
 Technologie-Peripheriegeräte
KI
Wayformer: Ein einfaches und effektives Aufmerksamkeitsnetzwerk zur Bewegungsvorhersage
Technologie-Peripheriegeräte
KI
Wayformer: Ein einfaches und effektives Aufmerksamkeitsnetzwerk zur Bewegungsvorhersage
Wayformer: Ein einfaches und effektives Aufmerksamkeitsnetzwerk zur Bewegungsvorhersage

Das im Juli 2022 hochgeladene arXiv-Papier „Wayformer: Motion Forecasting via Simple & Efficient Attention Networks“ ist das Werk von Google Waymo.

Bewegungsvorhersage für autonomes Fahren ist eine herausfordernde Aufgabe, da komplexe Fahrszenarien zu verschiedenen Mischformen statischer und dynamischer Eingaben führen. Es ist ein ungelöstes Problem, wie sich historische Informationen über Straßengeometrie, Fahrspurkonnektivität, zeitlich variierende Ampelzustände und dynamische Gruppen von Agenten und deren Interaktionen am besten darstellen und in effizienten Kodierungen zusammenführen lassen. Um diesen vielfältigen Satz an Eingabefunktionen zu modellieren, gibt es viele Ansätze zum Entwurf gleichermaßen komplexer Systeme mit unterschiedlichen Sätzen modalitätsspezifischer Module. Dies führt zu Systemen, die schwer zu skalieren, zu skalieren oder auf strenge Weise Qualität und Effizienz abzuwägen.
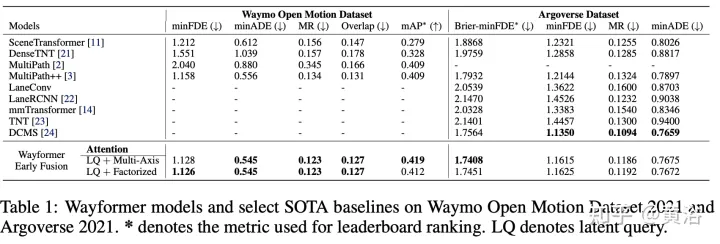
Der Wayformer in diesem Artikel ist eine Reihe einfacher und ähnlicher aufmerksamkeitsbasierter Bewegungsvorhersagearchitekturen. Wayformer bietet eine kompakte Modellbeschreibung bestehend aus aufmerksamkeitsbasierten Szenen-Encodern und -Decodern. Im Szenenencoder wird die Auswahl der Eingabemodi vor der Fusion, nach der Fusion und hierarchischen Fusion untersucht. Erkunden Sie für jeden Fusionstyp Strategien, die Effizienz und Qualität durch Zerlegungsaufmerksamkeit oder latente Abfrageaufmerksamkeit abwägen. Die Pre-Fusion-Struktur ist einfach und nicht nur modusunabhängig, sondern erzielt auch hochmoderne Ergebnisse sowohl im Waymo Open Movement Dataset (WOMD) als auch im Argoverse Leaderboard.
Fahrszenen bestehen aus multimodalen Daten wie Straßeninformationen, Ampelstatus, Agentenhistorie und Interaktionen. Für die Modalität gibt es eine Kontext4. Dimension, die den „Satz kontextueller Ziele“ für jeden modellierten Agenten darstellt (d. h. eine Darstellung anderer Verkehrsteilnehmer).
Intelligence History enthält eine Reihe vergangener Intellektzustände sowie den aktuellen Zustand. Berücksichtigen Sie für jeden Zeitschritt Merkmale, die den Zustand des Agenten definieren, wie z. B. x, y, Geschwindigkeit, Beschleunigung, Begrenzungsrahmen usw., sowie eine Kontextdimension.
Interaktionstensor repräsentiert die Beziehung zwischen Agenten. Für jeden modellierten Agenten wird eine feste Anzahl von Nächste-Nachbarn-Kontexten rund um den modellierten Agenten berücksichtigt. Diese kontextuellen Agenten stellen Agenten dar, die das Verhalten des modellierten Agenten beeinflussen.
