
 Technologie-Peripheriegeräte
KI
Ausführlicher Bericht: Große modellgesteuerte KI beschleunigt sich auf ganzer Linie! Das goldene Jahrzehnt beginnt
Technologie-Peripheriegeräte
KI
Ausführlicher Bericht: Große modellgesteuerte KI beschleunigt sich auf ganzer Linie! Das goldene Jahrzehnt beginnt
Ausführlicher Bericht: Große modellgesteuerte KI beschleunigt sich auf ganzer Linie! Das goldene Jahrzehnt beginnt

Nach den „drei Höhen und zwei Tiefen“ in den letzten 70 Jahren, mit der Verbesserung und dem Fortschritt der zugrunde liegenden Chips, Rechenleistung, Daten und anderen Infrastrukturen, bewegt sich die globale KI-Branche allmählich von rechnerischer Intelligenz zu wahrnehmungsbezogener Intelligenz und kognitiver Intelligenz. und bildete dementsprechend ein industrielles Arbeitsteilungs- und Kollaborationssystem „Chip, Rechenleistungseinrichtungen, KI-Framework und Algorithmusmodelle, Anwendungsszenarien“. Seit 2019 haben große KI-Modelle die Fähigkeit zur Verallgemeinerung von Problemlösungen erheblich verbessert, und „große Modelle + kleine Modelle“ haben sich nach und nach zum Mainstream-Technologieweg in der Branche entwickelt, was die allgemeine Beschleunigung der Entwicklung der globalen KI-Branche vorantreibt und eine bildet „Chip + Rechenleistungsinfrastruktur + KI“ Die stabile industrielle Wertschöpfungskettenstruktur von „Framework & Algorithmenbibliothek + Anwendungsszenarien“.
Als intelligente interne Referenz dieser Ausgabe empfehlen wir den Bericht „Large Models Drive AI to Accelerate Comprehensively, and the Industry's Golden Ten-Year Investment Cycle Begins“ von CITIC Securities, um den aktuellen Status der Branche der künstlichen Intelligenz und Kernthemen in der Branche zu interpretieren Entwicklung. Quelle: CITIC Securities
1. Die „drei Höhen und drei Tiefen“ der künstlichen Intelligenz
Seit das Konzept und die Theorie der „künstlichen Intelligenz“ erstmals im Jahr 1956 vorgeschlagen wurden, verlief die Entwicklung der KI-Industrie und -Technologie hauptsächlich in drei Hauptbereichen Entwicklungsstadien.
1) 20Jahrhundert50Ära~20 Jahrhundert 70Ära: abhängig von Rechenleistung, Datenvolumen usw., mehr Bleiben Sie in der Theorie Niveau. Die Dartmouth-Konferenz im Jahr 1956 förderte die Entstehung der weltweit ersten Welle künstlicher Intelligenz. Damals herrschte in der gesamten akademischen Welt eine optimistische Atmosphäre, und es entstanden viele Weltklasse-Erfindungen in Bezug auf Algorithmen, darunter ein Prototyp namens Reinforcement Learning. Reinforcement Learning ist die Kernidee des AlphaGo-Algorithmus von Google. In den frühen 1970er Jahren stieß die KI auf einen Engpass: Man stellte fest, dass Logikbeweiser, Perzeptrone, Verstärkungslernen usw. nur sehr einfache und eng begrenzte Aufgaben erledigen konnten und Aufgaben, die leicht über ihren Rahmen hinausgingen, nicht bewältigen konnten. Der begrenzte Speicher und die Verarbeitungsgeschwindigkeit der damaligen Computer reichten nicht aus, um praktische KI-Probleme zu lösen. Die Komplexität dieser Berechnungen nimmt exponentiell zu und macht sie zu einer unmöglichen Rechenaufgabe. Expertensystem ist der erste Kommerzialisierungsversuch künstlicher Intelligenz, hoch
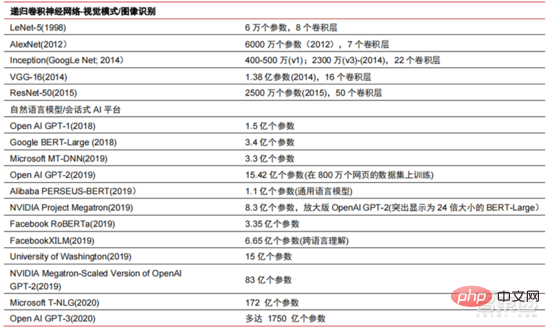
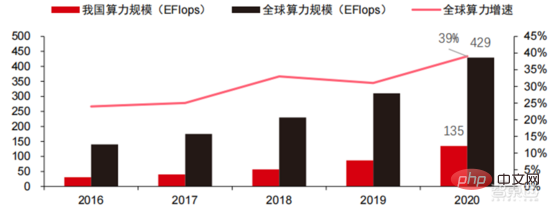
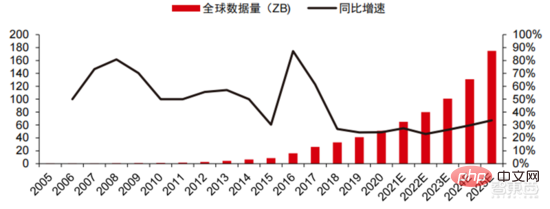
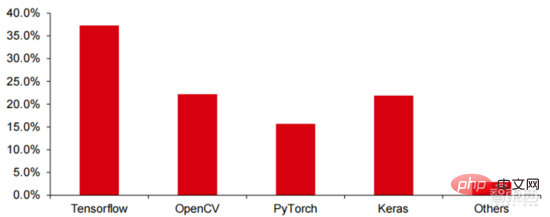
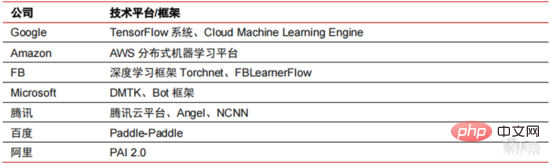
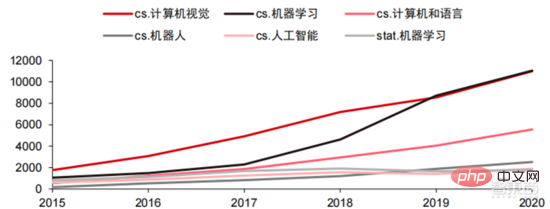
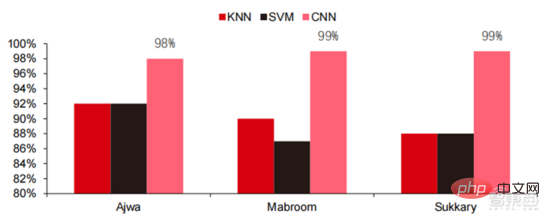
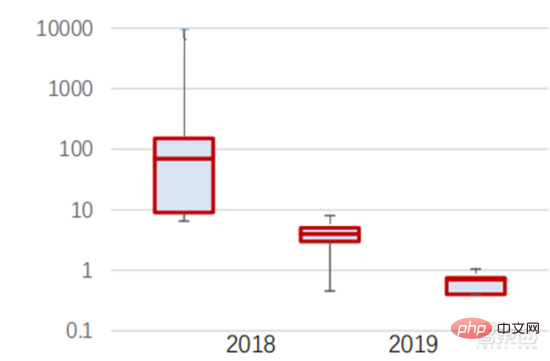
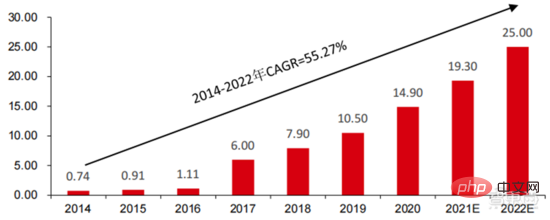
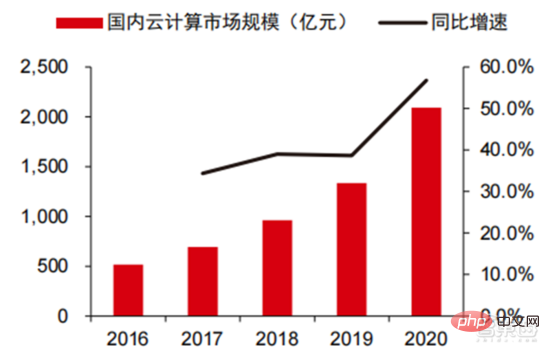
Ang Die hohen Hardwarekosten und begrenzten anwendbaren Szenarien schränken die weitere Entwicklung des Marktes ein. In den 1980er Jahren begannen Unternehmen auf der ganzen Welt, Expertensystem-KI-Programme einzuführen, und die „Wissensverarbeitung“ rückte in den Mittelpunkt der Mainstream-KI-Forschung. Die Fähigkeiten von Expertensystemen ergeben sich aus dem Fachwissen, das sie speichern, und Wissensbasissysteme und Knowledge Engineering wurden in den 1980er Jahren zu den Hauptrichtungen der KI-Forschung. Allerdings ist die Praktikabilität von Expertensystemen auf bestimmte Situationen beschränkt und die Begeisterung der Menschen für Expertensysteme wandelte sich bald in große Enttäuschung. Andererseits war die Einführung moderner PCs zwischen 1987 und 1993 weitaus kostengünstiger als Maschinen wie Symbolics und Lisp, die von Expertensystemen verwendet werden. Im Vergleich zu modernen PCs gelten Expertensysteme als veraltet und sehr schwer zu warten. Infolgedessen begannen die staatlichen Mittel zu sinken und der Winter kam erneut. 3) 2015Jahr bis heute: Allmähliche Bildung eines vollständigen Systems der Arbeitsteilung und Zusammenarbeit in der Industriekette. Das dritte bahnbrechende Ereignis in der künstlichen Intelligenz ereignete sich im März 2016. AlphaGo, entwickelt von Google DeepMind, besiegte den koreanischen Profi-Neun-Dan-Spieler Lee Sedol in einem Go-Kampf zwischen Mensch und Maschine. Anschließend wurde die Öffentlichkeit mit künstlicher Intelligenz vertraut gemacht und Begeisterung in verschiedenen Bereichen geweckt. Durch diesen Vorfall wurde ein Deep-Learning-Modell zur statistischen Klassifizierung basierend auf dem neuronalen DNN-Netzwerkalgorithmus erstellt. Dieser Modelltyp ist allgemeiner als in der Vergangenheit und kann durch unterschiedliche Merkmalswertextraktion auf verschiedene Anwendungsszenarien angewendet werden. Gleichzeitig brachte die Popularität des mobilen Internets von 2010 bis 2015 auch eine beispiellose Datenversorgung für Deep-Learning-Algorithmen. Dank der Zunahme des Datenvolumens, der Verbesserung der Rechenleistung und der Entstehung