
 Technologie-Peripheriegeräte
KI
Graph-DETR3D: Überlappende Bereiche bei der 3D-Objekterkennung mit mehreren Ansichten überdenken
Technologie-Peripheriegeräte
KI
Graph-DETR3D: Überlappende Bereiche bei der 3D-Objekterkennung mit mehreren Ansichten überdenken
Graph-DETR3D: Überlappende Bereiche bei der 3D-Objekterkennung mit mehreren Ansichten überdenken

arXiv-Artikel „Graph-DETR3D: Rethinking Overlapping Regions for Multi-View 3D Object Detection“, 22. Juni, Arbeit der University of Science and Technology of China, des Harbin Institute of Technology und SenseTime.

Das Erkennen von 3D-Objekten aus mehreren Bildansichten ist eine grundlegende, aber anspruchsvolle Aufgabe beim visuellen Szenenverständnis. Aufgrund der geringen Kosten und der hohen Effizienz bietet die Multi-View-3D-Objekterkennung breite Anwendungsaussichten. Aufgrund des Mangels an Tiefeninformationen ist es jedoch äußerst schwierig, Objekte perspektivisch im 3D-Raum genau zu erkennen. Kürzlich führte DETR3D ein neues 3D-2D-Abfrageparadigma zur Aggregation von Mehransichtsbildern zur 3D-Objekterkennung ein und erreichte eine Leistung auf dem neuesten Stand der Technik.
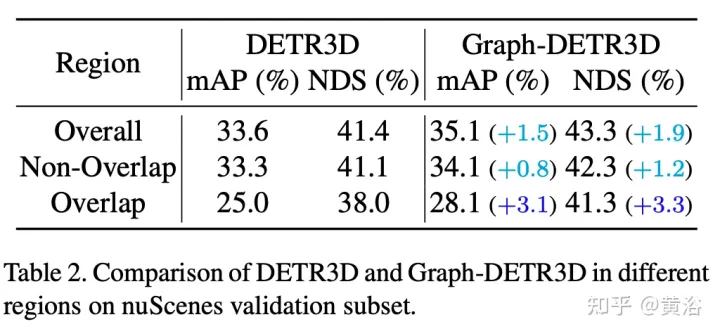
Durch intensive geführte Experimente quantifiziert dieser Artikel Ziele in verschiedenen Bereichen und stellt fest, dass „abgeschnittene Instanzen“ (d. h. die Grenzbereiche jedes Bildes) der Hauptengpass sind, der die Leistung von DETR3D beeinträchtigt. Trotz der Zusammenführung mehrerer Features aus zwei benachbarten Ansichten in überlappenden Regionen leidet DETR3D immer noch unter einer unzureichenden Feature-Aggregation und verpasst daher die Gelegenheit, die Erkennungsleistung vollständig zu verbessern.
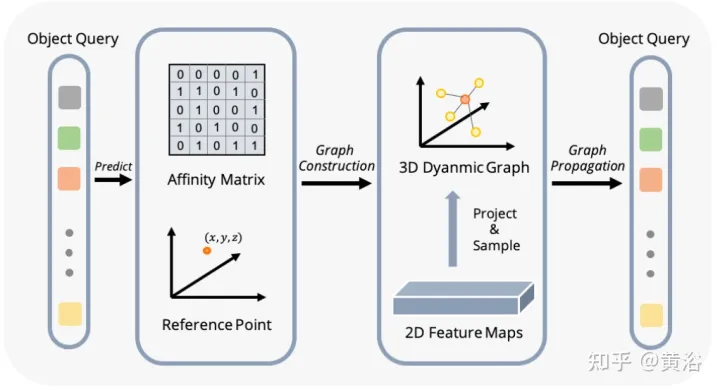
Um dieses Problem zu lösen, wird Graph-DETR3D vorgeschlagen, um Bildinformationen mit mehreren Ansichten durch Graph Structure Learning (GSL) automatisch zu aggregieren. Zwischen jeder Zielabfrage und der 2D-Feature-Map wird eine dynamische 3D-Karte erstellt, um die Zieldarstellung, insbesondere in Grenzregionen, zu verbessern. Darüber hinaus profitiert Graph-DETR3D von einer neuen tiefeninvarianten Multiskalen-Trainingsstrategie, die die visuelle Tiefenkonsistenz durch gleichzeitige Skalierung der Bildgröße und der Zieltiefe aufrechterhält.