Straßenkarte enthält Straßenmerkmale rund um den Agenten. Straßenkartensegmente werden als Polylinien dargestellt, eine Sammlung von Segmenten, die durch ihre Endpunkte angegeben und mit Typinformationen versehen sind, die der Form der Straße annähernd entsprechen. Verwenden Sie das Straßenkartensegment, das dem Modellierungsagenten am nächsten liegt. Bitte beachten Sie, dass Straßenmerkmale keine Zeitdimension haben und die Zeitdimension 1 hinzugefügt werden kann.
Für jeden Agenten enthalten die Ampelinformationen den Ampelstatus, der dem Agenten am nächsten liegt. Jeder Ampelpunkt verfügt über Merkmale, die den Standort und die Zuverlässigkeit des Signals beschreiben.
Wayformer-Modellreihe, bestehend aus zwei Hauptkomponenten: Szenen-Encoder und Decoder. Der Szenen-Encoder besteht hauptsächlich aus einem oder mehreren Aufmerksamkeits-Encodern, die zur Zusammenfassung der Fahrszene verwendet werden. Der Decoder besteht aus einem oder mehreren Standardtransformator-Cross-Attention-Modulen, die die erlernte Anfangsabfrage eingeben und dann Trajektorien mit Szenencodierung von Cross-Attention generieren.
Wie in der Abbildung gezeigt, verarbeitet das Wayformer-Modell multimodale Eingaben, um eine Szenenkodierung zu erzeugen: Diese Szenenkodierung wird als Kontext des Decoders verwendet und generiert k mögliche Trajektorien, die mehrere Modalitäten im Ausgaberaum abdecken.
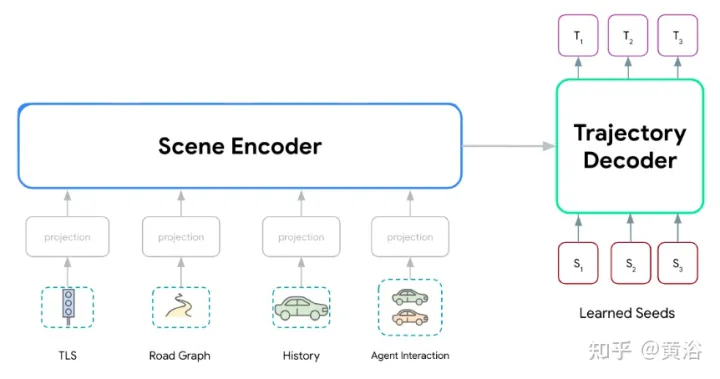
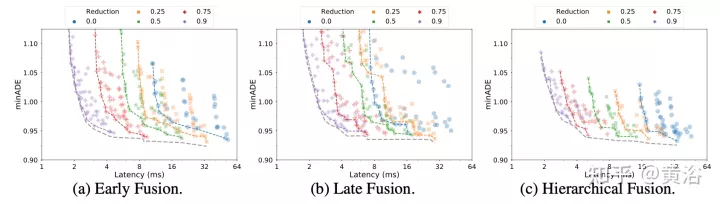
Die Vielfalt der Eingaben in den Szenenencoder macht diese Integration zu einer nicht trivialen Aufgabe. Modalitäten werden möglicherweise nicht auf derselben Abstraktionsebene oder Skala dargestellt: {Pixel vs. Zielobjekte}. Daher erfordern einige Modalitäten möglicherweise mehr Berechnungen als andere. Die rechnerische Zerlegung zwischen Modi ist anwendungsabhängig und für Ingenieure sehr wichtig. Um diesen Prozess zu vereinfachen, werden hier drei Fusionsebenen vorgeschlagen: {Post, Pre, Grade}, wie in der Abbildung gezeigt:
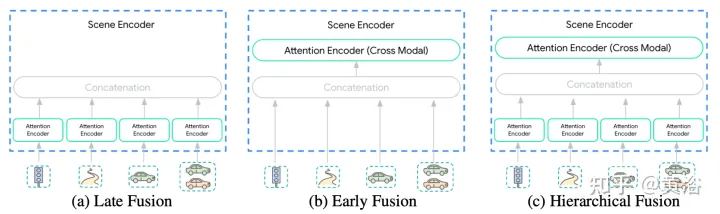
Postfusion ist die am häufigsten verwendete Methode für Bewegungsvorhersagemodelle, bei der jede Modalität ihre eigene hat eigener dedizierter Encoder. Wenn Sie die Breite dieser Encoder gleich einstellen, wird vermieden, dass zusätzliche Projektionsebenen in die Ausgabe eingefügt werden. Darüber hinaus wird der Erkundungsraum auf eine überschaubare Größe reduziert, da alle Encoder die gleiche Tiefe haben. Informationen dürfen nur in der Queraufmerksamkeitsschicht des Trajektoriendecoders über Modalitäten hinweg übertragen werden.
