das bei der Codeentwicklung verwendete Deep-Learning-Framework ist pyTorch, das verformbare Faltung DCNv2, Matrix NMS und andere schwierige Operatoren implementiert und Single-Machine-Single-Card, Single-Machine-Multi-Card und Multi-Machine-Multi-Card unterstützt Trainingsmodi (Multi-Card-Trainingsmodus wird unter Verwendung eines Linux-Systems empfohlen), unterstützt Windows- und Linux-Systeme.
Und da miemiedetection eine Erkennungsbibliothek ist, die keine Installation erfordert, können Benutzer ihren Code direkt ändern, um die Ausführungslogik zu ändern, sodass es auch einfach ist, der Bibliothek neue Algorithmen hinzuzufügen.
Der Autor gab an, dass in Zukunft mehr Algorithmusunterstützung (und Damenbekleidung) hinzugefügt wird.

Algorithmus wird garantiert als Fälschung ersetzt
Reproduktionsmodell, das Wichtigste ist, dass die Genauigkeitsrate im Wesentlichen mit der des Originals übereinstimmt.
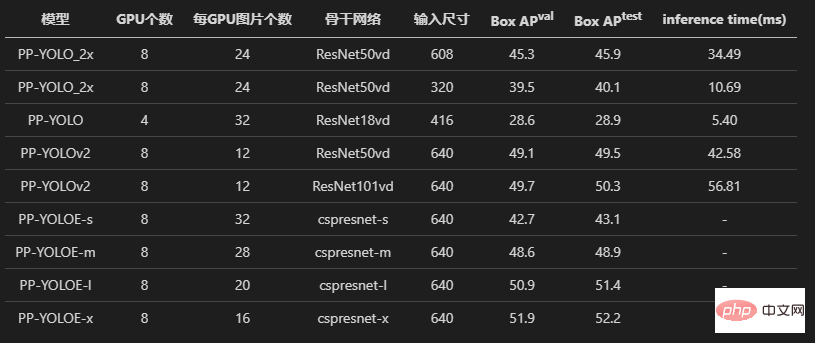
Schauen wir uns zunächst die drei Modelle PPYOLO, PPYOLOv2 und PPYOLOE an. Der Autor hat alle Experimente zur Verlustausrichtung und zur Gradientenausrichtung durchgeführt.
Um Beweise zu sichern, können Sie auch die auskommentierten Lese- und Schreibteile von *.npz im Quellcode sehen, bei denen es sich allesamt um Codes handelt, die vom Alignment-Experiment übrig geblieben sind.
Und der Autor hat auch den Leistungsausrichtungsprozess detailliert aufgezeichnet. Auch für Anfänger ist das Befolgen dieses Weges ein guter Lernprozess!
Alle Trainingsprotokolle werden auch aufgezeichnet und im Lager gespeichert, was ausreicht, um die Richtigkeit der Reproduktion der PPYOLO-Algorithmenreihe zu beweisen!
Die endgültigen Trainingsergebnisse zeigen, dass der reproduzierte PPYOLO-Algorithmus den gleichen Verlust und Gradienten wie das ursprüngliche Lager aufweist.
Darüber hinaus hat der Autor auch versucht, den ursprünglichen Warehouse- und Miemiedetection-Transfer-Learning-Voc2012-Datensatz zu verwenden und auch die gleiche Genauigkeit zu erzielen (unter Verwendung derselben Hyperparameter).
Dasselbe wie die ursprüngliche Implementierung, mit derselben Lernrate, derselben Lernraten-Abfallstrategie warm_piecewisedecay (verwendet von PPYOLO und PPYOLOv2) und warm_cosinedecay (verwendet von PPYOLOE), demselben exponentiellen gleitenden Durchschnitt EMA und derselben Datenvorverarbeitung Methode: Mit dem gleichen Parameter L2-Gewichtsdämpfung, dem gleichen Verlust, dem gleichen Gradienten und dem gleichen vorab trainierten Modell erreichte das Transferlernen die gleiche Genauigkeit.
