
 Technologie-Peripheriegeräte
KI
ICRA 2022 Outstanding Paper: Durch die Umwandlung von 2D-Bildern des autonomen Fahrens in eine Vogelperspektive erhöht sich die Modellerkennungsgenauigkeit um 15 %
Technologie-Peripheriegeräte
KI
ICRA 2022 Outstanding Paper: Durch die Umwandlung von 2D-Bildern des autonomen Fahrens in eine Vogelperspektive erhöht sich die Modellerkennungsgenauigkeit um 15 %
ICRA 2022 Outstanding Paper: Durch die Umwandlung von 2D-Bildern des autonomen Fahrens in eine Vogelperspektive erhöht sich die Modellerkennungsgenauigkeit um 15 %

Viele Aufgaben beim autonomen Fahren lassen sich leichter von oben nach unten, auf der Karte oder aus der Vogelperspektive (BEV) erledigen. Da viele Themen rund um das autonome Fahren auf die Bodenebene beschränkt sind, ist eine Draufsicht eine praktischere niedrigdimensionale Darstellung und eignet sich ideal für die Navigation, um relevante Hindernisse und Gefahren zu erfassen. Für Szenarien wie autonomes Fahren müssen semantisch segmentierte BEV-Karten als sofortige Schätzungen generiert werden, um frei bewegliche Objekte und Szenen zu verarbeiten, die nur einmal besucht werden.
Um eine BEV-Karte aus einem Bild abzuleiten, muss man die Entsprechung zwischen Bildelementen und ihren Positionen in der Umgebung bestimmen. Einige frühere Untersuchungen verwendeten dichte Tiefenkarten und Bildsegmentierungskarten, um diesen Konvertierungsprozess zu steuern, und einige Untersuchungen erweiterten die Methode der impliziten Analyse von Tiefe und Semantik. Einige Studien nutzen geometrische Prioritäten der Kamera, lernen jedoch nicht explizit die Interaktion zwischen Bildelementen und BEV-Ebenen.
In einem aktuellen Artikel stellten Forscher der University of Surrey einen Aufmerksamkeitsmechanismus vor, um 2D-Bilder des autonomen Fahrens in eine Vogelperspektive umzuwandeln und so das Modell zu erkennen Genauigkeit um 15 % erhöht. Diese Forschung wurde auf der ICRA-Konferenz 2022, die vor kurzem zu Ende ging, mit dem Outstanding Paper Award ausgezeichnet.