neuer Algorithmen für maschinelles Lernen hat die künstliche Intelligenz begonnen, große Anpassungen zu erfahren. Auch das Forschungsfeld der künstlichen Intelligenz erweitert sich und umfasst Expertensysteme, maschinelles Lernen, evolutionäres Rechnen, Fuzzy-Logik, Computer Vision, Verarbeitung natürlicher Sprache, Empfehlungssysteme usw. Die Entwicklung des Deep Learning hat die künstliche Intelligenz auf einen neuen Entwicklungshöhepunkt gebracht. ▲ Die dritte Welle der Entwicklung künstlicher IntelligenzDie dritte Welle der künstlichen Intelligenz hat uns eine Reihe von Szenarien beschert, die kommerzialisiert werden können. Die herausragende Leistung des DNN-Algorithmus hat dazu geführt, dass Spracherkennung und Bilderkennung in diesen Bereichen einen Beitrag leisten von Sicherheit und Bildung. Die erste Reihe erfolgreicher Geschäftsfälle. In den letzten Jahren hat die Entwicklung von Algorithmen wie Transformer, die auf neuronalen Netzwerkalgorithmen basieren, die Kommerzialisierung von NLP (Natural Language Processing) auf die Tagesordnung gesetzt, und es wird erwartet, dass es in den nächsten drei bis fünf Jahren ausgereifte Kommerzialisierungsszenarien geben wird. ▲ Anzahl der Jahre, die für die Industrialisierung der Technologie der künstlichen Intelligenz erforderlich sind Nach der Entwicklung der letzten 5 bis 6 Jahre ist die globale Die KI-Industrie bildet nach und nach eine Arbeitsteilung und Zusammenarbeit sowie eine vollständige Industriekettenstruktur und beginnt in einigen Bereichen, typische Anwendungsszenarien zu bilden. Künstliche Intelligenz dringt rasant in verschiedene Branchen vor und die Datenmenge wächst massiv. Dies führt zu äußerst komplexen Algorithmenmodellen, heterogenen Verarbeitungsobjekten und hohen Anforderungen an die Rechenleistung. Daher erfordert Deep Learning mit künstlicher Intelligenz äußerst leistungsstarke Parallelverarbeitungsfunktionen. KI-Chips verfügen über mehr logische Operationseinheiten (ALUs) für die Datenverarbeitung und eignen sich für die parallele Verarbeitung intensiver Daten. Field Programmable Gate Array (FPGA), anwendungsspezifische integrierte Schaltung (ASIC) usw. Aus Sicht der Nutzungsszenarien umfasst die relevante Hardware: Cloud-seitige Inferenzchips, Cloud-seitige Testchips, Terminalverarbeitungschips, IP-Kerne usw. Im „Trainings“- oder „Lern“-Teil der Cloud verfügt die NVIDIA GPU über einen starken Wettbewerbsvorteil, und auch Google TPU erweitert aktiv seinen Markt und seine Anwendungen. FPGAs und ASICs können bei „Inferenz“-Anwendungen für den Endverbrauch von Vorteil sein. Die Vereinigten Staaten haben große Vorteile in den Bereichen GPU und FPGA, da führende Unternehmen wie NVIDIA, Xilinx und AMD auch aktiv KI-Chips entwickeln. ?? Paralleles Rechnen mit KI-Chips Die Fähigkeit, komplexe Probleme zu lösen, ist derzeit die Mainstream-Lösung. Den Daten von Tractica zufolge betrug die globale KI-HPC-Marktgröße im Jahr 2019 etwa 1,36 Milliarden US-Dollar, und es wird erwartet, dass die Marktgröße bis 2025 11,19 Milliarden US-Dollar erreichen wird, mit einer siebenjährigen CAGR von 35,1 %. Der KI-HPC-Marktanteil wird von 13,2 % im Jahr 2019 auf 35,5 % im Jahr 2025 steigen. Gleichzeitig zeigen Daten von Tractica, dass der weltweite Markt für KI-Chips im Jahr 2019 6,4 Milliarden US-Dollar betrug und dass die Marktgröße bis 2023 voraussichtlich 51 Milliarden US-Dollar erreichen wird, wobei der Markt um fast das Zehnfache wächst. ▲ Auslieferungen von Edge-Computing-Chips (Millionen, nach Endgeräten) ▲ Globale Marktgröße für Chips für künstliche Intelligenz (Milliarden US-Dollar) In der Vergangenheit hat die Entwicklung der Rechenleistung dies effektiv gemildert Engpass bei der Entwicklung künstlicher Intelligenz. Als uraltes Konzept wurde die künstliche Intelligenz in ihrer bisherigen Entwicklung durch unzureichende Rechenleistung eingeschränkt. Der Bedarf an Rechenleistung ist hauptsächlich auf zwei Aspekte zurückzuführen: 1) Eine der größten Herausforderungen der künstlichen Intelligenz ist die geringe Erkennung und Genauigkeit. Es ist notwendig, den Maßstab und die Genauigkeit des Modells zu erhöhen, was eine stärkere Unterstützung der Rechenleistung erfordert. 2) Da die Anwendungsszenarien der künstlichen Intelligenz schrittweise umgesetzt werden, verzeichnen Daten in den Bereichen Bild, Sprache, maschinelles Sehen und Spiele ein explosionsartiges Wachstum, was auch zu höheren Anforderungen an die Rechenleistung geführt hat und die Computertechnologie in eine neue Runde eintritt Hochgeschwindigkeits-Innovationsperiode. Die Entwicklung der Rechenleistung im letzten Jahrzehnt hat den Entwicklungsengpass der künstlichen Intelligenz wirksam gemildert. Intelligentes Computing wird in Zukunft jederzeit und überall die Merkmale einer größeren Nachfrage, höherer Leistungsanforderungen und vielfältiger Bedürfnisse aufweisen. Wenn es sich der physikalischen Grenze nähert, läuft das Mooresche Gesetz des Rechenleistungswachstums allmählich aus und die Rechenleistungsbranche befindet sich in der Phase umfassender Innovation aus mehreren Elementen. In der Vergangenheit erfolgte die Verbesserung der Rechenleistungsversorgung hauptsächlich durch Prozessverkleinerung, also durch die Erhöhung der Anzahl von Transistorstapeln im selben Chip, um die Rechenleistung zu verbessern. Da sich die Prozesse jedoch weiterhin den physikalischen Grenzen nähern und die Kosten weiter steigen, wird das Mooresche Gesetz allmählich unwirksam. Die Rechenleistungsindustrie tritt in die Post-Moore-Ära ein und die Rechenleistungsversorgung muss durch umfassende Innovation mehrerer Faktoren verbessert werden. Derzeit gibt es vier Ebenen der Rechenleistungsversorgung: Einzelchip-Rechenleistung, komplette