Wir haben genug experimentiert und viele Tests durchgeführt, um sicherzustellen, dass jeder ein wunderbares Erlebnis hat!
Nein 998, nein 98, klicken Sie einfach auf den Stern und nehmen Sie alle Zielerkennungsalgorithmen kostenlos mit nach Hause!
Modell herunterladen und konvertieren
Wenn Sie das Modell durchgehen möchten, sind die Parameter sehr wichtig. Der Autor stellt die konvertierte pth-Gewichtsdatei vor dem Training bereit, die direkt über Baidu Netdisk heruntergeladen werden kann.
Link: https://pan.baidu.com/s/1ehEqnNYKb9Nz0XNeqAcwDw
Extraktionscode: qe3i
Oder befolgen Sie die folgenden Schritte, um es zu erhalten:
Schritt eins: Laden Sie die Gewichtsdatei herunter , Projekt Führen Sie es im Stammverzeichnis aus (dh laden Sie die Datei herunter. Windows-Benutzer können Thunder oder einen Browser verwenden, um den Link hinter wget herunterzuladen. Um die Schönheit zu zeigen, wird nur ppyoloe_crn_l_300e_coco als Beispiel verwendet):

Beachten Sie, dass Modelle mit den vorab trainierten Wörtern Es handelt sich um ein auf ImageNet, PPYOLOv2 und PPYOLOE vorab trainiertes Backbone-Netzwerk, das diese Gewichte lädt, um den COCO-Datensatz zu trainieren. Der Rest sind vorab trainierte Modelle auf COCO.
Der zweite Schritt besteht darin, die Gewichte zu konvertieren und im Stammverzeichnis des Projekts auszuführen:

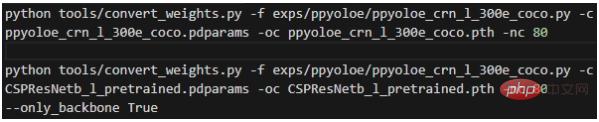
Die Bedeutung jedes Parameters ist:
- -f Stellt die verwendete Konfigurationsdatei dar;
- -c stellt die gelesene Quellgewichtsdatei dar; oc stellt die ausgegebene (gespeicherte) Pytorch-Gewichtsdatei dar;
- -nc stellt die Anzahl der Kategorien des Datensatzes dar; 🎜#- --only_backbone ist True, was bedeutet, dass nur die Gewichtung des Backbone-Netzwerks konvertiert wird; Erhalten Sie die konvertierte *.pth-Gewichtungsdatei im Stammverzeichnis.
Schritt-für-Schritt-Anleitung
In den folgenden Befehlen verwenden die meisten von ihnen die Konfigurationsdatei des Modells, daher ist dies erforderlich Erläutern Sie dies ausführlich zu Beginn der Konfigurationsdatei.
mmdet.exp.base_exp.BaseExp ist die Basisklasse der Konfigurationsdatei. Es handelt sich um eine abstrakte Klasse, die eine Reihe abstrakter Methoden deklariert, z. B. get_model(), die angibt, wie um das Modell zu erhalten. get_data_loader() gibt an, wie man den trainierten Datenlader erhält, get_optimizer() gibt an, wie man den Optimierer erhält usw.
mmdet.exp.datasets.coco_base.COCOBaseExp ist die Konfiguration des Datensatzes und erbt BaseExp. Es gibt nur die Konfiguration des Datensatzes an. Dieses Warehouse unterstützt nur das Training von Datensätzen im COCO-Annotationsformat!
Datensätze in anderen Annotationsformaten müssen vor dem Training in das COCO-Annotationsformat konvertiert werden (wenn zu viele Annotationsformate unterstützt werden, ist der Arbeitsaufwand zu groß). Benutzerdefinierte Datensätze können über miemieLabels in das COCO-Label-Format konvertiert werden. Alle Erkennungsalgorithmus-Konfigurationsklassen erben COCOBaseExp, was bedeutet, dass alle Erkennungsalgorithmen dieselbe Datensatzkonfiguration verwenden.