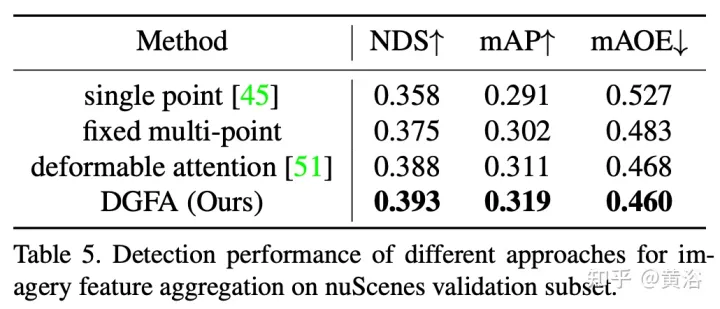
Graph-DETR3D unterscheidet sich in zwei Punkten, wie in der Abbildung gezeigt: (1) Aggregationsmodul dynamischer Diagrammfunktionen (2) tiefeninvariante Multiskalen-Trainingsstrategie. Es folgt der Grundstruktur von DETR3D und besteht aus drei Komponenten: Bild-Encoder, Transformator-Decoder und Zielvorhersagekopf. Bei einer Reihe von Bildern I = {I1, I2,…,IK} (aufgenommen von N Peri-View-Kameras) zielt Graph-DETR3D darauf ab, den Ort und die Kategorie des interessierenden Begrenzungsrahmens vorherzusagen. Verwenden Sie zunächst einen Bildencoder (einschließlich ResNet und FPN), um diese Bilder in einen Satz relativ L-Feature-Map-Level-Features F umzuwandeln. Anschließend wird ein dynamischer 3D-Graph erstellt, um 2D-Informationen über das DGFA-Modul (Dynamic Graph Feature Aggregation) umfassend zu aggregieren und so die Darstellung der Zielabfrage zu optimieren. Schließlich wird die erweiterte Zielabfrage verwendet, um die endgültige Vorhersage auszugeben.
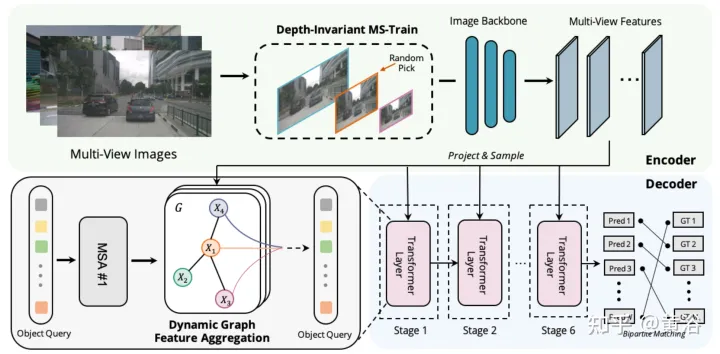
Die Abbildung zeigt den DFGA-Prozess (Dynamic Graph Feature Aggregation): Erstellen Sie zunächst ein lernbares 3D-Diagramm für jede Zielabfrage und probieren Sie dann Features aus der 2D-Bildebene aus. Schließlich wird die Darstellung der Zielabfrage durch Diagrammverbindungen verbessert. Dieses vernetzte Nachrichtenverbreitungsschema unterstützt die iterative Verfeinerung der Strukturkonstruktion des Graphen und die Funktionserweiterung.