Maschinen-Rechenleistung, Rechenzentrums-Rechenleistung und vernetzte Rechenleistung, die sich durch verschiedene Technologien kontinuierlich weiterentwickeln und verbessern, um den Versorgungsbedarf unterschiedlicher Rechenleistung zu decken das Smart-Zeitalter. Darüber hinaus ist die Verbesserung der Gesamtleistung von Computersystemen durch tiefe Integration von Software- und Hardwaresystemen und Algorithmenoptimierung auch eine wichtige Richtung für die Entwicklung der Rechenleistungsbranche. Rechenleistungsskala: Laut dem „China Computing Power Development Index White Paper“, das 2021 von der China Academy of Information and Communications Technology veröffentlicht wurde, wird die Gesamtgröße der globalen Rechenleistung im Jahr 2020 weiterhin einen Wachstumstrend aufweisen Der Gesamtumfang beträgt 429 EFlops, was einer Steigerung von 39 % gegenüber dem Vorjahr entspricht. Der Umfang der Rechenleistung beträgt 313 EFlops, der Umfang der intelligenten Rechenleistung beträgt 107 EFlops und der Anteil der Supercomputerleistung beträgt 9 EFlops der intelligenten Rechenleistung ist gestiegen. Das Entwicklungstempo der Rechenleistung meines Landes ähnelt dem der Welt. Im Jahr 2020 erreichte die Gesamtrechenleistung meines Landes 135 EFlops, was 39 % der globalen Rechenleistungsskala entspricht, und erreichte ein hohes Wachstum von 55 % drei Jahre in Folge eine Wachstumsrate von mehr als 40 % erreichen. ▲ Veränderungen im Ausmaß der globalen Rechenleistung Struktur der Rechenleistung: Die Entwicklungssituation meines Landes ähnelt der der Welt, wobei ihr Anteil von 3 % im Jahr 2016 gestiegen ist auf 41 % im Jahr 2020. Der Anteil der Basisrechenleistung ist von 95 % im Jahr 2016 auf 57 % im Jahr 2020 gesunken. Angetrieben durch die nachgelagerte Nachfrage hat sich die Rechenleistungsinfrastruktur für künstliche Intelligenz, die durch intelligente Rechenzentren repräsentiert wird, rasant entwickelt. Gleichzeitig wird im Hinblick auf die zukünftige Nachfrage laut dem von Huawei im Jahr 2020 veröffentlichten Bericht „Ubiquitous Computing Power: Cornerstone of an Intelligent Society“ mit der Popularisierung künstlicher Intelligenz erwartet, dass die Nachfrage nach künstlicher Intelligenz bis 2030 steigen wird Die Intelligenz-Rechenleistung wird 160 Milliarden Qualcomm-Chips entsprechen. Der Snapdragon 855 verfügt über einen integrierten KI-Chip, was etwa dem 390-fachen von 2018 und etwa 120-fach von 2020 entspricht. Datenspeicherung: Nicht relationale Datenbanken und Data Lakes, die zum Speichern und Verwalten unstrukturierter Daten verwendet werden, verzeichnen einen explosionsartigen Anstieg der Nachfrage. Laut IDC-Statistik ist die Menge der weltweit generierten Daten in den letzten Jahren explosionsartig gewachsen Das Datenvolumen könnte bis 2025 bis zu 175 ZB betragen und wird im Zeitraum 2019–2025 immer noch 175 ZB erreichen. Es wird eine durchschnittliche Wachstumsrate von fast 30 % beibehalten, und mehr als 80 % der Daten werden unstrukturierte Daten wie Text und Bilder sein , Audio und Video, die schwer zu verarbeiten sind. Der Anstieg des Datenvolumens (insbesondere unstrukturierter Daten) hat die Schwächen relationaler Datenbanken immer deutlicher gemacht. Angesichts des geometrisch exponentiellen Datenwachstums ist das vertikale Stapeldatenerweiterungsmodell traditioneller relationaler Datenbanken für strukturierte Daten schwer zu erfüllen . ▲ Globales Datenvolumen und jährliche Wachstumsrate (ZB, %) Tensorflow (Industrie), PyTorch (Wissenschaft). ) Nach und nach Dominanz erlangen. Tensorflow von Google ist der Mainstream und bildet zusammen mit anderen Open-Source-Modulen wie Keras (Tensorflow2 integriert das Keras-Modul), Facebooks Open-Source-PyTorch usw. das aktuelle Mainstream-Framework für KI-Lernen. Seit seiner Gründung im Jahr 2011 hat Google Brain umfangreiche Deep-Learning-Anwendungsforschung für die wissenschaftliche Forschung und die Produktentwicklung von Google durchgeführt. Seine frühe Arbeit war DistBelief, der Vorgänger von TensorFlow. DistBelief wird verfeinert und häufig in der Produktentwicklung bei Google und anderen Alphabet-eigenen Unternehmen eingesetzt. Im November 2015 schloss Google Brain basierend auf DistBelief die Entwicklung von TensorFlow, dem „maschinellen Lernsystem der zweiten Generation“, ab und stellte den Code als Open Source zur Verfügung. Im Vergleich zu seinem Vorgänger weist TensorFlow erhebliche Verbesserungen in Bezug auf Leistung, Architekturflexibilität und Portabilität auf. Obwohl Tensorflow und Pytorch Open-Source-Module sind, werden ihre Änderungen und Aktualisierungen aufgrund des riesigen Modells und der Komplexität des Deep-Learning-Frameworks grundsätzlich von Google durchgeführt. Daher dominieren Google und Facebook auch direkt die Update-Richtung von Tensorflow und PyTorch. Das Entwicklungsmodell der Branche für künstliche Intelligenz. ▲ Globale Marktanteilsstruktur für Frameworks für kommerzielle künstliche Intelligenz (2021) Microsoft investierte im Jahr 2020 1 Milliarde US-Dollar in OpenAI und erhielt eine exklusive Lizenz für das GPT-3-Sprachmodell. GPT-3 ist derzeit die erfolgreichste Anwendung in der Generierung natürlicher Sprache. Sie kann nicht nur zum Schreiben von „Papieren“, sondern auch zum „automatischen Generieren von Code“ verwendet werden. Seit ihrer Veröffentlichung im Juli dieses Jahres genießt sie auch in der Branche großes Ansehen als das leistungsstärkste Sprachmodell für künstliche Intelligenz. Facebook gründete bereits 2013 das AI Research Institute. FAIR selbst verfügt nicht über so berühmte Modelle und Anwendungen wie AlphaGo und GPT-3, aber sein Team hat wissenschaftliche Arbeiten in Bereichen veröffentlicht, an denen Facebook selbst