Die Konfigurationselemente von COCOBaseExp sind:
#🎜🎜 # Unter ihnen stellt
- self.num_classes die Anzahl der Kategorien im Datensatz dar; - self. data_dir stellt das Stammverzeichnis des Datensatzes dar;
- self.cls_names stellt den Kategorienamendateipfad des Datensatzes dar, der eine TXT-Datei ist und eine Zeile stellt einen Kategorienamen dar. Wenn es sich um einen benutzerdefinierten Datensatz handelt, müssen Sie eine neue TXT-Datei erstellen, den Kategorienamen bearbeiten und dann self.cls_names ändern, um darauf zu verweisen. self.ann_folder stellt die Daten dar. Das Stammverzeichnis der Anmerkungsdatei des Satzes muss sich im Verzeichnis self.data_dir befinden. 
- self.train_ann stellt die Anmerkung dar Der Dateiname des Trainingssatzes des Datensatzes muss sich im Verzeichnis self.ann_folder befinden Validierungssatz des Datensatzes, der sich im Verzeichnis self.ann_folder befinden muss; #🎜🎜 #
- self.train_image_folder stellt den Bildordnernamen des Trainingssatzes dar Datensatz, der sich im Verzeichnis self.data_dir befinden muss; muss sich im Verzeichnis self.data_dir befinden;
Für den VOC 2012-Datensatz müssen Sie die Konfiguration des Datensatzes wie folgt ändern: # 🎜🎜#
Darüber hinaus können Sie auch exps/ppyoloe/ mögen. Ändern Sie wie in ppyoloe_crn_l_voc2012.py die Konfiguration von self.num_classes und self. data_dir in der Unterklasse, sodass die Konfiguration von COCOBaseExp überschrieben (ungültig) wird.
Nachdem Sie das zuvor erwähnte Modell heruntergeladen haben, erstellen Sie einen neuen Ordner annotations2 im Verzeichnis self.data_dir des VOC2012-Datensatzes und legen Sie voc2012_train.json, voc2012_val.json ab es in diesen Ordner.
Schließlich sollte die Platzierung des COCO-Datensatzes, des VOC2012-Datensatzes und dieses Projekts wie folgt aussehen:
#🎜🎜 #
Das Stammverzeichnis des Datensatzes und miemiedetection-master sind Verzeichnisse auf derselben Ebene. Ich persönlich empfehle nicht, den Datensatz in miemiedetection-master abzulegen, da PyCharm sonst beim Öffnen sehr groß wird. Wenn mehrere Projekte (z. B. mmdetection, PaddleDetection, AdelaiDet) Datensätze gemeinsam nutzen, können Sie den Datensatzpfad und das Projekt festlegen Name ist egal.
mmdet.exp.ppyolo.ppyolo_method_base.PPYOLO_Method_Exp ist eine Klasse, die alle abstrakten Methoden bestimmter Algorithmen implementiert. Sie erbt COCOBaseExp, das alle abstrakten Methoden implementiert.
exp.ppyolo.ppyolo_r50vd_2x.Exp ist die letzte Konfigurationsklasse des Resnet50Vd-Modells des PPYOLO-Algorithmus, die PPYOLO_Method_Exp erbt; 🎜# Die Konfigurationsdatei von PPYOLOE hat ebenfalls eine ähnliche Struktur.
Vorhersage
Wenn es sich bei den Eingabedaten um ein Bild handelt, führen Sie es zunächst im Projektstammverzeichnis aus:

Die Bedeutung jedes Parameters ist:
- -f bedeutet, was in der Konfigurationsdatei verwendet wird ;
- -c stellt die gelesene Gewichtsdatei dar;
- --conf stellt den Bewertungsschwellenwert dar, nur ein Vorhersagefeld höher als dieser Schwellenwert;
- --tsize stellt die Auflösung dar, mit der das Bild während der Vorhersage auf --tsize geändert wird.