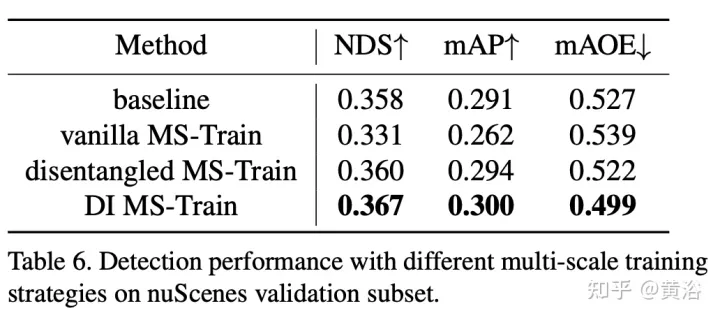
Multiskalentraining ist eine häufig verwendete Datenerweiterungsstrategie bei 2D- und 3D-Objekterkennungsaufgaben, die sich als effektive und kostengünstige Inferenz erwiesen hat. Bei visionsbasierten 3D-Inspektionsmethoden kommt es jedoch selten vor. Die Berücksichtigung unterschiedlicher Eingabebildgrößen kann die Robustheit des Modells verbessern, während gleichzeitig die Bildgröße angepasst und die internen Parameter der Kamera geändert werden, um eine gemeinsame Trainingsstrategie mit mehreren Maßstäben zu implementieren.
Ein interessantes Phänomen ist, dass die Endleistung stark abnimmt. Durch sorgfältige Analyse der Eingabedaten haben wir herausgefunden, dass eine einfache Neuskalierung des Bildes zu einem Problem der perspektivischen Mehrdeutigkeit führt: Wenn die Größe des Ziels auf einen größeren/kleineren Maßstab geändert wird, werden seine absoluten Eigenschaften (d. h. die Größe des Ziels, die Entfernung zum Ego) verändert Punkt) nicht ändern.
Als konkretes Beispiel zeigt die Abbildung dieses mehrdeutige Problem: Obwohl die absolute 3D-Position des ausgewählten Bereichs in (a) und (b) gleich ist, ist die Anzahl der Bildpixel unterschiedlich. Tiefenvorhersagenetzwerke neigen dazu, die Tiefe basierend auf dem eingenommenen Bereich des Bildes zu schätzen. Daher kann dieses Trainingsmuster in der Abbildung das Tiefenvorhersagemodell verwirren und die endgültige Leistung weiter verschlechtern.

Berechnen Sie hierfür die Tiefe aus Pixelperspektive neu. Der Pseudocode des Algorithmus lautet wie folgt:

Das Folgende ist die Dekodierungsoperation:

Die neu berechnete Pixelgröße lautet:
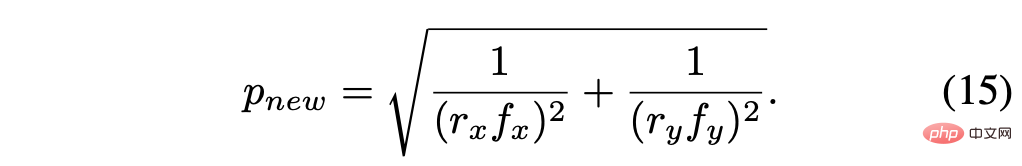
Unter der Annahme des Skalierungsfaktors r = rx = ry, vereinfacht Ergebnis ist:
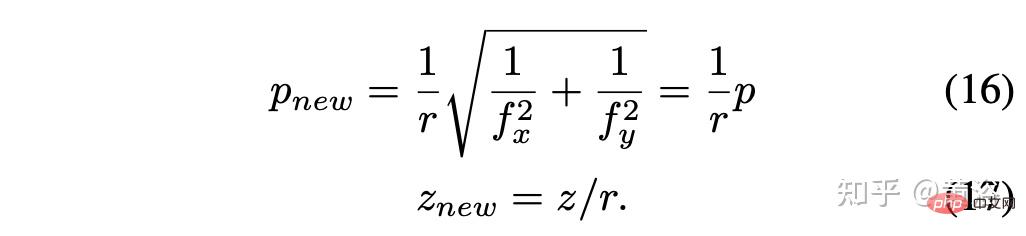
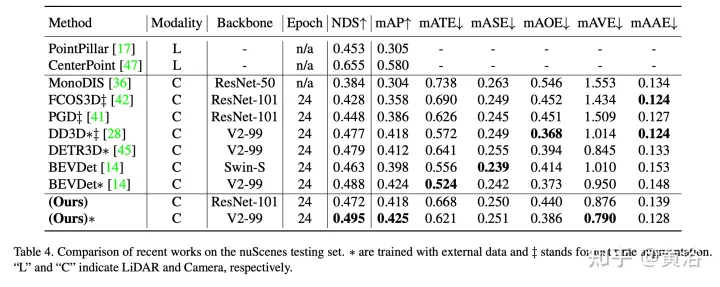
Die experimentellen Ergebnisse sind wie folgt:
 #🎜🎜 ##🎜 🎜#
#🎜🎜 ##🎜 🎜#
 Hinweis: DI = Tiefeninvariant
Hinweis: DI = Tiefeninvariant
Das obige ist der detaillierte Inhalt vonGraph-DETR3D: Überlappende Bereiche bei der 3D-Objekterkennung mit mehreren Ansichten überdenken. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Das Stable Diffusion 3-Papier wird endlich veröffentlicht und die architektonischen Details werden enthüllt. Wird es helfen, Sora zu reproduzieren?