interessiert ist, darunter Computer Vision, Verarbeitung natürlicher Sprache und Konversations-KI usw. Im Jahr 2021 wurden bei Google 177 Artikel von NeurIPS (derzeit die höchste Fachzeitschrift für Algorithmen der künstlichen Intelligenz) angenommen und veröffentlicht, bei Microsoft waren es 116 Artikel, bei DeepMind waren es 81 Artikel, bei Facebook waren es 78 Artikel, bei IBM waren es 36 Artikel und bei Amazon waren es nur 35 Artikel. Deep Learning geht in ein tiefes neuronales Netzwerk über. Maschinelles Lernen ist ein Computeralgorithmus, der Bilder, Töne und andere Daten durch mehrschichtiges nichtlineares Feature-Learning und hierarchische Feature-Extraktion vorhersagt. Deep Learning ist ein fortgeschrittenes maschinelles Lernen, auch bekannt als Deep Neural Network (DNN: Deep Neural Networks). Für das Training und die Schlussfolgerung in verschiedenen Szenarien (Informationen) werden verschiedene neuronale Netze und Trainingsmethoden etabliert. Beim Training wird das Gewicht und die Übertragungsrichtung jedes Neurons durch massive Datenableitung optimiert. Das Faltungs-Neuronale Netzwerk kann einzelne Pixel und umgebende Umgebungsvariablen berücksichtigen und die Menge der Datenextraktion vereinfachen, wodurch die Effizienz des Algorithmus des Neuronalen Netzwerks weiter verbessert wird. Neuronale Netzwerkalgorithmen sind zum Kern der Big-Data-Verarbeitung geworden. KI führt Deep Learning durch riesige beschriftete Daten durch, optimiert neuronale Netze und Modelle und führt die Anwendungsverbindung von Argumentation und Entscheidungsfindung ein. Die 1990er Jahre waren eine Zeit des rasanten Aufschwungs des maschinellen Lernens und der Algorithmen für neuronale Netze, und die Algorithmen wurden mit Unterstützung der Rechenleistung kommerziell genutzt. Zu den praktischen Anwendungsfeldern der KI-Technologie gehören nach den 1990er Jahren Data Mining, Industrieroboter, Logistik, Spracherkennung, Bankensoftware, medizinische Diagnose und Suchmaschinen usw. Der Rahmen verwandter Algorithmen ist zum Schwerpunkt der Gestaltung von Technologiegiganten geworden. ▲ Algorithmus-Plattform-Framework der großen Technologiegiganten In Bezug auf die Technologierichtung sind Computer Vision und maschinelles Lernen die wichtigsten Forschungs- und Entwicklungsrichtungen im Bereich Technologie. Laut ARXIV-Daten entwickelten sich aus theoretischer Forschungsperspektive die beiden Bereiche Computer Vision und maschinelles Lernen von 2015 bis 2020 rasant, gefolgt vom Bereich der Robotik. Im Jahr 2020 überstieg die Zahl der Veröffentlichungen im Bereich Computer Vision unter den KI-bezogenen Veröffentlichungen auf ARXIV 11.000 und belegte damit den ersten Platz bei der Zahl der KI-bezogenen Veröffentlichungen. ▲Anzahl der KI-bezogenen Veröffentlichungen auf ARXIV von 2015 bis 2020 In den letzten fünf Jahren haben wir beobachtet, dass neuronale Netzwerkalgorithmen, hauptsächlich CNN und DNN, aufgrund ihrer hervorragenden Leistung in den Bereichen Computer Vision, Verarbeitung natürlicher Sprache und anderen Bereichen die am schnellsten wachsenden Algorithmen sind beschleunigte die Geschwindigkeit der künstlichen Intelligenz. Die Geschwindigkeit der Implementierung intelligenter Anwendungen ist ein Schlüsselfaktor für die schnelle Reife von Computer Vision und Entscheidungsintelligenz. Aus der Seitenansicht ist ersichtlich, dass die Standard-DNN-Methode bei Spracherkennungsaufgaben offensichtliche Vorteile gegenüber herkömmlichen KNN-, SVM- und Random-Forest-Methoden hat. ▲ Der Faltungsalgorithmus durchbricht den Genauigkeitsengpass der herkömmlichen Bildverarbeitung und ist erstmals industriell verfügbar In Bezug auf die Trainingskosten werden die Kosten für das Training künstlicher Intelligenz mit neuronalen Netzwerkalgorithmen erheblich reduziert. ImageNet ist ein Datensatz mit über 14 Millionen Bildern, der zum Trainieren von Algorithmen für künstliche Intelligenz verwendet wird. Laut Tests des Stanford DAWNBench-Teams kostet das Training eines modernen Bilderkennungssystems im Jahr 2020 nur etwa 7,5 US-Dollar, ein Rückgang von mehr als 99 % gegenüber 1.100 US-Dollar im Jahr 2017. Dies ist hauptsächlich auf die Optimierung des Algorithmusdesigns, die Reduzierung von, zurückzuführen Kosten für Rechenleistung und Fortschritte in der groß angelegten KI-Trainingsinfrastruktur. Je schneller das System trainiert werden kann, desto schneller kann es ausgewertet und mit neuen Daten aktualisiert werden, was das Training des ImageNet-Systems weiter beschleunigen und die Produktivität bei der Entwicklung und dem Einsatz von Systemen der künstlichen Intelligenz steigern wird. Ein Blick auf die Trainingszeitverteilung zeigt, dass die für das Training neuronaler Netzwerkalgorithmen erforderliche Zeit insgesamt reduziert wurde. Durch die Analyse der Verteilung der Trainingszeit in jedem Zeitraum wurde festgestellt, dass die Trainingszeit in den letzten Jahren stark verkürzt und die Verteilung der Trainingszeit konzentrierter geworden ist, was vor allem dem weit verbreiteten Einsatz von Beschleunigerchips zugute kommt . ▲ ImageNet-Trainingszeitverteilung (Minuten) Angetrieben durch Faltungs-Neuronale Netze haben sich die Ergebnisse von Computer-Vision-Genauigkeitstests deutlich verbessert und befinden sich in der Industrialisierungsphase. Die Genauigkeit von Computer Vision hat im letzten Jahrzehnt enorme Fortschritte gemacht, hauptsächlich aufgrund der Anwendung maschineller Lerntechnologie. Top-1-Genauigkeitstest: Je besser ein KI-System einem Bild das richtige Label zuordnet, desto identischer sind seine Vorhersagen (unter allen möglichen Labels) mit dem Ziellabel. Mit zusätzlichen Trainingsdaten (z. B. Fotos aus sozialen Medien) gab es im Januar 