Pre-FusionAnstatt jeder Modalität einen Selbstaufmerksamkeits-Encoder zuzuweisen, werden die Parameter der spezifischen Modalität auf die Projektionsebene reduziert. Der Szenen-Encoder in der Abbildung besteht aus einem einzelnen Selbstaufmerksamkeits-Encoder (dem „kreuzmodalen Encoder“), der dem Netzwerk maximale Flexibilität bei der Zuweisung von Wichtigkeit über Modalitäten hinweg bei minimaler induktiver Vorspannung ermöglicht.
Hierarchische FusionAls Kompromiss zwischen den ersten beiden Extremen wird das Volumen hierarchisch zwischen modalitätsspezifischen Selbstaufmerksamkeits-Encodern und modalübergreifenden Encodern zerlegt. Wie bei der Postfusion werden Breite und Tiefe im Aufmerksamkeitsencoder und im modalübergreifenden Encoder gemeinsam genutzt. Dadurch wird die Tiefe des Szenen-Encoders effektiv zwischen modalitätsspezifischen Encodern und modalübergreifenden Encodern aufgeteilt.
Transformatornetzwerke lassen sich aufgrund der folgenden zwei Faktoren nicht gut auf große mehrdimensionale Sequenzen skalieren:
- (a) Die Selbstaufmerksamkeit ist quadratisch zur Länge der Eingabesequenz.
- (b) Positions-Feedforward-Netzwerke sind teure Subnetzwerke.
Die Beschleunigungsmethode wird im Folgenden erläutert (S ist die räumliche Dimension, T ist die Zeitbereichsdimension) und ihr Rahmen ist wie in der Abbildung dargestellt:
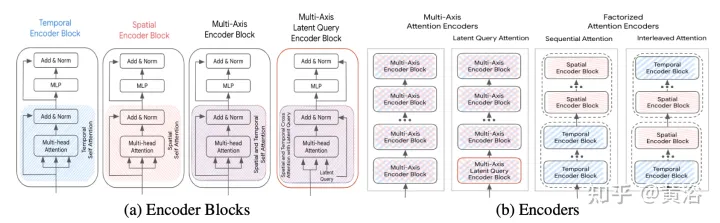
Mehrachsige Achtung: Dies bezieht sich auf Die standardmäßige Transformatoreinstellung, die Selbstaufmerksamkeit sowohl in räumlicher als auch in zeitlicher Dimension anwendet, dürfte die rechenintensivste sein. Die rechnerische Komplexität der vorderen, hinteren und hierarchischen Fusion mit mehrachsiger Aufmerksamkeit beträgt O(Sm2×T2).
Faktorisierte Aufmerksamkeit: Die rechnerische Komplexität der Selbstaufmerksamkeit ist das Quadrat der Länge der Eingabesequenz. Dies wird bei mehrdimensionalen Sequenzen noch deutlicher, da jede zusätzliche Dimension die Größe der Eingabe um einen multiplikativen Faktor erhöht. Einige Eingabemodalitäten haben beispielsweise Zeit- und Raumdimensionen, sodass der Rechenaufwand O(Sm2×T2) beträgt. Um diese Situation zu entschärfen, sollten Sie erwägen, die Aufmerksamkeit in zwei Dimensionen zu zerlegen. Diese Methode nutzt die mehrdimensionale Struktur der Eingabesequenz und reduziert die Kosten des Selbstaufmerksamkeits-Subnetzwerks von O(S2×T2) auf O(S2)+O(T2), indem Selbstaufmerksamkeit in jeder Dimension einzeln angewendet wird.