Mar 06, 2024 pm 05:34 PM
Das Stable Diffusion 3-Papier wird endlich veröffentlicht und die architektonischen Details werden enthüllt. Wird es helfen, Sora zu reproduzieren?
Mar 06, 2024 pm 05:34 PM
Der Artikel von StableDiffusion3 ist endlich da! Dieses Modell wurde vor zwei Wochen veröffentlicht und verwendet die gleiche DiT-Architektur (DiffusionTransformer) wie Sora. Nach seiner Veröffentlichung sorgte es für großes Aufsehen. Im Vergleich zur Vorgängerversion wurde die Qualität der von StableDiffusion3 generierten Bilder erheblich verbessert. Es unterstützt jetzt Eingabeaufforderungen mit mehreren Themen, und der Textschreibeffekt wurde ebenfalls verbessert, und es werden keine verstümmelten Zeichen mehr angezeigt. StabilityAI wies darauf hin, dass es sich bei StableDiffusion3 um eine Reihe von Modellen mit Parametergrößen von 800 M bis 8 B handelt. Durch diesen Parameterbereich kann das Modell direkt auf vielen tragbaren Geräten ausgeführt werden, wodurch der Einsatz von KI deutlich reduziert wird
 Beherrschen Sie die Koordinatensystemkonvertierung wirklich? Multisensorik-Themen, die für das autonome Fahren unverzichtbar sind
Oct 12, 2023 am 11:21 AM
Beherrschen Sie die Koordinatensystemkonvertierung wirklich? Multisensorik-Themen, die für das autonome Fahren unverzichtbar sind
Oct 12, 2023 am 11:21 AM
Der erste Pilot- und Schlüsselartikel stellt hauptsächlich mehrere häufig verwendete Koordinatensysteme in der autonomen Fahrtechnologie vor und erläutert, wie die Korrelation und Konvertierung zwischen ihnen abgeschlossen und schließlich ein einheitliches Umgebungsmodell erstellt werden kann. Der Schwerpunkt liegt hier auf dem Verständnis der Umrechnung vom Fahrzeug in den starren Kamerakörper (externe Parameter), der Kamera-in-Bild-Konvertierung (interne Parameter) und der Bild-in-Pixel-Einheitenkonvertierung. Die Konvertierung von 3D in 2D führt zu entsprechenden Verzerrungen, Verschiebungen usw. Wichtige Punkte: Das Fahrzeugkoordinatensystem und das Kamerakörperkoordinatensystem müssen neu geschrieben werden: Das Ebenenkoordinatensystem und das Pixelkoordinatensystem. Schwierigkeit: Sowohl die Entzerrung als auch die Verzerrungsaddition müssen auf der Bildebene kompensiert werden. 2. Einführung Insgesamt gibt es vier visuelle Systeme Koordinatensystem: Pixelebenenkoordinatensystem (u, v), Bildkoordinatensystem (x, y), Kamerakoordinatensystem () und Weltkoordinatensystem (). Es gibt eine Beziehung zwischen jedem Koordinatensystem,
 Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Die Trajektorienvorhersage spielt eine wichtige Rolle beim autonomen Fahren. Unter autonomer Fahrtrajektorienvorhersage versteht man die Vorhersage der zukünftigen Fahrtrajektorie des Fahrzeugs durch die Analyse verschiedener Daten während des Fahrvorgangs. Als Kernmodul des autonomen Fahrens ist die Qualität der Trajektorienvorhersage von entscheidender Bedeutung für die nachgelagerte Planungssteuerung. Die Trajektorienvorhersageaufgabe verfügt über einen umfangreichen Technologie-Stack und erfordert Vertrautheit mit der dynamischen/statischen Wahrnehmung des