2021 beim Top-1-Genauigkeitstest 1 Fehler pro 10 Versuche, verglichen mit 1 Fehler pro 10 Versuchen im Dezember 2012. Es werden 4 Fehler auftreten. Ein weiterer Genauigkeitstest, Top-5, fragt den Computer, ob die Zielbezeichnung zu den fünf besten Vorhersagen des Klassifikators gehört. Seine Genauigkeit stieg von 85 % im Jahr 2013 auf 99 % im Jahr 2021 und übertraf damit den menschlichen Wert. „TOP-1-Genauigkeitsänderung“ Jahre, Integration verschiedener verstreuter kleiner Modelle in der Vergangenheit. KIGroße Modellierung ist ein neuer Trend, der sich in den letzten zwei Jahren herausgebildet hat. Selbstüberwachtes Lernen. +vorab trainierte Modell-Feinabstimmungs- und Anpassungslösungen haben sich allmählich zum Mainstream entwickelt, und KI Modelle bewegen sich in Richtung der Unterstützung von Big Data. Eine Verallgemeinerung ist möglich. Herkömmliche kleine Modelle werden mit gekennzeichneten Daten in bestimmten Bereichen trainiert und weisen eine geringe Vielseitigkeit auf. Sie sind häufig nicht auf andere Anwendungsszenarien anwendbar und müssen neu trainiert werden. Große KI-Modelle werden normalerweise auf großen, unbeschrifteten Daten trainiert, und große Modelle können fein abgestimmt werden, um den Anforderungen verschiedener Anwendungsaufgaben gerecht zu werden. Der Einsatz groß angelegter intelligenter Modelle, vertreten durch OpenAI, Google, Microsoft, Facebook, NVIDIA und andere Institutionen, hat sich zu einem führenden globalen Trend entwickelt und hat Basismodelle mit großen Parametermengen wie GPT-3 und Switch Transformer hervorgebracht. Der Ende 2021 von NVIDIA und Microsoft gemeinsam entwickelte Megatron-LM verfügt über 8,3 Milliarden Parameter, während der von Facebook entwickelte Megatron über 11 Milliarden Parameter verfügt. Die meisten dieser Parameter stammen von Reddit, Wikipedia, Nachrichten-Websites usw. Tools wie Data Lakes, die für die Speicherung und Analyse großer Datenmengen erforderlich sind, werden einer der Schwerpunkte zukünftiger Forschung und Entwicklung sein. 5. Anwendungsszenarien: Nach und nach in den Bereichen Sicherheit, Internet, Einzelhandel und anderen Bereichen implementiert. Zu den relativ ausgereiften börsennotierten Unternehmen im Bereich der Spracherkennung gehören iFlytek und Nuance, das zuvor für 29 Milliarden US-Dollar von Microsoft übernommen wurde. Intelligente medizinische Versorgung: Medizinische Versorgung wird hauptsächlich in medizinischen Assistenzszenarien eingesetzt. KI-Produkte im Medizin- und Gesundheitsbereich umfassen mehrere Anwendungsszenarien wie intelligente Beratung, Erfassung der Krankengeschichte, sprachgesteuerte elektronische Krankenakten, medizinische Spracheingabe, medizinische Bilddiagnose, intelligente Nachsorge und medizinische Cloud-Plattformen. Aus der Sicht des medizinischen Behandlungsprozesses im Krankenhaus handelt es sich bei Produkten vor der Diagnose hauptsächlich um Sprachassistenten, z. B. um medizinische Beratung, Erfassung der Krankengeschichte usw.; Bei den Produkten handelt es sich hauptsächlich um Follow-up-Tracking-Produkte. Unter Berücksichtigung der unterschiedlichen Produkte im gesamten medizinischen Behandlungsprozess sind die aktuellen Hauptanwendungsbereiche der medizinischen Versorgung mit KI+ immer noch Hilfsszenarien, die die körperliche und repetitive Arbeit des Arztes ersetzen. Das führende ausländische Unternehmen in der medizinischen KI+-Versorgung ist Nuance. 50 % des Geschäfts des Unternehmens stammen aus intelligenten medizinischen Lösungen, und Transkriptionslösungen für klinische medizinische Dokumente wie Krankenakten sind die Haupteinnahmequelle des medizinischen Geschäfts. Intelligente Städte: Großstadtkrankheiten und neue Urbanisierung stellen neue Herausforderungen für die Stadtverwaltung dar und stimulieren die Nachfrage nach Stadtverwaltung. Mit der Zunahme der Bevölkerung und der Zahl der Kraftfahrzeuge in großen und mittelgroßen Städten treten Probleme wie die Überlastung der Städte immer stärker in den Vordergrund. Mit der fortschreitenden neuen Urbanisierung werden Smart Cities zum wichtigsten Entwicklungsmodell chinesischer Städte. Die KI+Sicherheit und das KI+Verkehrsmanagement in Smart Cities werden zu den wichtigsten Umsetzungslösungen auf der G-Seite. Im Jahr 2016 führte Hangzhou seine erste urbane Data-Brain-Transformation durch und der Peak-Congestion-Index sank auf unter 1,7. Derzeit haben die von Alibaba vertretenen städtischen Datenhirne mehr als 1,5 Milliarden Yuan investiert, hauptsächlich in Bereiche wie intelligente Sicherheit und intelligenten Transport. Das Ausmaß der Smart-City-Industrie meines Landes wächst weiter. Das Forward-looking Industry Research Institute prognostiziert, dass sie im Jahr 2022 25 Billionen Yuan erreichen wird, mit einer durchschnittlichen jährlichen Wachstumsrate von 55,27 % von 2014 bis 2022. Die jährliche Marktgröße beträgt 5710 Intelligente Lagerhaltung Es sind Tausende von Yuan Milliardenmarkt. Im Kontext hoher Kosten und digitaler Transformation in der Logistikbranche stehen Lagerlogistik und Produktherstellung vor dem dringenden Bedarf an Automatisierung, Digitalisierung und intelligenter Transformation, um die Produktions- und Umlaufeffizienz zu verbessern. Nach Angaben der China Federation of Logistics and Purchasing wird Chinas intelligenter Logistikmarkt im Jahr 2020 ein Volumen von 571 Milliarden Yuan erreichen, mit einer durchschnittlichen jährlichen Wachstumsrate von 21,61 % von 2013 bis 2020. Informationstechnologien der neuen Generation wie das Internet der Dinge, Big Data, Cloud Computing und künstliche Intelligenz haben nicht nur die Entwicklung der intelligenten Logistikbranche gefördert, sondern auch höhere Serviceanforderungen für die