Nach Abschluss der Vorhersage druckt die Konsole den Speicherpfad des Ergebnisbilds aus, Benutzer können es öffnen und Schau es dir an. Wenn Sie für die Vorhersage ein Modell verwenden, das in einem benutzerdefinierten Trainingsdatensatz gespeichert ist, ändern Sie einfach -c in den Pfad Ihres Modells.
Wenn Sie alle Bilder in einem Ordner vorhersagen, führen Sie es im Projektstammverzeichnis aus:
Ändern Sie --path zum Pfad des entsprechenden Bildordners. 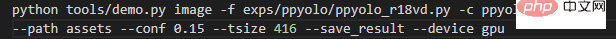
Trainings-COCO2017-Datensatz
Wenn Sie den ImageNet-Trainings-COCO-Datensatz für das Backbone-Netzwerk vor dem Training lesen, führen Sie ihn im Projektstammverzeichnis aus:
Ein Befehl startet direkt die Acht-Maschinen-Einzelmaschine. Kartentraining. Voraussetzung ist natürlich, dass Sie wirklich einen eigenständigen 8-Karten-Supercomputer haben. 
Die Bedeutung jedes Parameters ist:
-f stellt die verwendete Konfigurationsdatei dar;
-d stellt die Anzahl der Grafikkarten dar;
-b stellt die Stapelgröße dar (für
-eb stellt die Stapelgröße während der Auswertung dar (für alle Karten); --num_machines, die Anzahl der Maschinen, es wird empfohlen, mit mehreren Karten auf einer einzelnen Maschine zu trainieren;
--resume gibt an, ob es sich um ein Erholungstraining handelt;
Training eines benutzerdefinierten Datensatzes
Empfohlene Lektüre Verwenden Sie für das Training vorab trainierte COCO-Gewichte, da die Konvergenz schnell erfolgt.
Nehmen Sie den obigen VOC2012-Datensatz als Beispiel. Wenn es sich beim Modell ppyolo_r50vd um 1 Maschine und 1 Karte handelt, geben Sie den folgenden Befehl ein, um mit dem Training zu beginnen:
Wenn das Training für einige unterbrochen wird Aus diesem Grund möchten Sie lesen. Um das Training eines zuvor gespeicherten Modells fortzusetzen, ändern Sie einfach -c in den Pfad, in den Sie das Modell lesen möchten, und fügen Sie den Parameter --resume hinzu.
Wenn es sich um 2 Maschinen und 2 Karten handelt, also 1 Karte auf jeder Maschine, geben Sie auf Maschine 0 den folgenden Befehl ein:
und auf Maschine 1 folgenden Befehl: 
Ändern Sie einfach die 192.168.0.107 in den beiden obigen Befehlen in die LAN-IP von Maschine 0.
Wenn es sich um 1 Maschine und 2 Karten handelt, geben Sie den folgenden Befehl ein, um mit dem Training zu beginnen: 
 Übertragen Sie den Lern-VOC2012-Datensatz. Der gemessene AP von ppyolo_r50vd_2x (0,50:0,95) kann 0,59+ erreichen. AP (0,50) kann 0,82+ erreichen, AP (klein) kann 0,18+ erreichen. Unabhängig davon, ob es sich um eine einzelne Karte oder um mehrere Karten handelt, kann dieses Ergebnis erzielt werden.
Übertragen Sie den Lern-VOC2012-Datensatz. Der gemessene AP von ppyolo_r50vd_2x (0,50:0,95) kann 0,59+ erreichen. AP (0,50) kann 0,82+ erreichen, AP (klein) kann 0,18+ erreichen. Unabhängig davon, ob es sich um eine einzelne Karte oder um mehrere Karten handelt, kann dieses Ergebnis erzielt werden.
Während des Transferlernens hat es die gleiche Genauigkeit und Konvergenzgeschwindigkeit wie PaddleDetection. Die Trainingsprotokolle von beiden befinden sich im Ordner train_ppyolo_in_voc2012.