Papierlink: https://arxiv.org/pdf/2110.00966.pdf#🎜 🎜#

Anders als frühere Methoden kombiniert diese Studie BEV Die Umrechnung ist Wird als „Image-to-World“-Konvertierungsproblem angesehen , dessen Ziel darin besteht, die vertikalen Scanlinien im Bild und die vertikalen Scanlinien in der BEV-Ausrichtung zu lernen zwischen Polarstrahlen. Daher ist diese projektive Geometrie implizit für das Netzwerk.
Im Ausrichtungsmodell verwendeten die Forscher Transformer, eine aufmerksamkeitsbasierte Sequenzvorhersagestruktur#🎜🎜 ## 🎜🎜#. Mithilfe ihres Aufmerksamkeitsmechanismus modellieren wir explizit die paarweise Interaktion zwischen vertikalen Scanlinien in einem Bild und ihren polaren BEV-Projektionen. Transformer eignen sich ideal für Bild-zu-BEV-Übersetzungsprobleme, da sie über die gegenseitigen Abhängigkeiten zwischen Objekten, Tiefe und Szenenbeleuchtung nachdenken können, um global konsistente Darstellungen zu erzielen. Die Forscher betten das Transformer-basierte Ausrichtungsmodell in eine End-to-End-Lernformel ein, die monokulare Bilder und deren Intrinsik verwendet Die Matrix wird als Eingabe verwendet und dann wird die semantische BEV-Zuordnung statischer und dynamischer Klassen vorhergesagt.
Dieses Papier erstellt eine Architektur, die dabei hilft, die semantische BEV-Zuordnung aus monokularen Bildern um ein Ausrichtungsmodell vorherzusagen. Wie in Abbildung 1 unten dargestellt, enthält es drei Hauptkomponenten: ein Standard-CNN-Backbone zum Extrahieren räumlicher Merkmale auf der Bildebene; einen Encoder-Decoder-Transformer zum Konvertieren der Merkmale auf der Bildebene in BEV-Merkmale; in semantische Karten.
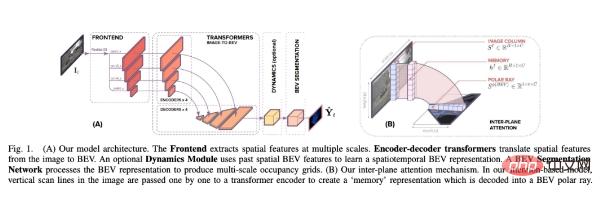
 Im Einzelnen ist der Hauptbeitrag dieser Studie:
Im Einzelnen ist der Hauptbeitrag dieser Studie:
- (1) Verwenden Sie eine Reihe von 1D-Sequenz-Sequenz-Konvertierungen, um eine BEV-Karte aus einem Bild zu generieren.
- (2) Erstellen Sie ein eingeschränktes dateneffizientes Transformer-Netzwerk mit räumlichen Wahrnehmungsfunktionen der Formel (3) und der monotonen Aufmerksamkeit im Sprachbereich zeigen, dass es für eine genaue Zuordnung wichtiger ist, zu wissen, was sich unter einem Punkt im Bild befindet, als zu wissen, was darüber liegt, obwohl die Verwendung beider zur besten Leistung führt
- (4) zeigt, wie axiale Aufmerksamkeit die Leistung verbessert, indem sie zeitliches Bewusstsein schafft, und präsentiert hochmoderne Ergebnisse zu drei großen Datensätzen.
- Experimentelle Ergebnisse
Ablationsexperiment
Wie im ersten Teil der Tabelle 2 unten gezeigt, verglichen die Forscher sanfte Aufmerksamkeit (in beide Richtungen schauen), monotone Aufmerksamkeit beim Zurückverfolgen des Bildes unten (Blick nach unten) und beim Zurückverfolgen des Bildes oben (Blick). nach oben) monotone Aufmerksamkeit.
Es stellt sich heraus, dass es besser ist, von einem Punkt im Bild nach unten zu schauen, als nach oben zu schauen.Entlang lokaler Texturhinweise – Dies steht im Einklang mit der Art und Weise, wie Menschen versuchen, die Entfernung von Objekten in städtischen Umgebungen zu bestimmen. Wir verwenden die Stelle, an der das Objekt die Bodenebene schneidet. Die Ergebnisse zeigen auch, dass die Beobachtung in beide Richtungen die Genauigkeit weiter verbessert und tiefe Schlussfolgerungen diskriminierender macht.