intelligente Logistikbranche gestellt Der Logistikmarkt wird voraussichtlich weiter wachsen. Den Berechnungen von GGII zufolge betrug die Größe des chinesischen Marktes für intelligente Lagerhaltung im Jahr 2019 fast 90 Milliarden Yuan, und das Forward Research Institute prognostiziert, dass diese Zahl im Jahr 2025 mehr als 150 Milliarden Yuan erreichen wird. Neuer Einzelhandel: Künstliche Intelligenz wird die Arbeitskosten senken und die betriebliche Effizienz verbessern. Amazon Go ist das von Amazon vorgeschlagene unbemannte Ladenkonzept. Der unbemannte Laden wurde am 22. Januar 2018 offiziell in Seattle, USA, eröffnet. AmazonGo kombiniert Cloud Computing und maschinelles Lernen und nutzt dabei die Just Walk Out-Technologie und Amazon Rekognition. In-Store-Kameras, Sensormonitore und die dahinter stehenden Maschinenalgorithmen werden die Artikel identifizieren, die Verbraucher mitnehmen, und diese automatisch auschecken, wenn Kunden den Laden verlassen. Dies ist eine völlig neue Revolution im Bereich des Einzelhandels. Cloudbasierte Modulkomponenten für künstliche Intelligenz sind derzeit die Hauptrichtung der Kommerzialisierung künstlicher Intelligenz durch große Internetgiganten. Integrieren Sie die Technologie der künstlichen Intelligenz in zum Verkauf stehende öffentliche Cloud-Dienste. Die KI-Technologie der Google Cloud Platform war schon immer führend in der Branche und engagiert sich für die Integration fortschrittlicher KI-Technologie in Cloud-Computing-Servicezentren. In den letzten Jahren hat Google eine Reihe von KI-Unternehmen übernommen und Produkte wie KI-spezifische Chips TPU und den Cloud-Dienst Cloud AutoML auf den Markt gebracht, um sein Layout zu vervollständigen. Derzeit umfassen die KI-Funktionen von Google kognitive Dienste, maschinelles Lernen, Robotik, Datenanalyse und Zusammenarbeit sowie andere Bereiche. Im Gegensatz zu den relativ verstreuten Produkten einiger Cloud-Anbieter im KI-Bereich ist Google beim Betrieb von KI-Produkten umfassender und systematischer. Es integriert vertikale Anwendungen in grundlegende KI-Komponenten und integriert Tensorflow und TPU-Computing in die Infrastruktur Komplette KI-Plattformdienste. Baidu ist der fähigste Public-Cloud-Anbieter in China AI Baidu AI s Kernstrategie ist Open Empowerment. Baidu hat eine KI-Plattform aufgebaut, die durch DuerOS und Apollo repräsentiert wird, um das Ökosystem zu öffnen und eine positive Iteration von Daten und Szenarien zu bilden. Basierend auf der Datengrundlage der Baidu-Internetsuche sind die Technologien zur Verarbeitung natürlicher Sprache, Wissensgraphen und Benutzerporträts nach und nach ausgereift. Auf Plattform- und ökologischer Ebene ist Baidu Cloud eine große Computerplattform, die allen Partnern offen steht und zu einer grundlegenden Supportplattform mit verschiedenen Funktionen von Baidu Brain wird. Es gibt auch einige vertikale Lösungen, wie zum Beispiel ein Betriebssystem der neuen Generation, das auf natürlicher Sprache basierender Mensch-Computer-Interaktion basiert, und Apollo im Zusammenhang mit intelligentem Fahren. Fahrzeughersteller können auf die Fähigkeiten zurückgreifen, die sie benötigen, und Hersteller von Automobilelektronik können auch auf die entsprechenden Fähigkeiten zurückgreifen, die sie benötigen, um gemeinsam die gesamte Plattform und das gesamte Ökosystem aufzubauen. In den letzten Jahren hat der technologische Entwicklungsweg der KI-Industrie hauptsächlich die folgenden Merkmale gezeigt: die Kontinuität Verbesserung der Leistung der zugrunde liegenden Module und Konzentration auf die Generalisierungsfähigkeit des Modells, wodurch die Vielseitigkeit von KI-Algorithmen und die Rückmeldung der Datenerfassung optimiert werden. Die nachhaltige Entwicklung der KI-Technologie hängt von Durchbrüchen bei den zugrunde liegenden Algorithmen ab, was auch den Aufbau grundlegender Fähigkeiten mit Rechenleistung als Kern und einer durch Big Data unterstützten Umgebung für Wissens- und Erfahrungslernen erfordert. Die rasante Beliebtheit großer Modelle in der Branche, die Funktionsweise von großen Modellen + kleinen Modellen und die kontinuierliche Verbesserung der Fähigkeiten zugrunde liegender Verbindungen wie Chips und Rechenleistungsinfrastruktur sowie die daraus resultierende kontinuierliche Verbesserung der Anwendungsszenariokategorien und Szenariotiefe, und letztendlich wird es eine kontinuierliche gegenseitige Förderung zwischen grundlegenden industriellen Fähigkeiten und Anwendungsszenarien bewirken und die Entwicklung der globalen KI-Industrie vorantreiben, um sich unter der Logik eines positiven Zyklus weiter zu beschleunigen. Große Modelle bringen starke allgemeine Fähigkeiten zur Problemlösung mit. Derzeit handelt es sich bei den meisten künstlichen Intelligenzen um einen „manuellen Werkstattstil“. Angesichts nachgelagerter Anwendungen in verschiedenen Branchen hat die KI nach und nach die Merkmale der Fragmentierung und Diversifizierung gezeigt, und die Modellvielseitigkeit ist nicht hoch. Um die allgemeinen Lösungsfähigkeiten zu verbessern, bieten große Modelle eine praktikable Lösung, nämlich „Große Modelle vorab trainieren + Feinabstimmung der nachgelagerten Aufgabe“. Diese Lösung bezieht sich auf die Erfassung von Wissen aus einer großen Menge gekennzeichneter und unbeschrifteter Daten, die Verbesserung der Modellverallgemeinerungsfähigkeiten durch die Speicherung von Wissen in einer großen Anzahl von Parametern und die Feinabstimmung spezifischer Aufgaben. Es wird erwartet, dass das große Modell die Genauigkeitsbeschränkungen der bestehenden Modellstruktur weiter durchbricht und in Kombination mit dem Training verschachtelter kleiner Modelle die Modelleffizienz in bestimmten Szenarien weiter