Wenn es sich um das ppyoloe_l-Modell handelt, geben Sie den folgenden Befehl auf einer einzelnen Maschine ein, um mit dem Training zu beginnen (Einfrieren des Backbone-Netzwerks).


Übertragen Sie den Lern-VOC2012-Datensatz, den gemessenen AP von ppyoloe_l (0,50:0,95 ) kann 0,66+ erreichen, AP (0,50) kann 0,85+ erreichen, AP (klein) kann 0,28+ erreichen.
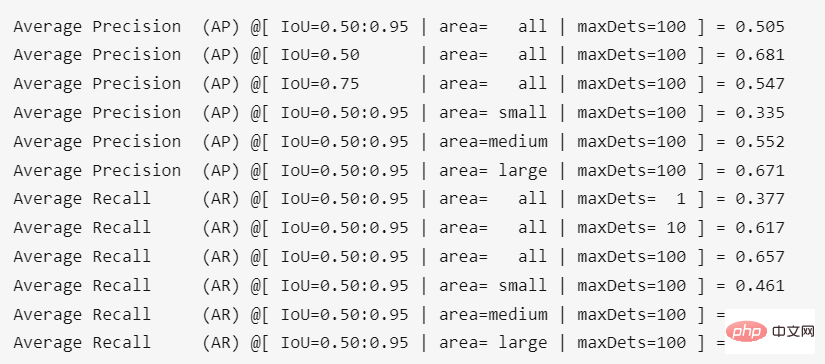
Auswertung
Befehle und spezifische Parameter sind wie folgt.Das Ergebnis der Ausführung im Projektstammverzeichnis ist: 
 #🎜🎜 ## 🎜🎜#
#🎜🎜 ## 🎜🎜#
Das obige ist der detaillierte Inhalt vonGitHub Open Source 130+Sterne: Bringen Sie Ihnen Schritt für Schritt bei, den Zielerkennungsalgorithmus basierend auf der PPYOLO-Serie zu reproduzieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1379
1379
 52
52

 Zehn empfohlene Open-Source-Tools für kostenlose Textanmerkungen
Mar 26, 2024 pm 08:20 PM
Zehn empfohlene Open-Source-Tools für kostenlose Textanmerkungen
Mar 26, 2024 pm 08:20 PM
Bei der Textanmerkung handelt es sich um die Arbeit mit entsprechenden Beschriftungen oder Tags für bestimmte Inhalte im Text. Sein Hauptzweck besteht darin, zusätzliche Informationen zum Text für eine tiefere Analyse und Verarbeitung bereitzustellen, insbesondere im Bereich der künstlichen Intelligenz. Textanmerkungen sind für überwachte maschinelle Lernaufgaben in Anwendungen der künstlichen Intelligenz von entscheidender Bedeutung. Es wird zum Trainieren von KI-Modellen verwendet, um Textinformationen in natürlicher Sprache genauer zu verstehen und die Leistung von Aufgaben wie Textklassifizierung, Stimmungsanalyse und Sprachübersetzung zu verbessern. Durch Textanmerkungen können wir KI-Modellen beibringen, Entitäten im Text zu erkennen, den Kontext zu verstehen und genaue Vorhersagen zu treffen, wenn neue ähnliche Daten auftauchen. In diesem Artikel werden hauptsächlich einige bessere Open-Source-Textanmerkungstools empfohlen. 1.LabelStudiohttps://github.com/Hu
 15 empfohlene kostenlose Open-Source-Bildanmerkungstools
Mar 28, 2024 pm 01:21 PM
15 empfohlene kostenlose Open-Source-Bildanmerkungstools
Mar 28, 2024 pm 01:21 PM
Bei der Bildanmerkung handelt es sich um das Verknüpfen von Beschriftungen oder beschreibenden Informationen mit Bildern, um dem Bildinhalt eine tiefere Bedeutung und Erklärung zu verleihen. Dieser Prozess ist entscheidend für maschinelles Lernen, das dabei hilft, Sehmodelle zu trainieren, um einzelne Elemente in Bildern genauer zu identifizieren. Durch das Hinzufügen von Anmerkungen zu Bildern kann der Computer die Semantik und den Kontext hinter den Bildern verstehen und so den Bildinhalt besser verstehen und analysieren. Die Bildanmerkung hat ein breites Anwendungsspektrum und deckt viele Bereiche ab, z. B. Computer Vision, Verarbeitung natürlicher Sprache und Diagramm-Vision-Modelle. Sie verfügt über ein breites Anwendungsspektrum, z. B. zur Unterstützung von Fahrzeugen bei der Identifizierung von Hindernissen auf der Straße und bei der Erkennung und Diagnose von Krankheiten durch medizinische Bilderkennung. In diesem Artikel werden hauptsächlich einige bessere Open-Source- und kostenlose Bildanmerkungstools empfohlen. 1.Makesens
 CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
Oben geschrieben und das persönliche Verständnis des Autors: Derzeit spielt das Wahrnehmungsmodul im gesamten autonomen Fahrsystem eine entscheidende Rolle Das Steuermodul im autonomen Fahrsystem trifft zeitnahe und korrekte Urteile und Verhaltensentscheidungen. Derzeit sind Autos mit autonomen Fahrfunktionen in der Regel mit einer Vielzahl von Dateninformationssensoren ausgestattet, darunter Rundumsichtkamerasensoren, Lidar-Sensoren und Millimeterwellenradarsensoren, um Informationen in verschiedenen Modalitäten zu sammeln und so genaue Wahrnehmungsaufgaben zu erfüllen. Der auf reinem Sehen basierende BEV-Wahrnehmungsalgorithmus wird von der Industrie aufgrund seiner geringen Hardwarekosten und einfachen Bereitstellung bevorzugt, und seine Ausgabeergebnisse können problemlos auf verschiedene nachgelagerte Aufgaben angewendet werden.
 Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Zu den häufigsten Herausforderungen, mit denen Algorithmen für maschinelles Lernen in C++ konfrontiert sind, gehören Speicherverwaltung, Multithreading, Leistungsoptimierung und Wartbarkeit. Zu den Lösungen gehören die Verwendung intelligenter Zeiger, moderner Threading-Bibliotheken, SIMD-Anweisungen und Bibliotheken von Drittanbietern sowie die Einhaltung von Codierungsstilrichtlinien und die Verwendung von Automatisierungstools. Praktische Fälle zeigen, wie man die Eigen-Bibliothek nutzt, um lineare Regressionsalgorithmen zu implementieren, den Speicher effektiv zu verwalten und leistungsstarke Matrixoperationen zu nutzen.
 Empfohlen: Ausgezeichnetes JS-Open-Source-Projekt zur Gesichtserkennung und -erkennung
Apr 03, 2024 am 11:55 AM
Empfohlen: Ausgezeichnetes JS-Open-Source-Projekt zur Gesichtserkennung und -erkennung
Apr 03, 2024 am 11:55 AM
Die Technologie zur Gesichtserkennung und -erkennung ist bereits eine relativ ausgereifte und weit verbreitete Technologie. Derzeit ist JS die am weitesten verbreitete Internetanwendungssprache. Die Implementierung der Gesichtserkennung und -erkennung im Web-Frontend hat im Vergleich zur Back-End-Gesichtserkennung Vor- und Nachteile. Zu den Vorteilen gehören die Reduzierung der Netzwerkinteraktion und die Echtzeiterkennung, was die Wartezeit des Benutzers erheblich verkürzt und das Benutzererlebnis verbessert. Die Nachteile sind: Es ist durch die Größe des Modells begrenzt und auch die Genauigkeit ist begrenzt. Wie implementiert man mit js die Gesichtserkennung im Web? Um die Gesichtserkennung im Web zu implementieren, müssen Sie mit verwandten Programmiersprachen und -technologien wie JavaScript, HTML, CSS, WebRTC usw. vertraut sein. Gleichzeitig müssen Sie auch relevante Technologien für Computer Vision und künstliche Intelligenz beherrschen. Dies ist aufgrund des Designs der Webseite erwähnenswert