autonomen Fahrens, hochpräzisen Karten, Fahrspurlinien, Fähigkeiten in der neuronalen Netzwerkarchitektur (CNN&GNN&Transformer) usw. Der Einstieg ist sehr schwierig! Viele Fans hoffen, so schnell wie möglich mit der Flugbahnvorhersage beginnen zu können und Fallstricke zu vermeiden. Heute werde ich eine Bestandsaufnahme einiger häufiger Probleme und einführender Lernmethoden für die Flugbahnvorhersage machen! Einführungsbezogenes Wissen 1. Sind die Vorschaupapiere in Ordnung? A: Schauen Sie sich zuerst die Umfrage an, S
 Redundante Begrenzungsrahmenanmerkung mit mehreren Gittern für eine genaue Objekterkennung
Jun 01, 2024 pm 09:46 PM
Redundante Begrenzungsrahmenanmerkung mit mehreren Gittern für eine genaue Objekterkennung
Jun 01, 2024 pm 09:46 PM
1. Einleitung Derzeit sind die führenden Objektdetektoren zweistufige oder einstufige Netzwerke, die auf dem umfunktionierten Backbone-Klassifizierungsnetzwerk von Deep CNN basieren. YOLOv3 ist ein solcher bekannter hochmoderner einstufiger Detektor, der ein Eingabebild empfängt und es in eine gleich große Gittermatrix aufteilt. Für die Erkennung spezifischer Ziele sind Gitterzellen mit Zielzentren zuständig. Was ich heute vorstelle, ist eine neue mathematische Methode, die jedem Ziel mehrere Gitter zuordnet, um eine genaue Vorhersage des Begrenzungsrahmens zu erreichen. Die Forscher schlugen außerdem eine effektive Offline-Datenverbesserung durch Kopieren und Einfügen für die Zielerkennung vor. Die neu vorgeschlagene Methode übertrifft einige aktuelle Objektdetektoren auf dem neuesten Stand der Technik deutlich und verspricht eine bessere Leistung. 2. Das Hintergrundzielerkennungsnetzwerk ist für die Verwendung konzipiert
 Neues SOTA zur Zielerkennung: YOLOv9 erscheint und die neue Architektur erweckt die traditionelle Faltung wieder zum Leben
Feb 23, 2024 pm 12:49 PM
Neues SOTA zur Zielerkennung: YOLOv9 erscheint und die neue Architektur erweckt die traditionelle Faltung wieder zum Leben
Feb 23, 2024 pm 12:49 PM
Im Bereich der Zielerkennung macht YOLOv9 weiterhin Fortschritte im Implementierungsprozess. Durch die Einführung neuer Architekturen und Methoden wird die Parameternutzung der herkömmlichen Faltung effektiv verbessert, wodurch die Leistung den Produkten der vorherigen Generation weit überlegen ist. Mehr als ein Jahr nach der offiziellen Veröffentlichung von YOLOv8 im Januar 2023 ist YOLOv9 endlich da! Seit Joseph Redmon, Ali Farhadi und andere im Jahr 2015 das YOLO-Modell der ersten Generation vorgeschlagen haben, haben Forscher auf dem Gebiet der Zielerkennung es viele Male aktualisiert und iteriert. YOLO ist ein Vorhersagesystem, das auf globalen Bildinformationen basiert und dessen Modellleistung kontinuierlich verbessert wird. Durch die kontinuierliche Verbesserung von Algorithmen und Technologien haben Forscher bemerkenswerte Ergebnisse erzielt, die YOLO bei Zielerkennungsaufgaben immer leistungsfähiger machen.
 DualBEV: BEVFormer und BEVDet4D deutlich übertreffen, öffnen Sie das Buch!
Mar 21, 2024 pm 05:21 PM
DualBEV: BEVFormer und BEVDet4D deutlich übertreffen, öffnen Sie das Buch!