verbessert. In den letzten zehn Jahren beruhte die Verbesserung der Modellgenauigkeit hauptsächlich auf strukturellen Änderungen des Netzwerks. Da die Technologie zum Entwurf neuronaler Netzwerkstrukturen jedoch allmählich ausgereift ist und zur Konvergenz neigt, hat die Verbesserung der Genauigkeit einen Engpass erreicht, und die Anwendung von Es wird erwartet, dass große Modelle diesen Engpass überwinden werden. Am Beispiel des visuellen Übertragungsmodells Big Transfer, BiT, von Google werden zwei Datensätze, ILSVRC-2012 (1,28 Millionen Bilder, 1000 Kategorien) und JFT-300M (300 Millionen Bilder, 18291 Kategorien), zum Trainieren der ResNet50-Genauigkeit verwendet Sie liegen bei 77 % bzw. 79 %. Durch die Verwendung großer Modelle wird die Engpassgenauigkeit weiter verbessert. Darüber hinaus kann die Genauigkeit durch die Verwendung von JFT-300M zum Trainieren von ResNet152x4 auf 87,5 % erhöht werden, was 10,5 % höher ist als bei der ILSVRC-2012+ResNet50-Struktur. Großes Modell+Kleines Modell: Die Förderung allgemeiner großer künstlicher Intelligenz in Kombination mit der Datenoptimierung in bestimmten Szenarien wird mittelfristig zum Schlüssel für die Kommerzialisierung der künstlichen Intelligenzbranche. Das ursprüngliche Modell der erneuten Extraktion von Daten für bestimmte Szenarien hat sich als schwierig erwiesen, um Gewinne zu erzielen. Die Kosten für die erneute Schulung des Modells sind zu hoch, und das erhaltene Modell weist eine geringe Vielseitigkeit auf und ist schwer wiederzuverwenden. Im Zusammenhang mit der kontinuierlichen Verbesserung der Chip-Rechenleistung bietet der Versuch, große Modelle in kleine Modelle zu verschachteln, den Herstellern eine weitere Idee. Durch die Analyse großer Datenmengen können sie Allzweckmodelle erhalten und dann spezifische kleine Modelle verschachteln, um Lösungen bereitzustellen verschiedene Szenarien optimiert und eine Menge Kosten gespart. Anbieter öffentlicher Clouds wie Alibaba Cloud, Huawei Cloud und Tencent Cloud entwickeln aktiv selbst entwickelte große Modellplattformen, um die Allgemeingültigkeit der Modelle zu verbessern. Die von NVIDIA vertretenen KIChipgiganten haben speziell neue Engines für die KIModelle entwickelt, die in der Branche häufig in der neuen Generation von Chips verwendet werden, um die Rechenleistung erheblich zu verbessern. Wie Sie der Abbildung entnehmen können, ist der Preis des m1.large-Produkts mit 2 vCPUs, 2 ECUs und 7,5 GiB weiter von etwa 0,4 $/Stunde im Jahr 2008 auf etwa 0,18 $/Stunde im Jahr 2022 gesunken. Auch der On-Demand-Nutzungspreis des n1-standard-8-Produkts von Google Cloud mit 8 vCPUs und 30 GB Speicher ist von 0,5 US-Dollar/Stunde im Jahr 2014 auf 0,38 US-Dollar/Stunde im Jahr 2022 gesunken. Es ist ersichtlich, dass die Preise für Cloud Computing steigen insgesamt ein Abwärtstrend. In den nächsten drei bis fünf Jahren werden wir weitere AI-as-a-Service-Angebote (AIaaS) sehen. Der zuvor erwähnte Trend zu großen Modellen, insbesondere die Geburt von GPT-3, hat diesen Trend ausgelöst. Aufgrund der großen Anzahl von Parametern muss GPT-3 auf einer riesigen öffentlichen Cloud-Rechenleistung wie Azure-Recheneinrichtungen ausgeführt werden. Wenn Microsoft es zu einem Dienst macht, der über die Web-API abgerufen werden kann, wird dies auch die Entstehung größerer Modelle fördern. ▲ Historischer standardisierter AWS EC2-Preis (USD/Stunde) Mit der Unterstützung der aktuellen Rechenleistungsbedingungen und vorhersehbaren technischen Möglichkeiten wird die Anwendungsseite weiterhin eine Algorithmeniteration und -optimierung durch Datenerfassung erreichen und das aktuelle Verständnis verbessern Es bestehen immer noch Defizite bei der Intelligenz (Bilderkennungsrichtung) und es wird versucht, sich in Richtung Entscheidungsintelligenz zu entwickeln. Aufgrund der aktuellen technischen Möglichkeiten und der Hardware-Rechenleistungsunterstützung wird es in drei bis fünf Jahren noch lange dauern, bis eine vollständige Entscheidungsintelligenz auf der Grundlage der weiteren Vertiefung bestehender Szenarien erreicht ist. Die aktuelle KI-Anwendungsebene ist immer noch zu punktuell, und die Vervollständigung der lokalen Reihenverbindung wird der erste Schritt sein, um Entscheidungsintelligenz zu erreichen. Softwareanwendungen für künstliche Intelligenz umfassen vom unteren Treiber bis zum oberen Anwendungs- und Algorithmus-Framework, von geschäftsorientierten Anwendungen (Fertigung, Finanzen, Logistik, Einzelhandel, Immobilien usw.) bis hin zu Menschen (Metaverse, Medizin, humanoide Roboter usw.). ), autonomes Fahren und andere Bereiche. Zhixixi glaubt, dass die KI-Industrie mit der kontinuierlichen Verbesserung grundlegender Elemente wie KI-Chips, Rechenleistungseinrichtungen und Daten sowie der erheblichen Verbesserung der allgemeinen Problemlösungsfähigkeiten durch große Modelle einen „Chip“ bildet + Rechenleistungsinfrastruktur + KI“ Mit der stabilen industriellen Wertschöpfungskettenstruktur von „Framework & Algorithm Library + Application Scenario“, KI-Chipherstellern, Cloud-Computing-Herstellern (Rechenleistungseinrichtungen + Algorithmus-Framework), KI + Anwendungsszenario-Herstellern, Plattformalgorithmus-Framework Es wird erwartet, dass Hersteller usw. weiterhin die Hauptnutznießer der Branche werden. 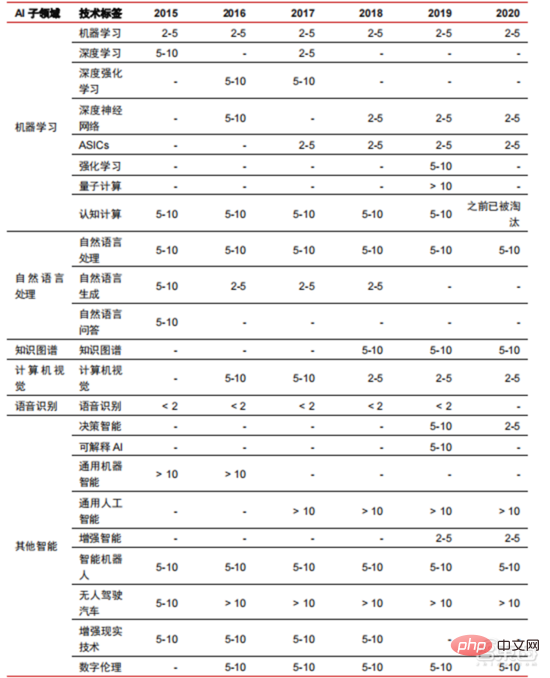
2. Die Arbeitsteilung ist nach und nach abgeschlossen und die Implementierungsszenarien werden ständig erweitert
1. KI-Chips: Von der GPU bis zum FPGA, ASIC usw. verbessert sich die Leistung ständig. Der Wohlstand dieser Branche der künstlichen Intelligenz ist auf die stark verbesserte KI-Rechenleistung zurückzuführen, die Deep Learning und mehrschichtige neuronale Netzwerkalgorithmen ermöglicht.