Während zerlegte Aufmerksamkeit das Potenzial hat, den Rechenaufwand im Vergleich zu mehrachsiger Aufmerksamkeit zu reduzieren, entsteht Komplexität, wenn die Selbstaufmerksamkeit auf die Reihenfolge jeder Dimension angewendet wird. Hier vergleichen wir zwei zerlegte Aufmerksamkeitsparadigmen:
- Sequentielle Aufmerksamkeit: Ein N-Schicht-Encoder besteht aus N/2 zeitlichen Encoderblöcken und einem weiteren N/2 räumlichen Encoderblock.
- Interleaved Attention: Der N-Layer-Encoder besteht aus zeitlichen und räumlichen Encoderblöcken, die sich N/2-mal abwechseln.
Achtung bei latenten Abfragen: Eine andere Möglichkeit, mit den Rechenkosten großer Eingabesequenzen umzugehen, besteht darin, latente Abfragen im ersten Encoderblock zu verwenden, wobei die Eingabe dem latenten Raum zugeordnet wird. Diese latenten Variablen werden von einer Reihe von Encoderblöcken weiterverarbeitet, die den latenten Raum empfangen und zurückgeben. Dies ermöglicht völlige Freiheit bei der Einstellung der Latentraumauflösung und reduziert den Rechenaufwand der Selbstaufmerksamkeitskomponente und des Positions-Feedforward-Netzwerks in jedem Block. Legen Sie den Reduzierungsbetrag (R=Lout/Lin) als Prozentsatz der Länge der Eingabesequenz fest. Bei der Postfusion und der hierarchischen Fusion bleibt der Reduktionsfaktor R für alle Aufmerksamkeitsencoder unverändert.
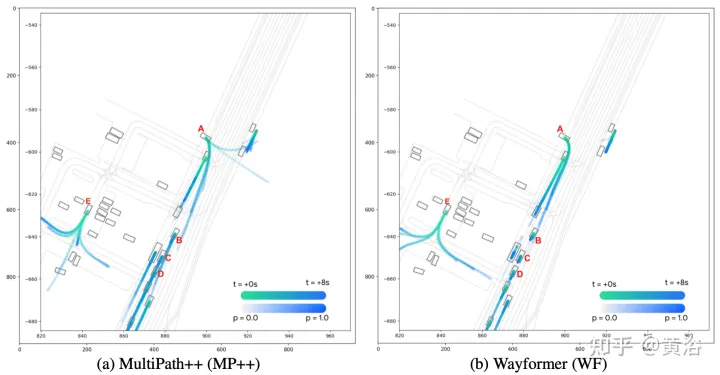
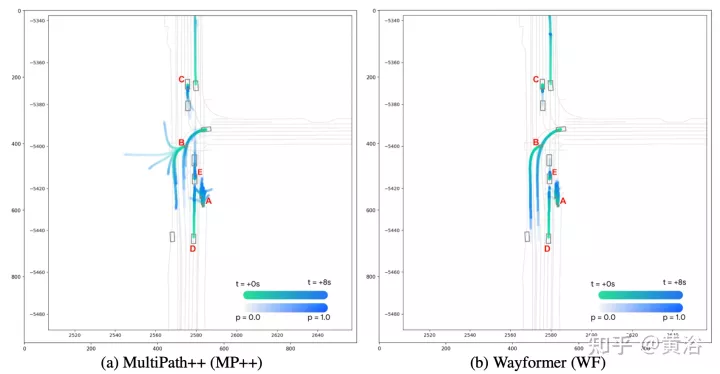
Der Wayformer-Prädiktor gibt eine Gaußsche Mischung aus, die die Flugbahn darstellt, die der Agent nehmen könnte. Um Vorhersagen zu generieren, wird ein Transformer-Decoder verwendet, der einen Satz von k gelernten Anfangsabfragen (Si) eingibt und eine Kreuzaufmerksamkeit mit den Szeneneinbettungen des Encoders durchführt, um Einbettungen für jede Komponente der Gaußschen Mischung zu generieren. Angesichts der Einbettung einer bestimmten Komponente in eine Mischung erzeugt eine lineare Projektionsebene eine nicht-kanonische Log-Wahrscheinlichkeit dieser Komponente und schätzt die gesamte Mischungswahrscheinlichkeit. Um Trajektorien zu erzeugen, wird eine weitere lineare Schichtprojektion verwendet, die 4 Zeitreihen ausgibt, die dem Mittelwert und der logarithmischen Standardabweichung der vorhergesagten Gaußschen Funktion in jedem Zeitschritt entsprechen. Während des Trainings wird der Verlust in entsprechende Klassifizierungs- und Regressionsverluste zerlegt. Unter der Annahme von k vorhergesagten Gaußschen Werten wird die Mischungswahrscheinlichkeit trainiert, um die logarithmische Wahrscheinlichkeit der wahren Flugbahn zu maximieren. Wenn der Prädiktor eine Mischung aus Gauß-Funktionen mit mehreren Modi ausgibt, ist es