 Das multimodale Dokumentenverständnis-Großmodell Alibaba 7B gewinnt neue SOTA
Apr 02, 2024 am 11:31 AM
Das multimodale Dokumentenverständnis-Großmodell Alibaba 7B gewinnt neue SOTA
Apr 02, 2024 am 11:31 AM
Neues SOTA für multimodale Dokumentverständnisfunktionen! Das Alibaba mPLUG-Team hat die neueste Open-Source-Arbeit mPLUG-DocOwl1.5 veröffentlicht, die eine Reihe von Lösungen zur Bewältigung der vier großen Herausforderungen der hochauflösenden Bildtexterkennung, des allgemeinen Verständnisses der Dokumentstruktur, der Befolgung von Anweisungen und der Einführung externen Wissens vorschlägt. Schauen wir uns ohne weitere Umschweife zunächst die Auswirkungen an. Ein-Klick-Erkennung und Konvertierung von Diagrammen mit komplexen Strukturen in das Markdown-Format: Es stehen Diagramme verschiedener Stile zur Verfügung: Auch eine detailliertere Texterkennung und -positionierung ist einfach zu handhaben: Auch ausführliche Erläuterungen zum Dokumentverständnis können gegeben werden: Sie wissen schon, „Document Understanding“. " ist derzeit ein wichtiges Szenario für die Implementierung großer Sprachmodelle. Es gibt viele Produkte auf dem Markt, die das Lesen von Dokumenten unterstützen. Einige von ihnen verwenden hauptsächlich OCR-Systeme zur Texterkennung und arbeiten mit LLM zur Textverarbeitung zusammen.
 Entdecken Sie die zugrunde liegenden Prinzipien und die Algorithmusauswahl der C++-Sortierfunktion
Apr 02, 2024 pm 05:36 PM
Entdecken Sie die zugrunde liegenden Prinzipien und die Algorithmusauswahl der C++-Sortierfunktion
Apr 02, 2024 pm 05:36 PM
Die unterste Ebene der C++-Sortierfunktion verwendet die Zusammenführungssortierung, ihre Komplexität beträgt O(nlogn) und bietet verschiedene Auswahlmöglichkeiten für Sortieralgorithmen, einschließlich schneller Sortierung, Heap-Sortierung und stabiler Sortierung.
 Gerade erschienen! Ein Open-Source-Modell zum Generieren von Bildern im Anime-Stil mit einem Klick
Apr 08, 2024 pm 06:01 PM
Gerade erschienen! Ein Open-Source-Modell zum Generieren von Bildern im Anime-Stil mit einem Klick
Apr 08, 2024 pm 06:01 PM
Lassen Sie mich Ihnen das neueste AIGC-Open-Source-Projekt vorstellen – AnimagineXL3.1. Dieses Projekt ist die neueste Version des Text-zu-Bild-Modells mit Anime-Thema und zielt darauf ab, Benutzern ein optimiertes und leistungsfähigeres Erlebnis bei der Generierung von Anime-Bildern zu bieten. Bei AnimagineXL3.1 konzentrierte sich das Entwicklungsteam auf die Optimierung mehrerer Schlüsselaspekte, um sicherzustellen, dass das Modell neue Höhen in Bezug auf Leistung und Funktionalität erreicht. Zunächst erweiterten sie die Trainingsdaten, um nicht nur Spielcharakterdaten aus früheren Versionen, sondern auch Daten aus vielen anderen bekannten Anime-Serien in das Trainingsset aufzunehmen. Dieser Schritt erweitert die Wissensbasis des Modells und ermöglicht ihm ein umfassenderes Verständnis verschiedener Anime-Stile und Charaktere. AnimagineXL3.1 führt eine neue Reihe spezieller Tags und Ästhetiken ein