人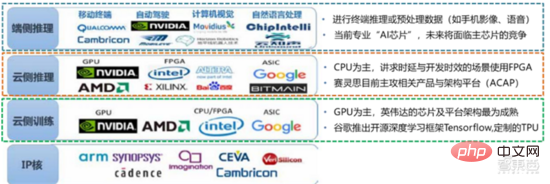
2. Rechenleistungseinrichtungen: Mit Hilfe von Cloud Computing, Selbstkonstruktion und anderen Methoden wurden Indikatoren wie Rechenleistungsumfang und Stückkosten kontinuierlich verbessert
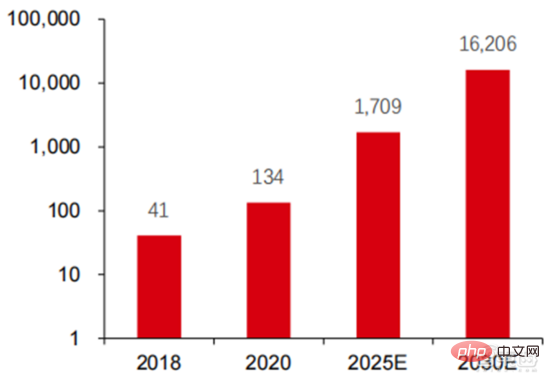
3. KI-Framework: relativ ausgereift, dominiert von einigen Giganten
4. Algorithmusmodell: Der neuronale Netzwerkalgorithmus ist die wichtigste theoretische Grundlage.
3. Industrielle Veränderungen: KI-Großmodelle werden allmählich zum Mainstream, und die industrielle Entwicklung wird sich voraussichtlich auf breiter Front beschleunigen
Das obige ist der detaillierte Inhalt vonAusführlicher Bericht: Große modellgesteuerte KI beschleunigt sich auf ganzer Linie! Das goldene Jahrzehnt beginnt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
Der Befehl centOS stilldown wird heruntergefahren und die Syntax wird von [Optionen] ausgeführt [Informationen]. Zu den Optionen gehören: -h das System sofort stoppen; -P schalten Sie die Leistung nach dem Herunterfahren aus; -r neu starten; -t Wartezeit. Zeiten können als unmittelbar (jetzt), Minuten (Minuten) oder als bestimmte Zeit (HH: MM) angegeben werden. Hinzugefügten Informationen können in Systemmeldungen angezeigt werden.
 Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Backup- und Wiederherstellungsrichtlinie von GitLab im Rahmen von CentOS -System Um die Datensicherheit und Wiederherstellung der Daten zu gewährleisten, bietet GitLab on CentOS eine Vielzahl von Sicherungsmethoden. In diesem Artikel werden mehrere gängige Sicherungsmethoden, Konfigurationsparameter und Wiederherstellungsprozesse im Detail eingeführt, um eine vollständige GitLab -Sicherungs- und Wiederherstellungsstrategie aufzubauen. 1. Manuell Backup Verwenden Sie den GitLab-RakegitLab: Backup: Befehl erstellen, um die manuelle Sicherung auszuführen. Dieser Befehl unterstützt wichtige Informationen wie GitLab Repository, Datenbank, Benutzer, Benutzergruppen, Schlüssel und Berechtigungen. Die Standardsicherungsdatei wird im Verzeichnis/var/opt/gitlab/backups gespeichert. Sie können /etc /gitlab ändern
 So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
Vollständige Anleitung zur Überprüfung der HDFS -Konfiguration in CentOS -Systemen In diesem Artikel wird die Konfiguration und den laufenden Status von HDFS auf CentOS -Systemen effektiv überprüft. Die folgenden Schritte helfen Ihnen dabei, das Setup und den Betrieb von HDFs vollständig zu verstehen. Überprüfen Sie die Hadoop -Umgebungsvariable: Stellen Sie zunächst sicher, dass die Hadoop -Umgebungsvariable korrekt eingestellt ist. Führen Sie im Terminal den folgenden Befehl aus, um zu überprüfen, ob Hadoop ordnungsgemäß installiert und konfiguriert ist: Hadoopsion-Check HDFS-Konfigurationsdatei: Die Kernkonfigurationsdatei von HDFS befindet sich im/etc/hadoop/conf/verzeichnis, wobei core-site.xml und hdfs-site.xml von entscheidender Bedeutung sind. verwenden
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
Die Installation von MySQL auf CentOS umfasst die folgenden Schritte: Hinzufügen der entsprechenden MySQL Yum -Quelle. Führen Sie den Befehl mySQL-server aus, um den MySQL-Server zu installieren. Verwenden Sie den Befehl mySQL_SECURE_INSTALLATION, um Sicherheitseinstellungen vorzunehmen, z. B. das Festlegen des Stammbenutzerkennworts. Passen Sie die MySQL -Konfigurationsdatei nach Bedarf an. Tune MySQL -Parameter und optimieren Sie Datenbanken für die Leistung.
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 CentOS8 startet SSH
Apr 14, 2025 pm 09:00 PM
CentOS8 startet SSH
Apr 14, 2025 pm 09:00 PM
Der Befehl zum Neustart des SSH -Dienstes lautet: SystemCTL Neustart SSHD. Detaillierte Schritte: 1. Zugriff auf das Terminal und eine Verbindung zum Server; 2. Geben Sie den Befehl ein: SystemCTL Neustart SSHD; 1. Überprüfen Sie den Dienststatus: SystemCTL -Status SSHD.
 Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Pytorch Distributed Training on CentOS -System erfordert die folgenden Schritte: Pytorch -Installation: Die Prämisse ist, dass Python und PIP im CentOS -System installiert sind. Nehmen Sie abhängig von Ihrer CUDA -Version den entsprechenden Installationsbefehl von der offiziellen Pytorch -Website ab. Für CPU-Schulungen können Sie den folgenden Befehl verwenden: PipinstallTorChTorChVisionTorChaudio Wenn Sie GPU-Unterstützung benötigen, stellen Sie sicher, dass die entsprechende Version von CUDA und CUDNN installiert ist und die entsprechende Pytorch-Version für die Installation verwenden. Konfiguration der verteilten Umgebung: Verteiltes Training erfordert in der Regel mehrere Maschinen oder mehrere Maschinen-Mehrfach-GPUs. Ort