schwierig, Schlussfolgerungen zu ziehen, und Benchmark-Maßnahmen begrenzen häufig die Anzahl der berücksichtigten Trajektorien. Daher wird während des Bewertungsprozesses die Trajektorienaggregation angewendet, wodurch die Anzahl der berücksichtigten Modi reduziert wird und gleichzeitig die Vielfalt der ursprünglichen Ausgabemischung erhalten bleibt. Die experimentellen Ergebnisse sind wie folgt: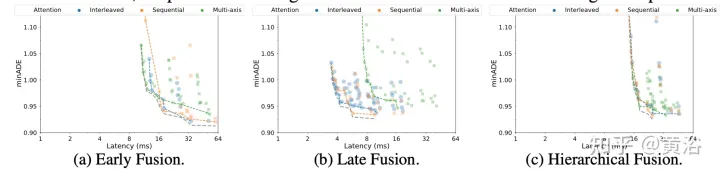
Das obige ist der detaillierte Inhalt vonWayformer: Ein einfaches und effektives Aufmerksamkeitsnetzwerk zur Bewegungsvorhersage. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Oben geschrieben und persönliches Verständnis des Autors. Dreidimensionales Gaussplatting (3DGS) ist eine transformative Technologie, die in den letzten Jahren in den Bereichen explizite Strahlungsfelder und Computergrafik entstanden ist. Diese innovative Methode zeichnet sich durch die Verwendung von Millionen von 3D-Gaußkurven aus, was sich stark von der Neural Radiation Field (NeRF)-Methode unterscheidet, die hauptsächlich ein implizites koordinatenbasiertes Modell verwendet, um räumliche Koordinaten auf Pixelwerte abzubilden. Mit seiner expliziten Szenendarstellung und differenzierbaren Rendering-Algorithmen garantiert 3DGS nicht nur Echtzeit-Rendering-Fähigkeiten, sondern führt auch ein beispielloses Maß an Kontrolle und Szenenbearbeitung ein. Dies positioniert 3DGS als potenziellen Game-Changer für die 3D-Rekonstruktion und -Darstellung der nächsten Generation. Zu diesem Zweck geben wir erstmals einen systematischen Überblick über die neuesten Entwicklungen und Anliegen im Bereich 3DGS.
 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
0. Vorab geschrieben&& Persönliches Verständnis, dass autonome Fahrsysteme auf fortschrittlichen Wahrnehmungs-, Entscheidungs- und Steuerungstechnologien beruhen, indem sie verschiedene Sensoren (wie Kameras, Lidar, Radar usw.) verwenden, um die Umgebung wahrzunehmen, und Algorithmen und Modelle verwenden für Echtzeitanalysen und Entscheidungsfindung. Dies ermöglicht es Fahrzeugen, Verkehrszeichen zu erkennen, andere Fahrzeuge zu erkennen und zu verfolgen, das Verhalten von Fußgängern vorherzusagen usw. und sich so sicher an komplexe Verkehrsumgebungen anzupassen. Diese Technologie erregt derzeit große Aufmerksamkeit und gilt als wichtiger Entwicklungsbereich für die Zukunft des Transportwesens . eins. Aber was autonomes Fahren schwierig macht, ist herauszufinden, wie man dem Auto klarmachen kann, was um es herum passiert. Dies erfordert, dass der dreidimensionale Objekterkennungsalgorithmus im autonomen Fahrsystem Objekte in der Umgebung, einschließlich ihrer Standorte, genau wahrnehmen und beschreiben kann.
 Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Die Trajektorienvorhersage spielt eine wichtige Rolle beim autonomen Fahren. Unter autonomer Fahrtrajektorienvorhersage versteht man die Vorhersage der zukünftigen Fahrtrajektorie des Fahrzeugs durch die Analyse verschiedener Daten während des Fahrvorgangs. Als Kernmodul des autonomen Fahrens ist die Qualität der Trajektorienvorhersage von entscheidender Bedeutung für die nachgelagerte Planungssteuerung. Die Trajektorienvorhersageaufgabe verfügt über einen umfangreichen Technologie-Stack und erfordert Vertrautheit mit der dynamischen/statischen Wahrnehmung des autonomen Fahrens, hochpräzisen Karten, Fahrspurlinien, Fähigkeiten in der neuronalen Netzwerkarchitektur (CNN&GNN&Transformer) usw. Der Einstieg ist sehr schwierig! Viele Fans hoffen, so schnell wie möglich mit der Flugbahnvorhersage beginnen zu können und Fallstricke zu vermeiden. Heute werde ich eine Bestandsaufnahme einiger häufiger Probleme und einführender Lernmethoden für die Flugbahnvorhersage machen! Einführungsbezogenes Wissen 1. Sind die Vorschaupapiere in Ordnung? A: Schauen Sie sich zuerst die Umfrage an, S
 SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
Originaltitel: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper-Link: https://arxiv.org/pdf/2402.02519.pdf Code-Link: https://github.com/HKUST-Aerial-Robotics/SIMPL Autor: Hong Kong University of Science und Technologie DJI-Papieridee: Dieses Papier schlägt eine einfache und effiziente Bewegungsvorhersagebasislinie (SIMPL) für autonome Fahrzeuge vor. Im Vergleich zum herkömmlichen Agent-Cent
 nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
Vorab geschrieben und Ausgangspunkt Das End-to-End-Paradigma verwendet ein einheitliches Framework, um Multitasking in autonomen Fahrsystemen zu erreichen. Trotz der Einfachheit und Klarheit dieses Paradigmas bleibt die Leistung von End-to-End-Methoden für das autonome Fahren bei Teilaufgaben immer noch weit hinter Methoden für einzelne Aufgaben zurück. Gleichzeitig erschweren die in früheren End-to-End-Methoden weit verbreiteten Funktionen der dichten Vogelperspektive (BEV) die Skalierung auf mehr Modalitäten oder Aufgaben. Hier wird ein Sparse-Search-zentriertes End-to-End-Paradigma für autonomes Fahren (SparseAD) vorgeschlagen, bei dem die Sparse-Suche das gesamte Fahrszenario, einschließlich Raum, Zeit und Aufgaben, ohne dichte BEV-Darstellung vollständig abbildet. Insbesondere ist eine einheitliche, spärliche Architektur für die Aufgabenerkennung einschließlich Erkennung, Verfolgung und Online-Zuordnung konzipiert. Zudem schwer
 Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Im vergangenen Monat hatte ich aus bekannten Gründen einen sehr intensiven Austausch mit verschiedenen Lehrern und Mitschülern der Branche. Ein unvermeidliches Thema im Austausch ist natürlich End-to-End und der beliebte Tesla FSDV12. Ich möchte diese Gelegenheit nutzen, einige meiner aktuellen Gedanken und Meinungen als Referenz und Diskussion darzulegen. Wie definiert man ein durchgängiges autonomes Fahrsystem und welche Probleme sollten voraussichtlich durchgängig gelöst werden? Gemäß der traditionellsten Definition bezieht sich ein End-to-End-System auf ein System, das Rohinformationen von Sensoren eingibt und für die Aufgabe relevante Variablen direkt ausgibt. Bei der Bilderkennung kann CNN beispielsweise als End-to-End bezeichnet werden, verglichen mit der herkömmlichen Methode zum Extrahieren von Merkmalen + Klassifizieren. Bei autonomen Fahraufgaben werden Eingabedaten verschiedener Sensoren (Kamera/LiDAR) benötigt
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