Die Bild-zu-BEV-Konvertierung erfolgt hier als eine Reihe von 1D-Sequenz-zu-Sequenz-Konvertierungen. Eine Frage ist also, was passiert, wenn das gesamte Bild in BEV konvertiert wird. Angesichts der sekundären Rechenzeit und des Speichers, die zum Generieren von Aufmerksamkeitskarten erforderlich sind, ist dieser Ansatz unerschwinglich teuer. Die kontextbezogenen Vorteile der Verwendung des gesamten Bildes können jedoch angenähert werden, indem die horizontale axiale Aufmerksamkeit auf Bildebenenmerkmale gerichtet wird. Bei axialer Aufmerksamkeit durch die Bildzeilen haben Pixel in vertikalen Scanzeilen jetzt einen weitreichenden horizontalen Kontext, und dann wird ein weitreichender vertikaler Kontext durch den Übergang zwischen 1D-Sequenzen wie zuvor bereitgestellt. Wie im mittleren Teil von Tabelle 2 gezeigt,
das Zusammenführen von Kontexten auf langer Sequenzebene kommt dem Modell nicht zuguteund hat sogar eine leichte nachteilige Wirkung. Dies verdeutlicht zwei Punkte: Erstens erfordert jeder transformierte Strahl keine Informationen über die gesamte Breite des Eingabebilds, oder vielmehr liefert der lange Sequenzkontext keine zusätzlichen Informationen im Vergleich zu dem Kontext, der bereits durch die Front-End-Faltung aggregiert wurde . Dies zeigt, dass die Verwendung des gesamten Bildes zur Durchführung der Transformation die Modellgenauigkeit nicht über die Grundlinienbeschränkungsformel hinaus verbessert. Darüber hinaus bedeutet die durch die Einführung horizontaler axialer Aufmerksamkeit verursachte Leistungseinbuße, dass es schwierig ist, die Aufmerksamkeit auf die Trainingssequenzen der Bildbreite zu verwenden Wie man sieht, wird es schwieriger sein, das gesamte Bild als Eingabesequenz zu trainieren.
Polaragnostische vs. polaradaptive Transformatoren: Der letzte Teil von Tabelle 2 vergleicht Po-Ag- und Po-Ad-Varianten. Ein Po-Ag-Modell verfügt über keine Polarisationspositionsinformationen, das Po-Ad der Bildebene enthält Polarkodierungen, die dem Transformer-Encoder hinzugefügt wurden, und für die BEV-Ebene werden diese Informationen dem Decoder hinzugefügt. Das Hinzufügen polarer Kodierungen zu beiden Ebenen ist vorteilhafter als das Hinzufügen zum agnostischen Modell, wobei die dynamische Klasse den größten Beitrag leistet. Das Hinzufügen zu beiden Ebenen verstärkt dies noch weiter, hat jedoch die größte Auswirkung auf statische Klassen. Vergleich mit SOTA-Methoden
Die Forscher verglichen diese Methode mit einigen SOTA-Methoden.
Wie in Tabelle 1 unten gezeigt, ist die Leistung des räumlichen Modells besser als die der aktuellen komprimierten SOTA-Methode STA-S, mit einer durchschnittlichen relativen Verbesserung von 15 %. Bei den kleineren dynamischen Klassen ist die Verbesserung sogar noch deutlicher, da die Genauigkeit der Bus-, LKW-, Anhänger- und Hinderniserkennung um relative 35–45 % zunimmt. Die in Abbildung 2 unten erhaltenen qualitativen Ergebnisse stützen diese Schlussfolgerung ebenfalls. Das Modell in diesem Artikel zeigt eine größere strukturelle Ähnlichkeit und ein besseres Formgefühl. Dieser Unterschied kann teilweise auf die für die Komprimierung verwendeten vollständig verbundenen Schichten (FCL) zurückgeführt werden: Bei der Erkennung kleiner und entfernter Objekte ist ein Großteil des Bildes redundanter Kontext. Darüber hinaus werden Fußgänger und andere Objekte häufig teilweise von Fahrzeugen blockiert. In diesem Fall wird die vollständig verbundene Schicht dazu neigen, Fußgänger zu ignorieren und stattdessen die Semantik von Fahrzeugen beizubehalten. Hier zeigt die Aufmerksamkeitsmethode ihren Vorteil, da jede radiale Tiefe unabhängig vom Bild wahrgenommen werden kann – sodass tiefere Tiefen die Körper von Fußgängern sichtbar machen können, während frühere Tiefen nur Fahrzeuge wahrnehmen können. Die Ergebnisse des Argoverse-Datensatzes in Tabelle 3 unten zeigen ein ähnliches Muster, bei dem sich unsere Methode im Vergleich zu PON [8] um 30 % verbessert. Wie in Tabelle 4 unten gezeigt, ist die Leistung dieser Methode auf nuScenes und Lyft besser als bei LSS [9 ] und FIERY [20]. Ein echter Vergleich ist bei Lyft nicht möglich, da es keine kanonische Zug-/Val-Aufteilung gibt und es keine Möglichkeit gibt, die Aufteilung von LSS zu nutzen. Weitere Forschungsdetails finden Sie im Originalpapier. 



Das obige ist der detaillierte Inhalt vonICRA 2022 Outstanding Paper: Durch die Umwandlung von 2D-Bildern des autonomen Fahrens in eine Vogelperspektive erhöht sich die Modellerkennungsgenauigkeit um 15 %. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1205
24
52
1205
24

 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Im vergangenen Monat hatte ich aus bekannten Gründen einen sehr intensiven Austausch mit verschiedenen Lehrern und Mitschülern der Branche. Ein unvermeidliches Thema im Austausch ist natürlich End-to-End und der beliebte Tesla FSDV12. Ich möchte diese Gelegenheit nutzen, einige meiner aktuellen Gedanken und Meinungen als Referenz und Diskussion darzulegen. Wie definiert man ein durchgängiges autonomes Fahrsystem und welche Probleme sollten voraussichtlich durchgängig gelöst werden? Gemäß der traditionellsten Definition bezieht sich ein End-to-End-System auf ein System, das Rohinformationen von Sensoren eingibt und für die Aufgabe relevante Variablen direkt ausgibt. Bei der Bilderkennung kann CNN beispielsweise als End-to-End bezeichnet werden, verglichen mit der herkömmlichen Methode zum Extrahieren von Merkmalen + Klassifizieren. Bei autonomen Fahraufgaben werden Eingabedaten verschiedener Sensoren (Kamera/LiDAR) benötigt
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