Mar 21, 2024 pm 05:21 PM
In diesem Artikel wird das Problem der genauen Erkennung von Objekten aus verschiedenen Blickwinkeln (z. B. Perspektive und Vogelperspektive) beim autonomen Fahren untersucht, insbesondere wie die Transformation von Merkmalen aus der Perspektive (PV) in den Raum aus der Vogelperspektive (BEV) effektiv ist implementiert über das Modul Visual Transformation (VT). Bestehende Methoden lassen sich grob in zwei Strategien unterteilen: 2D-zu-3D- und 3D-zu-2D-Konvertierung. 2D-zu-3D-Methoden verbessern dichte 2D-Merkmale durch die Vorhersage von Tiefenwahrscheinlichkeiten, aber die inhärente Unsicherheit von Tiefenvorhersagen, insbesondere in entfernten Regionen, kann zu Ungenauigkeiten führen. Während 3D-zu-2D-Methoden normalerweise 3D-Abfragen verwenden, um 2D-Features abzutasten und die Aufmerksamkeitsgewichte der Korrespondenz zwischen 3D- und 2D-Features über einen Transformer zu lernen, erhöht sich die Rechen- und Bereitstellungszeit.
 Das erste Weltmodell zur Erzeugung autonomer Fahrszenen mit mehreren Ansichten | DrivingDiffusion: Neue Ideen für BEV-Daten und Simulation
Oct 23, 2023 am 11:13 AM
Das erste Weltmodell zur Erzeugung autonomer Fahrszenen mit mehreren Ansichten | DrivingDiffusion: Neue Ideen für BEV-Daten und Simulation
Oct 23, 2023 am 11:13 AM
Einige persönliche Gedanken des Autors Im Bereich des autonomen Fahrens sind mit der Entwicklung BEV-basierter Teilaufgaben/End-to-End-Lösungen hochwertige Multi-View-Trainingsdaten und der entsprechende Aufbau von Simulationsszenen immer wichtiger geworden. Als Reaktion auf die Schwachstellen aktueller Aufgaben kann „hohe Qualität“ in drei Aspekte zerlegt werden: Long-Tail-Szenarien in verschiedenen Dimensionen: z. B. Nahbereichsfahrzeuge in Hindernisdaten und präzise Kurswinkel beim Schneiden von Autos sowie Spurliniendaten . Szenen wie Kurven mit unterschiedlichen Krümmungen oder Rampen/Zusammenführungen/Zusammenführungen, die schwer zu erfassen sind. Diese basieren häufig auf der Sammlung großer Datenmengen und komplexen Data-Mining-Strategien, die kostspielig sind. Echter 3D-Wert – hochkonsistentes Bild: Die aktuelle BEV-Datenerfassung wird häufig durch Fehler bei der Sensorinstallation/-kalibrierung, hochpräzisen Karten und dem Rekonstruktionsalgorithmus selbst beeinträchtigt. das hat mich dazu geführt
 GSLAM |. Eine allgemeine SLAM-Architektur und ein Benchmark
Oct 20, 2023 am 11:37 AM
GSLAM |. Eine allgemeine SLAM-Architektur und ein Benchmark
Oct 20, 2023 am 11:37 AM
Plötzlich wurde ein 19 Jahre altes Papier namens GSLAM: A General SLAM Framework and Benchmark mit offenem Quellcode entdeckt: https://github.com/zdzhaoyong/GSLAM Gehen Sie direkt zum Volltext und spüren Sie die Qualität dieser Arbeit~1 Zusammenfassung der SLAM-Technologie hat in letzter Zeit viele Erfolge erzielt und die Aufmerksamkeit vieler High-Tech-Unternehmen auf sich gezogen. Es bleibt jedoch eine Frage, wie eine Schnittstelle zu bestehenden oder neuen Algorithmen hergestellt werden kann, um ein Benchmarking hinsichtlich Geschwindigkeit, Robustheit und Portabilität effizient durchzuführen. In diesem Artikel wird eine neue SLAM-Plattform namens GSLAM vorgeschlagen, die nicht nur Evaluierungsfunktionen bietet, sondern Forschern auch eine nützliche Möglichkeit bietet, schnell ihre eigenen SLAM-Systeme zu entwickeln.
